Post Syndicated from Jörg Janssen original https://aws.amazon.com/blogs/big-data/scaling-data-governance-with-amazon-datazone-covestro-success-story/
Covestro Deutschland AG, headquartered in Leverkusen, Germany, is a global leader in high-performance polymer materials and components. Since its spin-off from Bayer AG in 2015, Covestro has established itself as a key player in the chemical industry, with 48 production sites worldwide, €14.4 billion 2023 revenue, and 17,500 employees. Covestro’s core business focuses on developing innovative, sustainable solutions for products used in various aspects of daily life. The company offers materials for mobility, building and living, electrical and electronics sectors, in addition to sports and leisure, cosmetics, health, and the chemical industry. The company’s products, such as polycarbonates, polyurethanes, coatings, adhesives, and specialty elastomers, are important components in automotive, construction, electronics, and medical device industries.
To support this global operation and diverse product portfolio, Covestro adopted a robust data management solution. In this post, we show you how Covestro transformed its data architecture by implementing Amazon DataZone and AWS Serverless Data Lake Framework (SDLF), transitioning from a centralized data lake to a data mesh architecture. Through this strategic shift, teams can share and consume data while maintaining high quality standards through a consolidated data marketplace and business metadata glossary. The result: streamlined data access, better data quality, and stronger governance at scale that various producer and consumer teams can use to run data and analytics workloads at scale, enabling over 1,000 data pipelines and achieving a 70% reduction in time-to-market.
Business and data challenges
Prior to their transformation, Covestro operated with a centralized data lake managed by a single data platform team that handled the data engineering tasks. This centralized approach created several challenges: bottlenecks in project delivery because of limited engineering resources, complicated prioritization of use cases, and inefficient data sharing processes. The setup often resulted in unnecessary data duplication, which in turn slowed down time-to-market for new analytics initiatives, increased costs, and limited the ability of business units to act quickly on insights.The lack of visibility into data assets created significant operational challenges:
- Teams could not find existing datasets, often recreating data already stored elsewhere
- No clear understanding of data lineage or quality metrics
- Difficulty in determining who owned specific data assets or who to contact for access
- Absence of metadata and documentation about available datasets
- Departments shared little knowledge about how they were using data
These visibility issues, combined with the lack of unified access controls, led to:
- Siloed data initiatives across departments
- Reduced trust in data quality
- Inefficient use of resources
- Delayed project timelines
- Missed opportunities for cross-functional collaboration and insights
A strategic solution: Why Amazon DataZone and SDLF?
The challenges Covestro faced reflect deeper structural limitations of centralized data architectures. As Covestro scaled, central data teams often became bottlenecks, and lack of domain context led to fragmented quality, inconsistent standards, and poor collaboration. Instead of centralizing control, a data mesh gives ownership to the teams who generate and understand the data, while keeping the governance and interoperability consistent across the organization. This makes it well-suited for Covestro’s environment, which requires agility, scalability, and cross-team collaboration.
AWS Serverless Data Lake Framework (SDLF) is a solution to these challenges, providing a robust foundation for data mesh architectures. Traditional data lake implementations often centralize data ownership and governance, but with the flexible design of SDLF, organizations can build decentralized data domains that align with modern data mesh principles. The framework provides domain-oriented teams with the infrastructure, security controls, and operational patterns needed to own and manage their data products independently, while maintaining consistent governance across the organization. Through its modular architecture and infrastructure as code templates, SDLF accelerates the creation of domain-specific data products, so that Covestro’s teams can deploy standardized yet customizable data pipelines. This approach supports the key pillars of data mesh: domain-oriented decentralization, data as a product, self-serve infrastructure, and federated governance, providing Covestro with a practical path to overcome the limitations of traditional centralized architectures.
Amazon DataZone enhances the data mesh implementation through a unified experience for discovering and accessing data across decentralized domains. As a data management service, Amazon DataZone helps organizations catalog, discover, share, and govern data across organizational boundaries. It provides a central governance layer where organizations can establish data sharing agreements, manage access controls, and enable self-service data access while supporting security and compliance. While teams can use the SDLF framework to build and operate domain-specific data products, Amazon DataZone complements it with a searchable catalog enriched with metadata, business context, and usage policies, making data products easier to find, trust, and reuse.
Through the sharing capabilities of Amazon DataZone, domain teams can share their data products with other domains while maintaining granular access controls and governance policies, enabling cross-domain collaboration and data reuse. This integration means that domain teams can publish their SDLF-managed datasets to an Amazon DataZone catalog, so authorized consumers across the organization can discover and access them. Through the built-in governance capabilities built into Amazon DataZone, organizations can implement standardized data sharing workflows, check data quality, and enforce consistent access controls across their distributed data system, strengthening their data mesh architecture with robust data governance and democratization capabilities.Together, SDLF and Amazon DataZone provide Covestro with a comprehensive solution for implementing a modern data mesh architecture, enabling autonomous data domains to operate with consistent governance, seamless data sharing, and enterprise-wide data discovery.
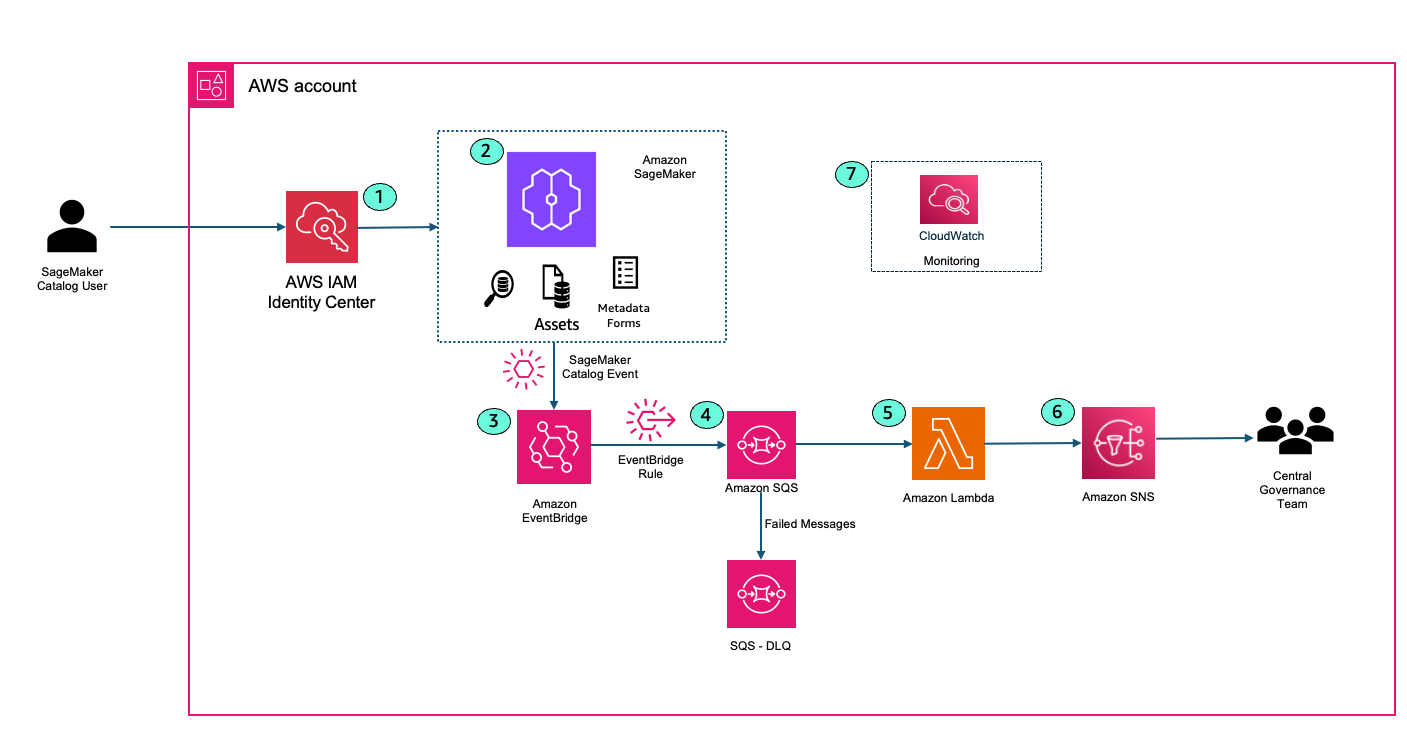
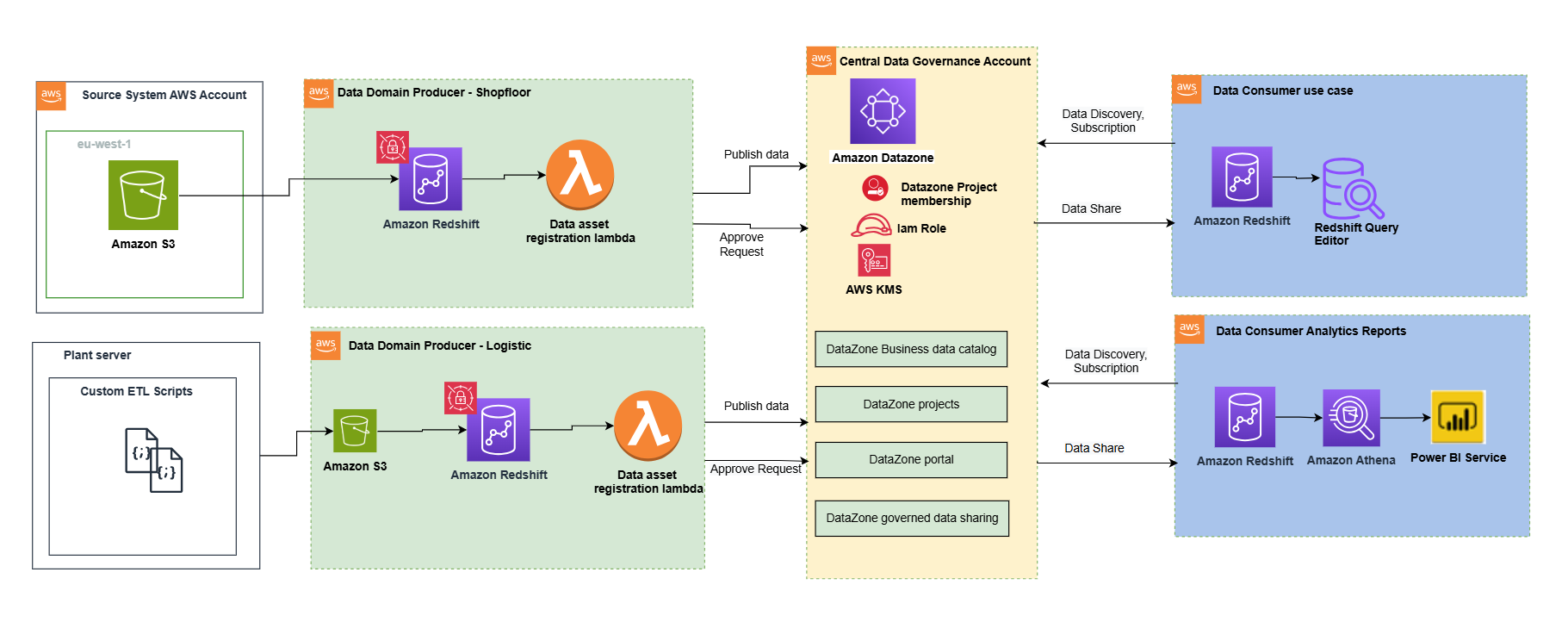
Solution architecture and implementation
The following architecture illustrates the high-level design of the data mesh solution. The implementation used a comprehensive AWS solution built on AWS services to create a robust, scalable, and governed data mesh that serves multiple business domains across the Covestro organization.
