Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/nts-reliable-device-testing-at-scale-43139ae05382
By Benson Ma, ZZ Zimmerman
With contributions from Alok Ahuja, Shravan Heroor, Michael Krasnow, Todor Minchev, Inder Singh
Introduction
At Netflix, we test hundreds of different device types every day, ranging from streaming sticks to smart TVs, to ensure that new version releases of the Netflix SDK continue to provide the exceptional Netflix experience that our customers expect. We also collaborate with our Partners to integrate the Netflix SDK onto their upcoming new devices, such as TVs and set top boxes. This program, known as Partner Certification, is particularly important for the business because device expansion historically has been crucial for new Netflix subscription acquisitions. The Netflix Test Studio (NTS) platform was created to support Netflix SDK testing and Partner Certification by providing a consistent automation solution for both Netflix and Partner developers to deploy and execute tests on “Netflix Ready” devices.
Over the years, both Netflix SDK testing and Partner Certification have gradually transitioned upstream towards a shift-left testing strategy. This requires the automation infrastructure to support large-scale CI, which NTS was not originally designed for. NTS 2.0 addresses this very limitation of NTS, as it has been built by taking the learnings from NTS 1.0 to re-architect the system into a platform that significantly improves reliable device testing at scale while maintaining the NTS user experience.
Background
The Test Workflow in NTS
We first describe the device testing workflow in NTS at a high level.
Tests: Netflix device tests are defined as scripts that run against the Netflix application. Test authors at Netflix write the tests and register them into the system along with information that specifies the hardware and software requirements for the test to be able to run correctly, since tests are written to exercise device- and Netflix SDK-specific features which can vary.
One feature that is unique to NTS as an automation system is the support for user interactions in device tests, i.e. tests that require user input or action in the middle of execution. For example, a test might ask the user to turn the volume button up, play an audio clip, then ask the user to either confirm the volume increase or fail the assertion. While most tests are fully automated, these semi-manual tests are often valuable in the device certification process, because they help us verify the integration of the Netflix SDK with the Partner device’s firmware, which we have no control over, and thus cannot automate.
Test Target: In both the Netflix SDK and Partner testing use cases, the test targets are generally production devices, meaning they may not necessarily provide ssh / root access. As such, operations on devices by the automation system may only be reliably carried out through established device communication protocols such as DIAL or ADB, instead of through hardware-specific debugging tools that the Partners use.
Test Environment: The test targets are located both internally at Netflix and inside the Partner networks. To normalize the diversity of networking environments across both the Netflix and Partner networks and create a consistent and controllable computing environment on which users can run certification testing on their devices, Netflix provides a customized embedded computer to Partners called the Reference Automation Environment (RAE). The devices are in turn connected to the RAE, which provides access to the testing services provided by NTS.
Device Onboarding: Before a user can execute tests, they must make their device known to NTS and associate it with their Netflix Partner account in a process called device onboarding. The user achieves this by connecting the device to the RAE in a plug-and-play fashion. The RAE collects the device properties and publishes this information to NTS. The user then goes to the UI to claim the newly-visible device so that its ownership is associated with their account.
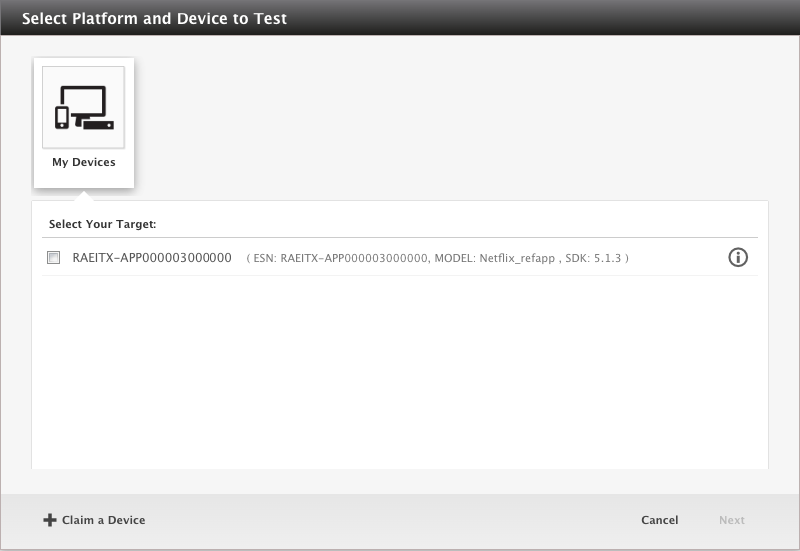
Device and Test Selection: To run tests, the user first selects from the browser-based web UI (the “NTS UI”) a target device from the list of devices under their ownership (Figure 1).
After a device has been selected, the user is presented with all tests that are applicable to the device being developed (Figure 2). The user then selects the subset of tests they are interested in running, and submits them for execution by NTS.

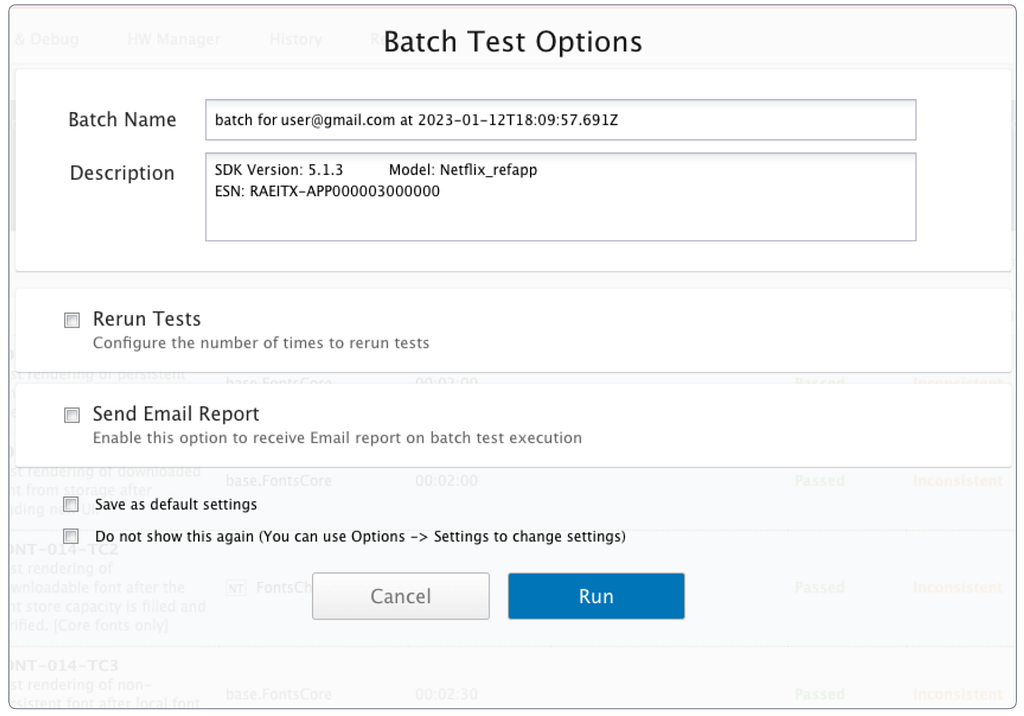
Tests can be executed as a single test run or as part of a batch run. In the latter case, additional execution options are available, such as the option to run multiple iterations of the same test or re-run tests on failure (Figure 3).
