Post Syndicated from Backblaze original https://www.backblaze.com/blog/the-python-gil-past-present-and-future/

We reached out to Barry Warsaw, a preeminent Python developer and contributor, because we could think of no one better to break down the evolution of the GIL for us. Barry is a longtime Python core developer, former release manager and steering council member, and PSF Fellow. He was project lead for the GNU Mailman mailing list manager. Barry, along with contributor Paweł Polewicz, a backend software developer and longtime Python user, went above and beyond anything we could have imagined, developing this comprehensive deep dive into the GIL and its evolution over the years. Thanks also go to Larry Hastings for his review and feedback.
If Python’s GIL is something you are curious about, we’d love to hear your thoughts in the comments. We’ll let Barry take it from here.
—The Editors
First Things First: What Is the GIL?
The Python GIL, or Global Interpreter Lock, is a mechanism in CPython (the most common implementation of Python) that serves to serialize operations involving the Python bytecode interpreter, and provides useful safety guarantees for internal object and interpreter state. While providing many benefits, as the discussion below will show, the GIL also prevents CPython from achieving full multicore performance.
In simplest terms, the GIL is a lock (or mutex) that allows only a single operating system thread to run the central Python bytecode interpreter loop. Normally, when multiple threads can access shared state, such as global interpreter or object internal state, a programmer would need to implement fine grained locks to prevent one thread from stomping on the state set by another thread. The GIL removes the need for these fine grained locks because it imposes a global lock that prevents multiple threads from mutating this state at the same time.
In this post, I’ll explore the pros and cons of the GIL, and the many efforts over the years to remove it, including some recent exciting developments.
Humble Beginnings
Back in November 1994, I was invited to a little gathering of programming language enthusiasts to meet the Dutch inventor of a relatively new and little known object-oriented language. This three day workshop was organized by my friends and former colleagues at the National Institute of Standards and Technology (NIST) in Gaithersburg, MD. I came with extensive experience in languages from C, C++, FORTH, LISP, Perl, TCL, and Objective-C and enjoyed learning and playing with new programming languages.
Of course, the Dutch inventor was Guido van Rossum and his little language was Python. I think most of us in attendance knew there was something special about Python and Guido, but it probably would have shocked us to know that Python would even be around almost 30 years later, let alone have the scope, impact, or popularity it enjoys today. For me personally, it was a life-changing moment.
A few years ago, I gave a talk at BayPiggies that took a retrospective look at the evolution of Python from version 1.1 in October 1994 (just before the abovementioned workshop), through the Python 2 series, and up to Python 3.7, the newest release of the language at the time. In many ways, Python 1.1 would be recognizable by today’s modern Python programmer. In other ways, you’d wonder how Python was ever usable without features that were introduced in the intervening years.
Can you imagine not having the tuple() or list() built-ins, or docstrings, or class exceptions, keyword arguments, *args, **kws, packages, or even different operators for assignment and equality tests? It was fun to go back through all those old changelogs and remember what it was like as each of the features we now take for granted were introduced, often in those early days with absolutely no regard for backward compatibility.
I managed to find the agenda for that first Python workshop, and one of the items to be discussed was “Improving the efficiency of Python (e.g., by using a different garbage collection scheme).” I don’t remember any of the details of that discussion, but even then, and from its start, Python employed a reference counting memory management scheme (the cyclic garbage detector being many years away yet). Reference counting is a simple way of managing your objects in a higher level language where you don’t directly allocate or free your memory. One of Guido’s early guiding principles for Python, and which has served Python well over the years, is to keep it as simple as possible while still being effective, useful, and fun.
The Basics of Reference Counting
Reference counting is simple; as it says on the tin, the interpreter keeps a counter that tracks every reference to an object. For example, binding an object to a variable (such as by an assignment) increases that object’s reference count by one. Appending an object to a list also increases its reference count by one. Removing an object from the list decreases that object’s reference count by one. When a variable goes out of scope, the reference count of the object the variable is bound to is decreased by one again. We call this reference count the object’s “refcount” and these two operations “incref” and “decref” respectively.
When an object’s refcount goes to zero it means there are no more live references to the object, so it can be safely freed (and finalized) because nothing in the program can reach that object anymore1. As these objects are deallocated, any references to objects they hold are also decref’d, and so on. Refcounting gives the Python interpreter a very simple mechanism for freeing garbage and more importantly, it allows for humans to reason about Python’s memory management, both from the point of view of the Python programmer, and from the vantage point of the C extension writer, who doesn’t have the luxury of all that reference counting happening automatically.
This is a crucial point: When we talk about “Python” we generally mean “CPython,” the implementation of the runtime written in C2. The C programmer working on the CPython runtime, and the module author writing extensions for Python in C (for performance or to integrate with some system library) does have to worry about all the nitty gritty details of when to incref or decref an object. Get this wrong and your extension can leak memory or double free an object, either way wreaking havoc on your system. Fortunately, Python has clear rules to follow and good documentation, but it can still be difficult to get refcounting right in complex situations, such as when proper error handling leads to multiple exit paths from a function.
