Post Syndicated from Meyer Zinn original https://blog.cloudflare.com/making-magic-transit-health-checks-faster-and-more-responsive/


Magic Transit advertises our customer’s IP prefixes directly from our edge network, applying DDoS mitigation and firewall policies to all traffic destined for the customer’s network. After the traffic is scrubbed, we deliver clean traffic to the customer over GRE tunnels (over the public Internet or Cloudflare Network Interconnect). But sometimes, we experience inclement weather on the Internet: network paths between Cloudflare and the customer can become unreliable or go down. Customers often configure multiple tunnels through different network paths and rely on Cloudflare to pick the best tunnel to use if, for example, some router on the Internet is having a stormy day and starts dropping traffic.
Because we use Anycast GRE, every server across Cloudflare’s 200+ locations globally can send GRE traffic to customers. Every server needs to know the status of every tunnel, and every location has completely different network routes to customers. Where to start?
In this post, I’ll break down my work to improve the Magic Transit GRE tunnel health check system, creating a more stable experience for customers and dramatically reducing CPU and memory usage at Cloudflare’s edge.
Everybody has their own weather station
To decide where to send traffic, Cloudflare edge servers need to periodically send health checks to each customer tunnel endpoint.
When Magic Transit was first launched, every server sent a health check to every tunnel once per minute. This naive, “shared-nothing” approach was simple to implement and served customers well, but would occasionally deliver less than optimal health check behavior in two specific ways.
Way #1: Inconsistent weather reports
Sometimes a server just runs into bad luck, and a check randomly fails. From there, the server would mark the tunnel as degraded and immediately start shifting traffic towards a fallback tunnel. Imagine you and I were standing right next to each other under a clear sky, and I felt a single drop of water and declared, “It’s raining!” whereas you felt no raindrops and declared, “It’s all clear!”
With relatively minimal data per server, it means that health determinations can be imprecise. It also means that individual servers could overreact to individual failures. From a customer’s point of view, it’s like Cloudflare detected a problem with the primary tunnel. But, in reality, the server just got a bad weather forecast and made a different judgement call.
Way #2: Slow to respond to storms
Even when tunnel states are consistent across servers, they can be slow to respond. In this case, if a server runs a health check which succeeds, but a second later the tunnel goes down, the next health check won’t happen for another 59 seconds. Until that next health check fails, the server has no idea anything is wrong, so it keeps sending traffic over unhealthy tunnels, leading to packet loss and latency for the customer.
Much like how a live, up-to-the-minute rain forecast helps you decide when to leave to avoid the rain, servers that send tunnel checks more frequently get a finer view of the Internet weather and can respond faster to localized storms. But if every server across Cloudflare’s edge sent health checks too frequently, we would very quickly start to overwhelm our customers’ networks.
All of the weather stations nearby start sharing observations
Clearly, we needed to hammer out some kinks. We wanted servers in the same location to come to the same conclusions about where to send traffic, and we wanted faster detection of issues without increasing the frequency of tunnel checks.
Health checks sent from servers in the same data center take the same route across the Internet. Why not share the results among them?
Instead of a single raindrop causing me to declare that it’s raining, I’d tell you about the raindrop I felt, and you’d tell me about the clear sky you’re looking at. Together, we come to the same conclusion: there isn’t enough rain to open an umbrella.
There is even a special networking protocol that allows us to easily share information between servers in the same private network. From the makers of Unicast and Anycast, now presenting: Multicast!
A single IP address does not necessarily represent a single machine in a network. The Internet Protocol specifies a way to send one message that gets delivered to a group of machines, like writing to an email list. Every machine has to opt into the group—we can’t just enroll people at random for our email list—but once a machine joins, it receives a copy of any message sent to the group’s address.
