Post Syndicated from Diego Benavides original https://aws.amazon.com/blogs/big-data/how-belcorp-decreased-cost-and-improved-reliability-in-its-big-data-processing-framework-using-amazon-emr-managed-scaling/
This is a guest post by Diego Benavides and Luis Bendezú, Senior Data Architects, Data Architecture Direction at Belcorp.
Belcorp is one of the main consumer packaged goods (CPG) companies providing cosmetics products in the region for more than 50 years, allocated to around 13 countries in North, Central, and South America (AMER). Born in Peru and with its own product factory in Colombia, Belcorp always stayed ahead of the curve and adapted its business model according to customer needs and strengthened its strategy with technological trends, providing each time a better customer experience. Focused on this, Belcorp began to implement its own data strategy encouraging the use of data for decision-making. Based on this strategy, the Belcorp data architecture team designed and implemented a data ecosystem allowing business and analytics teams to consume functional data that they use to generate hypotheses and insights that are materialized in better marketing strategies or novel products. This post aims to detail a series of continuous improvements carried out during 2021 in order to reduce the number of platform incidents reported at the end of 2020, optimize SLAs required by the business, and be more cost-efficient when using Amazon EMR, resulting in up to 30% savings for the company.
To stay ahead of the curve, stronger companies have built a data strategy that allows them to improve main business strategies, or even create new ones, using data as a main driver. As one of the main consumer packaged goods (CPG) companies in the region, Belcorp is not an exception—in recent years we have been working to implement data-driven decision-making.
We know that all good data strategy is aligned to business objectives and based on main business use cases. Currently, all our team efforts are focused on the final consumers, and almost all business initiatives are related to hyper-personalization, pricing, and customer engagement.
To support these initiatives, the data architecture department provides data services like data integration, only one source of truth, data governance and data quality frameworks, data availability, data accessibility, and optimized time to market, according to business requirements like other big companies. To provide minimal capabilities to support all these services, we needed a scalable, flexible, and cost-efficient data ecosystem. Belcorp started this adventure a couple of years ago using AWS services like Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda, AWS Fargate, Amazon EMR, Amazon DynamoDB, and Amazon Redshift, which currently feed our main analytical solutions with data.
As we were growing, we had to continually improve our architecture design and processing framework in regards to data volume and more complex data solution requirements. We also had to adopt quality and monitoring frameworks in order to guarantee data integrity, data quality, and service level agreements (SLAs). As you can expect, it’s not an easy task, and requires its own strategy. At the beginning of 2021 and due to critical incidents we were finding, operational stability was affected, directly impacting business outcomes. Billing was also impacted, due to more new complex workloads being included, which caused an unexpected increase in platform costs. In response, we decided to focus on three challenges:
- Operational stability
- Cost-efficiency
- Service level agreements
This post details some action points we carried out during 2021 over Belcorp’s data processing framework based on Amazon EMR. We also discuss how these actions helped us face the challenges previously mentioned, and also provide economic savings to Belcorp, which was the data architecture team’s main contribution to the company.
Overview of solution
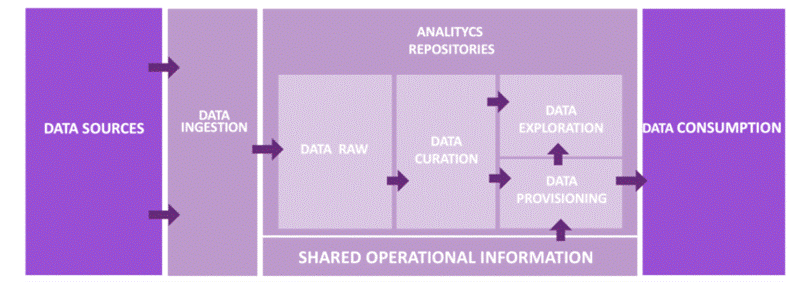
Belcorp’s data ecosystem is composed by seven key capability pillars (as shown in the following diagram) that define our architectural design and give us more or less technological flexible options. Our data platform can be classified as a part of the second generation of data platforms, as mentioned by Zhamak Dehghani in How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. In fact, it has all the limitations and restrictions of a Lakehouse approach as mentioned in the paper Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics .
