Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/genpage-towards-end-to-end-generative-homepage-construction-at-netflix-77146fba8a08
Authors: Lequn Wang, Jiangwei Pan, and Linas Baltrunas

Introduction
The Netflix homepage is the first thing users see when they open the app and the primary way they discover content to enjoy. Almost every part of it is personalized, including which rows appear, which entities show up within those rows, and how everything is arranged on the page.
Constructing that homepage is a genuinely hard problem. It is not simply producing one ranked list. The homepage is a structured, two-dimensional layout, made up of recommendation rows and the entities within them. Here, an entity can be a movie, show, game, live event, or other recommendable item. Each choice can affect the value of the others. Traditionally, it is built through a complex, multi-stage pipeline, with separate components for candidate generation and ranking at both the row and entity levels.
We saw an opportunity to rethink this design. Large language models have shown that a single generative model can perform diverse tasks just by generating a response to a prompt. Inspired by this prompt-response paradigm, we trained a single generative model to build the homepage by directly answering one question:
Given everything we know about this user and this request, what homepage should we generate to maximize user satisfaction?
We call this approach GenPage. It treats the user history and request context as the prompt, and autoregressively generates the entire homepage as the response (Figure 1). Unlike most generative recommenders, such as TIGER, HSTU, and OneRec, which generate flat ranked lists, GenPage generates the rows, entities, and layout together.
This shift is motivated by several goals:
- End-to-end modeling. A single transformer model that constructs the page from raw input signals can replace a complex multi-stage recommender stack. This reduces the number of ML models to maintain, avoids misaligned objectives across stages, and eliminates much of the traditional feature engineering.
- Whole-page optimization via reinforcement learning (RL). Autoregressive page generation makes it possible to optimize for page-level rewards with RL. This can capture interactions across rows and entities, such as diversity or the balance between rows with different stopping power. For example, a Continue Watching row near the top of the page may strongly satisfy a user’s immediate intent, but also reduce how much of the page they browse. Modeling these interactions at the page level lets us align the system more directly with user satisfaction than entity-level objectives alone.
- Better scaling behavior. A generative transformer model gives us a clearer path to improving quality through more data, compute, and model capacity, without repeatedly redesigning the system.
- Flexibility and extensibility. The prompt-response paradigm is flexible by design. By simplifying feature engineering and enabling whole-page optimization, GenPage makes it easier to support new product experiences, such as additional content types like live events, games, and podcasts; layouts beyond the current two-dimensional structure; personalized UI components; and per-entity artwork personalization, all with fewer architectural changes.
Bringing GenPage into production at Netflix also required solving challenges specific to industry-scale recommender systems. Because the homepage is generated in real time, serving latency is a primary engineering constraint. We also need to handle entity cold start in a constantly evolving catalog, keep the model fresh as user interests and cultural trends shift, and enforce complex product and business rules on the generated output.
Despite these challenges, GenPage has already had substantial production impact. In an online A/B test against a mature, highly optimized multi-stage production recommender, GenPage delivered statistically significant gains on the core user engagement metric we use for launch decisions, while reducing end-to-end serving latency by 20%.
Offline, two findings stood out. First, enriching the prompt helped more than scaling model capacity in our current regime. Second, RL post-training increased homepage diversity even though diversity was not part of the objective.
We expect this approach to generalize to many personalization settings. In this post, we focus on Netflix homepage construction as a concrete case study, sharing our design, trade-offs, and lessons learned.
Data
Moving from a traditional recommender to a generative transformer requires us to rethink how the data is represented. Similar to how an LLM turns text into tokens, GenPage represents both the user context and the generated homepage as one sequence of discrete tokens (Figure 2). This sequence includes the full structured homepage layout, with multiple rows and the entities inside them, so the model can generate the page holistically rather than scoring each row or entity in isolation.
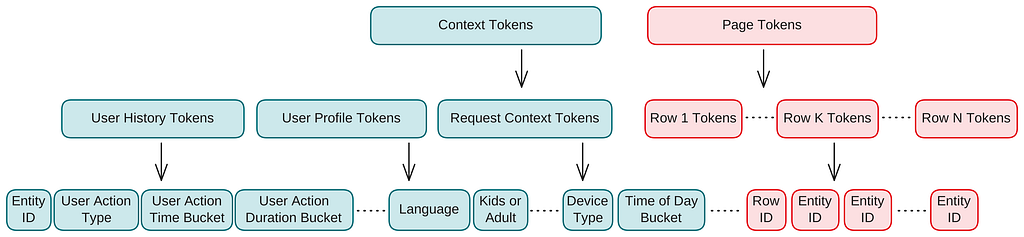
Each training example represents a homepage impression and consists of three components:
- Context: user engagement history, profile attributes, and request context.