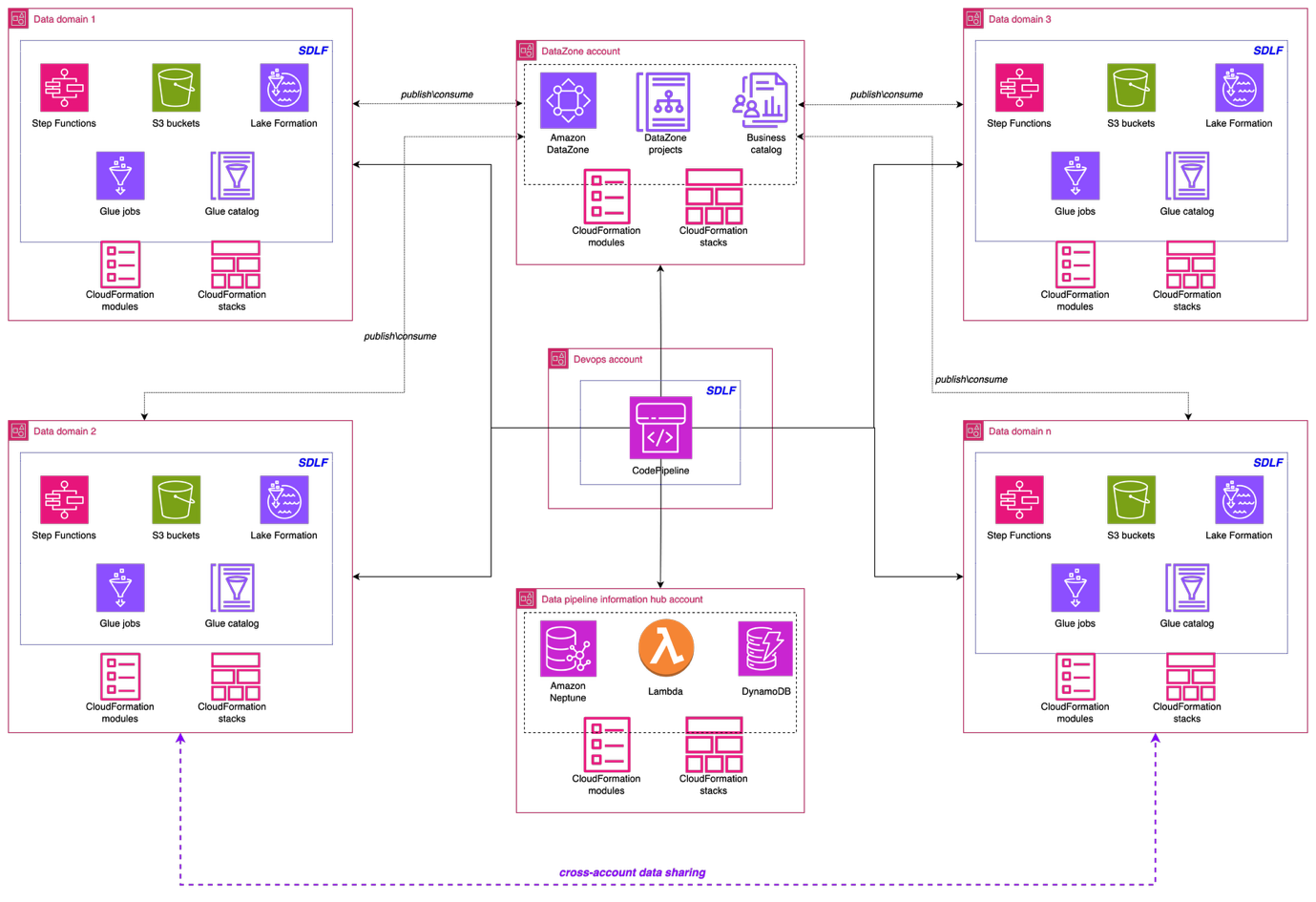
Data domain foundation: Serverless Data Lake Framework
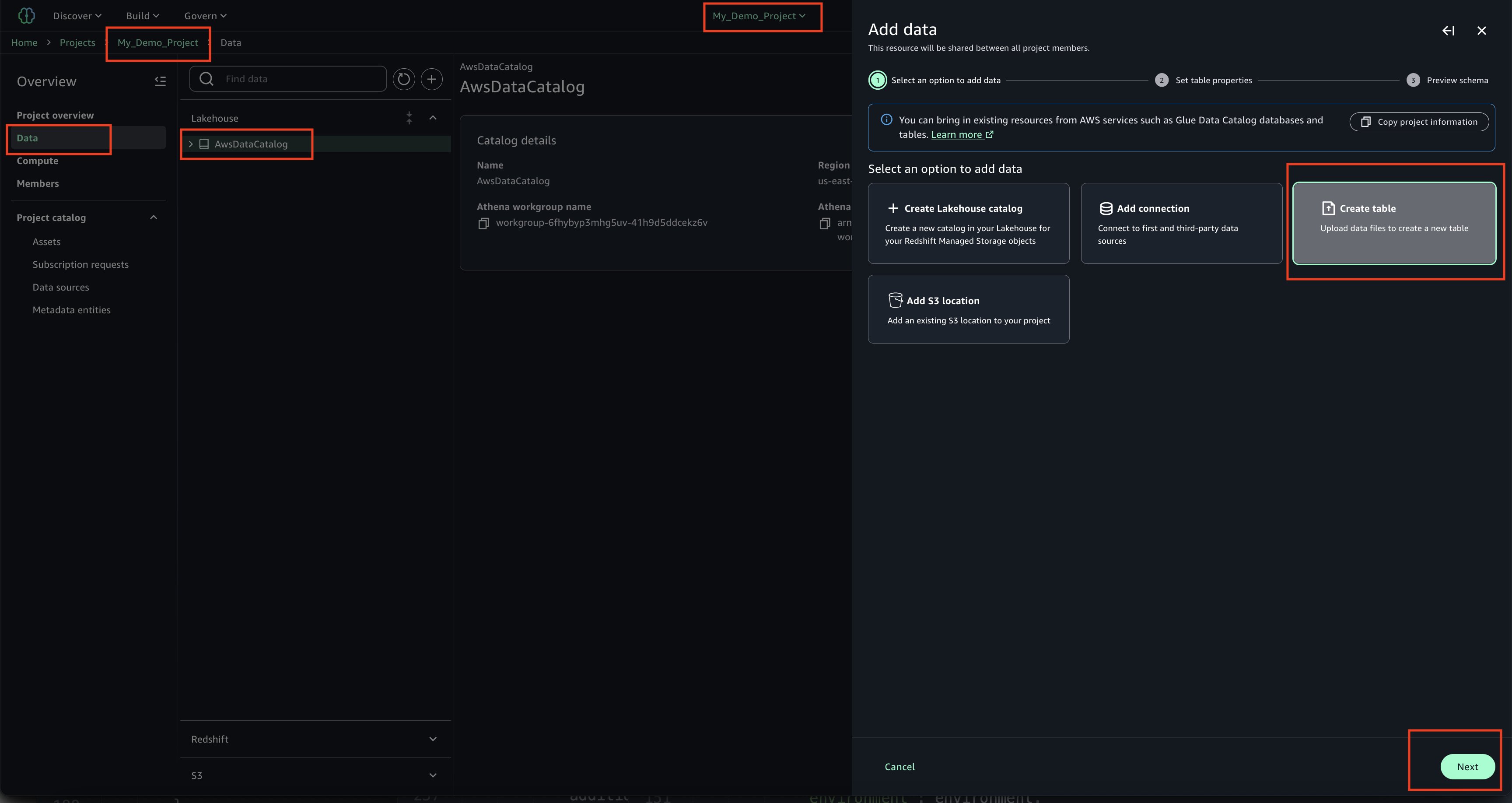
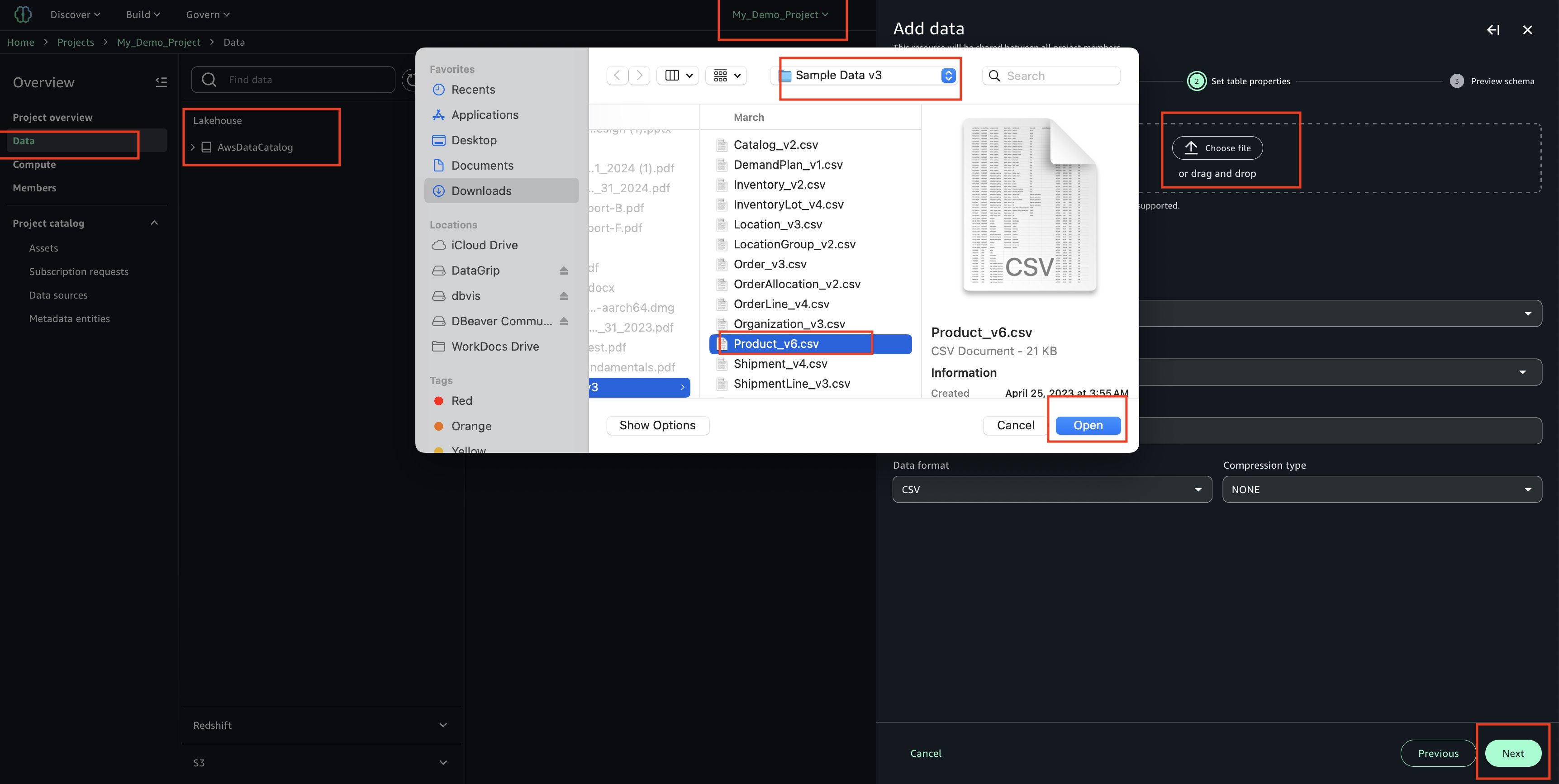
A key pillar of the implementation is the Serverless Data Lake Framework (SDLF), which provides the foundational infrastructure and security needed to support data mesh strategies. SDLF delivers the core building blocks for data domains such as Amazon S3 storage layers, built-in encryption with AWS KMS, IAM-based access control, and infrastructure as code (IaC) automation. By using these components, Covestro can deploy decentralized, domain-owned data products rapidly while maintaining consistent governance across the enterprise.
The framework uses Amazon Simple Storage Service (Amazon S3) as the primary data storage layer, delivering virtually unlimited scalability and eleven nines of durability for diverse data assets. The proposed S3 bucket architecture follows AWS Well-Architected principles, implementing a multi-tiered structure with distinct raw, staging, and analytics data zones. This layered approach helps different business domains to maintain data sovereignty (each domain owns and controls its data, while keeping accessibility patterns organization-wide).
Security is a fundamental aspect in Covestro’s data mesh implementation. SDLF automatically implements encryption at rest and in transit across data storage and processing components. AWS Key Management Service (AWS KMS) provides centralized key management, while carefully crafted AWS Identity and Access Management (IAM) roles enable resource isolation.
Data processing with AWS Glue
AWS Glue serves as the cornerstone of the data processing and transformation capabilities, offering serverless extract, transform, and load ETL services that automatically scale based on workload demands.
Covestro’s pre-existent centralized data lake was fed by more than 1,000 ingestion data pipelines interacting with a variety of source systems. To support the migration of existing ingestion and processing pipelines, Covestro developed reusable blueprints that included the development and security standards defined for the data mesh.Covestro released standardized patterns that teams can deploy across multiple domains while providing the flexibility needed for domain-specific requirements. These blueprints support diverse source systems, from traditional databases like Oracle, SQL Server, and MySQL to modern software as a service (SaaS) applications such as SAP C4C.
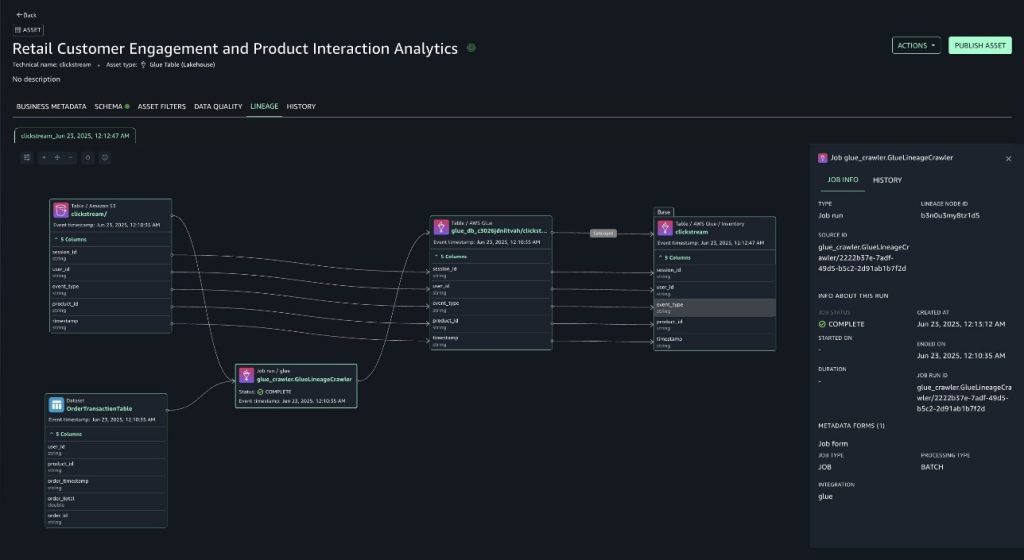
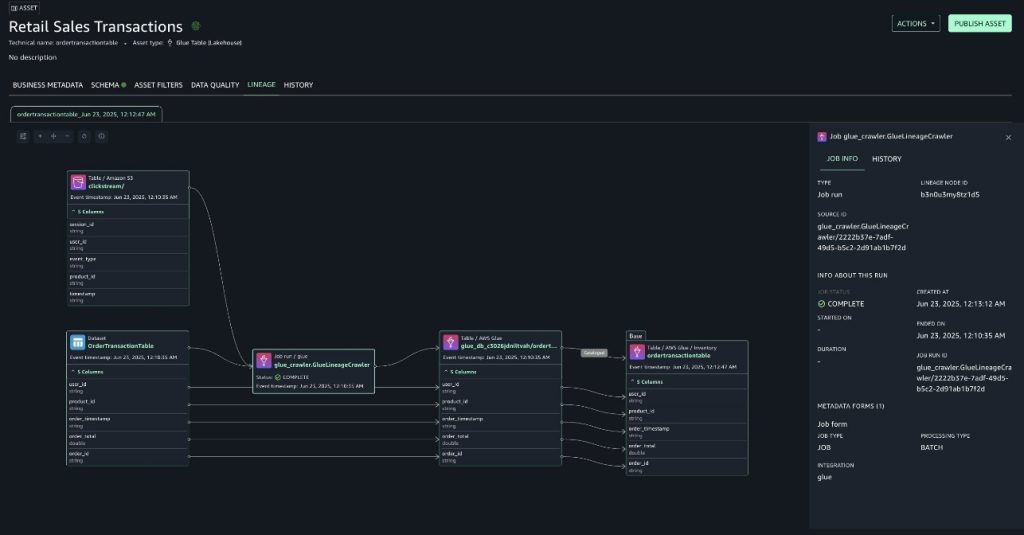
They also developed specialized blueprints for processing, standardizing, and cleaning ingested raw data. These blueprints store processed data in Apache Iceberg format, automatically saving metadata in the AWS Glue Data Catalog and providing built-in capabilities to handle schema evolution seamlessly.