Belcorp’s data platform supports two main use cases. On one side, it provides data to be consumed using visualization tools, encouraging self-service. On the other side, it provides functional data to end-users, like data scientists or data analysts, through distributed data warehouses and object storage more suited to advanced analytical practices.

The following reference design explains the main two layers in charge of providing functional data for these use cases. The data processing layer is composed of two sub-layers. The first is Belcorp’s Data Lake Integrator, which is a built-in, in-house Python solution with a set of API REST services in charge of organizing all the data workloads and data stages inside the analytics repositories. It also works as a point of control to distribute resources to be allocated for each Amazon EMR Spark job. The processing sub-layer is mainly composed of the EMR cluster, which is in charge of orchestrating, tracking, and maintaining all the Spark jobs developed using a Scala framework.

For the persistent repository layer, we use Amazon Simple Storage Service (Amazon S3) object storage as a data repository for analytics workloads, where we have designed a set of data stages that have operational and functional purposes based on the reference architecture design. Discussing the repository design in more depth is out of scope for this post, but we must note that it covers all the common challenges related to data availability, data accessibility, data consistency, and data quality. In addition, it achieves all Belcorp’s needs required by its business model, despite all limitations and restrictions we inherit by the design previously mentioned.
We can now move our attention to the main purpose of this post.
As we mentioned, we experienced critical incidents (some of which existed before) and unexpected cost increases at the beginning of 2021, which motivated us to take action. The following table lists some of the main issues that attracted our attention.
| Reported Incidents |
Impact |
| Delay in Spark jobs on Amazon EMR |
Core workloads take a long time |
| Delay in Amazon EMR nodes auto scaling |
Workloads take a long time |
| Increase in Amazon EMR computational usage per node |
Unexpected cost increase |
| Lost resource containers |
Workloads process a huge data crash |
| Overestimated memory and CPUs |
Unexpected cost increase |
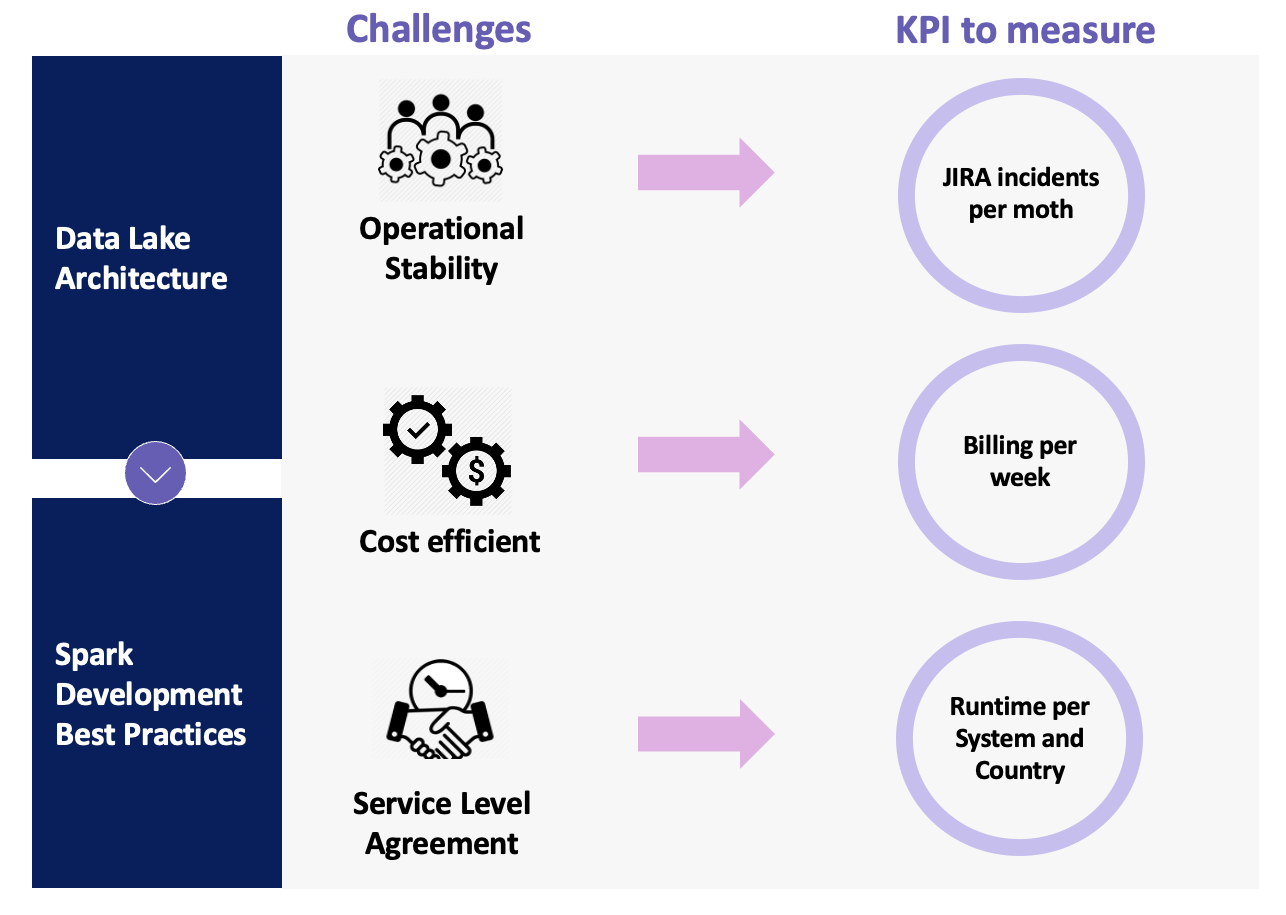
To face these issues, we decided to change strategies and started to analyze each issue in order to identify the cause. We defined two action lines based on three challenges that the leaders wanted us to work on. The following figure summarizes these lines and challenges.

