Post Syndicated from Vara Bonthu original https://aws.amazon.com/blogs/big-data/building-a-serverless-data-quality-and-analysis-framework-with-deequ-and-aws-glue/
With ever-increasing amounts of data at their disposal, large organizations struggle to cope with not only the volume but also the quality of the data they manage. Indeed, alongside volume and velocity, veracity is an equally critical issue in data analysis, often seen as a precondition to analyzing data and guaranteeing its value. High-quality data is commonly described as fit for purpose and a fair representation of the real-world constructs it depicts. Ensuring data sources meet these requirements is an arduous task that is best addressed through an automated approach and adequate tooling.
Challenges when running data quality at scale can include choosing the right data quality tools, managing the rules and constraints to apply on top of the data, and taking on the large upfront cost of setting up infrastructure in production.
Deequ, an open-source data quality library developed internally at Amazon, addresses these requirements by defining unit tests for data that it can then scale to datasets with billions of records. It provides multiple features, like automatic constraint suggestions and verification, metrics computation, and data profiling. For more information about how Deequ is used at Amazon, see Test data quality data at scale with Deequ.
You need to follow several steps to implement Deequ in production, including building the infrastructure, writing custom AWS Glue jobs, profiling the data, and generating rules before applying them. In this post, we introduce an open-source Data Quality and Analysis Framework (DQAF) that simplifies this process and its orchestration. Built on top of Deequ, this framework makes it easy to create the data quality jobs that you need, manage the associated constraints through a web UI, and run them on the data as you ingest it into your data lake.
Architecture
As illustrated in the following architecture diagram, the DQAF exclusively uses serverless AWS technology. It takes a database and tables in the AWS Glue Data Catalog as inputs to AWS Glue jobs, and outputs various data quality metrics into Amazon Simple Storage Service (Amazon S3). Additionally, it saves time by automatically generating constraints on previously unseen data. The resulting suggestions are stored in Amazon DynamoDB tables and can be reviewed and amended at any point by data owners in the AWS Amplify managed UI. Amplify makes it easy to create, configure, and implement scalable web applications on AWS. The orchestration of these operations is carried out by an AWS Step Functions workflow. The code, artifacts, and an installation guide are available in the GitHub repository.

In this post, we walk through a deployment of the DQAF using some sample data. We assume you have a database in the AWS Glue Data Catalog hosting one or more tables in the same Region where you deploy the framework. We use a legislators database with two tables (persons_json and organizations_json) referencing data about United States legislators. For more information about this database, see Code Example: Joining and Relationalizing Data.

Deploying the solution
Click on the button below to launch an AWS CloudFormation stack that deploys the solution in your AWS account in the last Region that was used:
![]()
The process takes 10–15 minutes to complete. You can verify that the framework was successfully deployed by checking that the CloudFormation stacks show the status CREATE_COMPLETE.

Testing the data quality and analysis framework
The next step is to understand (profile) your test data and set up data quality constraints. Constraints can be defined as a set of rules to validate whether incoming data meets specific requirements along various dimensions (such as completeness, consistency, or contextual accuracy). Creating these rules can be a painful process if you have lots of tables with multiple columns, but DQAF makes it easy by sampling your data and suggesting the constraints automatically.
On the Step Functions console, locate the data-quality-sm state machine, which represents the entry point to data quality in the framework. When you provide a valid input, it starts a series of AWS Glue jobs running Deequ. This step function can be called on demand, on a schedule, or based on an event. You run the state machine by entering a value in JSON format.

