Post Syndicated from Jon Roberts original https://aws.amazon.com/blogs/big-data/part-3-migrate-a-large-data-warehouse-from-greenplum-to-amazon-redshift-using-aws-sct/
In this third post of a multi-part series, we explore some of the edge cases in migrating a large data warehouse from Greenplum to Amazon Redshift using AWS Schema Conversion Tool (AWS SCT) and how to handle these challenges. Challenges include how best to use virtual partitioning, edge cases for numeric and character fields, and arrays.
You can check out the first post of this series for guidance on planning, running, and validating the migration. You can also check out the second post for best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns.
Unbounded character data type
Greenplum supports creating columns as text and varchar without specifying the length of the field. This works without an issue in Greenplum but doesn’t work well in migrating to Amazon Redshift. Amazon Redshift stores data in columnar format and gets better compression when using shorter column lengths. Therefore, the Amazon Redshift best practice is to use the smallest character length possible.
AWS SCT will convert these unbounded fields as large objects (LOBs) instead of treating the columns as character fields with a specified length. LOBs are implemented differently in each database product on the market, but in general, a LOB is not stored with the rest of the table data. Instead, there is a pointer to the location of the data. When the LOB is queried, the database reconstitutes the data automatically for you, but this typically requires more resources.
Amazon Redshift doesn’t support LOBs, so AWS SCT resolves this by loading the data into Amazon Simple Storage Service (Amazon S3) and in the column, it stores the S3 URL. When you need to retrieve this data, you have to query the table, get the S3 URL, and then fetch the data from Amazon S3. This isn’t ideal because most of the time, the actual maximum length of the field doesn’t require it to be treated as a LOB, and storing the data remotely means it will take much longer to fetch the data for queries.
The current resolution is to calculate the maximum length of these columns and update the Greenplum tables before converting to Amazon Redshift with AWS SCT.
Note that in a future release of AWS SCT, the collection of statistics will include calculating the maximum length for each column, and the conversion of unbounded varchar and text will set the length in Amazon Redshift automatically.
The following code is an example of an unbounded character data type:
This table uses a primary key column on an unbounded text column. This needs to be converted to varchar(n), where n is the maximum length found in this column.
- Drop unique constraints on affected columns:
- Drop indexes on affected columns:
- Calculate maximum length of affected columns:
Note that in this example, the description1 and description2 columns only contain NULL values, or the table doesn’t have any data in it, or the calculated length of the columns is 10.
- Alter the length of the affected columns:
You can now proceed with using AWS SCT to convert the Greenplum schema to Amazon Redshift and avoiding using LOBs to store the column values.
GitHub help
If you have many tables to update and want an automated solution, you can use the add_varchar_lengths.sh script found in the GitHub repo to fix all of the unbounded varchar and text columns in a given schema in Greenplum. The script calculates the appropriate maximum length and then alters the Greenplum tables so the varchar data type is bounded by a length.
Please note that the script also will drop any constraints or indexes on the affected columns.
Empty character data
Greenplum and Amazon Redshift support an empty string value in a field that is different from NULL. The behavior is the same between the two databases. However, AWS SCT defaults to convert empty strings to NULL. This simply needs to be disabled to avoid problems.
