Post Syndicated from Vara Bonthu original https://aws.amazon.com/blogs/big-data/run-apache-spark-with-amazon-emr-on-eks-backed-by-amazon-fsx-for-lustre-storage/
Traditionally, Spark workloads have been run on a dedicated setup like a Hadoop stack with YARN or MESOS as a resource manager. Starting from Apache Spark 2.3, Spark added support for Kubernetes as a resource manager. The new Kubernetes scheduler natively supports the submission of Spark jobs to a Kubernetes cluster. Spark on Kubernetes provides simpler administration, better developer experience, easier dependency management with containers, a fine-grained security layer, and optimized resource allocation. As a result, Spark on Kubernetes gained much traction for high-performance and cost-effective ways of running big data and machine learning (ML) workloads.
In AWS, we offer a managed service, Amazon EMR on EKS, to run your Apache Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) . This service uses the Amazon EMR runtime for Apache Spark, which increases the performance of your Spark jobs so that they run faster and cost less. EMR on EKS lets you run Spark applications alongside other application types on the same Amazon EKS cluster to improve resource utilization. In addition, EMR on EKS integrates with Amazon EMR Studio for authoring jobs and the Apache Spark UI for debugging out of the box to simplify infrastructure management.
For storage, EMR on EKS supports node ephemeral storage using hostPath where the storage is attached to individual nodes, and Amazon Elastic Block Store (Amazon EBS) volume per executor/driver pod using dynamic Persistent Volume Claims. However, some Spark users are looking for an HDFS-like shared file system to handle specific workloads like time-sensitive applications or streaming analytics. HDFS is best suited for jobs that requires highly interactive speed for a large number of files with random access reads, atomic rename operations, and sequential metadata requests.
Amazon FSx for Lustre is a fully managed shared storage option built on the world’s most popular high-performance file system. It offers highly scalable, cost-effective storage, which provides sub-millisecond latencies, millions of IOPS, and throughput of hundreds of gigabytes per second. Its popular use cases include high-performance computing (HPC), financial modeling, video rendering, and machine learning. FSx for Lustre supports two types of deployments:
- Scratch file systems – These are designed for temporary or short-term storage where the data is not needed to replicate or persist if a file server fails
- Persistent file systems – These are suitable for long-term storage where the file server is highly available and the data is replicated within the Availability Zone
In both deployment types, automatic data sync between the mounted file system and Amazon Simple Storage Service (Amazon S3) buckets is supported, helping you offload large volumes of cold and warm data for a better cost-efficient design. It makes multi-AZ or multi-region failover possible via Amazon S3 for businesses that require resiliency and availability.
This post demonstrates how to use EMR on EKS to submit Spark jobs with FSx for Lustre as the storage. It can be mounted on Spark driver and executor pods through static and dynamic PersistentVolumeClaims methods.
Static vs. dynamic provisioning
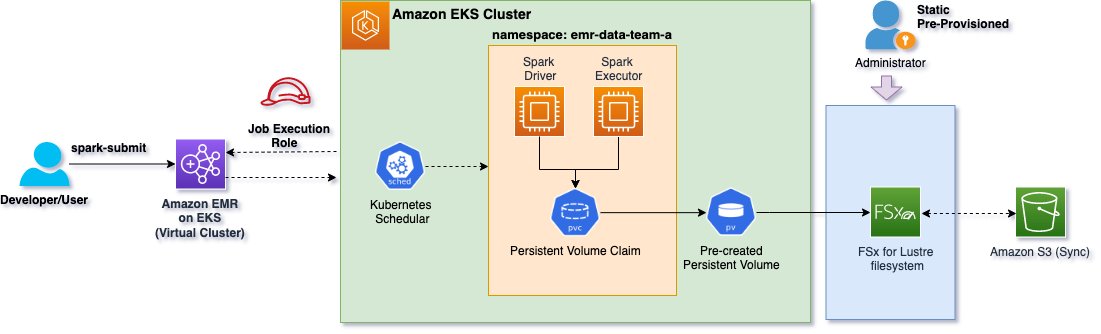
With static provisioning, the FSx for Lustre file system and PersistentVolume (PV) must be created in advance. The following diagram illustrates the static provisioning architecture. The Spark application driver and executor pods refer to an existing static PersistentVolumeClaim (PVC) to mount the FSx for Lustre file system.
