Recently, a short seller made claims about Backblaze that were factually inaccurate, misleading, and filled with errors.
Short sellers frequently spread false or misleading information to manipulate a company’s stock price for their personal financial gain at the expense of other stockholders. Nevertheless, we want to set the record straight.
Whether you’re a Backblaze customer, investor, or you’re just getting to know us, here’s what you need to know:
The short seller largely rehashed baseless claims made by two disgruntled former employees last year.
Out of an abundance of caution, and following industry best practices, our Audit Committee hired an independent third party law firm and forensic accounting firm, which confirmed there was no wrongdoing or issues with Backblaze’s public financial results.Since then, we have publicly filed two annual financial statements, which were fully audited and which are available on the SEC EDGAR site.
In an effort to enrich themselves, the short seller questioned the health of Backblaze.
We have never been stronger. As reported in our last earnings call, we continue to demonstrate financial strength. Our revenue is over $127 million per year and growing. Our balance sheet is strong with over $50 million in cash and short-term investments as of December 31, 2024.
Wall Street analysts report that the company is strong. For example, a respected analyst who has closely watched Backblaze since the IPO in November 2021, released an analysis of Backblaze after the short seller report was published. TipRanks, summarizing the report, finds the short seller claims to be unsubstantiated.
The short seller tried to push some other false narratives about Backblaze. Here are the facts:
Your data is safe. We have successfully safeguarded customer data for more than 17 years, and continue to focus on delivering reliable, high-performance cloud solutions for our customers.
Leading cloud storage provider. We are driving business growth by providing high value to customers. We have a track record of customer success stories that highlight how we help them improve performance, reduce costs, and transition to us from competitors, unlocking efficiencies in the process.
Continued innovation. We continue to innovate to best serve the needs of our customers. We recently announced B2 Overdrive, a high-performance offering designed to power customers’ massive AI needs, as well as Event Notifications, Live Read, and Scalable Application Keys, amongst others.
If you want to hear more about how we’re doing and what we’re working on, check out our investor relations section.
Backblaze is happy to announce that Marc Suidan has joined our team as Chief Financial Officer (CFO). Marc will lead the financial organization, spearheading overall strategy, forecasting, and reporting.
What Marc brings to the role
Marc comes to Backblaze with 20 years of experience advising and leading companies of all sizes in the technology and media industries, including most recently serving as the CFO of The Beachbody Company (NYSE: BODi). He has also held leadership positions with PricewaterhouseCoopers, McKinsey & Company, and others where he drove growth and innovation.
Marc has deep knowledge and experience strategically guiding companies through financial growth. His expertise and leadership will be a valuable asset as we empower customers to move to an open cloud and to do more with their data.”
—Gleb Budman, CEO and Chairperson of the Board, Backblaze
Marc takes over for Frank Patchel, who will retire from the company in Q3 2024 after leading Backblaze through a successful IPO in 2021 and serving as an integral member of the leadership team in the years since. Thanks to Frank for all his contributions to Backblaze—we wish him well in retirement.
Regarding his new role at Backblaze, Marc said:
I believe that Backblaze is uniquely positioned for success in the cloud services industry and their vision to lead and grow the open cloud ecosystem is what drew me to the company. I’m excited to join Backblaze and lead the financial organization as we continue to drive strong growth, increase profitability, and deliver shareholder value.”
Backblaze is happy to announce that Jason Wakeam has joined our team as Backblaze’s first Chief Revenue Officer (CRO). Jason will take on spearheading our overall sales strategy, with a focus on expanding market share and driving new revenue opportunities.
What Jason Brings to the Role
An industry veteran with nearly three decades of global leadership experience, Jason brings a proven track record of driving growth and innovation at technology companies. Jason has previously served as a vice president of global sales at SnapLogic, and held leadership roles in a range of public and private companies including Cloudera, Microsoft, and Hewlett-Packard.
I am pleased to welcome Jason as our chief revenue officer. He has an impressive track record that showcases his ability to drive businesses to the next level. His expertise will be crucial as we help more, larger customers break free from traditional cloud walled gardens, move to an open cloud ecosystem, and empower them to do more with their data.
—Gleb Budman, CEO and Chairperson of the Board, Backblaze
Jason takes over from long-time Backblazer Nilay Patel, who previously served as vice president of sales, and has transitioned to oversee our recently established New Markets team with a special focus on AI.
The addition of Jason to our leadership is a sign of our commitment to attracting, retaining, and growing with larger mid-market customers. Jason says of his new role:
Backblaze’s mission deeply resonates with me, and I am excited to help accelerate growth for our company. I’m looking forward to working with this amazing team as we continue to scale with our customers and further innovation.
Backblaze is happy to announce that David Ngo has joined our team as Chief Product Officer, a role responsible for spearheading the company’s global product management function, shaping the strategy, crafting the technology roadmap and overseeing execution.
What David Brings to the Role
David is a software as a service (SaaS) data protection industry veteran with more than 25 years of global leadership experience. He previously served as the global chief technology officer (CTO) for Metallic, a division of Commvault, which provides data protection and cyber resilience as a service. He will play a pivotal role in guiding overall product direction for our existing customers as well as emerging needs as the company continues to succeed in moving upmarket.
I am pleased to welcome David as our new Chief Product Officer. David brings impressive engineering, design, and product leadership to Backblaze. He joins us at an exciting time as we help more customers break free from traditional cloud walled gardens and move to an open cloud ecosystem and empower them to do more with their data.
Gleb Budman, Backblaze CEO and Chairperson of the Board
Ngo joins a team with an impressive track record of building and scaling products and solutions that excite customers, drive growth, and deliver impact. With over 500,000 customers and three billion gigabytes of data storage under management, Backblaze has built data storage products at industry leading pricing over the past 15 years. Ngo further expands the company’s leadership by bringing his vast cloud, infrastructure, and data management knowledge developed during his time leading global teams at Commvault.
David says of his new role:
I am thrilled to lead the amazing product organization at Backblaze and to help accelerate growth for our company. I am committed to continuing the company’s impressive track record of building powerful products that support customers’ data needs and leading the industry towards an open cloud ecosystem.
Last year, our team published a history of the Python GIL. We tapped two contributors, Barry Warsaw, a longtime Python core developer, and Pawel Polewicz, a backend software developer and longtime Python user, to help us write the post.
Today, Pawel is back to revisit the original inspiration for the post: the experiments he did testing different versions of Python with the Backblaze B2 CLI.
If you find the results of Pawel’s speed tests useful, sign up to get more developer content every month in our Backblaze Developer Newsletter. We’ll let Pawel take it from here.
—The Editors
I was setting up and testing a backup solution for one of my clients when I noticed a couple of interesting things I’d like to share today. I realized by using Python 3.9-nogil, I could increase I/O performance by 10x. I’ll get into the tests themselves, but first let me tell you why I’m telling this story on the Backblaze blog.
Durability: The numbers bear out that B2 Cloud Storage is reliable.
Redundancy: If the entire AWS, Google Cloud Platform (GCP), or Microsoft Azure account of one of my clients (usually a startup founder) gets hacked, backups stored in B2 Cloud Storage will stay safe.
Affordability: The price for B2 Cloud Storage is one-fifth the cost of AWS, GCP, or Azure—better than anywhere else.
Availability: You can read data immediately without any special “restore from archive” steps. Those might be hard to perform when your hands are shaking after you accidentally deleted something.
Naturally, I always want to make sure my clients can get their backup data out of cloud storage fast should they need to. This brings us to “The Experiment.”
