Post Syndicated from Jan Michael Go Tan original https://aws.amazon.com/blogs/big-data/use-an-event-driven-architecture-to-build-a-data-mesh-on-aws/
In this post, we take the data mesh design discussed in Design a data mesh architecture using AWS Lake Formation and AWS Glue, and demonstrate how to initialize data domain accounts to enable managed sharing; we also go through how we can use an event-driven approach to automate processes between the central governance account and data domain accounts (producers and consumers). We build a data mesh pattern from scratch as Infrastructure as Code (IaC) using AWS CDK and use an open-source self-service data platform UI to share and discover data between business units.
The key advantage of this approach is being able to add actions in response to data mesh events such as permission management, tag propagation, search index management, and to automate different processes.
Before we dive into it, let’s look at AWS Analytics Reference Architecture, an open-source library that we use to build our solution.
AWS Analytics Reference Architecture
AWS Analytics Reference Architecture (ARA) is a set of analytics solutions put together as end-to-end examples. It regroups AWS best practices for designing, implementing, and operating analytics platforms through different purpose-built patterns, handling common requirements, and solving customers’ challenges.
ARA exposes reusable core components in an AWS CDK library, currently available in Typescript and Python. This library contains AWS CDK constructs (L3) that can be used to quickly provision analytics solutions in demos, prototypes, proofs of concept, and end-to-end reference architectures.
The following table lists data mesh specific constructs in the AWS Analytics Reference Architecture library.
| Construct Name | Purpose |
| CentralGovernance | Creates an Amazon EventBridge event bus for central governance account that is used to communicate with data domain accounts (producer/consumer). Creates workflows to automate data product registration and sharing. |
| DataDomain | Creates an Amazon EventBridge event bus for data domain account (producer/consumer) to communicate with central governance account. It creates data lake storage (Amazon S3), and workflow to automate data product registration. It also creates a workflow to populate AWS Glue Catalog metadata for newly registered data product. |
You can find AWS CDK constructs for the AWS Analytics Reference Architecture on Construct Hub.
In addition to ARA constructs, we also use an open-source Self-service data platform (User Interface). It is built using AWS Amplify, Amazon DynamoDB, AWS Step Functions, AWS Lambda, Amazon API Gateway, Amazon EventBridge, Amazon Cognito, and Amazon OpenSearch. The frontend is built with React. Through the self-service data platform you can: 1) manage data domains and data products, and 2) discover and request access to data products.
Central Governance and data sharing
For the governance of our data mesh, we will use AWS Lake Formation. AWS Lake Formation is a fully managed service that simplifies data lake setup, supports centralized security management, and provides transactional access on top of your data lake. Moreover, it enables data sharing across accounts and organizations. This centralized approach has a number of key benefits, such as: centralized audit; centralized permission management; and centralized data discovery. More importantly, this allows organizations to gain the benefits of centralized governance while taking advantage of the inherent scaling characteristics of decentralized data product management.
There are two ways to share data resources in Lake Formation: 1) Named Based Access Control (NRAC), and 2) Tag-Based Access Control (LF-TBAC). NRAC uses AWS Resource Access Manager (AWS RAM) to share data resources across accounts. Those are consumed via resource links that are based on created resource shares. Tag-Based Access Control (LF-TBAC) is another approach to share data resources in AWS Lake Formation, that defines permissions based on attributes. These attributes are called LF-tags. You can read this blog to learn about LF-TBAC in the context of data mesh.
The following diagram shows how NRAC and LF-TBAC data sharing works. In this example, data domain is registered as a node on mesh and therefore we create two databases in the central governance account. NRAC database is shared with data domain via AWS RAM. Access to data products that we register in this database will be handled through NRAC. LF-TBAC database is tagged with data domain N line of business (LOB) LF-tag: <LOB:N>. LOB tag is automatically shared with data domain N account and therefore database is available in that account. Access to Data Products in this database will be handled through LF-TBAC.
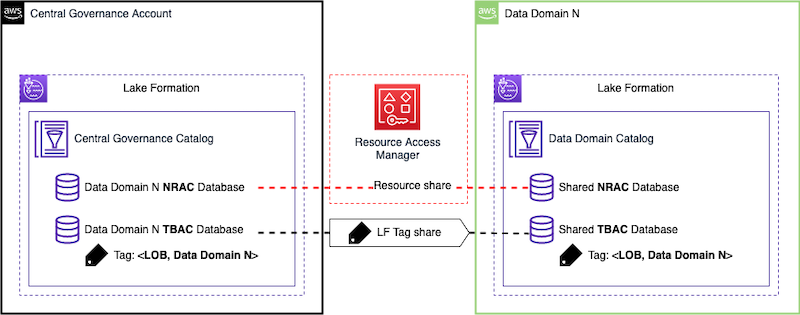
In our solution we will demonstrate both NRAC and LF-TBAC approaches. With the NRAC approach, we will build up an event-based workflow that would automatically accept RAM share in the data domain accounts and automate the creation of the necessary metadata objects (eg. local database, resource links, etc). While with the LF-TBAC approach, we rely on permissions associated with the shared LF-Tags to allow producer data domains to manage their data products, and consumer data domains read access to the relevant data products associated with the LF-Tags that they requested access to.
We use CentralGovernance construct from ARA library to build a central governance account. It creates an EventBridge event bus to enable communication with data domain accounts that register as nodes on mesh. For each registered data domain, specific event bus rules are created that route events towards that account. Central governance account has a central metadata catalog that allows for data to be stored in different data domains, as opposed to a single central lake. For each registered data domain, we create two separate databases in central governance catalog to demonstrate both NRAC and LF-TBAC data sharing. CentralGovernance construct creates workflows for data product registration and data product sharing. We also deploy a self-service data platform UI to enable good user experience to manage data domains, data products, and to simplify data discovery and sharing.

