Post Syndicated from Amir Basirat original https://aws.amazon.com/blogs/big-data/detecting-anomalous-values-by-invoking-the-amazon-athena-machine-learning-inference-function/
Amazon Athena has released a new feature that allows you to easily invoke machine learning (ML) models for inference directly from your SQL queries. Inference is the stage in which a trained model is used to infer and predict the testing samples and comprises a similar forward pass as training to predict the values. Unlike training, it doesn’t include a backward pass to compute the error and update weights. It’s usually the production phase where you deploy your model to predict real-world data. Using ML models in SQL queries makes complex tasks such as anomaly detection, customer cohort analysis, and sales predictions as simple as invoking a function in a SQL query.
In this post, we show you how to use Athena ML to run a federated query that uses Amazon SageMaker inference to detect an anomalous value in your result set.
Solution overview
To use ML with Athena (Preview), you define an ML with Athena function with the USING FUNCTION clause. The function points to the Amazon SageMaker model endpoint that you want to use and specifies the variable names and data types to pass to the model. Subsequent clauses in the query reference the function to pass values to the model. The model runs inference based on the values that the query passes and returns inference results.
You can use more than a dozen built-in ML algorithms provided by Amazon SageMaker, train your own models, or find and subscribe to model packages from AWS Marketplace and deploy on Amazon SageMaker hosting services. No additional setup is required. You can invoke these ML models in your SQL queries from the Athena console, Athena APIs, and through the Athena JDBC driver.
To detect anomalous values, we use the Random Cut Forest (RCF) algorithm, which is an unsupervised algorithm for detecting anomalous data points within a dataset.
Prerequisites
This post continues the work done in this blog. You need to follow steps in that post to run the AWS CloudFormation template before proceeding with this post. No additional setup is required.
As part of the CloudFormation stack that you run to build the environment, we create a new AWS Identity and Access Management (IAM) role that Amazon SageMaker uses to run an Athena query to generate our training dataset, train a new model, and deploy that model to an Amazon SageMaker endpoint. To perform these tasks, our IAM role should have AmazonSageMakerFullAccess, AmazonAthenaFullAccess, and AmazonS3FullAccess managed policies. In a production setting, you should scope down the AmazonS3FullAccess policy to include only the Amazon Simple Storage Service (Amazon S3) buckets that you require for training your model.
Additionally, we create a new Amazon SageMaker notebook instance using an ml.m4.xlarge instance type. We use the ARN of the IAM role for Amazon SageMaker as the IAM role that this notebook uses when interacting with other AWS services.
Uploading and launching the Jupyter notebook
To upload and launch your Jupyter notebook, complete the following steps:
- On the Amazon SageMaker console, choose Notebook Instances.
You can see a workshop notebook instance of size ml.m4.xlarge, which you created when you deployed the CloudFormation stack.
- Select the instance and choose Open Jupyter.
- Download the Jupyter notebook file that we provide as part of this post.
- Upload the file to Jupyter.
- Choose the file and open the Python code so you can go through it step by step.
Running the Python code
You now run the Jupyter notebook Python code on the console, starting from the first cell.

Make sure to update the S3 bucket defined in the second cell of the notebook by replacing the bucket name with your S3 athena-federation-workshop-******** bucket, which you created when deploying the CloudFormation template. This bucket name in your account is globally unique, and we use this bucket to store our training data and model.

