Post Syndicated from Lorenzo Ripani original https://aws.amazon.com/blogs/big-data/implement-a-highly-available-key-distribution-center-for-amazon-emr/
High availability (HA) is the property of a system or service to operate continuously without failing for a designated period of time. Implementing HA properties over a system allows you to eliminate single points of failure that usually translate to service disruptions, which can then lead to a business loss or the inability to use a service.
The core idea behind fault tolerance and high availability is very straightforward in terms of definition. You usually use multiple machines to give you redundancy for a specific service. This guarantees that if a host goes down, other machines are able to take over the traffic. Although this might be easy to say, it’s difficult to obtain such a property, especially when working with distributed technologies.
When focusing on Hadoop technologies, the concept of availability multiplies in different layers depending on the frameworks we’re using. To achieve a fault-tolerant system, we need to consider the following layers:
- Data layer
- Processing layer
- Authentication layer
The first two layers are typically handled using native capabilities of the Hadoop framework (such as HDFS High Availability or ResourceManager High Availability) or with the help of features available in the specific framework used (for example, HBase table replication to achieve highly available reads).
The authentication layer is typically managed through the utilization of the Kerberos protocol. Although multiple implementations of Kerberos exist, Amazon EMR uses a free implementation of the Kerberos protocol, which is directly provided by the Massachusetts Institute of Technology (MIT), also referred to as MIT Kerberos.
When looking at the native setup for a key distribution center (KDC), we can see that the tool comes with a typical primary/secondary configuration, where you can configure a primary KDC with one or more additional replicas to provide some features of a highly available system.
However, this configuration doesn’t provide an automatic failover mechanism to elect a new primary KDC in the event of a system interruption. As a result, the failover has to be performed manually or by implementing an automated process, which can be complex to set up.
With AWS native services, we can improve the MIT KDC capabilities to increase the resilience to failures of our system.
Highly available MIT KDC
Amazon EMR provides different architecture options to enable Kerberos authentication, where each of them tries to solve a specific need or use case. Kerberos authentication can be enabled by defining an Amazon EMR security configuration, which is a set of information stored within Amazon EMR itself. This enables you to reuse this configuration across multiple clusters.
When creating an Amazon EMR security configuration, you’re asked to choose between a cluster-dedicated KDC or an external KDC, so it’s important to understand the benefits and limits of each solution.
When you enable the cluster-dedicated KDC, Amazon EMR configures and installs an MIT KDC on the EMR primary node of the cluster that you’re launching. In contrast, when you use an external KDC, the cluster launched relies on a KDC external to the cluster. In this case, the KDC can be a cluster-dedicated KDC of a different EMR cluster that you reference as an external KDC, or a KDC installed on an Amazon Elastic Compute Cloud (Amazon EC2) instance or a container that you own.
The cluster-dedicated KDC is an easy configuration option that delegates the installation and configuration of the KDC service to the cluster itself. This option doesn’t require significant knowledge of the Kerberos system and might be a good option for a test environment. Additionally, having a dedicated KDC in a cluster enables you to segregate the Kerberos realm, thereby providing a dedicated authentication system that can be used only to authenticate a specific team or department in your organization.
However, because the KDC is located on the EMR primary node, you have to consider that if you delete the cluster, the KDC will be deleted as well. Considering the case in which the KDC is shared with other EMR clusters (defined as external KDC in their security configuration), the authentication layer for those will be compromised and as a result all Kerberos enabled frameworks will break. This might be acceptable in test environments, but it’s not recommended for a production one.
Because the KDC lifetime isn’t always bound to a specific EMR cluster, it’s common to use an external KDC located on an EC2 instance or Docker container. This pattern comes with some benefits:
- You can persist end-user credentials in the Kerberos KDC rather than using an Active Directory (although you can also enable a cross-realm trust)
- You can enable communication across multiple EMR clusters, so that all the cluster principals join the same Kerberos realm, thereby enabling a common authentication system for all the clusters
- You can remove the dependency of the EMR primary node, because deleting it will result in an impairment for other systems to authenticate
- If you require a multi-master EMR cluster, then an external KDC is required
That being said, installing an MIT KDC on a single instance doesn’t address our HA requirements, which typically are crucial in a production environment. In the following section, we discuss how we can implement a highly available MIT KDC using AWS services to improve the resiliency of our authentication system.