The data lake architecture action line refers to all the architectural gaps and deprecated features that we determined as part of the main problems that were generating the incidents. The Spark development best practices action line is related to the developed Spark data solution that had been causing instability due to bad practices during the development lifecycle. Focusing on these action lines, our leaders defined three challenges in order to decrease the number of incidents and guarantee the quality of the service we provide: operational stability, cost-efficiency, and SLAs.
Based on these challenges, we defined three KPIs to measure the success of the project. Jira incidents allow us to validate that our changes are having a positive impact; billing per week shows the leaders that part of the changes we applied will gradually optimize cost; and runtime provides the business users with a better time to market.
Next, we defined the next steps and how to measure progress. Based on our monitoring framework, we determined that almost all incidents that arose were related to the data processing and persistent repository layers. Then we had to decide how to solve them. We could make reactive fixes in order to achieve operational stability and not have an impact on business, or we could change our usual way of working, analyze each issue, and provide a final solution to optimize our framework. As you can guess, we decided to change our way of working.
We performed a preliminary analysis to determine the main impacts and challenges. We then proposed the following actions and improvements based on our action lines:
- Data lake architecture – We redesigned the EMR cluster; we’re now using core and task nodes
- Spark development best practices – We optimized Spark parameters (RAM memory, cores, CPUs, and executor number)
In the next section, we explain in detail the actions and improvements proposed in order to achieve our goals.
Actions and improvements
As we mentioned in the previous section, the analysis made by the architecture team resulted in a list of actions and improvements that would help us face three challenges: operational stability, a cost-efficient data ecosystem, and SLAs.
Before going further, it’s a good time to provide more details about the Belcorp data processing framework. We built it based on Apache Spark using the Scala programming language. Our data processing framework is a set of scalable, parameterizable, and reusable Scala artifacts that provide development teams with a powerful tool to implement complex data pipelines, achieving the most complex business requirements using Apache Spark technology. Through the Belcorp DevOps framework, we deploy each artifact to several non-production environments. Then we promote into production, where the EMR cluster launches all the routines using the Scala artifacts that reference each conceptual area inside the analytical platform. This part of the cycle provides the teams with some degree of flexibility and agility. However, we forgot, for a moment, the quality of the software we were developing using Apache Spark technology.
In this section, we dive into the actions and improvements we applied in order to optimize the Belcorp data processing framework and improve the architecture.
