Post Syndicated from Cloudflare original https://blog.cloudflare.com/introducing-rollbacks-for-workers-deployments/
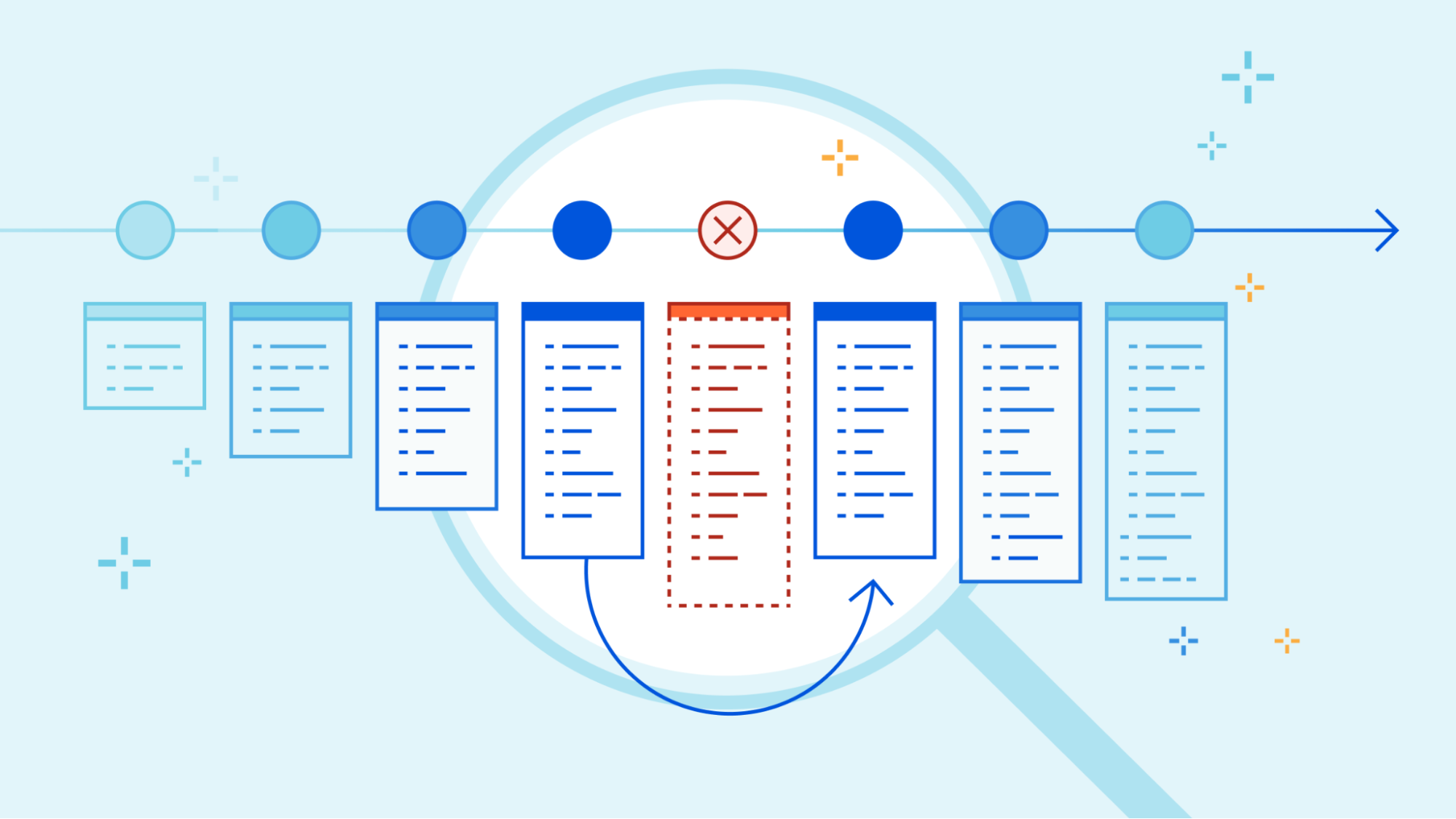
In November, 2022, we introduced deployments for Workers. Deployments are created as you make changes to a Worker. Each one is unique. These let you track changes to your Workers over time, seeing who made the changes, and where they came from.