Here’s Where the GIL Comes In: Reference Counting and Concurrency
One of the key simplifying rules is that the programmer doesn’t have to worry about concurrency when managing Python reference counting. Think about the situation where you have multiple threads, each inserting and removing a Python object from a collection such as a list or dictionary. Because those threads may run at any time and in any order, you would normally have to be extremely defensive in how you incref and decref those objects, and it would be way too easy to get this wrong. You could crash Python, or worse, if you didn’t implement the proper locks around your incref and decref operations. Having to worry about all that would make your C code very complicated and likely pretty error prone. The CPython implementation also has global and static variables which are vulnerable to race conditions3.
In keeping with Python’s principles, in 1992, when Guido first began to implement threading support in Python, he utilized a simple mechanism to keep this manageable for a wide range of Python programmers and extension authors: a Global Interpreter Lock—the infamous GIL!
Because the Python interpreter itself is not thread-safe, the GIL allows only one thread to execute Python bytecode at a time, and thus serializes all access to Python objects. So, barring bugs, it is impossible for multiple threads to stomp on each other’s reference count operations. There are C API functions to release and acquire the GIL around blocking I/O or compute intensive functions that don’t touch Python objects, and these provide boundaries for the interpreter to switch to other Python-executing threads.
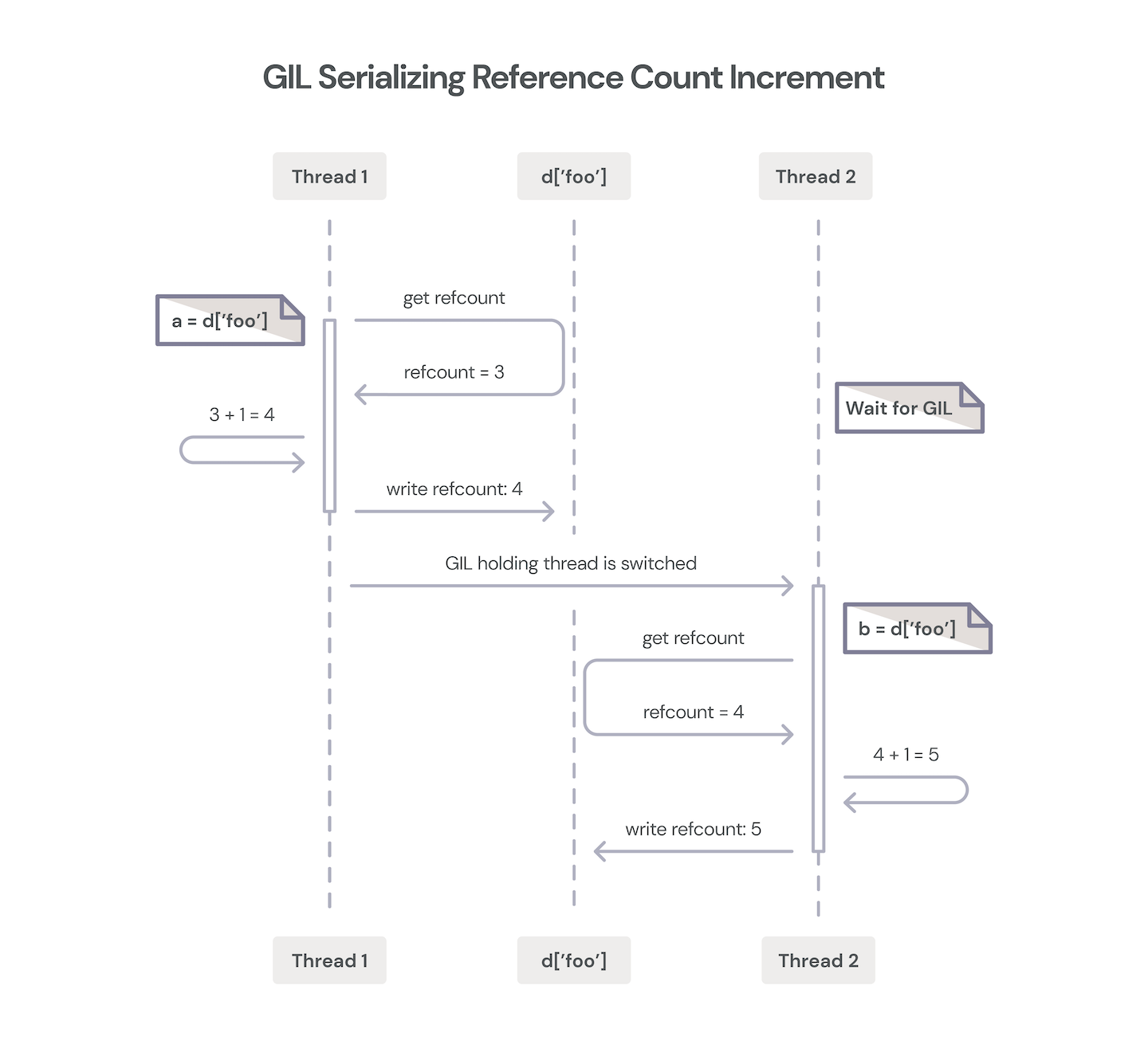
Thus, we gain significant C implementation simplicity at the expense of some parallelism. Modern Python has many ways to work around this limitation, from asyncio to subprocesses and multiprocessing, which all work fine if they align with your requirements. Python also surfaces operating system threading primitives, but these can’t take full advantage of multicore operations because of the GIL.