First pass and automatic suggestion of constraints
After the step function is triggered, it calls the AWS Glue controller job, which is responsible for determining the data quality checks to perform. Because the submitted tables were never checked before, a first step is to generate data quality constraints on attributes of the data. In Deequ, this is done through an automatic suggestion of constraints, a process where data is profiled and a set of heuristic rules is applied to suggest constraints. It’s particularly useful when dealing with large multi-column datasets. In the framework, this operation is performed by the AWS Glue suggestions job, which logs the constraints into the DataQualitySuggestions DynamoDB table and outputs preliminary quality check results based on those suggestions into Amazon S3 in Parquet file format.
AWS Glue suggestions job
The Deequ suggestions job generates constraints based on three major dimensions:
- Completeness – Measures the presence of null values, for example
isComplete("gender")orisComplete("name") - Consistency – Consistency of data types and value ranges, for example
.isUnique("id")orisContainedIn("gender",Array("female","male")) - Statistics – Univariate dimensions in the data, for example
.hasMax("Salary",“90000”)or.hasSize(_>=10)
The following table lists the available constraints that can be manually added in addition to the automatically suggested ones.
| Constraints | Argument | Semantics |
| Dimension Completeness | ||
| isComplete | column | Check that there are no missing values in a column |
| hasCompleteness | column, udf | Custom validation of missing values in a column |
| Dimension Consistency | ||
| isUnique | column | Check that there are no duplicates in a column |
| hasUniqueness | column, udf | Custom validation of the unique value ratio in a column |
| hasDistinctness | column, udf | Custom validation of the unique row ratio in a column |
| isInRange | column, value range | Validation of the fraction of values that are in a valid range |
| hasConsistentType | column | Validation of the largest fraction of values that have the same type |
| isNonNegative | column | Validation whether all the values in a numeric column are non-negative |
| isLessThan | column pair | Validation whether all the values in the first column are always less than the second column |
| satisfies | predicate | Validation whether all the rows match predicate |
| satisfiesIf | predicate pair | Validation whether all the rows matching first predicate also match the second predicate |
| hasPredictability | column, column(s), udf | User-defined validation of the predictability of a column |
| Statistics (can be used to verify dimension consistency) | ||
| hasSize | udf | Custom validation of the number of records |
| hasTypeConsistency | column, udf | Custom validation of the maximum fraction of the values of the same datatype |
| hastCountDistinct | column | Custom validation of the number of distinct non null values in a column |
| hasApproxCountDistinct | column, udf | Custom validation of the approximate number of distinct non-null values |
| hasMin | column, udf | Custom validation of the column’s minimum value |
| hasMax | column, udf | Custom validation of the column’s maximum value |
| hasMean | column, udf | Custom validation of the column’s mean value |
| hasStandardDeviation | column, udf | Custom validation of the column’s standard deviation value |
| hasApproxQuantile | column,quantile,udf | Custom validation of a particular quantile of a column (approximate) |
| hasEntropy | column, udf | Custom validation of the column’s entropy |
| hasMutualInformation | column pair,udf | Custom validation of the column pair’s mutual information |
| hasHistogramValues | column, udf | Custom validation of the column’s histogram |
| hasCorrelation | column pair,udf | Custom validation of the column pair’s correlation |
The following screenshot shows the DynamoDB table output with suggested constraints generated by the AWS Glue job.

AWS Glue data profiler job
Deequ also supports single-column profiling of data, and its implementation scales to large datasets with billions of rows. As a result, we get a profile for each column in the data, which allows us to inspect the completeness of the column, the approximate number of distinct values, and the inferred datatype.
The controller triggers an AWS Glue data profiler job in parallel to the suggestions job. This profiler Deequ process runs three passes over the data and avoids any shuffles in order to easily scale to large datasets. Results are stored as Parquet files in the S3 data quality bucket.
When the controller job is complete, the second step in the data quality state machine is to crawl the Amazon S3 output data into a data_quality_db database in the AWS Glue Data Catalog, which is then immediately available to be queried in Amazon Athena. The following screenshot shows the list of tables created by this AWS Glue framework and a sample output from the data profiler results.

Reviewing and verifying data quality constraints
As good as Deequ is at suggesting data quality rules, the data stewards should first review the constraints before applying them in production. Because it may be cumbersome to edit large tables in DynamoDB directly, we have created a web app that enables you to add or amend the constraints. The changes are updated in the relevant DynamoDB tables in the background.
Accessing the web front end
To access the user interface, on the AWS Amplify console, choose the deequ-constraints app. Choosing the URL (listed as https://<env>.<appsync_app_id>.amplifyapp.com) opens the data quality constraints front end. After you complete the registration process with Amazon Cognito (create an account) and sign in, you see a UI similar to the following screenshot.