The Experiment: Speed Testing the Backblaze B2 CLI With Different Python Versions
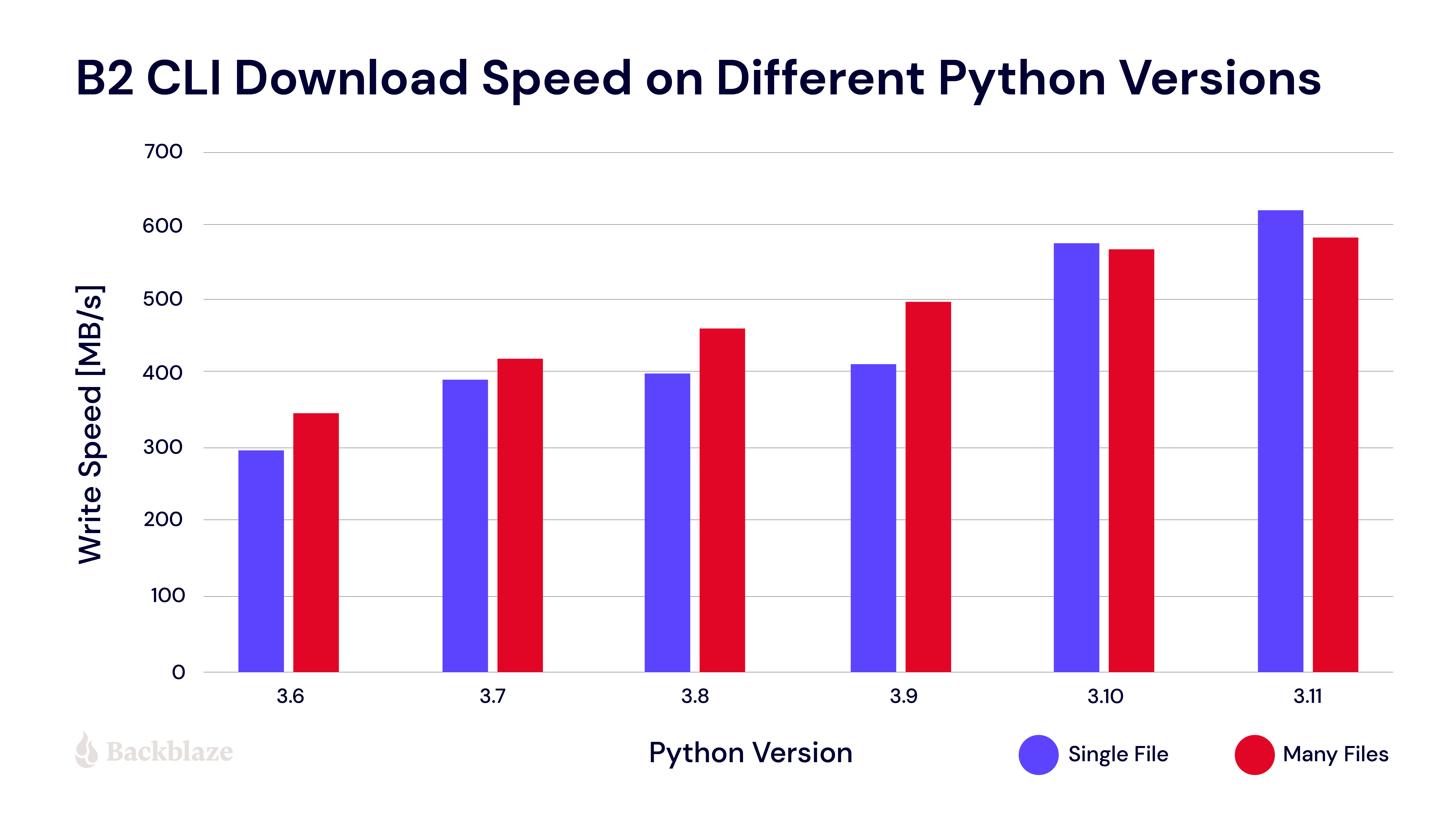
I ran a speed test to see how quickly we could get large files back from Backblaze B2 using the B2 CLI. To my surprise, I’ve found that it depends on the Python version.
The chart below shows download speeds from different Python versions, 3.6 to 3.11, for both single-file and multi-file downloads.
What’s Going On Under the Hood?
The Backblaze B2 CLI is fetching data from the B2 Cloud Storage server using Python’s Requests library. It then saves it on a local storage device using Python threads—one writer thread per file. In this type of workload, the newer versions of Python are much faster than the older ones—developers of CPython (the standard implementation of the Python programming language) have been working hard on performance for many years. CPython 3.10 had the highest performance improvement from the official releases I’ve tested. CPython 3.11 is almost twice as fast as 3.6!
Refresher: What’s the GIL Again?
GIL stands for global interpreter lock. You can check out the history of the GIL in the post from last year for a deep dive, but essentially, the GIL is a lock that allows only a single operating system thread to run the central Python bytecode interpreter loop. It serves to serialize operations involving the Python bytecode interpreter—that is, to run tasks in an order—without which developers would need to implement fine grained locks to prevent one thread from overriding the state set by another thread.
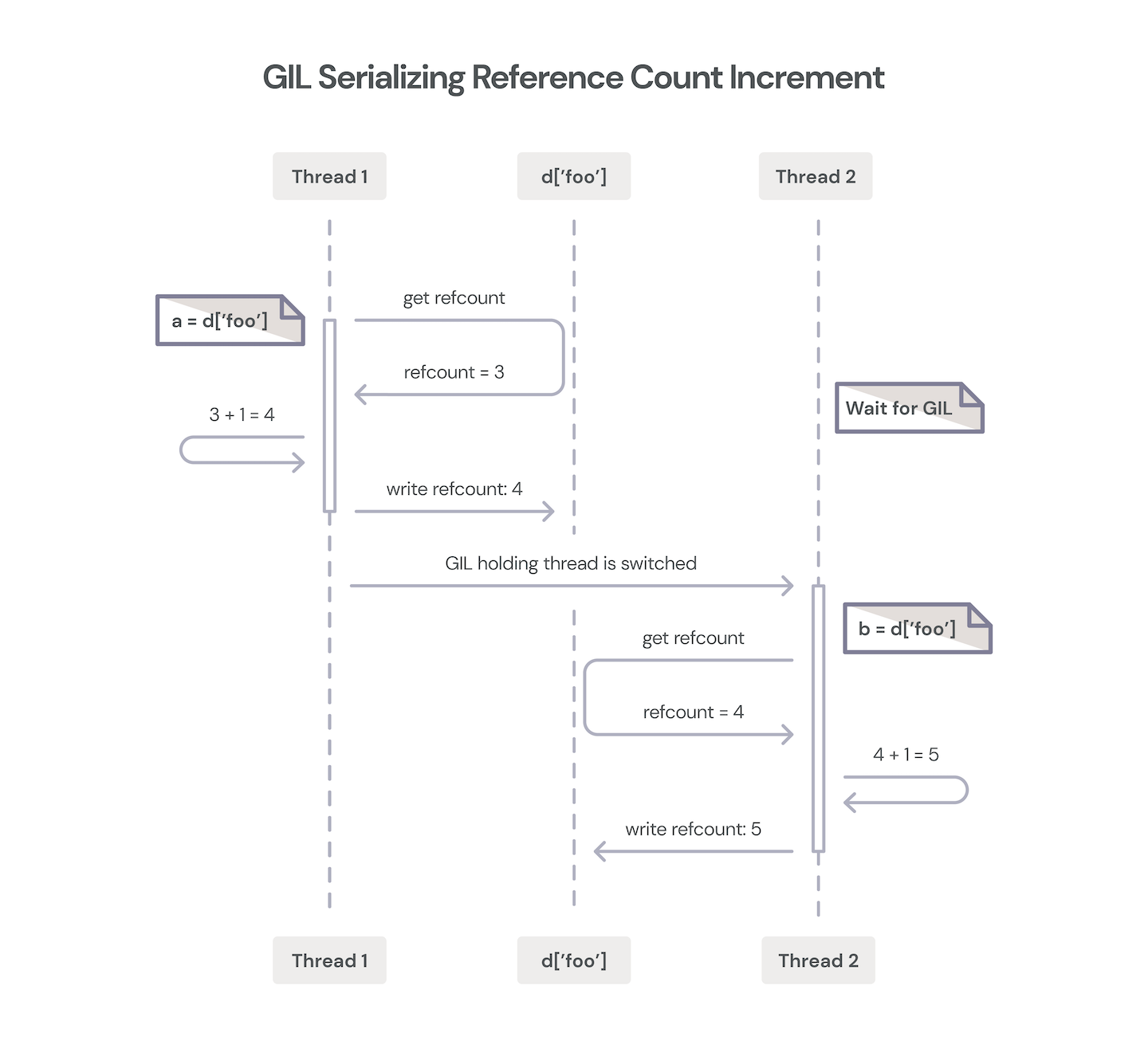
Don’t worry—here’s a diagram.
Two threads incrementing an object reference counter.
The GIL prevents multiple threads from mutating this state at the same time, which is a good thing as it prevents data corruption, but unfortunately it also prevents any Python code from running in other threads (regardless of whether they would mutate a shared state or not).
How Did “nogil” Perform?
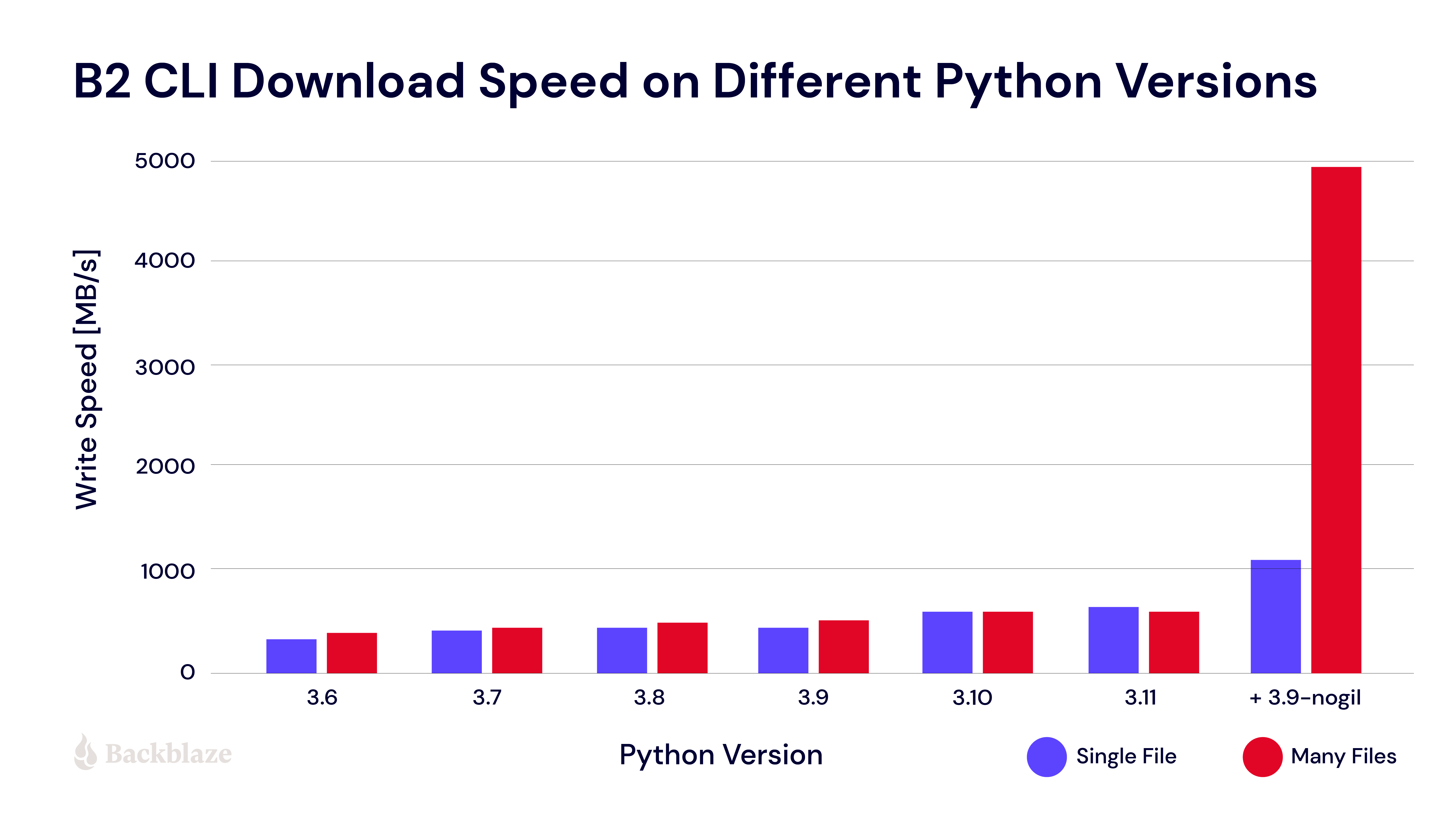
I ran one more test using the “nogil” fork of CPython 3.9. I had heard it improves performance in some cases, so I wanted to try it out to see how much faster my program would be without GIL.