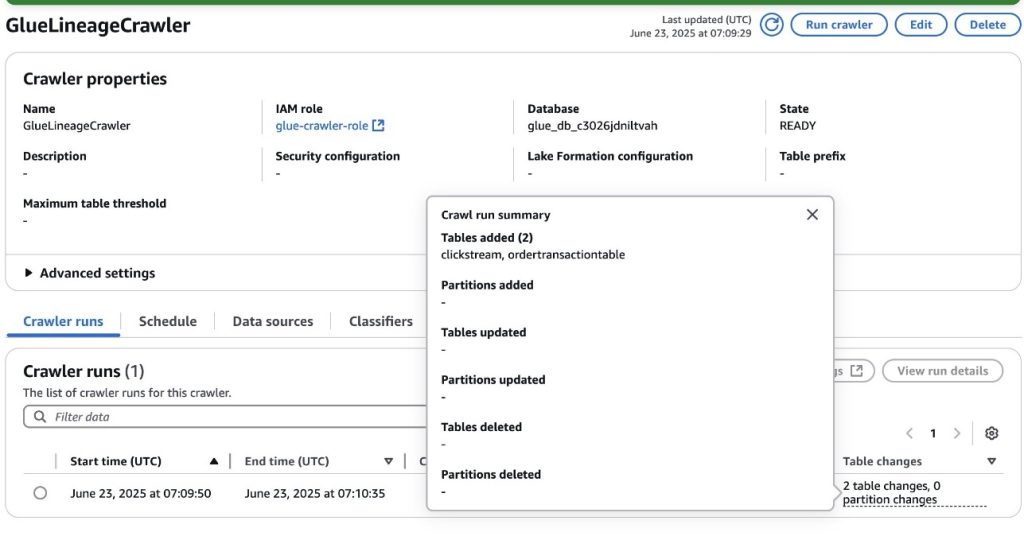
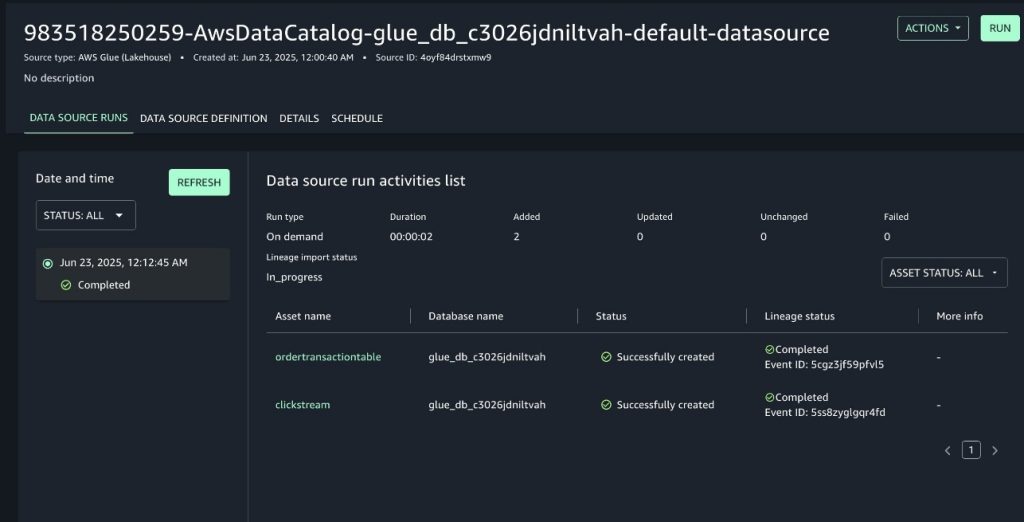
Covestro relies on SDLF to quickly configure and deploy the blueprints as AWS Glue jobs inside the domain. With SDLF, teams deploy a data pipeline through a YAML configuration file, and the orchestration and management mechanisms of SDLF handle the rest. The solution includes comprehensive monitoring capabilities built on Amazon DynamoDB, providing real-time visibility into data pipeline health and performance metrics (when teams deploy a pipeline through SDLF, the system automatically integrates it with the monitoring setup).
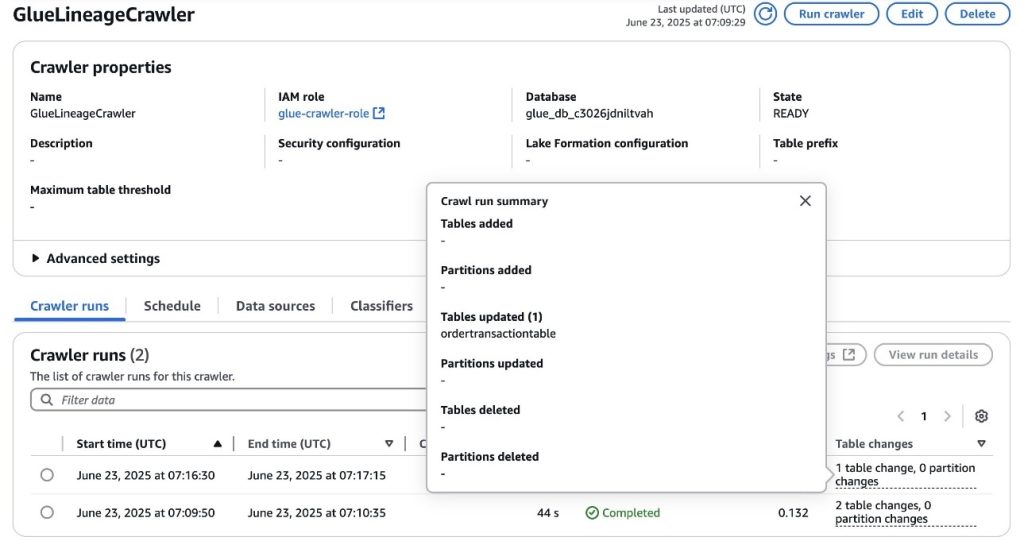
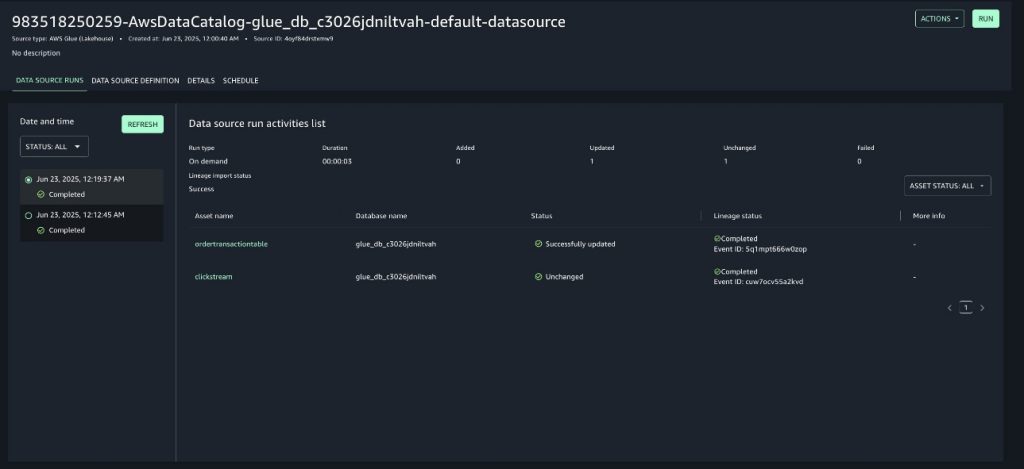
Data quality with AWS Glue Data Quality
To achieve data reliability across domains, Covestro extended the capabilities of SDLF to incorporate AWS Glue Data Quality into data processing pipelines. This integration enables automated data quality checks as part of the standard data processing workflow. Thanks to the configuration-driven design of SDLF, data producers can implement quality controls either using recommended rules, which are automatically generated through data profiling, or applying their own domain-specific rules.
The integration provides data teams with the flexibility to define quality expectations while maintaining consistency in how quality checks are implemented at the pipeline level. The solution logs quality evaluation results, providing visibility into the data quality metrics for each data product. These elements are illustrated in the following figure.
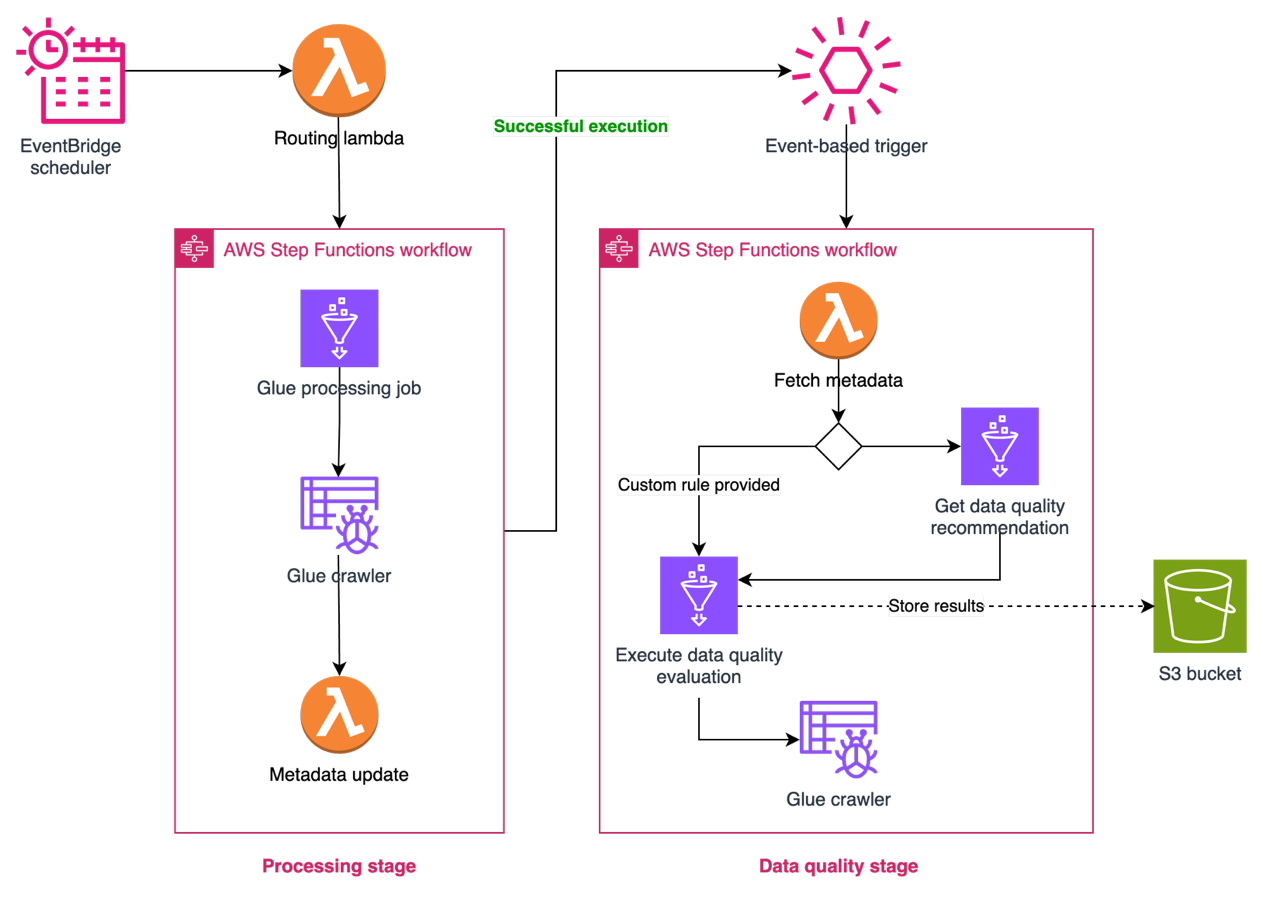
Enterprise-ready access control with AWS Lake Formation
AWS Lake Formation integration with the Data Catalog supports the security and access control layer that makes the data mesh implementation enterprise-ready. Through Lake Formation, Covestro implemented fine-grained access controls that respect domain boundaries while enabling controlled cross-domain data sharing.
