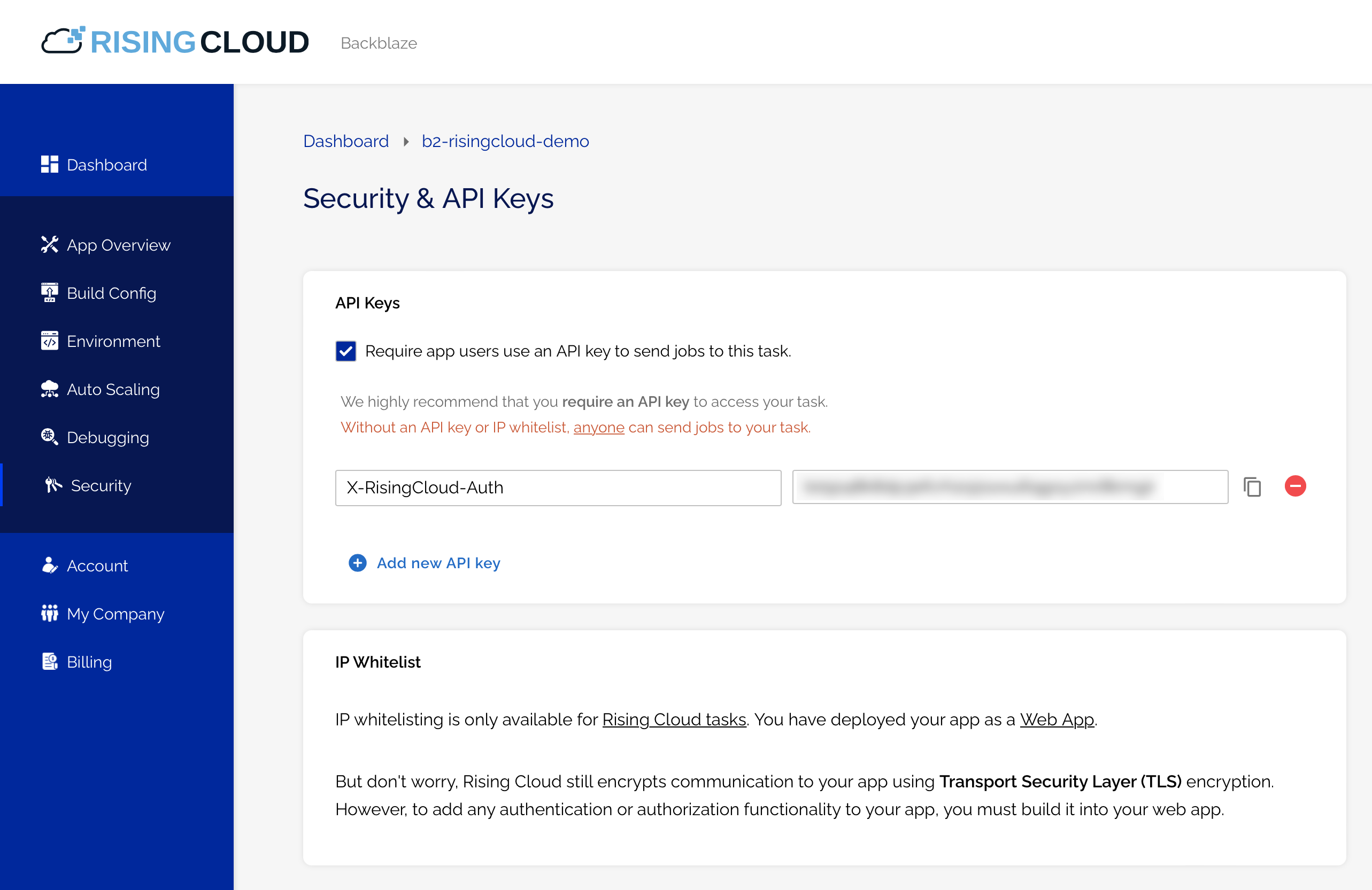
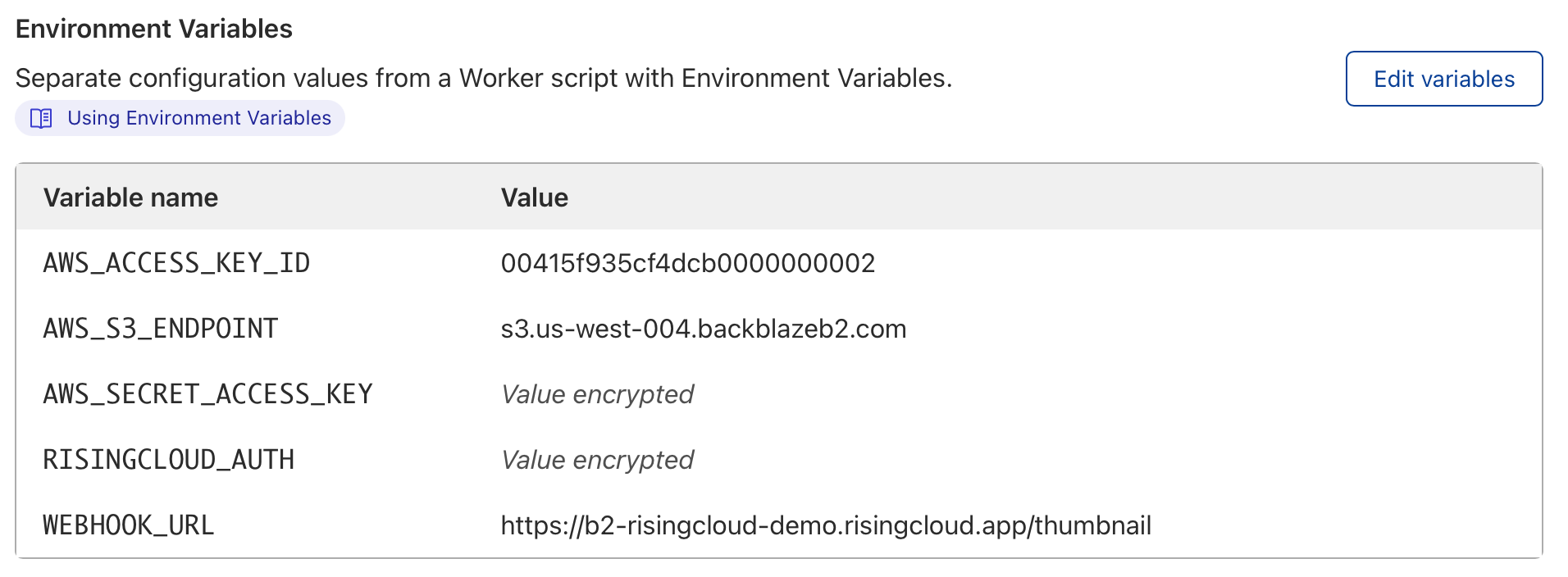
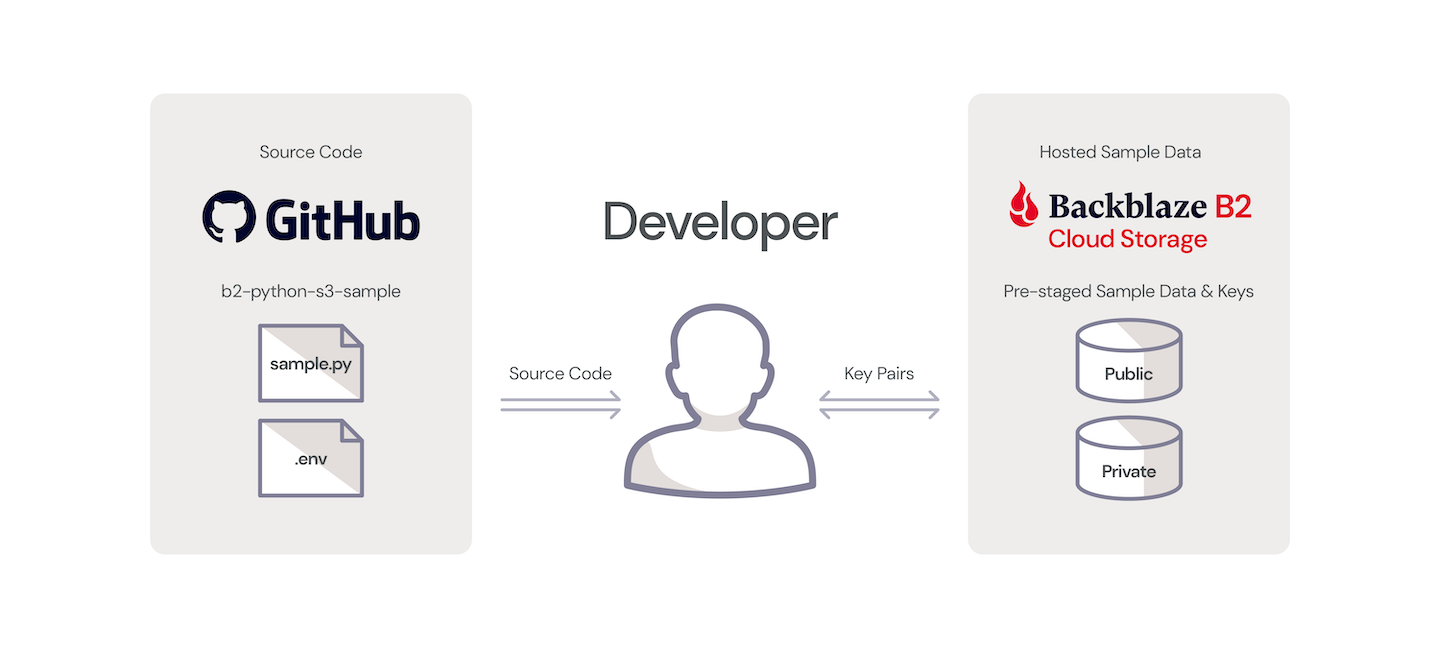
It’s almost a guarantee that no data analyst, data manager, CIO, or CEO for that matter, ever uttered the words, “I wish we did less with our data.” You always want to do more—squeeze more value out of it, learn more from it, and make it work harder for you.
Aparavi helps customers do just that. The cloud-based platform is designed to unlock the value of data, no matter where it lives. Backblaze’s new partnership with Aparavi offers joint customers simple, scalable cloud storage services for unstructured data management. Read on to learn more about the partnership.
What Is Aparavi?
Aparavi is a cloud-based data intelligence and automation platform that helps customers identify, classify, optimize, and move unstructured data no matter where it resides. The platform finds, automates, governs, and consolidates distributed data easily using deep intelligence. It ensures secure access for modern data demands of analytics, machine learning, and collaboration, connecting business and IT to transform data into a competitive asset.
How Does Backblaze Integrate With Aparavi?
The Aparavi Data Intelligence and Automation Platform and Backblaze B2 Cloud Storage together provide data lifecycle management and universal data migration services. Joint customers can choose Backblaze B2 as a destination for their unstructured data.
“We are very excited about our partnership with Backblaze. This partnership will combine Aparavi’s automated and continuous data movement with Backblaze B2’s simple, scalable cloud storage services to help companies know and visualize their data, including the impact of risk, cost, and value they may or may not be aware of today.”
—Adrian Knapp, CEO and Founder, Aparavi
How Does This Partnership Benefit Joint Customers?
The partnership delivers in three key value areas:
It facilitates redundant, obsolete, trivial—commonly referred to as ROT—data cleanup, helping to reduce on-premises operational costs, redundancies, and complexities.
It recognizes personally identifiable information to deliver deeper insights into organizational data.
It enables data lifecycle management and automation to low-cost, secure, and highly available Backblaze B2 Cloud Storage.
“Backblaze helps organizations optimize their infrastructure in B2 Cloud Storage by eliminating their biggest barrier to choosing a new provider: excessive costs and complexity. By partnering with Aparavi, we can take that to the next level for our joint customers, providing cost-effective data management, storage, and access.”
—Nilay Patel, Vice President of Sales and Partnerships, Backblaze
Getting Started With Backblaze B2 and Aparavi
Ready to do more with your data affordably? Contact our Sales team today to get started.
When you’re responsible for protecting your company’s data from ransomware, you don’t need to be convinced of the risks an attack poses. Staying up to date on the latest ransomware trends is probably high on your radar. But sometimes it’s not as easy to convince others in your organization to take the necessary precautions. Protecting your data from ransomware might require operational changes and investments, and that can be hard to advance, especially when headlines report that dire predictions haven’t come true.
To help you stay up to date and inform others in your organization of the latest threats and what you can do about them, we put together five quick, timely, shareable takeaways from our monitoring over Q2 2022.
This post is a part of our ongoing series on ransomware. Take a look at our other posts for more information on how businesses can defend themselves against a ransomware attack, and more.
Things have been somewhat quieter on the ransomware front, and many security experts point out that the sanctions against Russia have made it harder for cybercriminals to ply their trade. The sanctions make it harder to receive payments, move money around, and provision infrastructure. As such, The Wall Street Journal reported that the ransomware economy in Russia is changing. Groups are reorganizing, splintering off into smaller gangs, and changing up the software they use to avoid detection.
Key Takeaway: Cybercriminals are working harder to avoid revealing their identities, making it challenging for victims to know whether they’re dealing with a sanctioned entity or not. Especially at a time when the federal government is cracking down on companies that violate sanctions, the best fix is to put an ironclad sanctions compliance program in place before you’re asked about it.
2. AI-powered Ransomware Is Coming
The idea of AI-powered ransomware is not new, but we’ve seen predictions in Q2 that it’s closer to reality than we might think. To date, the AI advantage in the ransomware wars has fallen squarely on the defense. Security firms employ top talent to automate ransomware detection and prevention.
Meanwhile, ransomware profits have escalated in recent years. Chainalysis, a firm that analyzes crypto payments, reported ransomware payments in excess of $692 million in 2020 and $602 million in 2021 (which they expect to continue to go up with further analysis), up from just $152 million in 2019. With business booming, some security experts warn that, while cybercrime syndicates haven’t been able to afford developer talent to build AI capabilities yet, that might not be the case for long.
They predict that, in the coming 12 to 24 months, ransomware groups could start employing AI capabilities to get more efficient in their ability to target a broader swath of companies and even individuals—small game for cybercriminals at the moment but not with the power of machine learning and automation on hand.
Key Takeaway: Small to medium-sized enterprises can take simple steps now to prevent future “spray and pray” style attacks. It may seem too easy, but fundamental steps like staying up to date on security patches and implementing multi-factor authentication can make a big difference in keeping your company safe.
3. Conti Ransomware Group Still In Business
In Q1, we reported that the ransomware group Conti suffered a data leak after pledging allegiance to Russia in the wake of the Ukraine invasion. Despite the leak, business seems to be trucking along over at Conti HQ. Despite suffering a leak of its own sensitive data, Conti doesn’t seem to have learned a lesson. The group continues threatening to publish stolen data in return for encryption keys—a hallmark of the group’s tactics.
Key Takeaway: As detailed in ZDnet, Conti tends to exploit unpatched vulnerabilities, so, again, staying up to date on security patches is advised, as is ramping up monitoring of your networks for suspicious activity.
4. Two-thirds of Victims Paid Ransoms Last Year
New analyses that came out in Q2 from CyberEdge group, covering the span of 2021 overall, found that two-thirds of ransomware victims paid ransoms in 2021. The firm surveyed 1,200 IT security professionals, and found three reasons why firms choose to make the payments:
Concerns about exfiltrated data getting out.
Increased confidence they’ll be able to recover their data.
Decreasing cost of recoveries.
When recoveries are easier, more firms are opting just to pay the attackers to go away, avoid downtime, and recover from some mix of backups and unencrypted data.
Key Takeaway: While we certainly don’t advocate for paying ransoms, having a robust disaster recovery plan in place can help you survive an attack and even avoid paying the ransom altogether.
5. Hacktivism Is on the Rise
With as much doom and gloom as we cover in the ransomware space, it seems hacking for a good cause is on the rise. CloudSEK, an AI firm, profiled the hacking group GoodWill’s efforts to force…well, some goodwill. Instead of astronomical payments in return for decryption keys, GoodWill simply asks that victims do some good in the world. One request: “Take any five less fortunate children to Pizza Hut or KFC for a treat, take pictures and videos, and post them on social media.”
Key Takeaway: While the hacktivists seem to have good intentions at heart, is it truly goodwill if it’s coerced with your company’s data held hostage? If you’ve been paying attention, you have a strong disaster recovery plan in place, and you can restore from backups in any situation. Then, consider their efforts a good reminder to revisit your corporate social responsibility program as well.
The Bottom Line: What This Means for You
Ransomware gangs are always changing tactics, and even more so in the wake of stricter sanctions. That, combined with the potential emergence of AI-powered ransomware means a wider range of businesses could be targets in the coming months and years. As noted above, applying good security practices and developing a disaster recovery plan are excellent steps towards becoming more resilient as tactics change. And the good news, at least for now, is that not all hackers are forces for evil even if some of their tactics to spread goodwill are a bit brutish.
In business, data loss is unavoidable unless you have good server backups. Files get deleted accidentally, servers crash, computers fail, and employees make mistakes.
However, those aren’t the only dangers. You could also lose your company data in a natural disaster or cybersecurity attack. Ransomware is a serious concern for small to medium-sized businesses as well as large enterprises. Smart companies plan ahead to avoid data loss.
This post will discuss server backup basics, the different types of server backup, why it’s critical to keep your data backed up, and how to create a solid backup strategy for your company. Read on to learn everything you ever wanted to know about server backups.
Check out the other posts in our Server Backup 101 series:
A server is a virtual or physical device that performs a function to support other computers and users. Sometimes servers are dedicated machines used for a single purpose, and sometimes they serve multiple functions. Other computers or devices that connect to the server are called “clients.” Typically, clients use special software to communicate with the server and reply to requests. This communication is referred to as the server/client model. Some common uses for this setup include:
Web Server: Hosts web pages and online applications.
Email Server: Manages email for a company.
Database Server: Hosts various databases and controls access.
Application Server: Allows users to share applications.
File Server: Used to host files shared on a network.
DNS Server: Used to decode web addresses and deliver the user to the correct address.
FTP Server: Used specifically for hosting files for shared use.
Proxy Server: Adds a layer of security between client and server.
Servers run on many operating systems (OS) such as Windows, Linux, Mac, Apache, Unix, NetWare, and FreeBSD. The OS handles access control, user connections, memory allocation, and network functions. Each OS offers varying degrees of control, security, flexibility, and scalability.
Why It’s Important to Back Up Your Server
Did you know that roughly 40% of small and medium-sized businesses (SMBs) will be attacked by cybercriminals within a year, and 61% of all SMBs have already been attacked? Additionally, statistics show that 93% of companies that lost data for more than 10 days were forced into bankruptcy within a year. More than half of them filed immediately, and most shut down.
Company data is vulnerable to fire, theft, natural disasters, hardware failure, and cybercrime. Backups are an essential prevention tool.
Types of Servers
Within the realm of servers, there are many different types for virtually any purpose and environment. However, the primary function of most servers is data storage and processing. Some examples of servers include:
Physical Servers: These are hardware devices (usually computers) that connect users, share resources, and control access.
Virtual Servers: Using special software (called a hypervisor), you can set up multiple virtual servers on one physical machine. Each server acts like a physical server while the hypervisor manages memory and allocates other system resources as needed.
Hybrid Servers: Hybrids are servers combining physical servers and virtual servers. They offer the speed and efficiency of a physical server combined with the flexibility of cloud-hosted resources.
NAS Devices: Network-attached storage (NAS) devices store data and are accessed directly through the network without first connecting to a computer. These hardware devices contain a storage drive, processor, and OS, and can be accessed remotely.
SAN Server: Although not technically a server, a storage area network (SAN) connects multiple storage devices to multiple servers expanding the network and controlling connections.
Cloud Servers: Cloud servers exist in a virtual online environment, and you can access them through web portals, applications, and specialized software.
Regardless of how you save your data and where, backups are essential to protecting yourself from loss.
How to Back Up a Server
You have options for backing up data, and the methods vary. First, let’s talk about terminology.
Backup vs. Archive
Backing up is copying your data, whereas an archive is a historical copy that you keep for retention purposes, often for long periods. Archives are typically used to save old, inactive data for compliance reasons.
Here are two examples that illustrate backups vs. an archives. An example of a backup is when your mobile phone backs up to the cloud, and if you factory reset the phone, you can restore all your applications, settings, and data from the backup copy. An example of an archive is a tape backup of old HR files that have long since been deleted from the server.
Backup vs. Sync
Sometimes people confuse the word backup with sync. They are not the same thing. A backup is a copy of your data you can use to restore lost files. Syncing is the automatic updating and merging of two file sources. Cloud computing often uses syncing to keep files in one location identical to files in another.
To prevent data loss, backups are the process to use. Syncing overwrites files with the latest version; a backup can restore back to a single point in time, so you don’t lose anything valuable.
Backup Destinations
When selecting a backup destination, you have many mediums to choose from. There are pros and cons for each type. Some popular backup destinations and their pros and cons are as follows:
Destination
Pros
Cons
External Media (USB, CD, Removable Hard Drives, Flash Drives, etc.)
Quick, easy, affordable.
Fragile if dropped, crushed, or exposed to magnets; very small capacity.
NAS
Always available on the network, small size, and great for SMBs.
Vulnerable to on-premises threats and non-scalable due to limits.
Network or SAN Storage
High speed, view connected drives as local, good security, failover protection, excellent disk utilization, and high-end disaster recovery options.
Can be expensive, doesn’t work with all types of servers, and is vulnerable to attacks on the network.
Tape
Dependable (robust, not fragile), can be kept for years, low cost, and simple to replicate.
High initial setup costs, limited scalability, potential media corruption over time, and time consuming to manage.
FTP
Excellent for large files, copy multiple files at once, can resume if the connection is lost, schedule backups and recover lost data.
No security, vendors vary widely, not all solutions include encryption, and vulnerable to attacks.
Cloud backups are an altogether different type of backup; typically, you have two options available: all-in-one tools or integrated solutions.
All-in-one Tools
All-in-one tools like Carbonite Safe, Carbonite Server, Acronis, IDrive, CrashPlan, and SpiderOak combine both the backup software and the backend cloud storage in one offering. They have the ability to back up entire operating systems, files, images, videos, and sometimes even mobile device data. Depending on the tool you choose, you may be able to back up an unlimited number of devices, or you may have limits. However, most of these all-in-one solutions are expensive and can be complex to use. All those bells and whistles often come at a price—a steep learning curve.
Integrated Solutions (Backup Software Paired With Cloud Storage)
Pairing software and cloud storage is another option that combines the best of both worlds. It allows users to choose the software they want with the features they need and fast, reliable cloud storage. Cloud storage is scalable, so you will never run out of space as your business grows. Using your chosen software, it’s fast and easy to restore your files. Although it may seem counterintuitive, it’s often more affordable to use two integrated solutions versus an all-in-one tool. Another big bonus of using cloud storage is that it integrates with many popular software options. For example, Backblaze works seamlessly with:
An important factor to consider when choosing the right backup software and cloud storage is compatibility. Research which platforms your software will back up and what types of backups it offers (file, image, system, etc.). You also need to think about the restore process and your options (e.g., file, folder, bare metal/image, virtual, etc.). User-friendliness is important when deciding. Some programs like rClone require a working knowledge of command line. Choose a software program that is best for you.