- Page: the recommended rows and entities shown on the homepage, in layout order.
- Feedback: user interactions with that page, such as play, thumbs-up, or abandonment for entities on the page.
Only the context and page are tokenized as model inputs and outputs. Feedback is used to derive supervision signals via our internal reward system (see the Reward system section).
Instead of using an off-the-shelf text tokenizer, we build a domain-specific tokenizer for the homepage construction data. This is a proven approach in recommender systems and other specialized domains including computer vision, biology, and chemistry, where the raw data is not naturally represented as text. Compared with generic text tokenization, this gives us two key advantages:
- Computational efficiency. Custom tokenization significantly reduces sequence length, lowering inference cost and latency. For example, representing the event “User watched Orange Is the New Black for 50 minutes 30 days ago.” would require 16 tokens with the GPT-5 tokenizer, whereas our scheme compresses it to 4 tokens: [Entity_ID], [Action_Type], [Action_Time_Bucket], and [Action_Duration_Bucket].
- Product control. A direct mapping between tokens and product concepts, such as rows and entities, makes it easier to control what the model can generate. This is crucial for enforcing business rules on the final homepage.
Context tokens
Context tokens encode user engagement history, user profile, and request context.
We represent user history as a sequence of user actions. For each action, we extract key metadata, including the action type, entity ID, timestamp, and duration. These actions include both explicit signals, such as play, add to My List, and thumbs-up, and implicit signals, such as trailer views or visits to a details page.
User profile tokens capture attributes such as language and profile type. Request context tokens encode signals like time of day, day of week, and device.
Some data sources are too long to include directly as raw token sequences. A user’s full impression history, for example, would be prohibitively expensive to represent in full. In these cases, we use a summarized version. This is a pragmatic trade-off: while GenPage aims to operate on raw inputs as much as possible, handcrafted summaries still introduce a form of prompt engineering into the pipeline. Learning to compress these long data sources end to end is an important direction for future work.
To help the model distinguish between data sources, we insert special tokens that mark the start of each segment. Continuous signals, such as timestamps and durations, are bucketized into discrete ranges to keep the vocabulary finite.
Page tokens
Each entity, such as a show, movie, or game, and each row, such as Korean TV Shows, is represented as a single token. The homepage is serialized in layout order: left to right, then top to bottom. We update the entity and row vocabulary daily to incorporate newly added entities and rows. Entities that are still out of vocabulary at serving time are handled through semantic embedding fusion and fallback tokens, both described later.
In principle, the same paradigm can extend to any output that can be expressed as a linear token sequence. This includes layouts beyond the current two-dimensional structure, such as one-dimensional feeds or mixed layouts, as well as personalized UI components and per-entity outputs such as personalized artwork. We leave these extensions to future work.
Paginated recommendation
To make recommendations responsive to in-session user preferences, the homepage is often generated incrementally, a few rows at a time. Before each pagination request, we append the page tokens from previously generated rows to the prompt, along with the user’s latest engagements on those rows from Netflix’s real-time event-logging infrastructure. This allows the model to generate the next set of recommendations using both the user’s long-term preferences and their most recent in-session behavior.
Reward system
To quantify the long-term value of a recommendation, we rely on an internal reward system described in prior work. The reward system is tuned through online A/B testing to align with long-term user satisfaction and serves as the primary supervision signal for both supervised and reinforcement learning.
The reward system processes user feedback and assigns a scalar reward for every impressed entity on the homepage. For instance, a TV show binge-watched in one night reflects stronger user satisfaction and receives a higher reward than a movie watched for only 10 minutes. An impressed entity that the user abandons receives a negative reward.
We define the page-level reward as the sum of rewards across all impressed entities on the homepage.
Model architecture
GenPage uses a standard decoder-only transformer architecture, the same general architecture behind many modern LLMs. This choice keeps the model simple and flexible, while also letting us benefit from the broad ecosystem of tooling around transformer training and serving.
One architectural detail is that we untie the input embedding and output projection weights. This is useful because pretraining and post-training place different demands on the logits. Next-token prediction pretraining optimizes a softmax over the vocabulary, while weighted binary classification (WBC) post-training optimizes per-token sigmoid scores, as described below. Untying the weights gives the model more flexibility to adapt to both objectives.
Training recipe
Our training pipeline mirrors the LLM recipe: we first teach the model the “language” of the Netflix homepage through pretraining, then align its outputs with user satisfaction through post-training. For post-training, we explore two alternative approaches: weighted binary classification (WBC) and reinforcement learning (RL).