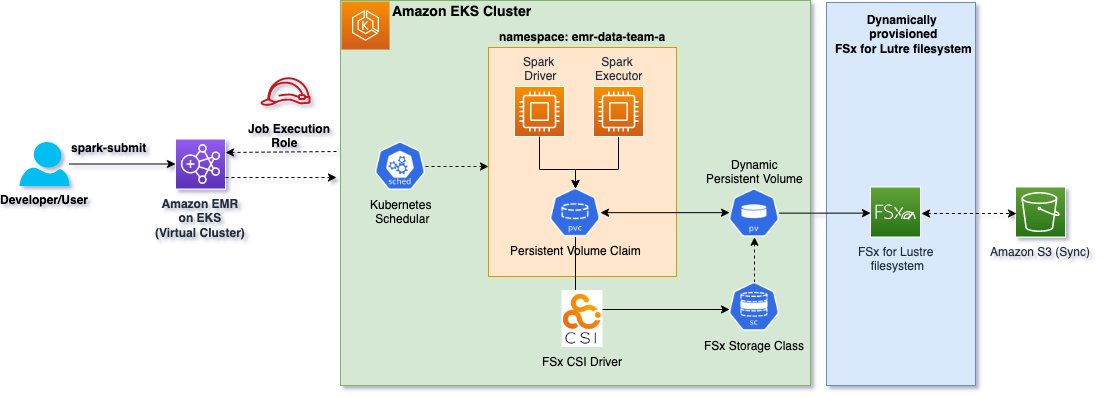
Unlike static provisioning, the FSx for Lustre file system and PV doesn’t need to be pre-created for dynamic provisioning. As shown in the following diagram, the FSx for Lustre CSI driver plugin is deployed to an Amazon EKS cluster to dynamically provision the FSx for Lustre file system with a given PVC. Dynamic provisioning only requires a PVC and the corresponding storage class. After the PVC is created in Kubernetes, the FSx for Lustre CSI driver identifies the storage class and creates the requested file system.
The Spark application driver and executor pods in the architecture refer to an existing dynamic PVC to mount the FSx for Lustre file system.
Solution overview
In this post, you provision the following resources with Amazon EKS Blueprints for Terraform to run Spark jobs using EMR on EKS:
- A VPC, three private subnets, three public subnets, a single NAT gateway, and an internet gateway
- An Amazon EKS cluster with two managed node groups:
- A core node group (
core-node-grp) for placing all the critical Kubernetes add-on deployments - A Spark node group (
spark-node-grp) for running the Spark jobs
- A core node group (
- An EMR on EKS virtual cluster, namespace, service accounts, and IAM Roles for Service Accounts (IRSA)
- An FSx for Lustre persistent file system, FSx storage class, Persistent Volume, and Persistent Volume Claim for static provisioning.
- An S3 bucket for the data sync between the static FSx for Lustre file system and S3 bucket
- A Persistent Volume Claim for dynamic provisioning.
- Kubernetes add-ons CoreDNS, Cluster Autoscaler, Prometheus Server with Vertical Pod Scaler, Amazon Prometheus, and FSx for Lustre CSI driver
Pre-requisites
Before you build the entire infrastructure, you must have the following prerequisites:
- An AWS account with valid AWS credentials with assumed AWS Identity and Access Management (IAM) role
- The AWS Command Line Interface (AWS CLI) installed
- Terraform 1.0.1
- kubectl installed
Now you’re ready to deploy the solution.
Clone the GitHub repo
Open your terminal window, change to the home directory, and clone the GitHub repo:
Then, navigate to the following:
Initialize Terraform
Initialize the project, which downloads plugins that allow Terraform to interact with AWS services:
Run terraform plan
Run terraform plan to verify the resources created by this deployment:
The terraform plan output shows the resources that are created by this plan.
Run terraform apply
Run terraform apply to deploy the resources:
This deployment may take up to 30 minutes to create all the resources.