Think about scalability and how much storage it can handle now and in the future as your business grows. A few other things to consider are pricing, security, and support. Your backup files are no good if they are vulnerable to attack. Compare prices and check out the support options before making your final decision.
Creating a Solid Backup Strategy
A solid backup strategy is the best way to protect your company against data loss. Again, you have options. The 3-2-1 strategy is the gold standard, but some companies are choosing options like a 3-2-1-1-0 option or even a 4-3-2 scheme. Learn more about how each plan works.
Before determining your strategy, you must consider what data you need to back up. For example, will you be backing up just servers or also workstations and dedicated servers, such as email servers or SaaS data devices?
Another concern is how you will get your data into the cloud. You need to figure out which method will work best for you. You have the option of direct transfer over internet bandwidth or using a rapid ingest device (e.g., the Backblaze Fireball rapid ingest device).
Universal Data Migration
Migrating your data can seem like an insurmountable task. We launched our Universal Data Migration service to make migrating to Backblaze just as easy as it is to use Backblaze. You can migrate from virtually any source to Backblaze B2 Cloud Storage, and it’s free to new customers who have 10TB of data or more to migrate with a one-year commitment.
How Often Should You Back Up Your Data?
Should you run full backups regularly? Or rely on incremental backups? The answer is that both have their place.
To fully protect yourself, performing regular full backups and keeping them safe is essential. Full backups can be scheduled for slow times or performed overnight when no one is using the data. Remember that full backups take the longest to complete and are the costliest but the easiest to restore.
A full backup backs up the entire server. An incremental backup only backs up files that have changed or been added since the last backup, saving storage space. The cadence of full versus incremental backups might look different for each organization. Learn more about full vs. incremental, differential, and full synthetic backups.
How Long Should You Keep Your Previous Backups?
You also must consider how long you want to keep your previous backups. Will you keep them for a specific amount of time and overwrite older backups?
By overwriting the files, you can save space, but you may not have an old enough backup when you need it. Also, keep in mind that many cloud storage vendors have minimum retention policies for deleted files. While “retention” sounds like a good thing, in this case it’s not. They might be charging you for data storage for 30, 60, or even 90 days even if you deleted it after storing it for just one day. That may also factor into your decision about how long you should keep your previous backup files. Some experts recommend three months, but that may not be enough in some situations.
You need to keep full backups for as long as you might need to recover from various issues. If, for example, you are infiltrated by a cybercriminal and don’t discover it for two months, will your oldest backup be enough to restore your system back to a clean state?
Another question to think about is if you’ll keep an archive. As a refresher, an archive is a backup of historical data that you keep long-term even if the files have already been deleted from the server. Most sources say you should plan to keep archives forever unless you have no use for the data in the future, but your company might have a different appetite for retention timeframes. Forever probably seems like…well, a long time, but keep in mind that the security of having those files available may be worth it.
How Will You Monitor Your Backup?
It’s not enough to just schedule your backups and walk away. You need to monitor them to ensure they are occurring on schedule. You should also test your ability to restore and fully understand the options you have for restoring your data. A backup is only as good as its ability to restore. You must test this out periodically to ensure you have a solid disaster recovery plan in place.
Special Considerations for Backing Up
When backing up servers with different operating systems, you need to consider the constraints of that system. For example, SQL servers can handle differential backups, whereas other servers cannot. Some backup software like Veeam integrates easily with all the major operating systems and therefore supports backups of multiple servers using different platforms.
If you are backing up a single server, things are easy. You have only one OS to worry about. However, if you are backing up multiple servers with different platforms and applications running on them, things could get more complex. Be sure to research all your options and use a vendor that can easily handle groups management and SaaS-managed backup services so that you can view all your data through a single pane of glass. You want consolidation and easy delineation if you need to pinpoint a single system to restore. You can use groups to easily manage different servers with similar operating systems to keep things organized and streamline your backup strategy.
As you can see, there are many facets to server backups, and you have options. If you have questions or want to learn more about Backblaze backup solutions, contact us today. Or, click here if you’re ready to get started backing up your server.
Between tech layoffs and recession fears, economic uncertainty is at a high. If you’re battening down the hatches for whatever comes next, you might be taking a closer look at your cloud spend. Even before the bear market, 59% of cloud decision makers named “optimizing existing use of cloud (cost savings)” as their top cloud initiative of 2022 according to the Flexera State of the Cloud report.
Cloud storage is one piece of your cloud infrastructure puzzle, but it’s one where some simple considerations can save you anywhere from 25% up to 80%. As such, understanding cloud storage pricing is critical when you are comparing different solutions. When you understand pricing, you can better decide which provider is right for your organization.
In this post, we won’t look at 1:1 comparisons of cloud storage pricing, but you can check out a price calculator here. Instead, you will learn tips to help you make a good cloud storage decision for your organization.
Evaluating Your Cloud Storage? Gather These Facts
Looking at the pricing options of different cloud providers only makes sense when you know your needs. Use the following considerations to clarify your storage needs to approach a cloud decision thoughtfully:
How do you plan to use cloud storage?
How much does cloud storage cost?
What features are offered?
1. How Do You Plan to Use Cloud Storage?
Some popular use cases for cloud storage include:
Backup and archive.
Origin storage.
Migrating away from LTO/tape.
Managing a media workflow.
Backup and Archive
Maintaining data backups helps make your company more resilient. You can more easily recover from a disaster and keep serving customers. The cloud provides a reliable, off-site place to keep backups of your company workstations, servers, NAS devices, and Kubernetes environments.
Case Study: Famed Photographer Stores a Lifetime of Work
Photographer Steve McCurry, renowned for his 1984 photo of the “Afghan Girl” which has been on the cover of National Geographic several times, backed up his life’s work in the cloud when his team didn’t want to take chances with his irreplaceable archives.
Origin Storage
If you run a website, video streaming service, or online gaming community, you can use the cloud to serve as your origin store where you keep content to be served out to your users.
Case Study: Serving 1M+ Websites From Cloud Storage
Big Cartel hosts more than one million e-commerce websites. To increase resilience, the company recently started using a second cloud provider. By adopting a multi-cloud infrastructure, the business now has lower costs and less risk of failure.
Migrating Away From LTO/Tape
Managing a tape library can be time-consuming and comes with high CapEx spending. With inflation, replacing tapes costs more, shipping tapes off-site costs more, and physical storage space costs more. The cloud provides an affordable alternative to storing data on tape where you pass the decreased margins off to a cloud provider—they have to worry about provisioning enough physical storage devices and space while you pay as you go.
Managing Media Workflow
Your department or organization may need to work with large media files to create movies or digital videos. Cloud storage provides an alternative to provisioning huge on-premises servers to handle large files.
Case Study: Using the Cloud to Store Media
Hagerty Insurance stored a huge library of video assets on an aging server that couldn’t keep up. They implemented a hybrid cloud solution for cloud backup and sync, saving the team over 200 hours per year searching for files and waiting for their slow server to respond.
2. How Much Does Cloud Storage Cost?
Cloud storage costs are calculated in a variety of different ways. Before considering any specific vendors, knowing the most common options, variables, and fees is helpful, including:
Flat or single-tier pricing vs. tiered pricing.
Hot vs. cold storage.
Storage location.
Minimum retention periods.
Egress fees.
Flat or Single-tier Pricing vs. Tiered Pricing
A flat or single-tier pricing approach charges the user based on the storage volume, and cost is typically expressed per gigabyte stored. There is only one tier, making budgeting and planning for cloud expenses simple.
On the other hand, some cloud storage services use a tiered storage pricing model. For example, a provider may have a small business pricing tier and an enterprise tier. Note that different pricing tiers may include different services and features. Today, your business might use an entry-level pricing tier but need to move to a higher-priced tier as you produce more data.
Hot vs. Cold Storage
Hot storage is helpful for data that needs to be accessible immediately (e.g., last month’s customer records). By contrast, cold storage is helpful for data that does not need to be accessed quickly (e.g., tax records from five years ago). For more insight on hot vs. cold storage, check out our post: “What’s the Diff: Hot and Cold Data Storage.” Generally speaking, cold storage is the cheapest, but that low price comes at the cost of speed. For data that needs to be accessed frequently or even for data where you’re not sure how often you need access, hot storage is better.
Storage Location
Some organizations need their cloud storage to be located in the same country or region due to regulations or just preference. But some storage vendors charge different prices to store data in different regions. Keeping data in a specific location may impact cloud storage prices.
Minimum Retention Periods
Most folks think of “retention” as a good thing, but some storage vendors enforce minimum retention periods that essentially impose penalties for deleting your data. Some vendors enforce minimum retention periods of 30, 60, or even 90 days. Deleting your data could cost you a lot, especially if you have a backup approach where you retire older backups before the retention period ends.
Egress Fees
Cloud companies charge egress fees when customers want to move their data out of the provider’s platform. These fees can be egregiously high, making it expensive for customers to use multi-cloud infrastructures and therefore locking customers into their services.
3. What Additional Features Are Offered?
While price is likely one of your biggest considerations, choosing a cloud storage provider solely based on price can lead to disappointment. There are specific cloud storage features that can make a big difference in your productivity, security, and convenience. Keep these features and capabilities in mind when comparing different cloud storage solutions.
Security Features
You may be placing highly sensitive data like financial records and customer service data in the cloud, so features like server-side encryption could be important. In addition, you might look for a provider that offers Object Lock so you can protect data using a Write Once, Read Many (WORM) model.
Data Speed
Find out how quickly the cloud storage provider can provide data regarding upload and download speed. Keep in mind that the speed of your internet connection also impacts how fast you can access data. Data speed is critically important in several industries, including media and live streaming.
Customer Support
If your company has a data storage problem outside of regular business hours, customer support becomes critically important. What level of support can you expect from the provider? Do they offer expanded support tiers?
Partner Integrations
Partner integrations make it easier to manage your data. Check if the cloud storage provider has integrations with services you already use.
The Next Step in Choosing Cloud Storage
Understanding cloud storage pricing requires a holistic view. First, you need to understand your organization’s data needs. Second, it is wise to understand the typical cloud storage pricing models commonly used in the industry. Finally, cloud storage pricing needs to be understood in the context of features like security, integrations, and customer service. Once you consider these steps, you can approach a decision to switch cloud providers or optimize your cloud spend more rigorously and methodically.
As an IT leader or business owner, establishing a solid, working backup strategy is one of the most important tasks on your plate. Server backups are an essential part of a good security and disaster recovery stance. One decision you’re faced with as part of setting up that strategy is where and how you’ll store server backups: on-premises, in the cloud, or in some mix of the two.
As the cloud has become more secure, affordable, and accessible, more organizations are using a hybrid cloud strategy for their cloud computing needs, and server backups are particularly well suited to this strategy. It allows you to maintain existing on-premises infrastructure while taking advantage of the scalability, affordability, and geographic separation offered by the cloud.
If you’re confused about how to set up a hybrid cloud strategy for backups, you’re not alone. There are as many ways to approach it as there are companies backing up to the cloud. Today, we’re discussing different server backup approaches to help you architect a hybrid server backup strategy that fits your business.
Server Backup Destinations
Learning about different backup destinations can help administrators craft better backup policies and procedures to ensure the safety of your data for the long term. When structuring your server backup strategy, you essentially have three choices for where to store data: on-premises, in the cloud, or in a hybrid environment that uses both. First, though, let’s explain what a hybrid environment truly is.
Refresher: What Is Hybrid Cloud?
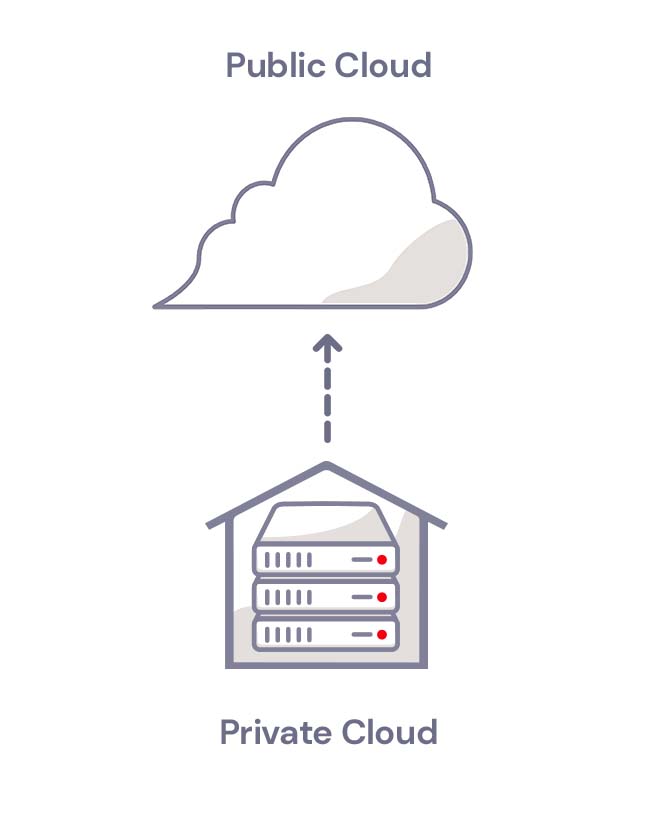
Hybrid cloud refers to a cloud environment made up of both private cloud resources (typically on-premises, although they don’t have to be) and public cloud resources with some kind of orchestration between them. Let’s define private and public clouds:
A public cloud essentially lives in a data center that’s used by many different tenants and maintained by a third-party company. Tenants share the same physical hardware, and their data is virtually separated so one tenant can’t access another tenant’s data.
A private cloud is dedicated to a single tenant. Private clouds are traditionally thought of as on-premises. Your company provisions and maintains the infrastructure needed to run the cloud at your office. Now, though, you can rent rackspace or even private, dedicated servers in a data center, so a private cloud can be off-premises, but it’s still dedicated only to your company.
Hybrid clouds are defined by a combined management approach, which means they have some type of orchestration between the public and private cloud that allows data to move between them as demands, needs, and costs change, giving businesses greater flexibility and more options for data deployment and use.
Here are some examples of different server backup destinations according to where your data is located:
Local backup destinations.
Cloud-only backups.
Hybrid cloud backups.
Local Backup Destinations
On-premises backup, also known as a local backup, is the process of backing up your system, applications, and other data to a local device. Tape and network-attached storage (NAS) are examples of common local backup solutions.
Tape: With tape backup, data is copied from its primary storage location to a tape cartridge using a tape drive. Tape creates a physical air gap, meaning there’s a literal gap of air between the data on the tape and the network—they are not connected in any way. This makes tape a highly secure option, but it comes at a cost. Tape requires physical storage space some businesses may not have. Tape maintenance and management can be very time consuming. And tapes can degrade, resulting in data loss.
NAS:NAS is a type of storage device that is connected to a network to allow data processing and storage through a secure, centralized location. With NAS, authorized users can access stored data from anywhere with a browser and a LAN connection. NAS is flexible, relatively easy to scale, and cost-effective.
Cloud-only Backups
Cloud-only backup strategies are becoming more commonplace as startups take a cloud-native approach and existing companies undergo digital transformations. A cloud-only backup strategy involves eliminating local, on-premises backups and sending files and databases to the cloud vendor for storage. It’s still a great idea to keep a local copy of your backup so you comply with a 3-2-1 backup strategy (more on that below). You could also utilize multiple cloud vendors or multiple regions with the same vendor to ensure redundancy. In the event of an outage, your data is stored safely in a separate cloud or a different cloud region and can easily be restored.
With services like Cloud Replication, companies can easily achieve a solid cloud-only server backup solution within the same cloud vendor’s infrastructure. It’s also possible to orchestrate redundancy between two different cloud vendors in a multi-cloud strategy.
Hybrid Cloud Backups
When you hear the term “hybrid” when it comes to servers, you might initially think about a combination of on-premises and cloud data. That’s typically what people think of when they imagine a hybrid cloud, but as we mentioned earlier, a hybrid cloud is a combination of a public cloud and a private cloud. Today, private clouds can live off-premises, but for our purposes, we’ll consider private clouds as being on-premises. A hybrid server backup strategy is an easy way to accomplish a 3-2-1 backup strategy, generally considered the gold standard when it comes to backups.
Refresher: What Is the 3-2-1 Backup Strategy?
The 3-2-1 backup strategy is a tried and tested way to keep your data accessible, yet safe. It includes:
3: Keep three copies of any important file—one primary and two backups.
2: Keep the files on two different media types to protect against different types of hazards.
1: Store one copy off-site.
A hybrid server backup strategy can be helpful for fulfilling this sage backup advice as it provides two backup locations, one in the private cloud and one in the public cloud.
Choosing a Backup Strategy
Choosing a backup strategy that is right for you involves carefully evaluating your existing systems and your future goals. Can you get there with your current backup strategy? What if a ransomware or distributed denial of service (DDoS) attack affected your organization tomorrow? Decide what gaps need to be filled and take into consideration a few more crucial points:
Evaluate your vulnerabilities. Is your location susceptible to a local data disaster? How often do you think you might need to access your backups? How quickly would you need them?
Price. Various backup strategies will incur costs for hardware, service, expansions, and more. Carefully evaluate your organization’s finances to decide on a budget. And keep in mind that monthly fees and service charges may go up over time as you add more storage or use enhanced backup tools.
Storage capacity. How much storage capacity do you have on-site? How much data does your business generate over a given period of time? Do you have IT personnel to manage on-premises systems?
Access to hardware. Provisioning a private cloud on-premises involves purchasing hardware. Increasing supply chain issues can slow down factories, so be mindful of shortages and increased delivery times.
Scalability. As your organization grows, it’s likely that your data backup needs will grow, too. If you’re projecting growth, choose a data backup strategy that can keep up with rapidly expanding backup needs.
Backup Strategy Pros and Cons
Local Backup Strategy
Pros: A major benefit to using a local backup strategy is that organizations have fast access to data backups in case of emergencies. Backing up to NAS can also be faster locally depending on the size of your data set.
Cons: Maintaining on-premises hardware can be costly, but more important, your data is at a higher risk of loss from local disasters like floods, fires, or theft.
Cloud Backup Strategy
Pros: With a cloud-only backup strategy, there is no need for on-site hardware, and backup and recovery can be initiated from any location. Cloud resources are inherently scalable, so the stress of budgeting for and provisioning hardware is gone.
Cons: A cloud-only strategy is susceptible to outages if your data is consolidated with one vendor, however this risk can be mitigated by diversifying vendors and regions within the same vendor. Similarly, if your network goes down, then you won’t have access to your data.
Hybrid Cloud Backup Strategy
Pros: Hybrid cloud server backup strategies combine the best features of public and private clouds: You have fast access to your data locally while protecting your data from disaster by adding an off-site location to your backup strategy.
Cons: Setting up and running a private cloud server can be very costly. Businesses also need to plan their backup strategy a bit more thoughtfully because they must decide what to keep in a public cloud versus a private cloud or on local storage.
Hybrid Server Backup Considerations
Once you’ve decided a hybrid server backup strategy is right for you, there are many ways you can structure it. Here are just a few examples:
Keep backups of active working files on-premises and move all archives to the cloud.
Choose a cutover date if your business is ready to move mostly to the cloud going forward. All backups and archives prior to the cutover date could remain on-premises and everything after the cutover date gets stored in cloud storage.
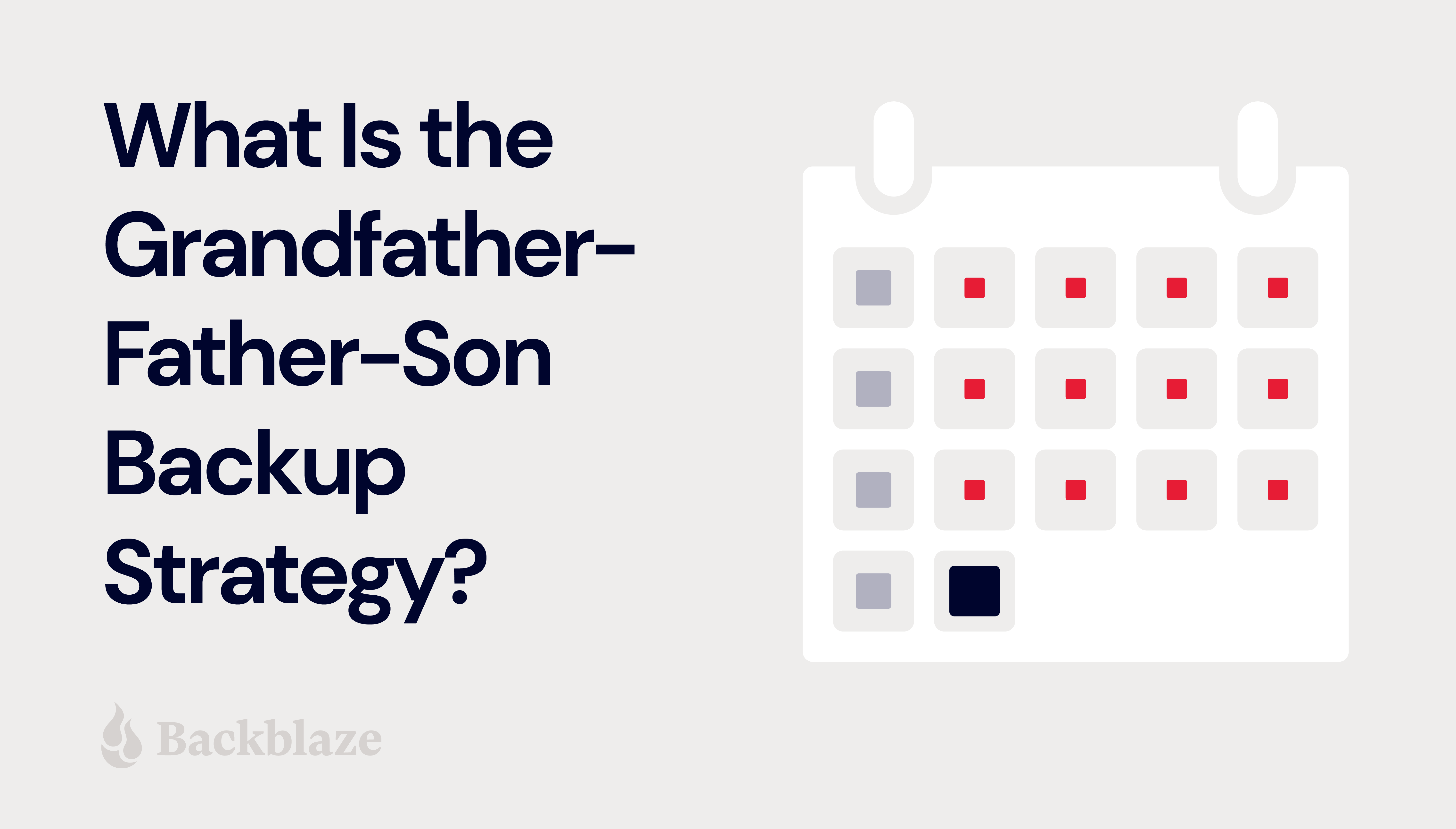
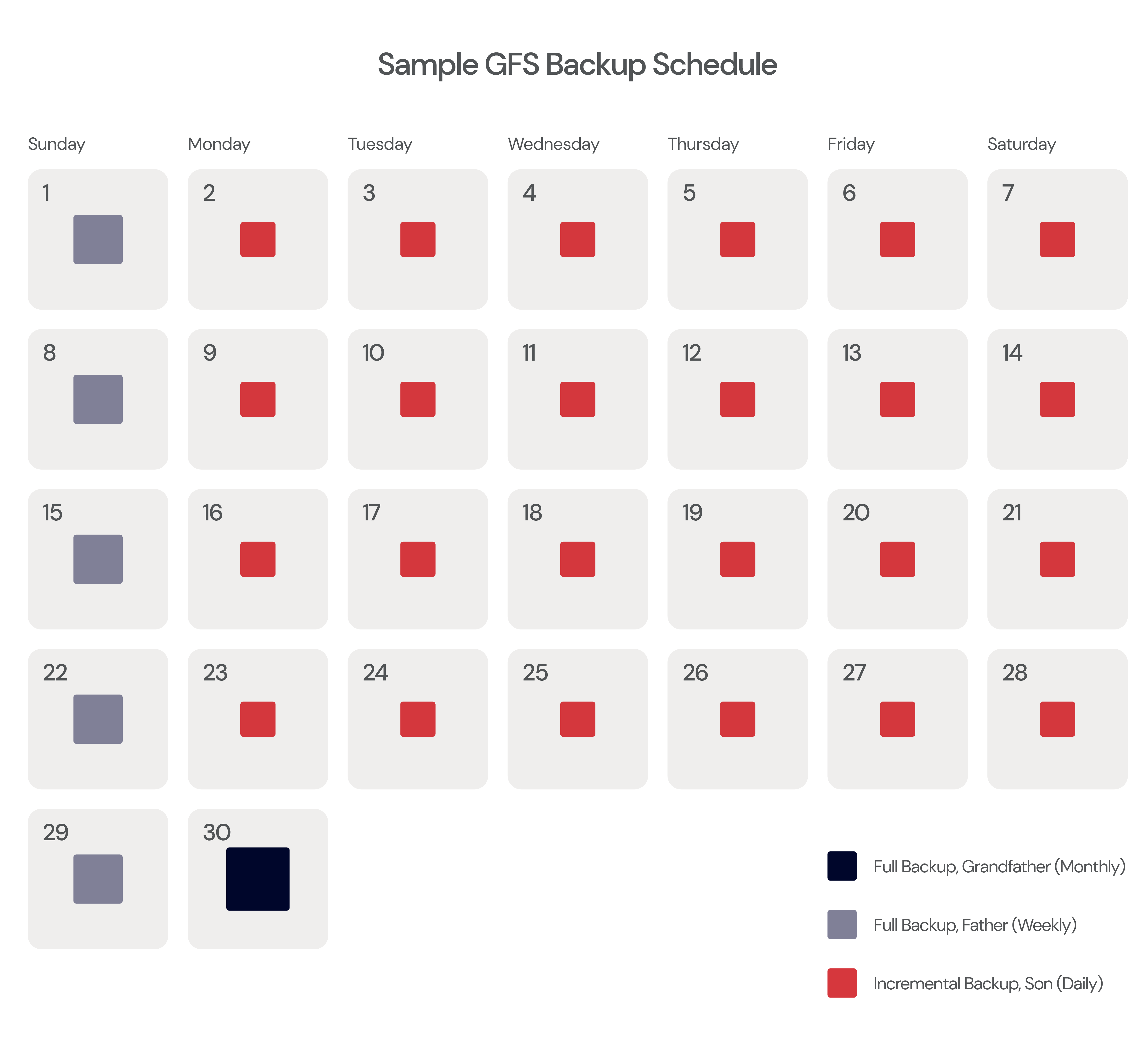
Store all incremental backups in cloud storage and keep all full backups and archives stored locally. Or, following the Grandfather-Father-Son (GFS) approach, put the father and son backups in the cloud and grandfather backups in local storage. (Or vice versa.)