WBC is simpler to optimize and aligns directly with the entity-level objectives of our production ranking models. RL is harder to evaluate and optimize, but it is the key path to GenPage’s full vision of page-level optimization, with the flexibility to incorporate test-time reasoning and multi-token entity representations.
Pretraining via next-token prediction
We pretrain the model with a standard next-token prediction objective: given the context tokens and a prefix of page tokens, the model learns to predict the next page token. This stage focuses on representation learning, teaching the model the relationship between user contexts and successful homepages. Note that our context-page training examples resemble the prompt-response pairs used in LLM supervised fine-tuning (SFT) more than the raw text used in LLM pretraining. We nonetheless call this stage pretraining because we train the model from scratch rather than fine-tuning from an existing checkpoint.
Unlike LLMs, which often face a scarcity of high-quality labeled data, recommender systems have an abundance of user feedback. For pretraining, we use homepage impressions that received positive feedback when served in production, bootstrapping the model to generate pages similar to those produced by the existing production system.
However, pretraining mainly teaches GenPage to imitate the production system. It does not directly optimize the magnitude of the reward, and as GenPage becomes part of production, repeatedly training on pages generated by earlier versions of the model can risk model degeneration. To address these limitations, we explore two post-training approaches.
Post-training via weighted binary classification
One effective way to align the generative model with user satisfaction is weighted binary classification (WBC). At a high level, WBC turns generation into token-level value prediction: given the user context and the tokens generated so far, the model learns to estimate the value of generating each possible next row or entity token.
This objective is easier to optimize than page-level RL. By decomposing the homepage into per-token targets, WBC provides token-level credit assignment by construction, rather than requiring RL to infer how each generated decision contributed to the final page-level reward.
This training setup is enabled by our custom tokenization. Each page token corresponds directly to a specific entity or row, making it straightforward to assign a reward. For every impressed entity on the page, our reward system provides a scalar reward based on user feedback. For each impressed row, we derive a row-level reward by aggregating the rewards of the entities in that row.
From each reward, we derive a binary label from its sign, such as positive engagement versus abandonment, and a weight from its magnitude, such as binge-watching receiving a higher weight than a short play. We then optimize a weighted binary cross-entropy loss on the logit for the corresponding token. Under this setup, the logit for a token can be interpreted as the model’s value estimate for generating that token at that position.
Although the model is trained as a value predictor, it can still generate pages autoregressively. At each step, the model scores the candidate next tokens, greedily selects the token with the highest value, and appends it to the prefix. This process repeats token by token until the full homepage is generated.
Post-training via reinforcement learning
Our second post-training approach is reinforcement learning (RL). WBC is effective for optimizing entity-level metrics, but it does not directly optimize the homepage as a whole. RL treats page generation as a sequential decision-making problem, allowing the model to optimize a page-level reward while preserving the flexibility of autoregressive generation.
This opens the door to several important capabilities:
- Whole-page optimization. RL directly optimizes an aggregate page-level reward, allowing the model to account for interactions across rows and entities, such as diversity, stopping power, and page-level business constraints.
- Test-time reasoning. Analogous to its application in LLMs, RL can optimize reasoning capabilities for generative recommendation. Reasoning outputs can also be viewed as a form of automated feature engineering.
- Multi-token entity support. In our current tokenization, each entity and row is represented as a single token, so rewards map cleanly to individual tokens. In more complex settings, however, an entity may require multiple tokens, such as [Show_ID] plus [Episode_#] for an episode, or a sequence of semantic ID tokens. In that case, WBC’s per-token labeling becomes ambiguous because a single entity-level reward must be distributed across multiple tokens. RL avoids this issue by optimizing the sequence-level return, making it a more natural fit for variable-length, multi-token entities.
Inspired by the RLHF recipe used to align large language models, we adopt a two-step approach. First, we train a reward model that predicts the page-level reward for a generated page. This reward model is distinct from the reward system described earlier. The reward system converts observed user feedback into a scalar reward for a page that was actually shown, whereas the reward model predicts the page-level reward for a generated page without showing it to the user. This prediction is what lets RL optimize against arbitrary candidate pages during training.
Training against a reward model avoids the high variance of off-policy correction on logged or predicted propensities, but introduces the risk of reward hacking. Since the reward model is trained on data generated from the production policy, it is most reliable on pages similar to those the production policy generates. We therefore use a KL penalty to keep the policy close to the pretrained checkpoint, which itself was trained to mimic the production policy. This keeps the pages within the reward model’s region of coverage and limits opportunities for reward hacking.
For the RL algorithm, we adopt Dr. GRPO, a variant of GRPO that mitigates biases in the training objective. To train the model within this framework, we need the following components:
- Prompts: production user requests, represented by context tokens.
