Post Syndicated from Lorenzo Ripani original https://aws.amazon.com/blogs/big-data/enhance-amazon-emr-scaling-capabilities-with-application-master-placement/
In today’s data-driven world, processing large datasets efficiently is crucial for businesses to gain insights and maintain a competitive edge. Amazon EMR is a managed big data service designed to handle these large-scale data processing needs across the cloud. It allows running applications built using open source frameworks on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), or AWS Outposts, or completely serverless. One of the key features of Amazon EMR on EC2 is managed scaling, which dynamically adjusts computing capacity in response to application demands, providing optimal performance and cost-efficiency.
Although managed scaling aims to optimize EMR clusters for best price-performance and elasticity, some use cases require more granular resource allocation. For example, when multiple applications are submitted to the same clusters, resource contention may occur, potentially impacting both performance and cost-efficiency. Additionally, allocating the Application Master (AM) container to non-reliable nodes like Spot can potentially result in loss of the container and immediate shutdown of the entire YARN application, resulting in wasted resources and additional costs for rescheduling the entire YARN application. These uses cases require more granular resource allocation and sophisticated scheduling policies to optimize resource utilization and maintain high performance.
Starting with the Amazon EMR 7.2 release, Amazon EMR on EC2 introduced a new feature called Application Master (AM) label awareness, which allows users to enable YARN node labels to allocate the AM containers within On-Demand nodes only. Because the AM container is responsible for orchestrating the overall job execution, it’s crucial to verify that it gets allocated to a reliable instance and not be subjected to shutdown due to Spot Instance interruption. Additionally, limiting AM containers to On-Demand helps maintain consistent application launch time, because the fulfillment of the On-Demand Instance isn’t prone to unavailable Spot capacity or bid price.
In this post, we explore the key features and use cases where this new functionality can provide significant benefits, enabling cluster administrators to achieve optimal resource utilization, improved application reliability, and cost-efficiency in your EMR on EC2 clusters.
Solution overview
The Application Master label awareness feature in Amazon EMR works in conjunction with YARN node labels, a functionality offered by Hadoop that empowers you to define labels to nodes within a Hadoop cluster. You can use these labels to determine which nodes of the cluster should host specific YARN containers (such as mappers vs. reducers in a MapReduce, or drivers vs. executors in Apache Spark).
This feature is enabled by default when a cluster is launched with Amazon EMR 7.2.0 and later using Amazon EMR managed scaling, and it has been configured to use YARN node labels. The following code is a basic configuration setup that enables this feature:
Within this configuration snippet, we activate the Hadoop node label feature and define a value for the yarn.node-labels.am.default-node-label-expression property. This property defines the YARN node label that will be used to schedule the AM container of each YARN application submitted to the cluster. This specific container plays a key role in maintaining the lifecycle of the workflow, so verifying its placement on reliable nodes in production workloads is crucial, because the unexpected shutdown of this container can result in the shutdown and failure of the entire application.
Currently, the Application Master label awareness feature only supports two predefined node labels that can be specified to allocate the AM container of a YARN job: ON_DEMAND and CORE. When one of these labels is defined using Amazon EMR configurations (see the preceding example code), Amazon EMR automatically creates the corresponding node labels in YARN and labels the instances in the cluster accordingly.
To demonstrate how this feature works, we launch a sample cluster and run some Spark jobs to see how Amazon EMR managed scaling integrates with YARN node labels.
