Post Syndicated from Brent Nowak original https://www.backblaze.com/blog/network-stats-for-q4-2025-neocloud-traffic-trends/

Welcome to our second quarterly Network Stats report covering Q4 of 2025. Along with Drive Stats and Performance Stats, Network Stats pulls back the curtain on real-world infrastructure data, particularly how network-level analytics reflect emerging AI industry trends and usage patterns.
Get more Network Stats (and the details of the dataset)
If you are curious about what metrics we’re recording and how we classify data in this series, check out the details outlined in our Q3 2025 Network Stats report.
One of the roles of the Network Engineering (NetEng) team at Backblaze is to monitor how traffic moves into, out of, and across our platform—not just day-to-day, but over time as customer behavior and industry dynamics evolve. Right now, few forces are reshaping networks faster than AI.
With the launch of B2 Overdrive in April 2025, we built a direct, high-performance path between our storage layers and neoclouds where processing, inference, and modeling take place. It has given us a front-row seat to the impact of AI and how network behavior is changing with it. This quarter, in addition to our regular data analysis, I’ll walk through where AI-driven traffic is concentrated, how ingress and egress patterns showed up, and what the findings say about where AI infrastructure might be headed next.
Continue the conversation
Join us live for the Q4 2025 Network Stats webinar Wednesday, February 4, 2025 at 10:00 a.m. PT / 1:00 p.m. ET. We’ll explore where AI traffic concentrates, how high-magnitude data flows behave, and what early indicators suggest about the future of AI-native infrastructure design.
Can’t make it live, or reading this article after-the-fact? Sign up anyway and catch the recording on demand.

Brave new market
AI workflows don’t just need a place to store data, they need to be able to move it quickly, easily, and nearly constantly for short bursts. Large, multi-petabyte datasets are ingested, transformed, exported for training, pulled back for evaluation, and periodically refreshed as models evolve.
Backblaze plays a key role at both ends of that lifecycle. We serve as a durable storage layer for the initial data ingestion, and as the high-throughput source feeding model training, evaluation, and validation to whatever best neocloud is suitable at the moment. Once that model has been trained, it needs to be stored, served, and periodically retrained, where we serve as the storage medium.
This quarter, we saw a large amount of traffic between Backblaze, neoclouds, and traditional hyperscalers for processing concentrated across the months of June to November. This reflects large-scale ingestion events followed by intensive data manipulation and model-related egress.
From a network perspective, this represents a meaningful shift from diffuse, internet-style traffic patterns to large, high-bandwidth flows between a smaller set of endpoints typical of AI-centric infrastructure.
The neocloud slice
The defining theme of the quarter is “new:” new AI-oriented workflows, new traffic patterns, and leading indicators of new infrastructure trends.
The stacked area graph below shows total traffic by network type over time. While content delivery network (CDN), hosting, and internet service provider (ISP) traffic stayed largely within historical norms reflecting steady-state usage patterns like content delivery, web hosting, and traditional backup workflows, two slices stand out:
- Migration traffic: We saw a notable increase in migration traffic from August through October. This classification reflects an influx of data into our network over fiber connections we have in the data centers to cost effectively migrate large amounts of data over private links, not using the public Internet.
- Neocloud traffic: We saw a sharp increase in July through November, peaking in October.

What do we think is happening? Taken together, these patterns suggest a familiar AI lifecycle: large datasets consisting of assets like images, videos, and metadata are ingested and consolidated then exported for training and experimentation. Now, those assets can be periodically updated as new assets are added and generated models and stored. We see that heading into the new year, the overall baseline has increased indicating a new normal.
Quick terminology refresher
- Regions
- US-West: Our largest and longest-running region
- US-East: Region with the most observed proximity to neocloud infrastructure
- CA-East: Our newest region in Canada.
- Network Types
- CDN: Networks that use Backblaze as an origin store for content delivery
- Hosting: Traditional hosting providers that runs workloads like physical or virtual servers for web, database, or application tasks
- Hyperscaler: Large, traditional cloud providers
- ISP Regional: Local or regional ISPs, think of these as the “last mile” paths as these networks are very close to customer equipment and efficient
- ISP Tier1: National or international ISPs that carry our traffic long distances
- Neocloud: AI -focused compute networks
- Migration: Network links that we use for large-scale data onboarding
Heatmaps: Where AI traffic concentrates
To better understand where AI activity is happening, we thought it would be interesting to isolate the different Backblaze regions and to view concentrations of metrics visualized through heatmaps. We’re going to look at the following three dimensions:
- Total traffic volume: Where did we send and receive the most traffic?
- Magnitude: Where were the data transfers with the most bits per unique IP address?
- Uniqueness: What does the number of distinct IP addresses look like?