Architecture overview
The architecture presented in the following diagrams describes a highly available setup across multiple Availability Zones for our MIT Kerberos KDC that uses AWS services. We propose two versions of the architecture: one based on an Amazon Elastic File System (Amazon EFS) file system, and another based on an Amazon FSx for NetApp ONTAP file system.
Both services can be mounted on EC2 instances and used as local paths. Although Amazon EFS is cheaper compared to Amazon FSx for NetApp ONTAP, the latter provides better performance thanks to the sub-millisecond operation latency it provides.
We performed multiple tests to benchmark the solutions involving the different file systems. The following graph shows the results with Amazon EMR 5.36, in which we measured the time in seconds taken by the cluster to be fully up and running when selecting Hadoop and Spark as frameworks.

Looking at the test results, we can see that the Amazon EFS file system is suitable to handle small clusters (fewer than 100 nodes), because the performance degradation introduced by the latency of lock operations on the NFS protocol increases the delay in launching clusters as we add more nodes in our cluster topology. For example, for clusters with 200 nodes, the delay introduced by the Amazon EFS file system is such that some instances can’t join the cluster in time. As a result, those instances are deleted and then replaced, making the entire cluster provisioning slower. This is the reason why we decided not to publish any metric for Amazon EFS for 200 cluster nodes on the preceding graph.
On the other side, Amazon FSx for NetApp ONTAP is able to better handle the increasing number of principals created during the cluster provisioning with reduced performance degradation compared to Amazon EFS.
Even with the solution involving Amazon FSx for NetApp ONTAP, for clusters with a higher number of instances it’s still possible to encounter the behavior described earlier for Amazon EFS. Therefore, for big cluster configurations, this solution should be carefully tested and evaluated.
Amazon EFS based solution
The following diagram illustrates the architecture of our Amazon EFS based solution.

The infrastructure relies on different components to improve the fault tolerance of the KDC. The architecture uses the following services:
- A Network Load Balancer configured to serve Kerberos service ports (port 88 for authentication and port 749 for admin tasks like principals creation and deletion). The purpose of this component is to balance requests across multiple KDC instances located in separate Availability Zones. In addition, it provides a redirection mechanism in case of failures while connecting to an impaired KDC instance.
- An EC2 Auto Scaling group that helps you maintain KDC availability and allows you to automatically add or remove EC2 instances according to conditions you define. For the purpose of this scenario, we define a minimum number of KDC instances equal to two.
- The Amazon EFS file system provides a persistent and reliable storage layer for our KDC database. The service comes with built-in HA properties, so we can take advantage of its native features to obtain a persistent and reliable file system.
- We use AWS Secrets Manager to store and retrieve Kerberos configurations, in specific the password used for the Kadmin service, the Kerberos domain and realm managed by the KDC. With Secrets Manager, we avoid inputting any sensitive information as script parameters or passwords while launching KDC instances.
With this configuration, we eliminate the downsides resulting from a single instance installation:
- The KDC isn’t a single point of failure anymore because failed connections are redirected to healthy KDC hosts
- The lack of Kerberos traffic against the EMR primary node for the authentication will improve the health of our primary node, which might be critical for large Hadoop installations (hundreds of nodes)
- We can recover in case of failures, allowing survived instances to fulfill both admin and authentication operations
Amazon FSx for NetApp ONTAP based solution
The following diagram illustrates the solution using Amazon FSx for NetApp ONTAP.