Advantages of the GIL
Back in the early days of Python, we didn’t have the prevalence of multicore processors, so this all worked fine. These days, modern programming languages are more multicore friendly, and the GIL gets a bad rap. Before we explore the work to remove the GIL, it’s important to understand just how much benefit and mileage Python has gotten out of it.
One important aspect of the GIL is that it simplifies the programming model for extension module authors. When writing extension modules in C, C++, or any other low-level language with access to the internals of the Python interpreter, extension authors would normally have to ensure that there are no race conditions that could corrupt the internal state of Python objects. Concurrency is hard to get right, especially so in low-level languages, and one mistake can corrupt the entire state of the interpreter4. For an extension author, it can already be challenging to ensure all your increfs and decrefs are properly balanced, especially for any branches, early exits, or error conditions, and this would be monumentally more difficult if the author also had to contend with concurrent execution. The GIL provides an important simplifying model of object access (including refcount manipulation) because it ensures that only one thread of execution can mutate Python objects at a time5.
There are important performance benefits of the GIL for single-threaded operations as well. Without the GIL, Python would need some other way of ensuring that object refcounts are safe from corruption due to, for example, race conditions between threads, such as when adding or removing objects from any mutable collection (lists, dictionaries, sets) that are shared across threads. These techniques can be very expensive as some of the experiments described later showed. Ensuring that Python interpreter is safe for multithreaded use cases degrades its performance for the single-threaded use case. The GIL’s low performance overhead really shines for single-threaded operations, including I/O-multiplexed programs where libraries like asyncio are used, and this is still a predominant use of Python. Finer-grained locks also increase the chances of deadlocks, which isn’t possible with the GIL.
Also, one of the reasons Python is so popular today is that it had so many extensions written for it over the years. One of the reasons there are so many powerful extension modules, whether we like to admit it or not, is that the GIL makes those extensions easier to write.
And yet, Python programmers have long dreamed of being able to run multithreaded Python programs to take full advantage of all the cores available on modern computing platforms. Even today’s watches and phones have multiple cores, whereas in Python’s early days, multicore systems were rare. Here we are 30 or so years later, and while the GIL has served Python well, in order to take advantage of what clearly seems to be more than a passing fad, Python’s GIL often gets in the way of true high-performance multithreaded concurrency.
Attempting to Remove the GIL
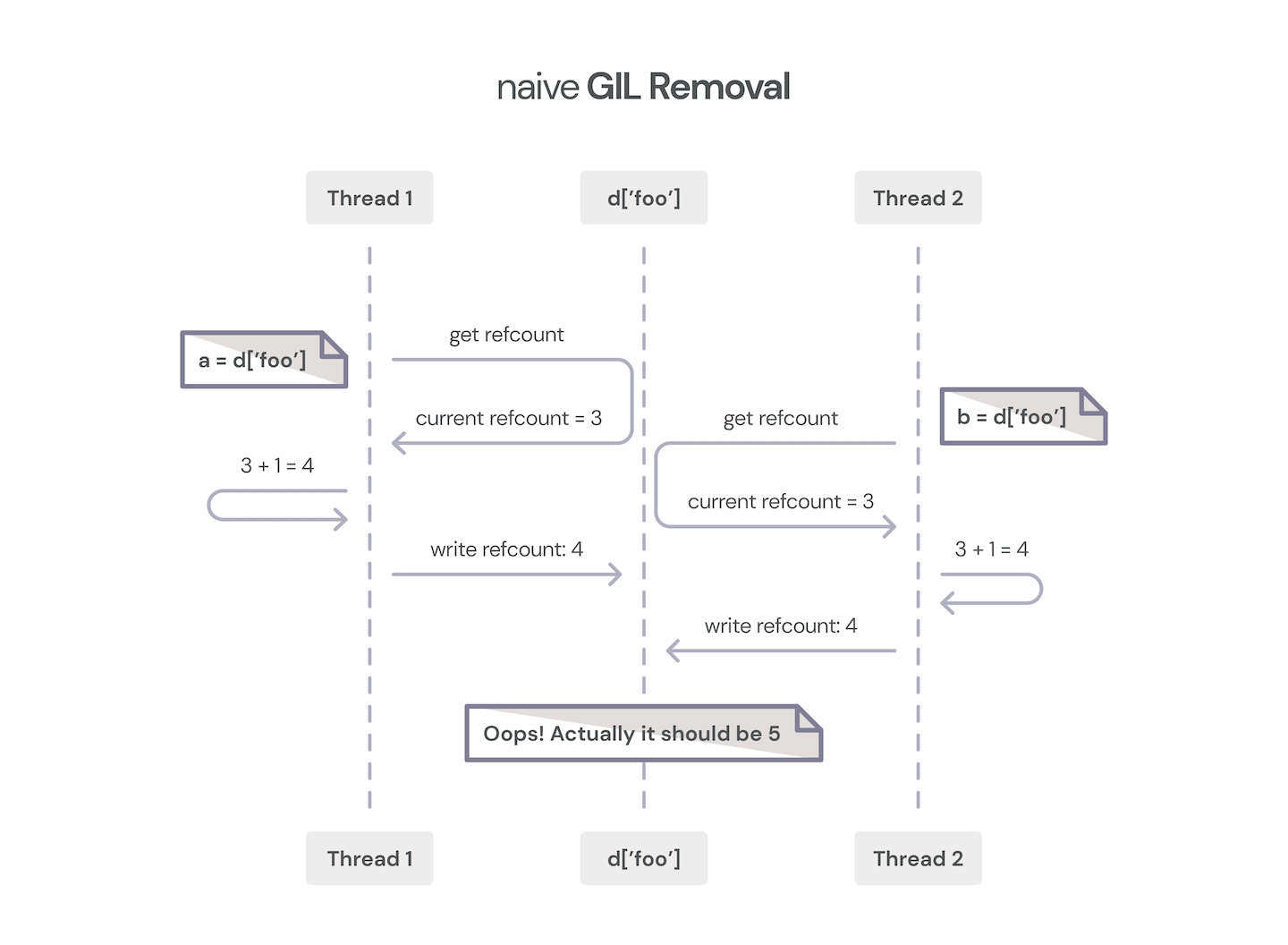
Over the years, many attempts have been made to remove the GIL.
1999: Greg Stein’s “Free Threading”
Circa 1999, Greg Stein’s “free threading” work was one of the first (successful!) attempts to remove the GIL. It made the locks much more fine-grained and moved global variables inside the interpreter into a structure, which we actually still use today. It had the unfortunate side effect however, of making your Python code multiple times slower. Thus, while the free threading work was a great experiment, it was far too impractical to adopt.
2015: Larry Hasting’s Gilectomy
