Post Syndicated from Himanshu Sahni original https://aws.amazon.com/blogs/big-data/automate-email-notifications-for-governance-teams-working-with-amazon-sagemaker-catalog/
Amazon SageMaker Catalog simplifies the discovery, governance, and collaboration for data and AI across Data Lakehouse, AI models, and applications. With Amazon SageMaker Catalog, you can securely discover and access approved data and models using semantic search with generative AI–created metadata or could just ask Amazon Q Developer with natural language to find their data.
Large enterprise customers have multiple lines of businesses who produce and consume data using a central SageMaker Data Catalog. Many customers have a central data governance team that is responsible for creating, publishing, and maintaining data governance standards and best practices across the firm. As the customer’s data platform scales, it becomes challenging for the central governance team to maintain the standards across all data producers and consumers. Because of this, many governance teams need to monitor user activity in Amazon SageMaker Catalog to ensure data assets are published according to established organizational governance standards and best practices. In this scenario, there is a need for automation where the central governance teams can be notified when critical events happen in Amazon SageMaker Catalog.
In this post, we show you how to create custom notifications for events occurring in SageMaker Catalog using Amazon EventBridge, AWS Lambda, and Amazon Simple Notification Service (Amazon SNS). You can expand this solution to automatically integrate SageMaker Catalog with in-house enterprise workflow tools like ServiceNow and Helix.
Solution overview
The following solution architecture shows how SageMaker Catalog integrates with other AWS services like AWS IAM Identity Center, Amazon EventBridge, Amazon SQS, AWS Lambda, and Amazon SNS to generate automated notifications to capture critical events in the enterprise catalog.
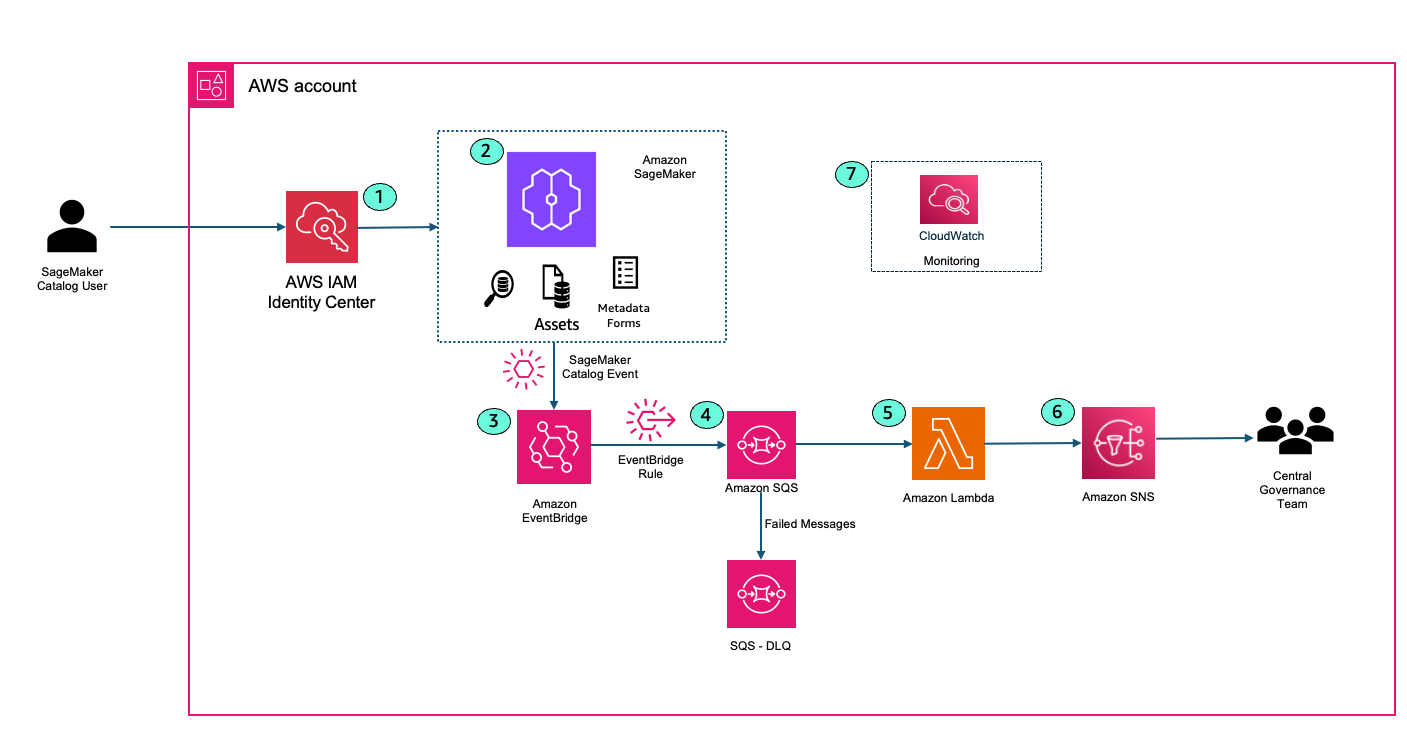
- A SageMaker Catalog user logs into Amazon SageMaker Unified Studio using IAM Identity center. This could be a data scientist, machine learning engineer, or analyst looking for published data sets in the firm. AWS IAM Identity center ensures that only authorized personnel can access the cataloged assets and ML resources.
- User performs an activity within SageMaker Catalog. Example user creates a new project or user searches for a data asset and creates a subscription request to access the asset.
- User events from SageMaker Catalog are captured in Amazon EventBridge. Amazon EventBridge is a fully managed, serverless event bus service designed to help you build scalable, event-driven applications across AWS, SaaS, and custom applications. Amazon EventBridge provides the ability to filter events and allow users to take action on specific events.The following example event pattern in EventBridge filters DataZone create project events.
- Amazon EventBridge sends the filtered events to Amazon SQS. Routing events to an SQS queue improves reliability and durability. Amazon SQS acts as a buffer between Amazon EventBridge and AWS Lambda, decoupling event producers from consumers. This allows your Lambda functions to process messages at their own pace, preventing overload during traffic spikes or when downstream resources are temporarily slow or unavailable. Amazon SQS provides durable, persistent storage for events. If Lambda service is unavailable or throttled, messages remain in the queue until they can be successfully processed, reducing the risk of data loss. There is a Dead Letter Queue (DLQ) attached to the main SQS queue. Attaching a DLQ to SQS ensures that any messages that can’t be processed after multiple attempts are safely captured for inspection and troubleshooting, preventing them from blocking or endlessly circulating in the main queue.
- AWS Lambda function reads the messages from SQS queue. Lambda function formats the notification based on your needs.
- AWS Lambda publishes the message to Amazon SNS. End users and Central Governance team can subscribe to the SNS topic to receive email alerts when an event happens in SageMaker catalog.
- Amazon CloudWatch integrates with AWS Lambda to monitor performance, logs events, and can trigger alarms if anything goes awry, ensuring your workflows run smoothly.
Prerequisites
You need to setup the following prerequisite resources:
- An AWS account with a configured Amazon Amazon Virtual Private Cloud (Amazon VPC) and base network.
- An existing SageMaker Unified Studio domain (follow instructions on Setting up Amazon SageMaker Unified Studio).
- Grant Lambda Access in SageMaker Unified Studio (required for Publishing the assets)
- Add the Lambda execution role as an IAM role in SageMaker Unified Studio.
- Assign the Lambda execution role to your project within the SageMaker Unified Studio portal.
This configuration ensures that Lambda function has the required authorization to access Data Zone resources and successfully publish assets from your SageMaker Unified Studio projects.
Code Deployment
Review the instructions on our GitHub repository to deploy the framework in your AWS account using AWS CDK. The CDK provisions an event-driven notification architecture for Amazon SageMaker Unified Studio, focusing on project creation and asset publishing events.
Core AWS Resources Deployed – The following are the core AWS resourced deployed:
- EventBridge Rules
- DataZoneCreateProjectRule: Captures DataZone project creation events (
CreateProject). - DataZonePublishAssetRule: Captures DataZone asset publishing events (
CreateListingChangeSetwithPUBLISHaction forASSETentity type).
- DataZoneCreateProjectRule: Captures DataZone project creation events (
- SQS Queue
- DataZoneEventQueue: Buffers DataZone events from EventBridge before processing.
- Queue Policy: Allows EventBridge to send messages to the SQS queue.
- Lambda Function
- ProjectNotificationLambda: Processes messages from the SQS queue, retrieves event details from DataZone, and sends notifications to an SNS topic.
- IAM Role: Grants permissions to access SQS, SNS, CloudWatch Logs, and DataZone services.
- Event Source Mapping: Triggers the Lambda function for each SQS message.
- ProjectNotificationLambda: Processes messages from the SQS queue, retrieves event details from DataZone, and sends notifications to an SNS topic.
- SNS Topic
- LambdaSNSTopic: Receives notifications from the Lambda function.
- Email Subscriptions: Two email endpoints are subscribed to receive notifications.
- Add your email ID to the SNS topic. You’ll receive an email to request for subscription, click on ‘Confirm Subscription’
- LambdaSNSTopic: Receives notifications from the Lambda function.
- Permissions
- Amazon EventBridge sends events to SQS (requiring SQS permissions), Lambda poll reads messages from Amazon SQS (requiring Lambda role in SQS permissions), and Lambda publishes to Amazon SNS (requiring SNS permissions).
- IAM Policies: Lambda execution role has necessary permissions for SQS, SNS, logging, and Data Zone operations.
Outputs Provided (CloudFormation Output)
- Amazon SNS Topic ARN: For notification publishing.
- Amazon SQS Queue ARN: For event buffering.
- AWS Lambda Function ARN: For event processing.
- Amazon EventBridge Rule ARNs: For both asset publishing and project creation events.
Project Creation Notification
Execute the following steps to login to SageMaker Unified Studio and create a project.
- Login to SageMaker Unified Studio Console. This takes you to Amazon SageMaker Unified Studio domain login screen (SSO and IAM sign-in options).