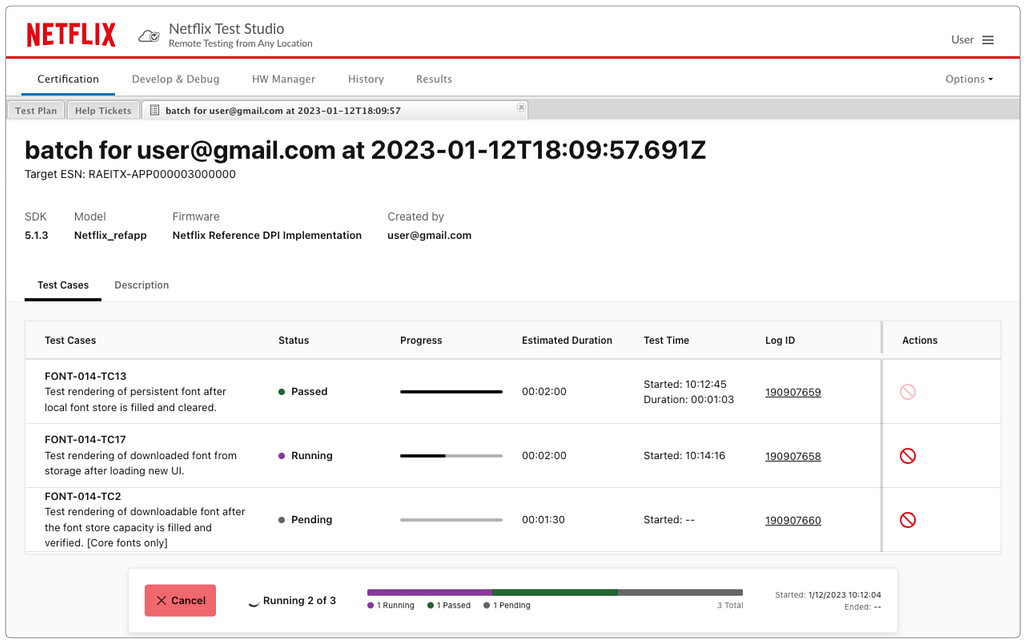
Test Execution: Once the tests are launched, the user will get a view of the tests being run, with a live update of their progress (Figure 4).
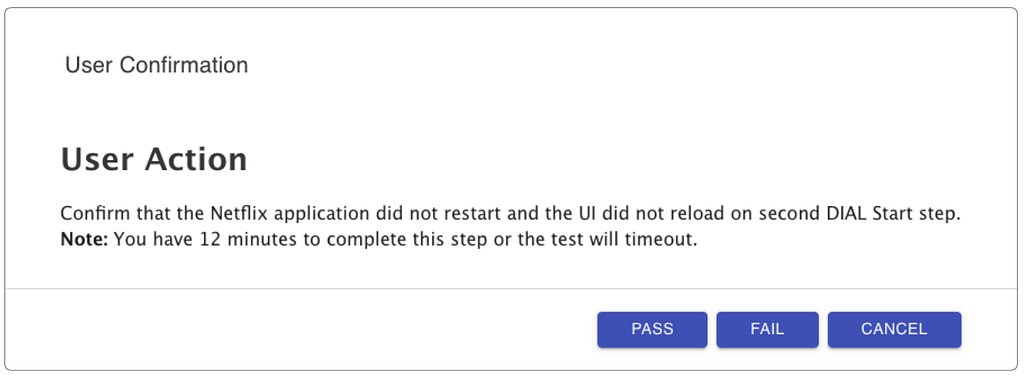
If the test is a manual test, prompts will appear in the UI at certain points during the test execution (Figure 5). The user follows the instructions in the prompt and clicks on the prompt buttons to notify the test to continue.
Defining the Stakeholders
To better define the business and system requirements for NTS, we must first identify who the stakeholders are and what their roles are in the business. For the purposes of this discussion, the major stakeholders in NTS are the following:
System Users: The system users are the Partners (system integrators) and the Partner Engineers that work with them. They select the certification targets, run tests, and analyze the results.
Test Authors: The test authors write the test cases that are to be run against the certification targets (devices). They are generally a subset of the system users, and are familiar or involved with the development of the Netflix SDK and UI.
System Developers: The system developers are responsible for developing the NTS platform and its components, adding new features, fixing bugs, maintaining uptime, and evolving the system architecture over time.
From the Use Cases to System Requirements
With the business workflows and stakeholders defined, we can articulate a set of high level system requirements / design guidelines that NTS should in theory follow:
Scheduling Non-requirement: The devices that are used in NTS form a pool of heterogeneous resources that have a diverse range of hardware constraints. However, NTS is built around the use case where users come in with a specific resource or pool of similar resources in mind and are searching for a subset of compatible tests to run on the target resource(s). This contrasts with test automation systems where users come in with a set of diverse tests, and are searching for compatible resources on which to run the tests. Resource sharing is possible, but it is expected to be manually coordinated between the users because the business workflows that use NTS often involve physical ownership of the device anyway. For these reasons, advanced resource scheduling is not a user requirement of this system.