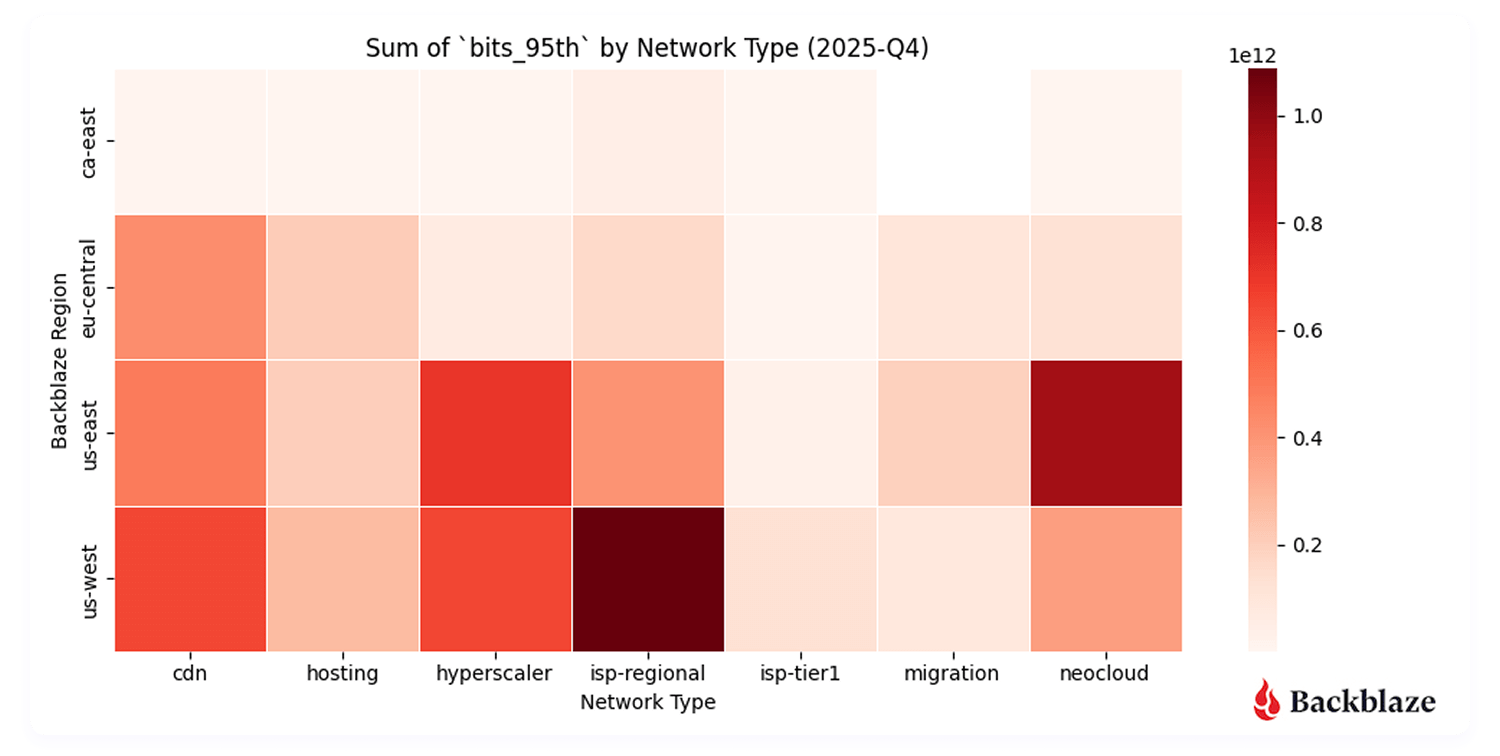
Heatmap #1: Where did we send and receive the most traffic?
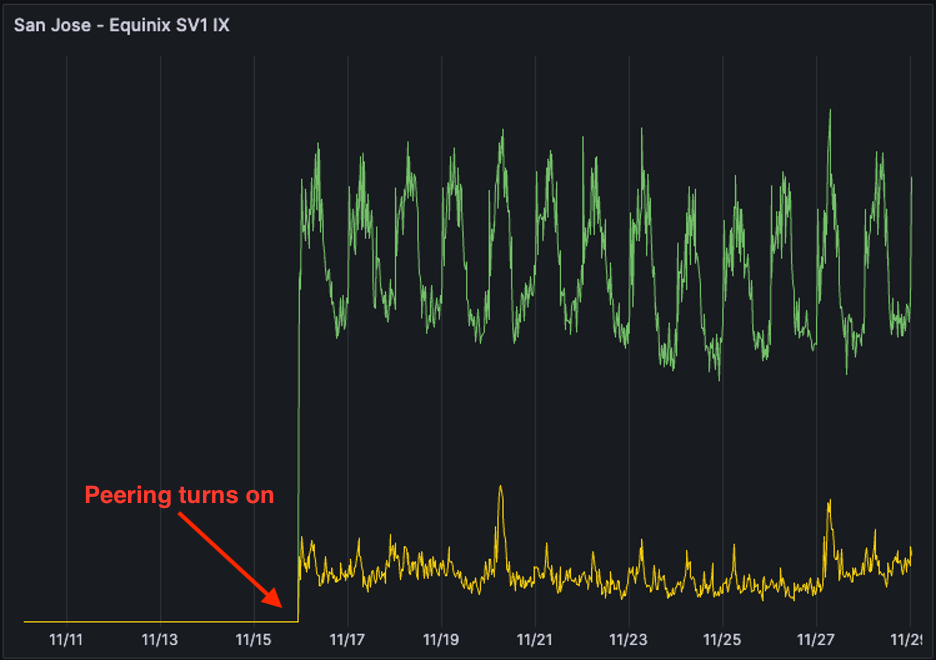
Unsurprisingly, US-West  ISP-Regional traffic dominates in total traffic volume. This region has the largest data center footprint behind it, with connectivity to internet exchanges (IX) such as Equinix-IX that were brought online in 2023. Internet exchanges bring us closer to consumer networks, where we can deliver traffic with lower latency.