The service’s integration with IAM means that Covestro can implement role-based access patterns that align with their organizational structure, so users can access the data they need while keeping appropriate security boundaries.
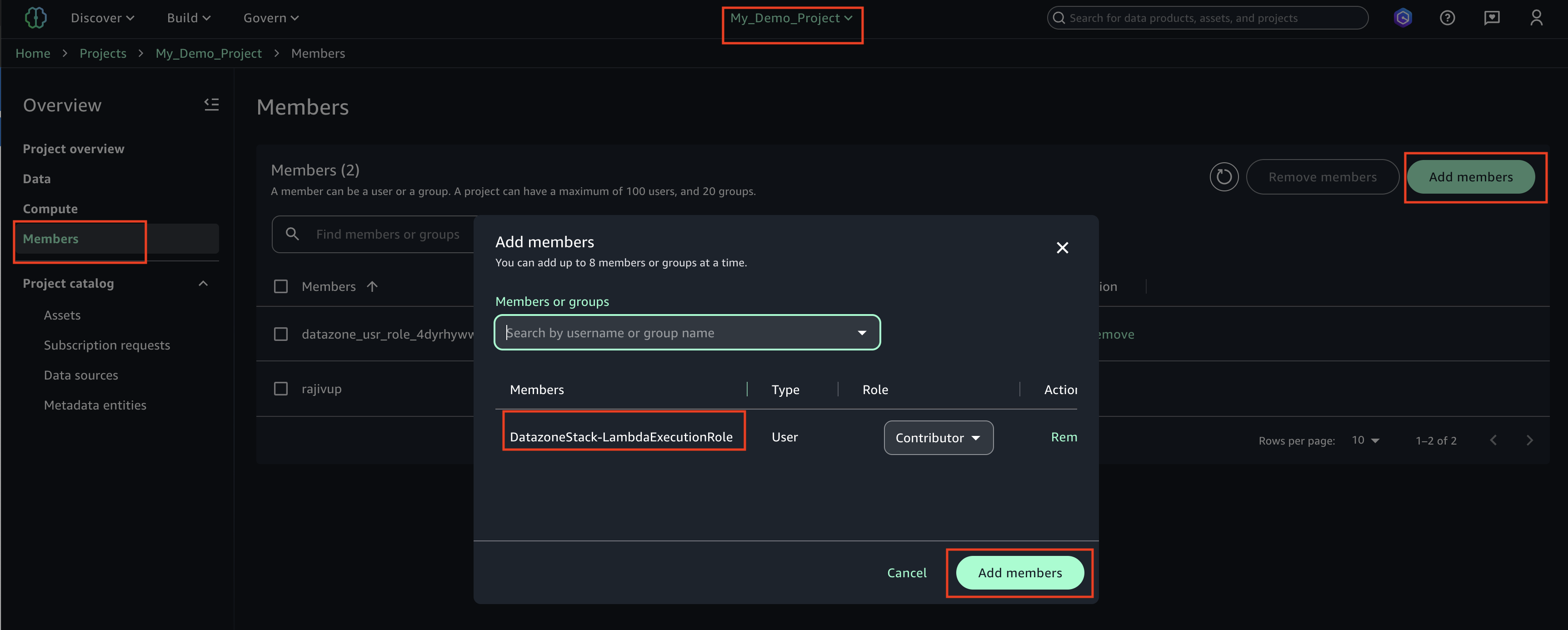
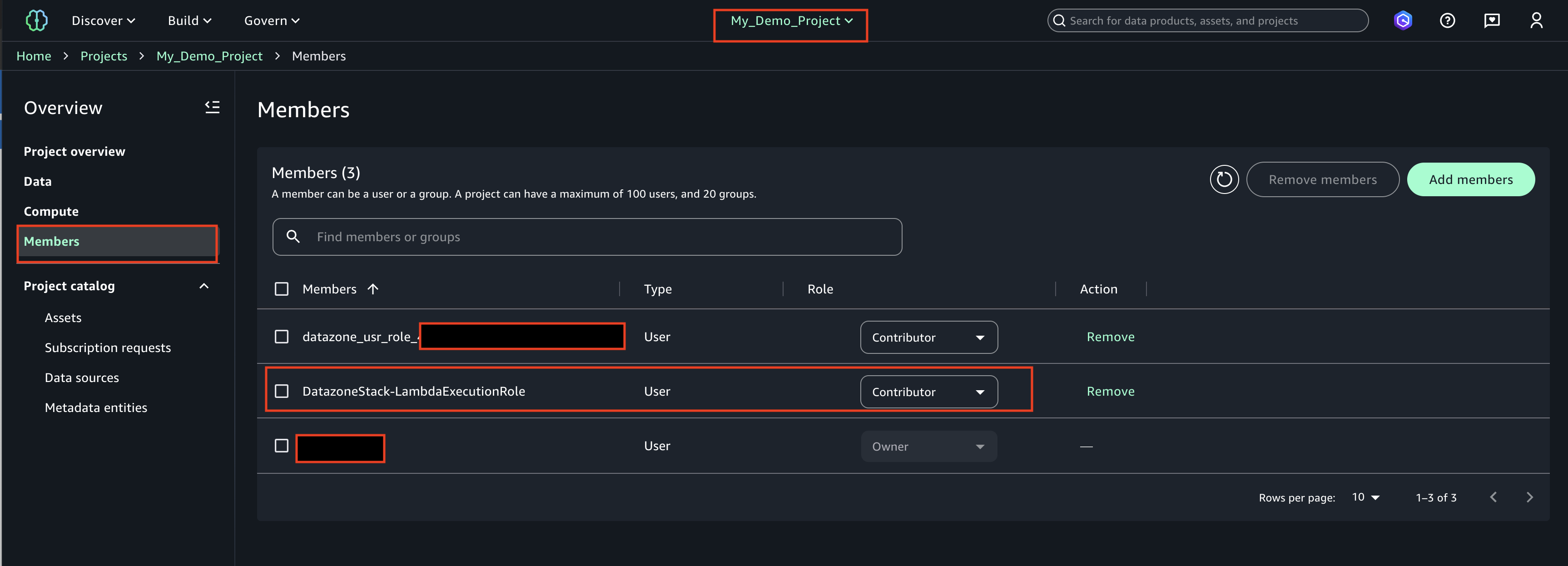
Data democratization with Amazon DataZone
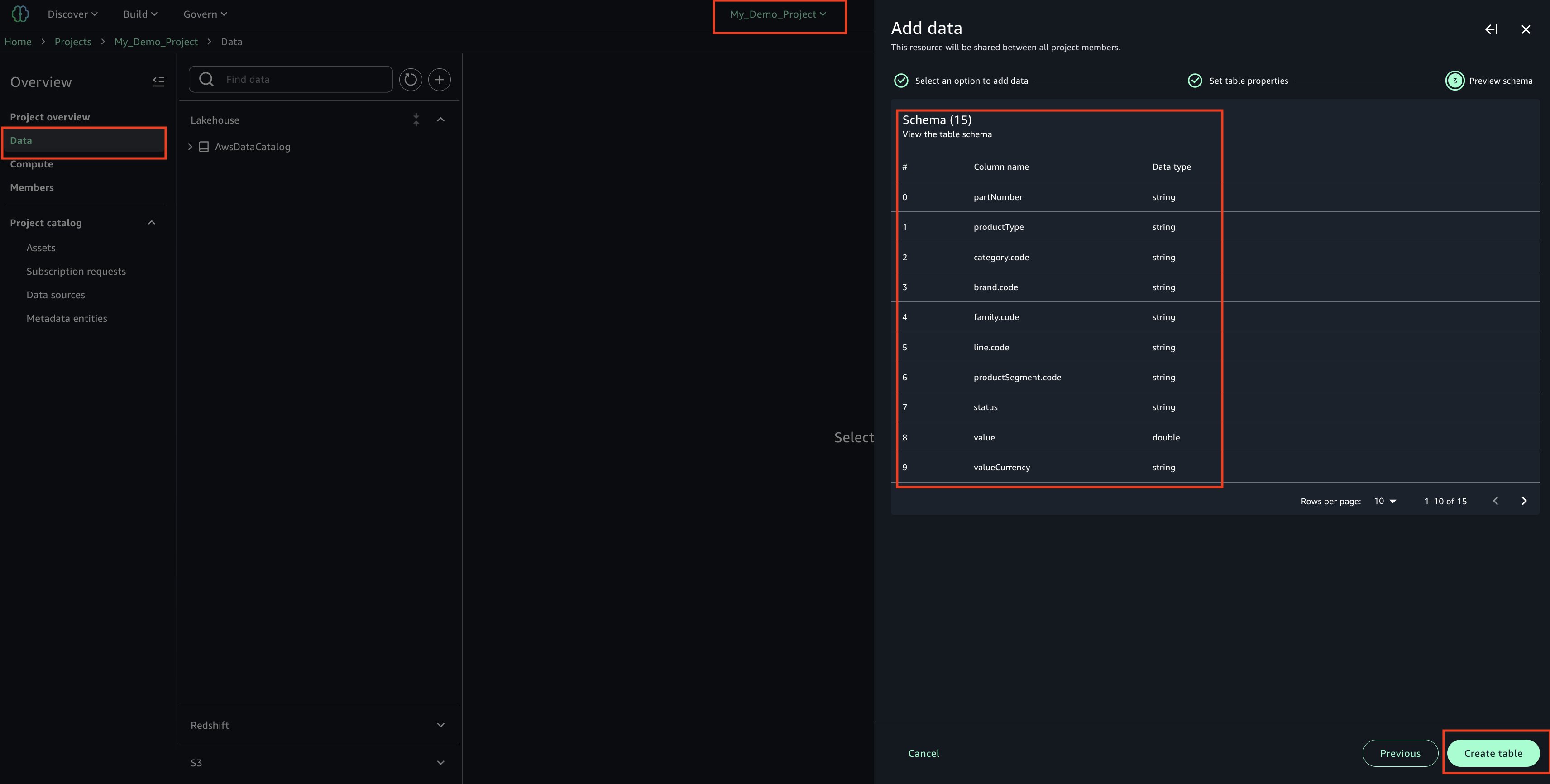
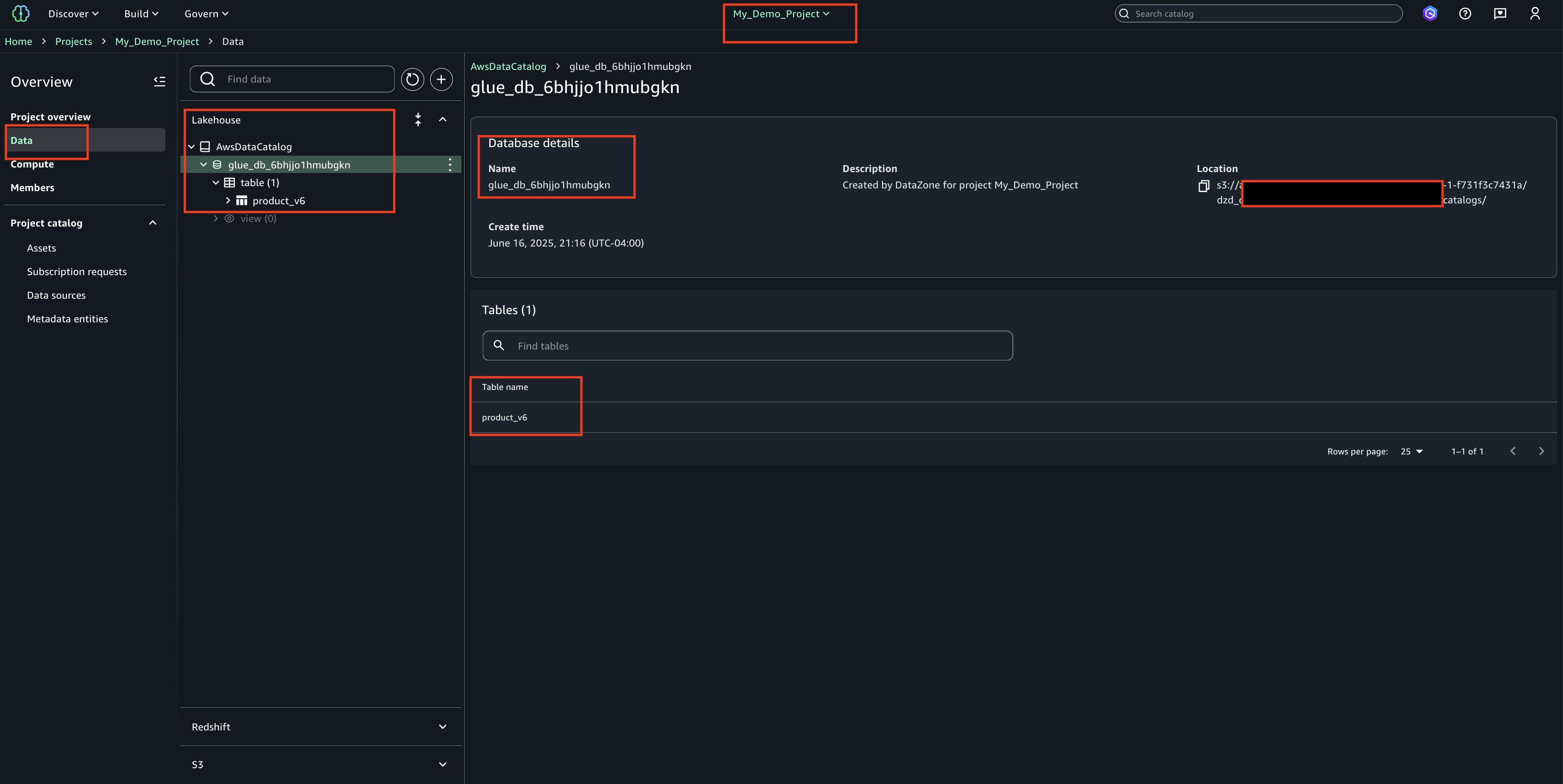
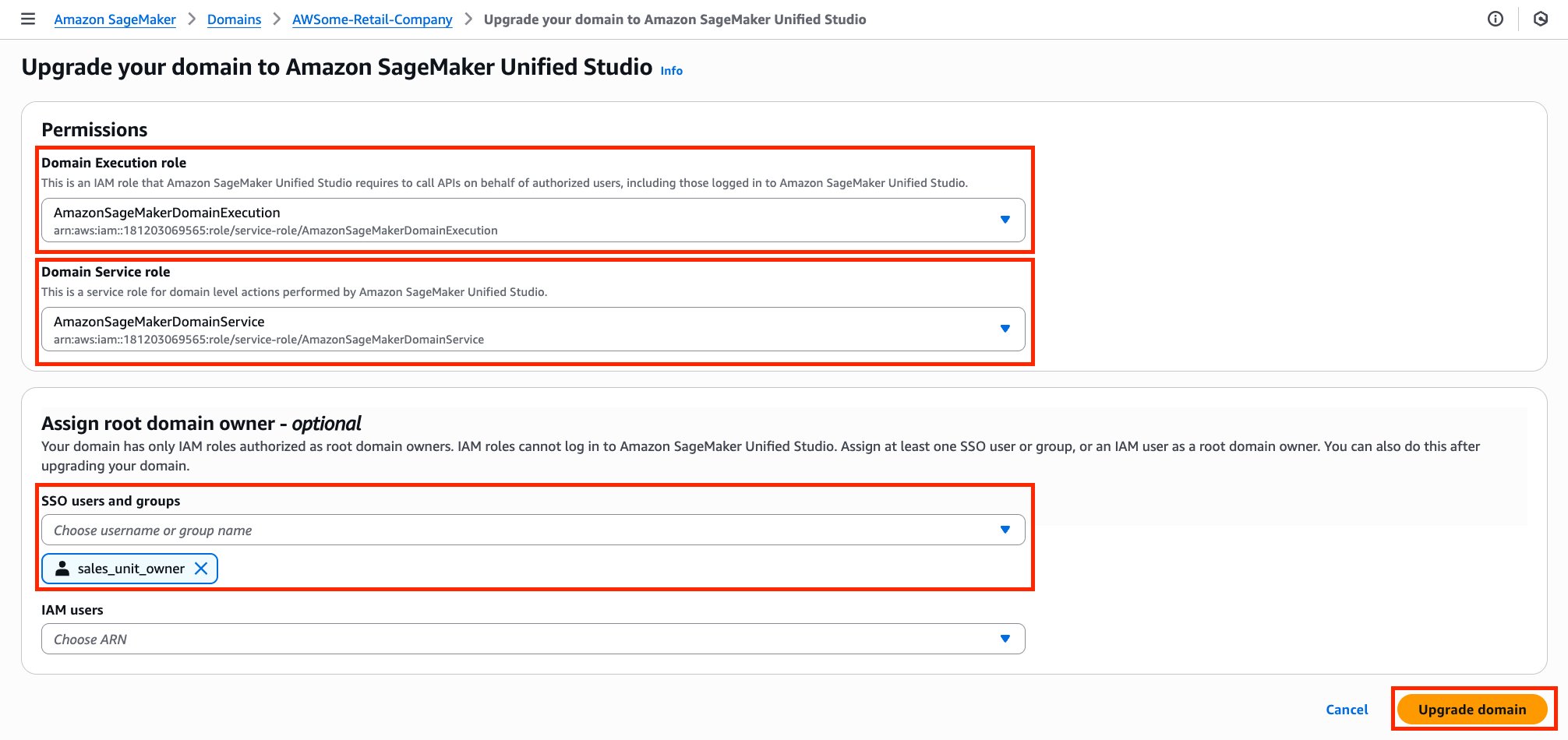
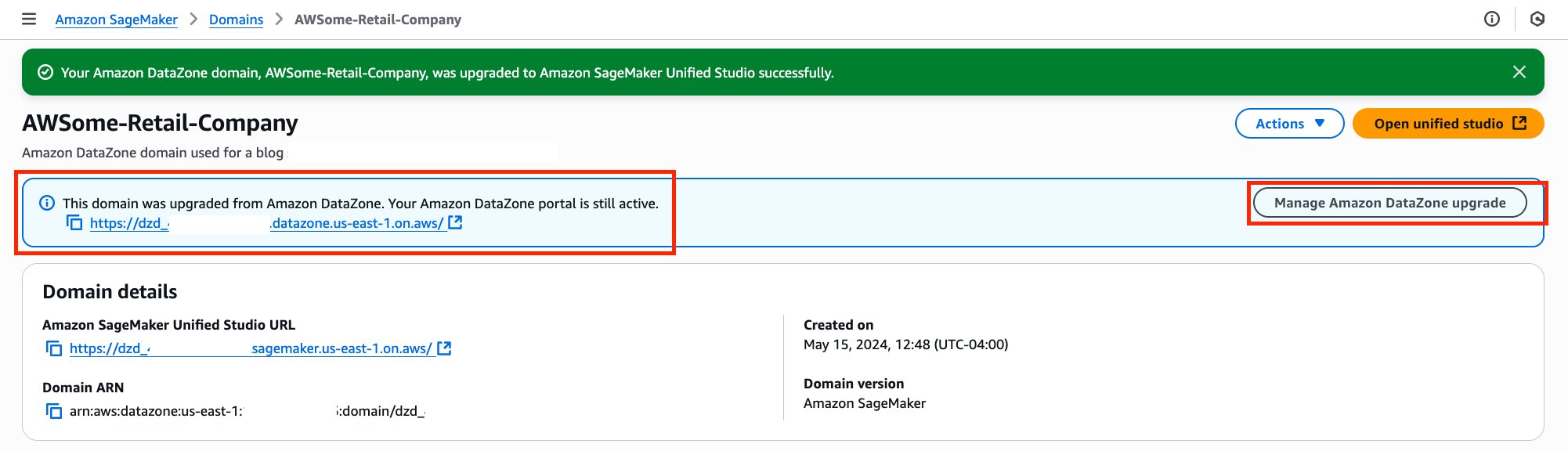
Amazon DataZone functions as the heart of the data mesh implementation. Deployed in a dedicated AWS account, it provides the data governance, discovery, and sharing capabilities that were missing