Redesigning the EMR cluster
The current design and implementation of the Belcorp data lake is not the first version. We’re currently in version 2.0, and from the beginning of the first implementation until now, we’ve tried different EMR cluster designs to implement the data processing layer. Initially, we used a fixed cluster with four nodes (as shown in the following figure), but when the auto scaling capability was launched and Belcorp’s data workloads increased, we decided to move it there to optimize resource usage and costs. However, an auto scaled EMR cluster has different options too. You can choose between core and task nodes with a minimal and maximum number of each. In addition, you can select On-Demand or Spot Instances. You can also implement an optimized allocation strategy using EMR instance fleets to reduce the probability of Spot Instance loss. For more information about Amazon EMR resources allocation strategies, see Spark enhancements for elasticity and resiliency on Amazon EMR and Optimizing Amazon EMR for resilience and cost with capacity-optimized Spot Instances.

We tested all these capabilities, but we found some problems.
First, although AWS offers many capabilities and functionalities around Amazon EMR, if you don’t have some degree of knowledge about the technology that you want to use, you may encounter many issues as the use cases arise. As we mentioned, we decided to use the Apache Spark data processing engine through Amazon EMR as a part of Belcorp data ecosystem, but we faced many issues. Whenever an incident appeared, it motivated the data architect team in charge to fix it, as a part of the operational and support tasks. Almost all these reactive fixes were related to changing Amazon EMR configuration to try different alternatives in order to efficiently solve these incidents.
We figured out that almost all incidents were related to resource allocation, so we tested many configuration options such as instance types, increasing the number of nodes, customized rules for auto scaling, and fleet strategies. This last option was used to reduce node loss. At the end of 2020, we validated that an EMR cluster with automatic scaling enabled with a minimum capacity of three On-Demand core nodes 24/7 and the ability to scale up to 25 On-Demand core nodes provided us with a stable data processing platform. At the beginning of 2021, more complex Spark jobs were deployed as a part of the data processing routines inside the EMR cluster, causing operational instability again. In addition, the billing was increasing unexpectedly, which alerted leaders whose team needed to redesign the EMR cluster in order to keep healthy operational stability and optimize the costs.
We soon realized that it was possible to reduce up to 40% of the current billing using Spot Instances, instead of keeping all core nodes in On-Demand consumption. Another infrastructure optimization that we wanted to apply was to replace a number of core nodes with task nodes, because almost all Belcorp data workloads are memory-intensive and use Amazon S3 to read the source data and write the result dataset. The question here was how to do that without losing the benefits of the current design. To answer this question, we had the guidance of the AWS Account Team and our AWS Analytics and Big Data Specialist SA, in order to clarify questions about the following:
- Apache Spark implementation in Amazon EMR
- Core and task node best practices for production environments
- Spot Instance behavior in Amazon EMR
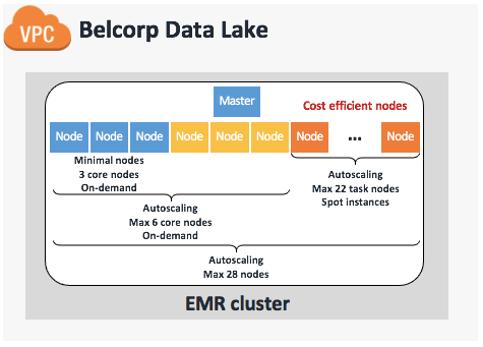
We definitely recommend addressing these three main points before applying any changes because, according to our previous experience, making modifications in the dark can lead to costly and underperforming Amazon EMR implementation. With that in mind, we redesigned the EMR cluster to utilize EMR managed scaling, which automatically resizes your cluster for best performance at the lowest possible cost. We defined a maximum of 28 capacity units with three On-Demand core nodes always on (24/7) in order to support data workloads during the day. We then set an auto scaling limit of six On-Demand cores in order to provide minimal HDFS capabilities to support the remaining 22 task nodes composed of Spot Instances. This final configuration is based on advice from AWS experts that we have at least one core node to support six task nodes, keeping a 1:6 ratio. The following table summarizes our cluster design.
| Cluster Scaling Policy |
Amazon EMR Managed Scaling Enabled |
Minimum node units (MinimumCapacityUnits) |
3 |
Maximum node units (a) |
28 |
On-demand limit (MaximumOnDemandCapacityUnits) |
6 |
Maximum core nodes (MaximumCoreCapacityUnits) |
6 |
| Instance type |
m4.10xlarge |
| Number of primary nodes |
1 |
| Primary node instance type |
m4.4xlarge |
The following figure illustrates our updated and current cluster design.