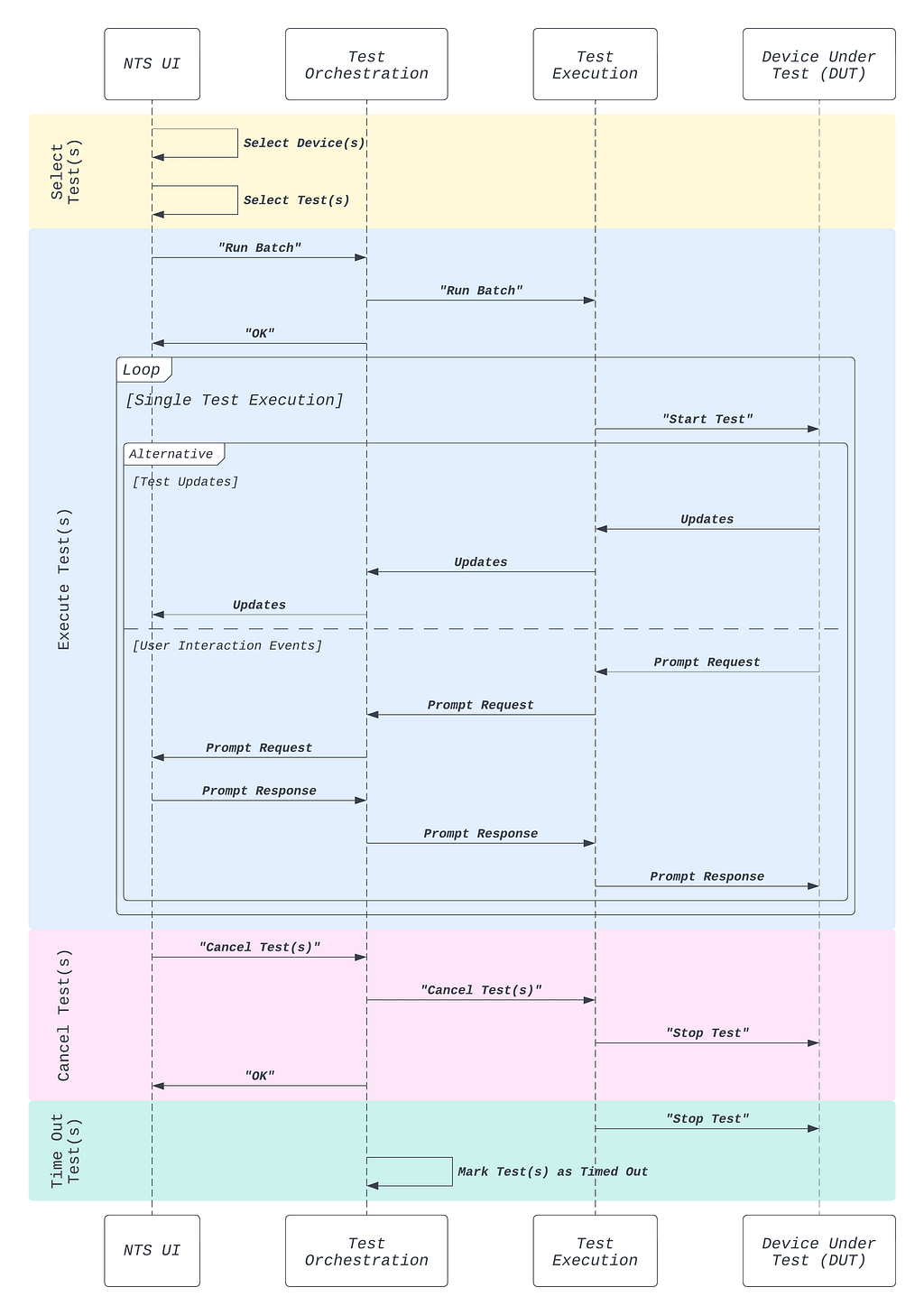
Test Execution Component: Similar to other workflow automation systems, running tests in NTS involve performing tasks external to the target. These include controlling the target device, keeping track of the device state / connectivity, setting up test accounts for the test execution, collecting device logs, publishing test updates, validating test input parameters, and uploading test results, just to name a few. Thus, there needs to be a well-defined test execution stack that sits outside of the device under test to coordinate all these operations.
Proper State Management: Test execution statuses need to be accurately tracked, so that multiple users can follow what is happening while the test is running. Furthermore, certain tests require user interactions via prompts, which necessitate the system keeping track of messages being passed back and forth from the UI to the device. These two use cases call for a well-defined data model for representing test executions, as well as a system that provides consistent and reliable test execution state management.
Higher Level Execution Semantics: As noted from the business workflow description, users may want to run tests in batches, run multiple iterations of a test case, retry failing tests up to a given number of times, cancel tests in single or at the batch level, and be notified on the completion of a batch execution. Given that the execution of a single test case is already complex as is, these user features call for the need to encapsulate single test executions as the unit of abstraction that we can then use to define higher level execution semantics for supporting said features in a consistent manner.
Automated Supervision: Running tests on prototype hardware inherently comes with reliability issues, not to mention that it takes place in a network environment which we do not necessarily control. At any point during a test execution, the target device can run into any number of errors stemming from either the target device itself, the test execution stack, or the network environment. When this happens, the users should not be left without test execution updates and incomplete test results. As such, multiple levels of supervision need to be built into the test system, so that test executions are always cleaned up in a reliable manner.
Test Orchestration Component: The requirements for proper state management, higher level execution semantics, and automated supervision call for a well-defined test orchestration stack that handles these three aspects in a consistent manner. To clearly delineate the responsibilities of test orchestration from those of test execution, the test orchestration stack should be separate from and sit on top of the test execution component abstraction (Figure 6).
System Scalability: Scalability in NTS has different meaning for each of the system’s stakeholders. For the users, scalability implies the ability to always be able to run and interact with tests, no matter the scale (notwithstanding genuine device unavailability). For the test authors, scalability implies the ease of defining, extending, and debugging certification test cases. For the system developers, scalability implies the employment of distributed system design patterns and practices that scale up the development and maintenance velocities required to meet the needs of the users.
Adherence to the Paved Path: At Netflix, we emphasize building out solutions that use paved-path tooling as much as possible (see posts here and here). JVM and Kafka support are the most relevant components of the paved-path tooling for this article.
The Evolution of NTS
With the system requirements properly articulated, let us do a high-level walkthrough of the NTS 1.0 as implemented and examine some of its shortcomings with respect to meeting the requirements.
Test Execution Stack
In NTS 1.0, the test execution stack is partitioned into two components to address two orthogonal concerns: maintaining the test environment and running the actual tests. The RAE serves as the foundation for addressing the first concern. On the RAE sits the first component of the test execution stack, the device agent. The device agent is a monolithic daemon running on the RAE that manages the physical connections to the devices under test (DUTs), and provides an RPC API abstraction over physical device management and control.
Complementing the device agent is the test harness, which manages the actual test execution. The test harness accepts HTTP requests to run a single test case, upon which it will spin off a test executor instance to drive and manage the test case’s execution through RPC calls to the device agent managing the target device (see the NTS 1.0 blog post for details). Throughout the lifecycle of the test execution, the test harness publishes test updates to a message bus (Kafka in this case) that other services consume from.
Because the device agent provides a hardware abstraction layer for device control, the business logic for executing tests that resides in the test harness, from invoking device commands to publishing test results, is device-independent. This provides freedom for the component to be developed and deployed as a cloud-native application, so that it can enjoy the benefits of the cloud application model, e.g. write once run everywhere, automatic scalability, etc. Together, the device agent and the test harness form what is called the Hybrid Execution Context (HEC), i.e. the test execution is co-managed by a cloud and edge software stack (Figure 7).