The results of that test were added to the tests run on versions of unmodified CPython and you can see them below:
In this case not being limited by GIL has quite an effect! Most performance benchmarks I’ve seen show how fast the CPython test suite is, but some Python programs move data around. For this type of usage, 3.9-nogil was 2.5 or 10 times faster (for single and multiple files, respectively) on the test than unmodified CPython 3.9.
Why Isn’t nogil Even Faster?
A simple test running parallel writes on the RAID-0 array we’ve set up on an AWS EC2 i3en.24xlarge instance—a monster VM, with 96 virtual CPUs, 768 GiB RAM and 8 x 7500GB of NVMe SSD storage—shows that the bottleneck is not in userspace. The bottleneck is likely a combination of filesystem, raid driver, and the storage device. A single I/O-heavy Python process outperformed one of the fastest virtual servers you can get in 2023, and enabling nogil required just one change—the FROM line of the Dockerfile.
Why Not Use Multiprocessing?
For a single file, POSIX doesn’t guarantee consistency of writes if those are done from different threads (or processes)—that’s why the B2 Cloud Storage CLI uses a single writer thread for each file while the other threads are getting data off the network and passing it to the writer using a queue.Queue object. Using a multiprocessing.Queue in the same place results in degraded performance (approximately -15%).
The cool thing about threading is that it’s easy to learn. You can take almost any synchronous code and run it in threads in a few minutes. Using something like asyncio or multiprocessing is not so easy. In fact, whenever I tried multiprocessing, the serialization overhead was so high that the entire program slowed down instead of speeding up. As for asyncio, it won’t make Python run on 20 cores, and the cost of rewriting a program based on Requests is prohibitive. Many libraries do not support async anyway and the only way to make them work with async is to wrap them in a thread. Performance of clean async code is known to be higher than threads, but if you mix the async code with threading code, you lose this performance gain.
But Threads Can Be Hard Too!
Threads might be easy in comparison to other ways of making your program concurrent, but even that’s a high bar. While some of us may feel confident enough to go around limitations of Python by using asyncio with uvloop or writing custom extensions in C, not everyone can do that. Case in point: over the last three years I’ve challenged 1622 applicants to a senior Python backend developer job opening with a very basic task using Python threads. There was more than enough time, but only 30% of the candidates managed to complete it.
What’s Next for nogil?
On January 9, 2023, Sam Gross (the author of the nogil branch) submitted [PEP-703]—an official proposal to include the nogil mode in CPython. I hope that it will be accepted and that one day nogil will be merged into mainline, so that Python can exceed single core performance when commanded by lots of users of Python and not just those who are talented and lucky enough to be able to benefit from asyncio, multiprocessing, or custom extensions written in C.
Hey, we can drive! (Pun absolutely intended.) Some days it’s hard to believe that what started as a “crazy” dream in a one-bedroom apartment has evolved into what we’re celebrating today—16 years of blazing on (pun, ahem, also intended).
To mark the occasion, we thought we’d share some of our highlights from past years. If you want to hear co-founder and CEO Gleb Budman talking about our evolution (plus where he thinks cloud storage is going in the future), check out his recent appearance on The Cloudcast podcast.
And, here are some other great moments for your reading and viewing pleasure:
View some of our technical content like our article on Reed-Solomon erasure coding, a history of the Python Gil, and load balancing while managing servers.
You already know there’s much, much more on the Backblaze blog, and we love chatting with folks in article comments and on socials. After all, we wouldn’t be here without all of you!
Thanks for supporting us over the years. If you feel like spreading the love, you can always refer a friend. (You’ll be prompted to log in so that you get credit for the referral.) Your friend will get a month free to try Backblaze, and when they sign up, you’ll get one too!
On Wednesday, April 5, 2023, at 8:00 a.m. PT (4:00 p.m. UTC), we’ll be performing planned maintenance on a data center in our U.S. West data region. We expect the work to take up to eight hours. During the window, we do not anticipate any service impacts outside of what customers typically experience during our standard scheduled maintenance. The maintenance is only being performed in one data center in the U.S. West data region. Customers with data stored in this region should see minimal to no impact beyond what is listed below.
Learn More On Our Status Page
Real-time updates on this planned maintenance window as well as general status updates will be shared on our new status page.
Most services, including Computer Backup uploads and most B2 Cloud Storage operations (i.e., uploads, downloads, listing, key creation) will function normally. Within the maintenance window, some customers may experience interruptions of up to eight hours in the following areas:
Web Interface:
Website sign-in
Computer Backup:
Data restore and recovery (requires website sign-in)
Backups may sleep temporarily when starting a new session
Sign-in via installers, downloader apps, and mobile apps
B2 Cloud Storage:
Bucket creation, deletion, and updating via API
B2 Snapshot creation (requires website sign-in)
If timing or impacts change materially—which we do not expect to occur—we will endeavor to offer updates on the Status Page and on our social media channels. If you experience any interruptions not listed above or experience interruptions beyond the expended completion time (4:00 p.m. PT, 12:00 a.m. UTC), you can contact our Support Team through the Help page.
On Wednesday, March 8, 2023, at 8:00 a.m. PT (4:00 p.m. UTC), we’ll be performing planned maintenance on a data center in our U.S. West data region. We expect the work to take up to eight hours. During the window, we do not anticipate any service impacts outside of what customers typically experience during our standard scheduled maintenance. The maintenance is only being performed in one data center in the U.S. West data region. Customers with data stored in this region should see minimal to no impact beyond what is listed below.
Most services, including Computer Backup uploads and most B2 Cloud Storage operations (i.e., uploads, downloads, listing, key creation) will function normally. Within the maintenance window, some customers may experience interruptions of up to eight hours in the following areas:
Web Interface:
Website sign-in
Computer Backup:
Data restore and recovery (requires website sign-in)
Backups may sleep temporarily when starting a new session
Sign-in via installers, downloader apps, and mobile apps
B2 Cloud Storage:
Bucket creation, deletion, and updating via API
B2 Snapshot creation (requires website sign-in)
If timing or impacts change materially—which we do not expect to occur—we will endeavor to offer updates on this blog and on our social media channels. If you have any questions, you can contact our Support Team through the Help page.
On Wednesday, February 1, at 8:00 a.m. PT (4:00 p.m. UTC), we’ll be performing planned maintenance on a data center in our U.S. West data region. We expect the work to take place over four to eight hours. During the window, we do not anticipate any service impacts outside of what customers typically experience during our standard scheduled maintenance. The maintenance is only being performed on one data center in the U.S. West data region. Customers with data stored in this region should see minimal to no impact beyond what is listed below.
Most services, including Computer Backup uploads and most B2 Cloud Storage operations (i.e., uploads, downloads, listing, key creation) will function normally. Within the maintenance window, some customers may experience interruptions of four hours to eight hours in the following areas:
Web Interface:
Website sign in
Computer Backup:
Data restore and recovery (requires website sign in)
Backups may sleep temporarily when starting a new session
Sign in via installers, downloader apps, and mobile apps
B2 Cloud Storage:
Bucket creation, deletion, and updating via API
B2 Snapshot creation (requires website sign in)
If timing or impacts change materially—which we do not expect to occur—we will endeavor to offer updates on our social media channels. If you have any questions, you can contact our Support Team through the Help page.
Our team had some fun experimenting with Python 3.9-nogil, the results of which will be reported in an upcoming blog post. In the meantime, we saw an opportunity to dive deeper into the history of the global interpreter lock (GIL), including why it makes Python so easy to integrate with and the tradeoff between ease and performance.