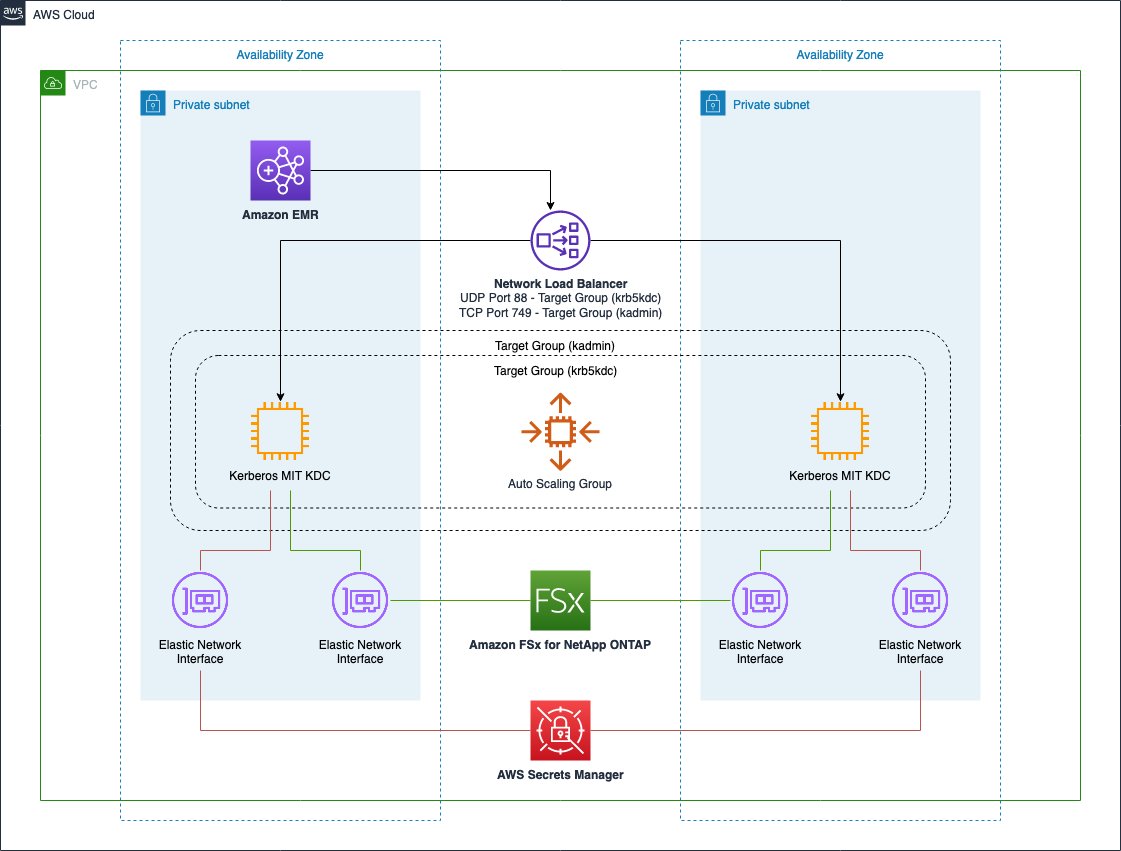
This infrastructure is almost identical compared to the previous one and provides the same benefits. The only difference is the utilization of a Multi-AZ Amazon FSx for NetApp ONTAP file system as a persistent and reliable storage layer for our KDC database. Even in this case, the service comes with built-in HA properties so we can take advantage of its native features to obtain a persistent and reliable file system.
Solution resources
We provide an AWS CloudFormation template in this post as a general guide. You should review and customize it as needed. You should also be aware that some of the resources deployed by this stack incur costs when they remain in use.
The CloudFormation template contains several nested templates. Together, they create the following:
- An Amazon VPC with two public and two private subnets where the KDC instances can be deployed
- An internet gateway attached to the public subnets and a NAT gateway for the private subnets
- An Amazon Simple Storage Service (Amazon S3) gateway endpoint and a Secrets Manager interface endpoint in each subnet
After the VPC resources are deployed, the KDC nested template is launched and provisions the following components:
- Two target groups, each connected to a listener for the specific KDC port to monitor (88 for Kerberos authentication and 749 for Kerberos administration).