Years later (circa 2015), Larry Hasting’s wonderfully named Gilectomy project tried a different approach to remove the GIL. In Larry’s PyCon 2016 talk, he discusses four technical considerations that must be addressed when removing the GIL:
- Reference Counting: Race conditions on updating the refcount between multiple threads as described previously.
- Globals and Statics: These include interpreter global housekeeping variables, and shared singleton objects. Much work has been done over the years to move these globals into per-thread structures. Eric Snow’s work on multiple interpreters (aka “subinterpreters”) has also made a lot of progress on isolating these variables into structures that represent an interpreter “instance” where theoretically each instance could run on a separate core. There are even proposals for making some of those shared singleton objects immortal, such that reference counting race conditions would have no effect on the lifetime of those objects. An interesting related proposal would move the GIL into a per-interpreter data structure, which could lead to the ability to run an isolated interpreter instance per core (with limitations).
- C Extensions: Keep in mind that there is a huge ecosystem of C extension modules, and much of Python’s power comes from these extension modules, of which NumPy is a hugely popular example. These extensions have never had to worry about parallelism or re-entrancy because they’ve always relied on the GIL to serialize their operations. At a minimum, a GIL-less Python will require recompilation of extension modules, and some or all may require some level of source code modifications as well. These changes may include protecting internal (non-Python) data structures for concurrency, using functional APIs for refcount modification instead of accessing refcount fields directly, not assuming that Python collections are stable over iteration, etc.
- Atomicity: Operations such as adding or deleting objects from Python collections such as lists and dictionaries actually involve a number of steps internally. To the Python developer, these all appear to be atomic operations, and in fact they are, thanks to the GIL.
Larry also identifies what he calls three “political” considerations, but which I think are more in the realm of the social contract between Python developers and Python users:
- Removing the GIL should not hurt performance for single-threaded or I/O-bound multithreaded code.
- We can’t break existing C extensions as described above6.
- Don’t let GIL removal make the CPython interpreter too complicated or difficult to understand. One of Guido’s guiding principles, and a subtle reason for Python’s huge success, is that even with complicated features such as exception handling, asyncio, generators, etc. Python’s C core is still relatively easy to learn and understand. This makes it easy for new contributors to engage with Python core development, an absolutely essential quality if you want your language to thrive and grow for its next 30 years as much as it has for its previous 30.
Larry’s Gilectomy work is quite impressive, and I highly recommend watching any of his PyCon talks for deep technical dives, served with a healthy dose of humor. As Larry points out, removing the GIL isn’t actually the hard part. The hard part is doing so while adhering to the above mentioned technical and social constraints, retaining Python’s single-threaded performance, and building a mechanism that scales with the number of cores. This latter constraint is important because if we’re going to enable multicore operations, we want to ensure that Python’s performance doesn’t hit a plateau at four or eight cores.