Verify the resources
Verify the Amazon EKS cluster created by the deployment. This following command displays the cluster details in JSON format:
Let’s create a kubeconfig file for the EKS cluster with the following command. This command creates a new cluster context entry with certificate authority data under ~/.kube/config to authenticate with the EKS cluster:
Verify the managed node groups:
The output should show two node groups:
List the pods created by the FSx for Lustre CSI driver. The following command shows two controllers and an fsx-csi-node daemonset pod for each node:
List the namespace created for emr-data-team-a:
The output will display the active namespace.
List the FSx storage class, PV, and PVCs created by this deployment. You may notice that fsx-dynamic-pvc is in Pending status because this dynamic PVC is still creating the FSx for Lustre. The dynamic PV status changed to Bound after the file system was created.
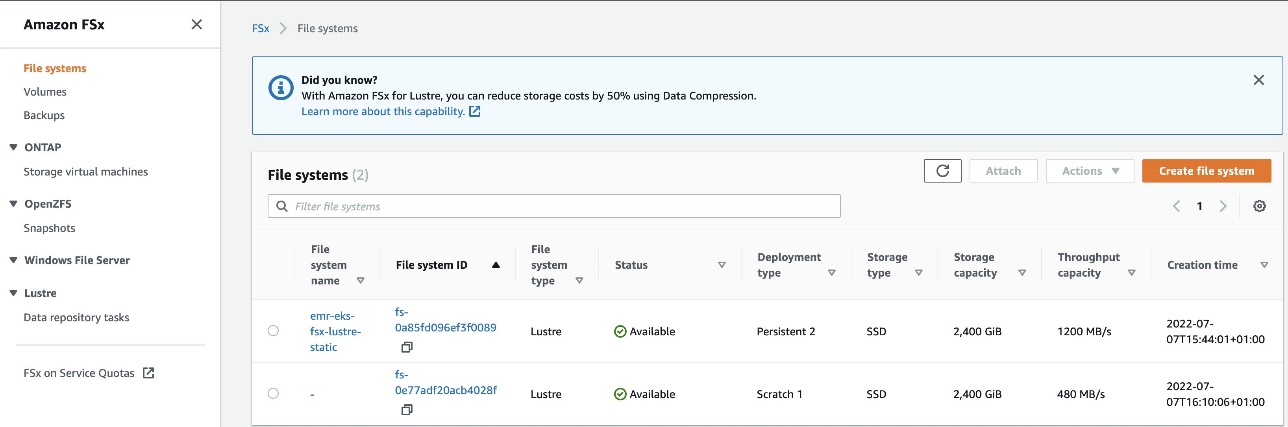
Log in to the FSx for Lustre console and verify the two file systems created by this deployment:
- The first file system (
emr-eks-fsx-lustre-static) is a persistent file system created with the Terraform resource - The second file system (
fs-0e77adf20acb4028f) is created by the FSx for Lustre CSI driver dynamically with a dynamic PVC manifest
In this demo, we learn how to use a statically provisioned FSx for Lustre file system and dynamically provisioned FSx for Lustre file system in EMR on EKS Spark jobs.
Static provisioning
You can create an FSx for Lustre file system using the AWS CLI or any infrastructure as code (IaC) tool. In this example, we used Terraform to create the FSx for Lustre file system with deployment type as PERSISTENT_2. For static provisioning, we must create the FSx for Lustre file system first, followed by the PV and PVCs. After we create all three resources, we can mount the FSx for Lustre file system on a Spark driver and executor pod.
We use the following Terraform code snippet in the deployment to create the FSx for Lustre file system (2400 GB) and the file system association with the S3 bucket for import and export under the /data file system path. Note that this resource refers to a single subnet (single Availability Zone) for creating an FSx for Lustre file system. However, the Spark pods can use this file system across all Availability Zones, unlike the EBS volume, which is Availability Zone specific. In addition, the FSx for Lustre association with the S3 bucket creates a file system directory called /data. The Spark job driver and executor pod templates use this /data directory as a spark-local-dir for scratch space.
Persistent Volume
The following YAML template shows the definition of the PV created by this deployment. For example, running the command kubectl edit pv fsx-static-pv -n kube-system displays the manifest. PVs are a cluster scoped resource, therefore no namespace is defined in the template. The DevOps or cluster admin teams typically create this.