- One Network Load Balancer to balance requests across the KDC instances created in different Availability Zones.
- Depending on the chosen file system, an Amazon EFS or Amazon FSx for NetApp ONTAP file system is created across multiple Availability Zones.
- Configuration and auto scaling to provision the KDC instances. In specific, the KDC instances are configured to mount the selected file system on a local folder that is used to store the principals database of the KDC.
At the end of the second template, the EMR cluster is launched with an external KDC set up and, if chosen, a multi-master configuration.
Launch the CloudFormation stack
To launch your stack and provision your resources, complete the following steps:
- Choose Launch Stack:

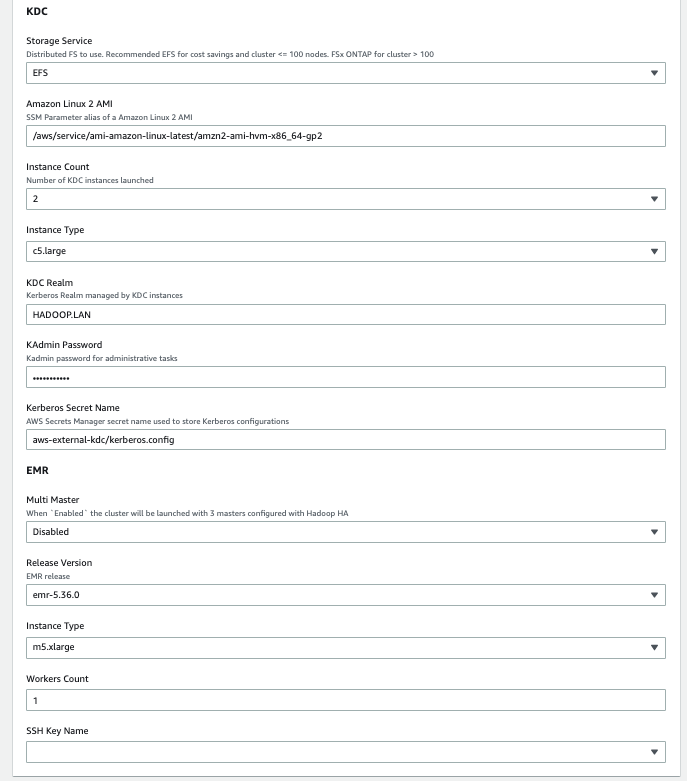
This automatically launches AWS CloudFormation in your AWS account with a template. It prompts you to sign in as needed. You can view the template on the AWS CloudFormation console as required. Make sure that you create the stack in your intended Region. The CloudFormation stack requires a few parameters, as shown in the following screenshot.


The following tables describe the parameters required in each section of the stack. - In the Core section, provide the following parameters:
Parameter Value (Default) Description Project aws-external-kdcThe name of the project for which the environment is deployed. This is used to create AWS tags associated to each resource created in the stack. Artifacts Repository aws-blogs-artifacts-public/artifacts/BDB-1689The Amazon S3 location hosting templates and script required to launch this stack. - In the Networking section, provide the following parameters:
Parameter Value (Default) Description VPC Network 10.0.0.0/16 Network range for the VPC (for example, 10.0.0.0/16). Public Subnet One 10.0.10.0/24 Network range for the first public subnet (for example, 10.0.10.0/24). Public Subnet Two 10.0.11.0/24 Network range for the second public subnet (for example, 10.0.11.0/24). Private Subnet One 10.0.1.0/24 Network range for the private subnet (for example, 10.0.1.0/24). Private Subnet Two 10.0.2.0/24 Network range for the private subnet (for example, 10.0.2.0/24). Availability Zone One (user selected) The Availability Zone chosen to host the first private and public subnets. This should differ from the value used for the Availability Zone Two parameter. Availability Zone Two (user selected) The Availability Zone chosen to host the second private and public subnets. This should differ from the value used for the Availability Zone One parameter. - In the KDC section, provide the following parameters:
Parameter Value (Default) Description Storage Service Amazon EFS Specify the KDC shared file system: Amazon EFS or Amazon FSx for NetApp ONTAP. Amazon Linux 2 AMI /aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2AWS Systems Manager parameter alias to retrieve the latest Amazon Linux 2 AMI. Instance Count 2Number of KDC instances launched. Instance Type c5.largeKDC instance type. KDC Realm HADOOP.LANThe Kerberos realm managed by the external KDC servers. KAdmin Password Password123The password to perform admin operations on the KDC. Kerberos Secret Name aws-external-kdc/kerberos.configSecrets Manager secret name used to store Kerberos configurations. - In the EMR section, provide the following parameters:
Parameter Value (Default) Description Multi Master Disabled When enabled, the cluster is launched with three primaries configured with Hadoop HA. Release Version emr-5.36.0 Amazon EMR release version. (Workers) Instance Type m5.xlarge The EC2 instance type used to provision the cluster. (Workers) Node Count 1 The number of Amazon EMR CORE nodes provisioned while launching the cluster. SSH Key Name (user selected) A valid SSH PEM key that will be attached to the cluster and KDC instances to provide SSH remote access. - Choose Next.
- Add additional AWS tags if required (the solution already uses some predefined AWS tags).
- Choose Next.
- Acknowledge the final requirements.
- Choose Create stack.

Make sure to select different Availability Zones in the Network selection of the template (Availability Zone One and Availability Zone Two). This prevents failures in the event of an impairment for an entire Availability Zone.
Test the infrastructure
After you’ve provisioned the whole infrastructure, it’s time to test and validate our HA setup.
In this test, we simulate an impairment on a KDC instance. As a result, we’ll see how we’re able to keep using remaining healthy KDCs, and we’ll see how the infrastructure self-recovers by adding an additional KDC as a substitution for the failed one.
We performed our tests by launching the CloudFormation stack and specifying two KDC instances and using Amazon EFS as the storage layer for the KDC database. The EMR cluster is launched with 11 CORE nodes.
After we deploy the whole infrastructure, we can connect to the EMR primary node using an SSH connection to perform our tests.

When inside our primary node instance, we can proceed with our test setup.
- First, we create 10 principals inside the KDC database. To do so, create a bash script named create_users.sh with the following content:
- Run the script using the following command:
- We can now verify those 10 principals have been correctly created inside the KDC database. To do so, create another script called
list_users.shand run it as the previous one:The output of the script shows the principals created by the cluster nodes when they’re provisioned, along with our test users just created.
We now run in parallel multiple
kinitrequests and while doing so, we stop thekrb5kdcprocess on one of the two available KDC instances.The test is performed through Spark to achieve high parallelization on the
kinitrequests. - First, create the following script and call it
user_kinit.sh: - Open a
spark-shelland use the--filesparameter to distribute the preceding bash script to all the Spark executors. In addition, we disable the Spark dynamic allocation and launch our application with 10 executors, each using 4 vCores. - We can now run the following Scala statements to initiate our distributed test:
This Spark application creates 1,600 tasks, and each task performs 10
kinitrequests. These tasks are run in parallel in batches of 40 Spark tasks at a time. The final output of our command returns the number of failedkinitrequests.

- We should now connect on the two available KDCs instances. We can connect without SSH keys by using AWS Systems Manager Session Manager because our template doesn’t provide any SSH key to the KDC instances for additional security. To connect on the KDC instances from the Amazon EC2 console using AWS Systems Manager, see Starting a session (Amazon EC2 console).
- On the first KDC, run the following commands to show incoming kinit authentication requests:
The following screenshot shows a sample output.

- On the second KDC, simulate a failure by running the following commands:
- We can now connect to the Amazon EC2 console and open the KDC related target group to confirm that the instance became unhealthy (after the three consecutive health checks failed), and was then deleted and replaced by a new one.