We reached out to Barry Warsaw, a preeminent Python developer and contributor, because we could think of no one better to break down the evolution of the GIL for us. Barry is a longtime Python core developer, former release manager and steering council member, and PSF Fellow. He was project lead for the GNU Mailman mailing list manager. Barry, along with contributor Paweł Polewicz, a backend software developer and longtime Python user, went above and beyond anything we could have imagined, developing this comprehensive deep dive into the GIL and its evolution over the years. Thanks also go to Larry Hastings for his review and feedback.
If Python’s GIL is something you are curious about, we’d love to hear your thoughts in the comments. We’ll let Barry take it from here.
—The Editors
First Things First: What Is the GIL?
The Python GIL, or Global Interpreter Lock, is a mechanism in CPython (the most common implementation of Python) that serves to serialize operations involving the Python bytecode interpreter, and provides useful safety guarantees for internal object and interpreter state. While providing many benefits, as the discussion below will show, the GIL also prevents CPython from achieving full multicore performance.
In simplest terms, the GIL is a lock (or mutex) that allows only a single operating system thread to run the central Python bytecode interpreter loop. Normally, when multiple threads can access shared state, such as global interpreter or object internal state, a programmer would need to implement fine grained locks to prevent one thread from stomping on the state set by another thread. The GIL removes the need for these fine grained locks because it imposes a global lock that prevents multiple threads from mutating this state at the same time.
In this post, I’ll explore the pros and cons of the GIL, and the many efforts over the years to remove it, including some recent exciting developments.
Humble Beginnings
Back in November 1994, I was invited to a little gathering of programming language enthusiasts to meet the Dutch inventor of a relatively new and little known object-oriented language. This three day workshop was organized by my friends and former colleagues at the National Institute of Standards and Technology (NIST) in Gaithersburg, MD. I came with extensive experience in languages from C, C++, FORTH, LISP, Perl, TCL, and Objective-C and enjoyed learning and playing with new programming languages.
Of course, the Dutch inventor was Guido van Rossum and his little language was Python. I think most of us in attendance knew there was something special about Python and Guido, but it probably would have shocked us to know that Python would even be around almost 30 years later, let alone have the scope, impact, or popularity it enjoys today. For me personally, it was a life-changing moment.
A few years ago, I gave a talk at BayPiggies that took a retrospective look at the evolution of Python from version 1.1 in October 1994 (just before the abovementioned workshop), through the Python 2 series, and up to Python 3.7, the newest release of the language at the time. In many ways, Python 1.1 would be recognizable by today’s modern Python programmer. In other ways, you’d wonder how Python was ever usable without features that were introduced in the intervening years.
Can you imagine not having the tuple() or list() built-ins, or docstrings, or class exceptions, keyword arguments, *args, **kws, packages, or even different operators for assignment and equality tests? It was fun to go back through all those old changelogs and remember what it was like as each of the features we now take for granted were introduced, often in those early days with absolutely no regard for backward compatibility.
I managed to find the agenda for that first Python workshop, and one of the items to be discussed was “Improving the efficiency of Python (e.g., by using a different garbage collection scheme).” I don’t remember any of the details of that discussion, but even then, and from its start, Python employed a reference counting memory management scheme (the cyclic garbage detector being many years away yet). Reference counting is a simple way of managing your objects in a higher level language where you don’t directly allocate or free your memory. One of Guido’s early guiding principles for Python, and which has served Python well over the years, is to keep it as simple as possible while still being effective, useful, and fun.
The Basics of Reference Counting
Reference counting is simple; as it says on the tin, the interpreter keeps a counter that tracks every reference to an object. For example, binding an object to a variable (such as by an assignment) increases that object’s reference count by one. Appending an object to a list also increases its reference count by one. Removing an object from the list decreases that object’s reference count by one. When a variable goes out of scope, the reference count of the object the variable is bound to is decreased by one again. We call this reference count the object’s “refcount” and these two operations “incref” and “decref” respectively.
When an object’s refcount goes to zero it means there are no more live references to the object, so it can be safely freed (and finalized) because nothing in the program can reach that object anymore1. As these objects are deallocated, any references to objects they hold are also decref’d, and so on. Refcounting gives the Python interpreter a very simple mechanism for freeing garbage and more importantly, it allows for humans to reason about Python’s memory management, both from the point of view of the Python programmer, and from the vantage point of the C extension writer, who doesn’t have the luxury of all that reference counting happening automatically.
This is a crucial point: When we talk about “Python” we generally mean “CPython,” the implementation of the runtime written in C2. The C programmer working on the CPython runtime, and the module author writing extensions for Python in C (for performance or to integrate with some system library) does have to worry about all the nitty gritty details of when to incref or decref an object. Get this wrong and your extension can leak memory or double free an object, either way wreaking havoc on your system. Fortunately, Python has clear rules to follow and good documentation, but it can still be difficult to get refcounting right in complex situations, such as when proper error handling leads to multiple exit paths from a function.
Here’s Where the GIL Comes In: Reference Counting and Concurrency
One of the key simplifying rules is that the programmer doesn’t have to worry about concurrency when managing Python reference counting. Think about the situation where you have multiple threads, each inserting and removing a Python object from a collection such as a list or dictionary. Because those threads may run at any time and in any order, you would normally have to be extremely defensive in how you incref and decref those objects, and it would be way too easy to get this wrong. You could crash Python, or worse, if you didn’t implement the proper locks around your incref and decref operations. Having to worry about all that would make your C code very complicated and likely pretty error prone. The CPython implementation also has global and static variables which are vulnerable to race conditions3.
In keeping with Python’s principles, in 1992, when Guido first began to implement threading support in Python, he utilized a simple mechanism to keep this manageable for a wide range of Python programmers and extension authors: a Global Interpreter Lock—the infamous GIL!
Because the Python interpreter itself is not thread-safe, the GIL allows only one thread to execute Python bytecode at a time, and thus serializes all access to Python objects. So, barring bugs, it is impossible for multiple threads to stomp on each other’s reference count operations. There are C API functions to release and acquire the GIL around blocking I/O or compute intensive functions that don’t touch Python objects, and these provide boundaries for the interpreter to switch to other Python-executing threads.
Two threads incrementing an object reference counter.
Thus, we gain significant C implementation simplicity at the expense of some parallelism. Modern Python has many ways to work around this limitation, from asyncio to subprocesses and multiprocessing, which all work fine if they align with your requirements. Python also surfaces operating system threading primitives, but these can’t take full advantage of multicore operations because of the GIL.
Advantages of the GIL
Back in the early days of Python, we didn’t have the prevalence of multicore processors, so this all worked fine. These days, modern programming languages are more multicore friendly, and the GIL gets a bad rap. Before we explore the work to remove the GIL, it’s important to understand just how much benefit and mileage Python has gotten out of it.
One important aspect of the GIL is that it simplifies the programming model for extension module authors. When writing extension modules in C, C++, or any other low-level language with access to the internals of the Python interpreter, extension authors would normally have to ensure that there are no race conditions that could corrupt the internal state of Python objects. Concurrency is hard to get right, especially so in low-level languages, and one mistake can corrupt the entire state of the interpreter4. For an extension author, it can already be challenging to ensure all your increfs and decrefs are properly balanced, especially for any branches, early exits, or error conditions, and this would be monumentally more difficult if the author also had to contend with concurrent execution. The GIL provides an important simplifying model of object access (including refcount manipulation) because it ensures that only one thread of execution can mutate Python objects at a time5.
There are important performance benefits of the GIL for single-threaded operations as well. Without the GIL, Python would need some other way of ensuring that object refcounts are safe from corruption due to, for example, race conditions between threads, such as when adding or removing objects from any mutable collection (lists, dictionaries, sets) that are shared across threads. These techniques can be very expensive as some of the experiments described later showed. Ensuring that Python interpreter is safe for multithreaded use cases degrades its performance for the single-threaded use case. The GIL’s low performance overhead really shines for single-threaded operations, including I/O-multiplexed programs where libraries like asyncio are used, and this is still a predominant use of Python. Finer-grained locks also increase the chances of deadlocks, which isn’t possible with the GIL.
Also, one of the reasons Python is so popular today is that it had so many extensions written for it over the years. One of the reasons there are so many powerful extension modules, whether we like to admit it or not, is that the GIL makes those extensions easier to write.
And yet, Python programmers have long dreamed of being able to run multithreaded Python programs to take full advantage of all the cores available on modern computing platforms. Even today’s watches and phones have multiple cores, whereas in Python’s early days, multicore systems were rare. Here we are 30 or so years later, and while the GIL has served Python well, in order to take advantage of what clearly seems to be more than a passing fad, Python’s GIL often gets in the way of true high-performance multithreaded concurrency.