ISP-Regional traffic dominates in total traffic volume. This region has the largest data center footprint behind it, with connectivity to internet exchanges (IX) such as Equinix-IX that were brought online in 2023. Internet exchanges bring us closer to consumer networks, where we can deliver traffic with lower latency.
More interesting, however, is the US-East neocloud concentration. Our flow data shows neocloud activity clustering in regions including Chicago, Dallas-Houston, Denver, New York, Northern Virginia (Reston/Ashburn corridor), and Atlanta—skewed more towards the East Coast where there’s dense AI compute availability.
From a performance standpoint, this makes sense. It’s important to keep latency (the time between the source and destination) lower to achieve consistent high bandwidth rates for AI data transfers. For now, that gravity is pulling activity towards the East coast.
Will neocloud traffic concentrations shift over time? Since this is our first quarter with a full dataset, it’s a bit early to draw long-term conclusions. But this is exactly the kind of trend we’ll be tracking. Stay tuned for future Network Stats reports.
Heatmap #2: Where were the data transfers with the most magnitude (bits per IP address)?
Another metric we record is bits per IP or what we termed in our last report “magnitude.” This combination of the amount of traffic transferred with how many actors are involved per network is a good proxy to measure how heavy or impactful individual data flows are. In short:
- High volume, many IPs: Easier to distribute and load-balance across infrastructure. And many source and destination pairs means that we can traffic engineer at the WAN layer, sending some traffic over one provider and some over another.
- High volume, few IPs: More difficult, but more interesting, from a NetEng perspective.
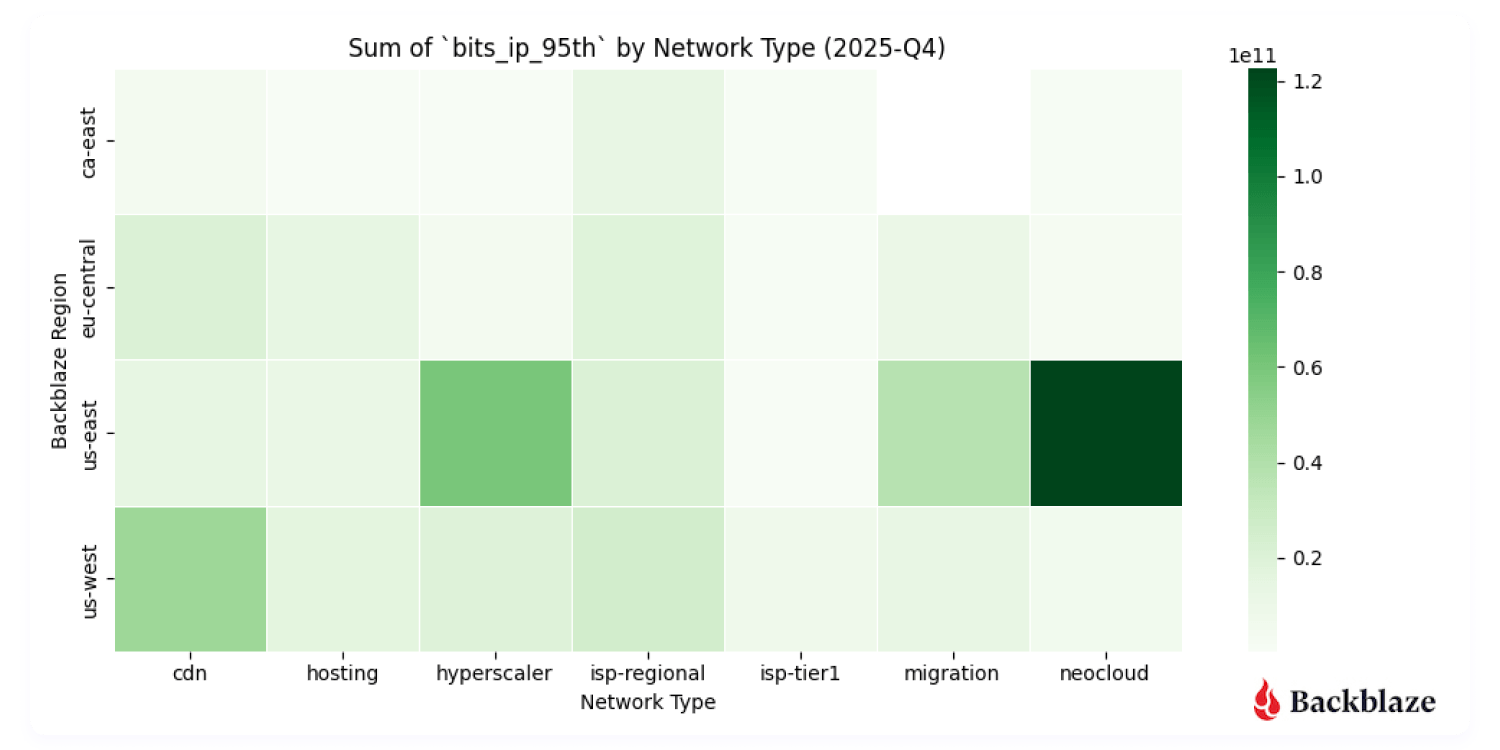
With B2 Overdrive, we routinely support client transfers starting at 100Gbps up to 1Tbps of throughput.These high-magnitude flows show up clearly in the data, especially in regions serving AI-heavy neocloud endpoints. Seeing these patterns emerge in the data validates that customers are actively using the platform the way it was designed.