As you’re structuring your server backup strategy, consider any GDPR, HIPAA, or cybersecurity requirements. Does it call for off-site, air-gapped backups? If so, you may want to move that data (like customer or patient records) to the cloud and keep other, non-regulated data local. Some industries, particularly government and heavily regulated industries, may require you to keep some data in a private cloud.
Every June, for Backup Awareness Month, we work with The Harris Poll to gauge the state of backups in the U.S. This is the 14th year of that survey, where we ask simply: “How often do you back up all the data on your computer?”
On occasion, we’ll throw some additional questions into the mix as well, and this year we focused on the confusion we often see between sync and backup services, along with respondents’ history of data loss. The backup frequency results of this year’s survey show that trends are holding pretty steady, but the rest of the results…very interesting!
First Things First: Are YOU Backing Up?
If you’re not backing up, start now and increase the stats for 2023.
How Backup Frequency Is Trending in 2022
When looking solely at backup frequency, the results are mostly neutral this year when compared to 2021. We see a slight 1% increase in computer owners that are backing up on a yearly basis, but that same 1% decrease in those that are backing up daily. The rest of the results were pretty consistent from year to year.
The main issue we’re seeing here is that the number of computer owners who have never backed up their computer appears to have stopped decreasing, meaning that about 20% of people are still at risk of losing all of their data in the event of a computer crash or loss.
Results are among computer owners.
Some people aren’t into reading charts, so we also have this handy table:
Results are among computer owners.
If you’re not a fan of tables, but do like pie, here’s a comparison of the 2022 data compared to when we first started in 2008:
It’s nice to see the mix changing so much over time, especially with the “never” category fading. While the number of daily backups is still not anywhere close to where we’d like it, the data indicates that:
Overall, computer owners are backing up more frequently than a decade ago. However, as our astute readers know, the longer you go without creating a backup, the more data you are prone to losing should disaster strike.
A woman between 35-44 years of age (21% likely to back up versus 9% of those 18-34 and 6% of those 55-64)…
Who lives in the Western United States (17% more likely to back up vs. the South and Midwest at 9% and 7%, respectively)…
With a household income of over $100K (13% likely to back up their data versus those households of $50K-$74.9K which are at 6%).
Has that changed over the last year? Well, in 2022, the data suggest no statistically significant deviations that we can pull out, so maybe that’s good news across the spectrum?
Is Confusion a Cause for Concern?
While the number of people backing up at least once is good, we think there might still be some confusion in the world about how exactly they are backing up their data and what is getting backed up. We wanted to dive a bit deeper. When looking at the Americans who own a computer:
80% backed up all the data on that computer at least once.
41% of those folks fully back it up once a month or more often.
57% who have ever backed up use a “cloud-based” system as their primary backup.
12% of computer owners use a cloud backup service like Backblaze as their primary backup, and among those who do:
52% say their service automatically backs up all the data on their computer.
25% say it backs up only the data they select with no limitations.
9% say it backs up only the data they select but with some limits.
3% marked “other” and more concerningly…
10% are not sure at all.
With 57% of computer owners using “the cloud” to back up their data, but only 12% of those using a cloud backup service, we’re left to wonder, what are the others using? In many cases, it’s a cloud drive or cloud sync service which may not actually be performing basic automated backup tasks.
Refresher: Backup vs. Sync
We’ve often discussed the differences between sync and backup—how both of them are useful tools, but very different. While sync services are great for collaborating on and sharing data, they are not true backup services in that they’re typically not automated, and don’t provide the same level of protection as dedicated backup services can. And, be careful about only having data in one location—44% lost access to their data when a shared or synced drive was deleted. For more information, read our cloud backup vs. cloud sync blog post!
Even of those using a proper cloud backup solution, 48% may not be backing up all their data, and 10% of folks aren’t sure at all what their cloud backup service is doing. Yikes.
We then asked those who use one of the listed backups (i.e., “the cloud,” external hard drive, or NAS) about their confidence level that the service they use is set up to protect all the data on their computer, and 61% of people were not very confident. The numbers are broken down below:
39% were very confident.
48% were somewhat confident.
13% were not at all or not very confident.
That’s not a ton of confidence, and maybe now is a good time to remind folks to check their backups and to test a restore!
Why Is Backing Up Important?
This year’s survey results continue to show us that having a good backup strategy in place, whether for a business or an individual, is a great way to mitigate against different data disasters. Especially when you consider that of Americans who own a computer:
67% report accidentally deleting something.
54% report having lost data.
53% were affected by a security incident.
48% had an external hard drive crash.
21% of those crashes have happened in the last year.
44% lost access to their data when a shared drive or synced drive was deleted.
External hard drives are a great local backup method, and we recommend them when we discuss having a 3-2-1 backup strategy, but as our own Hard Drive Stats indicate, even in our professional environment, they do fail. And with 48% of computer owners reporting that they experienced a similar failure on their home device, it underscores the importance of having an off-site backup like Backblaze, just in case.
With over half of computer owners reporting a security incident as well and ransomware on the rise, there’s never been a more appropriate time to start backing up your computer. At Backblaze, we’re on a mission to make storing and using your data astonishingly easy, and we invite you to give our services a try!
Survey Method:
This year’s survey was conducted online within the United States by The Harris Poll on behalf of Backblaze from May 19-23, 2022, among 2,068 adults ages 18+, among whom 1,861 own a computer. The sampling precision of Harris online polls is measured by using a Bayesian credible interval. For this study, the sample data is accurate to within +2.8 percentage points using a 95% confidence level.
Prior year’s surveys were conducted online by The Harris Poll on behalf of Backblaze among U.S. adults ages 18+ who own a computer in May 12-14, 2021 (n=1,870); June 1-3, 2020 (n=1,913); June 6-10, 2019 (n=1,858); June 5-7, 2018 (n=1,871); May 19-23, 2017 (n=1,954); May 13-17, 2016 (n=1,920); May 15-19, 2015 (n=2,009); June 2-4, 2014 (n=1,991); June 13–17, 2013 (n=1,952); May 31–June 4, 2012 (n=2,176); June 28–30, 2011 (n=2,209); June 3–7, 2010 (n=2,051); May 13–14, 2009 (n=2,154); and May 27–29, 2008 (n=2,723).
For complete survey methodologies, including weighting variables and subgroup sample sizes, please contact Backblaze.
Leading business media brand, Fortune, has amassed hundreds of thousands of hours of footage capturing conference recordings, executive interviews, panel discussions, and more showcasing some of the world’s most high-profile business leaders over the years. It’s the jewel in their content crown, and there are no second chances when it comes to capturing those moments. If any of those videos were to be lost or damaged, they’d be gone forever, with potential financial consequences to boot.
At the same time, Fortune’s distributed team of video editors needs regular and reliable access to that footage for use on the company’s sites, social media channels, and third-party web properties. So when Fortune divested from their parent company Meredith Corporation in 2018, revising its tech infrastructure was a priority.
Becoming an independent enterprise gave Fortune the freedom to escape legacy limitations and pop the cork on bottlenecks that were slowing productivity and raking up expenses. But their first attempt at a solution was expensive, unreliable, and difficult to use—until they migrated to Backblaze B2 Cloud Storage. Jeff Billark, Head of IT Infrastructure for Fortune Media Group, shared how it all went down.
Not Quite Camera-ready: An Overly Complex Tech Stack
Working with systems integrator CHESA, Fortune used a physical storage device to seed data to the cloud. They then built a tech stack that included:
An on-premises server housing Primestream Xchange media asset management (MAM) software for editing, tagging, and categorization.
Archive management software to handle backups and long-term archiving.
Cold object storage from one of the diversified cloud providers to hold backups and archive data.
But it didn’t take long for the gears to gum up. The MAM system couldn’t process the huge quantity of data in the archive they’d seeded to the cloud, so unprocessed footage stayed buried in cold storage. To access a video, Fortune editors had to work with the IT department to find the file, thaw it, and save it somewhere accessible. And the archiving software wasn’t reliable or robust enough to handle Fortune’s file volume; it indicated that video files had been archived without ever actually writing them to the cloud.
Time for a Close-up: Simplifying the Archive Process
If they hadn’t identified the issue quickly, Fortune could have lost 100TB of active project data. That’s when CHESA suggested Fortune simplify its tech stack by migrating from the diversified cloud provider to Backblaze B2. Two key tools allowed Fortune to eliminate archiving middleware by making the move:
Thanks to Primestream’s new Backblaze data connector, Backblaze integrated seamlessly with the MAM system, allowing them to write files directly to the cloud.
They implemented Panic’s Transmit tool to allow editors to access the archives themselves.
Backblaze’s Universal Data Migration program sealed the deal by eliminating the transfer and egress fees typically associated with a major data migration. Fortune transferred over 300TB of data in less than a week with zero downtime, business disruption, or egress costs.
For Fortune, the most important benefits of migrating to Backblaze B2 were:
Increasing reliability around both archiving and downloading video files.
Minimizing need for IT support with a system that’s easy to use and manage.
Unlocking self-service options within a modern digital tech experience.
“Backblaze really speeds up the archive process because data no longer has to be broken up into virtual tape blocks and sequences. It can flow directly into Backblaze B2.”
—Jeff Billark, Head of IT Infrastructure, Fortune Media Group
Unlocking Hundreds of Thousands of Hours of Searchable, Accessible Footage
Fortune’s video editing team now has access to two Backblaze B2 buckets that they can access without any additional IT support:
Bucket #1: 100TB of active video projects.
When any of the team’s video editors needs to find and manipulate footage that’s already been ingested into Primestream, it’s easy to locate the right file and kick off a streamlined workflow that leads to polished, new video content.
Bucket #2: 300TB of historical video files.
Using Panic’s Transmit tool, editors sync data between their Mac laptops and Backblaze B2 and can easily search historical footage that has not yet been ingested into Primestream. Once files have been ingested and manipulated, editors can upload the results back to Bucket #1 for sharing, collaboration, and storage purposes.
With Backblaze B2, Fortune’s approach to file management is simple and reliable. The risk of archiving failures and lost files is greatly reduced, and self-service workflows empower editors to collaborate and be productive without IT interruptions. Fortune also reduced storage and egress costs by about two-thirds, all while accelerating its content pipeline and maximizing the potential of its huge and powerful video archive.
“Backblaze is so simple to use, our editors can manage the entire file transfer and archiving process themselves.”
—Jeff Billark, Head of IT Infrastructure, Fortune Media Group
If you’re in charge of IT for a public sector entity, you know the budgeting and procurement process doesn’t lend itself well to buying cloud services. But, today, the life of a public sector CIO just got a whole lot easier. Through a new partnership with Carahsoft, public sector customers can now leverage their existing state, local, and federal buying programs to access Backblaze B2 Cloud Storage.
We’re not the only cloud storage provider available through Carahsoft, the Master Government Aggregator for the IT industry, but we are the easy, affordable, trusted solution among providers in their ecosystem. Read on to learn more about the partnership.
The Right Cloud Solution at the Right Time
For state and local governments, federal agencies, healthcare providers, and higher education institutions, the pandemic introduced challenges that required cloud scalability—remote work and increased demand for public services, to name two. But due to procurement procedures and budgeting incompatibility, adopting the cloud isn’t always a smooth process for the public sector.
The public sector typically uses a CapEx model to budget for IT services. The cloud’s pay-as-you-go pricing model can be at odds with this budgeting method. Public sector CIOs are also typically required to use established buying programs to purchase services, which many cloud providers are not a part of.
Further, recent research shows that while public sector cloud adoption has increased, a “budget snapback” driven by return to office IT expenses is prompting CIOs in this field to optimize their cloud spend. Public sector institutions are seeking additional value in their cloud budgets, and clamoring for a way to purchase those services through existing programs and channels.
“Public sector decision-makers reference budget, pricing models, and transparency as their biggest barriers to cloud adoption. That’s why this partnership is so exciting: Our services come at a fraction of the price of other options, and we’ve long been known for our transparent, trusted approach to working with customers.” —Nilay Patel, VP of Sales, Backblaze
Bringing Capacity-based Cloud Services to the Public Sector
Backblaze, through the partnership with Carahsoft—which was enabled by our recent launch of a capacity-based pricing bundle, Backblaze B2 Reserve—solves both the budgeting and procurement challenges public sector CIOs are facing.
The partnership brings Backblaze services to state, local, and federal buying programs in a model they prefer at a fraction of the price of traditional cloud storage providers. It’s an affordable, easy solution for public sector CIOs seeking to optimize cloud spend in the wake of the pandemic.
“Backblaze’s ease of use, affordability, and transparency are just some of the major advantages of their robust cloud backup and storage services. We look forward to working with Backblaze and our reseller partners to help agencies better protect and secure their business data.” —Evan Slack, Director of Sales for Emerging Cloud and Virtualization Technologies, Carahsoft
About Carahsoft
Carahsoft Technology Corp. is The Trusted Government IT Solutions Provider®, supporting public sector organizations across federal, state, and local government agencies and education and healthcare markets. As the Master Government Aggregator® for vendor partners, Carahsoft delivers solutions for cybersecurity, multi-cloud, DevSecOps, big data, artificial intelligence, open-source, customer experience, and more. Working with resellers, systems integrators, and consultants, Carahsoft’s sales and marketing teams provide industry leading IT products, services, and training through hundreds of contract vehicles.
About Backblaze B2 Reserve
Backblaze B2 Reserve packages cloud storage in a capacity-based bundle with an annualized SKU which works seamlessly with channel billing models. The offering also provides seller incentives, Tera-grade support, and expanded migration services to empower the channel’s acceleration of cloud storage adoption and revenue growth. Customers can purchase Backblaze B2 through channel partners, starting at 20TB.
A Public Sector Case Study: Kings County Modernizes With Backblaze B2 Cloud Storage
With a looming bill to replace aging tapes and an out-of-warranty tape drive, the Kings County IT department modernized their IT infrastructure by moving to the cloud for backups. With help from Backblaze, Kings County natively tiered backups from their preferred backup software to Backblaze B2 Cloud Storage, enabling them to implement incremental backups, reduce their overall IT footprint and costs, and save about 150 hours of staff time per year.
How to Get Started With Backblaze B2 and Carahsoft
For resellers interested in offering Backblaze services, it is business as usual if you currently have an account with Carahsoft. Those with immediate quote requests should email partnerships@backblaze.com for further details. For any resellers who do not have an account with Carahsoft and would like the ability to sell Backblaze services, follow this link to create a Carahsoft account.
If you’re in charge of backups for your company, you know backing up your server is a critical task to protect important business data from data disasters like fires, floods, and ransomware attacks. You also likely know that digital transformation is pushing innovation forward with server backup solutions that live in the cloud.
Whether you operate in the cloud, on-premises, or with a hybrid environment, finding a server backup solution that meets your needs helps you keep your data and your business safe and secure.
This guide explains the various server backup solutions available both on-premises and in the cloud, and how to choose the right backup solution for you. Read on to learn more about choosing the right server backup solution for your needs.
On-premises Solutions for Server Backup
On-premises solutions store data on servers in an in-house data center managed and maintained internally. Although there has been a dramatic shift from on-premises to cloud server solutions, many organizations choose to operate their legacy systems on-premises alone or in conjunction with the cloud in a hybrid environment.
LTO/Tape
Linear tape-open (LTO) backup is the process of copying data from primary storage to a tape cartridge. If the hard disk crashes, the tapes will still hold a copy of the data.
Pros:
High capacity.
Tapes can last a long time.
Provides a physical air gap between backups and the network to protect against threats like ransomware.
Cons:
Up-front CapEx expense.
Tape drives must be monitored and maintained to ensure they are functioning properly.
Tapes take up lots of physical space.
Tape is susceptible to degradation over time.
The process of backing up to tape can be time consuming for high volumes of data.
NAS
Network-attached storage (NAS) enables multiple users and devices to store and back up data through a secure server. Anyone connected to a LAN can access the storage through a browser-based utility. It’s essentially an extra network strictly for storing data that users can access via its attached network device.
Pros:
Faster to restore files and access backups than tape backups.
More digitally intuitive and straightforward to navigate.
Comes with built-in backup and sync features.
Can connect and back up multiple computers and endpoints via the network.
Cons:
Requires physical maintenance and periodic drive replacement.
Each appliance has a limited storage capacity.
Because it’s connected to your network, it is also vulnerable to network attacks.
Local Server Backup
Putting your backup files on the same server or a storage server is not recommended for business applications. Still, many people choose to organize their backup storage on the same server the data runs on.
Pros:
Highly local.
Quick and easy to access.
Cons:
Generally less secure.
Capacity-limited.
Susceptible to malware, ransomware, and viruses.
Including these specific backup destinations, there are some pros to using on-premises backup solutions in general. For example, you might still be able to access backup files without an internet connection using on-premises solutions. And you can expect a fast restore if you have large amounts of data to recover.
However, all on-premises backup storage solutions are vulnerable to natural disasters, fires, and water damage despite your best efforts. While some methods like tape are naturally air-gapped, solutions like NAS are not. Even with a layered approach to data protection, NAS leaves a business susceptible to attacks.
Backing Up to Cloud Storage
Many organizations choose a cloud-based server for backup storage instead of or in addition to an on-premises solution (more on using both on-premises and cloud solutions together later) as they continue to integrate modern digital tools. While an on-premises system refers to data hardware and physical storage solutions, cloud storage lives “in the cloud.”
A cloud server is a virtual server that is hosted in a cloud provider’s data center. “The cloud” refers to the virtual servers users access through web browsers, APIs, CLIs, and SaaS applications and the databases that run on the servers themselves.
Because cloud providers manage the server’s physical location and hardware, organizations aren’t responsible for managing costly data centers. Even small businesses that can’t afford internal infrastructure can outsource data management, backup, and cloud storage from providers.
Pros
Highly scalable since companies can add as much storage as needed without ever running out of space.
Typically far less expensive than on-premises backup solutions because there’s no need to pay for dedicated IT staff, hardware upgrades or repair, or the space and electricity needed to run an on-premises system.
Builds resilience from natural disasters with off-site storage.
Virtual air-gapped protection may be available.
Fast recovery times in most cases.
Cons
Cloud storage fees can add up depending on the amount of storage your organization requires and the company you choose. Things like egress fees, minimum retention policies, and complicated pricing tiers can cause headaches later, so much so that there are companies dedicated to helping you decipher your AWS bill, for example.
Can require high bandwidth for initial deployment, however solutions like Universal Data Migration are making deployment and migrations easier.
Since backups can be accessed via API, they can be vulnerable to attacks without a feature like Object Lock.
It can be tough to choose between cloud storage vs. on-premises storage for backing up critical data. Many companies choose a hybrid cloud backup solution that involves both on-premises and cloud storage backup processes. Cloud backup providers often work with companies that want to build a hybrid cloud environment to run business applications and store data backups in case of a cyber attack, natural disaster, or hardware failure.
If you’re stuck between choosing an on-premises or cloud storage backup solution, a hybrid cloud option might be a good fit.
A hybrid cloud strategy combines a private, typically on-premises, cloud with a public cloud.
All-in-one vs. Integrated Solutions
When it comes to cloud backup solutions, there are two main types: all-in-one and integrated solutions.
Let’s talk about the differences between the two:
All-in-one Tools
All-in-one tools are cloud backup solutions that include both the backup application software and the cloud storage where backups will be stored. Instead of purchasing multiple products and deploying them separately, all-in-one tools allow users to deploy cloud storage with backup features together.