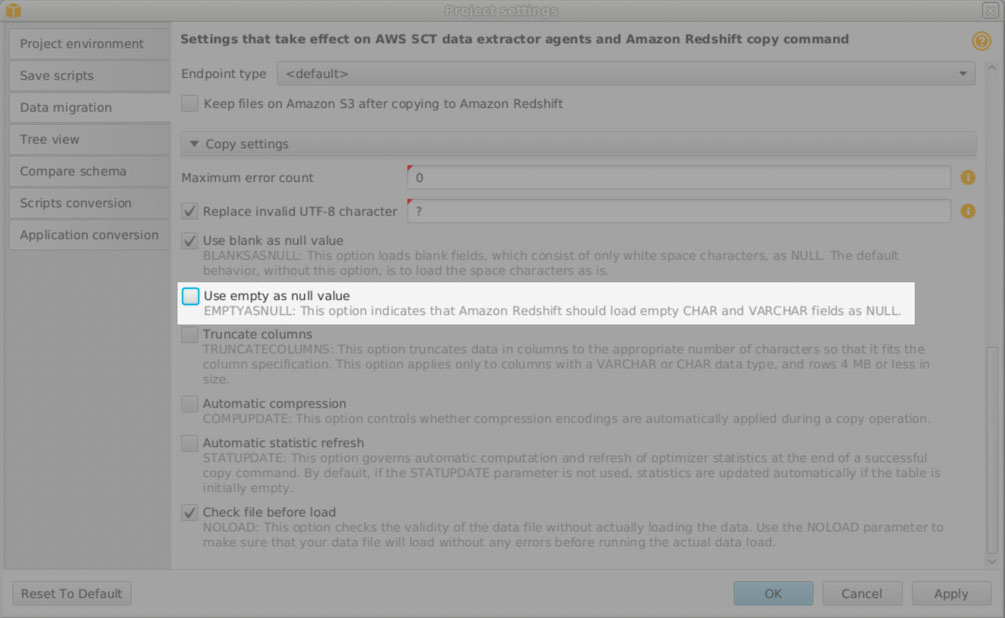
- In AWS SCT, open your project, choose Settings, Project settings, and Data migration.
- Scroll to the bottom and find Use empty as null value.
- Deselect this so that AWS SCT doesn’t convert empty strings to NULL.
NaN and Infinity numeric data type
Greenplum supports NaN and Infinity in a numeric field to represent an undefined calculation result and infinity. NaN is very uncommon because when using aggregate functions on a column with a NaN row, the result will also be NaN. Infinity is also uncommon and not useful when aggregating data. However, you may encounter these values in a Greenplum database.
Amazon Redshift doesn’t support NaN and Infinity, and AWS SCT doesn’t check for this in your data. If you do encounter this when using AWS SCT, the task will fail with a numeric conversion error.
To resolve this, it’s suggested to use NULL instead of NaN and Infinity. This allows you to aggregate data and get results other than NaN and, importantly, allow you to convert the Greenplum data to Amazon Redshift.
The following code is an example NaN numeric value:
- Drop the NOT NULL constraint:
- Update the table:
You can now proceed with using AWS SCT to migrate the Greenplum data to Amazon Redshift.
Note that in a future release of AWS SCT, there will be an option to convert NaN and Infinity to NULL so that you won’t have to update your Greenplum data to migrate to Amazon Redshift.
Virtual partitioning on GP_SEGMENT_ID
For large tables, it’s recommended to use virtual partitioning to extract data from Greenplum. Without virtual partitioning, AWS SCT will run a single query to unload data from Greenplum. For example:
If this table is very large, it will take a long time to extract the data because this is a single process querying the data. With virtual partitioning, multiple queries are run in parallel so that the extraction of data is completed faster. It also makes it easier to recover if there is an issue with the task.
Virtual partitioning is very flexible, but a simple way to do this in Amazon Redshift is to utilize the Greenplum hidden column gp_segment_id. This column identifies which segment in Greenplum has the data, and each segment should have an equal number of rows. Therefore, creating partitions for each gp_segment_id is an easy way to implement virtual partitioning.
If you’re not familiar with the term segment, it’s similar to an Amazon Redshift slice.
For example:
- First, determine the number of segments in Greenplum:
Now you can configure AWS SCT.
- In AWS SCT, go to Data Migration view (other) and choose (right-click) a large table.
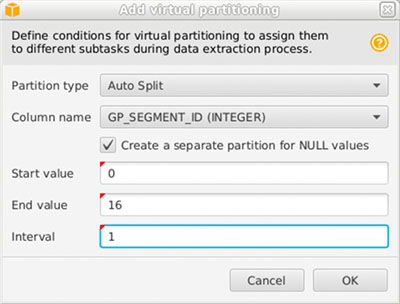
- Scroll down to Add virtual partitioning.
- For the partition type, choose Auto Split and change the column name to
GP_SEGMENT_ID. - Use
0for Start value, the number of segments found in Step 1 as End value, and Interval of1.