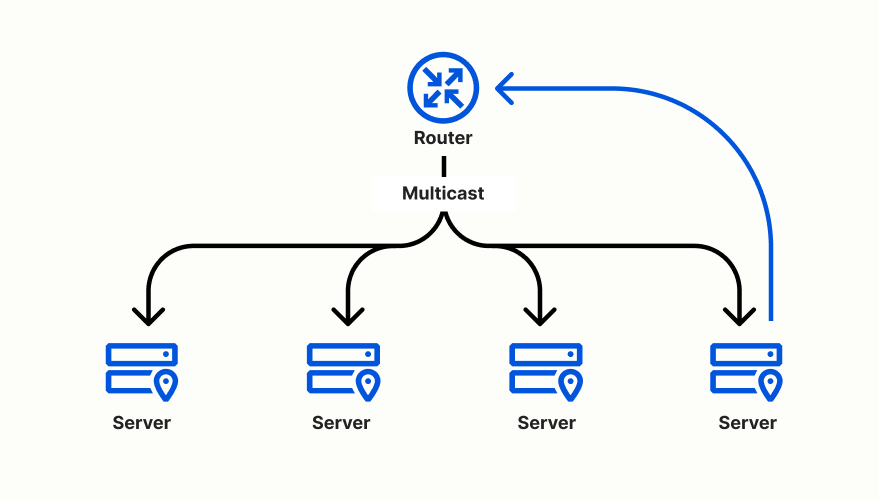
The servers in a Cloudflare edge data center are part of the same private network, so for “version 2” of our health check system, we had each server in a data center join a multicast group and share their health check results with one another. Each server still made an independent assessment for each tunnel, but that assessment was based on data collected by all servers in the same location.
This second version of tunnel health checks resulted in more consistent tunnel health determinations by servers in the same data center. It also resulted in faster response times—especially in large data centers where servers receive updates from their peers very rapidly.
However, we started seeing scaling problems. As we added more customers, we added more tunnel endpoints where we need to check the weather. In some of our larger data centers, each server was receiving close to half a billion messages per minute.
Imagine it’s not just you and me telling each other about the weather above us. You’re in a crowd of hundreds of people, and now everyone is shouting the weather updates for thousands of cities around the world!
One weather station to rule them all
As an engineering intern on the Magic Transit team, my project this summer has been developing a third approach. Rather than having every server infrequently check the weather for every tunnel and shouting the observation to everyone else, now every server tunnel can frequently check the weather for a few tunnels. With this new approach, servers would then only tell the others about the overall weather report—not every individual measurement.
That scenario sounds more efficient, but we need to distribute the task of sending tunnel health checks across all the servers in a location so one server doesn’t get an overwhelming amount of work. So how can we assign tunnels to servers in a way that doesn’t require a centralized orchestrator or shared database? Enter consistent hashing, the single coolest distributed computing concept I got to apply this summer.
Every server sends a multicast “heartbeat” every few seconds. Then, by listening for multicast heartbeats, each server can construct a list of the IP addresses of peers known to be alive, including its own address, sorted by taking the hash of each address. Every server in a data center has the same list of peers in the same order.
When a server needs to decide which tunnels it is responsible for sending health checks to, the server simply hashes each tunnel to an integer and searches through the list of peer addresses to find the peer with the smallest hash greater than the tunnel’s hash, wrapping around to the first peer if no peer is found. The server is responsible for sending health checks to the tunnel when the assigned peer’s address equals the server’s address.
If a server stops sending messages for a long enough period of time, the server gets removed from the known peers list. As a consequence, the next time another server tries to hash a tunnel the removed peer was previously assigned, the tunnel simply gets reassigned to the next peer in the list.
And like magic, we have devised a scheme to consistently assign tunnels to servers in a way that is resilient to server failures and does not require any extra coordination between servers beyond heartbeats. Now, the assigned server can send health checks way more frequently, compose more precise weather forecasts, and share those forecasts without being drowned out by the crowd.