So, why did the Gilectomy branch fail (measured in units of “didn’t get adopted by CPython”)? For the most part, the performance and complexity constraints couldn’t be met. One of the biggest hits on performance wasn’t actually lock contention on objects. The early Gilectomy work relied on atomic increment and decrement CPU instructions, which destroyed cache consistency, and caused a high overhead of communication on the intercore bus to ensure atomicity.
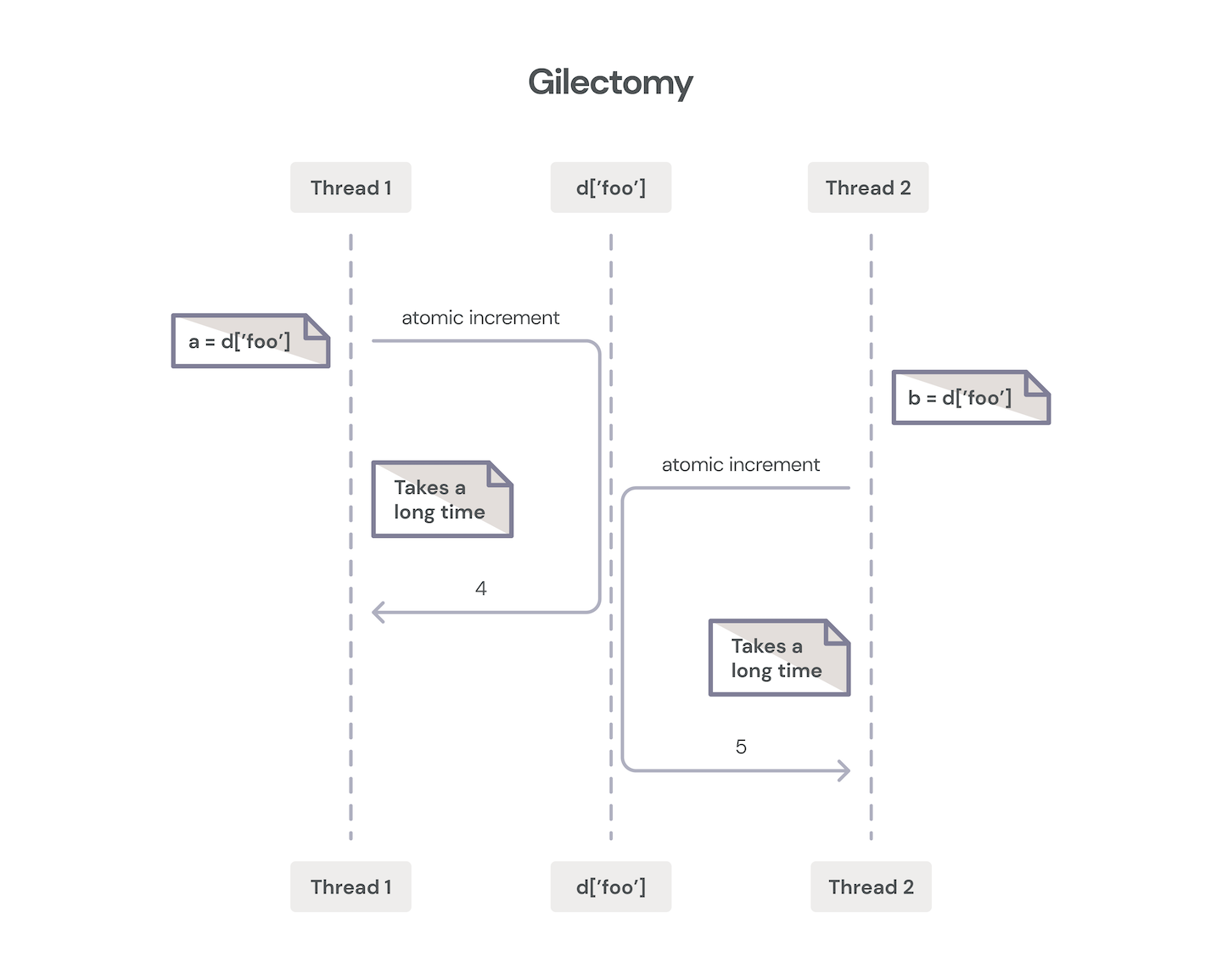
Later, Larry experimented with a technique borrowed from garbage collection research called “buffered reference counting,” essentially a transaction log for refcount changes. However, contention on transaction logs required further modifications to segregate logs by threads and by increment and decrement operations. This led to non-realtime garbage collection events on refcounts reaching zero, which broke features such as Python’s weakref objects.
Interestingly, another hotspot turned out to be what’s called “obmalloc,” which is a small block allocator that improves performance over just using system malloc for everything. We’ll touch on this again later. Solving all these knock-on effects (such as repairing the cyclic garbage collector) led to increased complexity of the implementation, making the chance that it would ever get merged into Python highly unlikely.