Persistent Volume Claim
The following YAML template shows the definition of the PVC created by this deployment. For example, running the command kubectl edit pvc fsx-static-pvc -n emr-data-team-a shows the deployed resource.
PVCs are namespace-specific resources typically created by the developers. The emr-data-team-a namespace is defined in the template.
Now that we have set up the static FSx for Lustre file system, we can use the PVC in EMR on EKS Spark jobs with pod templates. Key things to note in the template are that the volumes section in the following code is defined as persistentVolumeClaim with the claim name as fsx-static-pvc, and the containers section refers to the unique mountPath folder /static. We also use initContainers in the driver pod template to give correct permissions and ownership to the Hadoop users to be used by EMR on EKS driver executor pods. Finally, notice that data in the subPath is associated with the S3 bucket sync in the preceding Terraform resource.
We use the following driver pod template:
The executor pod template also refers to the same persistentVolumeClaim as fsx-static-pvc and volumeMounts with mountPath as /static. Notice that we don’t use the initContainers section in this template because the required permissions for the file system directory /static/data have been applied by the driver processes already. Because it’s a shared file system, the same permissions apply to the executor process as well.
Let’s run the sample PySpark script using the preceding pod templates. Navigate to the examples/spark-execute directory and run the shell script (fsx-static-spark.sh):
This shell script expects three input values. EMR_VIRTUAL_CLUSTER_ID and EMR_JOB_EXECUTION_ROLE_ARN can be extracted from the Terraform output values. Additionally, you create an S3 bucket with required permissions. This S3 bucket stores the sample PySpark scripts, pod templates, input and output data generated by this shell script, and the Spark job. Check out the shell script for more details.
Let’s run the fsx-static-spark.sh shell script. This job takes approximately 6 minutes by two executors, which processes 40 objects with a total size of 1.4 GB. Each object is around 36.4 MB. You can adjust the number of objects from 40 to any large number to process a large amount of data. This shell script downloads the public dataset (NY Taxi Trip Data) locally in your disk and uploads it to the S3 bucket using Amazon S3 sync. PySpark jobs read the data from the S3 buckets, apply GroupBy on a few fields, and write back to the S3 bucket to demonstrate the shuffling activity.
You can run the following queries to monitor the Spark job and the usage of the FSx for Lustre file system mounted on the driver and executor pods. Verify the job run events with the following command:
You will notice one job object pod, a driver pod, and two executor pods. The Spark executor instances count can be updated in the Shell script.
You can also query to monitor the usage of FSx for Lustre mounted file system size. The following command shows the size of the mounted file system growth during the test run:
The following diagram shows the output for the preceding commands. The files under the executor are the same as those under the S3 bucket. These files are the same because the S3 sync feature is enabled in the FSx for Lustre file system. This test uses the FSx for Lustre file system for scratch space, so the shuffle files will be deleted from the FSx for Lustre file system and S3 bucket when the test is complete.
This PySpark job is writing the aggregated and repartition output directly to an S3 bucket location. Instead, you can choose to write to the FSx for Lustre file system path, which syncs to an S3 bucket eventually. The FSx for Lustre file system provides low latency, high throughput, and high IOPS for reading and writing data by multiple Spark Jobs. In addition, the data stored in FSx disk is synced to an S3 bucket for durable storage.

You can monitor the FSx for Lustre file system using Amazon CloudWatch metrics. The following time series graph shows the average stats with a period of 30 seconds.

When the Spark job is complete, you can verify the results in the Spark Web UI from the EMR on EKS console.
