Post Syndicated from Manash Deb original https://aws.amazon.com/blogs/big-data/automate-building-an-integrated-analytics-solution-with-aws-analytics-automation-toolkit/
Amazon Redshift is a fast, fully managed, widely popular cloud data warehouse that powers the modern data architecture enabling fast and deep insights or machine learning (ML) predictions using SQL across your data warehouse, data lake, and operational databases. A key differentiating factor of Amazon Redshift is its native integration with other AWS services, which makes it easy to build complete, comprehensive, and enterprise-level analytics applications.
As analytics solutions have moved away from the one-size-fits-all model to choosing the right tool for the right function, architectures have become more optimized and performant while simultaneously becoming more complex. You can use Amazon Redshift for a variety of use cases, along with other AWS services for ingesting, transforming, and visualizing the data.
Manually deploying these services is time-consuming. It also runs the risk of making human errors and deviating from best practices.
In this post, we discuss how to automate the process of building an integrated analytics solution by using a simple script.
Solution overview
The framework described in this post uses Infrastructure as Code (IaC) to solve the challenges with manual deployments, by using AWS Cloud Development Kit (CDK) to automate provisioning AWS analytics services. You can indicate the services and resources you want to incorporate in your infrastructure by editing a simple JSON configuration file.
The script then instantly auto-provisions all the required infrastructure components in a dynamic manner, while simultaneously integrating them according to AWS recommended best practices.
In this post, we go into further detail on the specific steps to build this solution.
Prerequisites
Prior to deploying the AWS CDK stack, complete the following prerequisite steps:
- Verify that you’re deploying this solution in a Region that supports AWS CloudShell. For more information, see AWS CloudShell endpoints and quotas.
- Have an AWS Identity and Access Management (IAM) user with the following permissions:
AWSCloudShellFullAccessIAM Full AccessAWSCloudFormationFullAccessAmazonSSMFullAccessAmazonRedshiftFullAccessAmazonS3ReadOnlyAccessSecretsManagerReadWriteAmazonEC2FullAccess- Create a custom AWS Database Migration Service (AWS DMS) policy called
AmazonDMSRoleCustomwith the following permissions:
- Optionally, create a key pair that you have access to. This is only required if deploying the AWS Schema Conversion Tool (AWS SCT).
- Optionally, if using resources outside your AWS account, open firewalls and security groups to allow traffic from AWS. This is only applicable for AWS DMS and AWS SCT deployments.
Prepare the config file
To launch the target infrastructures, download the user-config-template.json file from the GitHub repo.
To prep the config file, start by entering one of the following values for each key in the top section: CREATE, N/A, or an existing resource ID to indicate whether you want to have the component provisioned on your behalf, skipped, or integrated using an existing resource in your account.
For each of the services with the CREATE value, you then edit the appropriate section under it with the specific parameters to use for that service. When you’re done customizing the form, save it as user-config.json.
You can see an example of the completed config file under user-config-sample.json in the GitHub repo, which illustrates a config file for the following architecture by newly provisioning all the services, including Amazon Virtual Private Cloud (Amazon VPC), Amazon Redshift, an Amazon Elastic Compute Cloud (Amazon EC2) instance with AWS SCT, and AWS DMS instance connecting an external source SQL Server on Amazon EC2 to the Amazon Redshift cluster.
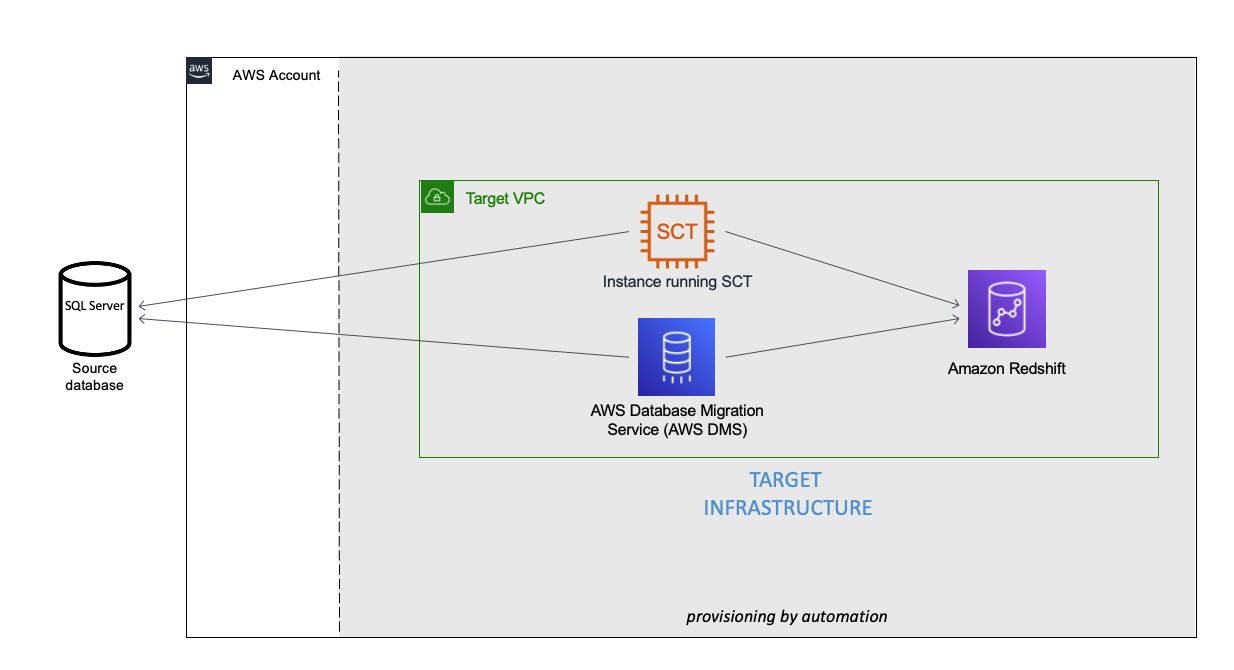
Launch the toolkit
This project uses CloudShell, a browser-based shell service, to programatically initiate the deployment through the AWS Management Console. Prior to opening CloudShell, you need to configure an IAM user, as described in the prerequisites.
- On the CloudShell console, clone the Git repository:
- Run the deployment script:
- On the Actions menu, choose Upload file and upload
user-config.json.