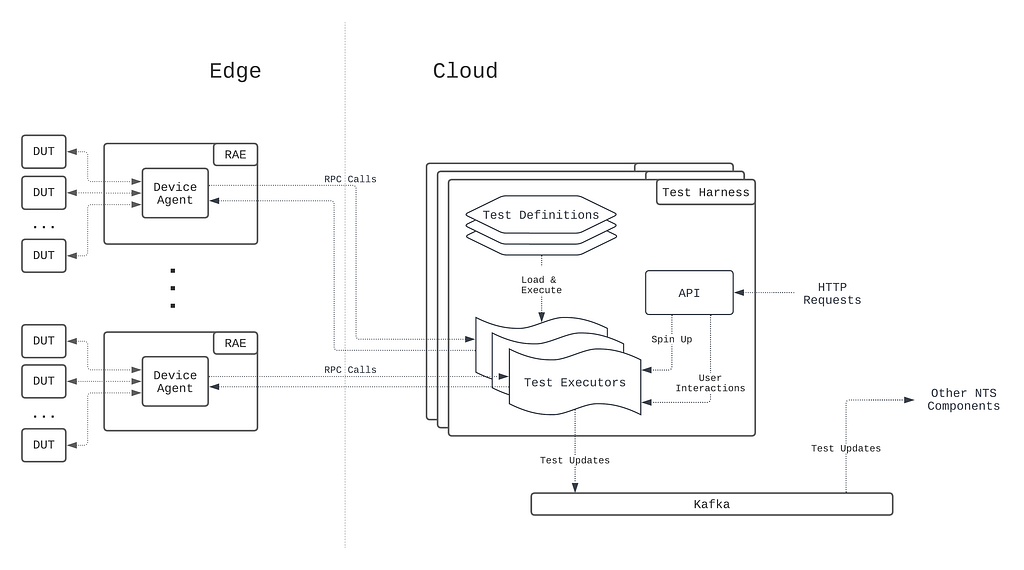
Because the test harness contains all the common test execution business logic, it effectively acts as an “SDK” that device tests can be written on top of. Consequently, test case definitions are packaged as a common software library that the test harness imports on startup, and are executed as library methods called by the test executors in the test harness. This development model complements the write once run everywhere development model of test harness, since improvements to the test harness generally translate to test case execution improvements without any changes made to the test definitions themselves.
As noted earlier, executing a single test case against a device consists of many operations involved in the setup, runtime, and teardown of the test. Accordingly, the responsibility for each of the operations was divided between the device agent and test harness along device-specific and non-device-specific lines. While this seemed reasonable in theory, oftentimes there were operations that could not be clearly delegated to one or the other component. For example, since relevant logs are emitted by both software inside and outside of the device during a test, test log collection becomes a responsibility for both the device agent and test harness.
Presentation Layer
While the test harness publishes test events that eventually make their way into the test results store, the test executors and thus the intermediate test execution states are ephemeral and localized to the individual test harness instances that spun them. Consequently, a middleware service called the test dispatcher sits in between the users and the test harness to handle the complexity of test executor “discovery” (see the NTS 1.0 blog post for details). In addition to proxying test run requests coming from the users to the test harness, the test dispatcher most importantly serves materialized views of the intermediate test execution states to the users, by building them up through the ingestion of test events published by the test harness (Figure 8).

This presentation layer that is offered by the test dispatcher is more accurately described as a console abstraction to the test execution, since users rely on this service to not just follow the latest updates to a test execution, but also to interact with the tests that require user interaction. Consequently, bidirectionality is a requirement for the communications protocol shared between the test dispatcher service and the user interface, and as such, the WebSocket protocol was adopted due to its relative simplicity of implementation for both the test dispatcher and the user interface (web browsers in this case). When a test executes, users open a WebSocket session with the test dispatcher through the UI, and materialized test updates flow to the UI through this session as they are consumed by the service. Likewise, test prompt responses / cancellation requests flow from the UI back to the test dispatcher via the same session, and the test dispatcher forwards the message to the appropriate test executor instance in the test harness.
Batch Execution Stack
In NTS 1.0, the unit of abstraction for running tests is the single test case execution, and both the test execution stack and presentation layer was designed and implemented with this in mind. The construct of a batch run containing multiple tests was introduced only later in the evolution of NTS, being motivated by a set of related user-demanded features: the ability to run and associate multiple tests together, the ability to retry tests on failure, and the ability to be notified when a group of tests completes. To address the business logic of managing batch runs, a batch executor was developed, separate from both the test harness and dispatcher services (Figure 9).

Similar to the test dispatcher service, the batch execution service proxies batch run requests coming from the users, and is ultimately responsible for dispatching the individual test runs in the batch through the test harness. However, the batch execution service maintains its own data model of the test execution that is separate from and thus incompatible with that materialized by the test dispatcher service. This is a necessary difference considering the unit of abstraction for running tests using the batch execution service is the batch run.
Examining the Shortcomings of NTS 1.0
Having described the major system components at a high level, we can now analyze some of the shortcomings of the system in detail:
Inconsistent Execution Semantics: Because batch runs were introduced as an afterthought, the semantics of batch executions in relation to those of the individual test executions were never fully clarified in implementation. In addition, the presence of both the test dispatcher and batch executor created a bifurcation in test executions management, where neither service alone satisfied the users’ needs. For example, a single test that is kicked off as part of a batch run through the batch executor must be canceled through the test dispatcher service. However, cancellation is only possible if the test is in a running state, since the test dispatcher has no information about tests prior to their execution. Behaviors such as this often resulted in the system appearing inconsistent and unintuitive to the users, while presenting a knowledge overhead for the system developers.
Test Execution Scalability and Reliability: The test execution stack suffered two technical issues that hampered its reliability and ability to scale. The first is in the partitioning of the test execution stack into two distinct components. While this division had emerged naturally from the setup of the business workflow, the device agent and test harness are fundamentally two pieces of a common stack separated by a control plane, i.e. the network. The conditions of the network at the Partner sites are known to be inconsistent and sometimes unreliable, as there might be traffic congestion, low bandwith, or unique firewall rules in place. Furthermore, RPC communications between the device agent and test harness are not direct, but go through a few more system components (e.g. gateway services). For these reasons, test executions in practice often suffer from a host of stability, reliability, and latency issues, most of which we cannot take action upon.
The second technical issue is in the implementation of the test executors hosted by the test harness. When a test case is run, a full thread is spawned off to manage its execution, and all intermediate test execution state is stored in thread-local memory. Given that much of the test execution lifecycle is involved with making blocking RPC calls, this choice of implementation in practice limits the number of tests that can effectively be run and managed per test harness instance. Moreover, the decision to maintain intermediate test execution state only in thread-local memory renders the test harness fragile, as all test executors running on a given test harness instance will be lost along with their data if the instance goes down. Operational issues stemming from the brittle implementation of the test executors and from the partitioning of the test execution stack frequently exacerbate each other, leading to situations where test executions are slow, unreliable, and prone to infrastructure errors.