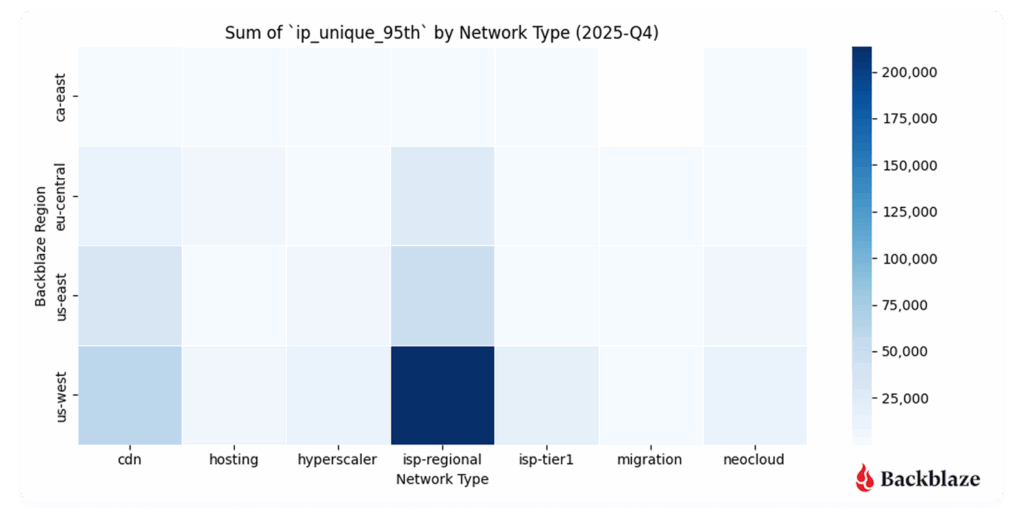
Heatmap #3: How many unique addresses do we interact with?
Uniqueness—measured by the number of distinct IP addresses per network type—adds another dimension to the story.
- US-West shows the highest overall uniqueness, driven by its larger number of data centers and mix of workloads.
- Neocloud traffic, by contrast, tends to involve fewer, more persistent endpoints, consistent with AI pipelines that rely on stable, long-standing connections between storage and compute.
This contrast reveals a broader trend: AI networking is less about many-to-many communication and more about sustained high-throughput relationships between specialized systems.
Summary: Early indicators of an AI-native network era
This quarter represents an early but important snapshot of how AI is reshaping network behavior:
- AI-driven traffic is concentrated and heavy (not groundbreaking news by any means, but interesting to see it played out on a network).
- Neocloud connectivity is a defining feature of data movement today.
- Data gravity is pulling storage, compute, and network design into tighter alignment.
This is our first look at these patterns specifically. As we gather more quarters of data, we’ll be watching closely to see how cyclical neocloud activity becomes, how regional concentrations shift, and how the growing ecosystem of AI-focused ISVs continues to change the shape of the network.
Quarter over quarter data
Last quarter we started capturing data and metrics that we were interested in tracking over time. This represents our first full quarter of data as we only started tracking in August of 2025, so it’s still early to start to see trends, but we’re including the visualizations for fidelity.