- Choose Create Project on SageMaker Unified Studio login page.

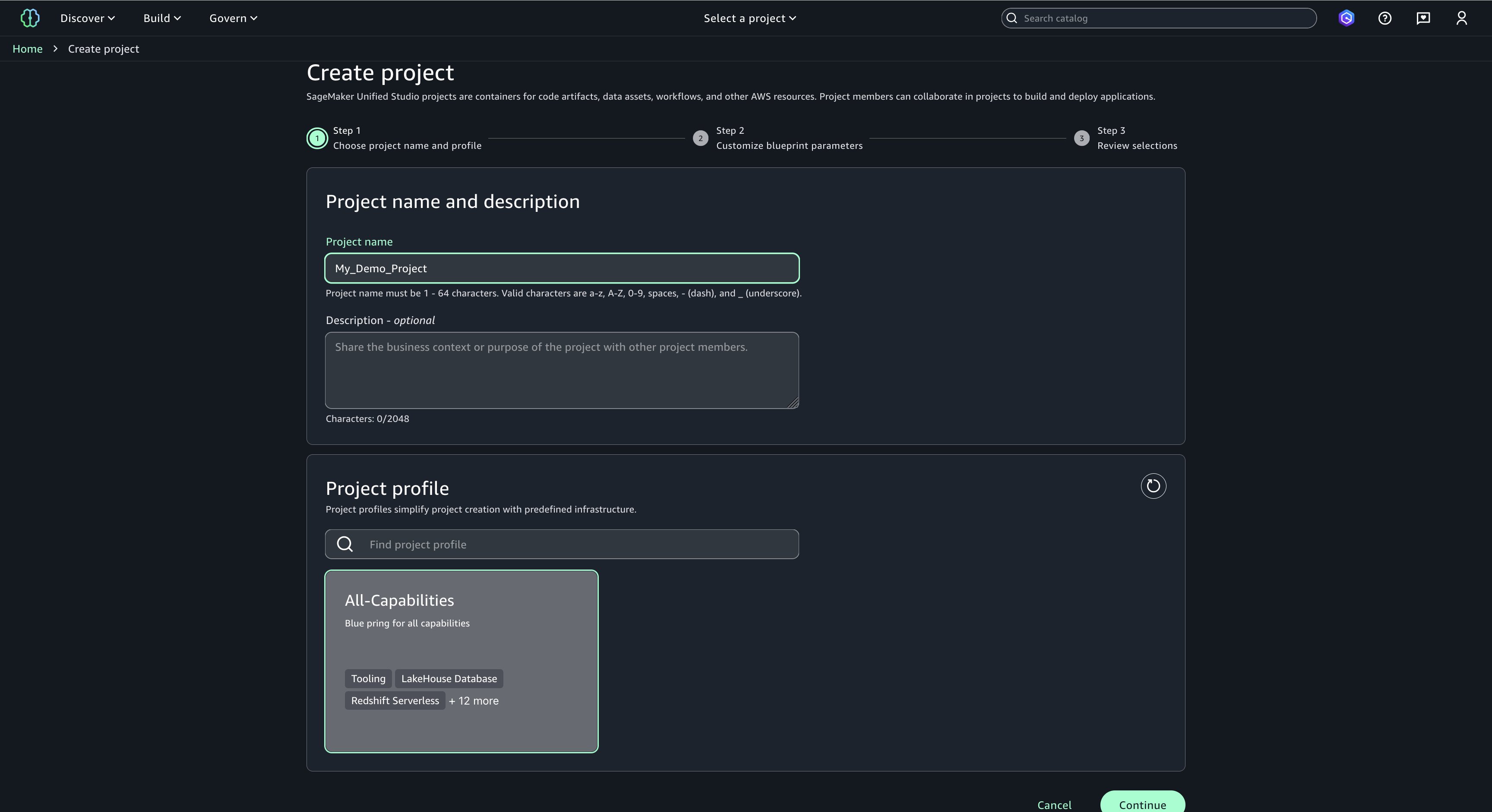
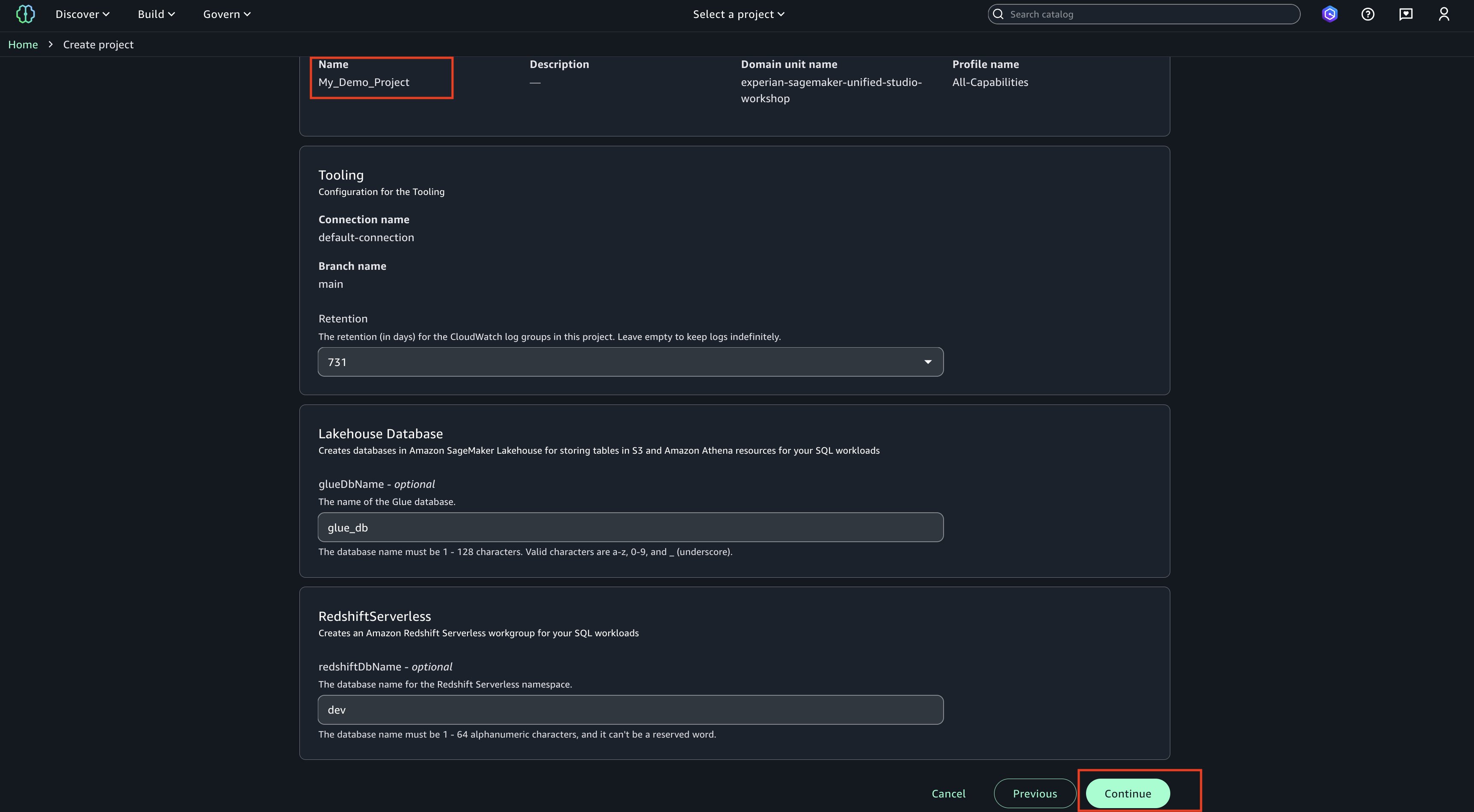
- Choose a project name of your choice, such as ‘My_Demo_Project’. In Project profile, select ‘All-Capabilities’.