Before we leave this topic to look at some new and exciting work, let’s return briefly to Eric Snow’s work on multiple interpreters (aka subinterpreters). PEP 554 proposes to add a new standard library module called “interpreters” which would expose the underlying work that Eric has been doing to isolate interpreter state out of global variables internal to CPython. One such global state is, of course, the GIL. With or without Python-level access to these features, if the GIL could be moved from global state to per-interpreter state, each interpreter instance could theoretically run concurrently with the others. You could therefore attach a different interpreter instance to each thread, and these could run Python code in parallel. This is definitely a work in progress and it’s unclear whether multiple interpreters will deliver on its promises of this kind of limited concurrency. I say “limited” because without full GIL removal, there is significant complexity in sharing Python objects between interpreters, which would almost certainly be necessary. Issues such as ownership (which thread owns which object) and safe mutability would need to be resolved. PEP 554 proposes some solutions to these problems and more, so we’ll have to keep an eye on this work. But even multiple interpreters don’t provide the same true concurrency that full GIL removal promises.
The Future of the GIL: Where Do We Go From Here?
And now we come full-circle, because Python’s popularity, vast influence, and reach is also one of the reasons why it still seems impossible to remove the GIL while retaining single-threaded performance and not breaking the entire ecosystem of extension modules.
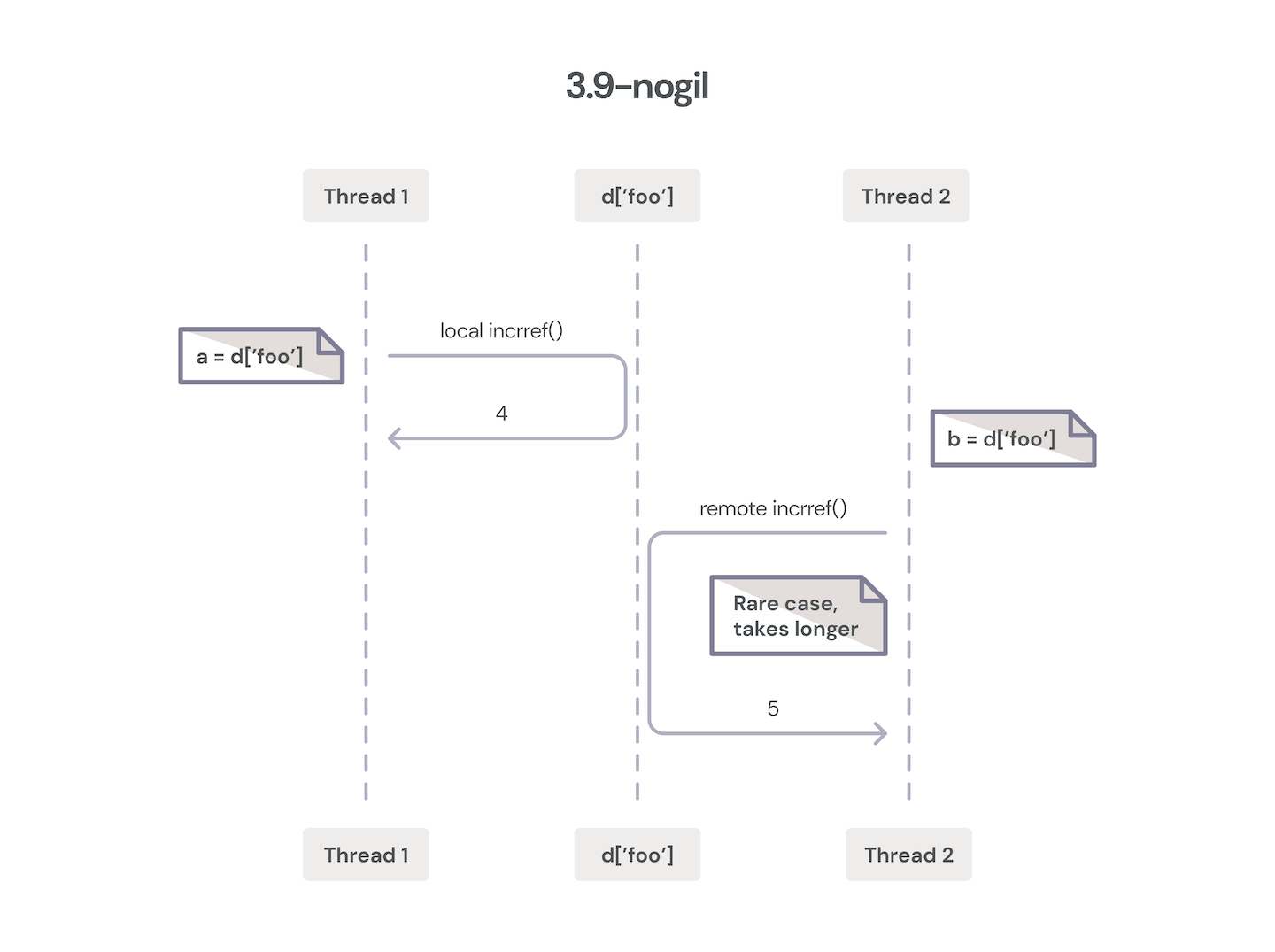
Yet here we are with PyCon 2022 just concluded, and there is renewed excitement for Sam Gross’ “nogil” work, which holds the promise of a performant, GIL-less CPython with minimal backward incompatibilities at both the Python and C layers. While some performance regressions are inevitable, Sam’s work also utilizes a number of clever techniques to claw these regressions back through other internal performance improvements.