- Policy and reference models: both are initialized from the pretrained checkpoint; the reference model anchors the KL penalty discussed above.
- Reward model: a dedicated transformer-based reward model, also initialized from the pretrained checkpoint, predicts the page-level outcome reward, using the sum of entity-level rewards from our internal reward system as the supervision target. We also incorporate rule-based format rewards to guide the RL policy. For example, the page should resemble a list of rows, and business-critical rows or entities should not appear too low on the page.
Addressing production challenges
Cold start
New entities lack the rich interaction data needed to learn robust token embeddings. We address this through two complementary strategies:
- Context injection. We inject metadata about new or time-sensitive entities (e.g., Live Now events) directly into the context tokens, providing the model with semantic and time-sensitive information.
- Semantic embedding fusion. Rather than relying solely on entity ID embeddings learned from user interaction data, we represent each entity as a fusion of its ID embedding and a content-based embedding derived from semantic information such as synopses, cast, transcripts, genres, and video content. This fused embedding serves as the input embedding for the entity’s token in the transformer. During training, with small probability, we randomly replace an entity ID token with the generic fallback token (described below), so the model learns to make recommendations from the content-based embedding alone. This ensures that a new entity has a meaningful representation in the same latent space as established entities as soon as its content metadata is available — even before it has any interaction data.
Multi-cadence incremental training
At Netflix scale, daily retraining of a large transformer from scratch is prohibitively expensive, but recommendation models must remain fresh to capture shifting trends and new catalog additions. We address this with a multi-cadence incremental training strategy (Figure 3).
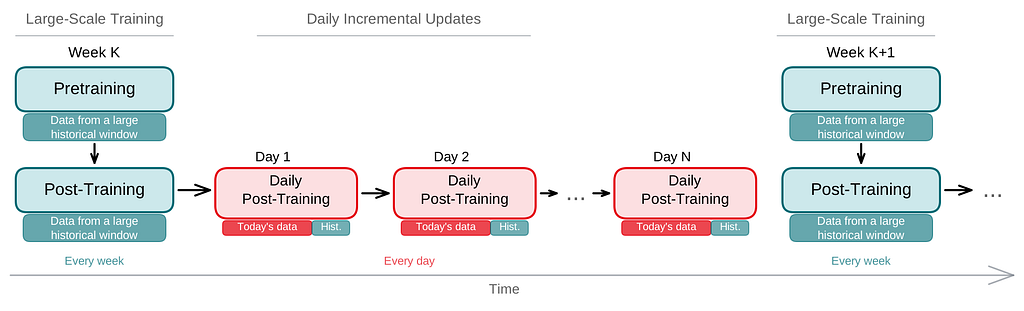
Our training pipeline operates on a cyclic schedule with two distinct rhythms. At a tunable cadence, we conduct a large-scale pretraining and post-training pass on data from a broad historical window. Between these passes, each day we perform an incremental update by continuing post-training from the previous day’s checkpoint, using a mix of the latest day’s data and a sampled subset of past data. This helps the model stay current with new trends and catalog changes while preventing overfitting and catastrophic forgetting.
To manage the daily influx of new tokens (e.g., new entities, rows), we employ fallback tokens. New tokens are initialized using fallback tokens of their type (e.g., [Row_Fallback_Token] for new rows, [Entity_Fallback_Token] for new entities). During training, we randomly replace a small percentage of known tokens with fallback tokens, teaching the model to handle unknown tokens gracefully.
Enforcing business rules
A Netflix homepage must satisfy structural constraints (e.g., organized as a list of rows) as well as product logic such as deduplication, row pinning, and category consistency (e.g., entities in a Comedy row must be comedies). While training signals can encourage rule adherence, they cannot guarantee strict compliance.
We enforce these rules at inference time through constrained decoding. At each autoregressive generation step, we compute a mask of eligible tokens based on the applicable business rules and apply it to the output logits, allowing only rule-compliant tokens to be generated. This is greatly simplified by our custom tokenization: because each entity and row is a single token, business rules map directly to token-level masks, avoiding the multi-token bookkeeping that constrained decoding requires over a text vocabulary. For example, to pin a specific row (e.g., popular games) at a fixed position (e.g., row position 2), we simply mask out all other tokens at that position.
Hybrid row decoding
Autoregressive generation ensures that each newly generated token is conditioned on the full preceding context, but generating every entity token one at a time can be expensive. We leverage the structure of the homepage to balance inference efficiency with the amount of contextual information available to each generated token.