When you create a local task to load this table, the task will have a sub-task for each gp_segment_id value.
Note that in a future release of AWS SCT, there will be an option to automatically virtually partition tables based on GP_SEGMENT_ID. This option will also retrieve the number of segments automatically.
Arrays
Greenplum supports arrays such as bigint[] that are unbounded. Typically, arrays are kept relatively small in Greenplum because arrays consume more memory in Greenplum than using an alternative strategy. However, it’s possible to have a very large array in Greenplum that isn’t supported by Amazon Redshift.
AWS SCT converts a Greenplum array to varchar(65535), but if the converted array is longer than 65,535 characters, then the load will fail.
The following code is an example of a large array:
In this example, the sales items are stored in an array for each sales_id. If you encounter an error while loading that the length is too long to load this data into Amazon Redshift with AWS SCT, then this is the solution. It’s also a more efficient pattern to store data in both Greenplum and Amazon Redshift!
- Create a new sales table that has all columns from the existing sales table, but exclude the array column:
- Populate the new sales table with the existing data except for the array column:
We create a new table that is a cross-reference of sales IDs with the sales items. Instead of having a single row for this association, now there will be a row for each relationship.
- Create a new sales item table:
- To unnest the array, create a row for each array element:
- Rename the sales tables:
In AWS SCT, refresh the tables and migrate the revised sales and the new sales_items table.
The following are some example queries before and after.
Before:
After:
Before:
After:
VACUUM ANALYZE
Greenplum, like Amazon Redshift, supports the VACUUM command, which reclaims storage space after UPDATE and DELETE commands are run on a table. Greenplum also allows you to add the ANALYZE option to run both statements with a single command.
The following code is the Greenplum command:
This is not very common, but you’ll see this from time to time. If you’re just inserting data into a table, there is no need to run VACUUM, but for ease of use, sometimes developers will use VACUUM ANALYZE.
The following are the Amazon Redshift commands:
Amazon Redshift doesn’t support adding ANALYZE to the VACUUM command, so instead, this needs to be two different statements. Also note that Amazon Redshift performs VACUUM and ANALYZE automatically for you so in most cases, you can remove these commands from your scripts entirely.
DISTINCT ON query
Greenplum supports an unusual shortcut for eliminating duplicates in a table. This feature keeps the first row for each set of rows based on the order of the data being fetched. It’s easiest to understand by looking at an example:
We get the following results:
The solution for running this in Amazon Redshift is to use the ANSI standard row_number() analytical function, as shown in the following code:
Clean up
The examples in this post create tables in Greenplum. To remove these example tables, run the following commands:
Conclusion
In this post, we covered some of the edge cases when migrating Greenplum to Amazon Redshift and how to handle these challenges, including easy virtual partitioning, edge cases for numeric and character fields, and arrays. This is not an exhaustive list of migrating Greenplum to Amazon Redshift, but this series should help you navigate modernizing your data platform by moving to Amazon Redshift.
For additional details, see the Amazon Redshift Getting Started Guide and the AWS SCT User Guide.
About the Authors
 Jon Roberts is a Sr. Analytics Specialist based out of Nashville, specializing in Amazon Redshift. He has over 27 years of experience working in relational databases. In his spare time, he runs.
Jon Roberts is a Sr. Analytics Specialist based out of Nashville, specializing in Amazon Redshift. He has over 27 years of experience working in relational databases. In his spare time, he runs.
 Nelly Susanto is a Senior Database Migration Specialist of AWS Database Migration Accelerator. She has over 10 years of technical experience focusing on migrating and replicating databases along with data warehouse workloads. She is passionate about helping customers in their cloud journey.
Nelly Susanto is a Senior Database Migration Specialist of AWS Database Migration Accelerator. She has over 10 years of technical experience focusing on migrating and replicating databases along with data warehouse workloads. She is passionate about helping customers in their cloud journey.
 Suresh Patnam is a Principal BDM – GTM AI/ML Leader at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible by leveraging Data & AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Principal BDM – GTM AI/ML Leader at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible by leveraging Data & AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.