Pros:
No need for additional software.
Simple, out-of-the-box deployment.
Creates a seamless native environment.
Cons:
Some all-in-one tools sacrifice granularity for convenience, meaning they may not fit every use case.
They can be more costly than pairing cloud storage with backup software.
Integrated Solutions
Integrated solutions are pure cloud storage providers that offer cloud storage infrastructure without built-in backup software. An integrated solution means that organizations have to bring their own backup application that integrates with their chosen cloud provider.
Pros:
Mix and match your cloud storage and backup vendors to create a tailored server backup solution.
More control over your environment.
More control over your spending.
Cons:
Requires identifying and contracting with more than one provider.
Can require more technical expertise than with an all-in-one solution, but many cloud storage providers and backup software providers have existing integrations to make onboarding seamless.
How to Choose a Cloud Storage Solution
Choosing the best cloud storage solution for your organization involves careful consideration. There are several types of solutions available, each with unique capabilities. You don’t need the most expensive solution with bells and whistles. All you need to do is find the solution that fits your business model and future goals.
However, there are five main features that every organization seeking object storage in the cloud should look out for:
Cost
Cost is always a top concern for adopting new processes and tools in any business setting. Before choosing a cloud storage solution, take note of any fees or file size requirements for retention, egress, and data retrieval. Costs can vary significantly between storage providers, so be sure to check pricing details.
Ease-of-use and Onboarding Support
Adopting a new digital tool may also require a bit of a learning curve. Choosing a solution that supports your OS and is easy to use can help speed up the adoption rate. Check to see if there are data transfer options or services that can help you migrate more effectively. Not only should cloud storage be simple to use, but easy to deploy as well.
Security and Recovery Capabilities
Most object storage cloud solutions come with security and recovery capabilities. For example, you may be looking for a provider with Object Lock capabilities to protect data from ransomware or a simple way to implement disaster recovery protocols with a single command. Otherwise, you should check if the security specs meet your needs.
Integrations
All organizations seeking cloud storage solutions need to make sure that they choose a compatible solution with their existing systems and software. For example, if your applications speak the S3 API language, your storage systems must also speak the same language.
Many organizations use software-based backup tools to get things done. To take advantage of the benefits of cloud storage, these digital tools should also integrate with your storage solution. Popular backup solutions such as MSP360 and Veeam are built with native integrations for ease of use.
Support Models
The level of support you want and need should factor into your decision-making when choosing a cloud provider. If you know your team needs fast access to support personnel, make sure the cloud provider you choose offers a support SLA or the opportunity to purchase elevated levels of support.
Questions to Ask Before Deciding on a Cloud Storage Solution
Of course, there are other considerations to take into account. For example, managed service providers will likely need a cloud storage solution to manage multiple servers. Small business owners may only need a set amount of storage for now but with the ability to easily scale with pay-as-you-go pricing as the business grows. IT professionals might be looking for a simplified interface and centralized management to make monitoring and reporting more efficient.
When comparing different cloud solutions for object storage, there are a few more questions to ask before making a purchase:
Is there a web-based admin console? A web-based admin console makes it easy to view backups from multiple servers. You can manage all your storage from one single location and download or recover files from anywhere in the world with a network connection.
Are there multiple ways to interact with the storage? Does the provider offer different ways to access your data, for example, via a web console, APIs, CLI, etc.? If your infrastructure is configured to work with the S3 API, does the provider offer S3 compatibility?
Can you set retention? Some industries are more highly regulated than others. Consider whether your company needs a certain retention policy and ensure that your cloud storage provider doesn’t unnecessarily charge minimum file retention fees.
Is there native application support? A native environment can be helpful to back up an Exchange and SQL Server appropriately, especially for team members who are less experienced in cloud storage.
What types of restores does it offer? Another crucial factor to consider is how you can recover your data from cloud storage, if necessary.
Making a Buying Decision: The Intangibles
Lastly, don’t just consider the individual software and cloud storage solutions you’re buying. You should also consider the company you’re buying from. It’s worth doing your due diligence when vetting a cloud storage provider. Here are some areas to consider:
Stability
When it comes to crucial business data, you need to choose a company with a long-standing reputation for stability.
Data loss can happen if a not-so-well-known cloud provider suddenly goes down for good. And some lesser-known providers may not offer the same quality of uptime, storage, and other security and customer support options.
Find out how long the company has been providing cloud storage services, and do a little research to find out how popular its cloud services are.
Customers
Next, take a look at the organizations that use their cloud storage backup solutions. Do they work with companies similar to yours? Are there industry-specific features that can boost your business?
Choosing a cloud storage company that can provide the specs that your business requires plays an important role in the overall success of your organization. By looking at the other customers that a cloud storage company works with, you can better understand whether or not the solution will meet your needs.
Reviews
Online reviews are a great way to see how users respond to a cloud storage product’s features and benefits before trying it out yourself.
Many software review websites such as G2, Gartner Peer Insights, and Capterra offer a comprehensive overview of different cloud storage products and reviews from real customers. You can also take a look at the company’s website for case studies with companies like yours.
Values
Another area to investigate when choosing a cloud storage provider is the company values.
Organizations typically work with other companies that mirror their values and enhance their ability to put them into action. Choosing a cloud storage provider with the correct values can help you reach new clients. But choosing a provider with values that don’t align with your organization can turn customers away.
Many tech companies are proud of their values, so it’s easy to get a feel for what they stand for by checking out their social media feeds, about pages, and reviews from people who work there.
Continuous Improvement
An organization’s ability to improve over time shows resiliency, an eye for innovation, and the ability to deliver high-quality products to users like you. You can find out if a cloud storage provider has a good track record for improving and innovating their products by performing a search query for new products and features, new offerings, additional options, and industry recognition.
Keep each of the above factors in mind when choosing a server backup solution for your needs.
How Cloud Storage Can Protect Servers and Critical Business Data
Businesses have already made huge progress in moving to the cloud to enable digital transformations. Cloud-based solutions can help businesses modernize server backup solutions or adopt hybrid cloud strategies. To summarize, here are a few things to remember when considering a cloud storage solution for your server backup needs:
Understand the pros and cons of on-premises backup solutions and consider a hybrid cloud approach to storing backups.
Evaluate a provider’s cost, security offerings, integrations, and support structure.
Consider intangible factors like reputation, reviews, and values.
Have more questions about cloud storage or how to implement cloud backups for your server? Let us know in the comments. Ready to get started? Your first 10GB are free.
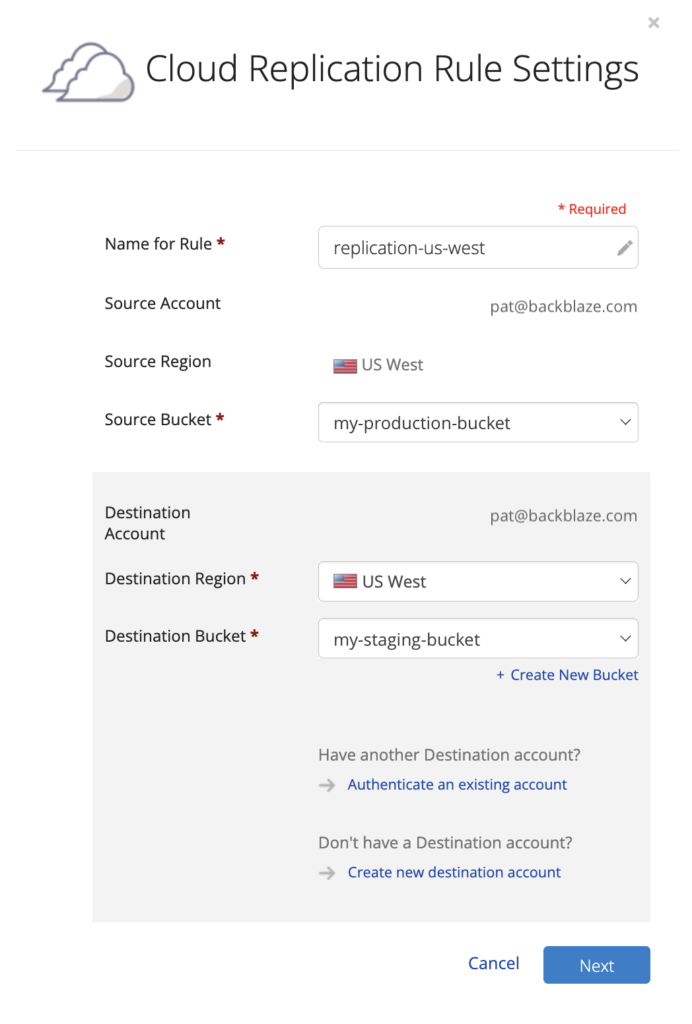
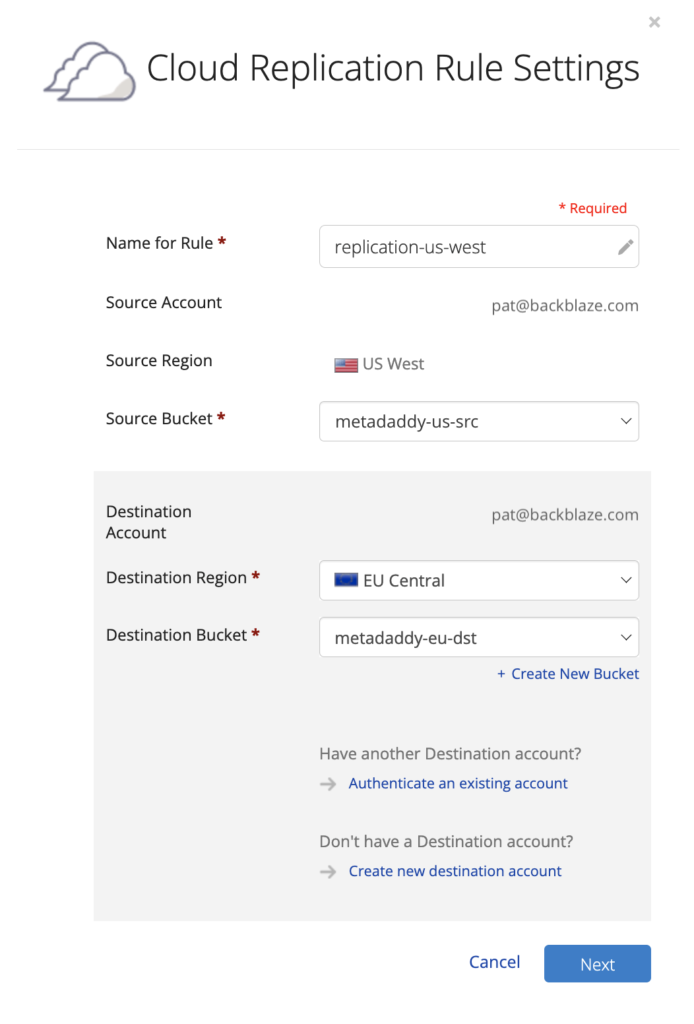
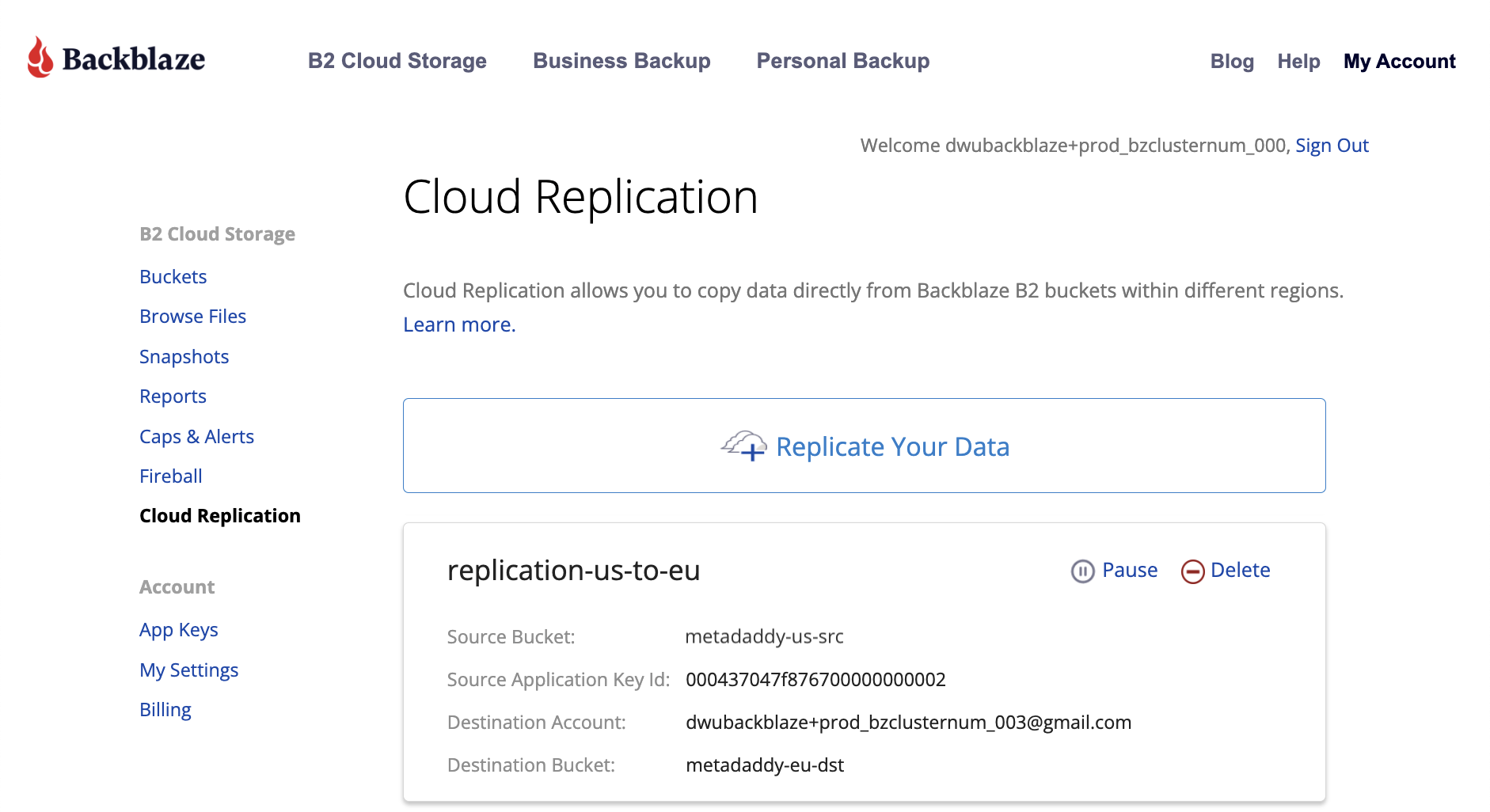
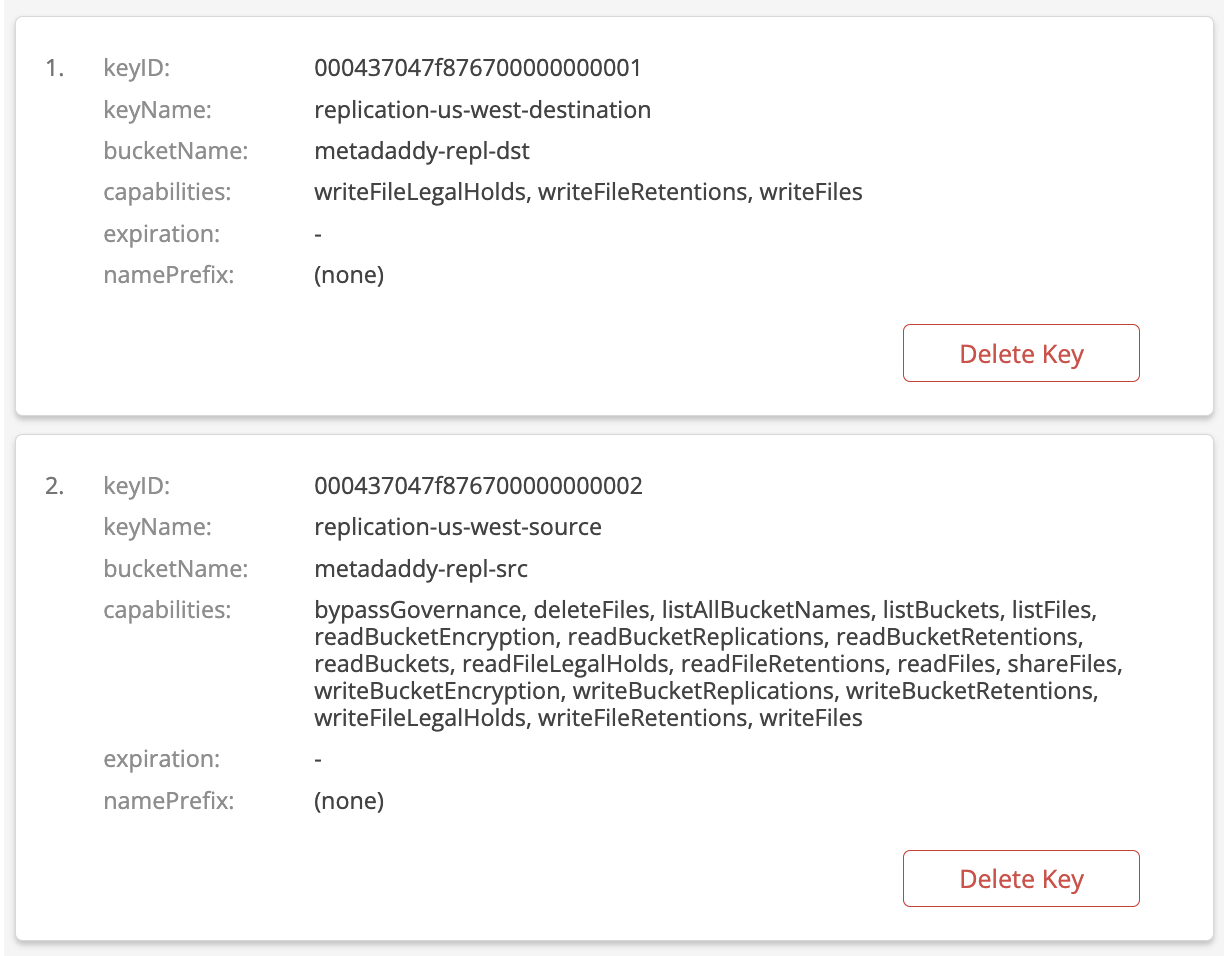
Cloning is a little bit creepy (Seriously, you can clone your pet now?), but having clones of your data is far from it—creating and storing redundant copies is essential when it comes to protecting your business, complying with regulations, or developing apps. With Backblaze Cloud Replication—now generally available—you can get set up in just a few clicks to automatically copy data across buckets, accounts, or regions.
Unbox Backblaze Cloud Replication
Join us for a webinar to unbox all the capabilities of Cloud Replication on July 13, 2022 at 10 a.m. PDT with Sam Lu, Product Manager at Backblaze.