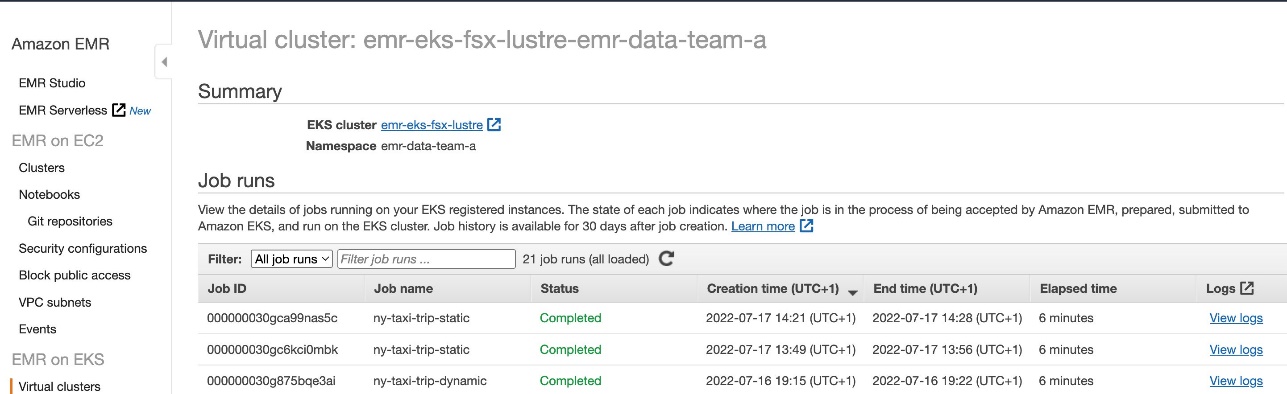
You can also verify the FSx for Lustre file system data sync to an S3 bucket.

Dynamic provisioning
So far, we have looked at an FSx for Lustre statically provisioned file system example and its usage with Spark jobs.
We can also provision an FSx for Lustre file system on-demand using the FSx for Lustre CSI driver and Persistent Volume Claim. Whenever you create a PVC with a dynamic volume referring to an FSx storage class, the FSx for Lustre CSI driver automatically provisions the FSx for Lustre file system and the corresponding Persistent Volume. Admin teams (DevOps) are responsible for deploying the FSx for Lustre CSI driver and FSx storage class, and the developers and data engineers (DataOps) are responsible for deploying the PVC, which refers to the FSx storage class.
The following storage class is deployed to Amazon EKS by this Terraform deployment. This dynamic PVC example doesn’t use the Amazon S3 backup association. You can still do that, but it requires an Amazon S3 config in the storage class manifest. Check out Dynamic Provisioning with Data Repository to configure the FSx storage class with the S3 import/export path with the choice of deployment type (SCRATCH_1, SCRATCH_2 and PERSISTENT_1). We have also created a dedicated security group used in this manifest. For more information, refer to File System Access Control with Amazon VPC.
The following YAML template shows the definition of the dynamic PVC used in this deployment. Running the command kubectl edit pvc fsx-dynamic-pvc -n emr-data-team-a shows the deployed resource. PVCs are a namespace-specific resources typically created by the developers, therefore we define the emr-data-team-a namespace.
Spark can dynamically provision the PVC with claimName using SparkConf (for example, spark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=OnDemand). However, we recommend deploying the PVC before the start of Spark jobs to avoid delays to provision the FSx for Lustre file system during the job run. The FSx for Lustre file system takes approximately 10–12 minutes to complete.
Now that we have set up the dynamic FSx for Lustre file system, we can use this in EMR on EKS Spark jobs using pod templates. Key things to note in the following template are that the volumes section is defined as persistentVolumeClaim with the claim name as fsx-dynamic-pvc, and the containers section refers to the unique mountPath folder as /dynamic. We also use initContainers in the driver pod template to give correct permissions and ownership to the Hadoop users to be used by EMR on EKS driver executor processes.
The following is our driver pod template:
The executor pod template also refers to the same persistentVolumeClaim as fsx-dynamic-pvc and volumeMounts with mountPath as /dynamic:
Let’s run the sample PySpark script using the preceding pod templates. Navigate to the examples/spark-execute directory and run the shell script (fsx-dynamic-spark.sh). This script is the same as the static provisioning example; the only difference is the pod templates, which refer to the dynamic volumes.
This shell script expects three input values: EMR_VIRTUAL_CLUSTER_ID, EMR_JOB_EXECUTION_ROLE_ARN, and your S3 bucket name. Use the same values used in the previous static provisioning example.