A data domain: producer and consumer
We use DataDomain construct from ARA library to build a data domain account that can be either producer, consumer, or both. Producers manage the lifecycle of their respective data products in their own AWS accounts. Typically, this data is stored in Amazon Simple Storage Service (Amazon S3). DataDomain construct creates a data lake storage with cross-account bucket policy that enables central governance account to access the data. Data is encrypted using AWS KMS, and central governance account has a permission to use the key. Config secret in AWS Secrets Manager contains all the necessary information to register data domain as a node on mesh in central governance. It includes: 1) data domain name, 2) S3 location that holds data products, and 3) encryption key ARN. DataDomain construct also creates data domain and crawler workflows to automate data product registration.
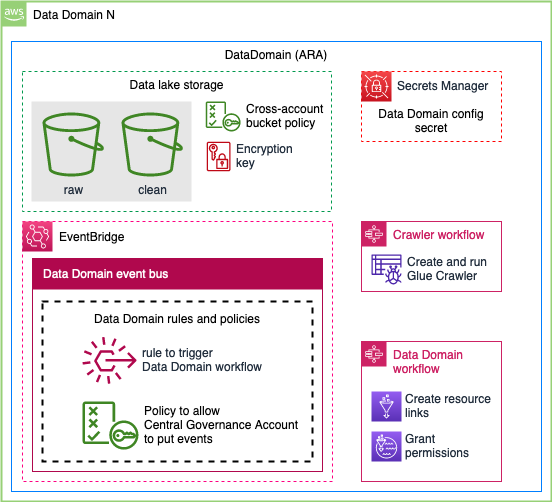
Creating an event-driven data mesh
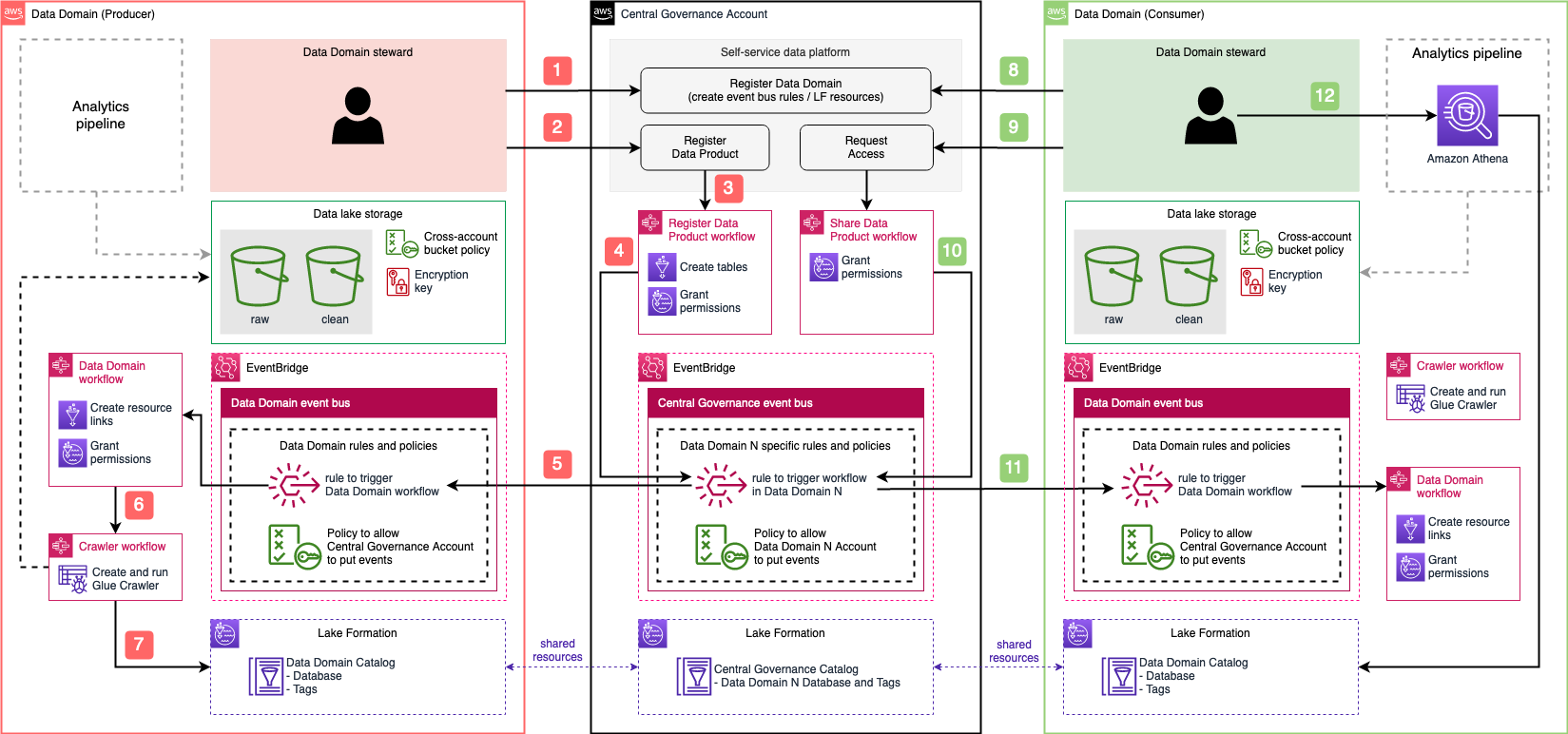
Data mesh architectures typically require some level of communication and trust policy management to maintain least privileges of the relevant principals between the different accounts (for example, central governance to producer, central governance to consumer). We use event-driven approach via EventBridge to securely forward events from one event bus to event bus in another account while maintaining the least privilege access. When we register data domain to central governance account through the self-service data platform UI, we establish bi-directional communication between the accounts via EventBridge. Domain registration process also creates database in the central governance catalog to hold data products for that particular domain. Registered data domain is now a node on mesh and we can register new data products.
The following diagram shows data product registration process:

- Starts Register Data Product workflow that creates an empty table (the schema is managed by the producers in their respective producer account). This workflow also grants a cross-account permission to the producer account that allows producer to manage the schema of the table.
- When complete, this emits an event into the central event bus.
- The central event bus contains a rule that forwards the event to the producer’s event bus. This rule was created during the data domain registration process.
- When the producer’s event bus receives the event, it triggers the Data Domain workflow, which creates resource-links and grants permissions.
- Still in the producer account, Crawler workflow gets triggered when the Data Domain workflow state changes to Successful. This creates the crawler, runs it, waits and checks if the crawler is done, and deletes the crawler when it’s complete. This workflow is responsible for populating tables’ schemas.
Now other data domains can find newly registered data products using the self-service data platform UI and request access. The sharing process works in the same way as product registration by sending events from the central governance account to consumer data domain, and triggering specific workflows.
Solution Overview
The following high-level solution diagram shows how everything fits together and how event-driven architecture enables multiple accounts to form a data mesh. You can follow the workshop that we released to deploy the solution that we covered in this blog post. You can deploy multiple data domains and test both data registration and data sharing. You can also use self-service data platform UI to search through data products and request access using both LF-TBAC and NRAC approaches.
Conclusion
Implementing a data mesh on top of an event-driven architecture provides both flexibility and extensibility. A data mesh by itself has several moving parts to support various functionalities, such as onboarding, search, access management and sharing, and more. With an event-driven architecture, we can implement these functionalities in smaller components to make them easier to test, operate, and maintain. Future requirements and applications can use the event stream to provide their own functionality, making the entire mesh much more valuable to your organization.
To learn more how to design and build applications based on event-driven architecture, see the AWS Event-Driven Architecture page. To dive deeper into data mesh concepts, see the Design a Data Mesh Architecture using AWS Lake Formation and AWS Glue blog.
If you’d like our team to run data mesh workshop with you, please reach out to your AWS team.
About the authors

Jan Michael Go Tan is a Principal Solutions Architect for Amazon Web Services. He helps customers design scalable and innovative solutions with the AWS Cloud.

Dzenan Softic is a Senior Solutions Architect at AWS. He works with startups to help them define and execute their ideas. His main focus is in data engineering and infrastructure.

David Greenshtein is a Specialist Solutions Architect for Analytics at AWS with a passion for ETL and automation. He works with AWS customers to design and build analytics solutions enabling business to make data-driven decisions. In his free time, he likes jogging and riding bikes with his son.
 Vincent Gromakowski is an Analytics Specialist Solutions Architect at AWS where he enjoys solving customers’ analytics, NoSQL, and streaming challenges. He has a strong expertise on distributed data processing engines and resource orchestration platform.
Vincent Gromakowski is an Analytics Specialist Solutions Architect at AWS where he enjoys solving customers’ analytics, NoSQL, and streaming challenges. He has a strong expertise on distributed data processing engines and resource orchestration platform.