- Choose Continue. Keep everything as default.

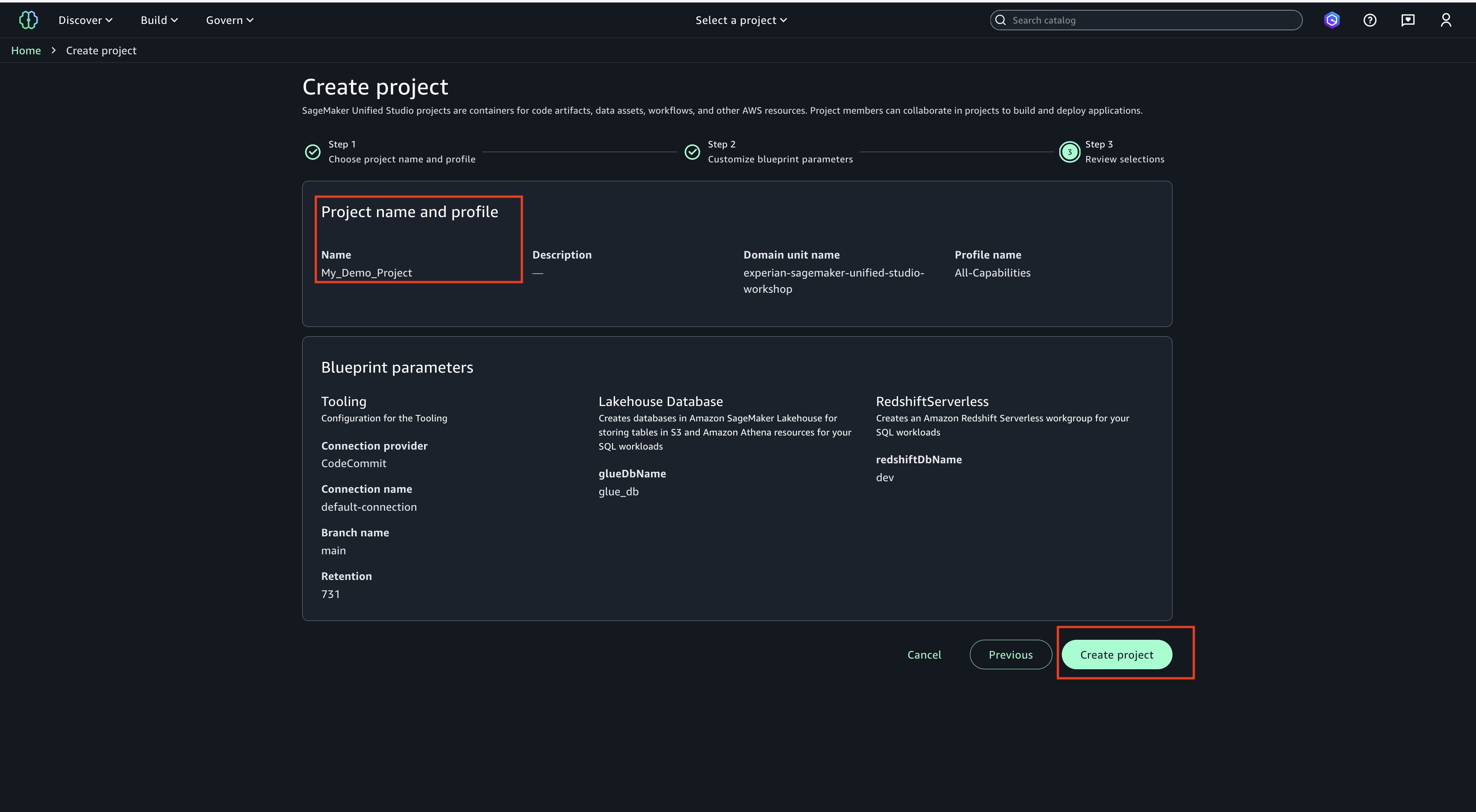
- Choose Continue. On next page, create on ‘Create project’.

- Project creation final screen

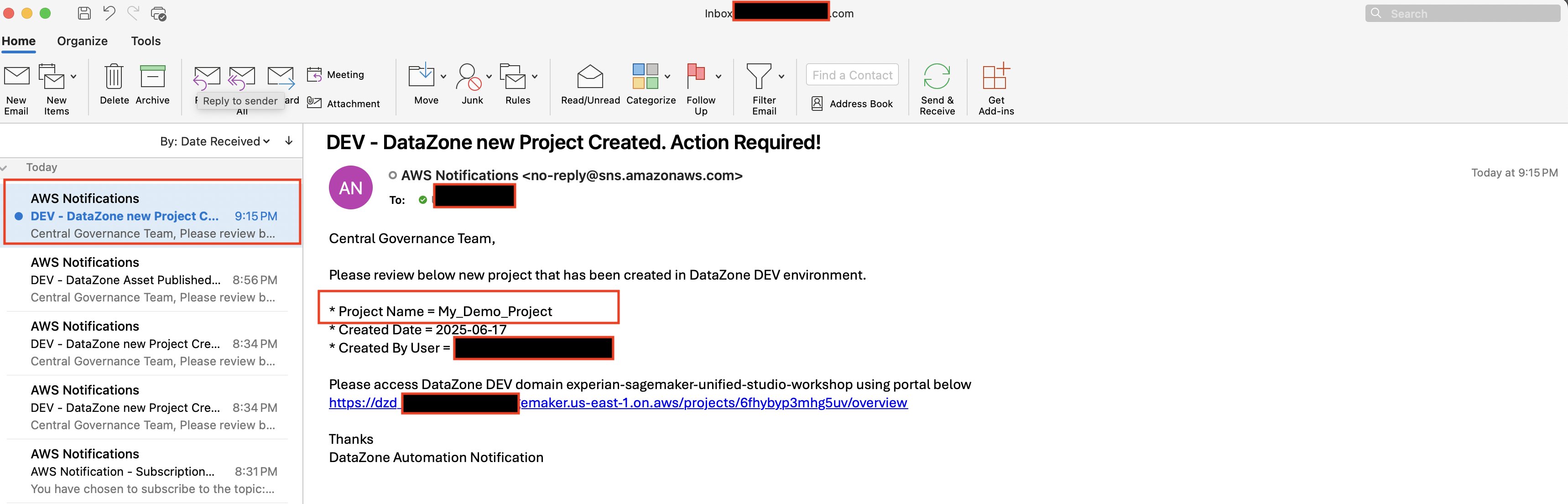
- Email Notification. Once project creation is successful, you should see an email notification sent by the above deployed automation.

