Post Syndicated from Grab Tech original https://engineering.grab.com/kafka-connect
Grab’s real-time data platform team a.k.a. Coban has written about Plumbing at scale, Optimally scaling Kakfa consumer applications, and Exposing Kafka via VPCE. In this article, we will cover the importance of being able to easily move data in and out of Kafka in a low-code way and how we achieved this with Kafka Connect.
To build a NoOps managed streaming platform in Grab, the Coban team has:
- Engineered an ecosystem on top of Apache Kafka.
- Successfully adopted it to production for both transactional and analytical use cases.
- Made it a battle-tested industrial-standard platform.
In 2021, the Coban team embarked on a new journey (Kafka Connect) that enables and empowers Grabbers to move data in and out of Apache Kafka seamlessly and conveniently.
Kafka Connect stack in Grab
This is what Coban’s Kafka Connect stack looks like today. Multiple data sources and data sinks, such as MySQL, S3 and Azure Data Explorer, have already been supported and productionised.
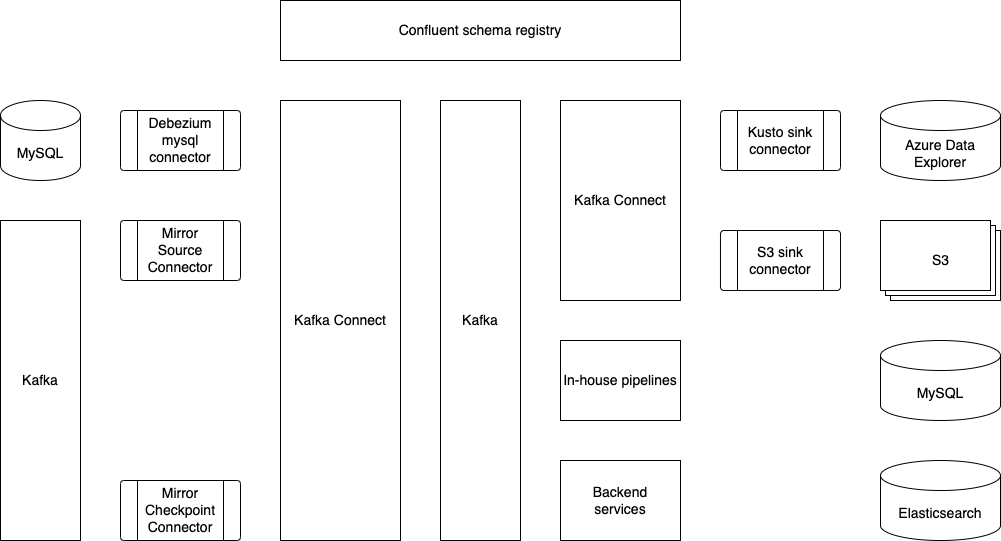
The Coban team has been using Protobuf as the serialisation-deserialisation (SerDes) format in Kafka. Therefore, the role of Confluent schema registry (shown at the top of the figure) is crucial to the Kafka Connect ecosystem, as it serves as the building block for conversions such as Protobuf-to-Avro, Protobuf-to-JSON and Protobuf-to-Parquet.
What problems are we trying to solve?
Problem 1: Change Data Capture (CDC)
In a big organisation like Grab, we handle large volumes of data and changes across many services on a daily basis, so it is important for these changes to be reflected in real time.
In addition, there are other technical challenges to be addressed:
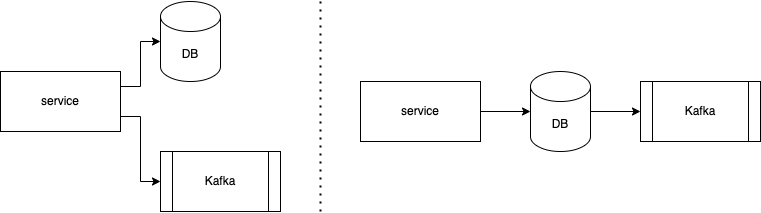
- As shown in the figure below, data is written twice in the code base – once into the database (DB) and once as a message into Kafka. In order for the data in the DB and Kafka to be consistent, the two writes have to be atomic in a two-phase commit protocol (or other atomic commitment protocols), which is non-trivial and impacts availability.
- Some use cases require data both before and after a change.
Problem 2: Message mirroring for disaster recovery
The Coban team has done some research on Kafka MirrorMaker, an open-source solution. While it can ensure better data consistency, it takes significant effort to adopt it onto existing Kubernetes infrastructure hosted by the Coban team and achieve high availability.
Another major challenge that the Coban team faces is offset mirroring and translation, which is a known challenge in Kafka communities. In order for Kafka consumers to seamlessly resume their work with a backup Kafka after a disaster, we need to cater for offset translation.