Tuning Spark parameters
As any good book about Apache Spark can tell you, Spark parameter tuning is the main topic you need to look into before deploying a Spark application in production.
Adjusting Spark parameters is the task of setting up the resources (CPUs, memory, and the number of executors) to each Spark application. In this post, we don’t focus on driver instance resources; we focus on the executors because that’s the main issue we found inside Belcorp’s implementation.
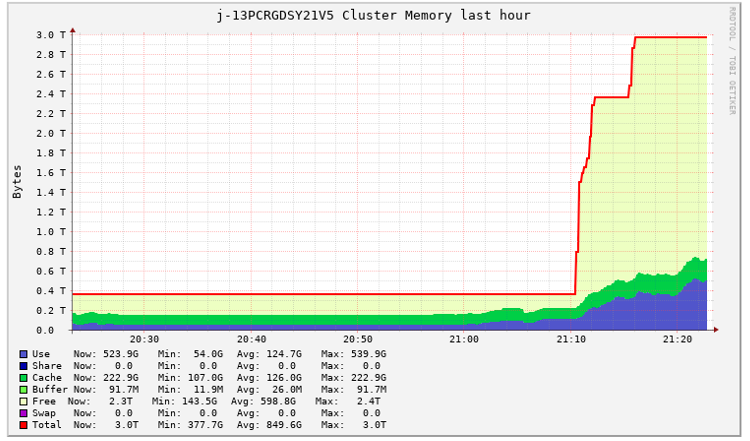
After we applied improvements around join operation and cache strategies in Spark application development, we realized that some of those applications were assigned with overestimated resources in the EMR cluster. That means Spark applications assigned resources, but only 30% of the resources were used. The following Ganglia report illustrates the overestimation of resource allocation for one Spark application job, which we captured during one of our tests.

A big consequence of this behavior was the massive deployment of EMR nodes that weren’t being properly utilized. That means that numerous nodes were provisioned because of the auto scaling feature required by a Spark application submit, but much of the resources of these nodes were kept free. We show a basic example of this later in this section.
With this evidence, we began to suspect that we needed to adjust the Spark parameters of some of our Spark applications.
As we mentioned in previous sections, as part of the Belcorp data ecosystem, we built a Data Pipelines Integrator, which has the main responsibility of maintaining centralized control of the runs of each Spark application. To do that, it uses a JSON file containing the Spark parameter configuration and performs each spark-submit using Livy service, as shown in the following example code:
'/usr/lib/spark/bin/spark-submit' '--class' 'LoadToFunctional' '--conf' 'spark.executor.instances=62' '--conf' 'spark.executor.memory=17g' '--conf' 'spark.yarn.maxAppAttempts=2' '--conf' 'spark.submit.deployMode=cluster' '--conf' 'spark.master=yarn' '--conf' 'spark.executor.cores=5' 's3://<bucket-name>/FunctionalLayer.jar' '--system' 'CM' '--country' 'PE' '--current_step' 'functional' '--attempts' '1' '--ingest_attributes' '{"FileFormat": "zip", "environment": "PRD", "request_origin": "datalake_integrator", "next_step": "load-redshift"}' '--fileFormat' 'zip' '--next_step' 'load-redshift'
This JSON file contains the Spark parameter configuration of each Spark application related to an internal system and country we submit to the EMR cluster. In the following example, CM is the name of the system and PE is the country code that the data comes from:
"systems" : {
"CM" : {
"PE" : {
"params" : {"executorCores": 15, "executorMemory": "45g", "numExecutors": 50 },
"conf" : { "spark.sql.shuffle.partitions" :120 }
}
}
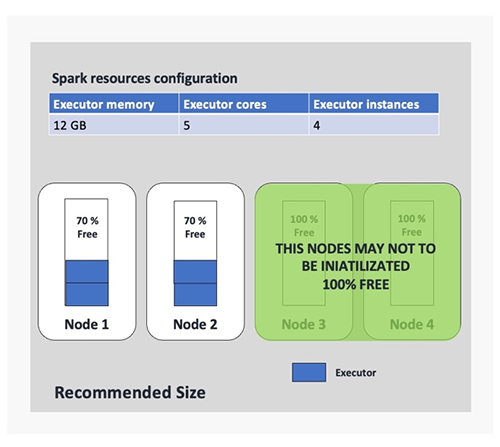
