Post Syndicated from Younggu Yun original https://aws.amazon.com/blogs/big-data/how-encored-technologies-built-serverless-event-driven-data-pipelines-with-aws/
This post is a guest post co-written with SeonJeong Lee, JaeRyun Yim, and HyeonSeok Yang from Encored Technologies.
Encored Technologies (Encored) is an energy IT company in Korea that helps their customers generate higher revenue and reduce operational costs in renewable energy industries by providing various AI-based solutions. Encored develops machine learning (ML) applications predicting and optimizing various energy-related processes, and their key initiative is to predict the amount of power generated at renewable energy power plants.
In this post, we share how Encored runs data engineering pipelines for containerized ML applications on AWS and how they use AWS Lambda to achieve performance improvement, cost reduction, and operational efficiency. We also demonstrate how to use AWS services to ingest and process GRIB (GRIdded Binary) format data, which is a file format commonly used in meteorology to store and exchange weather and climate data in a compressed binary form. It allows for efficient data storage and transmission, as well as easy manipulation of the data using specialized software.
Business and technical challenge
Encored is expanding their business into multiple countries to provide power trading services for end customers. The amount of data and the number of power plants they need to collect data are rapidly increasing over time. For example, the volume of data required for training one of the ML models is more than 200 TB. To meet the growing requirements of the business, the data science and platform team needed to speed up the process of delivering model outputs. As a solution, Encored aimed to migrate existing data and run ML applications in the AWS Cloud environment to efficiently process a scalable and robust end-to-end data and ML pipeline.
Solution overview
The primary objective of the solution is to develop an optimized data ingestion pipeline that addresses the scaling challenges related to data ingestion. During its previous deployment in an on-premises environment, the time taken to process data from ingestion to preparing the training dataset exceeded the required service level agreement (SLA). One of the input datasets required for ML models is weather data supplied by the Korea Meteorological Administration (KMA). In order to use the GRIB datasets for the ML models, Encored needed to prepare the raw data to make it suitable for building and training ML models. The first step was to convert GRIB to the Parquet file format.
Encored used Lambda to run an existing data ingestion pipeline built in a Linux-based container image. Lambda is a compute service that lets you run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, and logging. AWS Lambda is triggered to ingest and process GRIB data files when they are uploaded to Amazon Simple Storage Service (Amazon S3). Once the files are processed, they are stored in Parquet format in the other S3 bucket. Encored receives GRIB files throughout the day, and whenever new files arrive, an AWS Lambda function runs a container image registered in Amazon Elastic Container Registry (ECR). This event-based pipeline triggers a customized data pipeline that is packaged in a container-based solution. Leveraging Amazon AWS Lambda, this solution is cost-effective, scalable, and high-performing.Encored uses Python as their preferred language.
The following diagram illustrates the solution architecture.
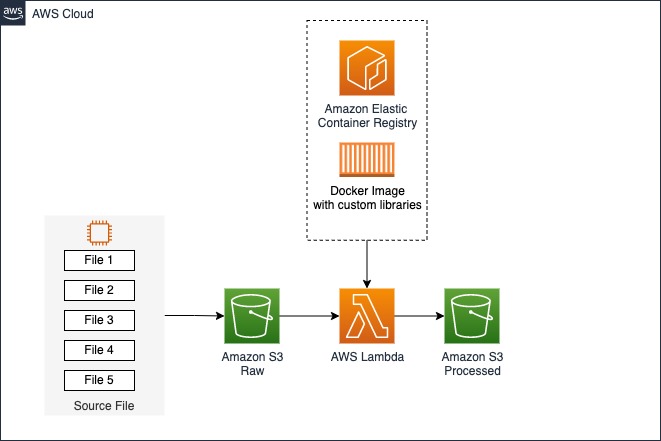
For data-intensive tasks such as extract, transform, and load (ETL) jobs and ML inference, Lambda is an ideal solution because it offers several key benefits, including rapid scaling to meet demand, automatic scaling to zero when not in use, and S3 event triggers that can initiate actions in response to object-created events. All this contributes to building a scalable and cost-effective data event-driven pipeline. In addition to these benefits, Lambda allows you to configure ephemeral storage (/tmp) between 512–10,240 MB. Encored used this storage for their data application when reading or writing data, enabling them to optimize performance and cost-effectiveness. Furthermore, Lambda’s pay-per-use pricing model means that users only pay for the compute time in use, making it a cost-effective solution for a wide range of use cases.
Prerequisites
For this walkthrough, you should have the following:
- An AWS account
- The AWS Command Line Interface (AWS CLI) installed
- The Docker CLI
- Your function codes
Build your application required for your Docker image
The first step is to develop an application that can ingest and process files. This application reads the bucket name and object key passed from a trigger added to Lambda function. The processing logic involves three parts: downloading the file from Amazon S3 into ephemeral storage (/tmp), parsing the GRIB formatted data, and saving the parsed data to Parquet format.