Within each row, the first few entities are especially important: they receive the most user attention and strongly shape the row’s perceived quality and theme. To reduce inference latency, we use a hybrid row decoding strategy. The model autoregressively generates only the first few entities in each row. Conditioned on this generated prefix, we obtain logits for all eligible entities in a single forward pass and select the top-scoring remaining entities, subject to the same inference-time business-rule constraints described above.
This approach preserves autoregressive conditioning where it matters most while avoiding the latency and cost of decoding long rows token by token.
Offline experiments
We ran a series of ablations on Netflix internal data to understand how different components of GenPage affect model quality. Because the system was developed iteratively, individual ablations span different training configurations and data snapshots, so we report only relative comparisons within each study. Unless otherwise noted, experiments use ~200M-parameter models and report results on a held-out evaluation set.
Does pretraining help?
We compare WBC post-training with and without a preceding next-token-prediction pretraining stage. Figure 4 shows that pretraining yields substantial improvements across all metrics.
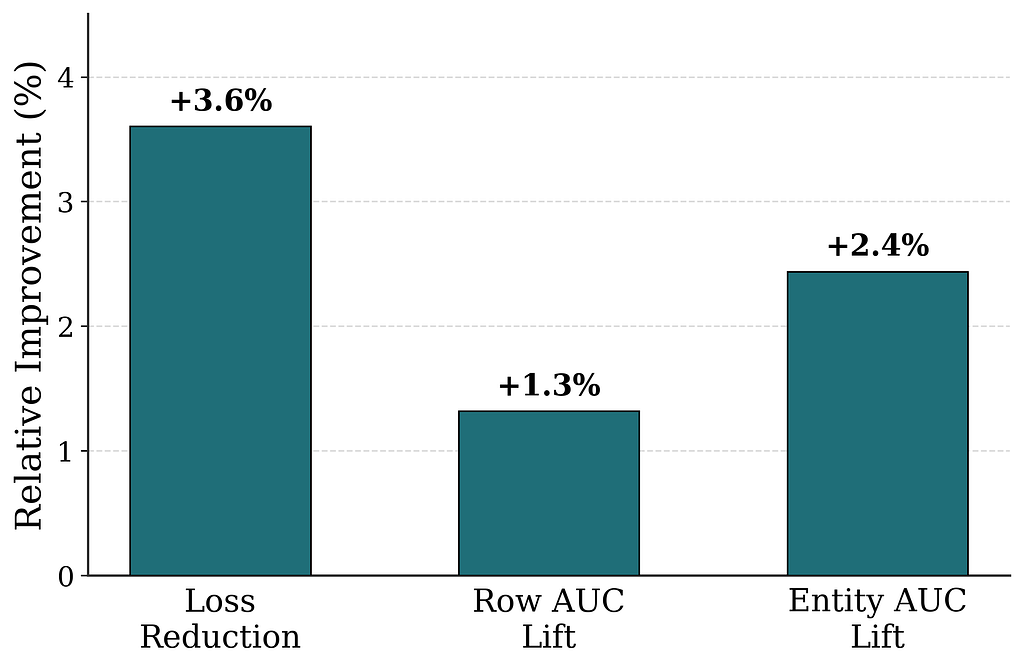
The gains may look small in absolute terms, but they are large in our production regime: setting aside the sample weighting, an Entity AUC lift from 0.91 to 0.92 means that for a randomly drawn pair of impressed entities, the model’s misranking rate drops from 9% to 8% — a magnitude of improvement we rarely observe from a single change on a mature production system. Pretraining the model on the “language” of the Netflix homepage provides a strong initialization for post-training, mirroring the pretrain-then-post-train recipe behind modern LLMs.
How does performance scale with model size?