Attempting to Remove the GIL
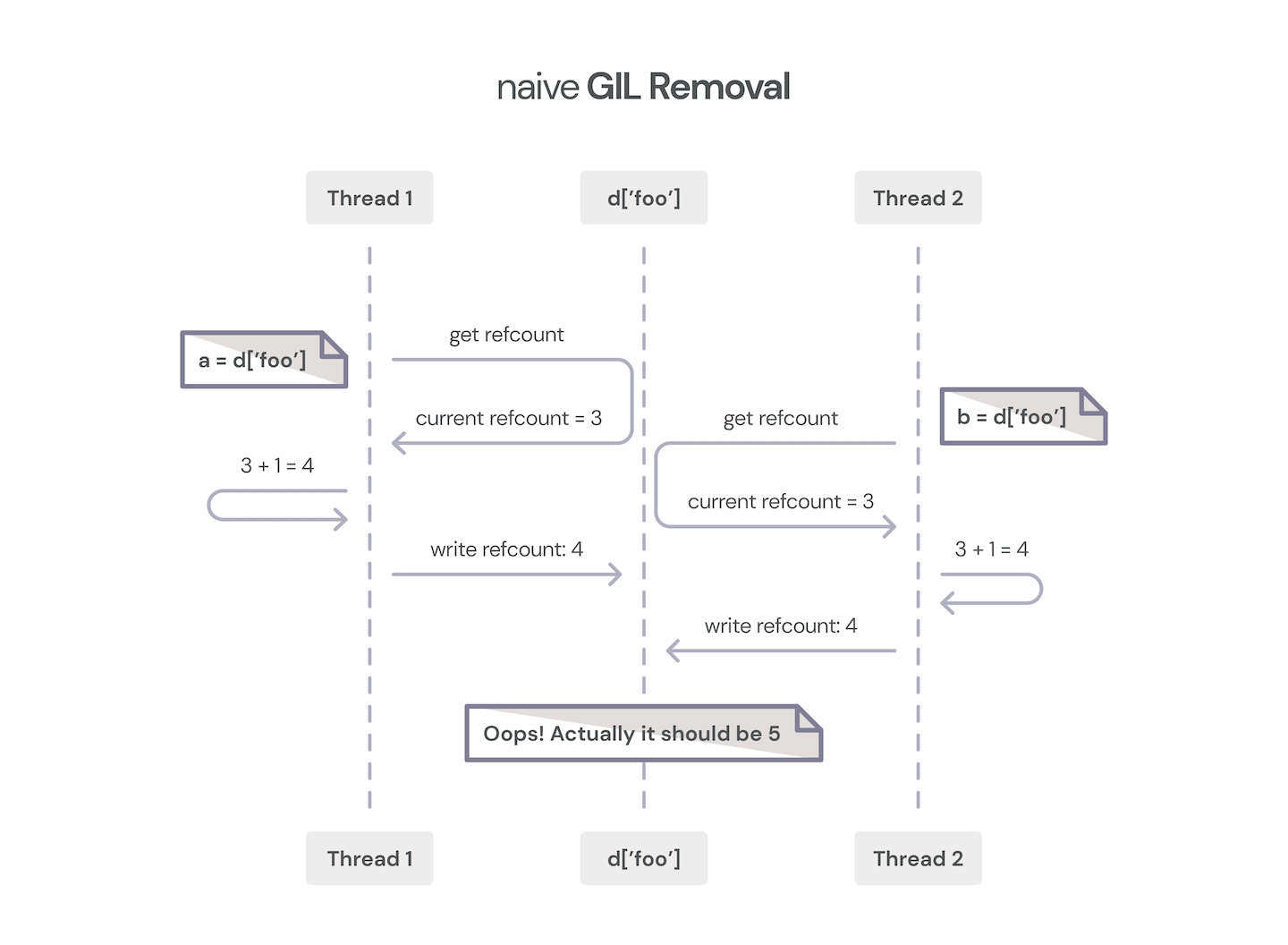
Two threads incrementing object reference counter without GIL protection.
Over the years, many attempts have been made to remove the GIL.
1999: Greg Stein’s “Free Threading”
Circa 1999, Greg Stein’s “free threading” work was one of the first (successful!) attempts to remove the GIL. It made the locks much more fine-grained and moved global variables inside the interpreter into a structure, which we actually still use today. It had the unfortunate side effect however, of making your Python code multiple times slower. Thus, while the free threading work was a great experiment, it was far too impractical to adopt.
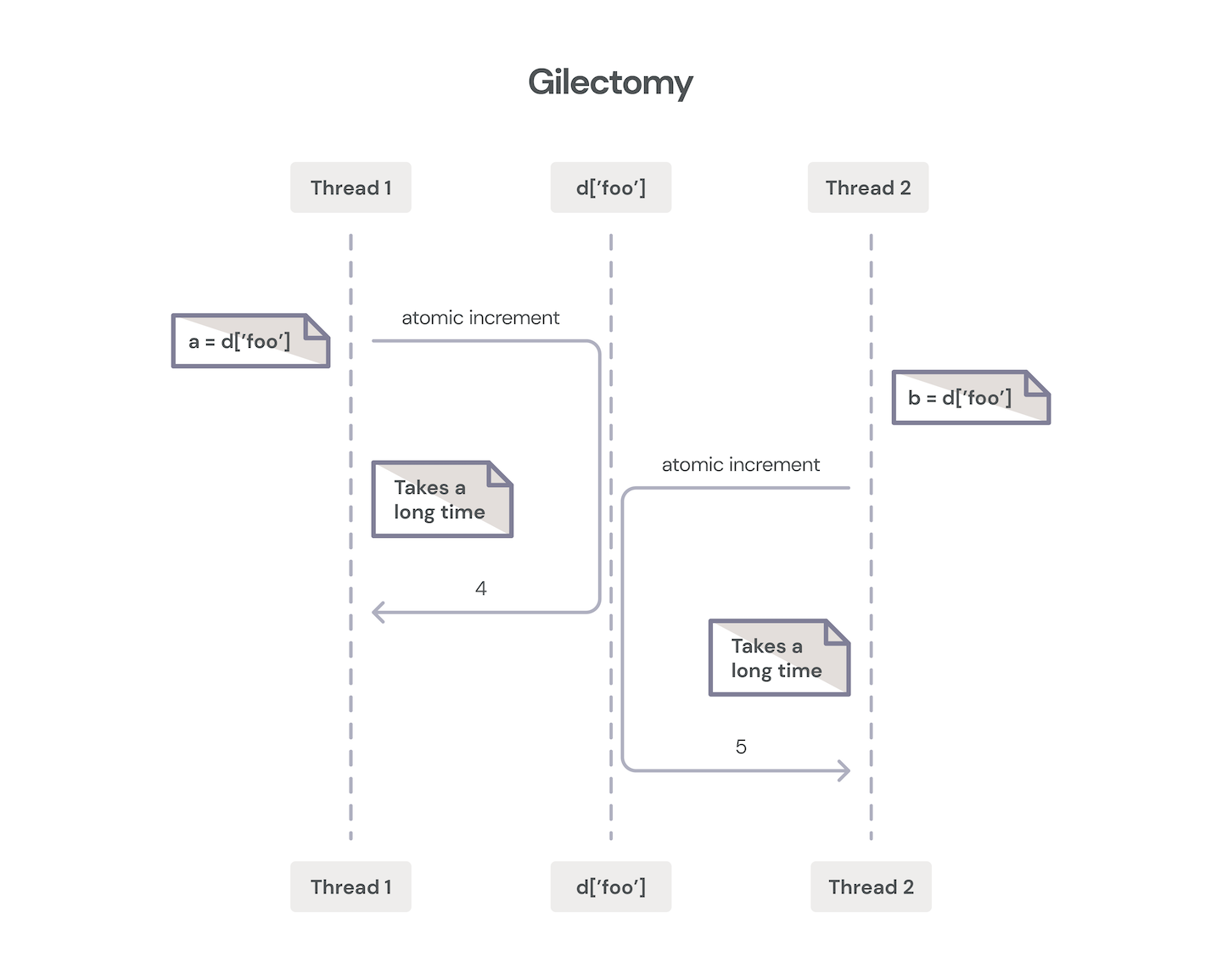
2015: Larry Hasting’s Gilectomy
Years later (circa 2015), Larry Hasting’s wonderfully named Gilectomy project tried a different approach to remove the GIL. In Larry’s PyCon 2016 talk, he discusses four technical considerations that must be addressed when removing the GIL:
Reference Counting: Race conditions on updating the refcount between multiple threads as described previously.
Globals and Statics: These include interpreter global housekeeping variables, and shared singleton objects. Much work has been done over the years to move these globals into per-thread structures. Eric Snow’s work on multiple interpreters (aka “subinterpreters”) has also made a lot of progress on isolating these variables into structures that represent an interpreter “instance” where theoretically each instance could run on a separate core. There are even proposals for making some of those shared singleton objects immortal, such that reference counting race conditions would have no effect on the lifetime of those objects. An interesting related proposal would move the GIL into a per-interpreter data structure, which could lead to the ability to run an isolated interpreter instance per core (with limitations).
C Extensions: Keep in mind that there is a huge ecosystem of C extension modules, and much of Python’s power comes from these extension modules, of which NumPy is a hugely popular example. These extensions have never had to worry about parallelism or re-entrancy because they’ve always relied on the GIL to serialize their operations. At a minimum, a GIL-less Python will require recompilation of extension modules, and some or all may require some level of source code modifications as well. These changes may include protecting internal (non-Python) data structures for concurrency, using functional APIs for refcount modification instead of accessing refcount fields directly, not assuming that Python collections are stable over iteration, etc.
Atomicity: Operations such as adding or deleting objects from Python collections such as lists and dictionaries actually involve a number of steps internally. To the Python developer, these all appear to be atomic operations, and in fact they are, thanks to the GIL.
Larry also identifies what he calls three “political” considerations, but which I think are more in the realm of the social contract between Python developers and Python users:
Removing the GIL should not hurt performance for single-threaded or I/O-bound multithreaded code.
We can’t break existing C extensions as described above6.