The target group performed the following specific steps during an impairment in one of the services:- The KDC instance enters the unhealthy state
- The unhealthy KDC instance is de-registered from the target group (draining process)
- A new KDC instance is launched
- The new KDC is registered to the target group so that it can start receiving traffic from the load balancer
You might expect to see output similar to the following screenshot while causing an impairment in one of your KDCs.

- If we now connect on the replaced KDC instance, we can see the traffic starting to appear in the
krbr5kdclogs.






At the end of the tests, we have a total number of failed Kerberos authentications.
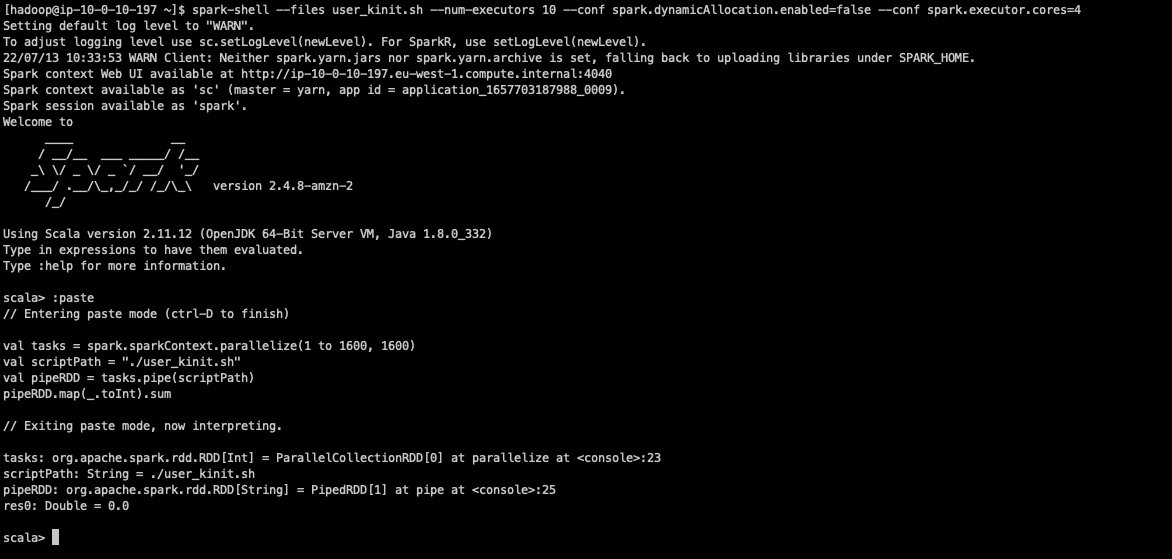
As we can see from the output result, we didn’t get any failure during this test. However, when repeating the test multiple times, you might still expect to see few errors (one or two on average) that might occur due to the krbr5kdc process stopping while some requests are still authenticating.
Note the kinit tool itself doesn’t have any retry mechanism. Both the Hadoop services running on the cluster and the creation of Kerberos principals during EMR instance provisioning are configured to retry if KDC calls fails.
If you want to automate these tests, you might also consider using AWS Fault Injection Simulator, a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resiliency.
Clean up
To clean up all the resources:
- Delete the root stack in AWS CloudFormation.
- After a while from the deletion startup, you should see a failure.
- Click on the VPC nested CloudFormation stack, choose Resources.You should see a single
DELETE_FAILEDentry for the VPC resource. This is due to EMR automatically creating the Default Security Groups and those are preventing the VPC to be deleted by CloudFormation. - Move to the VPC section of the AWS console and delete that VPC manually.
- After that, move back to Cloudformation, select again the root stack and choose Delete. This time the deletion should complete.
File system backups
Both Amazon EFS and Amazon FSx for NetApp ONTAP are natively integrated with AWS Backup.
AWS Backup helps you automate and centrally manage your backups. After you create policy-driven plans, you can monitor the status of ongoing backups, verify compliance, and find and restore backups, all from a central console.