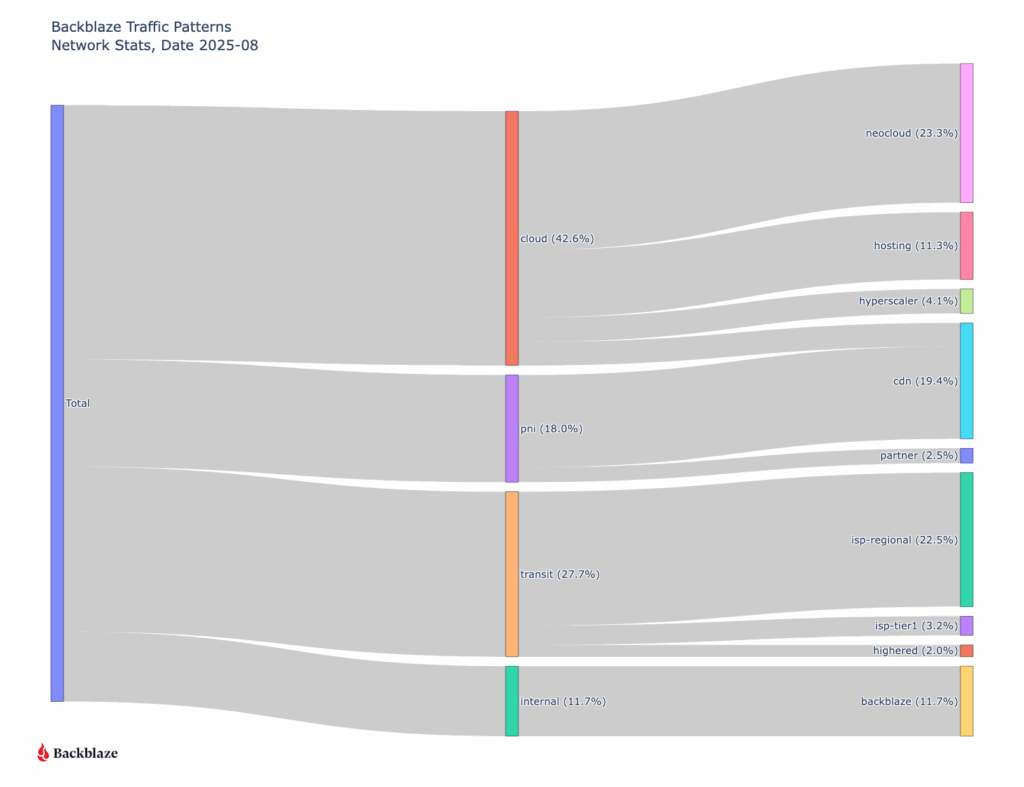
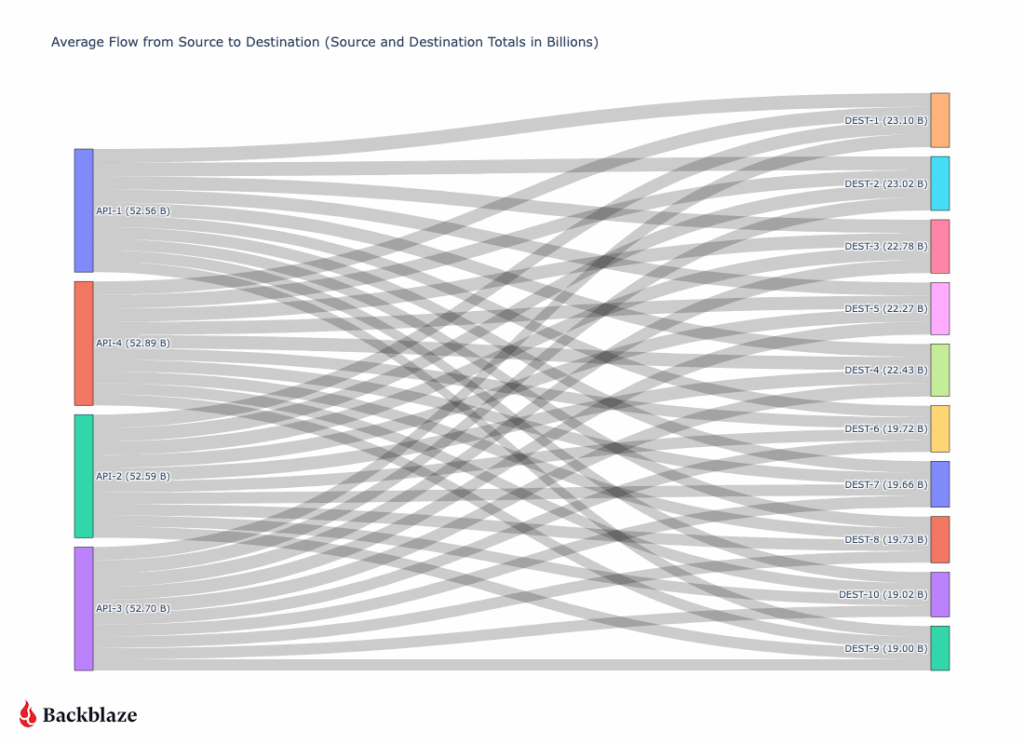
First let’s take a look at where all our traffic goes from a global perspective with an updated view of last quarter.