Asset Publish Notification
To publish a sample asset in SageMaker Unified Studio.
- Lambda Permissions
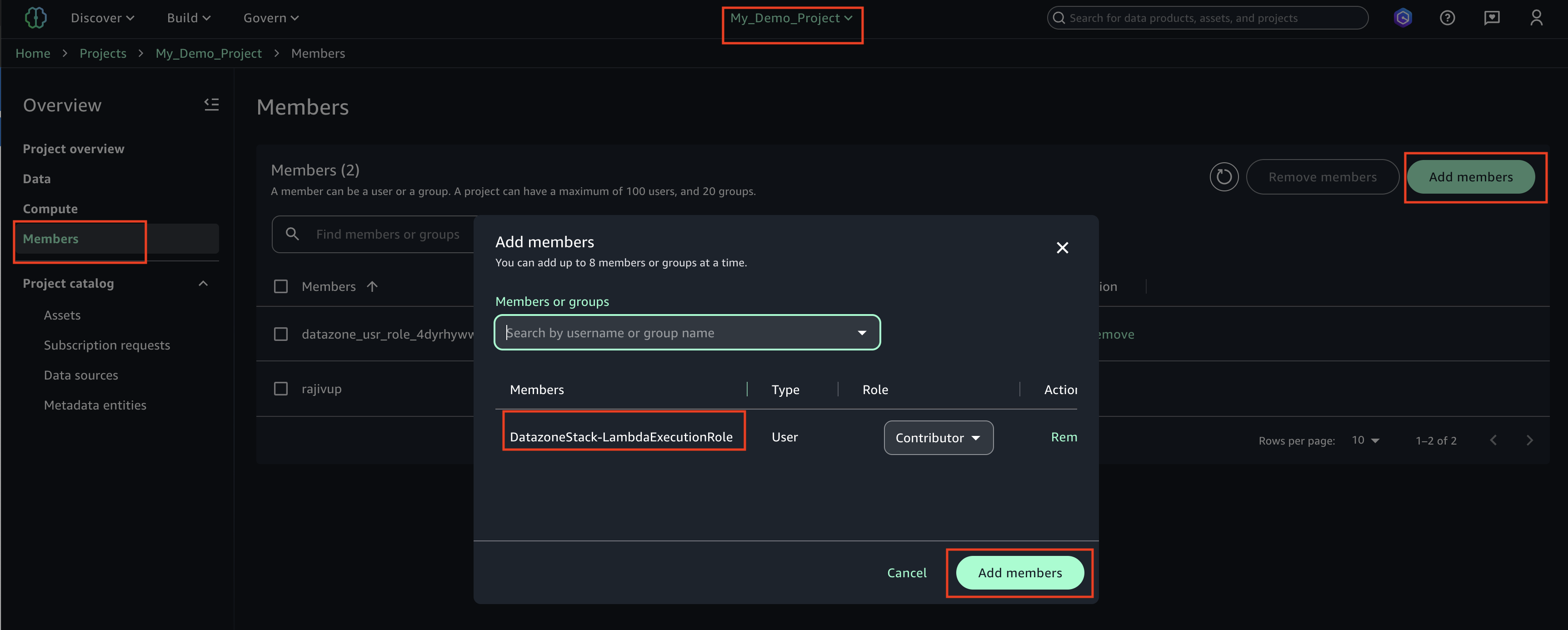
After the CDK Stack creates the Lambda execution role ‘DatazoneStack-LambdaExecutionRole’, use the following procedure to integrate this role into your SageMaker Studio project. This integration enables Lambda functions to interact with DataZone API in SageMaker Unified Studio project.- Login to SageMaker Unified studio using SSO, click on Members, Add members.
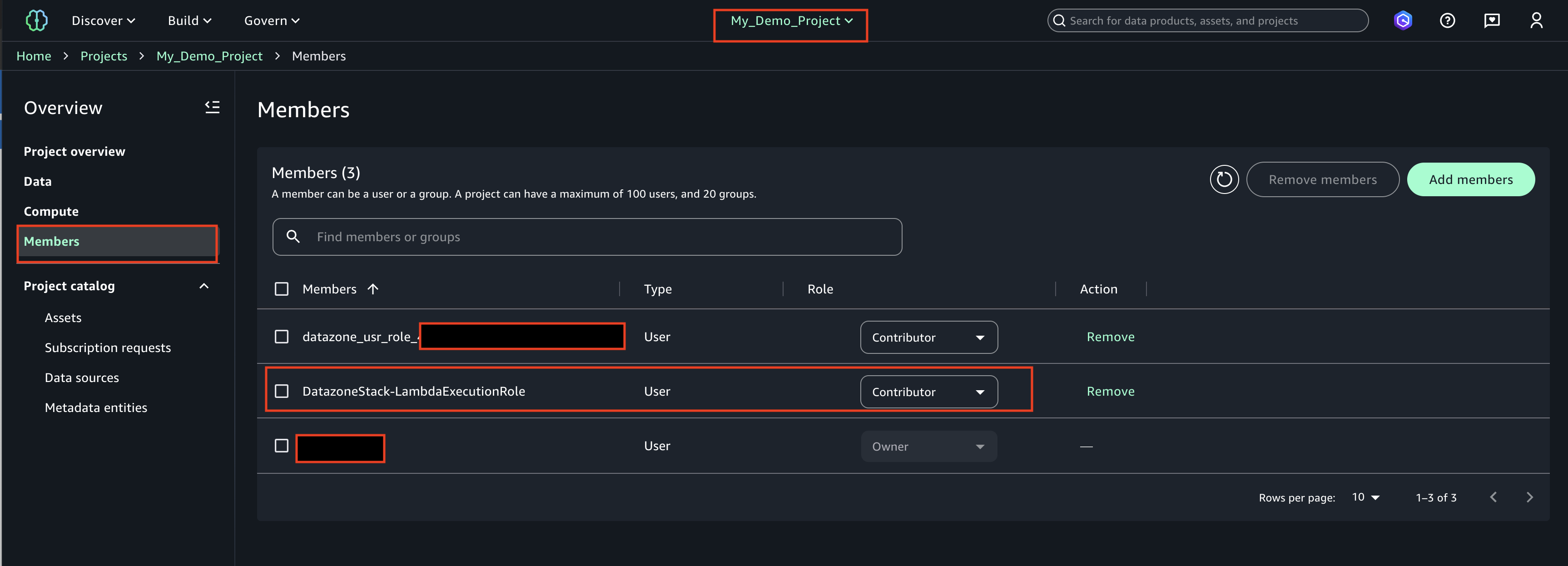
- Find the role ‘DatazoneStack-LambdaExecutionRole’ and add as a ‘Contributor’