in the previous centralized approach. DataZone offers a unified, searchable catalog enriched with business context, automated access controls, and standardized sharing workflows that enable true data democratization across the organization.
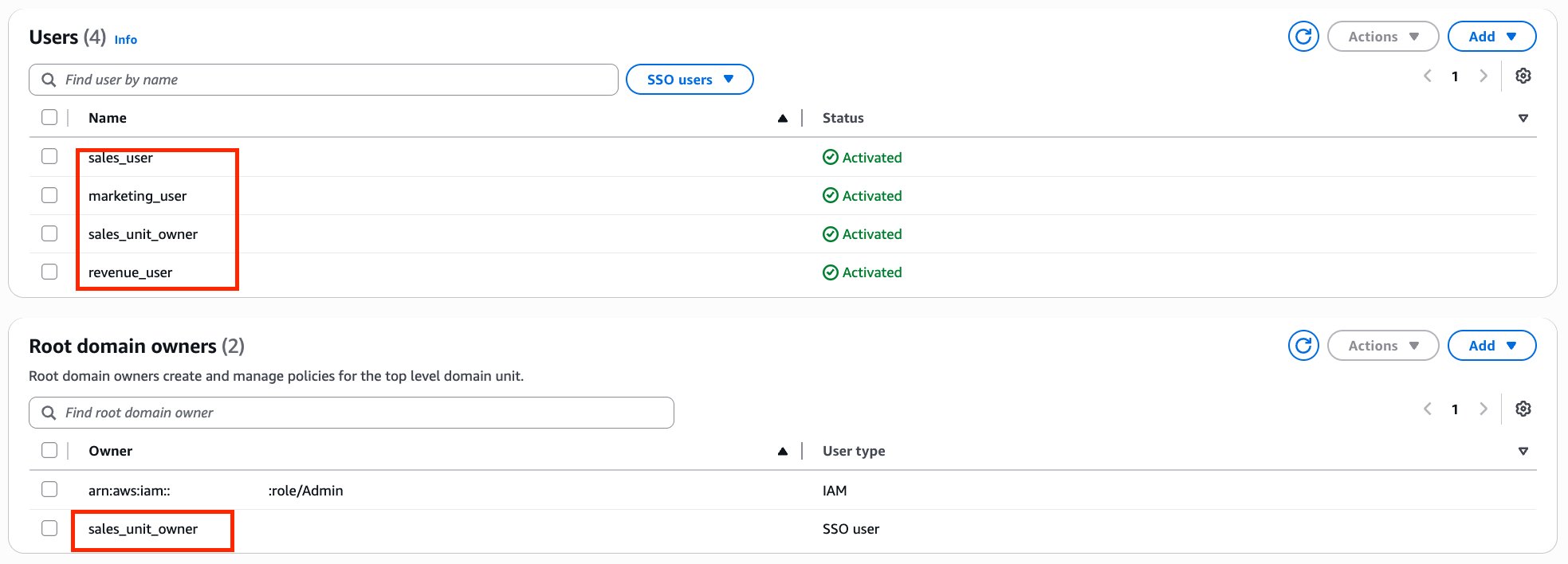
Through Amazon DataZone, Covestro established a comprehensive data catalog that helps business users across different domains to discover, understand, and request access to data assets without requiring deep technical expertise. The business glossary functionality supports consistent data definitions across domains, eliminating the confusion that often arises when different teams use different terminology for the same concepts.