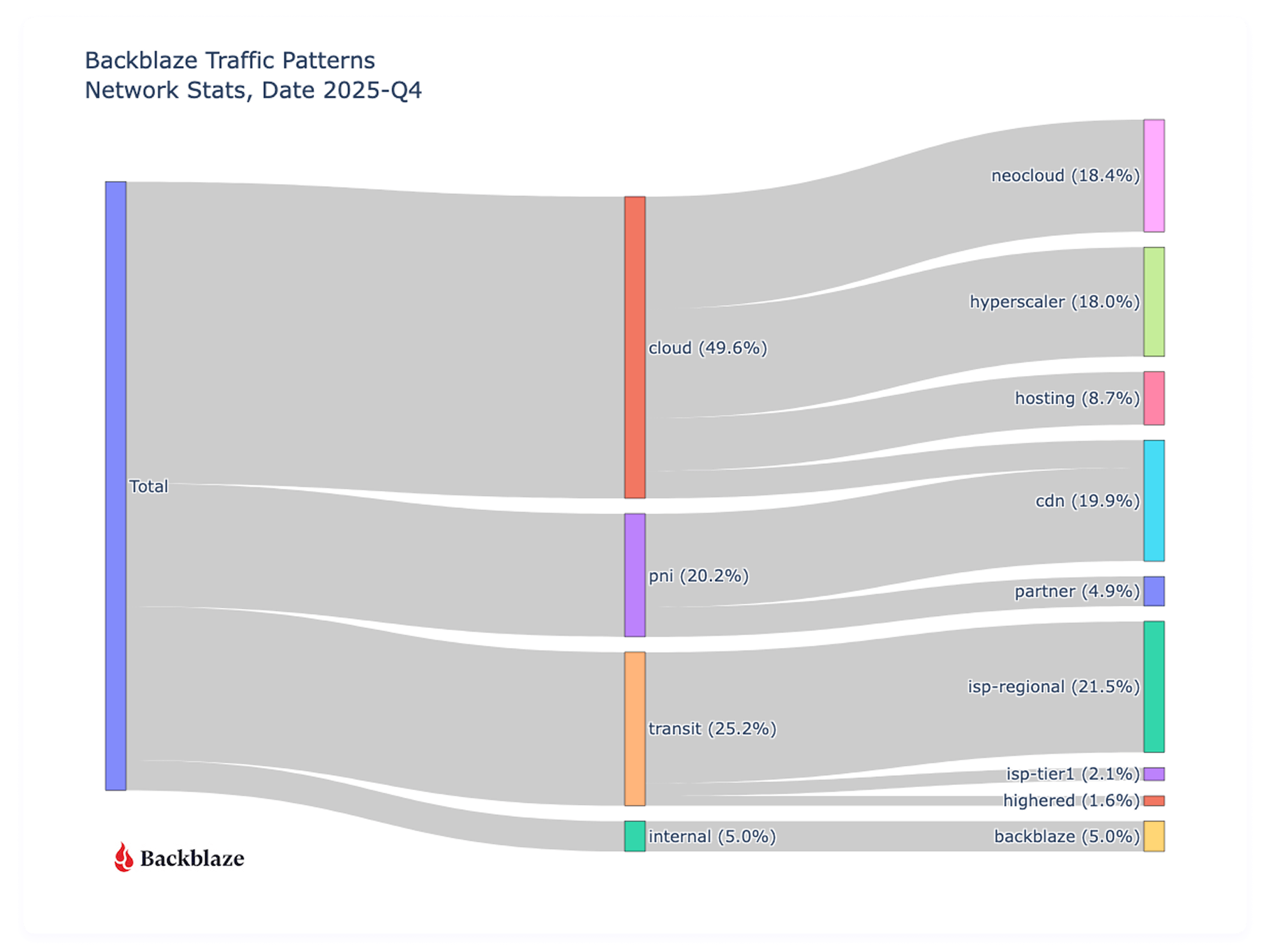
Traffic to other clouds has increased (36.2% to 49.6%) since we last reported in August of 2025, with a slight decrease (19.8% to 18.4%) in Neocloud destinations, but a large increase (3.5% to 18%) to hyperscalers. It’s too early to call these things statistically significant trends or patterns that impact the cloud storage industry broadly, because they’re reflective of what types of customers Backblaze specifically has and our sampling range is only a quarter. That said, we do see an overall increase in cloud to cloud traffic, but the higher percentage to the type of clouds rotated from last quarter.
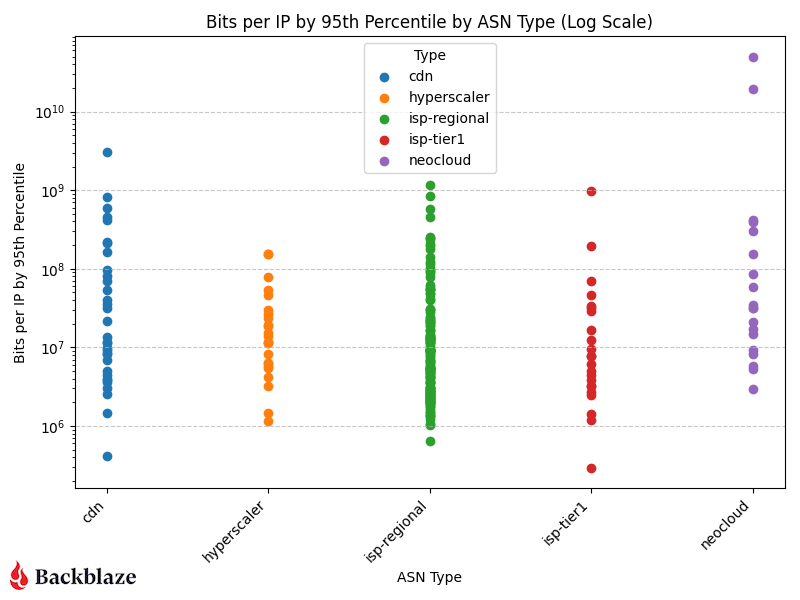
Next, let’s look at the magnitude of our network traffic based on the category of the traffic destination. As a reminder, magnitude represents the amount of traffic transferred with how many actors are involved per network.