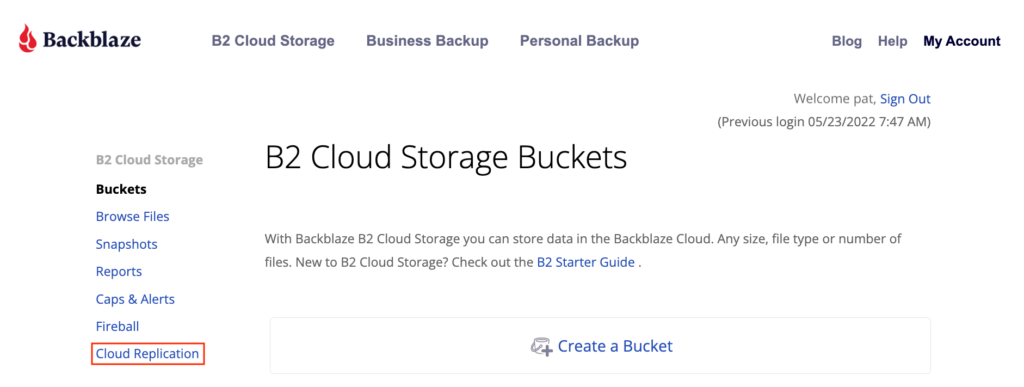
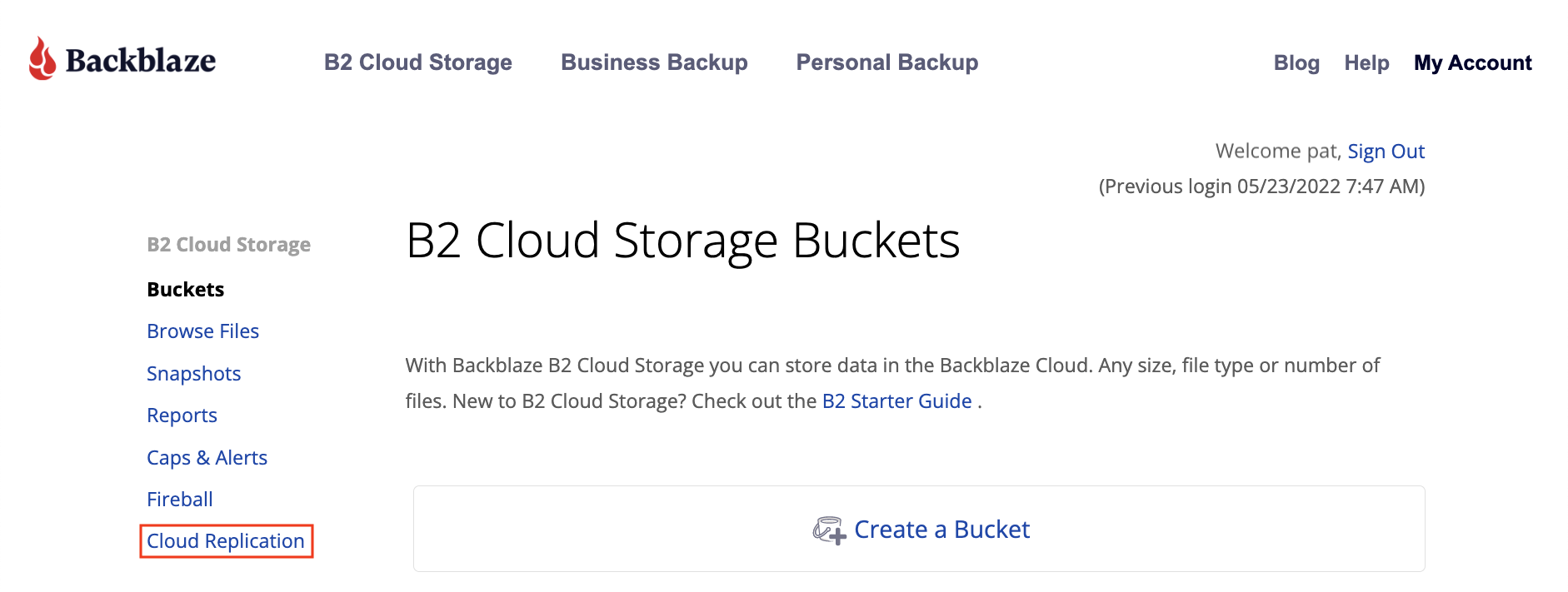
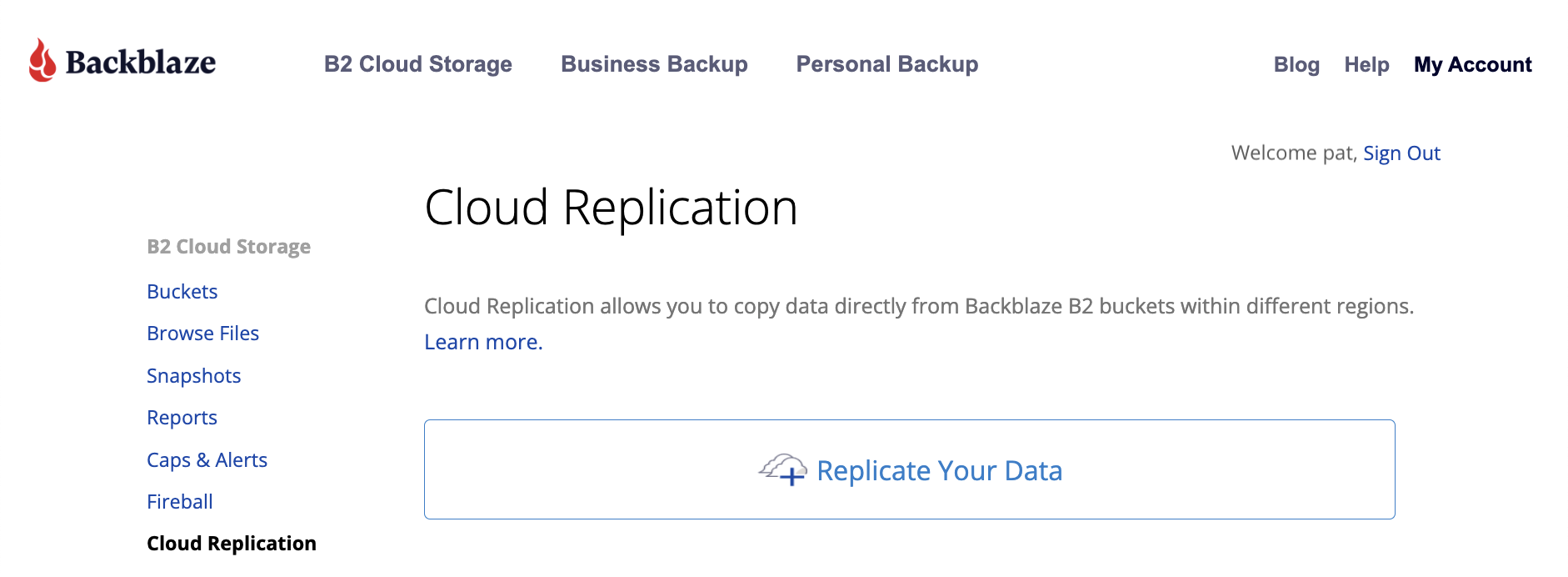
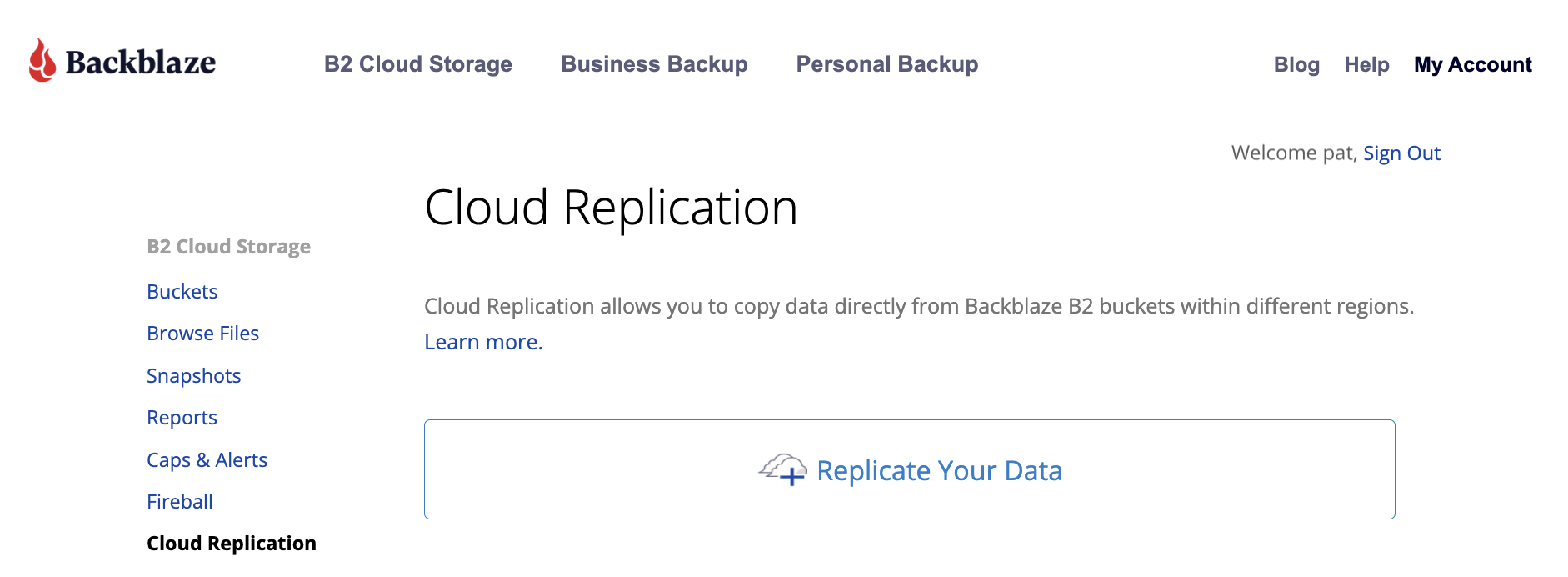
Existing customers can start using Cloud Replication immediately by clicking on Cloud Replication within their Backblaze account or via the Backblaze B2 Native API.
Simply click on Cloud Replication in your account to get started.
Not a Backblaze customer yet? Sign up here. And read on for more details on how this feature can benefit you.
What Is Backblaze Cloud Replication?
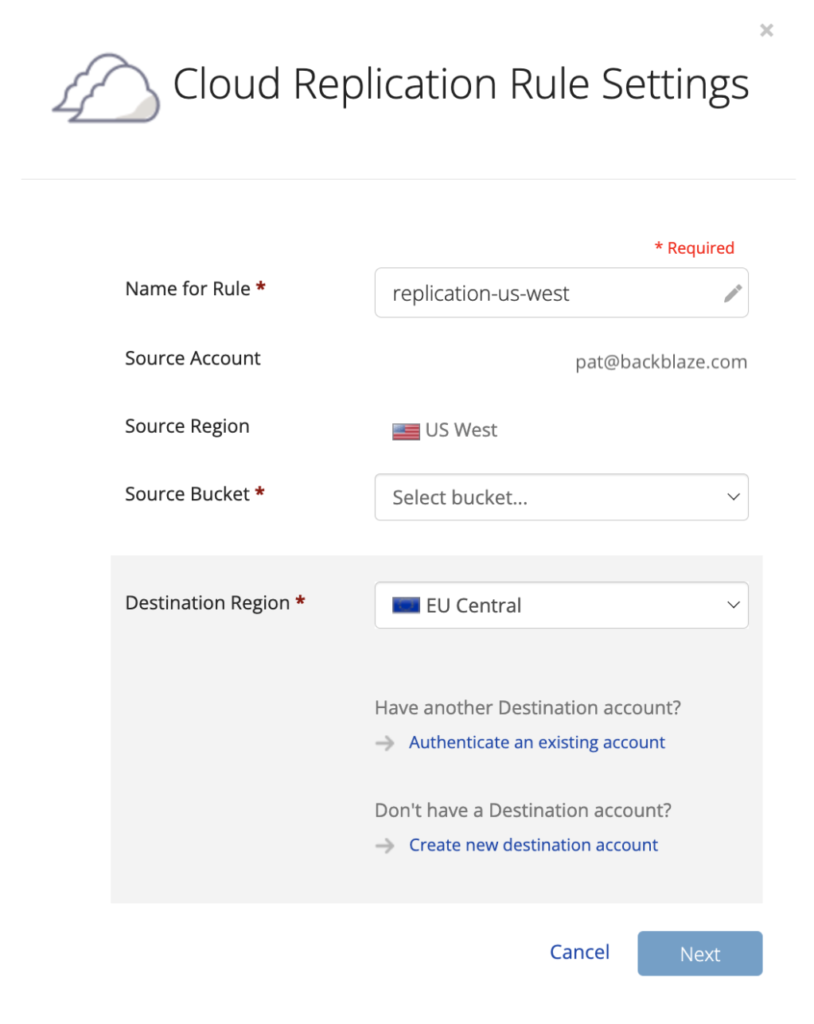
Backblaze Cloud Replication is a new service that allows customers to automatically store to different locations—across regions, across accounts, or in different buckets within the same account. You can set replication rules in a few easy steps.
Once the rules are set on a given bucket, any data uploaded to that bucket will automatically be replicated into the destination bucket you choose.
What Is Cloud Replication Good For?
There are three main reasons you might want to use Cloud Replication:
Data Redundancy: Replicating data for security, compliance, and continuity purposes.
Data Proximity: Bringing data closer to distant teams or customers for faster access.
Replication Between Environments: Replicating data between testing, staging, and production environments when developing applications.
Data Redundancy
Keeping redundant copies of your data is the most common use case for Cloud Replication. Enterprises with comprehensive backup strategies, especially as they are increasingly cloud-based, will likely find Cloud Replication immediately applicable. It can help businesses:
Recover quickly from natural disasters and cybersecurity threats.
Support modern business continuity.
Reduce the risk of data loss and downtime.
Comply with industry or board regulations centered on concentration risk issues.
Meet data residency requirements stemming from regulations like GDPR.
Data redundancy has always been a best practice—the gold standard for backup strategies has long been a 3-2-1 approach. The core principles of 3-2-1—keeping at least three copies of your data, on two different media, with one copy off-site—were originally developed for an on-premises world. They still hold true, and today they are being applied in even more robust ways to an increasingly cloud-based world.
Backblaze’s Cloud Replication helps businesses apply the principles of 3-2-1 within a cloud-first or cloud-dominant infrastructure. By storing to multiple regions and/or multiple buckets in the same region, businesses virtually achieve an “off-site” backup—easily and automatically protecting data from natural disasters, political instability, or even run-of-the-mill compliance headaches.
Data Proximity
If you have teams, customers, or workflows spread around the world, bringing a copy of your data closer to where work gets done can minimize speed-of-light limitations. Especially for media-heavy teams in industries like game development and postproduction, seconds can make the difference in keeping creative teams operating smoothly. And because you can automate replication and use metadata to track accuracy and process, you can remove some manual steps from the process where errors and data loss tend to crop up.
Replication Between Environments
Version control and smoke testing are nothing new, but when you’re controlling versions of large applications or trying to keep track of what’s live and what’s in testing, you might need a tool with more horsepower and options for customization. Backblaze Cloud Replication can serve these needs.
You can easily replicate objects between buckets dedicated for production, testing, or staging if you need to use the same data and maintain the same metadata. This allows you to observe best practices and automate replication between environments.
Want to Learn More About Backblaze Cloud Replication?
Here’s a walk-through of Cloud Replication, including step-by-step instructions for using Cloud Replication via the web UI and the Backblaze B2 Native API.
In late April, thousands of professionals from all corners of the media, entertainment, and technology ecosystem assembled in Las Vegas for the National Association of Broadcasters trade show, better known as the NAB Show. We were delighted to sponsor NAB after its two year hiatus due to COVID-19. Our staff came in blazing hot and ready to hit the tradeshow floor.
One of the stars of the 2022 event was Backblaze partner LucidLink, named a Cloud Computing and Storage category winner in the NAB Show Product of the Year Awards. In this blog post, I’ll explain how to combine LucidLink’s Filespaces product with Backblaze B2 Cloud Storage and media asset management from iconik, another Backblaze partner, to optimize your media production workflow. But first, some context…
How iconik, LucidLink, and Backblaze B2 Fit in a Media Storage Architecture
The media and entertainment industry has always been a natural fit for Backblaze. Some of our first Backblaze Computer Backup customers were creative professionals looking to protect their work, and the launch of Backblaze B2 opened up new options for archiving, backing up, and distributing media assets.
As the media and entertainment industry moved to 4K Ultra HD for digital video recording over the past few years, file sizes ballooned. An hour of high quality 4K video shot at 60 frames per second can require up to one terabyte of storage. Backblaze B2 matches well with today’s media and entertainment storage demands, as customers such as Fortune Media, Complex Networks, and Alton Brown of “Good Eats” fame have discovered.
Alongside Backblaze B2, an ecosystem of tools has emerged to help professionals manage their media assets, including iconik and LucidLink. iconik’s cloud-native media management and collaboration solution gathers and organizes media securely from a wide range of locations, including Backblaze B2. iconik can scan and index content from a Backblaze B2 bucket, creating an asset for each file. An iconik asset can combine a lower resolution proxy with a link to the original full-resolution file in Backblaze B2. For a large part of the process, the production team can work quickly and easily with these proxy files, previewing and selecting clips and editing them into a sequence.
Complementing iconik and B2 Cloud Storage, LucidLink provides a high-performance, cloud-native, network-attached storage (NAS) solution that allows professionals to collaborate on files stored in the cloud almost as if the files were on their local machine. With LucidLink, a production team can work with multi-terabyte 4K resolution video files, making final edits and rendering the finished product at full resolution.
It’s important to understand that the video editing process is non-destructive. The original video files are immutable—they are never altered during the production process. As the production team “edits” a sequence, they are actually creating a series of transformations that are applied to the original videos as the final product is rendered.
You can think of B2 Cloud Storage and LucidLink as tiers in a media storage architecture. Backblaze B2 excels at cost-effective, durable storage of full-resolution video assets through their entire lifetime from acquisition to archive, while LucidLink shines during the later stages of the production process, from when the team transitions to working with the original full-resolution files to the final rendering of the sequence for release.
iconik brings B2 Cloud Storage and LucidLink together; not only can an iconik asset include a proxy and links to copies of the original video in both B2 Cloud Storage and LucidLink, iconik Storage Gateway can copy the original file from Backblaze B2 to LucidLink when full-resolution work commences, and later delete the LucidLink copy at the end of the production process, leaving the original archived in Backblaze B2. All that’s missing is a little orchestration.
The Backblaze B2 Storage Plugin for iconik
The Backblaze B2 Storage Plugin for iconik allows creative professionals to copy files from B2 Cloud Storage to LucidLink, and later delete them from LucidLink, in a couple of mouse clicks. The plugin adds a pair of custom actions to iconik: “Add to LucidLink” and “Remove from LucidLink,” applicable to one or many assets or collections, accessible from the Search page and the Asset/Collection page. You can see them on the lower right of this screenshot:
The user experience could hardly be simpler, but there is a lot going on under the covers.
There are several components involved:
The plugin, deployed as a serverless function. The initial version of the plugin is written in Python for deployment on Google Cloud Functions, but it could easily be adapted for other serverless cloud platforms.
A LucidLink Filespace.
A machine with both the LucidLink client and iconik Storage Gateway installed. The iconik Storage Gateway accesses the LucidLink Filespace as if it were local file storage.
iconik, accessed both by the user via its web interface and by the plugin via the iconik API. iconik is configured with two iconik “storages”, one for Backblaze B2 and one for the iconik Storage Gateway instance.
When the user selects the “Add to LucidLink” custom action, iconik sends an HTTP request, containing the list of selected entities, to the plugin. The plugin calls the iconik API with a request to copy those entities from Backblaze B2 to the iconik Storage Gateway. The gateway writes the files to the LucidLink Filespace, exactly as if it were writing to the local disk, and the LucidLink client sends the files to LucidLink. Now the full-resolution files are available for the production team to access in the Filespace, while the originals remain in B2 Cloud Storage.
Later, when the user selects the “Remove from LucidLink” custom action, iconik sends another HTTP request containing the list of selected entities to the plugin. This time, the plugin has more work to do. Collections can contain other collections as well as assets, so the plugin must access each collection in turn, calling the iconik API for each file in the collection to request that it be deleted from the iconik Storage Gateway. The gateway simply deletes each file from the Filespace, and the LucidLink client relays those operations to LucidLink. Now the files are no longer stored in the Filespace, but the originals remain in B2 Cloud Storage, safely archived for future use.
This short video shows the plugin in action, and walks through the flow in a little more detail:
Deploying the Backblaze B2 Storage Plugin for iconik
Don’t have a Backblaze B2 account? You can get started here, and the first 10GB are on us. We can also set up larger scale trials involving terabytes of storage—enter your details and we’ll get back to you right away.
Customize the Plugin to Your Requirements
You can use the plugin as is, or modify it to your requirements. For example, the plugin is written to be deployed on Google Cloud Functions, but you could adapt it to another serverless cloud platform. Please report any issues with the plugin via the issues tab in the GitHub repository, and feel free to submit contributions via pull requests.
June is Backup Awareness Month and we’re kicking it off with the next installment in our series of guides to help you protect social content across many different platforms. We’re working on developing this list—please comment below if you’d like to see another platform covered.
Some of your most valuable digital assets are memories, scattered across the digital ether. For a lot of us, these mementoes of our meta life are tied up in one of Meta’s most popular apps, WhatsApp. The last group chat you had with old college friends. An inspiring note from a loved one. A funny meme that proves your weird uncle does, in fact, have a sense of humor. They’re all out there, drifting through the cloud.
These are treasured memories, and worth preserving, especially in the always uncertain world online. You might find yourself gravitating towards a new messaging app as the technology changes. You might get locked out of your account. It might even be that your country winds up banning the app. (So far, it’s only happened in places like Cuba and Uganda, and while those were temporary, the app was “temporarily” blocked in China in 2017 and is still blocked. The point being, you never know which way the wind is going to blow).
So obviously, it’s worth it to make sure you have some kind of backup for these treasured memories. Now it’s just a matter of creating those backups, and finding somewhere (or, more accurately, several somewheres) to securely store them.
How to Create Backups of Your WhatsApp Data
Back Up Individual Messages and Group Chats
By default, WhatsApp automatically archives your chats every day onto your device, with the option to back them up to Google Drive. As you’ll see, this is not quite sufficient if you really want to preserve those memories. To create a backup that you can preserve elsewhere, use the following steps:
Tap the three vertical dots within an individual message or group chat.
Tap More, and then Export Chat.
You can then choose whether to export with or without media, with the most recent media being added as attachments.
From here, you can choose how to share the attachments, which will consist of a .txt file as well as individual attachments for each piece of media in the chat.
Here we see it as a step-by-step guide, which also helpfully demonstrates the idiotic conversations the author has with his friends on WhatsApp.
Choose Your Backup Destination
We suggest downloading your backup to your device at this point. This step creates a local backup on your phone. From here, you can either download the attachment onto your computer from that same email, or connect your phone and make a copy from local storage onto your desktop. This will create two copies, but we’re just getting started.
Initiating Backup in 3…2…1…
As with anything you back up, the best strategy to employ is the classic 3-2-1 backup strategy. In essence, this is creating a trio of redundant copies, giving your backups their own backups in case anything should go wrong. Typically, you’ll want two copies stored on two different local devices and a third in the cloud.
Is this a little bit of overkill? Absolutely, and we mean that in the best possible way. You’ll thank us when a spilled cup of coffee doesn’t wipe out some of your favorite WhatsApp chats.
Backup #1: Local Storage (i.e., PC)
If you’ve followed the directions so far, you’ll now have a copy of your chats on your phone as well as on your desktop. This constitutes your first local copy.
Backup #2: Options
For your second local copy, you have a few options:
Flash drive: Your computer is prone to any number of breakdowns, outages, or viruses that a flash drive simply isn’t, providing a safe, secondary, local place to store those all-important chats. As anyone who has ever accidentally sat on, stepped on, lost, or otherwise accidentally mutilated a flash drive can tell you, it’s not the end-all-be-all solution. However, having this redundant safety measure could be the thing that saves you from losing your data forever.
External hard drive: An external hard drive is another good option to house a second copy of your data, and we know a little bit about them—we monitor 203,168 hard drives used to store data in our data centers. If you’re new to using an external hard drive, check out this handy guide.
SSD: Like flash and hard drives, external SSDs are another form of external storage you can use to keep backup copies of your data. If you really want to get into the weeds on external storage, check out our guide on the difference between SSD vs. NVMe vs. M.2 drives.
Backup #3: Cloud Storage
We’ll admit to being a bit biased here, but for true peace of mind that your backups will survive any number of disasters and mishaps, you have to incorporate cloud storage into your 3-2-1 solution. (If for no other reason than without it, you have a 2-1 situation which doesn’t quite have the same ring to it. But believe us, there are plenty of other reasons, mainly so you don’t lose your data when your computer suddenly dies or you drop your flash drive down the sewer.)
If you are one of the millions of extraordinarily clever people who use Backblaze Personal Backup, this might just be the easiest step in the process because it’s all done automatically. Simply by having your WhatsApp backups on your computer, you’ll rest easy knowing that the software is one step ahead of you, storing your chats and online memories safely in the cloud.
If space is limited locally, and you don’t necessarily need the WhatsApp files on your own computer, Backblaze B2 Cloud Storage gives you plenty of space in the cloud to stash them until they’re needed. Paired with local copies elsewhere, you could also use this method to achieve a 3-2-1 strategy without taking up a huge amount of space locally on your machine.
Bonus Pro Tips: Transferring Your WhatsApp Data to a New Phone
While it’s all well and good to have your data securely tucked away using the 3-2-1 strategy, what happens when you get a new phone and want to have easy access through the app to all of your old chats? When that happens, you’re going to be glad you squirreled it away, and thrilled that we’ve outlined step-by-step how to get your new phone up and running with all of your old memories intact.
How to Restore Your Backup to an Android Phone
Restoring your WhatsApp backup to an Android phone takes a few steps. In these steps, we will assume you have reinstalled WhatsApp on your new phone.
Install a file manager app on your Android phone.
Copy the backup file to your Android phone.
Open the file manager app.
Copy the backup file to WhatsApp > Databases.
Remember to restore the most recently created backup file to the device’s Databases folder.
Restore your WhatsApp backup from local storage.
How to Restore Your Backup to an iPhone
The restore process for WhatsApp on an iPhone is similar. We will assume you do not have WhatsApp installed with the Android steps.
Connect your iPhone to your computer.
Open iTunes.
Back up your iPhone using iTunes. This step will create a WhatsApp backup (along with your other phone data) to your computer.
Restore data to your iPhone using iTunes. Restoring your WhatsApp data to your iPhone is simple. Connect your iPhone to the computer where you ran the backup. Open iTunes and use the “restore a backup” feature.
Keep Your WhatsApp Archive Safe
When it comes to your digital assets, backups matter. Even the most mundane conversations you engage in on WhatsApp now might end up being a treasured memory of old friends later on. Preserving them is important, and if you’ve followed these steps and backed up your memories to your computer and to the cloud, you’ll have those memories available at a moment’s notice wherever you are.