When we made the announcement, we also said our intention was to build more functionality on top of deployments.
Today, we’re proud to release rollbacks for deployments.
Rollbacks
As nice as it would be to know that every deployment is perfect, it’s not always possible – for various reasons. Rollbacks provide a quick way to deploy past versions of a Worker – providing another layer of confidence when developing and deploying with Workers.
Via the dashboard
In the dashboard, you can navigate to the Deployments tab. For each deployment that’s not the most recent, you should see a new icon on the far right of the deployment. Hovering over that icon will display the option to rollback to the specified deployment.
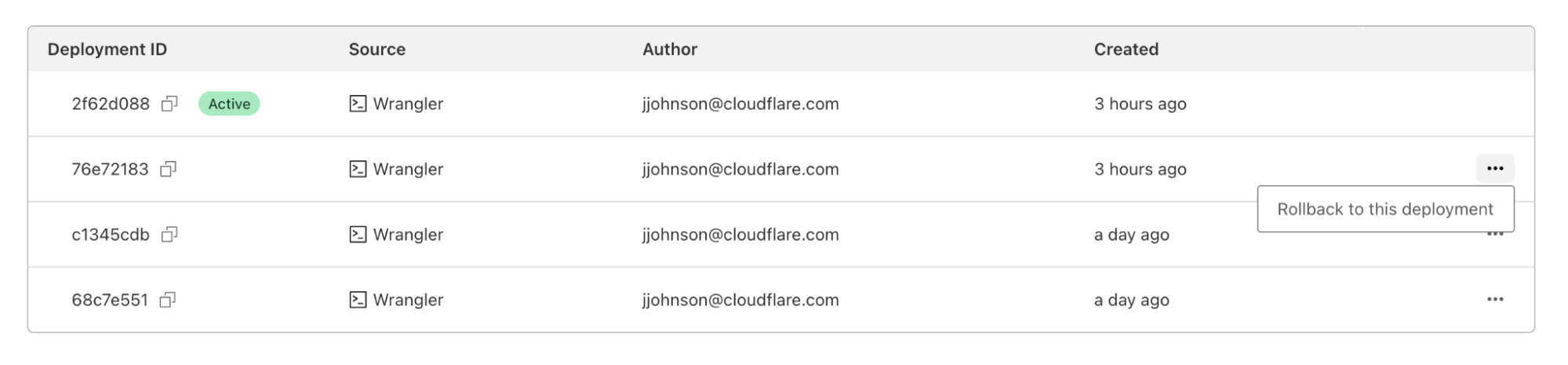
Clicking on that will bring up a confirmation dialog, where you can enter a reason for rollback. This provides another mechanism of record-keeping and helps give more context for why the rollback was necessary.
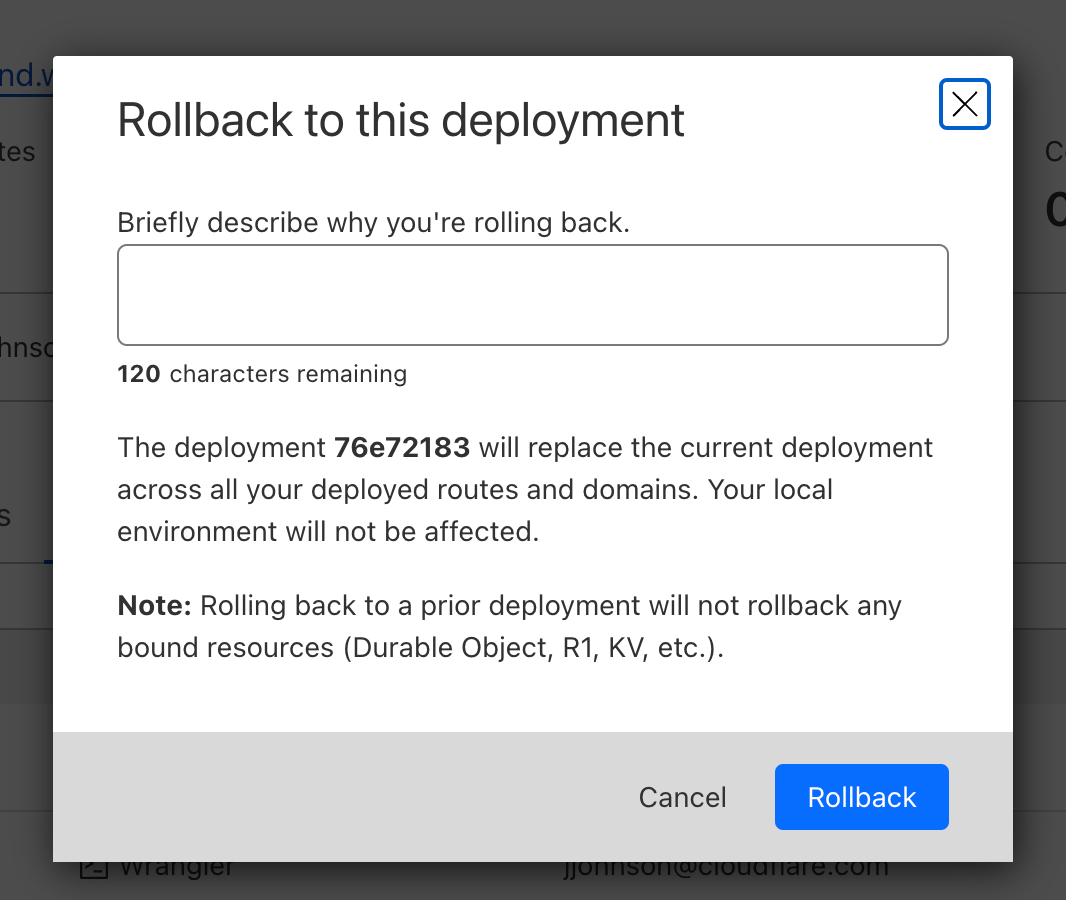