Don’t let GIL removal make the CPython interpreter too complicated or difficult to understand. One of Guido’s guiding principles, and a subtle reason for Python’s huge success, is that even with complicated features such as exception handling, asyncio, generators, etc. Python’s C core is still relatively easy to learn and understand. This makes it easy for new contributors to engage with Python core development, an absolutely essential quality if you want your language to thrive and grow for its next 30 years as much as it has for its previous 30.
Larry’s Gilectomy work is quite impressive, and I highly recommend watching any of his PyCon talks for deep technical dives, served with a healthy dose of humor. As Larry points out, removing the GIL isn’t actually the hard part. The hard part is doing so while adhering to the above mentioned technical and social constraints, retaining Python’s single-threaded performance, and building a mechanism that scales with the number of cores. This latter constraint is important because if we’re going to enable multicore operations, we want to ensure that Python’s performance doesn’t hit a plateau at four or eight cores.
So, why did the Gilectomy branch fail (measured in units of “didn’t get adopted by CPython”)? For the most part, the performance and complexity constraints couldn’t be met. One of the biggest hits on performance wasn’t actually lock contention on objects. The early Gilectomy work relied on atomic increment and decrement CPU instructions, which destroyed cache consistency, and caused a high overhead of communication on the intercore bus to ensure atomicity.
Intercore atomic incr/decr communication.
Later, Larry experimented with a technique borrowed from garbage collection research called “buffered reference counting,” essentially a transaction log for refcount changes. However, contention on transaction logs required further modifications to segregate logs by threads and by increment and decrement operations. This led to non-realtime garbage collection events on refcounts reaching zero, which broke features such as Python’s weakref objects.
Interestingly, another hotspot turned out to be what’s called “obmalloc,” which is a small block allocator that improves performance over just using system malloc for everything. We’ll touch on this again later. Solving all these knock-on effects (such as repairing the cyclic garbage collector) led to increased complexity of the implementation, making the chance that it would ever get merged into Python highly unlikely.
Before we leave this topic to look at some new and exciting work, let’s return briefly to Eric Snow’s work on multiple interpreters (aka subinterpreters). PEP 554 proposes to add a new standard library module called “interpreters” which would expose the underlying work that Eric has been doing to isolate interpreter state out of global variables internal to CPython. One such global state is, of course, the GIL. With or without Python-level access to these features, if the GIL could be moved from global state to per-interpreter state, each interpreter instance could theoretically run concurrently with the others. You could therefore attach a different interpreter instance to each thread, and these could run Python code in parallel. This is definitely a work in progress and it’s unclear whether multiple interpreters will deliver on its promises of this kind of limited concurrency. I say “limited” because without full GIL removal, there is significant complexity in sharing Python objects between interpreters, which would almost certainly be necessary. Issues such as ownership (which thread owns which object) and safe mutability would need to be resolved. PEP 554 proposes some solutions to these problems and more, so we’ll have to keep an eye on this work. But even multiple interpreters don’t provide the same true concurrency that full GIL removal promises.
The Future of the GIL: Where Do We Go From Here?
And now we come full-circle, because Python’s popularity, vast influence, and reach is also one of the reasons why it still seems impossible to remove the GIL while retaining single-threaded performance and not breaking the entire ecosystem of extension modules.
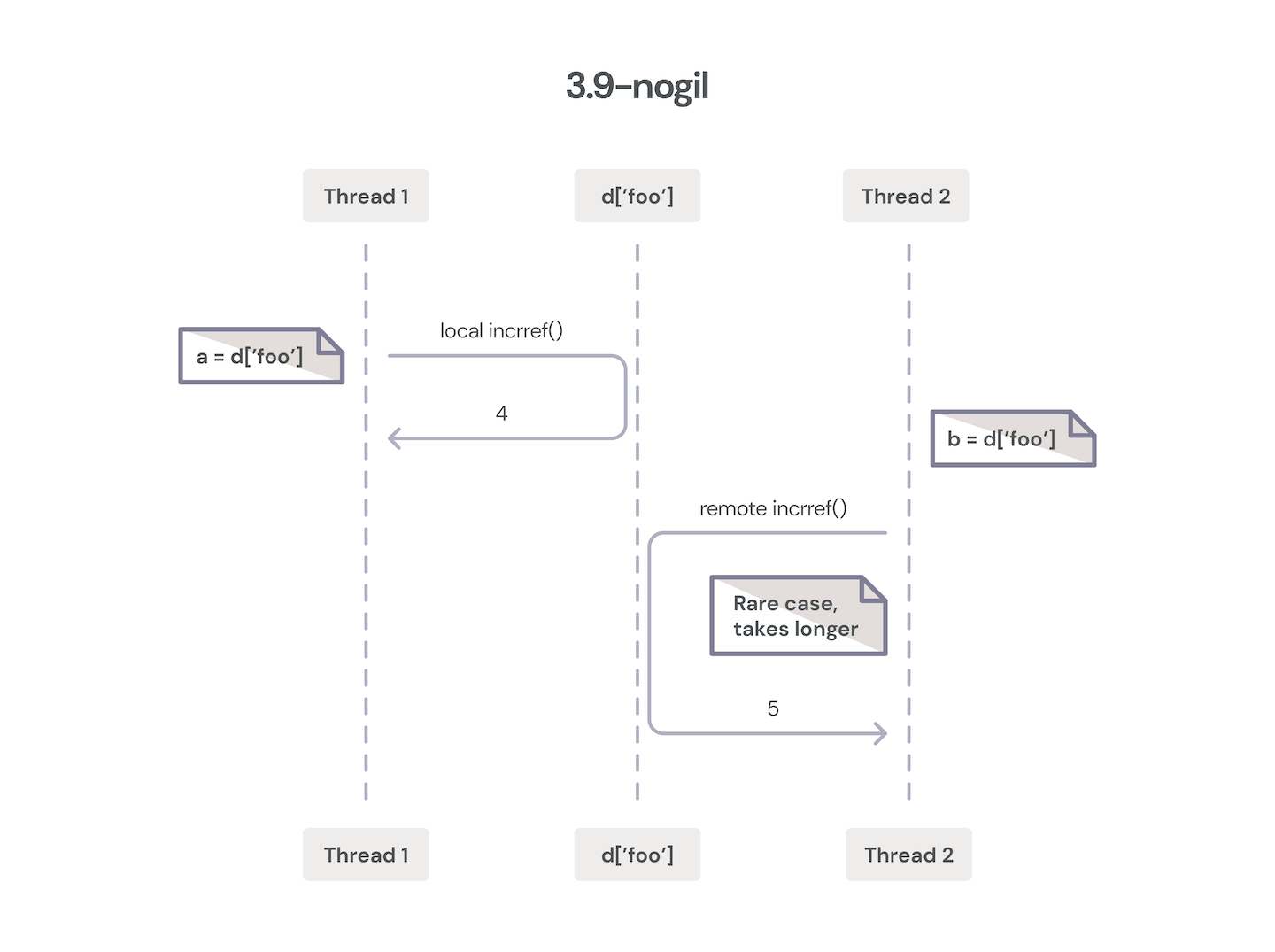
Yet here we are with PyCon 2022 just concluded, and there is renewed excitement for Sam Gross’ “nogil” work, which holds the promise of a performant, GIL-less CPython with minimal backward incompatibilities at both the Python and C layers. While some performance regressions are inevitable, Sam’s work also utilizes a number of clever techniques to claw these regressions back through other internal performance improvements.
Two threads incrementing object reference counter on Sam Gross’ “nogil” branch.
With these improvements as well as the work that Guido’s team at Microsoft is doing with its Faster CPython project, there is renewed hope and excitement that the GIL can be removed while retaining or even improving overall performance, and not giving up on backward compatibility. It will clearly be a multi-year effort.
Sam’s nogil project aims to support a concurrency sweet spot. It promises that data race conditions will never corrupt Python’s virtual machine, but it leaves the integrity of user-level data structures to the programmer. Concurrency is hard, and many Python programs and libraries benefit from the implicit GIL constraints, but solving this is a harder problem outside the scope of the nogil project. Data science applications are one big potential domain to benefit from true multiprocessor enabled concurrency in Python.
There are a number of techniques that the nogil project utilizes to remove the GIL bottleneck. As mentioned, the project also employs a number of other virtual machine improvements to regain some of the performance inevitably lost by removing the GIL. I won’t go into too much detail about these improvements, but it’s helpful to note that where these are independent of nogil, they can and are being investigated along with other work Guido’s team is doing to improve the overall performance of CPython.
Python 3.11 recently entered beta (and thus feature freeze), and with it we’ll see significant performance improvements, which no doubt will continue in future Python releases. When and if nogil is adopted, some of those performance gains may regress to support nogil. Whether and how this will be a good trade-off will be an interesting point of analysis and debate in the coming years. In Sam’s original paper, he proposes a runtime switch to choose between nogil and normal GIL operation, however this was discussed at the PyCon 2022 Language Summit, and the consensus was that this wouldn’t be practical. Thus, as the nogil experiment moves forward, it will be enabled by a compile-time switch.
At a high level, the removal of the GIL is afforded by changes in three areas: the memory allocator, reference counting, and concurrent collection protections. Each of these are deep topics on their own, so we’ll only be able to touch on them briefly.
nogil Part 1: Memory Allocators
Because everything in Python is an object, and most objects are dynamically allocated on the heap, the CPython interpreter implements several levels of memory allocators, and provides C API functions for allocating and freeing memory. This allows it to efficiently allocate blocks of raw memory from the operating system, and to subdivide and manage those blocks based on the type of objects being placed into them. For example, integers have different memory requirements than dictionaries, so having object-specific memory managers for these (and other) types of objects makes memory management inside the interpreter much more efficient.