Let’s run the fsx-dynamic-spark.sh shell script:
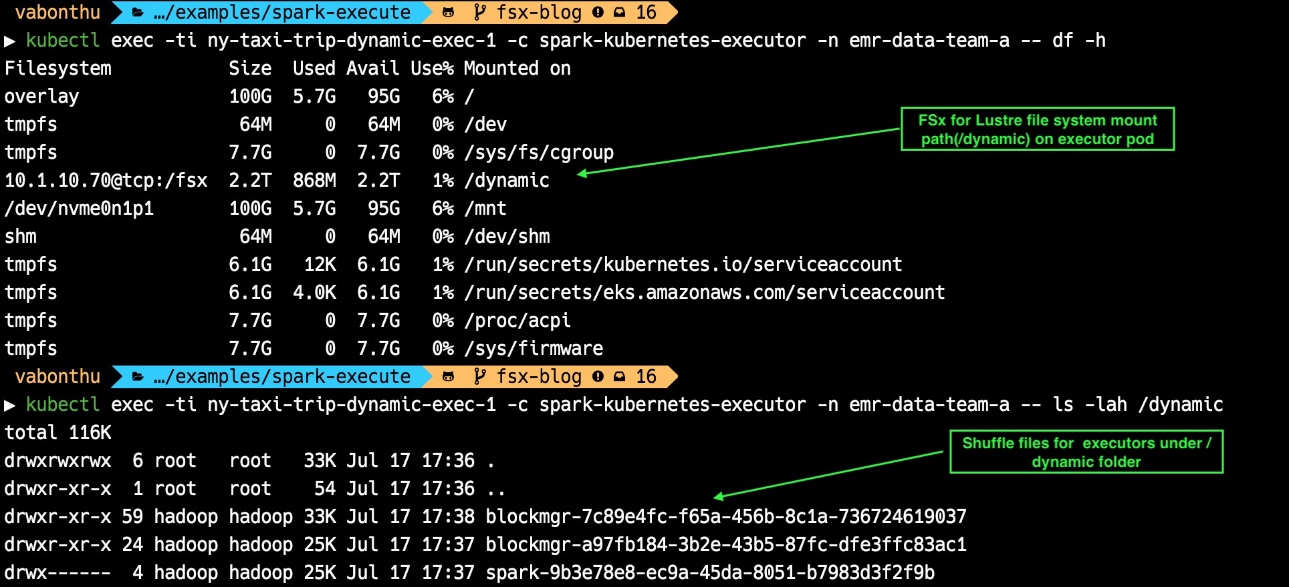
After the job is triggered, run the following commands to see the output of the job:
The following screenshot shows the file system mounted under the /dynamic path. We can also see the Spark shuffle files created in the /dynamic folder.
Clean up
To clean up your environment, destroy the Terraform modules in reverse order. Then, empty any S3 buckets created by this module and run the following commands:
Furthermore, log in to the AWS Management Console and delete any S3 buckets or FSX for Lustre file systems created by this deployment to avoid unwanted charges to your AWS account.
Conclusion
In this post, we demonstrated how to mount an FSx for Lustre file system as a PVC to Spark applications with EMR on EKS. We showed two mounting methods: static provisioning and dynamic provisioning via the FSx for Lustre CSI driver. The HDFS-like storage can be used by Spark on a Kubernetes pattern to achieve optimal storage performance. You can use it either as a temporary scratch space to store intermediate data while processing, or as a shared, persistent file system to exchange data for multiple pods in a single job or between multiple Spark jobs.
If you want to try out the full solution or for more EMR on EKS examples, check out our open-sourced project on GitHub.
About the authors
 Vara Bonthu is a Senior Open Source Engineer focused on data analytics and containers working with Strategic Accounts. He is passionate about open source, big data, Kubernetes, and has a substantial development, DevOps, and architecture background.
Vara Bonthu is a Senior Open Source Engineer focused on data analytics and containers working with Strategic Accounts. He is passionate about open source, big data, Kubernetes, and has a substantial development, DevOps, and architecture background.
 Karthik Prabhakar is a Senior Analytics Specialist Solutions Architect at AWS, helping strategic customers adopt and run AWS Analytics services.
Karthik Prabhakar is a Senior Analytics Specialist Solutions Architect at AWS, helping strategic customers adopt and run AWS Analytics services.
 Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering, and DataOps.
Melody Yang is a Senior Big Data Solutions Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering, and DataOps.