Once you enter a reason and confirm, a new rollback deployment will be created. This deployment has its own ID, but is a duplicate of the one you rolled back to. A message appears with the new deployment ID, as well as an icon showing the rollback message you entered above.
Via Wrangler
With Wrangler version 2.13, rolling back deployments via Wrangler can be done via a new command – wrangler rollback. This command takes an optional ID to rollback to a specific deployment, but can also be run without an ID to rollback to the previous deployment. This provides an even faster way to rollback in a situation where you know that the previous deployment is the one that you want.

Just like the dashboard, when you initiate a rollback you will be prompted to add a rollback reason and to confirm the action.
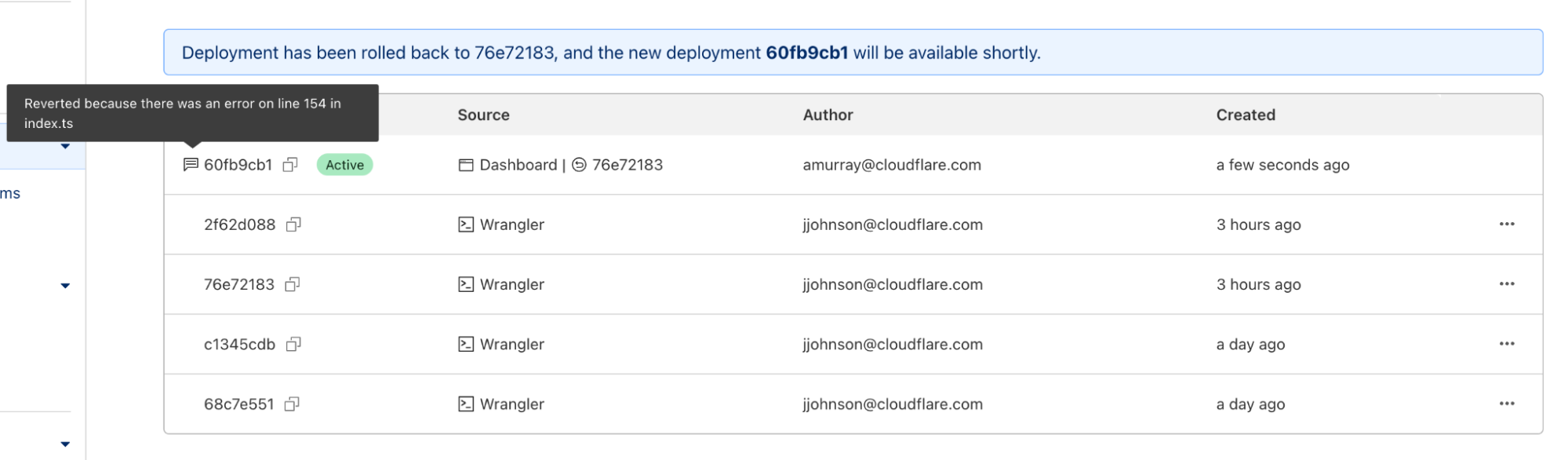
In addition to wrangler rollback we’ve done some refactoring to the wrangler deployments command. Now you can run wrangler deployments list to view up to the last 10 deployments.