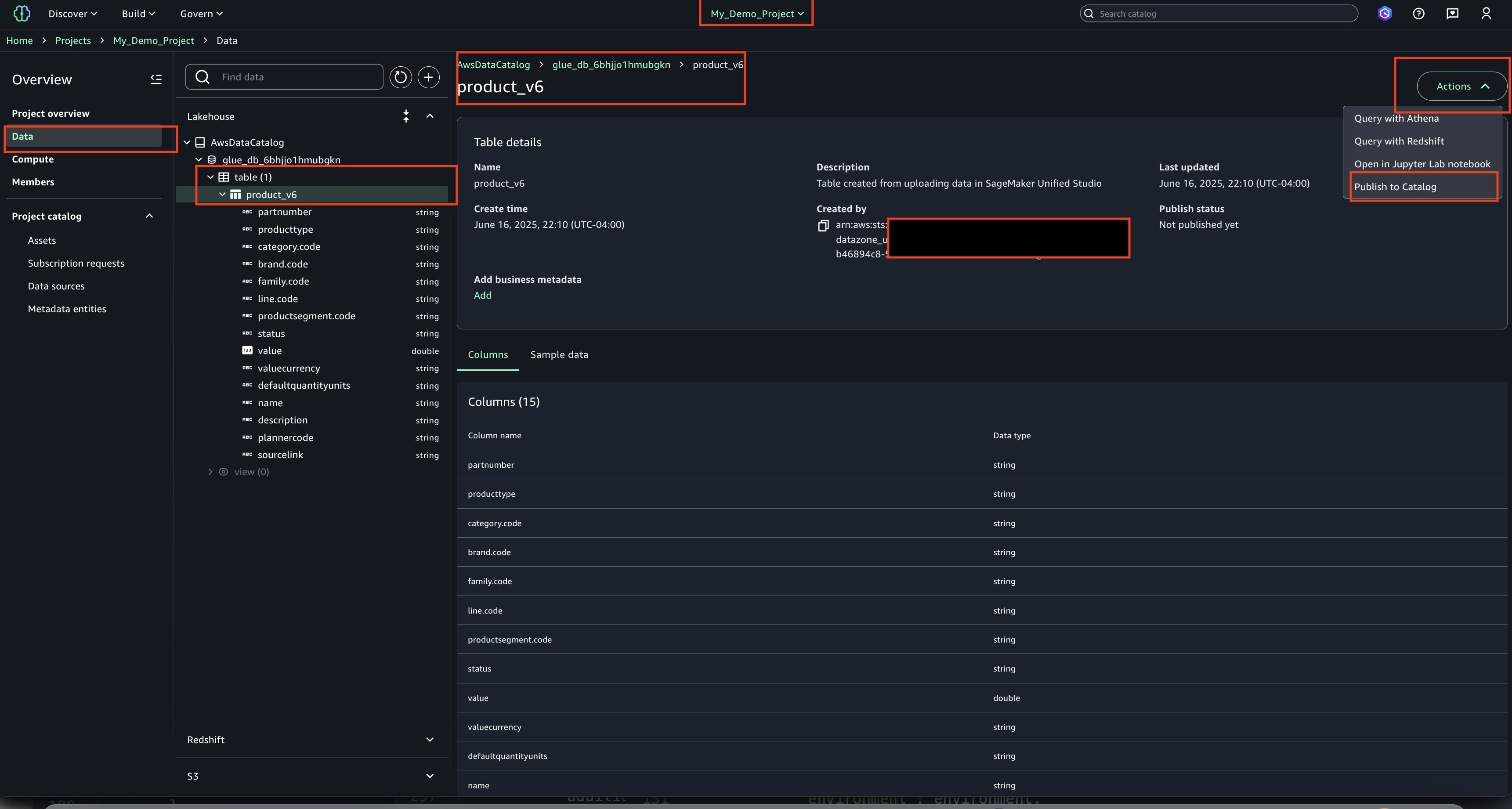
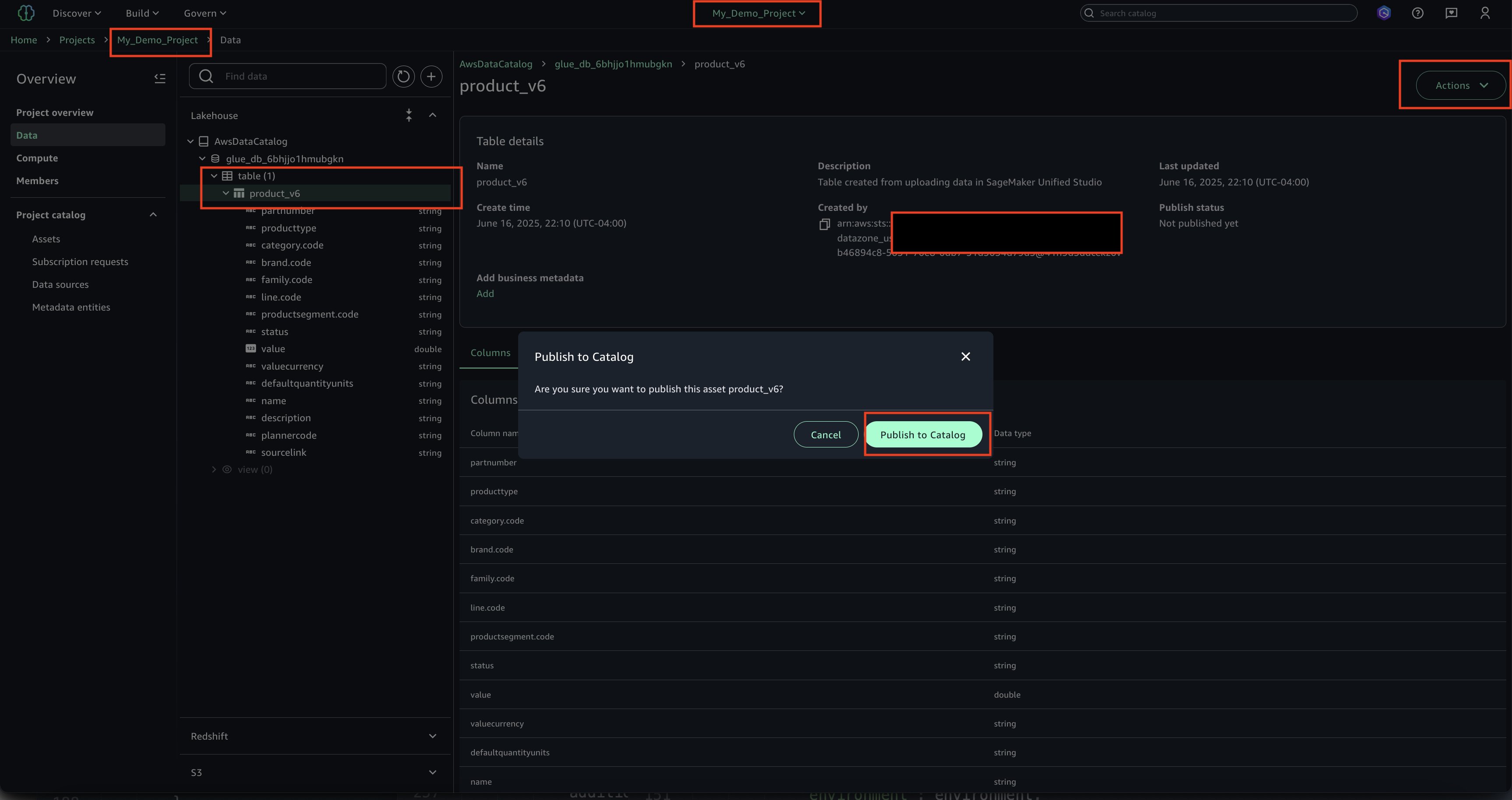
Data product owners can use the integration of Amazon DataZone integration with AWS Lake Formation to grant or revoke cross-domain access to data, streamlining the data sharing process while supporting security and compliance requirements.
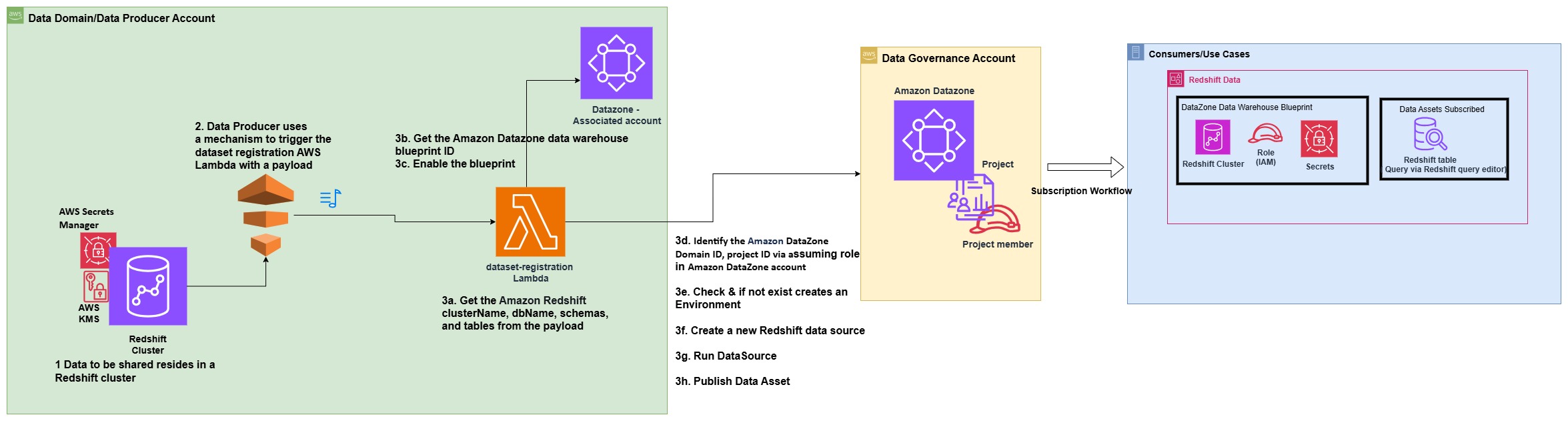
Managing cross-domain data pipeline dependencies
When implementing Covestro’s data mesh architecture on AWS, one of the most significant challenges was orchestrating data pipelines across multiple domains. The core question to address was “How can Data Domain A determine when a required dataset from Data Domain B has been refreshed and is ready for consumption?”.
In a data mesh architecture, domains maintain ownership of their data products while enabling consumption by other domains. This distributed model creates complex dependency chains where downstream pipelines must wait for upstream data products to complete processing before execution can begin.
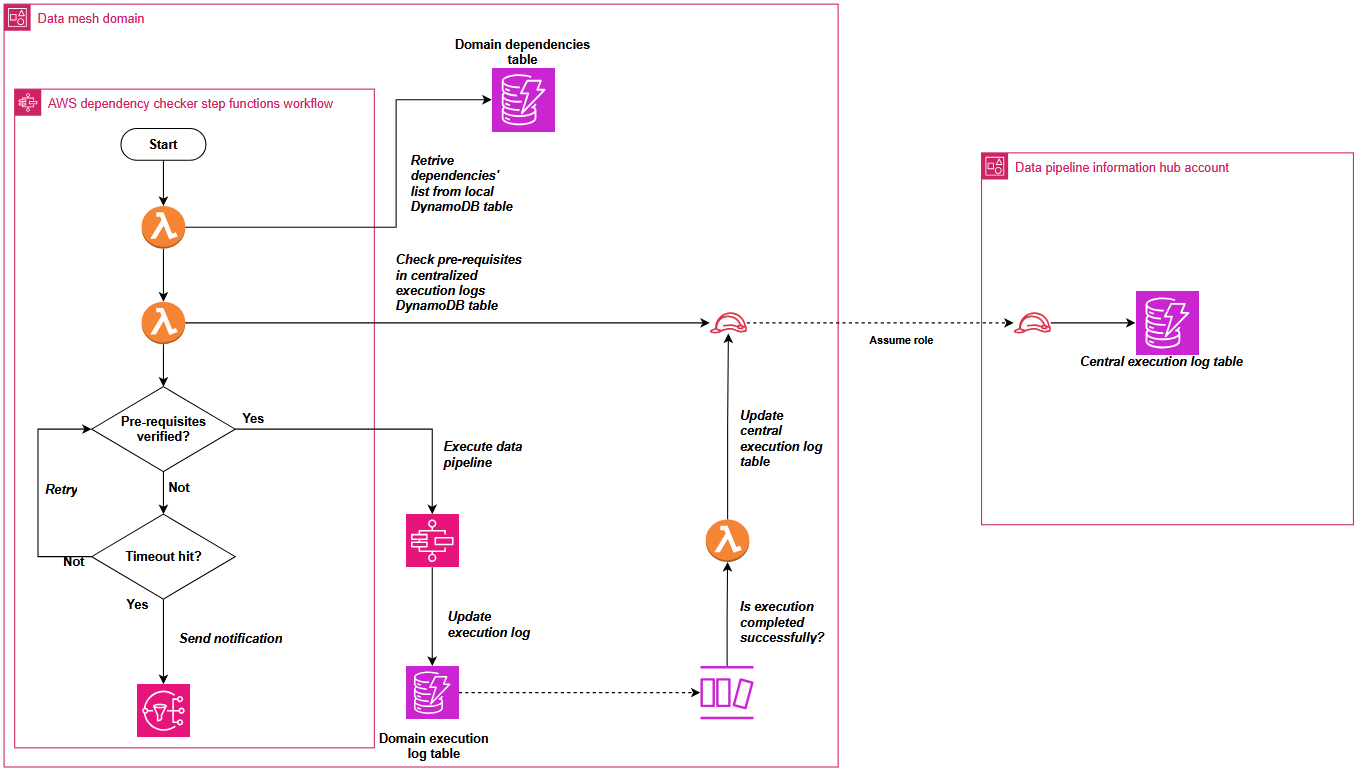
To address this cross-domain dependency coordination, Covestro extended the SDLF with a custom dependency checker component that operates through both shared and domain-specific elements.
The shared components consist of two centralized Amazon DynamoDB tables located in a hub AWS account: one collecting successful pipeline execution logs from the domains, and another aggregating pipeline dependencies across the entire data mesh.
These domains deploy local components such as a dependency-tracking Amazon DynamoDB table and an AWS Step Functions state machine. The state machine checks prerequisites using centralized execution logs and integrates seamlessly as the first step in every SDLF-deployed pipeline, without additional configuration. The following diagram shows the process described.
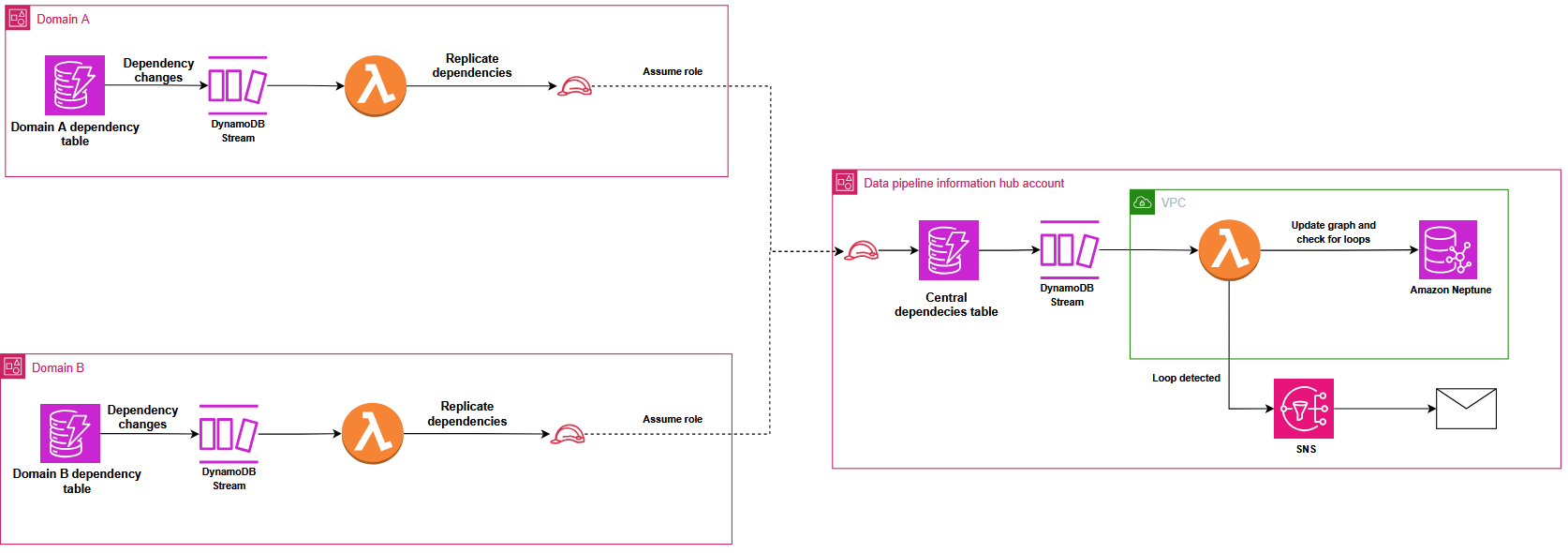
To prevent circular dependencies that could create locks in the distributed orchestration system, Covestro implemented a sophisticated detection mechanism using Amazon Neptune. DynamoDB Streams automatically replicate dependency changes from domain tables to the central registry, triggering an AWS Lambda function that uses the Gremlin graph traversal language (using pygremlin) to construct, update, and analyze a directed acyclic graph (DAG) of the pipeline relationships, with native Gremlin functions detecting circular dependencies and sending automated notifications, as illustrated in the following diagram. This process continuously updates the graph to reflect any new pipeline dependencies or changes across the data mesh.