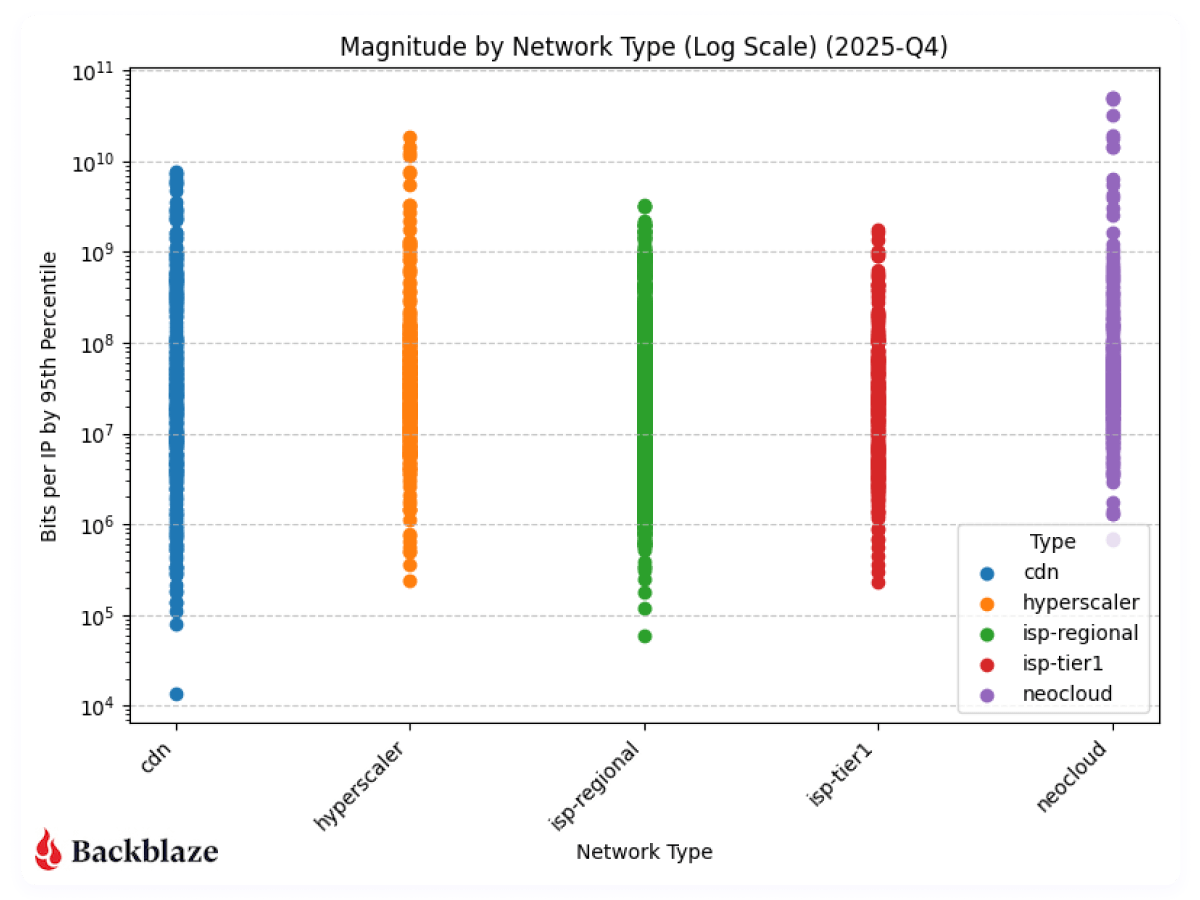
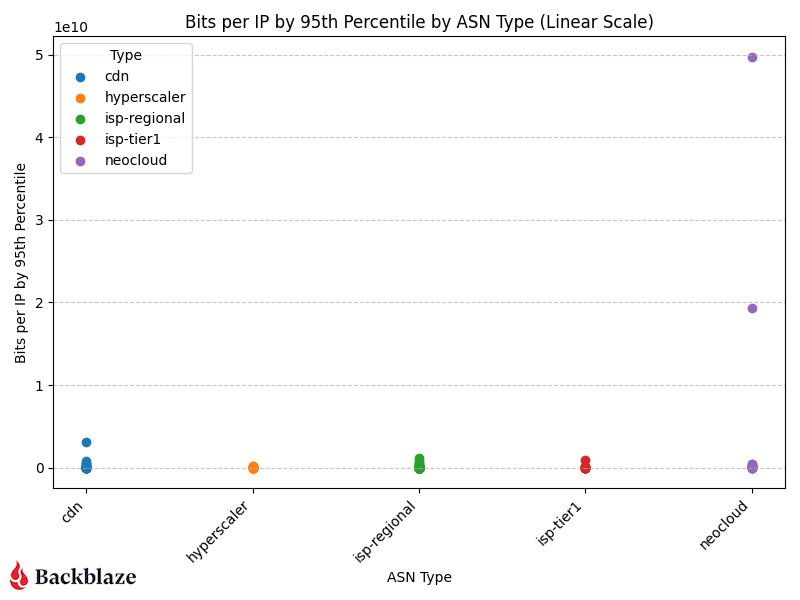
Next, to be consistent with our previous report, we’ll look at magnitude on a linear scale.