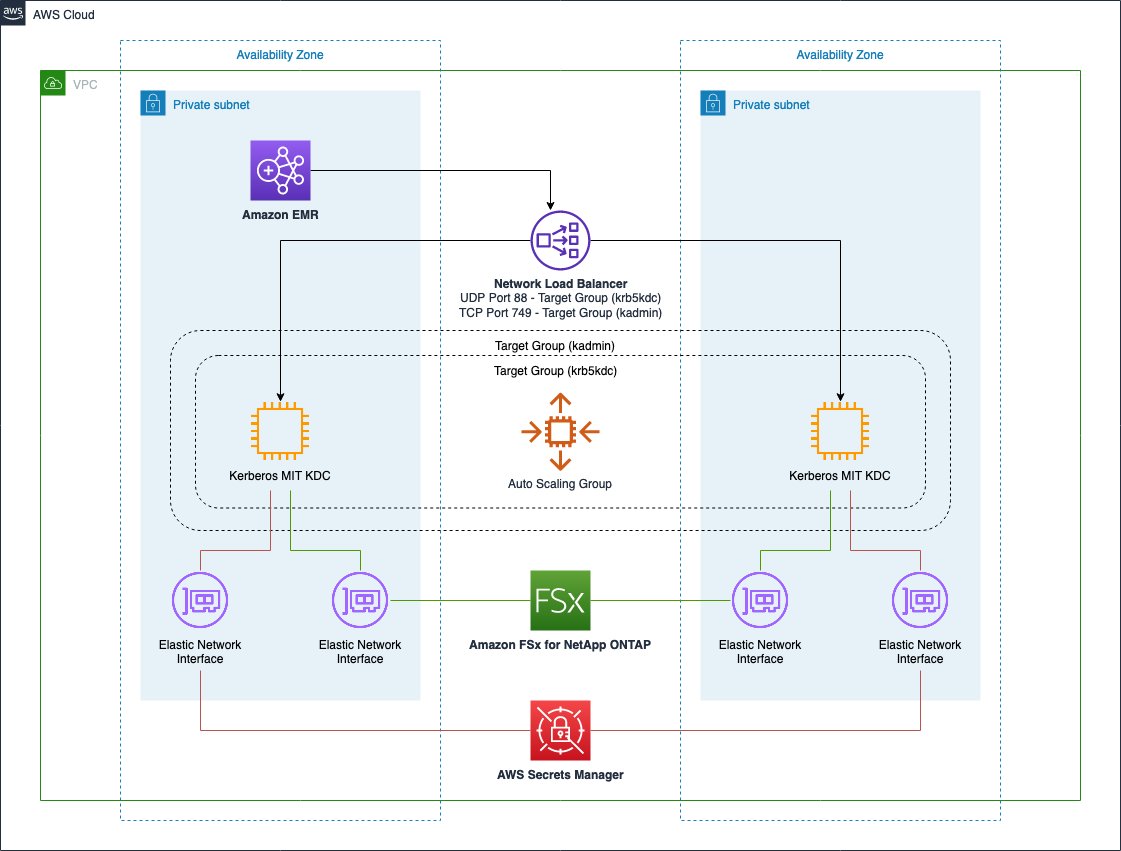
Launch an EMR cluster with Application Manager placement awareness
To perform some tests, you can launch the following AWS CloudFormation stack, which provisions an EMR cluster with managed scaling and the Application Manager placement awareness feature enabled. If this is your first time launching an EMR cluster, make sure to create the Amazon EMR default roles using the following AWS Command Line Interface (AWS CLI) command:
To create the cluster, choose Launch Stack:
![]()
Provide the following required parameters:
- VPC – An existing virtual private cloud (VPC) in your account where the cluster will be provisioned
- Subnet – The subnet in your VPC where you want to launch the cluster
- SSH Key Name – An EC2 key pair that you use to connect to the EMR primary node
After the EMR cluster has been provisioned, establish a tunnel to the Hadoop Resource Manager web UI to review the cluster configurations. To access the Resource Manager web UI, complete the following steps:
- Set up an SSH tunnel to the primary node using dynamic port forwarding.
- Point your browser to the URL
http://<primary-node-public-dns>:8088/, using the public DNS name of your cluster’s primary node.
This will open the Hadoop Resource Manager web UI, where you can see how the cluster has been configured.
YARN node labels
In the CloudFormation stack, you launched a cluster specifying to allocate the AM containers on nodes labeled as ON_DEMAND. If you explore the Resource Manager web UI, you can see that Amazon EMR created two labels in the cluster: ON_DEMAND and SPOT. To review the YARN node labels present in your cluster, you can inspect the Node Labels page, as shown in the following screenshot.