The LambdaExecutionRole (<cf-stack-name>-LambdaExecutionRole) has been added as a member to a project in SageMaker Unified Studio.
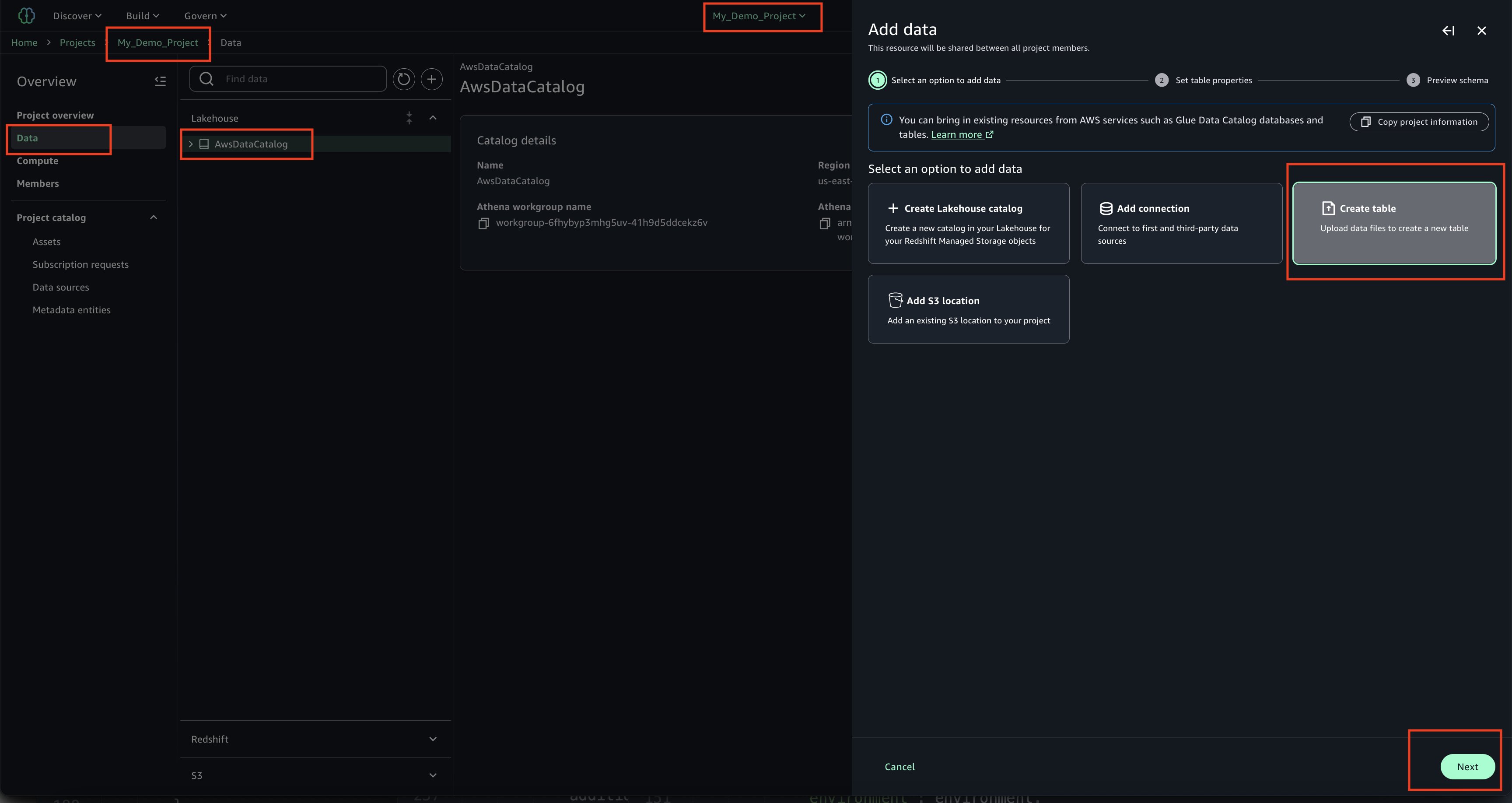
- Create Asset
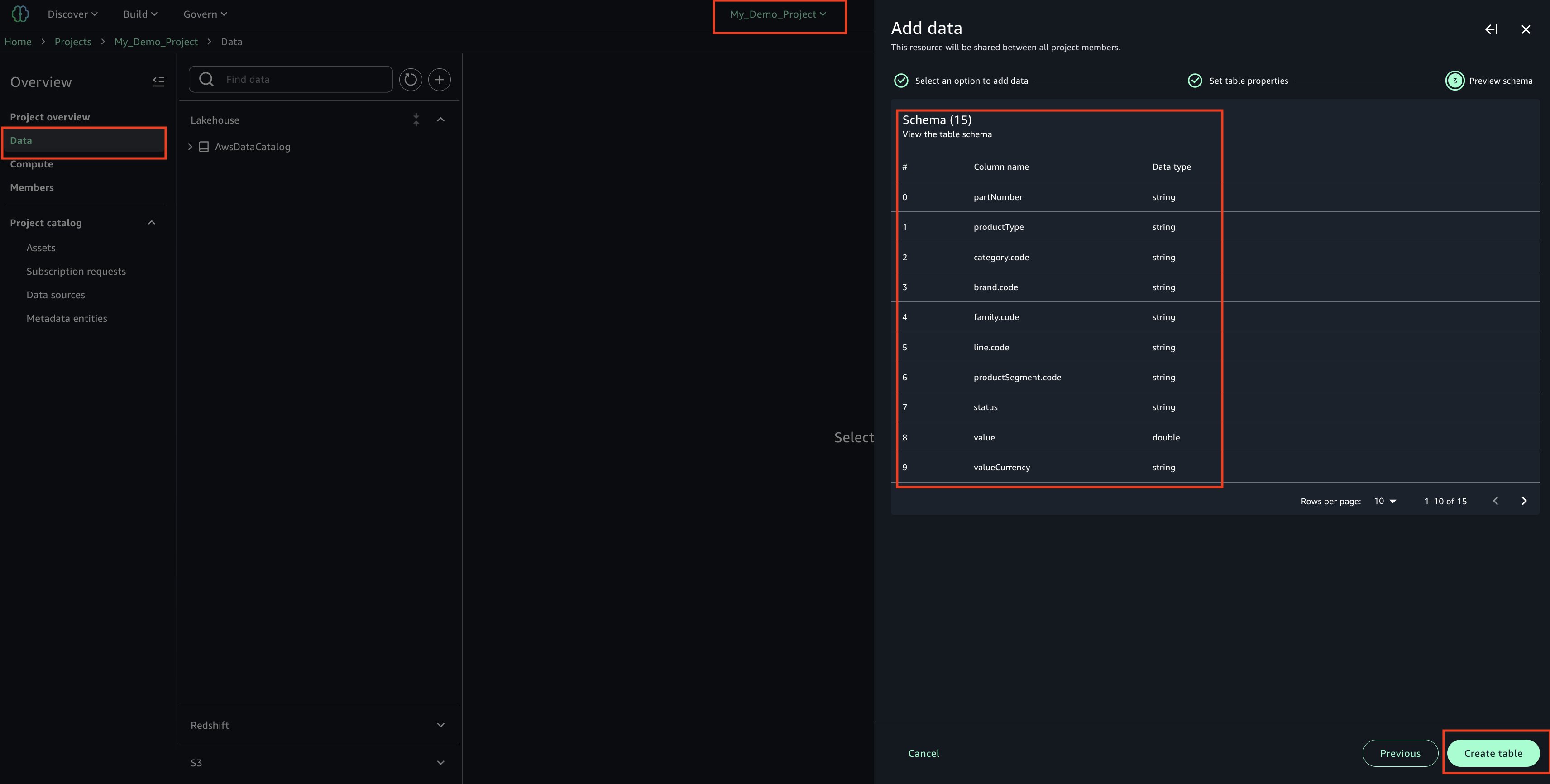
- In your project ‘My_Demo_Project’, click on Data. Choose the plus sign to add a data set.

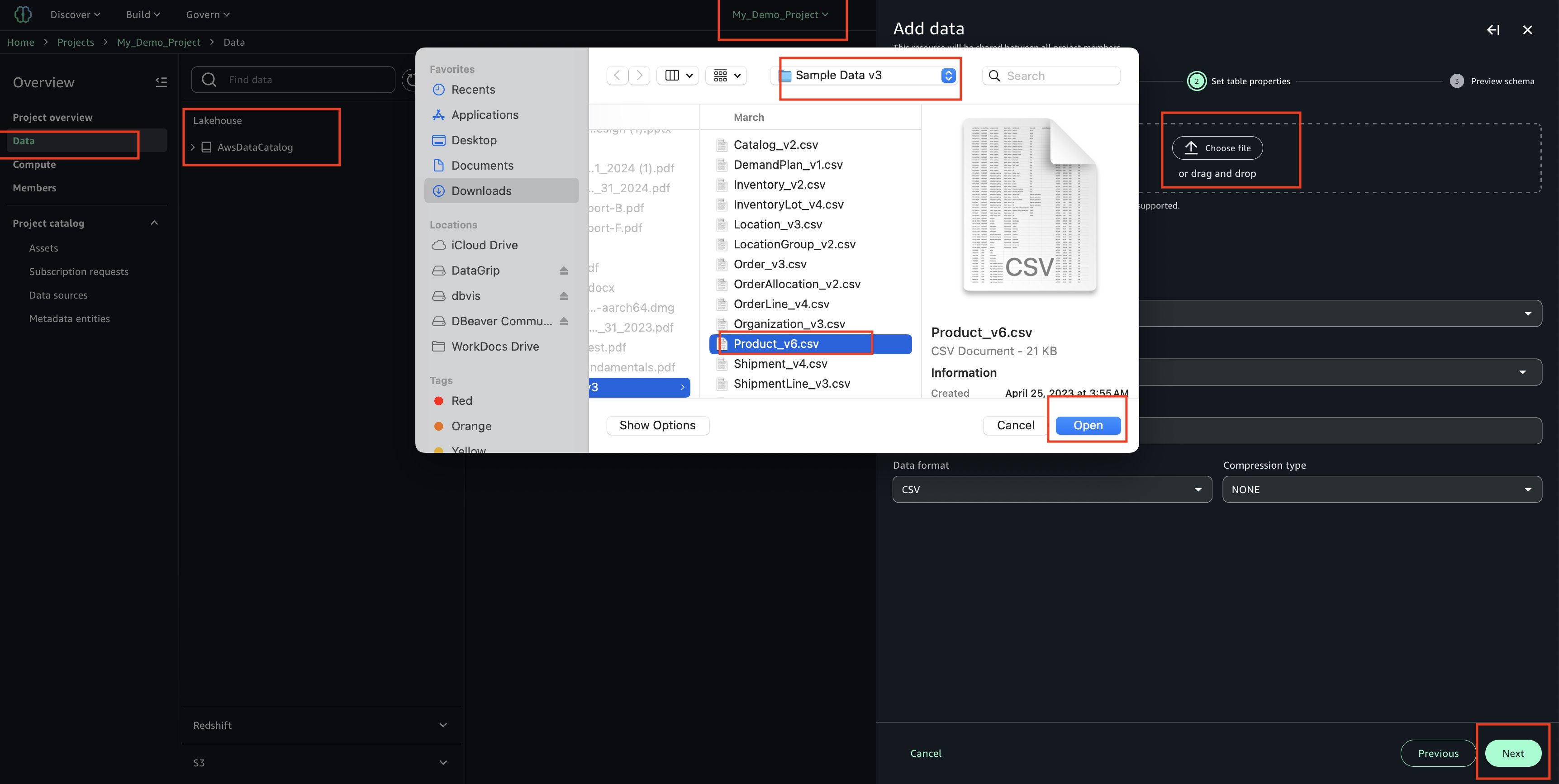
- Upload your CSV file using the sample ‘Product_v6.csv’ found in the checkout folder of the ‘sample-sagemaker-unified-studio-governance-notifications’ GitHub repository.