In the third cell, we call a federated query against the orders table on the Aurora MySQL database using the lambda:mysql connector that we defined and used in the previous post. This query generates a training dataset for number of orders per day.
![]()
After running the fourth cell and waiting for a few seconds, you should see the training dataset.
![]()
When you build, train, and deploy your ML model on Amazon SageMaker, you normally have a model training phase and a deployment phase. At the end of your deployment, Amazon SageMaker provides you with an endpoint that your client application can interact with to input data and get the inference response back. This endpoint is what we use in our SQL query to call the ML function for inference.
In the fifth cell, we train an RCF model to detect anomalies and we deploy the model to an Amazon SageMaker endpoint that our application or Athena query can call. This part can take up to 10 minutes before the training job is complete, after which you get a generated Amazon SageMaker endpoint. Record this endpoint name; we need this in our Athena federated query.
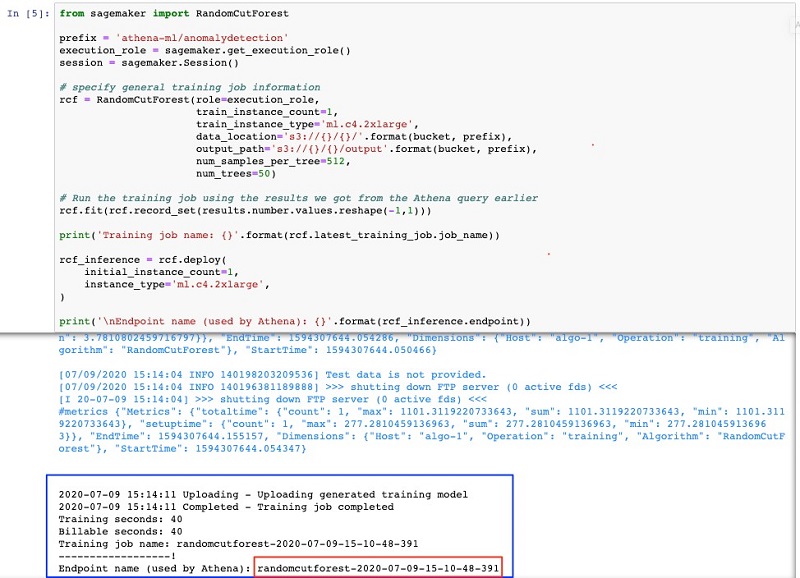
Running an Athena ML query
On the Athena console, check your workgroup and make sure that you’re switched to the AmazonAthenaPreviewFunctionality workgroup. This workgroup enables Athena ML capabilities for your query while this functionality is in preview.
Run the saved query DetectAnamolyInOrdersData after replacing the endpoint name with the one that you generated from your Amazon SageMaker notebook run.
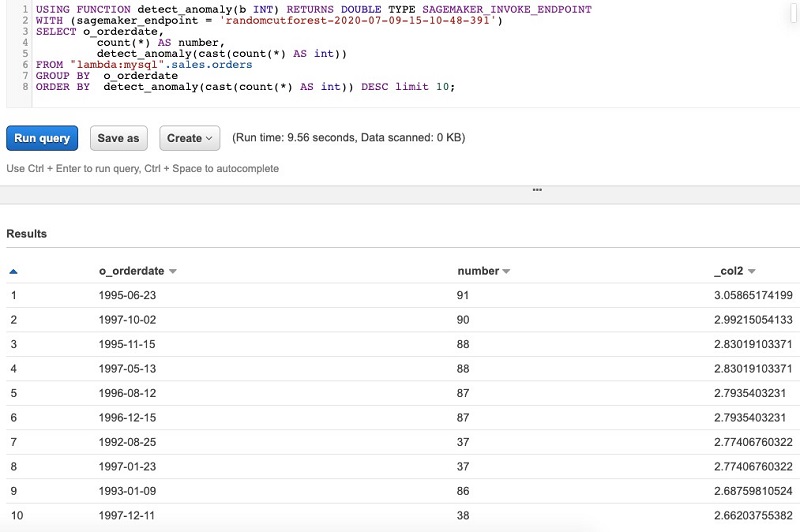
Amazon SageMaker RCF is an unsupervised algorithm for detecting anomalous data points within a dataset. These are observations that are distinguishable from well-structured or patterned data. In the preceding results, the RCF algorithm associates each data point an anomaly score. Low score values indicate that the data point is considered normal. High values indicate the presence of an anomaly in the data. The definitions of low and high depend on the application, but common practice suggests that scores beyond three standard deviations from the mean score are considered anomalous.
Cleaning up
When you finish experimenting with the features as part of this post, remember to clean up all the AWS resources that you created using AWS CloudFormation and during the setup.
- On the Amazon S3 console, empty the S3 bucket the CloudFormation template created. AWS CloudFormation can only delete the bucket if it’s empty.
- On the AWS CloudFormation console, delete all the connectors so they’re no longer attached to the elastic network interface (ENI) of the VPC. Alternatively, you can go to each connector and deselect the VPC so it’s no longer attached to the VPC that AWS CloudFormation created.
- On the Amazon SageMaker console, delete any endpoints you created as part of this post.
- On the Athena console, delete the
AmazonAthenaPreviewFunctionalityworkgroup.
Conclusion
In this post, you learned about Athena support for invoking ML inference model for detecting anomalous values using the RCF algorithm that was developed on Amazon SageMaker. We demonstrated how to deploy your ML model one time on Amazon SageMaker to enable anyone in your organization to run your models any number of times for inference. Additionally, if you run Athena federated queries with this feature, then you can run inference on data in any data source.
About the Authors

Amir Basirat is a Big Data specialist solutions architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue and AWS Lake Formation, where he helps customers craft distributed analytics applications on the AWS platform. Prior to his AWS Cloud journey, he worked as a Big Data specialist for different technology companies. He also has a PhD in computer science, where his research was focused on large-scale distributed computing and neural networks.
 Saurabh Bhutyani is a Senior Big Data specialist solutions architect at Amazon Web Services. He is an early adopter of open source Big Data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Saurabh Bhutyani is a Senior Big Data specialist solutions architect at Amazon Web Services. He is an early adopter of open source Big Data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.