On this page, you can see how the YARN labels were created in Amazon EMR:
- During initial cluster creation, default node labels such as
ON_DEMANDandSPOTare automatically generated as non-exclusive partitions - The
DEFAULT_PARTITIONlabel stays vacant because every node gets labeled based on its market type—either being an On-Demand or Spot Instance
In our example, because we launched a single core node as On-Demand, you can observe a single node assigned to the ON_DEMAND partition, and the SPOT partition remains empty. Because the labels are created as non-exclusive, nodes with these labels can run both containers launched with a specific YARN label and also containers that don’t specify a YARN label. For additional details on YARN node labels, see YARN Node Labels in the Hadoop documentation.
Now that we have discussed how the cluster was configured, we can perform some tests to validate and review the behavior of this feature when using it in combination with managed scaling.
Concurrent application submission with Spot Instances
To test the managed scaling capabilities, we submit a simple SparkPi job configured to utilize all available memory on the single core node initially launched in our cluster:
In the preceding snippet, we tuned specific Spark configurations to utilize all the resources of the cluster nodes launched (you could also achieve this using the maximizeResourceAllocation configuration while launching an EMR cluster). Because the cluster has been launched using m5.xlarge instances, we can launch individual containers up to 12 GB in terms of memory requirements. With these assumptions, the snippet configures the following:
- The Spark driver and executors were configured with 10 GB of memory to utilize most of the available memory on the node, in order to have a single container running on each node of our cluster and simplify this example.
- The
node-labels.am.default-node-label-expressionparameter was set toON_DEMAND, making sure the Spark driver is automatically allocated to theON_DEMANDpartition of our cluster. Because we specified this configuration while launching the cluster, the AM containers are automatically requested to be scheduled onON_DEMANDlabeled instances, so we don’t need to specify it at the job level. - The
yarn.executor.nodeLabelExpression=SPOTconfiguration verifies that the executors operated exclusively on TASK nodes using Spot Instances. Removing this configuration allows the Spark executors to be scheduled both onSPOTandON_DEMANDlabeled nodes. - The
dynamicAllocation.maxExecutorssetting was set to 1 to delay the processing time of the application and observe the scaling behavior when multiple YARN applications were submitted concurrently in the same cluster.
As the application transitioned to a RUNNING state, we can verify from the YARN Resource Manager UI that its driver placement was automatically assigned to the ON_DEMAND partition of our cluster (see the following screenshot).

Additionally, upon inspecting the YARN scheduler page, we can see that our SPOT partition doesn’t have a resource associated with it because the cluster was launched with just one On-Demand Instance.

Because the cluster didn’t have Spot Instances initially, you can observe from the Amazon EMR console that managed scaling generates a new Spot task group to accommodate the Spark executor requested to run on Spot nodes only (see the following screenshot) . Before this integration, managed scaling didn’t take into account the YARN labels requested by an application, potentially leading to unpredictable scaling behaviors. With this release, managed scaling now considers the YARN labels specified by applications, enabling more predictable and accurate scaling decisions.

While waiting for the launch of the new Spot node, we submitted another SparkPi job with identical specifications. However, because the memory required to allocate the new Spark Driver was 10 GB and such resources were currently unavailable in the ON_DEMAND partition, the application remained in a pending state until resources became available to schedule its container.
Upon detecting the lack of resources to allocate the new Spark driver, Amazon EMR managed scaling commenced scaling the core instance group (On-Demand Instances in our cluster) by launching a new core node. After the new core node was launched, YARN promptly allocated the pending container on the new node, enabling the application to start its processing. Subsequently, the application requested additional Spot nodes to allocate its own executors (see the following screenshot).

This example demonstrates how managed scaling and YARN labels work together to improve the resiliency of YARN applications, while using cost-effective job executions over Spot Instances.
