Post Syndicated from Jamie Herre original https://blog.cloudflare.com/cloudflare-incident-on-november-14-2024-resulting-in-lost-logs
On November 14, 2024, Cloudflare experienced an incident which impacted the majority of customers using Cloudflare Logs. During the roughly 3.5 hours that these services were impacted, about 55% of the logs we normally send to customers were not sent and were lost. We’re very sorry this happened, and we are working to ensure that a similar issue doesn’t happen again.
This blog post explains what happened and what we’re doing to prevent recurrences. Also, the systems involved and the particular class of failure we experienced will hopefully be of interest to engineering teams beyond those specifically using these products.
Failures within systems at scale are inevitable, and it’s essential that subsystems protect themselves from failures in other parts of the larger system to prevent cascades. In this case, a misconfiguration in one part of the system caused a cascading overload in another part of the system, which was itself misconfigured. Had it been properly configured, it could have prevented the loss of logs.
Cloudflare’s network is a globally distributed system enabling and supporting a wide variety of services. Every part of this system generates event logs which contain detailed metadata about what’s happening with our systems around the world. For example, an event log is generated for every request to Cloudflare’s CDN. Cloudflare Logs makes these event logs available to customers, who use them in a number of ways, including compliance, observability, and accounting.
On a typical day, Cloudflare sends about 4.5 trillion individual event logs to customers. Although this represents less than 10% of the over 50 trillion total customer event logs processed, it presents unique challenges of scale when building a reliable and fault-tolerant system.
Cloudflare’s network is composed of tens of thousands of individual servers, network hardware components, and specialized software programs located in over 330 cities around the world. Although Cloudflare’s Edge Log Delivery product will send customers their event logs directly from each server, most customers opt not to do this because doing so will create significant complication and cost at the receiving end.
By analogy, imagine the postal service ringing your doorbell once for each letter instead of once for each packet of letters. With thousands or millions of letters each second, the number of separate transactions that would entail becomes prohibitive.
Fortunately, we also offer Logpush, which collects and pushes logs to customers in more predictable file sizes and which scales automatically with usage. In order to provide this feature several services work together to collect and push the logs, as illustrated in the diagram below:

Logfwdr is an internal service written in Golang that accepts event logs from internal services running across Cloudflare’s global network and forwards them in batches to a service called Logreceiver. Logfwdr handles many different types of event logs, and one of its responsibilities is to determine which event logs should be forwarded and where they should be sent based on the type of event log, which customers it represents, and associated rules about where it should be processed. Configuration is provided to Logfwdr to enable it to make these determinations.
Logreceiver (also written in Golang) accepts the batches of logs from across Cloudflare’s global network and further sorts them depending on the type of event and its purpose. For Cloudflare Logs, Logreceiver demultiplexes the batches into per-customer batches and forwards them to be buffered by Buftee. Currently, Logreceiver is handling about 45 PB (uncompressed) of customer event logs each day.
It’s common for data pipelines to include a buffer. Producers and consumers of the data might be operating at different cadences, and parts of the pipeline will experience variances in how quickly they can process information. Using a buffer makes it easier to manage these situations, and helps to prevent data loss if downstream consumers are broken. It’s also convenient to have a buffer that supports multiple downstream consumers with different cadences (like the pipe fitting function of a tee.)
At Cloudflare, we use an internal system called Buftee (written in Golang) to support this combined function. Buftee is a highly distributed system which supports a large number of named “buffers”. It supports operating on named “prefixes” (collections of buffers) as well as multiple representations/resolutions of the same time-indexed dataset. Using Buftee makes it possible for Cloudflare to handle extremely high throughput very efficiently.
For Cloudflare Logs, Buftee provides buffers for each Logpush job, containing 100% of the logs generated by the zone or account referenced by each job. This means that failure to process one customer’s job will not affect progress on another customer’s job. Handling buffers in this way avoids “head of line” blocking and also enables us to encrypt and delete each customer’s data separately if needed.