Backblaze Cloud Replication—currently in private beta—enables Backblaze customers to store files in multiple regions, or create multiple copies of files in one region, across the Backblaze Storage Cloud. This capability, as we explained in an earlier blog post, allows you to create geographically separate copies of data for compliance and continuity, keep data closer to its consumers, or maintain a live copy of production data for testing and staging. Today we’ll look at how you can get started with Cloud Replication, so you’ll be ready for its release, likely early next month.
Backblaze Cloud Replication: The Basics
Backblaze B2 Cloud Storage organizes data into files (equivalent to Amazon S3’s objects) in buckets. Very simply, Cloud Replication allows you to create rules that control replication of files from a source bucket to a destination bucket. The source and destination buckets can be in the same or different accounts, or in the same or different regions.
Here’s a simple example: Suppose I want to replicate files from my-production-bucket to my-staging-bucket in the same account, so I can run acceptance tests on an application with real-life data. Using either the Backblaze web interface or the B2 Native API, I would simply create a Cloud Replication rule specifying the source and destination buckets in my account. Let’s walk through a couple of examples in each interface.
Cloud Replication via the Web Interface
Log in to the account containing the source bucket for your replication rule. Note that the account must have a payment method configured to participate in replication. Cloud Replication will be accessible via a new item in the B2 Cloud Storage menu on the left of the web interface:
Clicking Cloud Replication opens a new page in the web interface:
Click Replicate Your Data to create a new replication rule:
Configuring Replication Within the Same Account
To implement the simple rule, “replicate files from my-production-bucket to my-staging-bucket in the same account,” all you need to do is select the source bucket, set the destination region the same as the source region, and select or create the destination bucket:
Configuring Replication to a Different Account
To replicate data via the web interface to a different account, you must be able to log in to the destination account. Click Authenticate an existing account to log in. Note that the destination account must be enabled for Backblaze B2 and, again, must have a payment method configured:
After authenticating, you must select a bucket in the destination account. The process is the same whether the destination account is in the same or a different region:
Note that, currently, you may configure a bucket as a source in a maximum of two replication rules. A bucket can be configured as a destination in any number of rules.
Once you’ve created the rule, it is accessible via the web interface. You can pause a running rule, run a paused rule, or delete the rule altogether:
Replicating Data
Once you have created the replication rule, you can manipulate files in the source bucket as you normally would. By default, existing files in the source bucket will be copied to the destination bucket. New files, and new versions of existing files, in the source bucket will be replicated regardless of whether they are created via the Backblaze S3 Compatible API, the B2 Native API, or the Backblaze web interface. Note that the replication engine runs on a distributed system, so the time to complete replication is based on the number of other replication jobs scheduled, the number of files to replicate, and the size of the files to replicate.
Checking Replication Status
Click on a source or destination file in the web interface to see its details page. The file’s replication status is at the bottom of the list of attributes:
There are four possible values of replication status:
pending: The file is in the process of being replicated. If there are two rules, at least one of the rules is processing. (Reminder: Currently, you may configure a bucket as a source in a maximum of two replication rules.) Check again later to see if it has left this status.
completed: This status represents a successful replication. If two rules are configured, both rules have completed successfully.
failed: A non-recoverable error has occurred, such as insufficient permissions to write the file into the destination bucket. The system will not try again to process this file. If two rules are configured, at least one has failed.
replica: This file was created by the replication process. Note that replica files cannot be used as the source for further replication.
Cloud Replication and Application Keys
There’s one more detail to examine in the web interface before we move on to the API. Creating a replication rule creates up to two Application Keys; one with read permissions for the source bucket, if the source bucket is not already associated with an Application Key, and one with write permissions for the destination bucket.
The keys are visible in the App Keys page of the web interface:
You don’t need to worry about these keys if you are using the web interface, but it is useful to see how the pieces fit together if you are planning to go on to use the B2 Native API to configure Cloud Replication.
This short video walks you through setting up Cloud Replication in the web interface:
Cloud Replication via the B2 Native API
Configuring cloud replication in the web interface is quick and easy for a single rule, but quickly becomes burdensome if you have to set up multiple replication rules. The B2 Native API allows you to programmatically create replication rules, enabling automation and providing access to two features not currently accessible via the web interface: setting a prefix to constrain the set of files to be replicated and excluding existing files from the replication rule.
Configuring Replication
To create a replication rule, you must include replicationConfiguration when you call b2_create_bucket or b2_update_bucket. The source bucket’s replicationConfiguration must contain asReplicationSource, and the destination bucket’s replicationConfiguration must contain asReplicationDestination. Note that both can be present where a given bucket is the source in one replication rule and the destination in another.
Let’s illustrate the process with a concrete example. Let’s say you want to replicate newly created files with the prefix master_data/, and new versions of those files, from a bucket in the U.S. West region to one in the EU Central region so that you have geographically separate copies of that data. You don’t want to replicate any files that already exist in the source bucket.
Assuming the buckets already exist, you would first create a pair of Application Keys: one in the source account, with read permissions for the source bucket, and another in the destination account, with write permissions for the destination bucket.
Next, call b2_update_bucket with the following message body to configure the source bucket:
Note that the “file prefix” and “include existing buckets” configuration is not currently visible in the web interface.
Viewing Replication Rules
If you are planning to use the B2 Native API to set up replication rules, it’s a good idea to experiment with the web interface first and then call b2_list_buckets to examine the replicationConfiguration property.
Here’s an extract of the configuration of a bucket that is both a source and destination:
To see the replication status of a file, including whether the file is itself a replica, call b2_get_file_info and examine the replicationStatus field. For example, looking at the same file as in the web interface section above:
This short video runs through the various API calls:
How Much Will This Cost?
The majority of fees for Cloud Replication are identical to standard B2 Cloud Storage billing: You pay for the total data you store, replication (download) fees, and for any related transaction fees. For details regarding billing, click here.
The replication fee is only incurred between cross-regional accounts. For example, a source in the U.S. West and a destination in EU Central would incur replication fees, which are priced identically to our standard download fee. If the replication rule is created within a region—for example, both source and destination are located in our U.S. West region—there is no replication fee.
How to Start Replicating
Watch the Backblaze Blog for an announcement when we make Backblaze Cloud Replication generally available (GA), likely early next month. As mentioned above, you will need to set up a payment method on accounts included in replication rules. If you don’t yet have a Backblaze B2 account, or you need to set up a Backblaze B2 account in a different region from your existing account, sign up here and remember to select the region from the dropdown before hitting “Sign Up for Backblaze B2.”
Our team had some fun experimenting with Python 3.9-nogil, the results of which will be reported in an upcoming blog post. In the meantime, we saw an opportunity to dive deeper into the history of the global interpreter lock (GIL), including why it makes Python so easy to integrate with and the tradeoff between ease and performance.
We reached out to Barry Warsaw, a preeminent Python developer and contributor, because we could think of no one better to break down the evolution of the GIL for us. Barry is a longtime Python core developer, former release manager and steering council member, and PSF Fellow. He was project lead for the GNU Mailman mailing list manager. Barry, along with contributor Paweł Polewicz, a backend software developer and longtime Python user, went above and beyond anything we could have imagined, developing this comprehensive deep dive into the GIL and its evolution over the years. Thanks also go to Larry Hastings for his review and feedback.
If Python’s GIL is something you are curious about, we’d love to hear your thoughts in the comments. We’ll let Barry take it from here.
—The Editors
First Things First: What Is the GIL?
The Python GIL, or Global Interpreter Lock, is a mechanism in CPython (the most common implementation of Python) that serves to serialize operations involving the Python bytecode interpreter, and provides useful safety guarantees for internal object and interpreter state. While providing many benefits, as the discussion below will show, the GIL also prevents CPython from achieving full multicore performance.
In simplest terms, the GIL is a lock (or mutex) that allows only a single operating system thread to run the central Python bytecode interpreter loop. Normally, when multiple threads can access shared state, such as global interpreter or object internal state, a programmer would need to implement fine grained locks to prevent one thread from stomping on the state set by another thread. The GIL removes the need for these fine grained locks because it imposes a global lock that prevents multiple threads from mutating this state at the same time.
In this post, I’ll explore the pros and cons of the GIL, and the many efforts over the years to remove it, including some recent exciting developments.
Humble Beginnings
Back in November 1994, I was invited to a little gathering of programming language enthusiasts to meet the Dutch inventor of a relatively new and little known object-oriented language. This three day workshop was organized by my friends and former colleagues at the National Institute of Standards and Technology (NIST) in Gaithersburg, MD. I came with extensive experience in languages from C, C++, FORTH, LISP, Perl, TCL, and Objective-C and enjoyed learning and playing with new programming languages.
Of course, the Dutch inventor was Guido van Rossum and his little language was Python. I think most of us in attendance knew there was something special about Python and Guido, but it probably would have shocked us to know that Python would even be around almost 30 years later, let alone have the scope, impact, or popularity it enjoys today. For me personally, it was a life-changing moment.
A few years ago, I gave a talk at BayPiggies that took a retrospective look at the evolution of Python from version 1.1 in October 1994 (just before the abovementioned workshop), through the Python 2 series, and up to Python 3.7, the newest release of the language at the time. In many ways, Python 1.1 would be recognizable by today’s modern Python programmer. In other ways, you’d wonder how Python was ever usable without features that were introduced in the intervening years.
Can you imagine not having the tuple() or list() built-ins, or docstrings, or class exceptions, keyword arguments, *args, **kws, packages, or even different operators for assignment and equality tests? It was fun to go back through all those old changelogs and remember what it was like as each of the features we now take for granted were introduced, often in those early days with absolutely no regard for backward compatibility.
I managed to find the agenda for that first Python workshop, and one of the items to be discussed was “Improving the efficiency of Python (e.g., by using a different garbage collection scheme).” I don’t remember any of the details of that discussion, but even then, and from its start, Python employed a reference counting memory management scheme (the cyclic garbage detector being many years away yet). Reference counting is a simple way of managing your objects in a higher level language where you don’t directly allocate or free your memory. One of Guido’s early guiding principles for Python, and which has served Python well over the years, is to keep it as simple as possible while still being effective, useful, and fun.
The Basics of Reference Counting
Reference counting is simple; as it says on the tin, the interpreter keeps a counter that tracks every reference to an object. For example, binding an object to a variable (such as by an assignment) increases that object’s reference count by one. Appending an object to a list also increases its reference count by one. Removing an object from the list decreases that object’s reference count by one. When a variable goes out of scope, the reference count of the object the variable is bound to is decreased by one again. We call this reference count the object’s “refcount” and these two operations “incref” and “decref” respectively.
When an object’s refcount goes to zero it means there are no more live references to the object, so it can be safely freed (and finalized) because nothing in the program can reach that object anymore1. As these objects are deallocated, any references to objects they hold are also decref’d, and so on. Refcounting gives the Python interpreter a very simple mechanism for freeing garbage and more importantly, it allows for humans to reason about Python’s memory management, both from the point of view of the Python programmer, and from the vantage point of the C extension writer, who doesn’t have the luxury of all that reference counting happening automatically.
This is a crucial point: When we talk about “Python” we generally mean “CPython,” the implementation of the runtime written in C2. The C programmer working on the CPython runtime, and the module author writing extensions for Python in C (for performance or to integrate with some system library) does have to worry about all the nitty gritty details of when to incref or decref an object. Get this wrong and your extension can leak memory or double free an object, either way wreaking havoc on your system. Fortunately, Python has clear rules to follow and good documentation, but it can still be difficult to get refcounting right in complex situations, such as when proper error handling leads to multiple exit paths from a function.
Here’s Where the GIL Comes In: Reference Counting and Concurrency
One of the key simplifying rules is that the programmer doesn’t have to worry about concurrency when managing Python reference counting. Think about the situation where you have multiple threads, each inserting and removing a Python object from a collection such as a list or dictionary. Because those threads may run at any time and in any order, you would normally have to be extremely defensive in how you incref and decref those objects, and it would be way too easy to get this wrong. You could crash Python, or worse, if you didn’t implement the proper locks around your incref and decref operations. Having to worry about all that would make your C code very complicated and likely pretty error prone. The CPython implementation also has global and static variables which are vulnerable to race conditions3.
In keeping with Python’s principles, in 1992, when Guido first began to implement threading support in Python, he utilized a simple mechanism to keep this manageable for a wide range of Python programmers and extension authors: a Global Interpreter Lock—the infamous GIL!
Because the Python interpreter itself is not thread-safe, the GIL allows only one thread to execute Python bytecode at a time, and thus serializes all access to Python objects. So, barring bugs, it is impossible for multiple threads to stomp on each other’s reference count operations. There are C API functions to release and acquire the GIL around blocking I/O or compute intensive functions that don’t touch Python objects, and these provide boundaries for the interpreter to switch to other Python-executing threads.
Two threads incrementing an object reference counter.
Thus, we gain significant C implementation simplicity at the expense of some parallelism. Modern Python has many ways to work around this limitation, from asyncio to subprocesses and multiprocessing, which all work fine if they align with your requirements. Python also surfaces operating system threading primitives, but these can’t take full advantage of multicore operations because of the GIL.
Advantages of the GIL
Back in the early days of Python, we didn’t have the prevalence of multicore processors, so this all worked fine. These days, modern programming languages are more multicore friendly, and the GIL gets a bad rap. Before we explore the work to remove the GIL, it’s important to understand just how much benefit and mileage Python has gotten out of it.
One important aspect of the GIL is that it simplifies the programming model for extension module authors. When writing extension modules in C, C++, or any other low-level language with access to the internals of the Python interpreter, extension authors would normally have to ensure that there are no race conditions that could corrupt the internal state of Python objects. Concurrency is hard to get right, especially so in low-level languages, and one mistake can corrupt the entire state of the interpreter4. For an extension author, it can already be challenging to ensure all your increfs and decrefs are properly balanced, especially for any branches, early exits, or error conditions, and this would be monumentally more difficult if the author also had to contend with concurrent execution. The GIL provides an important simplifying model of object access (including refcount manipulation) because it ensures that only one thread of execution can mutate Python objects at a time5.
There are important performance benefits of the GIL for single-threaded operations as well. Without the GIL, Python would need some other way of ensuring that object refcounts are safe from corruption due to, for example, race conditions between threads, such as when adding or removing objects from any mutable collection (lists, dictionaries, sets) that are shared across threads. These techniques can be very expensive as some of the experiments described later showed. Ensuring that Python interpreter is safe for multithreaded use cases degrades its performance for the single-threaded use case. The GIL’s low performance overhead really shines for single-threaded operations, including I/O-multiplexed programs where libraries like asyncio are used, and this is still a predominant use of Python. Finer-grained locks also increase the chances of deadlocks, which isn’t possible with the GIL.
Also, one of the reasons Python is so popular today is that it had so many extensions written for it over the years. One of the reasons there are so many powerful extension modules, whether we like to admit it or not, is that the GIL makes those extensions easier to write.
And yet, Python programmers have long dreamed of being able to run multithreaded Python programs to take full advantage of all the cores available on modern computing platforms. Even today’s watches and phones have multiple cores, whereas in Python’s early days, multicore systems were rare. Here we are 30 or so years later, and while the GIL has served Python well, in order to take advantage of what clearly seems to be more than a passing fad, Python’s GIL often gets in the way of true high-performance multithreaded concurrency.
Attempting to Remove the GIL
Two threads incrementing object reference counter without GIL protection.
Over the years, many attempts have been made to remove the GIL.
1999: Greg Stein’s “Free Threading”
Circa 1999, Greg Stein’s “free threading” work was one of the first (successful!) attempts to remove the GIL. It made the locks much more fine-grained and moved global variables inside the interpreter into a structure, which we actually still use today. It had the unfortunate side effect however, of making your Python code multiple times slower. Thus, while the free threading work was a great experiment, it was far too impractical to adopt.
2015: Larry Hasting’s Gilectomy
Years later (circa 2015), Larry Hasting’s wonderfully named Gilectomy project tried a different approach to remove the GIL. In Larry’s PyCon 2016 talk, he discusses four technical considerations that must be addressed when removing the GIL:
Reference Counting: Race conditions on updating the refcount between multiple threads as described previously.
Globals and Statics: These include interpreter global housekeeping variables, and shared singleton objects. Much work has been done over the years to move these globals into per-thread structures. Eric Snow’s work on multiple interpreters (aka “subinterpreters”) has also made a lot of progress on isolating these variables into structures that represent an interpreter “instance” where theoretically each instance could run on a separate core. There are even proposals for making some of those shared singleton objects immortal, such that reference counting race conditions would have no effect on the lifetime of those objects. An interesting related proposal would move the GIL into a per-interpreter data structure, which could lead to the ability to run an isolated interpreter instance per core (with limitations).
C Extensions: Keep in mind that there is a huge ecosystem of C extension modules, and much of Python’s power comes from these extension modules, of which NumPy is a hugely popular example. These extensions have never had to worry about parallelism or re-entrancy because they’ve always relied on the GIL to serialize their operations. At a minimum, a GIL-less Python will require recompilation of extension modules, and some or all may require some level of source code modifications as well. These changes may include protecting internal (non-Python) data structures for concurrency, using functional APIs for refcount modification instead of accessing refcount fields directly, not assuming that Python collections are stable over iteration, etc.
Atomicity: Operations such as adding or deleting objects from Python collections such as lists and dictionaries actually involve a number of steps internally. To the Python developer, these all appear to be atomic operations, and in fact they are, thanks to the GIL.
Larry also identifies what he calls three “political” considerations, but which I think are more in the realm of the social contract between Python developers and Python users:
Removing the GIL should not hurt performance for single-threaded or I/O-bound multithreaded code.
We can’t break existing C extensions as described above6.
Don’t let GIL removal make the CPython interpreter too complicated or difficult to understand. One of Guido’s guiding principles, and a subtle reason for Python’s huge success, is that even with complicated features such as exception handling, asyncio, generators, etc. Python’s C core is still relatively easy to learn and understand. This makes it easy for new contributors to engage with Python core development, an absolutely essential quality if you want your language to thrive and grow for its next 30 years as much as it has for its previous 30.
Larry’s Gilectomy work is quite impressive, and I highly recommend watching any of his PyCon talks for deep technical dives, served with a healthy dose of humor. As Larry points out, removing the GIL isn’t actually the hard part. The hard part is doing so while adhering to the above mentioned technical and social constraints, retaining Python’s single-threaded performance, and building a mechanism that scales with the number of cores. This latter constraint is important because if we’re going to enable multicore operations, we want to ensure that Python’s performance doesn’t hit a plateau at four or eight cores.
So, why did the Gilectomy branch fail (measured in units of “didn’t get adopted by CPython”)? For the most part, the performance and complexity constraints couldn’t be met. One of the biggest hits on performance wasn’t actually lock contention on objects. The early Gilectomy work relied on atomic increment and decrement CPU instructions, which destroyed cache consistency, and caused a high overhead of communication on the intercore bus to ensure atomicity.
Intercore atomic incr/decr communication.
Later, Larry experimented with a technique borrowed from garbage collection research called “buffered reference counting,” essentially a transaction log for refcount changes. However, contention on transaction logs required further modifications to segregate logs by threads and by increment and decrement operations. This led to non-realtime garbage collection events on refcounts reaching zero, which broke features such as Python’s weakref objects.
Interestingly, another hotspot turned out to be what’s called “obmalloc,” which is a small block allocator that improves performance over just using system malloc for everything. We’ll touch on this again later. Solving all these knock-on effects (such as repairing the cyclic garbage collector) led to increased complexity of the implementation, making the chance that it would ever get merged into Python highly unlikely.
Before we leave this topic to look at some new and exciting work, let’s return briefly to Eric Snow’s work on multiple interpreters (aka subinterpreters). PEP 554 proposes to add a new standard library module called “interpreters” which would expose the underlying work that Eric has been doing to isolate interpreter state out of global variables internal to CPython. One such global state is, of course, the GIL. With or without Python-level access to these features, if the GIL could be moved from global state to per-interpreter state, each interpreter instance could theoretically run concurrently with the others. You could therefore attach a different interpreter instance to each thread, and these could run Python code in parallel. This is definitely a work in progress and it’s unclear whether multiple interpreters will deliver on its promises of this kind of limited concurrency. I say “limited” because without full GIL removal, there is significant complexity in sharing Python objects between interpreters, which would almost certainly be necessary. Issues such as ownership (which thread owns which object) and safe mutability would need to be resolved. PEP 554 proposes some solutions to these problems and more, so we’ll have to keep an eye on this work. But even multiple interpreters don’t provide the same true concurrency that full GIL removal promises.
The Future of the GIL: Where Do We Go From Here?
And now we come full-circle, because Python’s popularity, vast influence, and reach is also one of the reasons why it still seems impossible to remove the GIL while retaining single-threaded performance and not breaking the entire ecosystem of extension modules.
Yet here we are with PyCon 2022 just concluded, and there is renewed excitement for Sam Gross’ “nogil” work, which holds the promise of a performant, GIL-less CPython with minimal backward incompatibilities at both the Python and C layers. While some performance regressions are inevitable, Sam’s work also utilizes a number of clever techniques to claw these regressions back through other internal performance improvements.
Two threads incrementing object reference counter on Sam Gross’ “nogil” branch.
With these improvements as well as the work that Guido’s team at Microsoft is doing with its Faster CPython project, there is renewed hope and excitement that the GIL can be removed while retaining or even improving overall performance, and not giving up on backward compatibility. It will clearly be a multi-year effort.
Sam’s nogil project aims to support a concurrency sweet spot. It promises that data race conditions will never corrupt Python’s virtual machine, but it leaves the integrity of user-level data structures to the programmer. Concurrency is hard, and many Python programs and libraries benefit from the implicit GIL constraints, but solving this is a harder problem outside the scope of the nogil project. Data science applications are one big potential domain to benefit from true multiprocessor enabled concurrency in Python.
There are a number of techniques that the nogil project utilizes to remove the GIL bottleneck. As mentioned, the project also employs a number of other virtual machine improvements to regain some of the performance inevitably lost by removing the GIL. I won’t go into too much detail about these improvements, but it’s helpful to note that where these are independent of nogil, they can and are being investigated along with other work Guido’s team is doing to improve the overall performance of CPython.
Python 3.11 recently entered beta (and thus feature freeze), and with it we’ll see significant performance improvements, which no doubt will continue in future Python releases. When and if nogil is adopted, some of those performance gains may regress to support nogil. Whether and how this will be a good trade-off will be an interesting point of analysis and debate in the coming years. In Sam’s original paper, he proposes a runtime switch to choose between nogil and normal GIL operation, however this was discussed at the PyCon 2022 Language Summit, and the consensus was that this wouldn’t be practical. Thus, as the nogil experiment moves forward, it will be enabled by a compile-time switch.
At a high level, the removal of the GIL is afforded by changes in three areas: the memory allocator, reference counting, and concurrent collection protections. Each of these are deep topics on their own, so we’ll only be able to touch on them briefly.
nogil Part 1: Memory Allocators
Because everything in Python is an object, and most objects are dynamically allocated on the heap, the CPython interpreter implements several levels of memory allocators, and provides C API functions for allocating and freeing memory. This allows it to efficiently allocate blocks of raw memory from the operating system, and to subdivide and manage those blocks based on the type of objects being placed into them. For example, integers have different memory requirements than dictionaries, so having object-specific memory managers for these (and other) types of objects makes memory management inside the interpreter much more efficient.