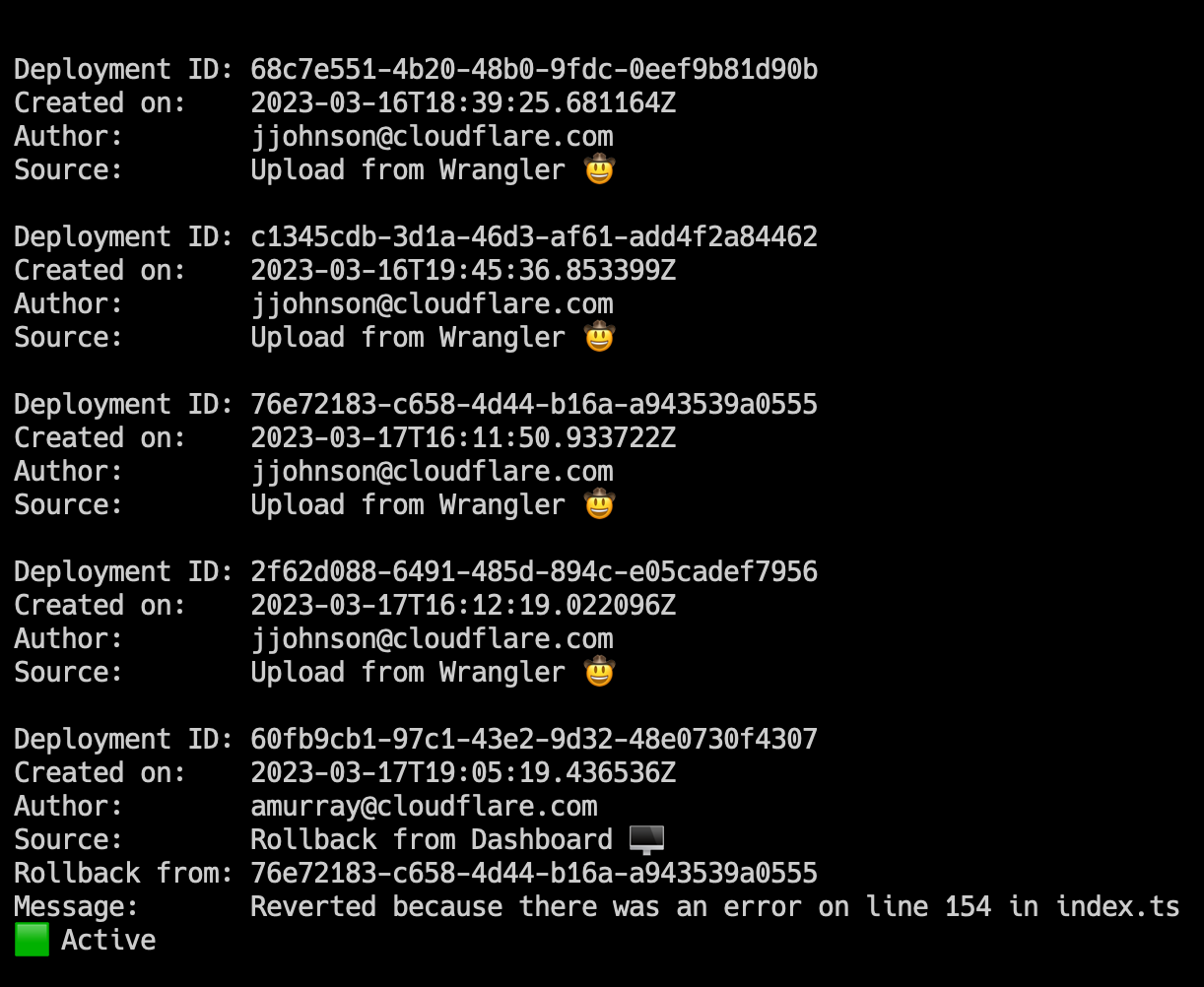
Here, you can see two new annotations: rollback from and message. These match the dashboard experience, and provide more visibility into your deployment history.