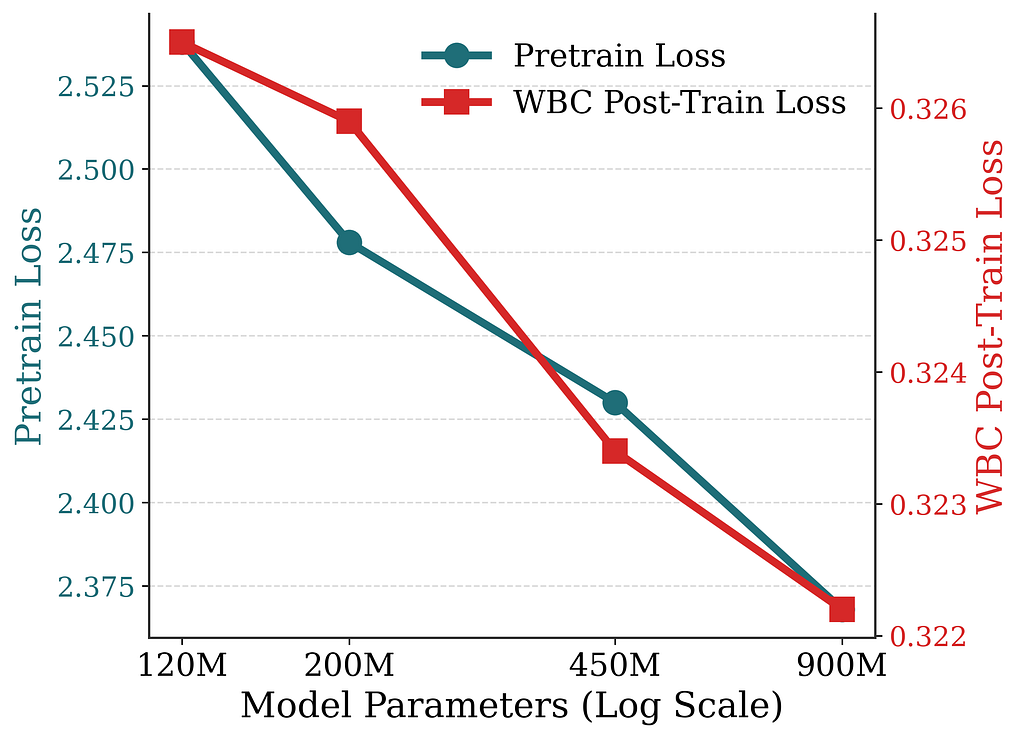
We sweep model size from ~120M to ~900M parameters (Figure 5) and report the next-token-prediction loss from pretraining and the WBC loss from post-training. Both losses decrease in a power-law-like fashion, mirroring the scaling trends seen in LLMs. This confirms that the generative approach scales favorably with model size, suggesting that recommendation quality can be further improved by scaling capacity.
How does performance scale with information in the user context?
Over the course of development, we progressively enriched the prompt, both by adding new data sources to the context and by refining how each source is tokenized. With model size held fixed, the WBC post-training loss decreases substantially as the context is enriched (Figure 6).
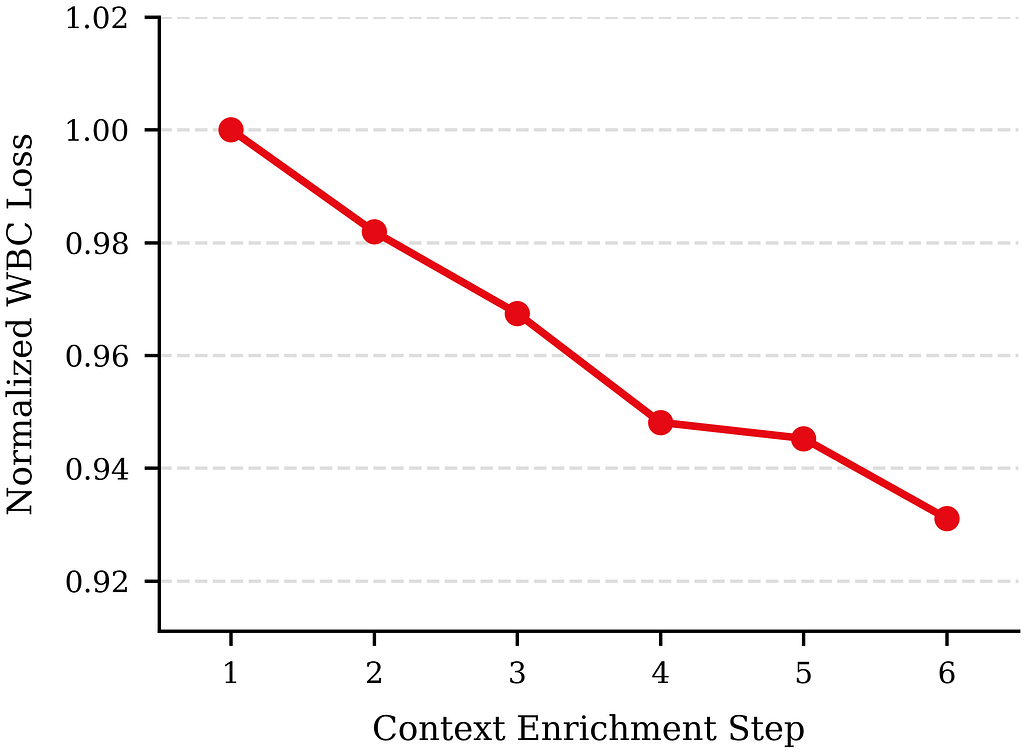
The model-size sweep and the context-enrichment sweep span different axes and are not strictly comparable: the model-size study covers roughly an order of magnitude in parameters, while the context study spans the full trajectory of our prompt design. Even so, the gap between the two is striking. Scaling the model from 120M to 900M parameters reduces WBC loss by roughly 1.3%, whereas the cumulative effect of enriching the context is around 6.9%. In several cases, a single well-designed context addition delivers a larger improvement than the entire ~7.5× model-capacity scaling.