With these improvements as well as the work that Guido’s team at Microsoft is doing with its Faster CPython project, there is renewed hope and excitement that the GIL can be removed while retaining or even improving overall performance, and not giving up on backward compatibility. It will clearly be a multi-year effort.
Sam’s nogil project aims to support a concurrency sweet spot. It promises that data race conditions will never corrupt Python’s virtual machine, but it leaves the integrity of user-level data structures to the programmer. Concurrency is hard, and many Python programs and libraries benefit from the implicit GIL constraints, but solving this is a harder problem outside the scope of the nogil project. Data science applications are one big potential domain to benefit from true multiprocessor enabled concurrency in Python.
There are a number of techniques that the nogil project utilizes to remove the GIL bottleneck. As mentioned, the project also employs a number of other virtual machine improvements to regain some of the performance inevitably lost by removing the GIL. I won’t go into too much detail about these improvements, but it’s helpful to note that where these are independent of nogil, they can and are being investigated along with other work Guido’s team is doing to improve the overall performance of CPython.
Python 3.11 recently entered beta (and thus feature freeze), and with it we’ll see significant performance improvements, which no doubt will continue in future Python releases. When and if nogil is adopted, some of those performance gains may regress to support nogil. Whether and how this will be a good trade-off will be an interesting point of analysis and debate in the coming years. In Sam’s original paper, he proposes a runtime switch to choose between nogil and normal GIL operation, however this was discussed at the PyCon 2022 Language Summit, and the consensus was that this wouldn’t be practical. Thus, as the nogil experiment moves forward, it will be enabled by a compile-time switch.
At a high level, the removal of the GIL is afforded by changes in three areas: the memory allocator, reference counting, and concurrent collection protections. Each of these are deep topics on their own, so we’ll only be able to touch on them briefly.
nogil Part 1: Memory Allocators
Because everything in Python is an object, and most objects are dynamically allocated on the heap, the CPython interpreter implements several levels of memory allocators, and provides C API functions for allocating and freeing memory. This allows it to efficiently allocate blocks of raw memory from the operating system, and to subdivide and manage those blocks based on the type of objects being placed into them. For example, integers have different memory requirements than dictionaries, so having object-specific memory managers for these (and other) types of objects makes memory management inside the interpreter much more efficient.
CPython also employs a small object allocator, called pymalloc, which improves performance for allocating and freeing objects smaller than or equal to 512 bytes. This only touches on the complexities of memory management inside the interpreter. The point of all this complexity is to enable more efficient object creation and destruction, but it also allows for features like memory allocation debugging and custom memory allocators.
The nogil works takes advantage of this pluggability to utilize a general purpose, highly efficient, thread-safe memory allocator developed by Daan Leijen at Microsoft called mimalloc. mimalloc itself is worthy of an in-depth look, but for our purposes it’s enough to know that the mimalloc design is extremely well tuned to efficient and thread-safe allocation of memory blocks. The nogil project utilizes these structures for the implementation of dictionaries and other collection types which minimize the need for locks on non-mutating access, as well as managing garbage collected objects7 with minimal bookkeeping. mimalloc has also been highly tuned for performance and thread-safety.
nogil Part 2: Reference Counting
nogil also makes several changes to reference counting, although it does so in a clever way that minimizes changes to the Limited C API, but does not preserve the stable ABI. This means that while extension modules must be recompiled, their source code may not require modification, outside of a few known corner cases8.
One very promising idea is to make some objects effectively immortal, which I touched on earlier. True, False, None and some other objects in practice never actually see their refcounts go to zero, and so they stay alive for the entire lifetime of the Python process. By utilizing the least significant bits of the object’s reference count field for bookkeeping, nogil can make the refcounting macros no-op for these objects, thus avoiding all contention across threads for these fields.
nogil uses a form of biased reference counting to split an object’s refcount into two buckets. For refcount changes in the thread that owns the object, these “local” changes can be made by the more efficient conventional (non-atomic) forms. For changing the refcount of objects in a different thread, an atomic operation is necessary for safe concurrent modification of a “shared” refcount. The thread that owns the object can then combine this local and shared refcount for garbage collection purposes, and it can give up ownership when its local refcount goes to zero. This is performant when most object accesses are local to the owning thread, which is generally the case. nogil’s biased reference counting scheme can utilize mimalloc’s memory pools to efficiently keep track of the owning threads.