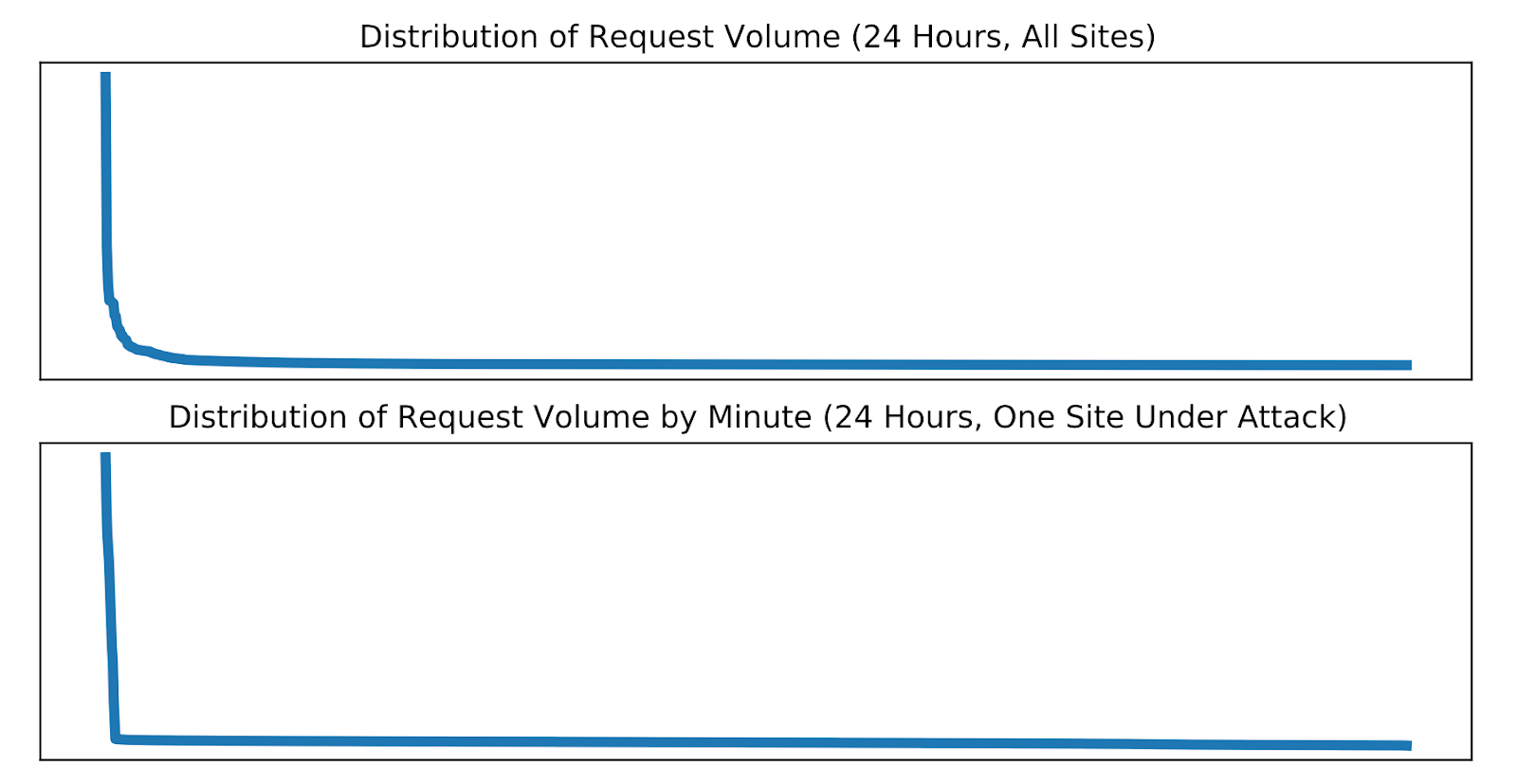
Buftee typically handles over 1 million buffers globally. The following is a snapshot of the number of buffers managed by Buftee servers in the period just prior to the incident.