- Use table type as S3/external table.

- Review and confirm that the column/attribute names in the uploaded CSV file.

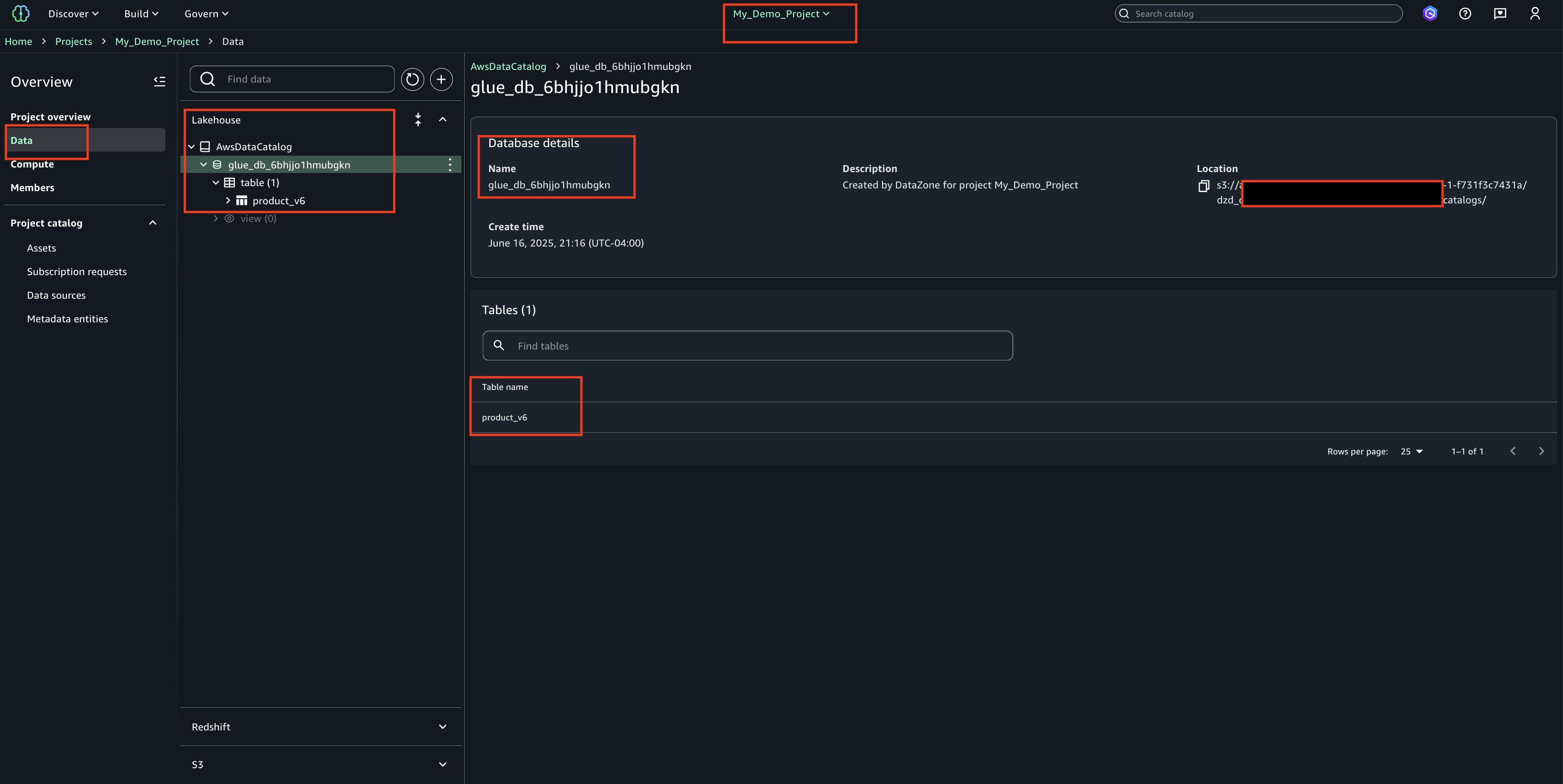
- Check the Glue database(glue_db_<unique_id>) to confirm that the table has been created and properly imported
- In your project ‘My_Demo_Project’, click on Data. Choose the plus sign to add a data set.
- Publish Asset
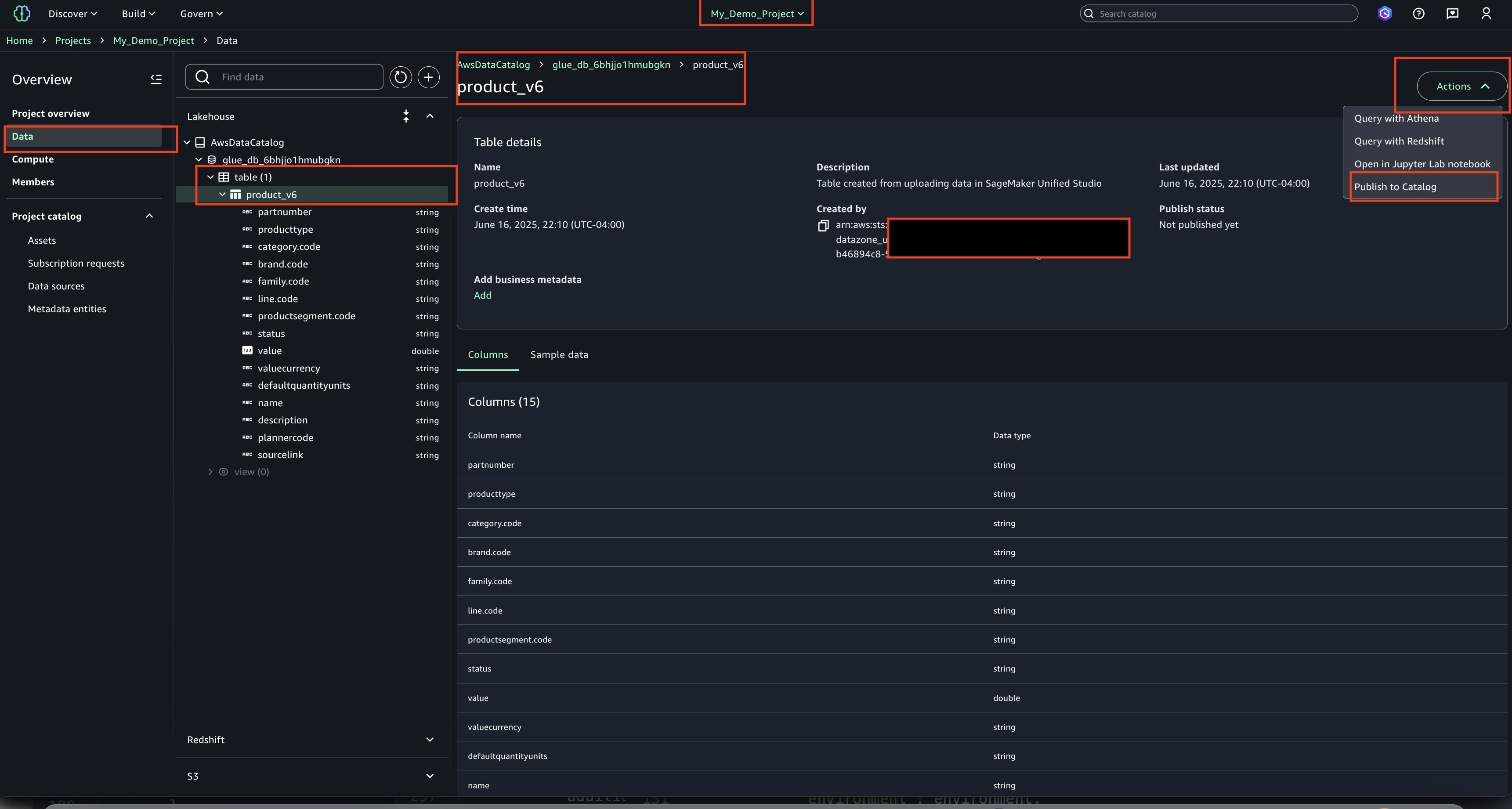
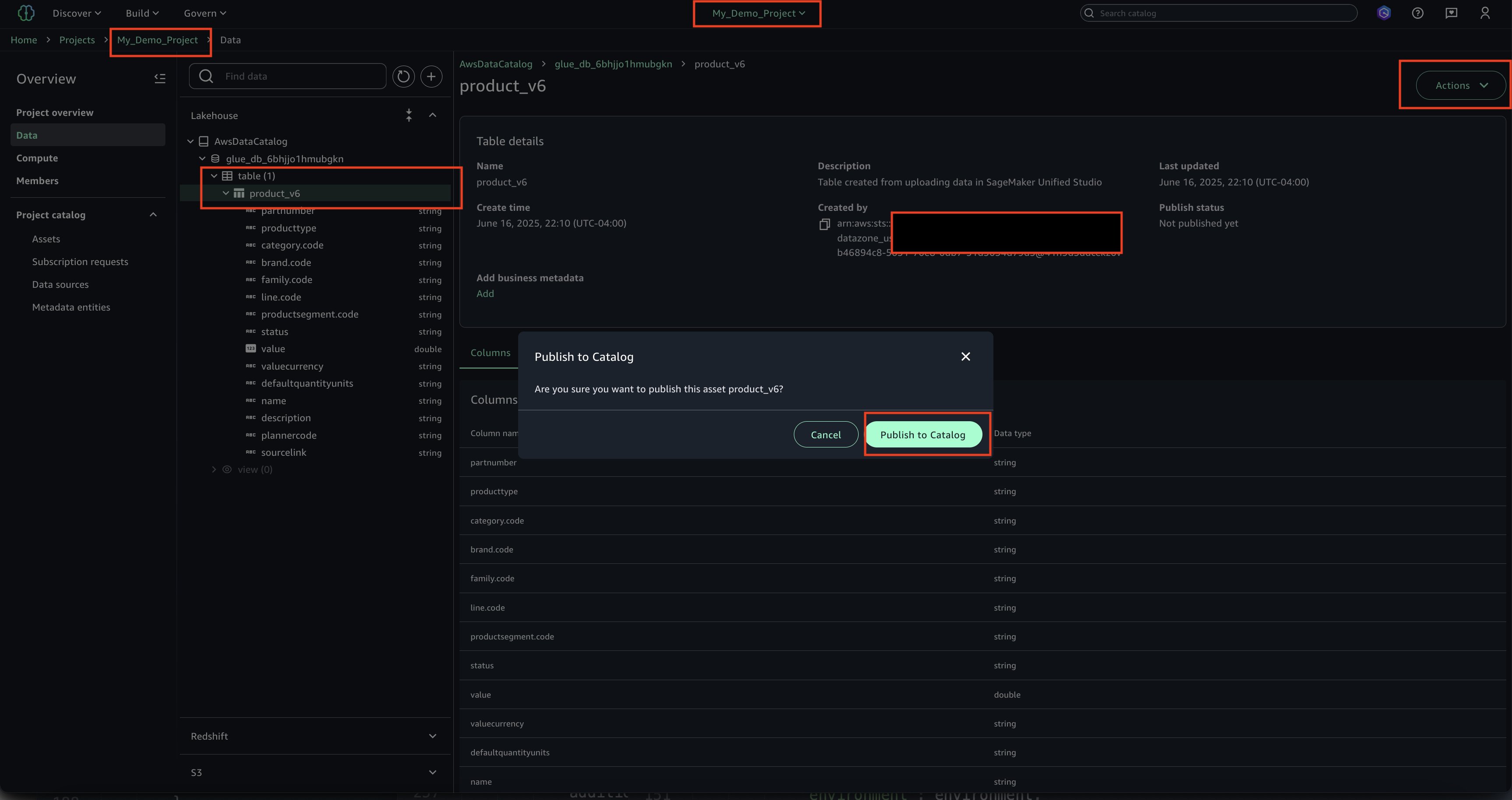
- Select the asset, choose Actions and Publish to Catalog.