Presentation Layer Scalability: In theory, the dispatcher service’s WebSocket server can scale up user sessions to the maximum number of HTTP connections allowed by the service and host configuration. However, the service was designed to be stateless so as to reduce the codebase size and complexity. This meant that the dispatcher service had to initialize a new Kafka consumer, read from the beginning of the target partition, filter for the relevant test updates, and build the intermediate test execution state on the fly each time a user opened a new WebSocket session with the service. This was a slow and resource-intensive process, which limited the scalability of the dispatcher service as an interactive test execution console for users in practice.
Test Authoring Scalability: Because the common test execution business logic was bundled with the test harness as a de facto SDK, test authors had to actually be familiar with the test harness stack in order to define new test cases. For the test authors, this presented a huge learning curve, since they had to learn a large codebase written in a programming language and toolchain that was completely different from those used in Netflix SDK and UI. Since only the test harness maintainers can effectively contribute test case definitions and improvements, this became a bottleneck as far as development velocity was concerned.
Unreliable State Management: Each of the three core services has a different policy with respect to test execution state management. In the test harness, state is held in thread-local memory, while in the test dispatcher, it is built on the fly by reading from Kafka with each new console session. In the batch executor, on the other hand, intermediate test execution states are ignored entirely and only test results are stored. Because there is no persistence story with regards to intermediate test execution state, and because there is no data model to represent test execution states consistently across the three services, it becomes very difficult to coordinate and track test executions. For example, two WebSocket sessions to the same test execution are generally not reproducible if user interactions such as prompt responses are involved, since each session has its own materialization of the test execution state. Without the ability to properly model and track test executions, supervision of test executions is consequently non-existent.
Moving To an Intentional Architecture
The evolution of NTS can best be described as that of an emergent system architecture, with many features added over time to fulfill the users’ ever-increasing needs. It became apparent that this model brought forth various shortcomings that prevented it from satisfying the system requirements laid out earlier. We now discuss the high-level architectural changes we have made with NTS 2.0, which was built with an intentional design approach to address the system requirements of the business problem.
Decoupling Test Definitions
In NTS 2.0, tests are defined as scripts against the Netflix SDK that execute on the device itself, as opposed to library code that is dependent on and executes in the test harness. These test definitions are hosted on a separate service where they can be accessed by the Netflix SDK on devices located in the Partner networks (Figure 10).
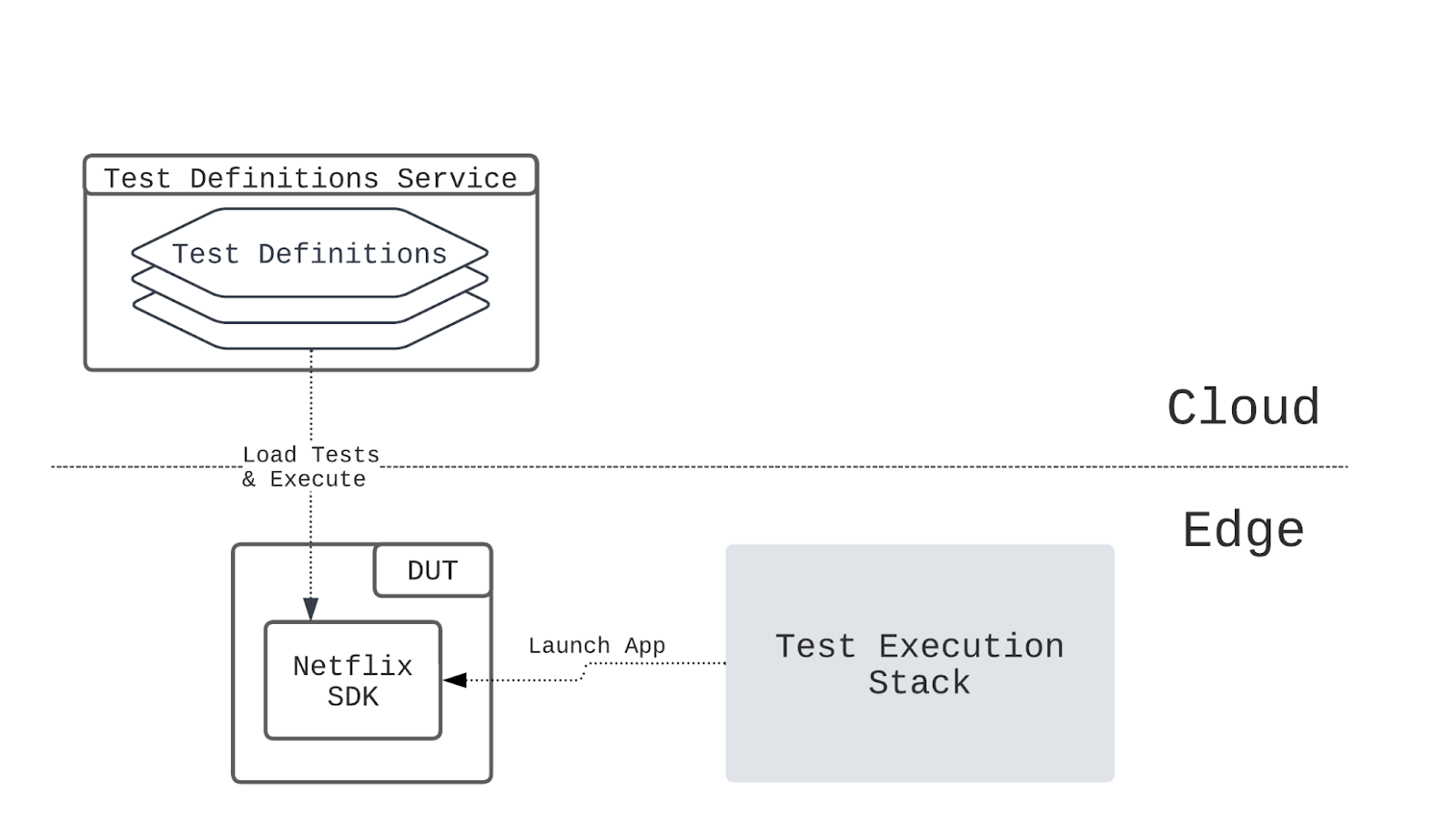
This change brings several distinct benefits to the system. The first is that the new setup is more aligned with device certification, where ultimately we are testing the integration of the Netflix SDK with the target device’s firmware. The second is that we are able to consolidate instrumentation and logging onto a single stack, which simplifies the debugging process for the developers. In addition, by having tests be defined using the same programming language and toolchain used to develop the Netflix UI, the learning curve for writing and maintaining tests is significantly reduced for the test authors. Finally, this setup strongly decouples test definitions from the rest of the test execution infrastructure, allowing for the two to be developed separately in parallel with improved velocity.
Defining the Job Execution Model
A proper job execution model with concise semantics has been defined in NTS 2.0 to address the inconsistent semantics between single test and batch executions (Figure 11). The model is summarized as follows:
- The base unit of test execution is the batch. A batch consists of one or more test cases to be run sequentially on the target device.