To view an individual deployment, you can run wrangler deployments view. This will display the last deployment made, which is the active deployment. If you would like to see a specific deployment, you can run wrangler deployments view [ID].
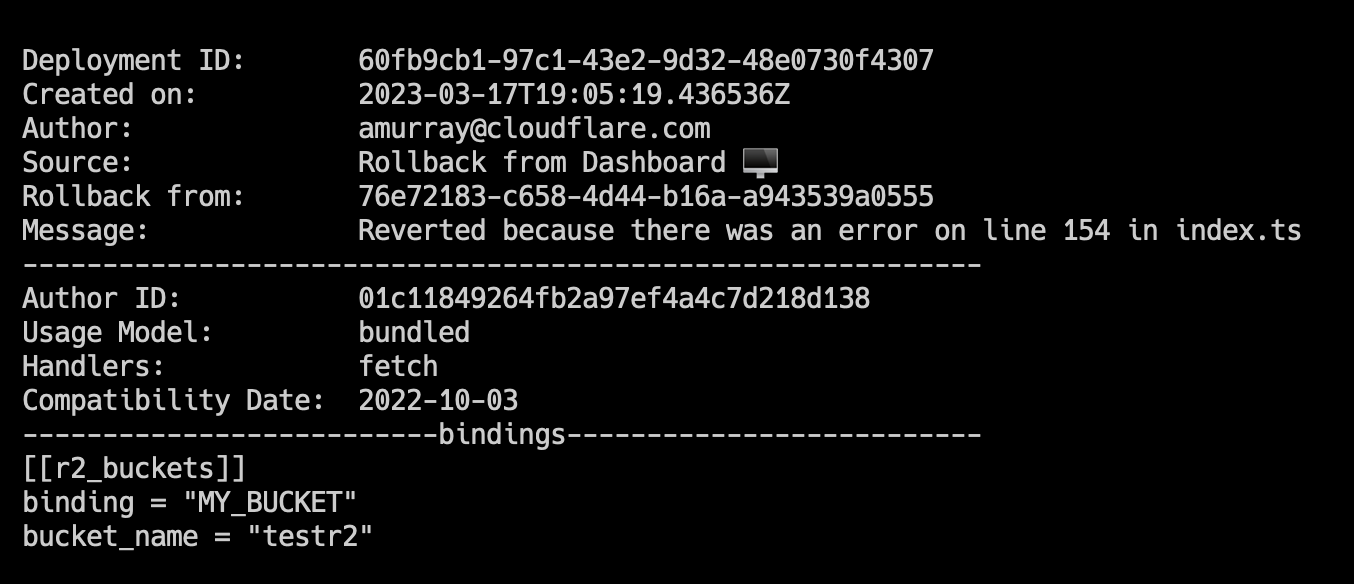
We’ve updated this command to display more data like: compatibility date, usage model, and bindings. This additional data will help you to quickly visualize changes to Worker or to see more about a specific Worker deployment without having to open your editor and go through source code.
Keep deploying!
We hope this feature provides even more confidence in deploying Workers, and encourages you to try it out! If you leverage the Cloudflare dashboard to manage deployments, you should have access immediately. Wrangler users will need to update to version 2.13 to see the new functionality.
Make sure to check out our updated deployments docs for more information, as well as information on limitations to rollbacks. If you have any feedback, please let us know via this form.