This suggests that, in our regime, enriching the prompt — both what we put in the context and how we tokenize it — yields a substantially larger improvement than scaling model capacity. Personalization quality appears to be bottlenecked first by the information and representation available to the model, and only then by capacity. We expect context enrichment to dominate until the context is saturated, at which point model capacity becomes the primary driver.
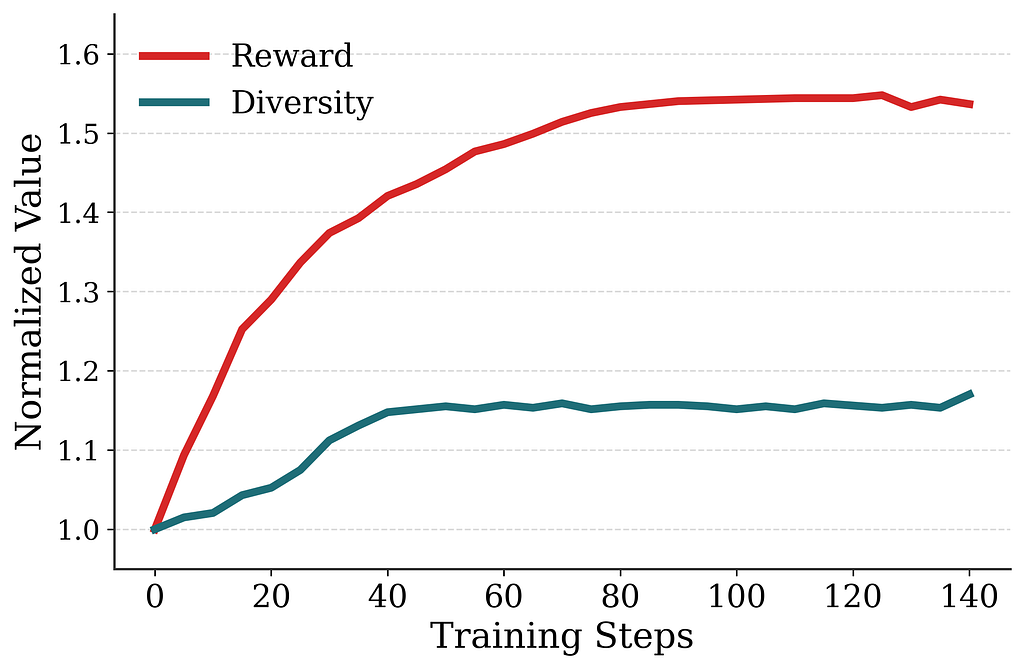
Does RL post-training optimize at the page level?
In offline evaluations (Figure 7), RL post-training consistently improves the page-level reward over the pretrained checkpoint, but this is largely confirmatory: the reward is computed using the same model the policy is optimizing against. More interestingly, although diversity is not part of the RL objective, homepage diversity — measured via pairwise embedding distance among entities on the page — also increases over the course of training. This suggests that the RL-trained policy is optimizing the page as a whole rather than myopically optimizing each token in isolation.
Online evaluation
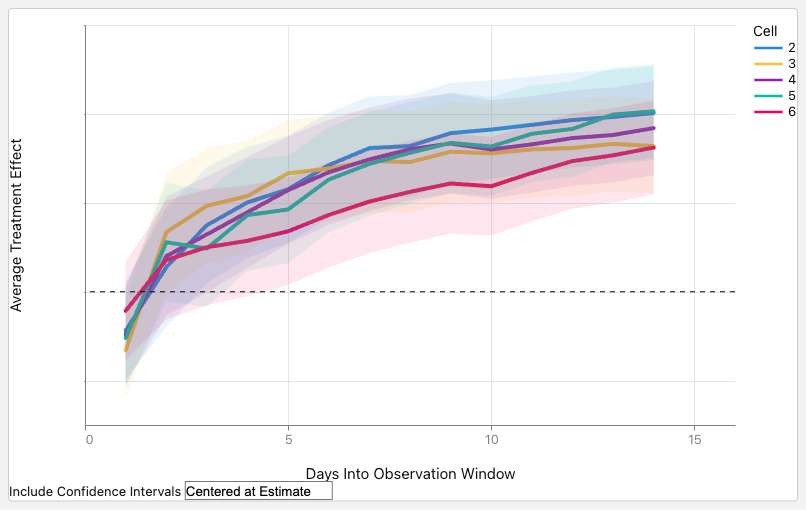
We conducted an online A/B test against the current production homepage recommender using GenPage. In this test, GenPage decoded over the existing production row and entity candidate sets, which help handle many business rules (such as eligibility).