CPython also employs a small object allocator, called pymalloc, which improves performance for allocating and freeing objects smaller than or equal to 512 bytes. This only touches on the complexities of memory management inside the interpreter. The point of all this complexity is to enable more efficient object creation and destruction, but it also allows for features like memory allocation debugging and custom memory allocators.
The nogil works takes advantage of this pluggability to utilize a general purpose, highly efficient, thread-safe memory allocator developed by Daan Leijen at Microsoft called mimalloc. mimalloc itself is worthy of an in-depth look, but for our purposes it’s enough to know that the mimalloc design is extremely well tuned to efficient and thread-safe allocation of memory blocks. The nogil project utilizes these structures for the implementation of dictionaries and other collection types which minimize the need for locks on non-mutating access, as well as managing garbage collected objects7 with minimal bookkeeping. mimalloc has also been highly tuned for performance and thread-safety.
nogil Part 2: Reference Counting
nogil also makes several changes to reference counting, although it does so in a clever way that minimizes changes to the Limited C API, but does not preserve the stable ABI. This means that while extension modules must be recompiled, their source code may not require modification, outside of a few known corner cases8.
One very promising idea is to make some objects effectively immortal, which I touched on earlier. True, False, None and some other objects in practice never actually see their refcounts go to zero, and so they stay alive for the entire lifetime of the Python process. By utilizing the least significant bits of the object’s reference count field for bookkeeping, nogil can make the refcounting macros no-op for these objects, thus avoiding all contention across threads for these fields.
nogil uses a form of biased reference counting to split an object’s refcount into two buckets. For refcount changes in the thread that owns the object, these “local” changes can be made by the more efficient conventional (non-atomic) forms. For changing the refcount of objects in a different thread, an atomic operation is necessary for safe concurrent modification of a “shared” refcount. The thread that owns the object can then combine this local and shared refcount for garbage collection purposes, and it can give up ownership when its local refcount goes to zero. This is performant when most object accesses are local to the owning thread, which is generally the case. nogil’s biased reference counting scheme can utilize mimalloc’s memory pools to efficiently keep track of the owning threads.
However, some objects are typically owned by multiple threads and are not immortal, and for these types of objects (e.g., functions, modules), a deferred reference counting scheme is employed. Incref and decref act as normal for these objects, but when the interpreter loads these objects onto its internal stack, the refcounts are not modified. The utility of this technique is limited to objects that are only deallocated during garbage collection because they are typically involved in reference cycles.
The garbage collector is also modified to ensure that it only runs at safe boundary points, such as a bytecode execution boundary. The current nogil implementation of garbage collection is single-threaded and stops the world, so it is thread-safe. It repurposes some of the existing C API functions to ensure that it doesn’t wait on threads that are blocked on I/O.
nogil Part 3: Concurrent Collection Protections
The third high-level technique that nogil uses to enable concurrency is to implement an efficient algorithm for locking container objects, such as dictionaries and lists, when mutating them. To maintain thread-safety, there’s just no way around employing locks for this. However, nogil optimizes for objects that are primarily modified in a single thread, and it admits that objects which are frequently and concurrently modified may need a different design.
Sam’s nogil paper goes into considerable detail about the locking algorithm, but at a high level it relies on container versioning (where every modification to a container bumps a “version” counter so the various read accesses can know whether the container has been modified between distinct reads or not), biased reference counting, and various mimalloc features to optimize for fast track, single-threaded, no modification reads while amortizing the cost of locking for writes against the other expensive operations a typical container write operation imposes.
The Last Word and Some Predictions
Sam Gross’ nogil project is impressive. He’s managed to satisfy most of the difficult constraints that have thwarted previous attempts at removing the GIL, including minimizing as much as possible the impact on single-threaded performance (and trading general interpreter performance improvements for the cost of removing the GIL), maintaining (mostly) Python’s C API backward compatibility to not force changes on the entire extension module ecosystem, and all the while (Despite the length of this article!) preserving the readability and comprehensibility of the CPython interpreter.
You’ve no doubt noticed that the rabbit hole goes pretty deep, and we’ve only explored some of the tunnels in this particular burrow. Fortunately, Python’s semantics and CPython’s implementation has been well documented over its 30 year life, so there are plenty of opportunities for self-exploration…and contributions! It will take sustained engagement through careful and incremental steps to bring these ideas to fruition. The future certainly is exciting.
If I had to guess, I would say that we’ll see features like multiple interpreters provide some concurrency value in the next release or so, with GIL removal five years (and thus five releases) or more away. However many of the techniques described here are already being experimented with and may show up earlier. Python 3.11 will have many noticeable performance improvements, with plenty of room for additional performance work in future releases. These will give the nogil work room to continue its experimentation at true multicore performance.
For a language and interpreter that has gone from a small group of lucky and prescient enthusiasts to a worldwide top-tier programming language, I think there is more excitement and optimism for Python’s future than ever. And that’s not even talking about game changers such as PyScript.
Stay tuned for a post that introduces the performance experiments the Backblaze team has done with Python 3.9-nogil and Backblaze B2 Cloud Storage. Have you experimented with Python 3.9-nogil? Let us know in the comments.
Barry Warsaw
Barry has been a Python core developer since 1994 and is listed as the first non-Dutch contributor to Python. He worked with Python’s inventor, Guido van Rossum, at CNRI when Guido, and Python development, moved from the Netherlands to the USA. He has been a Python release manager and steering council member, created and named the Python Enhancement (PEP) process, and is involved in Python development to this day. He was the project leader for GNU Mailman, and for a while maintained Jython, the implementation of Python built on the JVM. He is currently a senior staff engineer at LinkedIn, a semiprofessional bass player, and tai chi enthusiast. All opinions and commentary expressed in this article are his own.
Pawel has been a backend developer since 2002. He built the largest e-radio station on the planet in 2006-2007, worked as a QA manager for six years, and finally, started Reef Technologies, a software house highly specialized in building Python backends for startups.
Reference cycles are not only possible but surprisingly common, and these can keep graphs of unreachable objects alive indefinitely. Python 2.0 added a generational cyclic garbage collector to handle these cases. The details are tricky and worthy of an article in its own right.
CPython is also called the “reference implementation” because new features show up there first, even though they are defined for the generic “Python language.” It’s also the most popular implementation, and typically what people think of when they say “Python.”
Much work has been done over the years to reduce these as much as possible.
It’s even worse than this implies. Debugging concurrency problems is notoriously difficult because the conditions that lead to the bug are nearly impossible to reproduce, and few tools exist to help.
Instrumenting concurrent code to try to capture the behavior can introduce subtle timing differences that hide the problem. The industry has even coined the term, “Heisenbug,” to describe the complexity of this class of bug.
Some extension modules also use the GIL as a conveniently available mutex to protect concurrent access to their own, non-Python resources.
It doesn’t seem possible to completely satisfy this constraint in any attempt to remove the GIL.
I.e., the aforementioned cyclic reference garbage collector.
Such as when the extension module peeks and pokes inside CPython data structures directly or via various macros, instead of using the C API’s functional interfaces.
They say the older you get, the more you become your parents. It’s so true, Progressive Insurance built an entire marketing campaign around it. (Forcing food on your family? Guilty.) But when it comes to backups, generational copies are a good thing. In fact, there’s a widely-used backup approach based on the idea—grandfather-father-son (GFS) backups.
In this post, we’ll explain what GFS is and how GFS works, we’ll share an example GFS backup plan, and we’ll show you how you can use GFS to organize your backup approach.
What Are Grandfather-Father-Son Backups?
Whether you’re setting up your first cloud backup or researching how to enhance your data security practices, chances are you’ve already got the basics figured out, like using at least a 3-2-1 backup strategy, if not a 3-2-1-1-0 or a 4-3-2. You’ve realized you need at least three total copies of your data, two of which are local but on different media, and one copy stored off-site. The next part of your strategy is to consider how often to perform full backups, with the assumption that you’ll fill the gap between full backups with incremental (or differential) backups.
One way to simplify your decision-making around backup strategy, including when to perform full vs. incremental backups, is to follow the GFS backup scheme. GFS provides recommended, but flexible, rotation cycles for full and incremental backups and has the added benefit of providing layers of data protection in a manageable framework.
Refresher: Full vs. Incremental vs. Differential vs. Synthetic Backups
There are four different types of backups: full, incremental, synthetic full, and differential. And choosing the right mix of types helps you maximize efficiency versus simply performing full backups all the time and monopolizing bandwidth and storage space. Here’s a quick refresher on each type:
Full backups: A complete copy of your data.
Incremental backups: A copy of data that has changed or has been added since your last full backup or since the last incremental backup.
Synthetic full backups: A synthesized “full” backup copy created from the full backup you have stored in the cloud plus your subsequent incremental backups. Synthetic full backups are much faster than full backups.
Differential backups: A specialized type of backups popular for database applications like Microsoft SQL but not used frequently otherwise. Differential backups copy all changes since the last full backup every time (versus incrementals which only contain changes or additions since the last incremental). As you make changes to your data set, your differential backup grows.
Check out our complete guide on the difference between full, incremental, synthetic full, and differential backups here.
How Do GFS Backups Work?
In the traditional GFS approach, a full backup is completed on the same day of each month (for example, the last day of each month or the fourth Friday of each month—however you want to define it). This is the “grandfather” cycle. It’s best practice to store this backup off-site or in the cloud. This also helps satisfy the off-site requirement of a 3-2-1 strategy.
Next, another full backup is set to run on a more frequent basis, like weekly. Again, you can define when exactly this full backup should take place, keeping in mind your business’s bandwidth requirements. (Because full backups will most definitely tie up your network for a while!) This is the “father” cycle, and, ideally, your backup should be stored locally and/or in hot cloud storage, like Backblaze B2 Cloud Storage, where it can be quickly and easily accessed if needed.
Last, plan to cover your bases with daily incremental backups. These are the “son” backups, and they should be stored in the same location as your “father” backups.
GFS Backups: An Example
In the example month shown below, the grandfather backup is completed on the last day of each month. Father full backups run every Sunday, and incremental son backups run Monday through Saturday.
It’s important to note that the daily-weekly-monthly cadence is a common approach, but you could perform your incremental son backups even more often than daily (Like hourly!) or you could set your grandfather backups to run yearly instead of monthly. Some choose to run grandfather backups monthly and “great-grandfather” backups yearly. Essentially, you just want to create three regular backup cycles (one full backup to off-site storage; one full backup to local or hot storage; and incremental backups to fill the gaps) with your grandfather full backup cycle being performed less often than your father full backup cycle.
How Long Should You Retain GFS Backups?
Last, it’s important to also consider your retention policy for each backup cycle. In other words, how long do you want to keep your monthly grandfather backups, in case you need to restore data from one? How long do you want to keep your father and son backups? Are you in an industry that has strict data retention requirements?
You’ll want to think about how to balance regulatory requirements with storage costs. By the way, you might find us a little biased towards Backblaze B2 Cloud Storage because, at $5/TB/month, you can afford to keep your backups in quickly accessible hot storage and keep them archived for as long as you need without worrying about an excessive cloud storage bill.
Ultimately, you’ll find that grandfather-father-son is an organized approach to creating and retaining full and incremental backups. It takes some planning to set up but is fairly straightforward to follow once you have a system in place. You have multiple fallback options in case your business is impacted by ransomware or a natural disaster, and you still have the flexibility to set backup cycles that meet your business needs and storage requirements.
Ready to Get Started With GFS Backups and Backblaze B2?
Check out our Business Backup solutions and safeguard your GFS backups in the industry’s leading independent storage cloud.
Developers integrating applications and solutions with Backblaze B2 can use the same technique to solve a wide variety of use cases. As an example, in this blog post, I’ll explain how you can use that same Cloudflare Worker to trigger a serverless function at our partner Rising Cloud that automatically creates thumbnails as images are uploaded to a Backblaze B2 bucket, without incurring any egress fees for retrieving the full-size images.
What is Rising Cloud?
Rising Cloud hosts customer applications on a cloud platform that it describes as Intelligent-Workloads-as-a-Service. You package your application as a Linux executable or a Docker-style container, and Rising Cloud provisions instances as your application receives HTTP requests. If you’re familiar with AWS Lambda, Rising Cloud satisfies the same set of use cases while providing more intelligent auto-scaling, greater flexibility in application packaging, multi-cloud resiliency, and lower cost.
Rising Cloud’s platform uses artificial intelligence to predict when your application is expected to receive heavy traffic volumes and scales up server resources by provisioning new instances of your application in advance of when they are needed. Similarly, when your traffic is low, Rising Cloud spins down resources.
So far, so good, but, as we all know, artificial intelligence is not perfect. What happens when Rising Cloud’s algorithm predicts a rise in traffic and provisions new instances, but that traffic doesn’t arrive? Well, Rising Cloud picks up the tab—you only pay for the resources your application actually uses.
As is common with most cloud platforms, Rising Cloud applications must be stateless—that is, they cannot themselves maintain state from one request to the next. If your application needs to maintain state, you have to bring your own data store. Our use case, creating image thumbnails, is a perfect match for this model. Each thumbnail creation is a self-contained operation and has no effect on any other task.
Creating Image Thumbnails on Demand
As I explained in the previous post, the Cloudflare Worker will send a notification to a configured webhook URL for each operation that it proxies to Backblaze B2 via the Backblaze S3 Compatible API. That notification contains JSON-formatted metadata regarding the bucket, file, and operation. For example, on an image download, the notification looks like this:
If the metadata indicates an image upload (i.e. the method is PUT, the content type starts with image, and so on), the Rising Cloud app will retrieve the full-size image from the Backblaze B2 bucket, create a thumbnail image, and write that image back to the same bucket, modifying the filename to distinguish it from the original.
Here’s the message flow between the user’s app, the Cloudflare Worker, Backblaze B2, and the Rising Cloud app:
A user uploads an image in a Backblaze B2 client application.
The client app creates a signed upload request, exactly as it would for Backblaze B2, but sends it to the Cloudflare Worker rather than directly to Backblaze B2.
The Worker validates the client’s signature and creates its own signed request.
The Worker sends the signed request to Backblaze B2.
Backblaze B2 validates the signature and processes the upload.
Backblaze B2 returns the response to the Worker.
The Worker forwards the response to the client app.
The Worker sends a notification to the Rising Cloud Web Service.
The Web Service downloads the image from Backblaze B2.
The Web Service creates a thumbnail for the image.
The Web Service uploads the thumbnail to Backblaze B2.
These steps are illustrated in the diagram below.
I decided to write the application in JavaScript, since the Node.js runtime environment and its Express web application framework are well-suited to handling HTTP requests. Also, the open-source Sharp Node.js module performs this type of image processing task 4x-5x faster than either ImageMagick or GraphicsMagick. The source code is available on GitHub.
// Get the image from B2 (returns a readable stream as the body)
console.log(`Fetching image from ${inputUrl}`);
const obj = await client.getObject({
Bucket: bucket,
Key: keyBase + (extension ? "." + extension : "")
});
// Create a Sharp transformer into which we can stream image data
const transformer = sharp()
.rotate() // Auto-orient based on the EXIF Orientation tag
.resize(RESIZE_OPTIONS); // Resize according to configured options
// Pipe the image data into the transformer
obj.Body.pipe(transformer);
// We can read the transformer output into a buffer, since we know
// that thumbnails are small enough to fit in memory
const thumbnail = await transformer.toBuffer();
// Remove any extension from the incoming key and append '_tn.'
const outputKey = path.parse(keyBase).name + TN_SUFFIX
+ (extension ? "." + extension : "");
const outputUrl = B2_ENDPOINT + '/' + bucket + '/'
+ encodeURIComponent(outputKey);
// Write the thumbnail buffer to the same B2 bucket as the original
console.log(`Writing thumbnail to ${outputUrl}`);
await client.putObject({
Bucket: bucket,
Key: outputKey,
Body: thumbnail,
ContentType: 'image/jpeg'
});
// We're done - reply with the thumbnail's URL
response.json({
thumbnail: outputUrl
});
One thing you might notice in the above code is that neither the image nor the thumbnail is written to disk. The getObject() API provides a readable stream; the app passes that stream to the Sharp transformer, which reads the image data from B2 and creates the thumbnail in memory. This approach is much faster than downloading the image to a local file, running an image-processing tool such as ImageMagick to create the thumbnail on disk, then uploading the thumbnail to Backblaze B2.
Deploying a Rising Cloud Web Service
With my app written and tested running locally on my laptop, it was time to deploy it to Rising Cloud. There are two types of Rising Cloud applications: Web Services and Tasks. A Rising Cloud Web Service directly accepts HTTP requests and returns HTTP responses synchronously, with the condition that it must return an HTTP response within 44 seconds to avoid a timeout—an easy fit for my thumbnail creator app. If I was transcoding video, on the other hand, an operation that might take several minutes, or even hours, a Rising Cloud Task would be more suitable. A Rising Cloud Task is a queueable function, implemented as a Linux executable, which may not require millisecond-level response times.
Rising Cloud uses Docker-style containers to deploy, scale, and manage apps, so the next step was to package my app as a Docker image to deploy as a Rising Cloud Web Service by creating a Dockerfile.
With that done, I was able to configure my app with its Backblaze B2 Application Key and Key ID, endpoint, and the required dimensions for the thumbnail. As with many other cloud platforms, apps can be configured via environment variables. Using the AWS SDK’s variable names for the app’s Backblaze B2 credentials meant that I didn’t have to explicitly handle them in my code—the SDK automatically uses the variables if they are set in the environment.
Click to enlarge.
Notice also that the RESIZE_OPTIONS value is formatted as JSON, allowing maximum flexibility in configuring the resize operation. As you can see, I set the withoutEnlargement parameter as well as the desired width, so that images already smaller than the width would not be enlarged.
Calling a Rising Cloud Web Service
By default, Rising Cloud requires that app clients supply an API key with each request as an HTTP header with the name X-RisingCloud-Auth:
Click to enlarge.
So, to test the Web Service, I used the curl command-line tool to send a POST request containing a JSON payload in the format emitted by the Cloudflare Worker and the API key:
The final piece of the puzzle was to create a Cloudflare Worker from the Backblaze B2 Proxy template, and add a line of code to include the Rising Cloud API key HTTP header in its notification. The Cloudflare Worker configuration includes its Backblaze B2 credentials, Backblaze B2 endpoint, Rising Cloud API key, and the Web Service endpoint (webhook):
Click to enlarge.
This short video shows the application in action, and how Rising Cloud spins up new instances to handle an influx of traffic:
Process Your Own B2 Files in Rising Cloud
You can deploy an application on Rising Cloud to respond to any Backblaze B2 operation(s). You might want to upload a standard set of files whenever a bucket is created, or keep an audit log of Backblaze B2 operations performed on a particular set of buckets. And, of course, you’re not limited to triggering your Rising Cloud application from a Cloudflare worker—your app can respond to any HTTP request to its endpoint.
Submit your details here to set up a free trial of Rising Cloud. If you’re not already building on Backblaze B2, sign up to create an account today—the first 10 GB of storage is free!
For a lot of us here at Backblaze, skateboarding culture permeated our most formative years. That’s why we were excited to hear from the folks at Santa Cruz Skateboards about how they use Backblaze B2 Cloud Storage to protect decades of skateboarding history. The company is the pinnacle of cool for millennials of a certain age, and, let’s face it, anyone not living under a rock since the mid-70s.
We got the chance to talk shop with Randall Vevea, Information Technology Specialist for Santa Cruz Skateboards, and he shared how they:
Implemented a cloud disaster recovery strategy to protect decades of data in a tsunami risk zone.
Created an automated production and VM backup solution using rclone.
Backed up more data affordably and efficiently in truly accessible storage.
Read on to learn how they did it.
Professional skater Fabiana Delfino.
Santa Cruz Skateboards: The Origin Story
It’s 1973 in sunny Santa Cruz, California. Three local guys—Richard Novak, Doug Haut, and Jay Shuirman—are selling raw fiberglass to the folks that make surfboards, boats, and race car parts. On a surf trip in Hawaii, the trio gets a request to throw together some skateboards. They make 500 and sell out immediately. Twice. Just like that, Santa Cruz Skateboards is born.
Fast forward to today, and Santa Cruz Skateboards is considered the backbone of skateboarding. For over five decades, the company has been putting out a steady stream of skateboards, apparel, accessories, and so much more, all emblazoned with the kinds of memorable art that have shaped skate culture.
Their video archives trace the evolution of skateboarding, following big name players, introducing rising stars, and documenting the events and competitions that connect the skate community all over the world, and it all needs to be protected, accessible, and organized.
A Little Storm Surge Can’t Stop Santa Cruz Skateboards
Randall estimates that the company stores about 40 terabytes of data just in art and media assets alone. Those files form an important historical archive, but the creative team is also constantly referencing and updating existing art—losing it isn’t an option. But potential data loss situations abound, particularly in the weather-prone area of Santa Cruz Harbor.
In January 2022, an underwater volcanic eruption off the coast of Tonga caused a tsunami that flooded Santa Cruz to the tune of $6 million in damage to the harbor. Businesses in the area are used to living with tsunami advisories (there was another scare just two years ago), but that doesn’t make dealing with the damage any easier. “The tsunami lit a fire under us to make sure that in the event that something were to go wrong here, we had our data somewhere else,” Randall said.
On top of weather threats, the pandemic forced Santa Cruz Skateboards to transition from a physical, on-premises setup to a more virtualized infrastructure that could support remote work. That transition was one of the main reasons Santa Cruz Skateboards started looking for a cloud data storage solution; it’s not just easier to back up that virtual machine data, but also to spin up those machines on a hypervisor in the event that something does go wrong.
Professional skater Justin Sommer.
Dropping in on a Major Bummer Called AWS Glacier
Before Randall joined Santa Cruz Skateboards, the company had been using AWS Glacier, a cold storage solution. “When I came on, Glacier was not in a working state,” Randall recalled. Data had been uploaded, but wasn’t syncing. “I’m not an AWS expert—I feel like you could go to school for four years and never learn all the inner workings of AWS. We needed a solution that we could implement quickly and without the hassle,” he said.
Glacier posed the problems above and beyond that heavy lift, including:
Changes to the AWS architecture made Santa Cruz Skateboards’ data inaccessible.
Requests to download data timed out due to cold storage delays.
Endless support emails failed to answer questions or give Randall access to the data trapped in AWS’ black box.
“We were in a situation where we were paying AWS for nothing, basically,” Randall remembered. “I started looking around for different solutions and everywhere I turned, Backblaze was the answer.” Assuming it would take a long time, Randall started small with an FTP server and a local file server. Within two days, all that data was fully backed up. Impressed with those results, he contacted Backblaze for a more thorough introduction. “We were super stoked on something that just worked. I was able to deliver that to our executives and say look, our data is in Backblaze now. We don’t have to worry about this anymore,” Randall said.
“I feel like you could go to school for four years and never learn all the inner workings of AWS. We were in a situation where we were paying AWS for nothing, basically.”
—Randall Vevea, Information Technology Specialist, Santa Cruz Skateboards
Backups Are Like Helmets—They Let You Do the Big Things Better
When a project that Randall had expected to take three or four months was completed in one, Randall started to ask, “What else can we put in Backblaze?” They ended up expanding their scope considerably, including:
Decades of art, image, and video files.