It lists data quality constraint suggestions produced by the AWS Glue job in the previous step. Data owners can add or remove and enable or disable these constraints at any point via the UI. Suggestions are not enabled by default. This makes sure all constraints are human reviewed before they are processed. Choosing the check box enables a constraint.
Data analyzer (metric computations)
Alongside profiling, Deequ can also generate column-level statistics called data analyzer metrics (such as completeness, maximum, and correlation). They can help uncover data quality problems, for example by highlighting the share of null values in a primary key or the correlation between two columns.
The following table lists the metrics that you can apply to any column.
| Metric | Semantics |
| Dimension Completeness | |
| Completeness | Fraction of non-missing values in a column |
| Dimension Consistency | |
| Size | Number of records |
| Compliance | Ratio of columns matching predicate |
| Uniqueness | Unique value ratio in a column |
| Distinctness | Unique row ratio in a column |
| ValueRange | Value range verification for a column |
| DataType | Data type inference for a column |
| Predictability | Predictability of values in a column |
| Statistics (can be used to verify dimension consistency) | |
| Minimum | Minimal value in a column |
| Maximum | Maximal value in a column |
| Mean | Mean value in a column |
| StandardDeviation | Standard deviation of the value distribution in a column |
| CountDistinct | Number of distinct values in a column |
| ApproxCountDistinct | Number of distinct values in a column |
| ApproxQuantile | Approximate quantile of the value in a column |
| Correlation | Correlation between two columns |
| Entropy | Entropy of the value distribution in a column |
| Histogram | Histogram of an optionally binned column |
| MutualInformation | Mutual information between two columns |
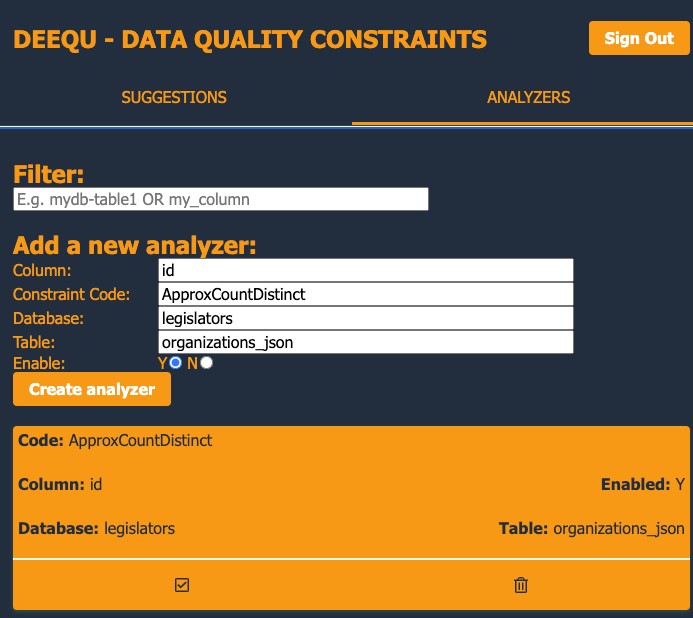
In the web UI, you can add these metrics on the Analyzers tab. In the following screenshot, we add an ApproxCountDistinct metric on an id column. Choosing Create analyzer inserts the record into the DataQualityAnalyzer table in DynamoDB and enables the constraint.
AWS Glue verification job
We’re now ready to put our rules into production and can use Athena to look at the resultsYou can start running the step function with the same JSON as input:
This time the AWS Glue verification job is triggered by the controller. This job performs two actions: it verifies the suggestion constraints and performs metric computations. You can immediately query the results in Athena under the constraints_verification_results table.
The following screenshot shows the verification output.

The following screenshot shows the metric computation results.

Summary
Dealing with large, real-world datasets requires a scalable and automated approach to data quality. Deequ is the tool of choice at Amazon when it comes to measuring the quality of large production datasets. It’s used to compute data quality metrics, suggest and verify constraints, and profile data.
This post introduced an open-source, serverless Data Quality and Analysis Framework that aims to simplify the process of deploying Deequ in production by setting up the necessary infrastructure and making it easy to manage data quality constraints. It enables data owners to generate automated data quality suggestions on previously unseen data that can then be reviewed and amended in a UI. These constraints serve as inputs to various AWS Glue jobs in order to produce data quality results queryable via Athena. Try this framework on your data and leave suggestions on how to improve it on our open-source GitHub repo.
About the Authors

Vara Bonthu is a Senior BigData/DevOps Architect for ProServe working with the Global Accounts team. He is passionate about big data and Kubernetes. He helps customers all over the world design, build, and migrate end-to-end data analytics and container-based solutions. In his spare time, he develops applications to help educate his 7-year-old autistic son.

Abdel Jaidi is a Data & Machine Learning Engineer for AWS Professional Services. He works with customers on Data & Analytics projects, helping them shorten their time to value and accelerate business outcomes. In his spare time, he enjoys participating in triathlons and walking dogs in parks in and around London.