CPython also employs a small object allocator, called pymalloc, which improves performance for allocating and freeing objects smaller than or equal to 512 bytes. This only touches on the complexities of memory management inside the interpreter. The point of all this complexity is to enable more efficient object creation and destruction, but it also allows for features like memory allocation debugging and custom memory allocators.
The nogil works takes advantage of this pluggability to utilize a general purpose, highly efficient, thread-safe memory allocator developed by Daan Leijen at Microsoft called mimalloc. mimalloc itself is worthy of an in-depth look, but for our purposes it’s enough to know that the mimalloc design is extremely well tuned to efficient and thread-safe allocation of memory blocks. The nogil project utilizes these structures for the implementation of dictionaries and other collection types which minimize the need for locks on non-mutating access, as well as managing garbage collected objects7 with minimal bookkeeping. mimalloc has also been highly tuned for performance and thread-safety.
nogil Part 2: Reference Counting
nogil also makes several changes to reference counting, although it does so in a clever way that minimizes changes to the Limited C API, but does not preserve the stable ABI. This means that while extension modules must be recompiled, their source code may not require modification, outside of a few known corner cases8.
One very promising idea is to make some objects effectively immortal, which I touched on earlier. True, False, None and some other objects in practice never actually see their refcounts go to zero, and so they stay alive for the entire lifetime of the Python process. By utilizing the least significant bits of the object’s reference count field for bookkeeping, nogil can make the refcounting macros no-op for these objects, thus avoiding all contention across threads for these fields.
nogil uses a form of biased reference counting to split an object’s refcount into two buckets. For refcount changes in the thread that owns the object, these “local” changes can be made by the more efficient conventional (non-atomic) forms. For changing the refcount of objects in a different thread, an atomic operation is necessary for safe concurrent modification of a “shared” refcount. The thread that owns the object can then combine this local and shared refcount for garbage collection purposes, and it can give up ownership when its local refcount goes to zero. This is performant when most object accesses are local to the owning thread, which is generally the case. nogil’s biased reference counting scheme can utilize mimalloc’s memory pools to efficiently keep track of the owning threads.
However, some objects are typically owned by multiple threads and are not immortal, and for these types of objects (e.g., functions, modules), a deferred reference counting scheme is employed. Incref and decref act as normal for these objects, but when the interpreter loads these objects onto its internal stack, the refcounts are not modified. The utility of this technique is limited to objects that are only deallocated during garbage collection because they are typically involved in reference cycles.
The garbage collector is also modified to ensure that it only runs at safe boundary points, such as a bytecode execution boundary. The current nogil implementation of garbage collection is single-threaded and stops the world, so it is thread-safe. It repurposes some of the existing C API functions to ensure that it doesn’t wait on threads that are blocked on I/O.
nogil Part 3: Concurrent Collection Protections
The third high-level technique that nogil uses to enable concurrency is to implement an efficient algorithm for locking container objects, such as dictionaries and lists, when mutating them. To maintain thread-safety, there’s just no way around employing locks for this. However, nogil optimizes for objects that are primarily modified in a single thread, and it admits that objects which are frequently and concurrently modified may need a different design.
Sam’s nogil paper goes into considerable detail about the locking algorithm, but at a high level it relies on container versioning (where every modification to a container bumps a “version” counter so the various read accesses can know whether the container has been modified between distinct reads or not), biased reference counting, and various mimalloc features to optimize for fast track, single-threaded, no modification reads while amortizing the cost of locking for writes against the other expensive operations a typical container write operation imposes.
The Last Word and Some Predictions
Sam Gross’ nogil project is impressive. He’s managed to satisfy most of the difficult constraints that have thwarted previous attempts at removing the GIL, including minimizing as much as possible the impact on single-threaded performance (and trading general interpreter performance improvements for the cost of removing the GIL), maintaining (mostly) Python’s C API backward compatibility to not force changes on the entire extension module ecosystem, and all the while (Despite the length of this article!) preserving the readability and comprehensibility of the CPython interpreter.
You’ve no doubt noticed that the rabbit hole goes pretty deep, and we’ve only explored some of the tunnels in this particular burrow. Fortunately, Python’s semantics and CPython’s implementation has been well documented over its 30 year life, so there are plenty of opportunities for self-exploration…and contributions! It will take sustained engagement through careful and incremental steps to bring these ideas to fruition. The future certainly is exciting.
If I had to guess, I would say that we’ll see features like multiple interpreters provide some concurrency value in the next release or so, with GIL removal five years (and thus five releases) or more away. However many of the techniques described here are already being experimented with and may show up earlier. Python 3.11 will have many noticeable performance improvements, with plenty of room for additional performance work in future releases. These will give the nogil work room to continue its experimentation at true multicore performance.
For a language and interpreter that has gone from a small group of lucky and prescient enthusiasts to a worldwide top-tier programming language, I think there is more excitement and optimism for Python’s future than ever. And that’s not even talking about game changers such as PyScript.
Stay tuned for a post that introduces the performance experiments the Backblaze team has done with Python 3.9-nogil and Backblaze B2 Cloud Storage. Have you experimented with Python 3.9-nogil? Let us know in the comments.
Barry Warsaw
Barry has been a Python core developer since 1994 and is listed as the first non-Dutch contributor to Python. He worked with Python’s inventor, Guido van Rossum, at CNRI when Guido, and Python development, moved from the Netherlands to the USA. He has been a Python release manager and steering council member, created and named the Python Enhancement (PEP) process, and is involved in Python development to this day. He was the project leader for GNU Mailman, and for a while maintained Jython, the implementation of Python built on the JVM. He is currently a senior staff engineer at LinkedIn, a semiprofessional bass player, and tai chi enthusiast. All opinions and commentary expressed in this article are his own.
Pawel has been a backend developer since 2002. He built the largest e-radio station on the planet in 2006-2007, worked as a QA manager for six years, and finally, started Reef Technologies, a software house highly specialized in building Python backends for startups.
Reference cycles are not only possible but surprisingly common, and these can keep graphs of unreachable objects alive indefinitely. Python 2.0 added a generational cyclic garbage collector to handle these cases. The details are tricky and worthy of an article in its own right.
CPython is also called the “reference implementation” because new features show up there first, even though they are defined for the generic “Python language.” It’s also the most popular implementation, and typically what people think of when they say “Python.”
Much work has been done over the years to reduce these as much as possible.
It’s even worse than this implies. Debugging concurrency problems is notoriously difficult because the conditions that lead to the bug are nearly impossible to reproduce, and few tools exist to help.
Instrumenting concurrent code to try to capture the behavior can introduce subtle timing differences that hide the problem. The industry has even coined the term, “Heisenbug,” to describe the complexity of this class of bug.
Some extension modules also use the GIL as a conveniently available mutex to protect concurrent access to their own, non-Python resources.
It doesn’t seem possible to completely satisfy this constraint in any attempt to remove the GIL.
I.e., the aforementioned cyclic reference garbage collector.
Such as when the extension module peeks and pokes inside CPython data structures directly or via various macros, instead of using the C API’s functional interfaces.
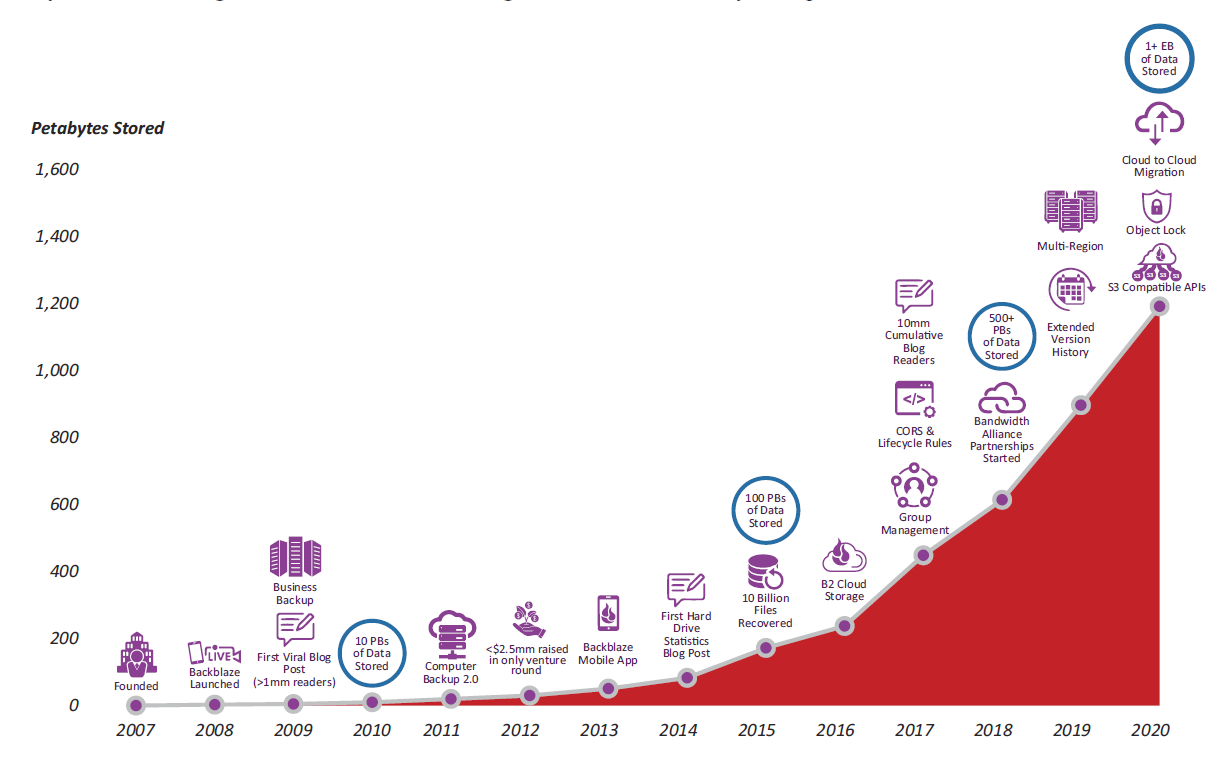
Who doesn’t like birthdays? We definitely do. And we usually celebrate ours on the Backblaze Blog because they’re fun, and we like reminiscing about the time we passed 10 petabytes of data under management and how cute exciting that was (we now have over two exabytes of data storage under management, for context).