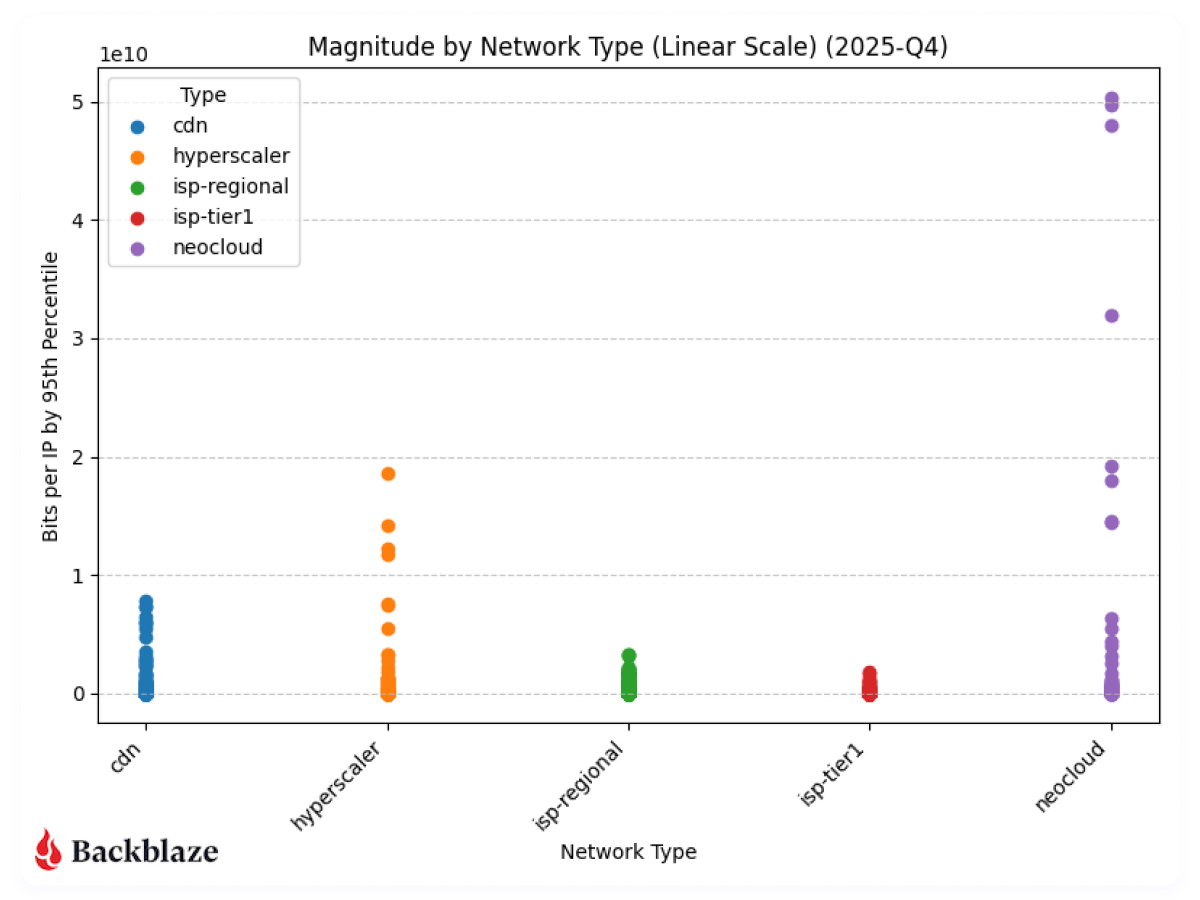
With more datapoints, we can clearly see the magnitude of the neocloud and hyperscaler transfers when compared to other network types. As above, it’s a bit early to claim concrete quarter over quarter patterns, but we’ll keep monitoring and updating the dataset.
What’s next?
Next quarter will be the first where we have true quarter over quarter data to analyze, and we’ll be back with more on how AI-driven flows change quarter over quarter. And as we get more data, we’re interested in looking at other trends like IPv4 vs. IPv6 traffic, cross-cloud connectivity trends, and revisiting the concentration analysis we did this quarter.
Anything specific you want to see? Let us know in the comments or reach out to our Evangelism team. Or, keep up-to-date with the latest technical content with our Developer Newsletter.
The post Network Stats for Q4 2025: Neocloud Traffic Trends appeared first on Backblaze Blog | Cloud Storage & Cloud Backup