Data ingestion into Azure Event Hubs
Azure Event Hubs has a Kafka-compatible interface and natively supports JSON and Avro schema. The Coban team uses Protobuf as the SerDes framework, which is not supported by Azure Event Hubs. It means that conversions have to be done for message ingestion into Azure Event Hubs.
Solution
To tackle these problems, the Coban team has picked Kafka Connect because:
- It is an open-source framework with a relatively big community that we can consult if we run into issues.
- It has the ability to plug in transformations and custom conversion logic.
Let us see how Kafka Connect can be used to resolve the previously mentioned problems.
Kafka Connect with Debezium connectors
Debezium is a framework built for capturing data changes on top of Apache Kafka and the Kafka Connect framework. It provides a series of connectors for various databases, such as MySQL, MongoDB and Cassandra.
Here are the benefits of MySQL binlog streams:
- They not only provide changes on data, but also give snapshots of data before and after a specific change.
- Some producers no longer have to push a message to Kafka after writing a row to a MySQL database. With Debezium connectors, services can choose not to deal with Kafka and only handle MySQL data stores.
Architecture
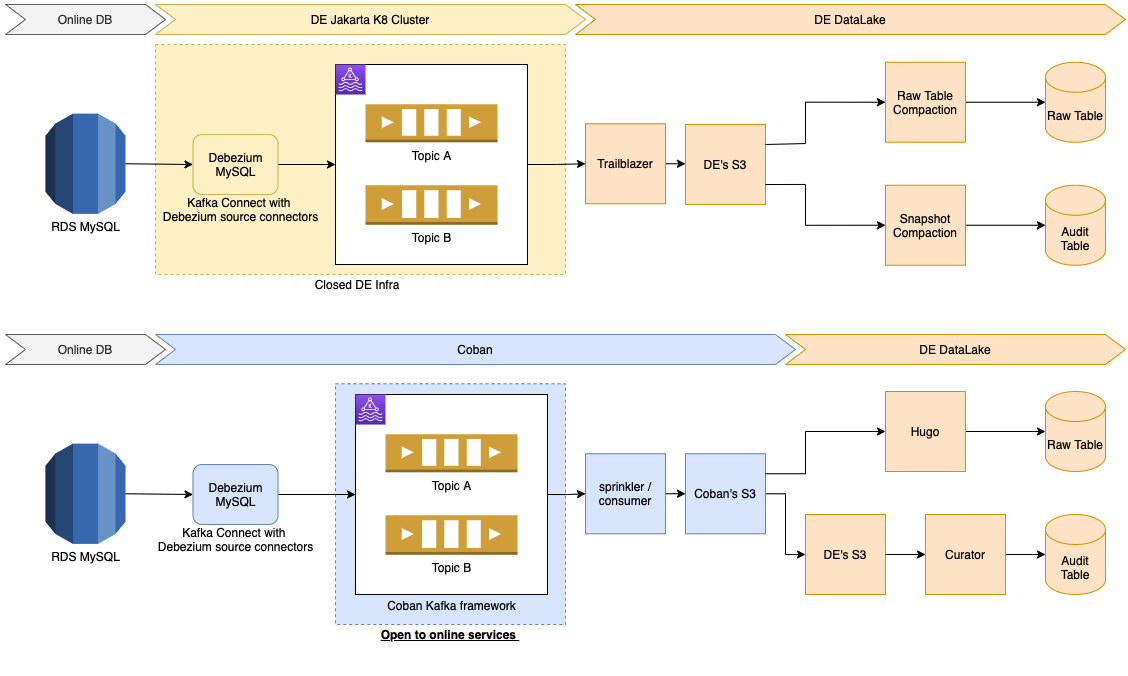
In case of DB upgrades and outages
DB Data Definition Language (DDL) changes, migrations, splits and outages are common in database operations, and each operation type has a systematic resolution.
The Debezium connector has built-in features to handle DDL changes made by DB migration tools, such as pt-online-schema-change, which is used by the Grab DB Ops team.
To deal with MySQL instance changes and database splits, the Coban team leverages on the Kafka Connect framework’s ability to change the offsets of connectors. By changing the offsets, Debezium connectors can properly function after DB migrations and resume binlog synchronisation from any position in any binlog file on a MySQL instance.
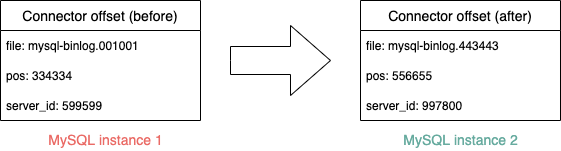
Refer to the Debezium documentation for more details.
Success stories
The CDC project on MySQL via Debezium connectors has been greatly successful in Grab. One of the biggest examples is its adoption in the Elasticsearch optimisation carried out by GrabFood, which has been published in another blog.