The problem with this approach is that as we add more applications, the management of these configuration files becomes more complex. In addition, we had a lot of Spark applications set up with a default configuration that was defined a long time ago when workloads were less expensive. So, it was expected that some things would change. One example of a Spark application with uncalibrated parameters is shown in the following figure (we use four executor instances only for the example). In this example, we realized we were allocating executors with a lot of resources without following any of the Spark best practices. This was causing the provisioning of fat executors (using Spark slang) allocating each of those in at least one node. That means that if we define a Spark application to be submitted using 10 executors, we require at least 10 nodes of the cluster and use 10 nodes for only one run, which was very expensive for us.

When you deal with Spark parameter tuning challenges, it’s always a good idea to follow expert advice. Perhaps one of the most important pieces of advice is related to the number of executor cores you should use in one Spark application. Experts suggest that an executor should have up to four or five cores. We were familiar with this restriction because we formerly developed Spark applications in the Hadoop ecosystem because of Hadoop File Systems I/O restrictions. That is, if we have more cores configured for one executor, we perform more I/O operations in a single HDFS data node, and it’s well known that HDFS degrades due to high concurrency. This constraint isn’t a problem if we use Amazon S3 as storage, but the suggestion remains due to the overload of the JVM. Remember, while you have more operational tasks, like I/O operations, the JVM of each executor has more work to do, so the JVM is degraded.
With these facts and previous findings, we realized that for some of our Spark applications, we were using only 30% of the assigned resources. We needed to recalibrate the Spark job parameters in order to allocate only the best-suited resources and significantly reduce the overuse of EMR nodes. The following figure provides an example of the benefits of this improvement, where we can observe a 50% of node reduction based on our earlier configuration.

We used the following optimized parameters to optimize the Spark application related to the CM system:
"systems" : {
"CM" : {
"PE" : {
"params" : {"executorCores": 5, "executorMemory": "17g", "numExecutors": 62 },
"conf" : { "spark.sql.shuffle.partitions" :120 }
}
}
Results
In this post, we wanted to share the success story of our project to improve the Belcorp data ecosystem, based on two lines of actions and three challenges defined by leaders using AWS data technologies and in-house platforms.
We were clear about our objectives from the beginning based on the defined KPIs, so we’ve been able to validate that the number of JIRA incidents reported at the end of May 2021 had a notable reduction. The following figures shows a reduction of up to 75% in respect to previous months, highlighting March as a critical peak.

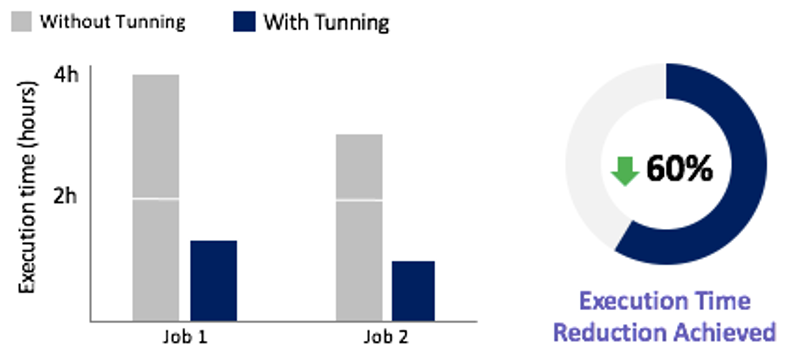
Based on this incident reduction, we figured out that almost all Spark job routines running in the EMR cluster benefitted from a runtime optimization, including the two most complex Spark jobs, with a reduction up to 60%, as shown in the following figure.