To get more information, refer to Using AWS Backup to back up and restore Amazon EFS file systems and Using AWS Backup with Amazon FSx.
Additional considerations
In this section, we share some additional considerations when using this solution.
Shared file system latency impacts
The utilization of a shared file system implies a degradation of the performance. In particular, the more Kerberos principals that have to be created at the same time, the more we can see a latency on the overall principals creation process and also on the cluster startup time.
This performance degradation is proportional to the number of parallel KDC requests made at the same time. For example, consider the scenario in which we have to launch 10 clusters, each with 20 nodes connected to the same KDC. If we launch all 10 clusters at the same time, we can potentially have 10×20 = 200 parallel connections to the KDC during the initial instance provisioning for the creation of the frameworks related Kerberos principals. In addition, because the duration of Kerberos tickets for services is 10 hours by default, and because all the cluster services are launched more or less at the same time, we could also have the same level of parallelism for service tickets renewal. If, instead, we launch these 10 clusters with a time gap between them, we’ll have potentially 20 parallel connections and as a result the latency introduced by the shared file system isn’t very impactful.
As discussed earlier in this post, multiple clusters can share the same KDC in case they need to communicate between each other without having to set up a cross-realm trust between the related KDCs. Before attaching multiple clusters to the same KDC, you should evaluate if there is a real need for that, because you might also consider segregating Kerberos realms on different KDC instances to obtain better performance and reduce the blast radius in case of issues.
Single-AZ high availability consideration
Although the solutions presented in this post might serve the purpose to provide a highly available MIT KDC across multiple Availability Zones, you might be only interested in providing an HA setup in a single Availability Zone. In this case, for better performance, you might also consider using Amazon FSx for Lustre, or attaching an IO2 EBS disk to multiple KDC instances in the same Availability Zone. In both cases, you might still use the same KDC script used in this post by just modifying the mount command to attach the shared file system on the KDC instances.
If you want to use an IO2 EBS volume as your shared file system, you have to set up a clustered file system to ensure data resiliency and reliability of our KDC database, because standard file systems such as XFS or EXT4 aren’t designed for such use cases. For example, you can use a GFS2 file system to access the KDC database simultaneously across KDC instances. For more details on how to set up a GFS2 file system on EC2 instances, refer to Clustered storage simplified: GFS2 on Amazon EBS Multi-Attach enabled volumes.
Summary
High availability and fault tolerance are key requirements for EMR clusters that can’t tolerate downtime. Analytics workloads run within those clusters can deal with sensitive data, therefore operating in a secured environment is also essential. As a result, we need a secure, highly available, and fault-tolerant setup.
In this post, we showed one possible way of achieving high availability and fault tolerance for the authentication layer of our big data workloads in Amazon EMR. We demonstrated how, by using AWS native services, multiple Kerberos KDCs can operate in parallel and be automatically replaced in case of failures. This, in combination with the framework-specific high availability and fault tolerance capabilities, allows us to operate in a secure, highly available, and fault-tolerant environment.
About the authors
 Lorenzo Ripani is a Big Data Solution Architect at AWS. He is passionate about distributed systems, open source technologies and security. He spends most of his time working with customers around the world to design, evaluate and optimize scalable and secure data pipelines with Amazon EMR.
Lorenzo Ripani is a Big Data Solution Architect at AWS. He is passionate about distributed systems, open source technologies and security. He spends most of his time working with customers around the world to design, evaluate and optimize scalable and secure data pipelines with Amazon EMR.
 Stefano Sandona is an Analytics Specialist Solution Architect with AWS. He loves data, distributed systems and security. He helps customers around the world architecting their data platforms. He has a strong focus on Amazon EMR and all the security aspects around it.
Stefano Sandona is an Analytics Specialist Solution Architect with AWS. He loves data, distributed systems and security. He helps customers around the world architecting their data platforms. He has a strong focus on Amazon EMR and all the security aspects around it.