Operational excellence through infrastructure as code
Infrastructure as code (IaC) practices using AWS CloudFormation and the AWS Cloud Development Kit (AWS CDK) significantly improve the operational efficiency of the data mesh implementation. The infrastructure code is version-controlled in GitHub repositories, providing complete traceability and collaboration capabilities for data engineering teams. This approach uses a dedicated deployment account that uses AWS CodePipeline to orchestrate consistent deployments across multiple data mesh domains.
The centralized deployment model supports that infrastructure changes follow a standardized continuous integration and deployment (CI/CD) process, where code commits trigger automated pipelines that validate, test, and deploy infrastructure components to the appropriate domain accounts. Each data domain resides in its own separate set of AWS accounts (dev, qa, prod), and the centralized deployment pipeline respects these boundaries while enabling controlled infrastructure provisioning.
IaC enables the data mesh to scale horizontally when onboarding new domains, supporting the maintenance of consistent security, governance, and operational standards across the entire environment. Covestro provisions new domains quickly using proven templates, accelerating time-to-value for business teams.
Business impact and technical outcomes
The implementation of the data mesh architecture using Amazon DataZone and SDLF has delivered significant measurable benefits across Covestro’s organization:
Accelerated data pipeline development
- 70% reduction in time-to-market for new data products through standardized blueprints
- Successful migration of more than 1,000 data pipelines to the new architecture
- Automated pipeline creation without manual coding requirements
- Standardized approach and sharing across domains
Enhanced data governance and quality
- Comprehensive business glossary implementation that supports consistent terminology
- Automated data quality checks integrated into pipelines
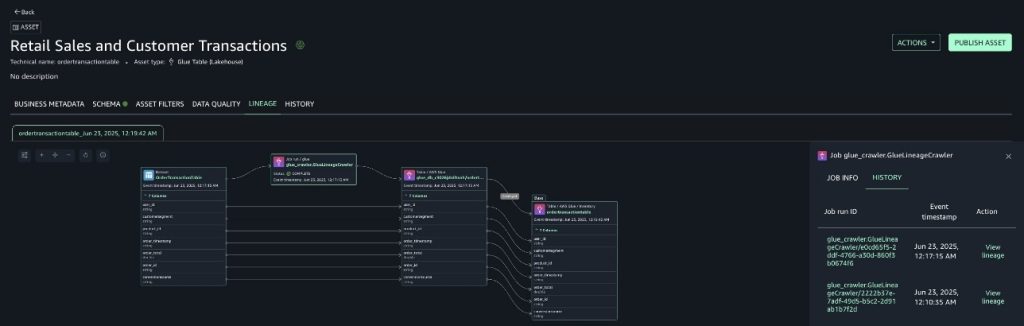
- End-to-end data lineage visibility across domains
- Standardized metadata management through Apache Iceberg integration
Improved data discovery and access
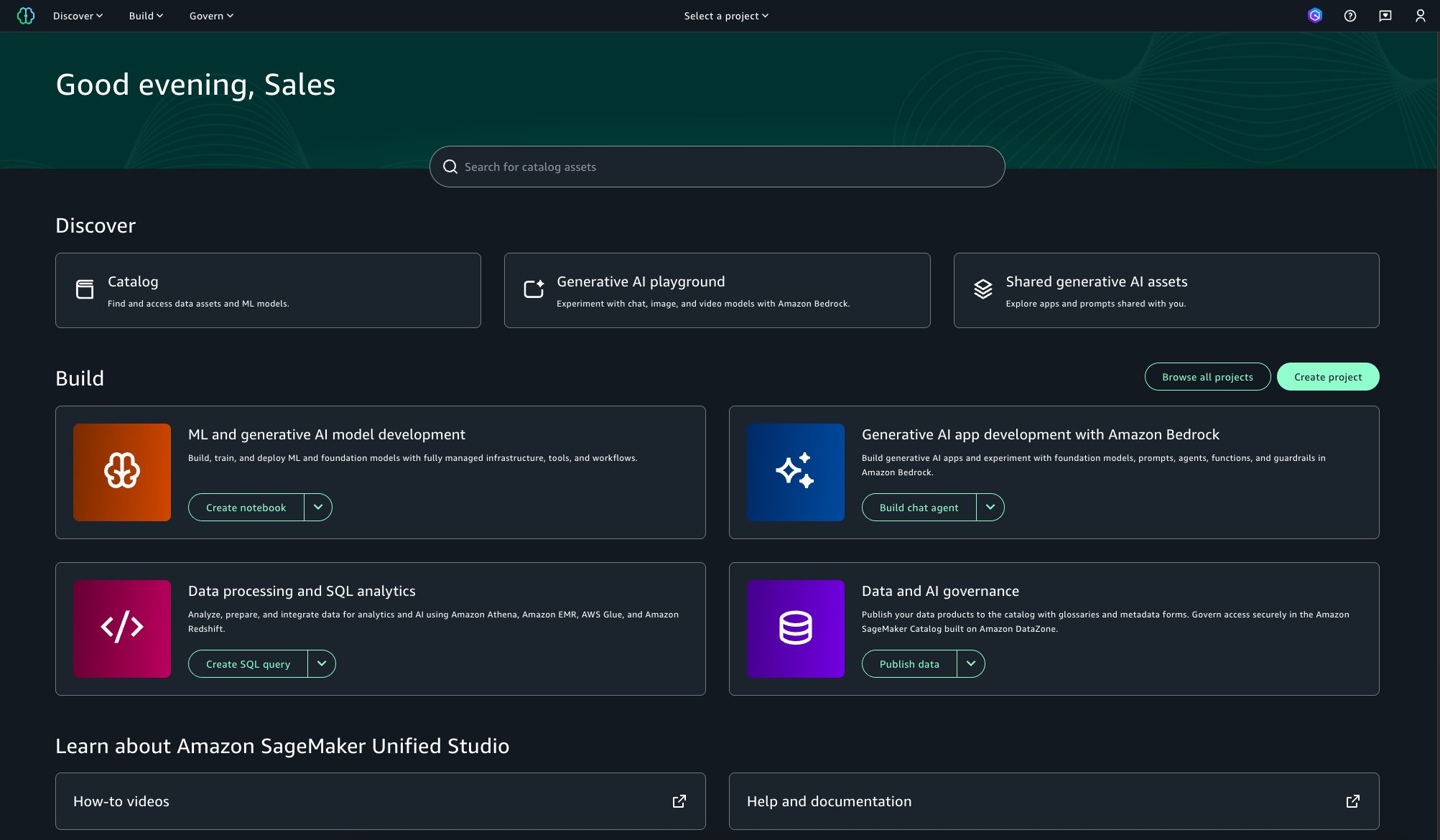
- Self-service data discovery portal through Amazon DataZone
- Streamlined cross-domain data sharing with appropriate security controls
- Reduced data duplication through improved visibility of existing assets
- Efficient management of cross-domain pipeline dependencies
Operational efficiency
- Decreased central data team bottlenecks through domain-oriented ownership
- Reduced operational overhead through automated deployment processes
- Improved resource utilization through elimination of redundant data processing
- Enhanced monitoring and troubleshooting capabilities
The new infrastructure has fundamentally transformed how Covestro’s teams interact with data, enabling business domains to operate autonomously while upholding enterprise-wide standards for quality and governance. This has created a more agile, efficient, and collaborative data ecosystem that supports both current needs and future growth.
What’s next
As Covestro’s data platform continues to evolve, the focus is now to support domain teams to effectively built data products for cross domain analytics. In parallel, Covestro is actively working to improve data transparency with data lineage in Amazon DataZone through OpenLineage to support more comprehensive data traceability across a diverse set of processing tools and formats.
Conclusion
In this post, we showed you how Covestro transformed its data architecture transitioning from a centralized data lake to a data mesh architecture, and how this foundation will prove invaluable in supporting their journey toward becoming a more data-driven organization. Their experience demonstrates how modern data architectures, when properly implemented with the right tools and frameworks, can transform business operations and unlock new opportunities for innovation.
This implementation serves as a blueprint for other enterprises looking to modernize their data infrastructure while maintaining security, governance, and scalability. It shows that with careful planning and the right technology choices, organizations can successfully transition from centralized to distributed data architectures without compromising on control or quality.
For more on Amazon DataZone, see the Getting Started guide. To learn about the SDLF, see Deploy and manage a serverless data lake on the AWS Cloud by using infrastructure as code.

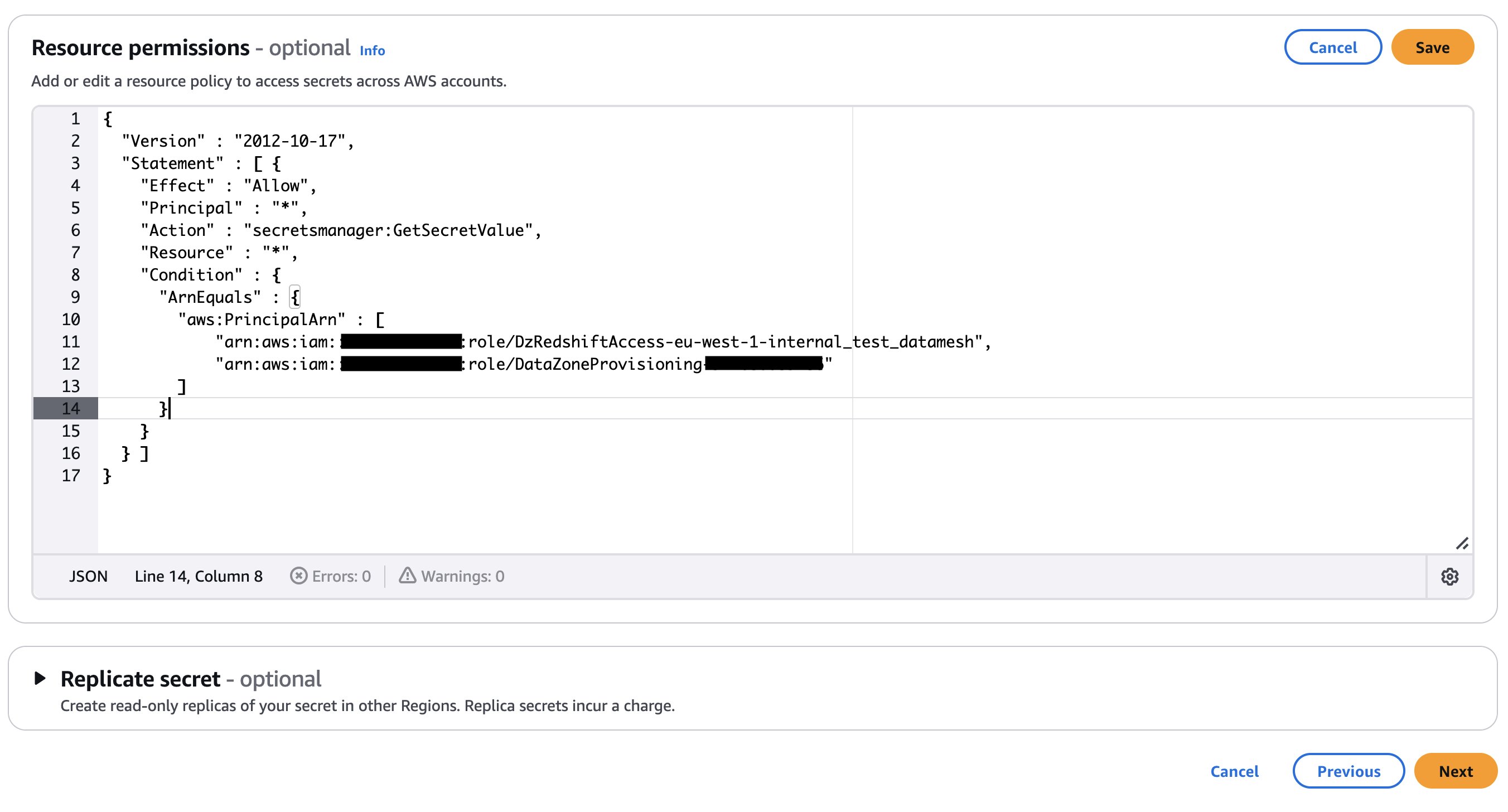 If your secret is encrypted with a custom KMS key, append the key policy with the following statement and add a tag to the key:
If your secret is encrypted with a custom KMS key, append the key policy with the following statement and add a tag to the key: 


 David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.