- The base unit of test orchestration is the job. A job is a template containing a list of test cases to be run, configurations for test retries and job notifications, and information on the target device.
- All test run requests create a job template, from which batches are instantiated for execution. This includes single test run requests.
- Upon batch completion, a new batch may be instantiated from the source job, but containing only the subset of the test cases that failed earlier. Whether or not this occurs depends on the source job’s test retries configuration.
- A job is considered finished when its instantiated batches and subsequent retries have completed. Notifications may then be sent out according to the job’s configuration.
- Cancellations are applicable to either the single test execution level or the batch execution level. Jobs are considered canceled when its current batch instantiation is canceled.
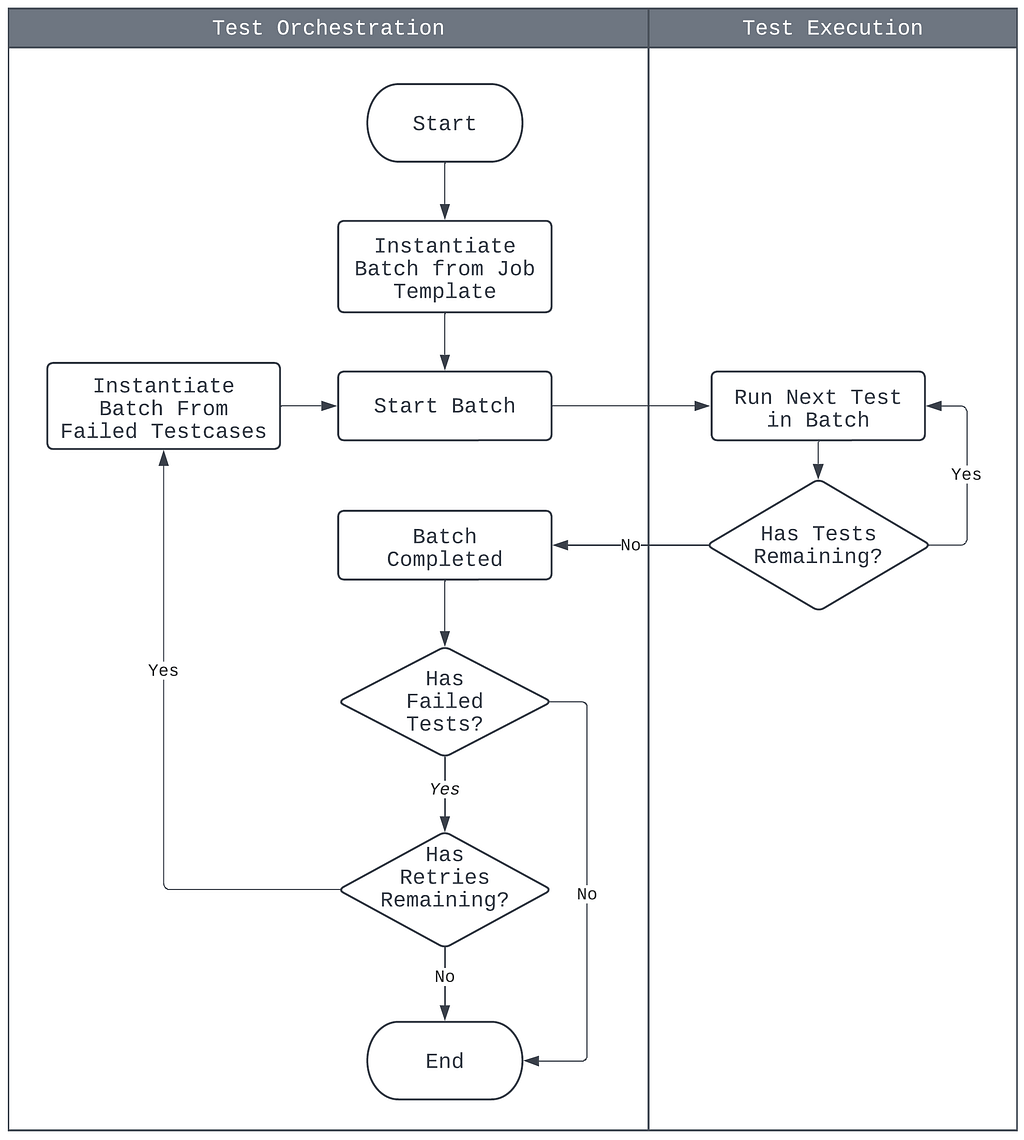
The newly-defined job execution model thoroughly clarifies the semantics of single test and batch executions while remaining consistent with all existing use cases of the system, and has informed the re-architecting of both the test execution and orchestration components, which we will discuss in the next few sections.
Replacement of the Control Plane
In NTS 1.0, the device agent at the edge and the test harness in the cloud communicate to each other via RPC calls proxied by intermediate gateway services. As noted in great detail earlier, this setup brought many stability, reliability, and latency issues that were observed in test executions. With NTS 2.0, this point-to-point-based control plane is replaced with a message bus-based control plane that is built on MQTT and Kafka (Figure 12).
MQTT is an OASIS standard messaging protocol for the Internet of Things (IoT) and was designed as a highly lightweight yet reliable publish/subscribe messaging transport that is ideal for connecting remote devices with a small code footprint and minimal network bandwidth. MQTT clients connect to the MQTT broker and send messages prefixed with a topic. The broker is responsible for receiving all messages, filtering them, determining who is subscribed to which topic, and sending the messages to the subscribed clients accordingly. The key features that make MQTT highly appealing to us are its support for request retries, fault tolerance, hierarchical topics, client authentication and authorization, per-topic ACLs, and bi-directional request/response message patterns, all of which are crucial for the business use cases around NTS.
Since the paved-path solution at Netflix supports Kafka, a bridge is established between the two protocols to allow cloud-side services to communicate with the control plane (Figure 12). Through the bridge, MQTT messages are converted directly to Kafka records, where the record key is set to be the MQTT topic that the message was assigned to. We take advantage of this construction by having test execution updates published on MQTT contain the test_id in the topic. This forces all updates for a given test execution to effectively appear on the same Kafka partition with a well-defined message order for consumption by NTS component cloud services.
The introduction of the new control plane has enabled communications between different NTS components to be carried out in a consistent, scalable, and reliable manner, regardless of where the components were located. One example of its use is described in our earlier blog post about reliable devices management. The new control plane sets the foundations for the evolution of the test execution stack in NTS 2.0, which we discuss next.
Migration from a Hybrid to Local Execution Context
The test execution component is completely migrated over from the cloud to the edge in NTS 2.0. This includes functionality from the batch execution stack in NTS 1.0, since batch executions are the new base unit of test execution. The migration immediately addresses the long standing problems of network reliability and latency in test executions, since the entire test execution stack now sits together in the same isolated environment, the RAE, instead of being partitioned by a control plane.