- Enter a name for the stack.
- Depending on the resources being deployed, you may have to provide additional information, such as the password for an existing database or Amazon Redshift cluster.
- Press Enter to initiate the deployment.

Monitor the deployment
After you run the script, you can monitor the deployment of resource stacks through the CloudShell terminal, or through the AWS CloudFormation console, as shown in the following screenshot.
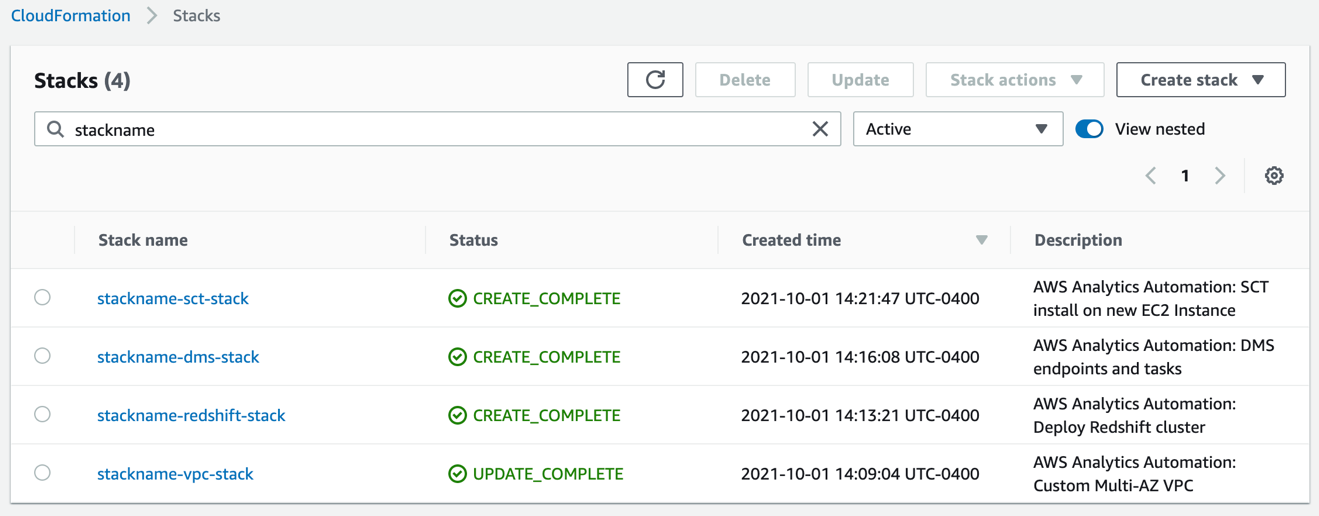
Each stack corresponds to the creation of a resource from the config file. You can see the newly created VPC, Amazon Redshift cluster, EC2 instance running AWS SCT, and AWS DMS instance. To test the success of the deployment, you can test the newly created AWS DMS endpoint connectivity to the source system and the target Amazon Redshift cluster. Select your endpoint and on the Actions menu, choose Test connection.

If both statuses say Success, the AWS DMS workflow is fully integrated.
Troubleshooting
If the stack launch stalls at any point, visit our GitHub repository for troubleshooting instructions.
Conclusion
In this post, we discussed how you can use the AWS Analytics Infrastructure Automation utility to quickly get started with Amazon Redshift and other AWS services. It helps you provision your entire solution on AWS instantly without any spending any time on challenges around integrating the services or scaling your solution.
About the Authors
 Manash Deb is a Software Development Engineer in the AWS Directory Service team. He has worked on building end-to-end applications in different database and technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems on AWS.
Manash Deb is a Software Development Engineer in the AWS Directory Service team. He has worked on building end-to-end applications in different database and technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems on AWS.
 Samir Kakli is an Analytics Specialist Solutions Architect at AWS. He has worked with building and tuning databases and data warehouse solutions for over 20 years. His focus is architecting end-to-end analytics solutions designed to meet the specific needs for each customer.
Samir Kakli is an Analytics Specialist Solutions Architect at AWS. He has worked with building and tuning databases and data warehouse solutions for over 20 years. His focus is architecting end-to-end analytics solutions designed to meet the specific needs for each customer.
 Julia Beck is a Specialist Solutions Architect at AWS. She supports customers building analytics proof of concept workloads. Outside of work, she enjoys traveling, cooking, and puzzles.
Julia Beck is a Specialist Solutions Architect at AWS. She supports customers building analytics proof of concept workloads. Outside of work, she enjoys traveling, cooking, and puzzles.