 Mohit Dawar is a Senior Software Engineer at Amazon Web Services (AWS) working on Amazon DataZone. Over the past 3 years, he has led efforts around the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on LinkedIn:
Mohit Dawar is a Senior Software Engineer at Amazon Web Services (AWS) working on Amazon DataZone. Over the past 3 years, he has led efforts around the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on LinkedIn:  Jose Romero is a Senior Solutions Architect for Startups at Amazon Web Services (AWS) based in Austin, TX, US. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on LinkedIn:
Jose Romero is a Senior Solutions Architect for Startups at Amazon Web Services (AWS) based in Austin, TX, US. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on LinkedIn: 


 Akira Mikami is a technical expert who played a central role in the FURUNO Data Platform (JuBuRaw) Construction Project at Furuno Electric Co., Ltd. Specializing in data platform construction and architecture, he led the implementation of cloud solutions utilizing AWS. He contributed to achieving efficient data management and strengthening team collaboration, leading the project to success.
Akira Mikami is a technical expert who played a central role in the FURUNO Data Platform (JuBuRaw) Construction Project at Furuno Electric Co., Ltd. Specializing in data platform construction and architecture, he led the implementation of cloud solutions utilizing AWS. He contributed to achieving efficient data management and strengthening team collaboration, leading the project to success. Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at Amazon Web Services (AWS) in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including data mesh, data lakehouse, and generative AI, so customers can build scalable and innovative solutions on Amazon Web Services (AWS).
Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at Amazon Web Services (AWS) in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including data mesh, data lakehouse, and generative AI, so customers can build scalable and innovative solutions on Amazon Web Services (AWS). Mitsuhiko Nishida is an Enterprise Solutions Architecture Automotive & Manufacturing Group Solutions Architect at Amazon Web Services (AWS) in Japan. He serves as a field Solutions Architect for manufacturing customers, helping them solve their business challenges. With expertise in generative AI and manufacturing IT, he guides the design and implementation of innovative solutions leveraging cutting-edge technologies. He supports manufacturing customers in building efficient architecture powered by AWS services to accelerate their cloud transformation journey and contribute to their digital transformation initiatives.
Mitsuhiko Nishida is an Enterprise Solutions Architecture Automotive & Manufacturing Group Solutions Architect at Amazon Web Services (AWS) in Japan. He serves as a field Solutions Architect for manufacturing customers, helping them solve their business challenges. With expertise in generative AI and manufacturing IT, he guides the design and implementation of innovative solutions leveraging cutting-edge technologies. He supports manufacturing customers in building efficient architecture powered by AWS services to accelerate their cloud transformation journey and contribute to their digital transformation initiatives.










 Jose Romero is a Senior Solutions Architect for Startups at AWS, based in Austin, Texas. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on
Jose Romero is a Senior Solutions Architect for Startups at AWS, based in Austin, Texas. He is passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on  Priya Tiruthani is a Senior Technical Product Manager with Amazon SageMaker Catalog (Amazon DataZone) at AWS. She focuses on building products and their capabilities in data analytics and governance. She is passionate about building innovative products to address and simplify customers’ challenges in their end-to-end data journey. Outside of work, she enjoys being outdoors to hike and capture nature’s beauty. Connect with her on
Priya Tiruthani is a Senior Technical Product Manager with Amazon SageMaker Catalog (Amazon DataZone) at AWS. She focuses on building products and their capabilities in data analytics and governance. She is passionate about building innovative products to address and simplify customers’ challenges in their end-to-end data journey. Outside of work, she enjoys being outdoors to hike and capture nature’s beauty. Connect with her on 
































































 Vincent Gromakowski is a Principal Analytics Solutions Architect at AWS where he enjoys solving customers’ data challenges. He uses his strong expertise on analytics, distributed systems and resource orchestration platform to be a trusted technical advisor for AWS customers.
Vincent Gromakowski is a Principal Analytics Solutions Architect at AWS where he enjoys solving customers’ data challenges. He uses his strong expertise on analytics, distributed systems and resource orchestration platform to be a trusted technical advisor for AWS customers. Francisco Morillo is a Sr. Streaming Solutions Architect at AWS, specializing in real-time analytics architectures. With over five years in the streaming data space, Francisco has worked as a data analyst for startups and as a big data engineer for consultancies, building streaming data pipelines. He has deep expertise in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Francisco collaborates closely with AWS customers to build scalable streaming data solutions and advanced streaming data lakes, ensuring seamless data processing and real-time insights.
Francisco Morillo is a Sr. Streaming Solutions Architect at AWS, specializing in real-time analytics architectures. With over five years in the streaming data space, Francisco has worked as a data analyst for startups and as a big data engineer for consultancies, building streaming data pipelines. He has deep expertise in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Francisco collaborates closely with AWS customers to build scalable streaming data solutions and advanced streaming data lakes, ensuring seamless data processing and real-time insights. Jan Michael Go Tan is a Principal Solutions Architect for Amazon Web Services. He helps customers design scalable and innovative solutions with the AWS Cloud.
Jan Michael Go Tan is a Principal Solutions Architect for Amazon Web Services. He helps customers design scalable and innovative solutions with the AWS Cloud. Sofia Zilberman is a Sr. Analytics Specialist Solutions Architect at Amazon Web Services. She has a track record of 15 years of creating large-scale, distributed processing systems. She remains passionate about big data technologies and architecture trends, and is constantly on the lookout for functional and technological innovations.
Sofia Zilberman is a Sr. Analytics Specialist Solutions Architect at Amazon Web Services. She has a track record of 15 years of creating large-scale, distributed processing systems. She remains passionate about big data technologies and architecture trends, and is constantly on the lookout for functional and technological innovations.











 Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum.
Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum. Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports.
Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports. Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.
Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.































 Somdeb Bhattacharjee is a Senior Solutions Architect specializing on data and analytics. He is part of the global Healthcare and Life sciences industry at AWS, helping his customers modernize their data platform solutions to achieve their business outcomes.
Somdeb Bhattacharjee is a Senior Solutions Architect specializing on data and analytics. He is part of the global Healthcare and Life sciences industry at AWS, helping his customers modernize their data platform solutions to achieve their business outcomes. Sam Yates is a Senior Solutions Architect in the Healthcare and Life Sciences business unit at AWS. He has spent most of the past two decades helping life sciences companies apply technology in pursuit of their missions to help patients. Sam holds BS and MS degrees in Computer Science.
Sam Yates is a Senior Solutions Architect in the Healthcare and Life Sciences business unit at AWS. He has spent most of the past two decades helping life sciences companies apply technology in pursuit of their missions to help patients. Sam holds BS and MS degrees in Computer Science.














 Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions.
Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions. Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.
Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.



 Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ.
Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ. Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.
Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML. Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.






















































 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon DataZone team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon DataZone team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on  Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters. Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon DataZone engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon DataZone engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.


 Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data analytics, and data governance at AWS. He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure AWS solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. An active contributor to the AWS community, Dhrubajyoti authors AWS Prescriptive Guidance publications, blog posts, and open source artifacts, sharing his insights and best practices with the broader community. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data analytics, and data governance at AWS. He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure AWS solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. An active contributor to the AWS community, Dhrubajyoti authors AWS Prescriptive Guidance publications, blog posts, and open source artifacts, sharing his insights and best practices with the broader community. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains. Ravi Kumar is a Data Architect and Analytics expert at AWS, where he finds immense fulfilment in working with data. His days are dedicated to designing and analyzing complex data systems, uncovering valuable insights that drive business decisions. Outside of work, he unwinds by listening to music and watching movies, activities that allow him to recharge after a long day of data wrangling.
Ravi Kumar is a Data Architect and Analytics expert at AWS, where he finds immense fulfilment in working with data. His days are dedicated to designing and analyzing complex data systems, uncovering valuable insights that drive business decisions. Outside of work, he unwinds by listening to music and watching movies, activities that allow him to recharge after a long day of data wrangling. Martin Mikoleizig studied mechanical engineering and production technology at the RWTH Aachen University before starting to work in Dr. h.c. Ing. F. Porsche AG 2015 as a production planner for the engine assembly. Over several years as a Project Manager on Testing Technology for new engine models, he also introduced several innovations like human-machine collaborations and intelligent assistance systems. Starting in 2017, he was responsible for the shop floor IT team of the module lines in Zuffenhausen before he became responsible for the planning of the E-Drive assembly at Porsche. Additionally, he was responsible for the Digitalisation Strategy of the Production Ressort at Porsche. In October 2022, he was assigned to Volkswagen Autoeuropa in Portugal in the role of a Digital Transformation Manager for the plant, driving the digital transformation towards a data-driven factory.
Martin Mikoleizig studied mechanical engineering and production technology at the RWTH Aachen University before starting to work in Dr. h.c. Ing. F. Porsche AG 2015 as a production planner for the engine assembly. Over several years as a Project Manager on Testing Technology for new engine models, he also introduced several innovations like human-machine collaborations and intelligent assistance systems. Starting in 2017, he was responsible for the shop floor IT team of the module lines in Zuffenhausen before he became responsible for the planning of the E-Drive assembly at Porsche. Additionally, he was responsible for the Digitalisation Strategy of the Production Ressort at Porsche. In October 2022, he was assigned to Volkswagen Autoeuropa in Portugal in the role of a Digital Transformation Manager for the plant, driving the digital transformation towards a data-driven factory. Weizhou Sun is a Lead Architect at AWS, specializing in digital manufacturing solutions and IoT. With extensive experience in Europe, she has enhanced operational efficiencies, reducing latency and increasing throughput. Weizhou’s expertise includes industrial computer vision, predictive maintenance, and predictive quality, consistently delivering top performance and client satisfaction. A recognized thought leader in IoT and remote driving, she has contributed to business growth through innovations and open source work. Committed to knowledge sharing, Weizhou mentors colleagues and contributes to practice development. Known for her problem-solving skills and customer focus, she delivers solutions that exceed expectations. In her free time, Weizhou explores new technologies and fosters a collaborative culture.
Weizhou Sun is a Lead Architect at AWS, specializing in digital manufacturing solutions and IoT. With extensive experience in Europe, she has enhanced operational efficiencies, reducing latency and increasing throughput. Weizhou’s expertise includes industrial computer vision, predictive maintenance, and predictive quality, consistently delivering top performance and client satisfaction. A recognized thought leader in IoT and remote driving, she has contributed to business growth through innovations and open source work. Committed to knowledge sharing, Weizhou mentors colleagues and contributes to practice development. Known for her problem-solving skills and customer focus, she delivers solutions that exceed expectations. In her free time, Weizhou explores new technologies and fosters a collaborative culture. Ajinkya Patil is a Senior Security Architect with AWS Professional Services, specializing in security consulting for customers in the automotive industry. Since joining AWS in 2019, he has played a key role in helping automotive companies design and implement robust security solutions on AWS. Ajinkya is an active contributor to the AWS community, having presented at AWS re:Inforce and authored articles for the AWS Security Blog and AWS Prescriptive Guidance. Outside of his professional pursuits, Ajinkya is passionate about travel and photography, often capturing the diverse landscapes he encounters on his journeys.
Ajinkya Patil is a Senior Security Architect with AWS Professional Services, specializing in security consulting for customers in the automotive industry. Since joining AWS in 2019, he has played a key role in helping automotive companies design and implement robust security solutions on AWS. Ajinkya is an active contributor to the AWS community, having presented at AWS re:Inforce and authored articles for the AWS Security Blog and AWS Prescriptive Guidance. Outside of his professional pursuits, Ajinkya is passionate about travel and photography, often capturing the diverse landscapes he encounters on his journeys. Adjoa Taylor has over 20 years of experience in industrial manufacturing, providing industry and technology consulting services, digital transformation, and solution delivery. Currently, Adjoa leads Product Centric Digital Transformation, enabling customers in solving complex manufacturing problems using smart factory and industry-leading transformation mechanisms. Most recently, she drives value with AI/ML and generative AI use cases for the plant floor. Adjoa is an experienced leader, having spent over 20 years of her career delivering projects in countries throughout North America, Latin America, Europe, and Asia. Adjoa brings deep experience across multiple business segments with a focus on business outcome-driven solutions. Adjoa is passionate about helping customers solve problems while realizing the art of the possible through implementing value-based solutions.
Adjoa Taylor has over 20 years of experience in industrial manufacturing, providing industry and technology consulting services, digital transformation, and solution delivery. Currently, Adjoa leads Product Centric Digital Transformation, enabling customers in solving complex manufacturing problems using smart factory and industry-leading transformation mechanisms. Most recently, she drives value with AI/ML and generative AI use cases for the plant floor. Adjoa is an experienced leader, having spent over 20 years of her career delivering projects in countries throughout North America, Latin America, Europe, and Asia. Adjoa brings deep experience across multiple business segments with a focus on business outcome-driven solutions. Adjoa is passionate about helping customers solve problems while realizing the art of the possible through implementing value-based solutions.