During the migration, the test harness and the device agent components were modularized, as each aspect of test execution management — device state management, device communications protocol management, batch executions management, log collection, etc — was moved into a dedicated system service running on the RAE that communicated with the other components via the new control plane (Figure 12). Together with the new control plane, these new local modules form what is called the Local Execution Context (LEC). By consolidating test execution management onto the edge and thus in close proximity to the device, the LEC becomes largely immune from the many network-related scalability, reliability, and stability issues that the HEC model frequently encounters. Alongside with the decoupling of test definitions from the test harness, the LEC has significantly reduced the complexity of the test execution stack, and has paved the way for its development to be parallelized and thus scalable.
Proper State Modeling with Event Sourcing
Test orchestration covers many aspects: support for the established job execution model (kicking off and running jobs), consistent state management for test executions, reconciliation of user interaction events with test execution state, and overall job execution supervision. These functions were divided amongst the three core services in NTS 1.0, but without a consistent model of the intermediate execution states that they can rely upon for coordination, test orchestration as defined by the system requirements could not be reliably achieved. With NTS 2.0, a unified data schema for test execution updates is defined according to the job execution model, with the data itself persisted in storage as an append-only log. In this state management model, all updates for a given test execution, including user interaction events, are stored as a totally-ordered sequence of immutable records ordered by time and grouped by the test_id. The append-only property here is a very powerful feature, because it gives us the ability to materialize a test execution state at any intermediate point in time simply by replaying the append-only log for the test execution from the beginning up until the given timestamp. Because the records are immutable, state materializations are always fully reproducible.
Since the test execution stack continuously publishes test updates to the control plane, state management at the test orchestration layer simply becomes a matter of ingesting and storing these updates in the correct order in accordance with the Event Sourcing Pattern. For this, we turn to the solution provided by Alpakka-Kafka, whose adoption we have previously pioneered in the implementation of our devices management platform (Figure 13). To summarize here, we chose Alpakka-Kafka as the basis of the test updates ingestion infrastructure because it fulfilled the following technical requirements: support for per-partition in-order processing of events, back-pressure support, fault tolerance, integration with the paved-path tooling, and long-term maintainability. Ingested updates are subsequently persisted into a log store backed by CockroachDB. CockroachDB was chosen as the backing store because it is designed to be horizontally scalable and it offers the SQL capabilities needed for working with the job execution data model.

With proper event sourcing in place and the test execution stack fully migrated over to the LEC, the remaining functionality in the three core services is consolidated into dedicated single service in NTS 2.0, effectively replacing and improving upon the former three in all areas where test orchestration was concerned. The scalable state management solution provided by this test orchestration service becomes the foundation for scalable presentation and job supervision in NTS 2.0, which we discuss next.
Scaling Up the Presentation Layer
The new test orchestration service serves the presentation layer, which, as with NTS 1.0, provides a test execution console abstraction implemented using WebSocket sessions. However, for the console abstraction to be truly reliable and functional, it needs to fulfill several requirements. The first and foremost is that console sessions must be fully reproducible, i.e. two users interacting with the same test execution should observe the exact same behavior. This was an area that was particularly problematic in NTS 1.0. The second is that console sessions must scale up with the number of concurrent users in practice, i.e. sessions should not be resource-intensive. The third is that communications between the session console and the user should be minimal and efficient, i.e. new test execution updates should be delivered to the user only once. This requirement implies the need for maintaining session-local memory to keep track of delivered updates. Finally, the test orchestration service itself needs to be able to intervene in console sessions, e.g. send session liveness updates to the users on an interval schedule or notify the users of session termination if the service instance hosting the session is shutting down.
To handle all of these requirements in a consistent yet scalable manner, we turn to the Actor Model for inspiration. The Actor Model is a concurrency model in which actors are the universal primitive of concurrent computation. Actors send messages to each other, and in response to incoming messages, they can perform operations, create more actors, send out other messages, and change their future behavior. Actors also maintain and modify their own private state, but they can only affect each other’s states indirectly through messaging. In-depth discussions of the Actor Model and its many applications can be found here and here.

The Actor Model naturally fits the mental model of the test execution console, since the console is fundamentally a standalone entity that reacts to messages (e.g. test updates, service-level notifications, and user interaction events) and maintains internal state. Accordingly, we modeled test execution sessions as such using Akka Typed, a well-known and highly-maintained actor system implementation for the JVM (Figure 14). Console sessions are instantiated when a WebSocket connection is opened by the user to the service, and upon launch, the console begins fetching new test updates for the given test_id from the data store. Updates are delivered to the user over the WebSocket connection and saved to session-local memory as record to keep track of what has already been delivered, while user interaction events are forwarded back to the LEC via the control plane. The polling process is repeated on a cron schedule (every 2 seconds) that is registered to the actor system’s scheduler during console instantiation, and the polling’s data query pattern is designed to be aligned with the service’s state management model.
Putting in Job Supervision
As a distributed system whose components communicate asynchronously and are involved with prototype embedded devices, faults frequently occur throughout the NTS stack. These faults range from device loops and crashes to the RAE being temporarily disconnected from the network, and generally result in missing test updates and/or incomplete test results if left unchecked. Such undefined behavior is a frequent occurrence in NTS 1.0 that impedes the reliability of the presentation layer as an accurate view of test executions. In NTS 2.0, multiple levels of supervision are present across the system to address this class of issues. Supervision is carried out through checks that are scheduled throughout the job execution lifecycle in reaction to the job’s progress. These checks include:
- Handling response timeouts for requests sent from the test orchestration service to the LEC.
- Handling test “liveness”, i.e. ensuring that updates are continuously present until the test execution reaches a terminal state.
- Handling test execution timeouts.
- Handling batch execution timeouts.
When these faults occur, the checks will discover them and automatically clean up the faulting test execution, e.g. marking test results as invalid, releasing the target device from reservation, etc. While some checks exist in the LEC stack, job-level supervision facilities mainly reside in the test orchestration service, whose log store can be reliably used for monitoring test execution runs.
Discussion
System Behavioral Reliability
The importance of understanding the business problem space and cementing this understanding through proper conceptual modeling cannot be underscored enough. Many of the perceived reliability issues in NTS 1.0 can be attributed to undefined behavior or missing features. These are an inevitable occurrence in the absence of conceptual modeling and thus strongly codified expectations of system behavior. With NTS 2.0, we properly defined from the very beginning the job execution model, the data schema for test execution updates according to the model, and the state management model for test execution states (i.e. the append-only log model). We then implemented various system-level features that are built upon these formalisms, such as event-sourcing of test updates, reproducible test execution console sessions, and job supervision. It is this development approach, along with the implementation choices made along the way, that empowers us to achieve behavioral reliability across the NTS system in accordance with the business requirements.