But this past year, well, things have been busy! And the last few months have been busier still. Honestly, our 15th anniversary almost slipped right by us. But, we couldn’t let such a milestone go by without marking it somehow.
Today, we thought we’d take a brief look back on our beginnings and where we are now as a public company—a little “how it started/how it’s going” retrospective to celebrate our coming of age—not to pat ourselves on the back, but to celebrate the ways our team and business have grown, especially over the past year.
How It Started
One of the things we’re most proud of is the incredible team we’ve built. Before we founded Backblaze, the five founders and two demi-founders had worked together for 20 years. So, we knew the kind of company we wanted to create when we sat down to hash out what Backblaze would be—a company that’s equally fair and good for its customers, partners, employees, investors, and the greater community.
Five co-founders; two demi-founders; 1,200 square feet; one white board; innumerable Post-Its.
The team today is a lot bigger than it once was (270+ and counting!), but when we started Backblaze, we wanted to create a culture, both internally and externally, of people who cared about each other, cared about their work, and cared about our product. We knew building that kind of culture would lead us authentically to where we are today, and we fiercely protected it. According to afewsources, we’re still doing well on that count.
How It’s Going
So, what have we been up to recently? Thus far in 2022:
We launched Universal Data Migration, a new service that covers all data transfer costs, including legacy provider egress fees, and manages data migration from any legacy on-premises or cloud source.
We enhanced our partner program with two new offerings (in addition to Universal Data Migration, which partners can also take advantage of):
Backblaze B2 Reserve: A predictable, capacity pricing model to empower our Channel Partners.
Backblaze Partner API: A new API that empowers our Alliance Partners to easily integrate and manage B2 Cloud Storage within their products and platforms.
We announced new partnerships with:
CTERA: An enterprise file services platform that extends the capabilities of traditional NAS and file servers to the cloud.
Catalogic: An enterprise and Kubernetes data protection solution.
Kasten by Veeam: A Kubernetes backup and application mobility solution.
We opened our Bug Bounty Program to any security researcher who wants to help us find any vulnerabilities and strengthen the security of our services.
And just a few weeks before 2021 came to a close: We went public on Nasdaq under BLZE.
Blazing it in Times Square.
As much as we’d like to reflect* on more of the great things that happened in our past, we’re more interested in keeping our heads down, working away at what’s next. Stay tuned for the next 15 years.
*If you ARE interested in celebrating some past milestones with us, we put together this nifty chart of some other key milestones that happened between our founding date, 4/20/2007 (yes yes, we were founded on 4/20 with a CEO whose name is Budman, we’ve heard it all before) and when we went public. We thought we’d share it here (obviously we can’t help ourselves, we really do love reminiscing).
Along with the rest of the world, the team at Backblaze is extremely saddened by the humanitarian crisis in Ukraine. To help both the people of Ukraine and our customers who call it home, we are taking three steps:
For our customers in Ukraine, we will be waiving charges for Backblaze services including Computer Backup license charges and B2 Cloud Storage charges until June 1, 2022.
For the people of Ukraine, we are making a monetary donation to Project Hope and United Help Ukraine.
We are promoting these charities to our employees in our philanthropy center, where we will also match their donations.
We share this commitment here in the hopes that it will encourage others to do what they can to help the people of Ukraine.
We hope for a swift and peaceful resolution to this situation. To our customers and the people of Ukraine: We sincerely hope that you and your friends and loved ones can stay healthy and safe.
As you may be aware, a vulnerability was publicly announced recently relating to Log4j, a common logging library widely used by companies around the world.
Our first priority was to make sure our customers’ data is protected and our environment is secure. So, when we learned of this vulnerability affecting Apache Log4j, our security, technical operations, and engineering teams quickly pulled together to establish a protocol for achieving our primary directive.
What is the Log4j vulnerability? As reported by ArsTechnica, a zero-day vulnerability was discovered in the Apache Log4j logging library that enables attackers to take control of vulnerable servers. Log4j is widely used, by everything from Minecraft to iCloud to the National Security Administration, and the Cybersecurity & Infrastructure Security Agency (CISA) urged users to apply patches immediately to address the vulnerabilities.
What actions have we taken?
On Friday, December 10 at approximately 4:30pm PT, Backblaze took services offline in order to protect customer data and roll out security patches across all our systems to address the vulnerability.
12/11/2021 1:05am PT update: Systems are coming back online. While our teams work diligently to bring everything up, you may experience continued service disruptions. Thank you for your patience.
12/11/2021 02:58am PT update: Systems are back online and functioning normally. If you are experiencing any problems, please reach out to our Support Team: https://help.backblaze.com/hc/en-us/requests/new.
SAN MATEO—November 2, 2021. Backblaze, Inc. (“Backblaze”), a leading storage cloud platform, today announced that it has launched the roadshow for its initial public offering. Backblaze has filed a registration statement on Form S-1 with the Securities and Exchange Commission (the “SEC”) to offer 6,250,000 shares of its Class A common stock to the public. In addition, the underwriters will have a 30-day option to purchase up to an additional 937,500 shares of Class A common stock from Backblaze. The initial public offering price is expected to be between $15.00 and $17.00 per share. Backblaze has applied to list its Class A common stock on the Nasdaq Global Market under the ticker symbol “BLZE.”
Oppenheimer & Co., William Blair and Raymond James will act as lead book-running managers for the proposed offering, with JMP Securities and B. Riley Securities acting as joint book-running managers. Lake Street will act as co-manager for the proposed offering.
The offering will be made only by means of a prospectus. Copies of the preliminary prospectus related to the offering may be obtained, when available, from Oppenheimer & Co. Inc., Attention: Syndicate Prospectus Department, 85 Broad St., 26th Floor, New York, NY 10004, by telephone at (212) 667-8055, or by email at [email protected]; William Blair & Company, L.L.C. Attention: Prospectus Department, 150 North Riverside Plaza, Chicago, IL 60606, or by telephone at (800) 621-0687 or by email at [email protected]; or Raymond James & Associates, Inc., 880 Carillon Parkway, St. Petersburg, FL 33716, email: [email protected], telephone: 800-248-8863.
A registration statement relating to the proposed sale of these securities has been filed with the SEC but has not yet become effective. These securities may not be sold, nor may offers to buy be accepted, prior to the time the registration statement becomes effective. This press release shall not constitute an offer to sell or the solicitation of an offer to buy, nor shall there be any sale of these securities in any state or jurisdiction in which such offer, solicitation, or sale would be unlawful prior to registration or qualification under the securities laws of any such state or jurisdiction.
San Mateo, California, October 18, 2021 – Backblaze, Inc. today announced that it has publicly filed a registration statement on Form S-1 with the U.S. Securities and Exchange Commission (“SEC”) relating to a proposed initial public offering of its Class A common stock. The number of shares to be offered and the price range for the offering have not yet been determined. Backblaze intends to list its Class A common stock on the Nasdaq Global Market under the ticker symbol “BLZE.”
Oppenheimer & Co., William Blair and Raymond James will act as lead book-running managers for the proposed offering, with JMP Securities and B. Riley Securities acting as joint book-running managers. Lake Street will act as co-manager for the proposed offering.
The offering will be made only by means of a prospectus. Copies of the preliminary prospectus related to the offering may be obtained, when available, from Oppenheimer & Co. Inc., Attention: Syndicate Prospectus Department, 85 Broad St., 26th Floor, New York, NY 10004, by telephone at (212) 667-8055, or by email at [email protected]; William Blair & Company, L.L.C. Attention: Prospectus Department, 150 North Riverside Plaza, Chicago, IL 60606, or by telephone at (800) 621-0687 or by email at [email protected]; or Raymond James & Associates, Inc., 880 Carillon Parkway, St. Petersburg, FL 33716, email: [email protected], telephone: 800-248-8863.
A registration statement relating to these securities has been filed with the SEC but has not yet become effective. These securities may not be sold, nor may offers to buy be accepted, prior to the time the registration statement becomes effective. This press release shall not constitute an offer to sell or the solicitation of an offer to buy, nor shall there be any sale of these securities in any state or jurisdiction in which such offer, solicitation, or sale would be unlawful prior to registration or qualification under the securities laws of any such state or jurisdiction.
Investors:
James Kisner
Vice President of Investor Relations ir@backblaze.com
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.