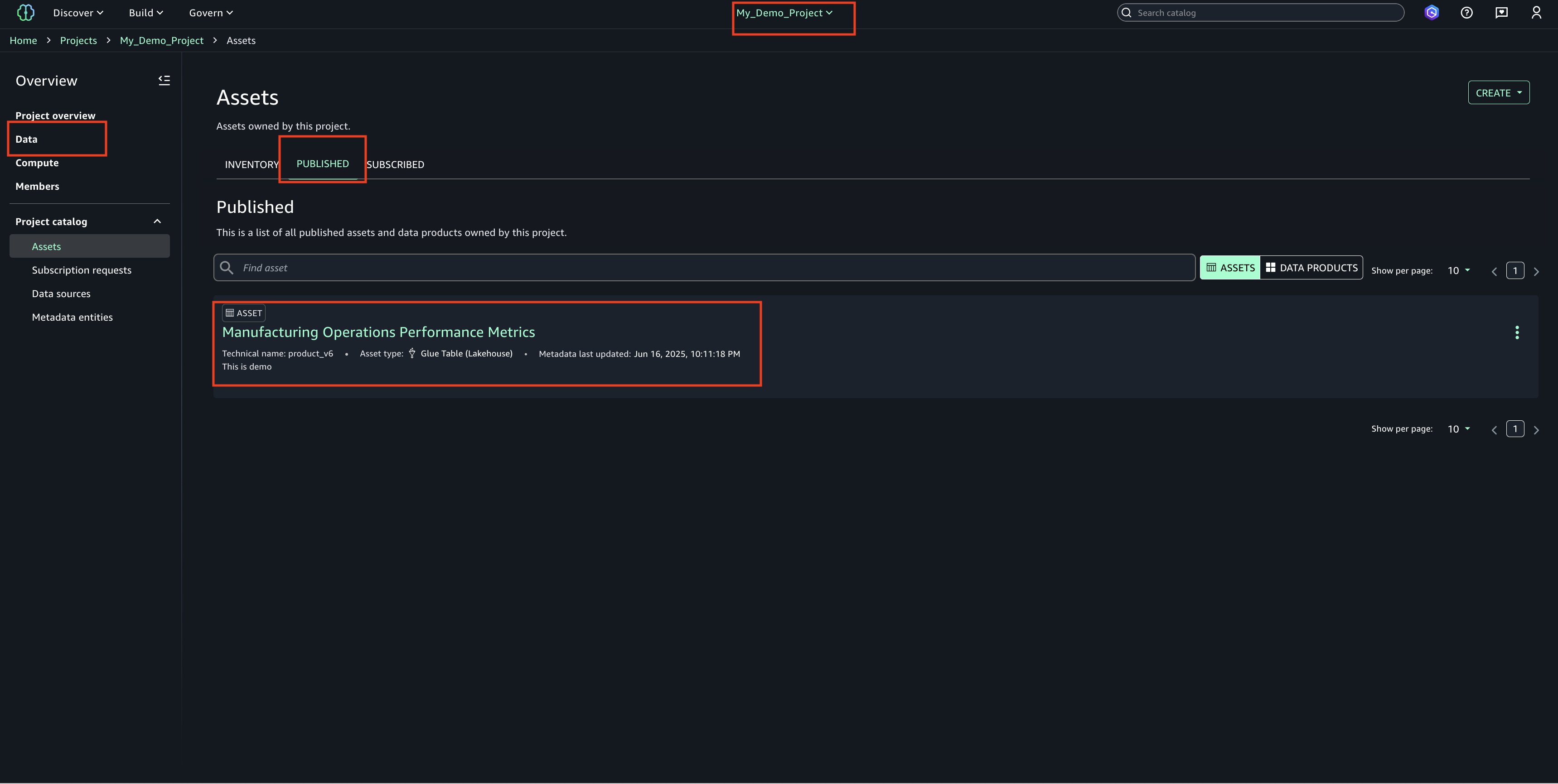
- View the published asset below.