When to use Application Manager placement awareness and managed scaling
You can use this placement awareness feature to improve cost-efficiency by using Spot Instances while protecting the Application Manager from being incorrectly shut down due to Spot interruptions. It’s particularly useful when you want to take advantage of the cost savings offered by Spot Instances while preserving the stability and reliability of your jobs running on the cluster. When working with managed scaling and the placement awareness feature, consider the following best practices:
- Maximum cost-efficiency for non-critical jobs – If you have jobs that don’t have strict service level agreement (SLA) requirements, you can force all Spark executors to run on Spot Instances for maximum cost savings. This can be achieved by setting the following Spark configuration:
- Resilient execution for production jobs – For production jobs where you require a more resilient execution, you might consider not setting the
yarn.executor.nodeLabelExpressionparameter. When no label is specified, executors are dynamically allocated between both On-Demand and Spot nodes, providing a more reliable execution. - Limit dynamic allocation for concurrent applications – When working with managed scaling and clusters with multiple applications running concurrently (for example, an interactive cluster with concurrent user utilization), you should consider setting a maximum limit for Spark dynamic allocation using the
dynamicAllocation.maxExecutorssetting. This can help manage resources over-provisioning and facilitate predictable scaling behavior across applications running on the same cluster. For more details, see Dynamic Allocation in the Spark documentation. - Managed scaling configurations – Make sure your managed scaling configurations are set up correctly to facilitate efficient scaling of Spot Instances based on your workload requirements. For example, set an appropriate value for Maximum On-Demand instances in managed scaling based on the number of concurrent applications you want to run on the cluster. Additionally, if you’re planning to use your On-Demand Instances for running solely AM containers, we recommend setting
scheduler.capacity.maximum-am-resource-percentto 1 using the Amazon EMR capacity-scheduler classification. - Improve startup time of the nodes – If your cluster is subject to frequent scaling events (for example, you have a long-running cluster that can run multiple concurrent EMR steps), you might want to optimize the startup time of your cluster nodes. When trying to get an efficient node startup, consider only installing the minimum required set of application frameworks in the cluster and, whenever possible, avoid installing non-YARN frameworks such as HBase or Trino, which might delay the startup of processing nodes dynamically attached by Amazon EMR managed scaling. Finally, whenever possible, don’t use complex and time-consuming EMR bootstrap actions to avoid increasing the startup time of nodes launched with managed scaling.
By following these best practices, you can take advantage of the cost savings of Spot Instances while maintaining the stability and reliability of your applications, particularly in scenarios where multiple applications are running concurrently on the same cluster.
Conclusion
In this post, we explored the benefits of the new integration between Amazon EMR managed scaling and YARN node labels, reviewed its implementation and usage, and defined a few best practices that can help you get started. Whether you’re running batch processing jobs, stream processing applications, or other YARN workloads on Amazon EMR, this feature can help you achieve substantial cost savings without compromising on performance or reliability.
As you embark on your journey to use Spot Instances in your EMR clusters, remember to follow the best practices outlined in this post, such as setting appropriate configurations for dynamic allocation, node label expressions, and managed scaling policies. By doing so, you can make sure that your applications run efficiently, reliably, and at the lowest possible cost.
About the authors
 Lorenzo Ripani is a Big Data Solution Architect at AWS. He is passionate about distributed systems, open source technologies and security. He spends most of his time working with customers around the world to design, evaluate and optimize scalable and secure data pipelines with Amazon EMR.
Lorenzo Ripani is a Big Data Solution Architect at AWS. He is passionate about distributed systems, open source technologies and security. He spends most of his time working with customers around the world to design, evaluate and optimize scalable and secure data pipelines with Amazon EMR.
 Miranda Diaz is a Software Development Engineer for EMR at AWS. Miranda works to design and develop technologies that make it easy for customers across the world to automatically scale their computing resources to their needs, helping them achieve the best performance at the optimal cost.
Miranda Diaz is a Software Development Engineer for EMR at AWS. Miranda works to design and develop technologies that make it easy for customers across the world to automatically scale their computing resources to their needs, helping them achieve the best performance at the optimal cost.
 Sajjan Bhattarai is a Senior Cloud Support Engineer at AWS, and specializes in BigData and Machine Learning workloads. He enjoys helping customers around the world to troubleshoot and optimize their data platforms.
Sajjan Bhattarai is a Senior Cloud Support Engineer at AWS, and specializes in BigData and Machine Learning workloads. He enjoys helping customers around the world to troubleshoot and optimize their data platforms.
 Bezuayehu Wate is an Associate Big Data Specialist Solutions Architect at AWS. She works with customers to provide strategic and architectural guidance on designing, building, and modernizing their cloud-based analytics solutions using AWS.
Bezuayehu Wate is an Associate Big Data Specialist Solutions Architect at AWS. She works with customers to provide strategic and architectural guidance on designing, building, and modernizing their cloud-based analytics solutions using AWS.