The customer has a Python script (for example, app.py) that performs these tasks as follows:
Prepare a Docker file
The second step is to create a Docker image using an AWS base image. To achieve this, you can create a new Dockerfile using a text editor on your local machine. This Dockerfile should contain two environment variables:
LAMBDA_TASK_ROOT=/var/taskLAMBDA_RUNTIME_DIR=/var/runtime
It’s important to install any dependencies under the ${LAMBDA_TASK_ROOT} directory alongside the function handler to ensure that the Lambda runtime can locate them when the function is invoked. Refer to the available Lambda base images for custom runtime for more information.
Build a Docker image
The third step is to build your Docker image using the docker build command. When running this command, make sure to enter a name for the image. For example:
docker build -t process-grib .
In this example, the name of the image is process-grib. You can choose any name you like for your Docker image.
Upload the image to the Amazon ECR repository
Your container image needs to reside in an Amazon Elastic Container Registry (Amazon ECR) repository. Amazon ECR is a fully managed container registry offering high-performance hosting, so you can reliably deploy application images and artifacts anywhere. For instructions on creating an ECR repository, refer to Creating a private repository.
The first step is to authenticate the Docker CLI to your ECR registry as follows:
The second step is to tag your image to match your repository name, and deploy the image to Amazon ECR using the docker push command:
Deploy Lambda functions as container images
To create your Lambda function, complete the following steps:
- On the Lambda console, choose Functions in the navigation pane.
- Choose Create function.
- Choose the Container image option.
- For Function name, enter a name.
- For Container image URI, provide a container image. You can enter the ECR image URI or browse for the ECR image.
- Under Container image overrides, you can override configuration settings such as the entry point or working directory that are included in the Dockerfile.
- Under Permissions, expand Change default execution role.
- Choose to create a new role or use an existing role.
- Choose Create function.
Key considerations
To handle a large amount of data concurrently and quickly, Encored needed to store GRIB formatted files in the ephemeral storage (/tmp) that comes with Lambda. To achieve this requirement, Encored used tempfile.NamedTemporaryFile, which allows users to create temporary files easily that are deleted when no longer needed. With Lambda, you can configure ephemeral storage between 512 MB–10,240 MB for reading or writing data, allowing you to run ETL jobs, ML inference, or other data-intensive workloads.
Business outcome
Hyoseop Lee (CTO at Encored Technologies) said, “Encored has experienced positive outcomes since migrating to AWS Cloud. Initially, there was a perception that running workloads on AWS would be more expensive than using an on-premises environment. However, we discovered that this was not the case once we started running our applications on AWS. One of the most fascinating aspects of AWS services is the flexible architecture options it provides for processing, storing, and accessing large volumes of data that are only required infrequently.”
Conclusion
In this post, we covered how Encored built serverless data pipelines with Lambda and Amazon ECR to achieve performance improvement, cost reduction, and operational efficiency.
Encored successfully built an architecture that will support their global expansion and enhance technical capabilities through AWS services and the AWS Data Lab program. Based on the architecture and various internal datasets Encored has consolidated and curated, Encored plans to provide renewable energy forecasting and energy trading services.
Thanks for reading this post and hopefully you found it useful. To accelerate your digital transformation with ML, AWS is available to support you by providing prescriptive architectural guidance on a particular use case, sharing best practices, and removing technical roadblocks. You’ll leave the engagement with an architecture or working prototype that is custom fit to your needs, a path to production, and deeper knowledge of AWS services. Please contact your AWS Account Manager or Solutions Architect to get started. If you don’t have an AWS Account Manager, please contact Sales.
To learn more about ML inference use cases with Lambda, check out the following blog posts:
- Machine learning inference at scale using AWS serverless
- Deploy a machine learning inference data capture solution on AWS Lambda
These resources will provide you with valuable insights and practical examples of how to use Lambda for ML inference.
About the Authors
 SeonJeong Lee is the Head of Algorithms at Encored. She is a data practitioner who finds peace of mind from beautiful codes and formulas.
SeonJeong Lee is the Head of Algorithms at Encored. She is a data practitioner who finds peace of mind from beautiful codes and formulas.
 JaeRyun Yim is a Senior Data Scientist at Encored. He is striving to improve both work and life by focusing on simplicity and essence in my work.
JaeRyun Yim is a Senior Data Scientist at Encored. He is striving to improve both work and life by focusing on simplicity and essence in my work.
 HyeonSeok Yang is the platform team lead at Encored. He always strives to work with passion and spirit to keep challenging like a junior developer, and become a role model for others.
HyeonSeok Yang is the platform team lead at Encored. He always strives to work with passion and spirit to keep challenging like a junior developer, and become a role model for others.
 Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.
Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.