- In the Project Catalog’s Assets section, locate the highlighted entry and verify the published table’s name

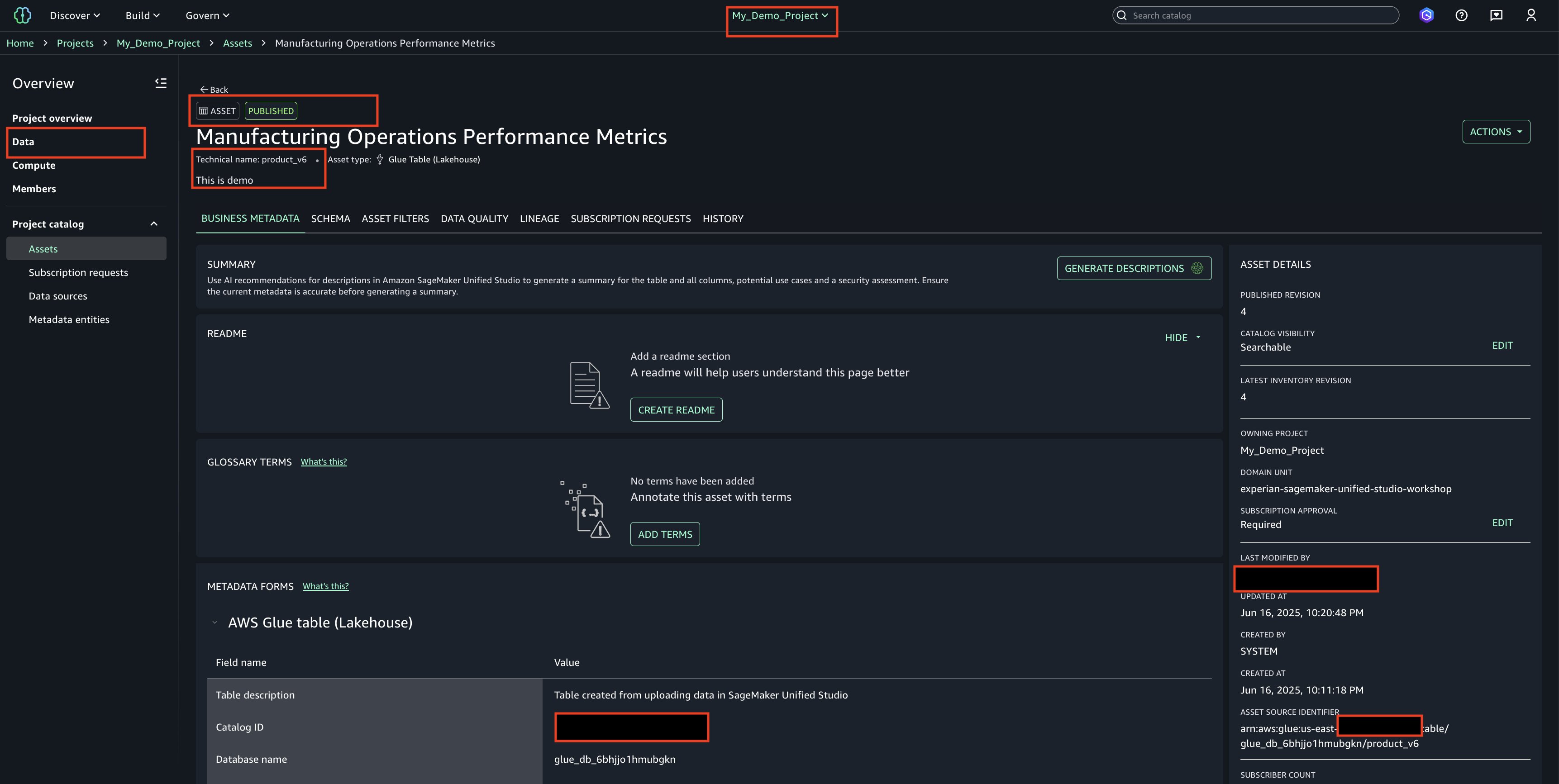
- Choose the asset name to display additional details and properties about the table/asset.
- Select the asset, choose Actions and Publish to Catalog.
- Email Alerts
- Once the asset is published to SageMaker Unified studio, you’ll receive an email alert sent with details of the published asset. Central governance teams can use this alert to review the published asset to ensure it aligns with the enterprise standards.

Email alerts are sent to notify users when assets have been published
- Once the asset is published to SageMaker Unified studio, you’ll receive an email alert sent with details of the published asset. Central governance teams can use this alert to review the published asset to ensure it aligns with the enterprise standards.

Cleanup
To clean up your resources, complete the following steps:
Conclusion
In this post, you learned how to build an automated notification system for Amazon SageMaker Unified Studio using AWS services. Specifically, we covered:
- How to set up event-driven notifications from Amazon SageMaker Unified Studio leveraging Amazon EventBridge, AWS Lambda, and Amazon SNS
- The step-by-step process of deploying the solution using AWS CDK
- Practical examples of monitoring critical events like project creation and asset publishing
- How to integrate AWS Lambda permissions with SageMaker Unified Studio for secure operations
- Best practices for implementing governance controls through automated notifications
Amazon SageMaker Catalog helps governance teams stay informed of catalog activities in real-time, enabling them to maintain organizational standards as their Data and ML platforms scale. The architecture is flexible and can be extended to integrate with enterprise workflow tools like ServiceNow or to monitor additional event types based on your organization’s needs.
We look forward to hearing how you adapt this solution for your organization’s governance needs. Fork the CDK code from our repository and share your implementation experience in the comments below


































 Himanshu Sahni is a Senior Data Architect in AWS Professional Services. Himanshu specializes in building Data and Analytics solutions for enterprise customers using AWS tools and services. He is an expert in AI/ ML and Big Data tools like Spark, AWS Glue and Amazon EMR. Outside of work, Himanshu likes playing chess and tennis.
Himanshu Sahni is a Senior Data Architect in AWS Professional Services. Himanshu specializes in building Data and Analytics solutions for enterprise customers using AWS tools and services. He is an expert in AI/ ML and Big Data tools like Spark, AWS Glue and Amazon EMR. Outside of work, Himanshu likes playing chess and tennis. Arunabha Datta is a Senior Data Architect at AWS Professional Services. He collaborates with customers and partners to create and execute modern data architecture using AWS Analytics services. Arunabha’s passion lies in assisting customers with digital transformation, particularly in the areas of data lakes, databases, and AI/ML technologies. Besides work, his hobbies include photography and he likes to spend quality time with his family.
Arunabha Datta is a Senior Data Architect at AWS Professional Services. He collaborates with customers and partners to create and execute modern data architecture using AWS Analytics services. Arunabha’s passion lies in assisting customers with digital transformation, particularly in the areas of data lakes, databases, and AI/ML technologies. Besides work, his hobbies include photography and he likes to spend quality time with his family. Charishma Ravoori is an Associate Data & ML Engineer at AWS Professional Services. She focuses on developing solutions for customers that include building out data pipelines, developing predictive models and generating ai chatbots using AWS/Amazon tools. Outside of work, Charishma likes to experiment with new recipes and play the guitar.
Charishma Ravoori is an Associate Data & ML Engineer at AWS Professional Services. She focuses on developing solutions for customers that include building out data pipelines, developing predictive models and generating ai chatbots using AWS/Amazon tools. Outside of work, Charishma likes to experiment with new recipes and play the guitar.