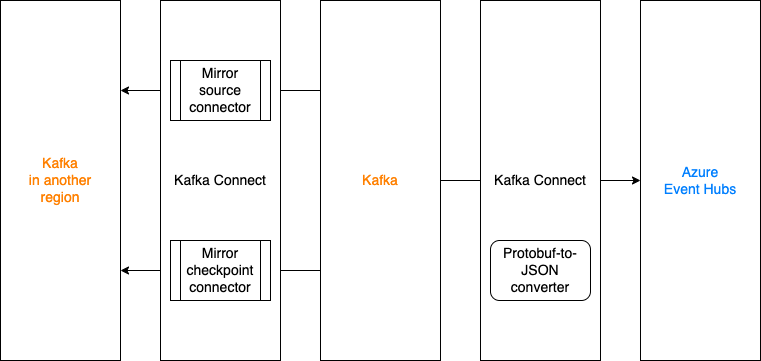
MirrorMaker2 with offset translation
Kafka MirrorMaker2 (MM2), developed in and shipped together with the Apache Kafka project, is a utility to mirror messages and consumer offsets. However, in the Coban team, the MM2 stack is deployed on the Kafka Connect framework per connector because:
- A few Kafka Connect clusters have already been provisioned.
- Compared to launching three connectors bundled in MM2, Coban can have finer controls on
MirrorSourceConnectorandMirrorCheckpointConnector, and manage both of them in an infrastructure-as-code way via Hashicorp Terraform.
Success stories
Ensuring business continuity is a key priority for Grab and this includes the ability to recover from incidents quickly. In 2021H2, there was a campaign that ran across many teams to examine the readiness and robustness of various services and middlewares. Coban’s Kafka is one of these services that proved to be robust after rounds of chaos engineering. With MM2 on Kafka Connect to mirror both messages and consumer offsets, critical services and pipelines could safely be replicated and launched across AWS regions if outages occur.
Because the Coban team has proven itself as the battle-tested Kafka service provider in Grab, other teams have also requested to migrate streams from self-managed Kafka clusters to ones managed by Coban. MM2 has been used in such migrations and brought zero downtime to the streams’ producers and consumers.
Mirror to Azure Event Hubs with an in-house converter
The Analytics team runs some real time ingestion and analytics projects on Azure. To support this cross-cloud use case, the Coban team has adopted MM2 for message mirroring to Azure Event Hubs.
Typically, Event Hubs only accept JSON and Avro bytes, which is incompatible with the existing SerDes framework. The Coban team has developed a custom converter that converts bytes serialised in Protobuf to JSON bytes at runtime.
These steps explain how the converter works:
- Deserialise bytes in Kafka to a Protobuf
DynamicMessageaccording to a schema retrieved from the Confluent™ schema registry. - Perform a recursive post-order depth-first-search on each field descriptor in the
DynamicMessage. - Convert every Protobuf field descriptor to a JSON node.
- Serialise the root JSON node to bytes.
The converter has not been open sourced yet.
Deployment

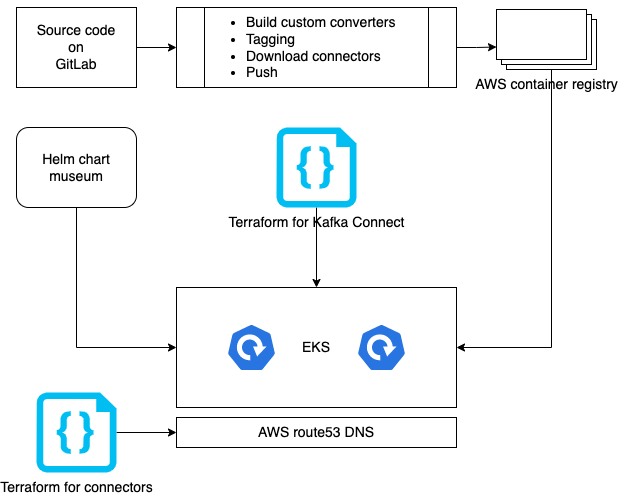
Docker containers are the Coban team’s preferred infrastructure, especially since some production Kafka clusters are already deployed on Kubernetes. The long-term goal is to provide Kafka in a software-as-a-service (SaaS) model, which is why Kubernetes was picked. The diagram below illustrates how Kafka Connect clusters are built and deployed.
What’s next?
The Coban team is iterating on a unified control plane to manage resources like Kafka topics, clusters and Kafka Connect. In the foreseeable future, internal users should be able to provision Kafka Connect connectors via RESTful APIs and a graphical user interface (GUI).
At the same time, the Coban team is closely working with the Data Engineering team to make Kafka Connect the preferred tool in Grab for moving data in and out of external storages (S3 and Apache Hudi).
Coban is hiring!
The Coban (Real-time Data Platform) team at Grab in Singapore is hiring software and site reliability engineers at all levels as we double down on growing our platform capabilities.
Join us in building state-of-the-art, mission critical, TB/hour scale data platforms that enable thousands of engineers, data scientists, and analysts to serve millions of consumers, businesses, and partners across Southeast Asia!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!