Results
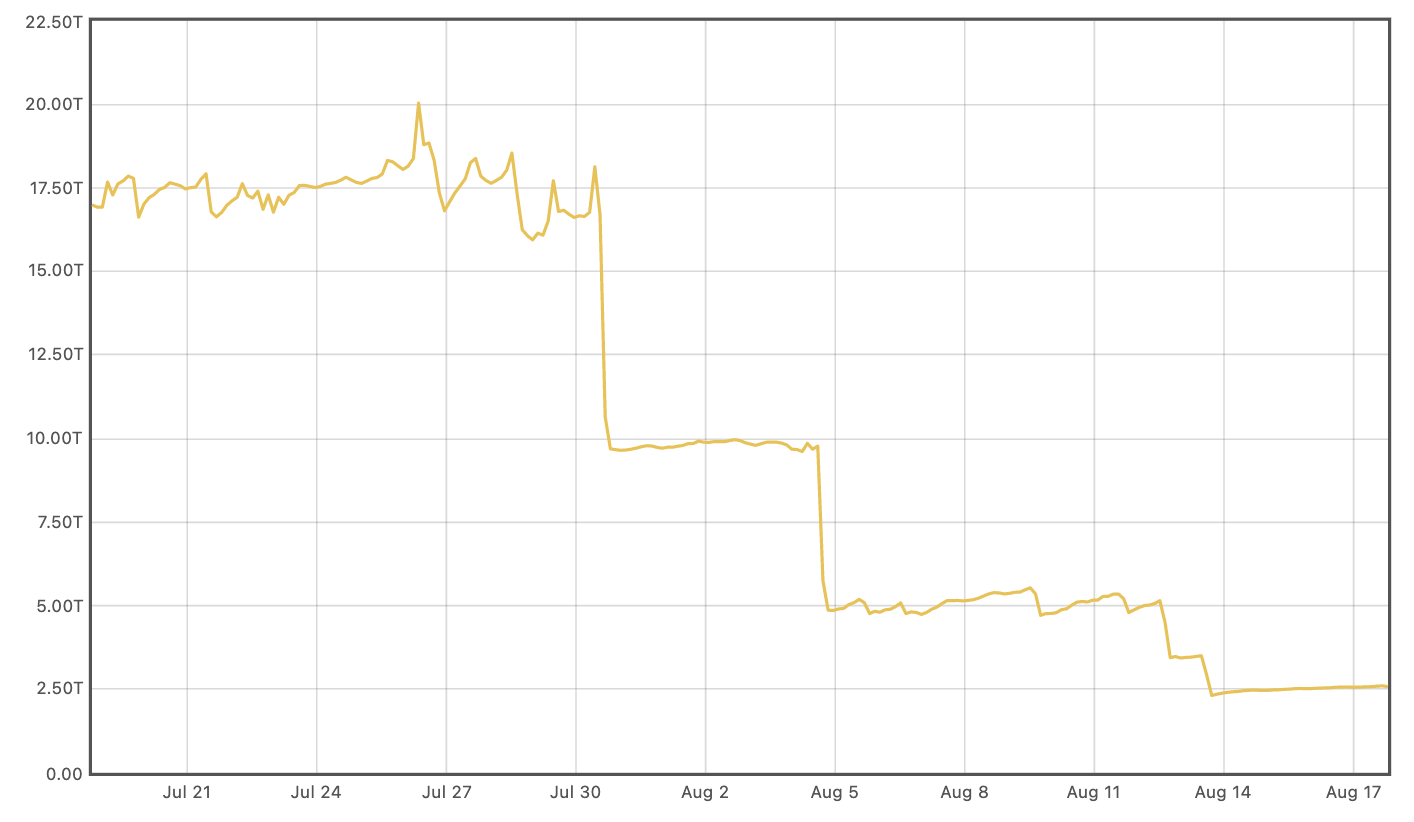
Releasing the new health check system globally reduced Magic Transit’s CPU usage by over 70% and memory usage by nearly 85%.
Memory usage (measured in terabytes):
CPU usage (measured in CPU-seconds per two minute interval, averaged over two days):

Reducing the number of multicast messages means that servers can now keep up with the Internet weather, even in the largest data centers. We’re now poised for the next stage of Magic Transit’s growth, just in time for our two-year anniversary.
If you want to help build the future of networking, join our team.