Mission critical business files.
Virtual machine backups.
OneDrive backups.
All told, that amounted to about 60TB of data all managed by a small IT team supporting about 150 employees company-wide. In order to return his valuable time and attention to critical everyday IT tasks—everything from fixing printers to preventing ransomware attacks—Randall needed to find a backup solution that could run reliably in the background without much manual input or upkeep, and Backblaze delivered.
Today, Santa Cruz Skateboards uses two network attached storage devices that clone each other and both back up to the cloud using rclone, an open-source command line program that people use to manage or migrate content. Rclone is also able to handle the company’s complex file names with characters in foreign scripts, like files with names written in Chinese, for example, which solved Randall’s worry about mismatched data as the creative team pulls down files to work with art and other visual assets. He set up a Linux box as a backup manager, which he uses to run rclone cronjobs weekly. By the time Randall shows up to work on Monday mornings, the sync is complete.
With Backups Out of the Way, Santa Cruz Lives to Shred Another Day
“I like the fact that I don’t have to think about backups on a day-to-day basis.”
—Randall Vevea, Information Technology Specialist, Santa Cruz Skateboards
Now, all Randall has to do is check the logs to make sure everything is working as it should. With the backup process automated, there’s a long list of projects that the IT team can devote their time to.
Since making the move to Backblaze B2, Santa Cruz Skateboards is spending less to back up more data. “We have a lot more data in Backblaze than we ever thought we would have in AWS,” Randall said. “As far as cost savings, I think we’re spending about the same amount to store more data that we can actually access.”
The company’s creative team relies on the art and media assets that are now stored and always available in Backblaze B2. Now it’s easy to find and download the specific files should they need to restore them. Meanwhile, the IT team is relieved not to have to navigate AWS’ giant dashboards and complex issues of hot and cold storage with the Glacier service.
Santa Cruz Skateboards had been feeling like a small fish in the huge AWS pond, using a product that amounted to a single cog in a complex machine. Instead of having to divert his attention to research every time questions arise, Randall feels confident that he can rely on Backblaze to get his questions answered right away. “Personally, it’s a big lift off my shoulders,” he said. “Our data’s safe and sound and is getting backed up regularly, and I’m happy with that. I think everybody else is pretty happy with that, too.”
The Santa Cruz Skateboards team.
Is disaster recovery on your to-do list? Learn about our backup and archive solutions to safeguard your data against threats like natural disasters and ransomware.
Since the early days of Backblaze B2 Cloud Storage, the advocacy that resellers and distributors have carried out in support of our products has been super important for us. Today, we can start to more fully return the favor: We are excited to announce the launch of our Channel Partner program.
In this program, we commit to delivering greater ease, transparency, and predictability to our Channel Partners through a suite of tools, resources, incentives, and benefits which will roll out over the balance of 2022. We’ve included the details below.
“When Backblaze expressed interest in working with CloudBlue Marketplace, we were excited to bring them into the fold. Their ease-of-use and affordable price point make them a great offering to our existing resellers, especially those in the traditional IT, MSP, and media & entertainment space.”
—Jess Warrington, General Manager, North America at CloudBlue
The Program’s Mission
This new program is designed to offer a simple and streamlined way for Channel Partners to do business with Backblaze. In this program, we are committed to three principles:
Ease
We’ll work consistently to simplify the way partners can do business with Backblaze, from recruitment to onboarding, and engagement to deal close. Work can be hard enough, we want work with us to feel easy.
Transparency
Openness and honesty are central to Backblaze’s business, and they will be in our dealings with partners as well. As we evolve the program, we’ll share our experiences and thoughts early and often, and we’ll encourage feedback and keep our doors open to your thoughts to inform how we can continue to improve the Channel Partner experience.
Predictability
Maintaining predictable pricing and a scalable capacity model for our resellers and distributors is central to this effort. We’ll also increasingly bundle additional features to answer all your customers’ cloud needs.
The Program’s Value
Making these new investments in our Channel Partner program is all about opening up the value of B2 Cloud Storage to more businesses. To achieve that, our team will help you to engage more customers, help those customers to build their businesses and accelerate their growth, and ultimately increase your profits.
Engage
Backblaze will drive joint marketing activities, provide co-branded collateral, and establish market development funds to drive demand.
Build
Any technology that supports S3-compatible storage can be paired with B2 Cloud Storage, and we continue to expand our Alliance Partner ecosystem—this means you can sell the industry-leading solutions your customers prefer paired with Backblaze B2.
Accelerate
Our products are differentiated by their ease of adoption and use, meaning they’ll be easy to serve to your customers for any use case: backup, archive or any object storage use case, and more—growing your topline revenue.
The Details
To deliver on the mission this program is aligned around, and the value it aims to deliver, our team has developed a collection of benefits, rewards, and resources. Many of these are available today, and some will come later this year (which we’ll clarify below). Importantly, we want to emphasize that this is just the beginning, and we will work to add to each of these lists over the coming months and years.
Partner sales manager to help with onboarding, engagement, and deal close.
Partner marketing manager to help with joint messaging, go-to-market, and collateral.
A password-protected partner portal (coming soon).
Automation of deal registration, lead passing, and seller incentive payments.
Join Us!
We can’t wait to join with our current and future Channel Partners to deliver tomorrow’s solutions to any customer who can use astonishingly easy cloud storage! (We think that’s pretty much everybody.)
If you’re a reseller or distributor, we’d love to hear from you. If you’re a customer interested in benefiting from any of the above, we’d love to connect you with the right Channel Partner team to serve your needs. Either way, the doors are open and we look forward to helping out.
Developing finished applications always requires coding custom functionality, but, as a developer, isn’t it great when you have pre-built, working code you can use as scaffolding for your applications? That way, you can get right to the custom components.
To help you finish building applications faster, we are launching our Developer Quick Start series. This series provides developers with free, open-source code available for download from GitHub. We also built pre-staged buckets with a browsable media application and sample data. For read-only API calls against those buckets, we are sharing API key pairs for programmatic access to these pre-staged buckets. That means you can download the code, run it, and see the results, all without even having to create a Backblaze account!
Today, we’re debuting the first Quick Start in the series—using Python with the Backblaze S3 Compatible API. Read on to get access to all of the resources, including the code on GitHub, sample data to run it against, a video walkthrough, and guided instructions.
Announcing Our Developer Quick Start for Using Python With the Backblaze S3 Compatible API
All of the resources you need to use Python with the Backblaze S3 Compatible API are linked below:
Sample Application: Get our open-source code on GitHub here.
Hosted Sample Data: Experiment with a media application with Application Keys shared for read-only access here.
Video Code Walk-throughs of Sample Application: Share and rewatch walk-throughs on demand here.
Guided Instructions: Get instructions that guide you through downloading the sample code, running it yourself, and then using the code as you see fit, including incorporating it into your own applications here.
Depending on your skill level, the open-source code may be all that you need. If you’re new to the cloud, or just want a deeper, guided walk-through on the source code, check out the written code walk-throughs and video-guided code walk-throughs, too. Whatever works best for you, please feel free to mix and match as you see fit.
Click to enlarge.
The Quick Start walks you through how to perform create and delete API operations inside your own account, all of which can be completed using Backblaze B2 Cloud Storage—and the first 10GB of storage per month are on us.
With the Quick Start code we are sharing, you can get basic functionality working and interacting with B2 Cloud Storage in minutes.
Share the Love
Know someone who might be interested in leveraging the power and ease of cloud storage? Feel free to share these resources at will. Also, we welcome your participation in the projects on GitHub via pull requests. If you are satisfied, feel free to star the project on GitHub or like the videos on YouTube.
The initial launch of the Developer Quick Start series logic is available in Python. We will be rolling out Developer Quick Starts for other languages in the months ahead.
Which programming languages (or scripting environments) are of most interest for you? Please let us know in the comments down below. We are continually adding more working examples in GitHub projects, both in Python and in additional languages. Your feedback in the comments below can help guide what gets priority.
We look forward to hearing from you about how these Developer Quick Starts work for you!
Anyone overwhelmed by their to-do list wishes they could be in two places at once. Backblaze’s newest feature—currently in beta—might not be able to grant that wish, but it will soon offer something similarly useful: The new Cloud Replication feature means data can be in two places at once, solving a whole suite of issues that keep IT teams up at night.
The Background: What Is Backblaze Cloud Replication?
Cloud Replication will enable Backblaze customers to store files in multiple regions, or create multiple copies of files in one region, across the Backblaze Storage Cloud. Simply set replication rules via web UI or API on a bucket. Once the rules are set, any data uploaded to that bucket will automatically be replicated into a destination bucket either in the same region or another region. If it sounds easy, that’s because it is—even the English majors in our Marketing department have mastered this one.
The Why: What Can Cloud Replication Do for You?
There are three key use cases for Cloud Replication:
Protecting data for security, compliance, and continuity purposes.
Bringing data closer to distant teams or customers for faster access.
Providing version protection for testing and staging in deployment environments.
Redundancy for Compliance and Continuity
This is the top use case for cloud replication, and will likely have value for almost any enterprise with advanced backup strategies.
Whether you are concerned about natural disasters, political instability, or complying with possible government, industry, or board regulations—replicating data to another geographic region can check a lot of boxes easily and efficiently. Especially as enterprises move completely into the cloud, data redundancy will increasingly be a requirement for:
Modern business continuity and disaster recovery plans.
Industry and board compliance efforts centered on concentration risk issues.
Data residency requirements stemming from regulations like GDPR.
The gold standard for backup strategies has long been a 3-2-1 approach. The core principles of 3-2-1, originally developed for an on-premises world, still hold true, and today they are being applied in even more robust ways to an increasingly cloud-based world. Cloud replication is a natural evolution for organizations that are storing much more or even all of their data in the cloud or plan to in the future. It enables you to implement the core principles of 3-2-1, including redundancy and geographic separation, all in the cloud.
Data Proximity
If you have teams, customers, or workflows spread around the world, bringing a copy of your data closer to where work gets done can minimize speed-of-light limitations. Especially for media-heavy teams in game development and postproduction, seconds can make the difference in keeping creative teams operating smoothly. And because you can automate replication and use metadata to track accuracy and process, you can remove some manual steps from the process where errors and data loss tend to crop up.
Testing and Staging
Version control and smoke testing are nothing new, but when you’re controlling versions of large applications or trying to keep track of what’s live and what’s in testing, you might need a tool with more horsepower and options for customization. Cloud Replication can serve these needs.
You can easily replicate objects between buckets dedicated for production, testing, or staging if you need to use the same data and maintain the same metadata. This allows you to observe best practices and automate replication between environments.
The Status: When Can I Get My Hands on Cloud Replication?
Cloud Replication kicked off in beta in early April and our team and early testers have been breaking in the feature since then.
Here’s how things are lined up:
April 18: Phase One (Underway)
Phase one is a limited release that is currently underway. We’ve only unlocked new file replication in this release—meaning testers have to upload new data to test functionality.
May 24 (Projected): Phase Two
We’ll be unlocking the “existing file” Cloud Replication functionality at this time. This means users will be able to set up replication rules on existing buckets to see how replication will work for their business data.
Early June (Projected): General Availability
We’ll open the gates completely on June 7 with full functionality, yeehaw!
Want to Learn More About Cloud Replication?
Stay in the know about Cloud Replication availability—click here to get notified first.
If you want to dig into how this feature works via the CLI and API and learn about some of the edge cases, special circumstances, billing implications, and lookouts—our draft Cloud Replication documentation can be accessed here. We also have some help articles walking through how to create rules via the web application here.
Otherwise, we look forward to sharing more when this feature is fully baked and ready for consumption.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.










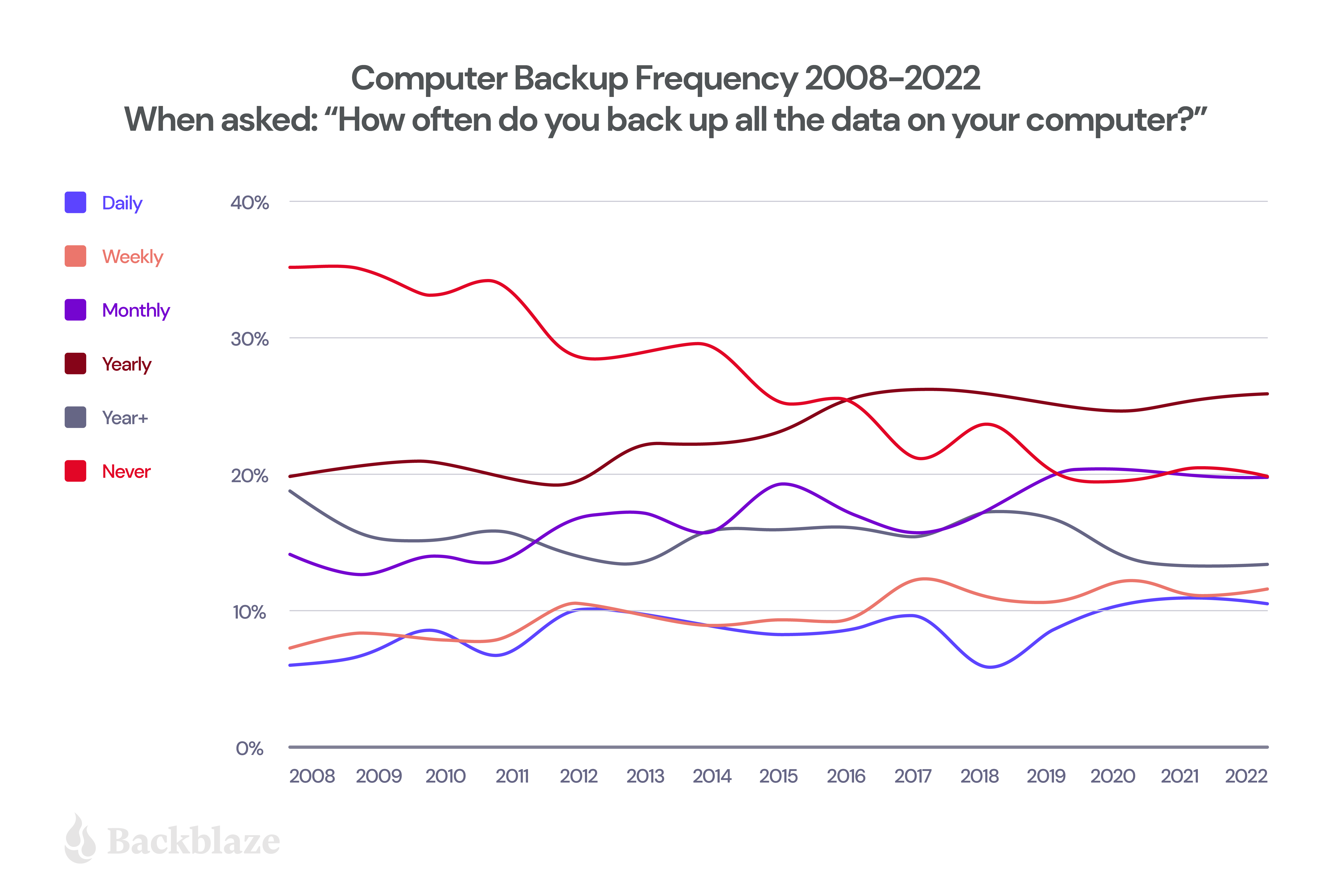

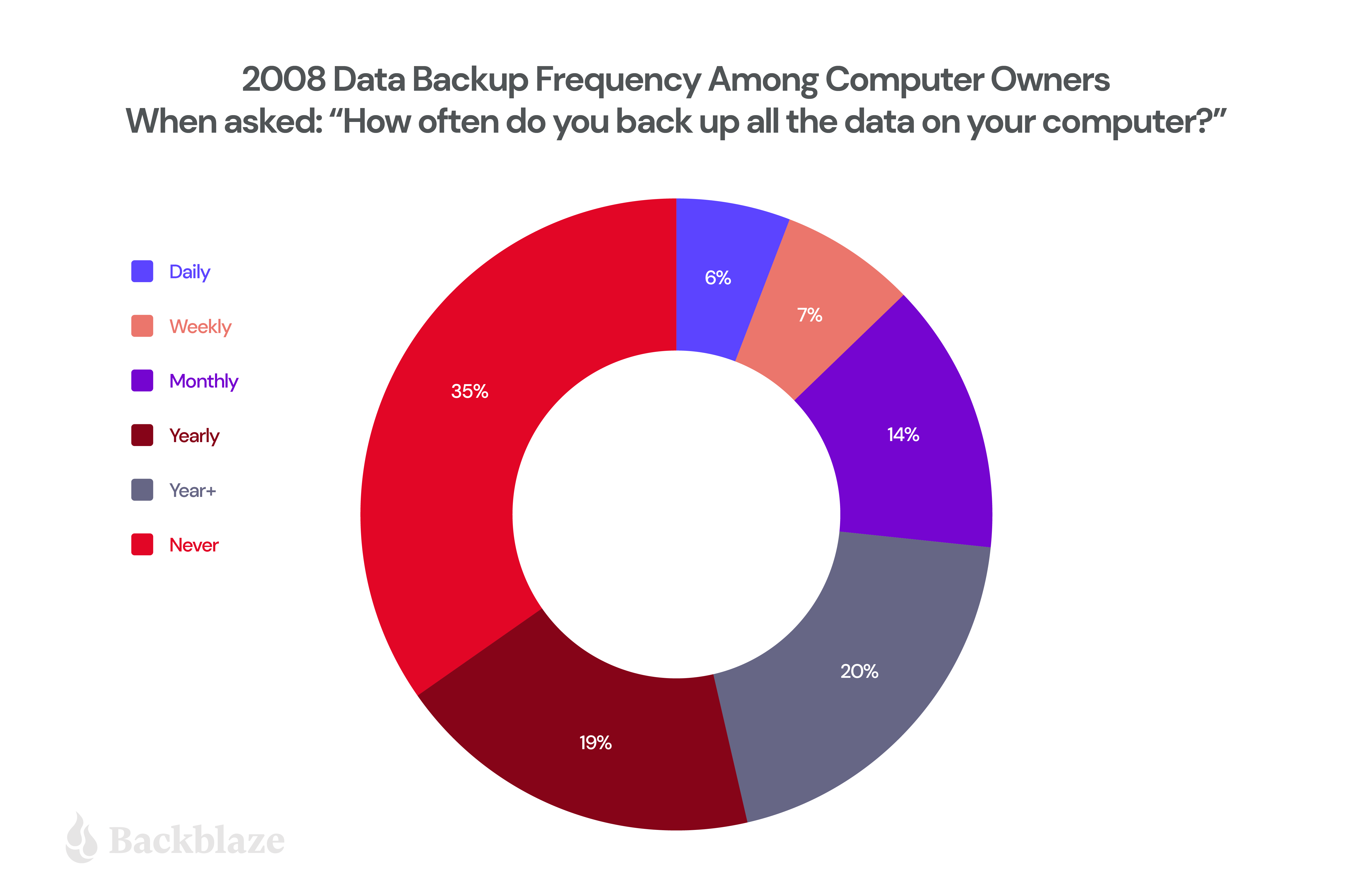
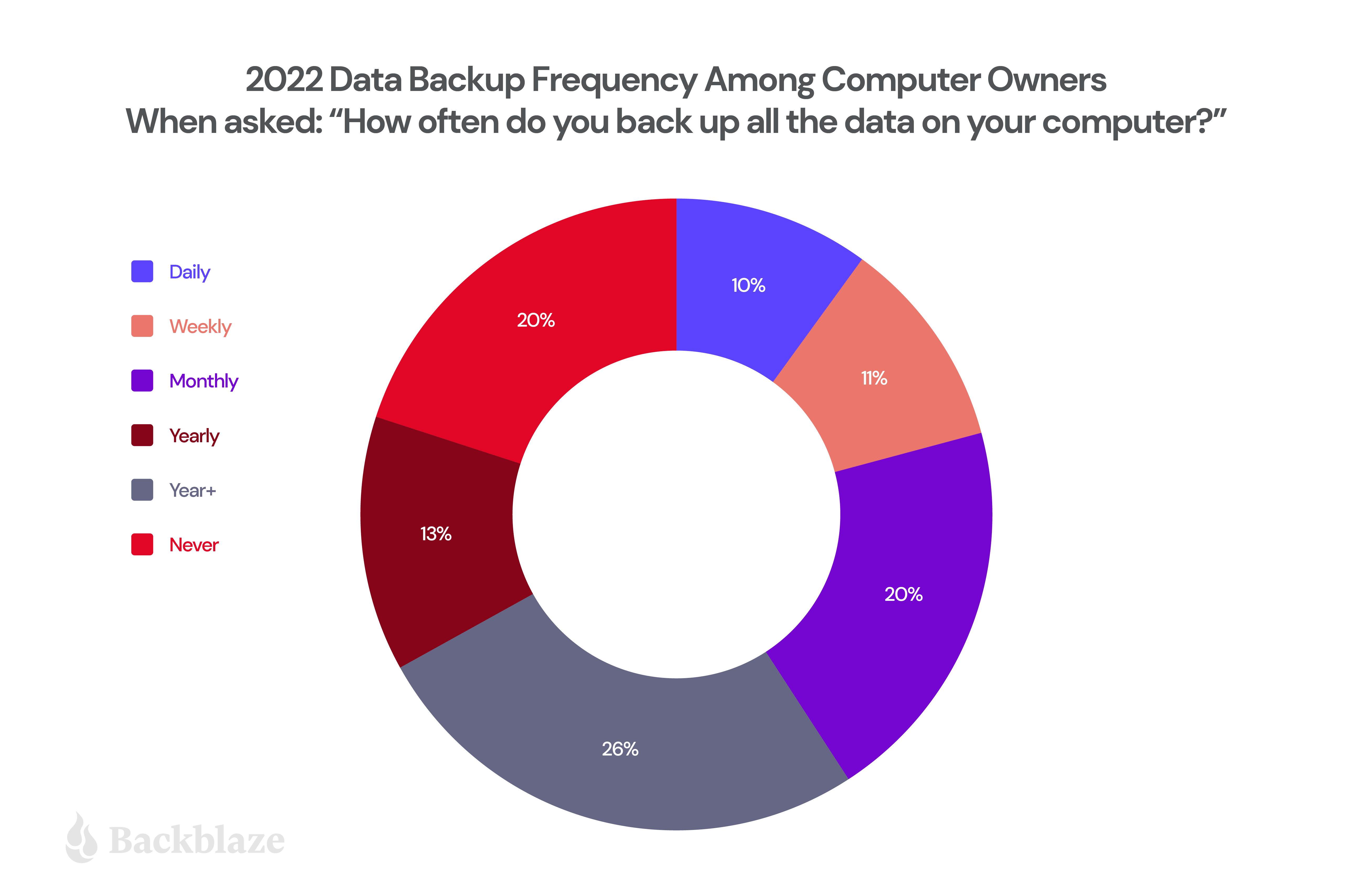




 for the IT industry, but we are the easy, affordable, trusted solution among providers in their ecosystem. Read on to learn more about the partnership.
for the IT industry, but we are the easy, affordable, trusted solution among providers in their ecosystem. Read on to learn more about the partnership.