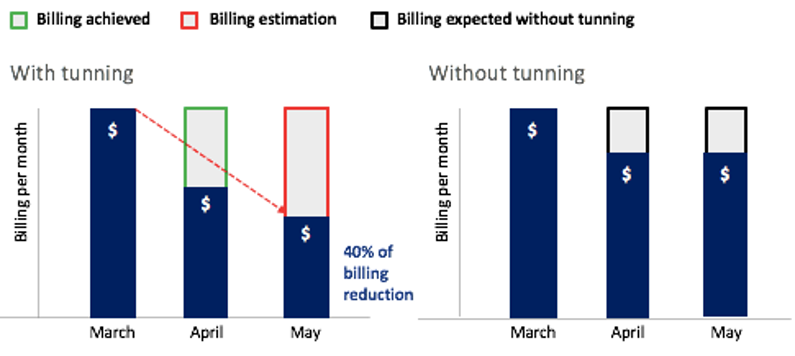
Perhaps the most important contribution of the improvements made by the team is directly related to the billing per week. For example, Amazon EMR redesigning, the join operation improvements, cache best practices applied, and Spark parameter tuning—all of these produced a notable reduction in the use of cluster resources. As we know, Amazon EMR calculates billing based on the time that the cluster nodes have been on, regardless of whether they do any work. So, when we optimized EMR cluster usage, we optimized the costs we were generating as well. As shown in the following figure, only in 2 months, between March and May, we achieved a billing reduction of up to 40%. We estimate that we will save up to 26% of the annual billing that would have been generated without the improvements.

Conclusion and next steps
The data architecture team is in charge of the Belcorp data ecosystem’s continuous improvements, and we’re always being challenged to achieve a best-in-class architecture, craft better architectural solution designs, optimize cost, and create the most automated, flexible, and scalable frameworks.
At the same time, we’re thinking about the future of this data ecosystem—how we can adapt to new business needs, generate new business models, and address current architectural gaps. We’re working now on the next generation of the Belcorp data platform, based on novel approaches like data products, data mesh, and lake houses. We believe these new approaches and concepts are going to help us to cover our current architectural gaps in the second generation of our data platform design. Additionally, it’s going to help us better organize the business and development teams in order to obtain greater agility during the development cycle. We’re thinking of data solutions as a data product, and providing teams with a set of technological components and automated frameworks they can use as building blocks.
Acknowledgments
We would like to thank our leaders, especially Jose Israel Rico, Corporate Data Architecture Director, and Venkat Gopalan, Chief Technology, Data and Digital Officer, who inspire us to be customer centric, insist on the highest standards, and support every technical decision based on a stronger knowledge of the state of the art.
About the Authors
 Diego Benavides is the Senior Data Architect of Belcorp in charge of the design, implementation, and the continuous improvement of the Global and Corporate Data Ecosystem Architecture. He has experience working with big data and advanced analytics technologies across many industry areas like telecommunication, banking, and retail.
Diego Benavides is the Senior Data Architect of Belcorp in charge of the design, implementation, and the continuous improvement of the Global and Corporate Data Ecosystem Architecture. He has experience working with big data and advanced analytics technologies across many industry areas like telecommunication, banking, and retail.
Luis Bendezú works as a Senior Data Engineer at Belcorp. He’s in charge of continuous improvements and implementing new data lake features using a number of AWS services. He also has experience as a software engineer, designing APIs, integrating many platforms, decoupling applications, and automating manual jobs.
 Mar Ortiz is a bioengineer who works as a Solutions Architect Associate at AWS. She has experience working with cloud compute and diverse technologies like media, databases, compute, and distributed architecture design.
Mar Ortiz is a bioengineer who works as a Solutions Architect Associate at AWS. She has experience working with cloud compute and diverse technologies like media, databases, compute, and distributed architecture design.
Raúl Hugo is an AWS Sr. Solutions Architect with more than 12 years of experience in LATAM financial companies and global telco companies as a SysAdmin, DevOps engineer, and cloud specialist.