Figure 8 shows the result: all variants delivered statistically significant improvements on the core user engagement metric we use for launch decisions (p < 0.001) against a mature, highly optimized multi-stage production baseline. The variants differed in their training-data configurations; that they all delivered comparable lifts suggests the gain is robust to these design choices rather than dependent on a particular configuration.
Alongside the engagement wins, we observed unintended shifts in the distribution of impressed entity categories (e.g., new vs. established titles, TV shows vs. movies). These shifts are not necessarily negative, but they are not something we explicitly optimized for, and they warrant deeper investigation. We suspect these shifts reflect GenPage personalizing more precisely than the production stack — consistent with an increase in homepage impression efficiency, i.e., users engaging with what they saw using fewer impressions. This sharper personalization appears to surface production-inherited components (such as the reward system) that aren’t yet aligned with the new generative paradigm. We plan to characterize the drivers of these shifts and, where appropriate, tune these components so the resulting distributions better align with desired product behavior.
We also observed strong responsiveness to in-session signals: the latest in-session actions quickly influenced subsequent recommendations and faded back to long-term preferences after a day or two, confirming that the model effectively attends to action timestamps. This responsiveness emerges naturally from the generative formulation, without the extensive manual feature engineering used in our production stack.
Contrary to the common assumption that generative models are slower, GenPage reduced end-to-end serving latency by 20% relative to the baseline. By replacing multiple ranking stages and heavy feature computation with a single transformer operating on raw tokenized inputs, we eliminated substantial serving complexity and computational overhead. Custom tokenization and hybrid row decoding further reduced the number of decoding steps, and thus latency. The 20% reduction was achieved without exhausting the available optimizations; further reductions are possible, and this headroom can be reinvested in capacity or richer prompts.
Conclusion
We presented GenPage, an early step toward end-to-end generative Netflix homepage construction: representing user context as a tokenized prompt and generating the entire homepage autoregressively in real time. This collapses the traditional multi-stage recommender stack into a single transformer that can be optimized end-to-end.
In online A/B tests against a mature, highly optimized multi-stage production system, GenPage delivered statistically significant gains on the core user engagement metric we use for launch decisions, while reducing end-to-end serving latency by 20%. Achieving this required adapting the LLM training recipe — pretraining followed by WBC or RL post-training — together with a set of domain-specific techniques: custom tokenization for serving efficiency and product control, context injection and semantic embedding fusion for entity cold start, multi-cadence incremental training for model freshness, constrained decoding for business-rule enforcement, and hybrid row decoding for inference efficiency.
Two offline findings stand out. First, in our current regime, enriching the prompt yields a substantially larger improvement than scaling model capacity — a takeaway we expect to generalize to other industry-scale personalization settings, at least until the available context is fully exploited. Second, RL post-training increases homepage diversity even though diversity is not part of the objective — an indication that page-level optimization captures interactions across rows and entities.
Several pieces of the full vision are still in progress: long context still relies on handcrafted summarization, and broader LLM-style capabilities — language, multimodality, and reasoning — have not yet been incorporated. One promising direction here is a hybrid tokenization combining our domain-specific tokens with generic text tokens, retaining structured control while inheriting the strengths of general-purpose LLMs; conceptually, this introduces an additional recommendation modality into an LLM.
More broadly, we expect many advances from the LLM ecosystem to transfer naturally to this setting, and the boundary between an LLM and a recommender system may increasingly blur. Our results suggest this is a viable path toward simpler recommender systems that align more directly with user satisfaction.
Acknowledgments
Contributors to this work (in alphabetical order): Abhishek Agrawal, Baolin Li, Casey Stella, Daneo Zhang, Dan Zheng, Donnie DeBoer, Fengdi Che, Fernando Amat Gil, Grace Huang, Inbar Naor, Ishita Verma, Jason Uh, Jimmy Patel, Justin Basilico, Lanxi Huang, Lingyi Liu, Liping Peng, Louis Wang, Michelle Kislak, Nathan Kallus, Nicolas Hortiguera, Paran Jain, Qusai Al-Rabadi, Rein Houthooft, Ryan Lee, Santino Ramos, Scarlet Chen, Shaojing Li, Sheallika Singh, Si Cheng, Wei Wang, and ZQ Zhang.
![]()
GenPage: Towards End-to-End Generative Homepage Construction at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.