System Scalability
We can examine how each component in NTS 2.0 addresses the scalability issues that are present in its predecessor:
LEC Stack: With the consolidation of the test execution stack fully onto the RAE, the challenge of scaling up test executions is now broken down into two separate problems:
- Whether or not the LEC stack can support executing as many tests simultaneously as the maximum number of devices that can be connected to the RAE.
- Whether or not the communications between the edge and the cloud can scale with the number of RAEs in the system.
The first problem is naturally resolved by hardware-imposed limitations on the number of connected devices, as the RAE is an embedded appliance. The second refers to the scalability of the NTS control plane, which we will discuss next.
Control Plane: With the replacement of the point-to-point RPC-based control plane with a message bus-based control plane, system faults stemming from Partner networks have become a rare occurrence and RAE-edge communications have become scalable. For the MQTT side of the control plane, we used HiveMQ as the cloud MQTT broker. We chose HiveMQ because it met all of our business use case requirements in terms of performance and stability (see our adoption report for details), and came with the MQTT-Kafka bridging support that we needed.
Event Sourcing Infrastructure: The event-sourcing solution provided by Alpakka-Kafka and CockroachDB has already been demonstrated to be very performant, scalable, and fault tolerant in our earlier work on reliable devices management.
Presentation Layer: The current implementation of the test execution console abstraction using actors removed the practical scaling limits of the previous implementation. The real advantage of this implementation model is that we can achieve meaningful concurrency and performance without having to worry about the low-level details of thread pool management and lock-based synchronization. Notably, systems built on Akka Typed have been shown to support roughly 2.5 million actors per GB of heap and relay actor messages at a throughput of nearly 50 million messages per second.
To be thorough, we performed basic load tests on the presentation layer using the Gatling load-testing framework to verify its scalability. The simulated test scenario per request is as follows:
- Open a test execution console session (i.e. WebSocket connection) in the test orchestration service.
- Wait for 2 to 3 minutes (randomized), during which the session will be polling the data store at 2 second intervals for test updates.
- Close the session.
This scenario is comparable to the typical NTS user workflow that involves the presentation layer. The load test plan is as follows:
- Burst ramp-up requests to 1000 over 5 seconds.
- Add 80 new requests per second for 10 minutes.
- Wait for all requests to complete.
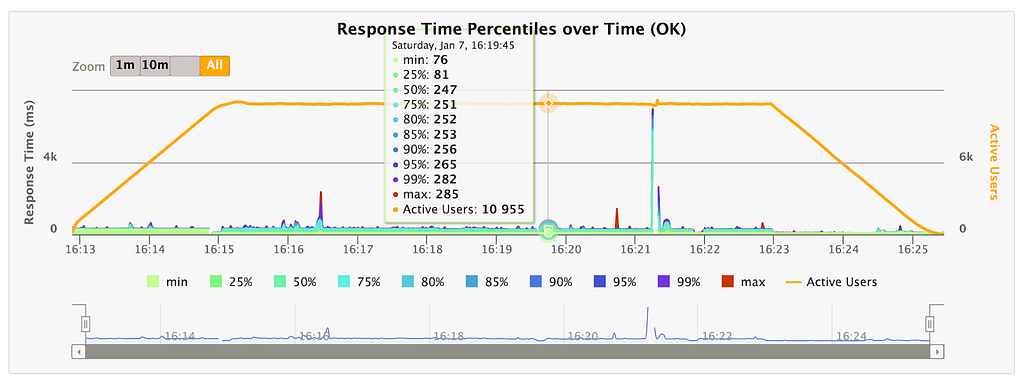
We observed that, in load tests of a single client machine (2.4 GHz, 8-Core, 32 GB RAM) running against a small cluster of 3 AWS m4.xlarge instances, we were able to peg the client at over 10,900 simultaneous live WebSocket connections before the client’s limits were reached (Figure 15). On the server side, neither CPU nor memory utilization appeared significantly impacted for the duration of the tests, and the database connection pool was able to handle the query load from all the data store polling (Figures 16–18). We can conclude from these load test results that scalability of the presentation layer has been achieved with the new implementation.



Job Supervision: While the actual business logic may be complex, job supervision itself is a very lightweight process, as checks are reactively scheduled in response to events across the job execution cycle. In implementation, checks are scheduled through the Akka scheduler and run using actors, which have been shown above to scale very well.
Development Velocity
The design decisions we have made with NTS 2.0 have simplified the NTS architecture and in the process made the platform run tests observably much faster, as there are simply a lot less moving components to work with. Whereas it used to take roughly 60 seconds to run through a “Hello, World” device test from setup to teardown, now it takes less than 5 seconds. This has translated to increased development velocity for our users, who can now iterate their test authoring and device integration / certification work much more frequently.
In NTS 2.0, we have thoroughly added multiple levels of observability across the stack using paved-path tools, from contextual logging to metrics to distributed tracing. Some of these capabilities were previously not available in NTS 1.0 because the component services were built prior to the introduction of paved-path tooling at Netflix. Combined with the simplification of the NTS architecture, this has increased development velocity for the system maintainers by an order of magnitude, as user-reported issues in general can now be tracked down and fixed within the same day as they were reported, for example.
Costs Reduction
Though our discussion of NTS 1.0 focused on the three core services, in reality there are many auxiliary services in between that coordinate different aspects of a test execution, such as RPC requests proxying from cloud to edge, test results collection, etc. Over the course of building NTS 2.0, we have deprecated a total of 10 microservices whose roles have been either obsolesced by the new architecture or consolidated into the LEC and test orchestration service. In addition, our work has paved the way for the eventual deprecation of 5 additional services and the evolution of several others. The consolidation of component services along with the increase in development and maintenance velocity brought about by NTS 2.0 has significantly reduced the business costs of maintaining the NTS platform, in terms of both compute and developer resources.
Conclusion
Systems design is a process of discovery and can be difficult to get right on the first iteration. Many design decisions need to be considered in light of the business requirements, which evolve over time. In addition, design decisions must be regularly revisited and guided by implementation experience and customer feedback in a process of value-driven development, while avoiding the pitfalls of an emergent model of system evolution. Our in-field experience with NTS 1.0 has thoroughly informed the evolution of NTS into a device testing solution that better satisfies the business workflows and requirements we have while scaling up developer productivity in building out and maintaining this solution.
Though we have brought in large changes with NTS 2.0 that addressed the systemic shortcomings of its predecessor, the improvements discussed here are focused on only a few components of the overall NTS platform. We have previously discussed reliable devices management, which is another large focus domain. The overall reliability of the NTS platform rests on significant work made in many other key areas, including devices onboarding, the MQTT-Kafka transport, authentication and authorization, test results management, and system observability, which we plan to discuss in detail in future blog posts. In the meantime, thanks to this work, we expect NTS to continue to scale with increasing workloads and diversity of workflows over time according to the needs of our stakeholders.
![]()
NTS: Reliable Device Testing at Scale was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.