However, some objects are typically owned by multiple threads and are not immortal, and for these types of objects (e.g., functions, modules), a deferred reference counting scheme is employed. Incref and decref act as normal for these objects, but when the interpreter loads these objects onto its internal stack, the refcounts are not modified. The utility of this technique is limited to objects that are only deallocated during garbage collection because they are typically involved in reference cycles.
The garbage collector is also modified to ensure that it only runs at safe boundary points, such as a bytecode execution boundary. The current nogil implementation of garbage collection is single-threaded and stops the world, so it is thread-safe. It repurposes some of the existing C API functions to ensure that it doesn’t wait on threads that are blocked on I/O.
nogil Part 3: Concurrent Collection Protections
The third high-level technique that nogil uses to enable concurrency is to implement an efficient algorithm for locking container objects, such as dictionaries and lists, when mutating them. To maintain thread-safety, there’s just no way around employing locks for this. However, nogil optimizes for objects that are primarily modified in a single thread, and it admits that objects which are frequently and concurrently modified may need a different design.
Sam’s nogil paper goes into considerable detail about the locking algorithm, but at a high level it relies on container versioning (where every modification to a container bumps a “version” counter so the various read accesses can know whether the container has been modified between distinct reads or not), biased reference counting, and various mimalloc features to optimize for fast track, single-threaded, no modification reads while amortizing the cost of locking for writes against the other expensive operations a typical container write operation imposes.
The Last Word and Some Predictions
Sam Gross’ nogil project is impressive. He’s managed to satisfy most of the difficult constraints that have thwarted previous attempts at removing the GIL, including minimizing as much as possible the impact on single-threaded performance (and trading general interpreter performance improvements for the cost of removing the GIL), maintaining (mostly) Python’s C API backward compatibility to not force changes on the entire extension module ecosystem, and all the while (Despite the length of this article!) preserving the readability and comprehensibility of the CPython interpreter.
You’ve no doubt noticed that the rabbit hole goes pretty deep, and we’ve only explored some of the tunnels in this particular burrow. Fortunately, Python’s semantics and CPython’s implementation has been well documented over its 30 year life, so there are plenty of opportunities for self-exploration…and contributions! It will take sustained engagement through careful and incremental steps to bring these ideas to fruition. The future certainly is exciting.
If I had to guess, I would say that we’ll see features like multiple interpreters provide some concurrency value in the next release or so, with GIL removal five years (and thus five releases) or more away. However many of the techniques described here are already being experimented with and may show up earlier. Python 3.11 will have many noticeable performance improvements, with plenty of room for additional performance work in future releases. These will give the nogil work room to continue its experimentation at true multicore performance.
For a language and interpreter that has gone from a small group of lucky and prescient enthusiasts to a worldwide top-tier programming language, I think there is more excitement and optimism for Python’s future than ever. And that’s not even talking about game changers such as PyScript.
Barry Warsaw
Barry has been a Python core developer since 1994 and is listed as the first non-Dutch contributor to Python. He worked with Python’s inventor, Guido van Rossum, at CNRI when Guido, and Python development, moved from the Netherlands to the USA. He has been a Python release manager and steering council member, created and named the Python Enhancement (PEP) process, and is involved in Python development to this day. He was the project leader for GNU Mailman, and for a while maintained Jython, the implementation of Python built on the JVM. He is currently a senior staff engineer at LinkedIn, a semiprofessional bass player, and tai chi enthusiast. All opinions and commentary expressed in this article are his own.
Get in touch with Barry:
Paweł Polewicz
Pawel has been a backend developer since 2002. He built the largest e-radio station on the planet in 2006-2007, worked as a QA manager for six years, and finally, started Reef Technologies, a software house highly specialized in building Python backends for startups.
Get in touch with Paweł:
Notes
- Reference cycles are not only possible but surprisingly common, and these can keep graphs of unreachable objects alive indefinitely. Python 2.0 added a generational cyclic garbage collector to handle these cases. The details are tricky and worthy of an article in its own right.
- CPython is also called the “reference implementation” because new features show up there first, even though they are defined for the generic “Python language.” It’s also the most popular implementation, and typically what people think of when they say “Python.”
- Much work has been done over the years to reduce these as much as possible.
- It’s even worse than this implies. Debugging concurrency problems is notoriously difficult because the conditions that lead to the bug are nearly impossible to reproduce, and few tools exist to help.
- Instrumenting concurrent code to try to capture the behavior can introduce subtle timing differences that hide the problem. The industry has even coined the term, “Heisenbug,” to describe the complexity of this class of bug.
- Some extension modules also use the GIL as a conveniently available mutex to protect concurrent access to their own, non-Python resources.
- It doesn’t seem possible to completely satisfy this constraint in any attempt to remove the GIL.
- I.e., the aforementioned cyclic reference garbage collector.
- Such as when the extension module peeks and pokes inside CPython data structures directly or via various macros, instead of using the C API’s functional interfaces.
The post The Python GIL: Past, Present, and Future appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.