Logpush is a Golang service which reads logs from Buftee buffers and pushes the results in batches to various destinations configured by customers. A batch could end up, for example, as a file in R2. Each job has a unique configuration, and only jobs that are active and configured will be pushed. Currently, we push over 600 million such batches each day.
On November 14, 2024, we made a change to support an additional dataset for Logpush. This required adding a new configuration to be provided to Logfwdr in order for it to know which customers’ logs to forward for this new stream. Every few minutes, a separate system re-generates the configuration used by Logfwdr to decide which logs need to be forwarded. A bug in this system resulted in a blank configuration being provided to Logfwdr.
This bug essentially informed Logfwdr that no customers had logs configured to be pushed. The team quickly noticed the mistake and reverted the change in under five minutes.
Unfortunately, this first mistake triggered a second, latent bug in Logfwdr itself. A failsafe introduced in the early days of this feature, when traffic was much lower, was configured to “fail open”. This failsafe was designed to protect against a situation when this specific Logfwdr configuration was unavailable (as in this case) by transmitting events for all customers instead of just those who had configured a Logpush job. This was intended to prevent the loss of logs at the expense of sending more logs than strictly necessary when individual hosts were prevented from getting the configuration due to intermittent networking errors, for example.
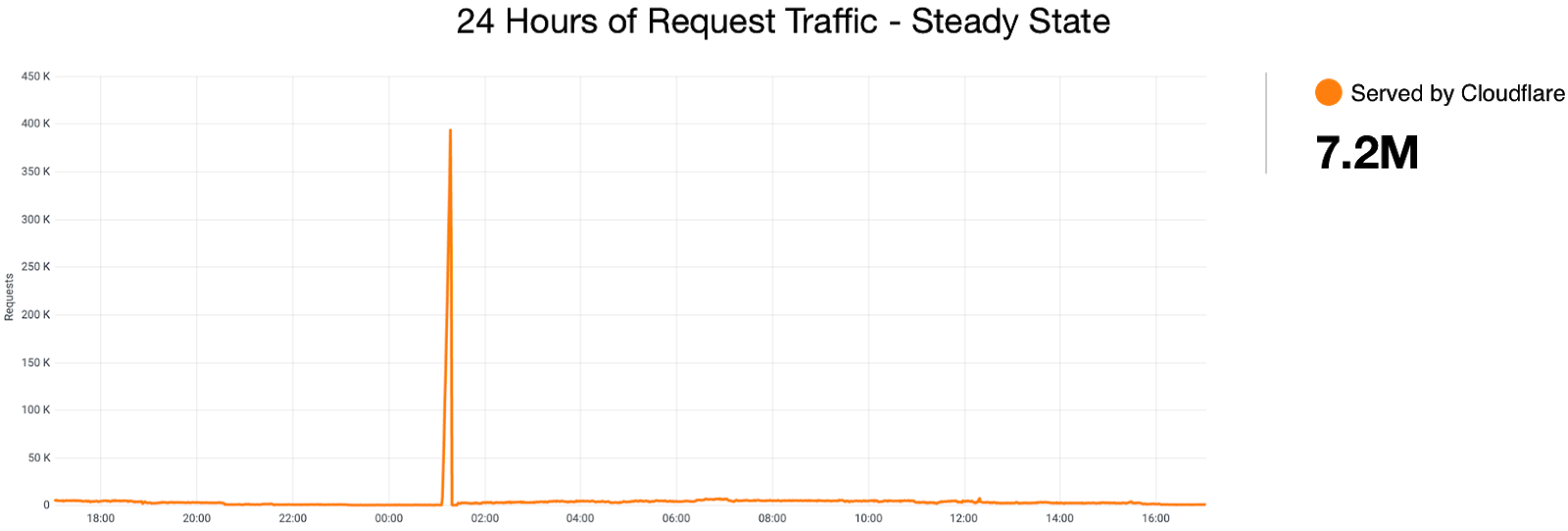
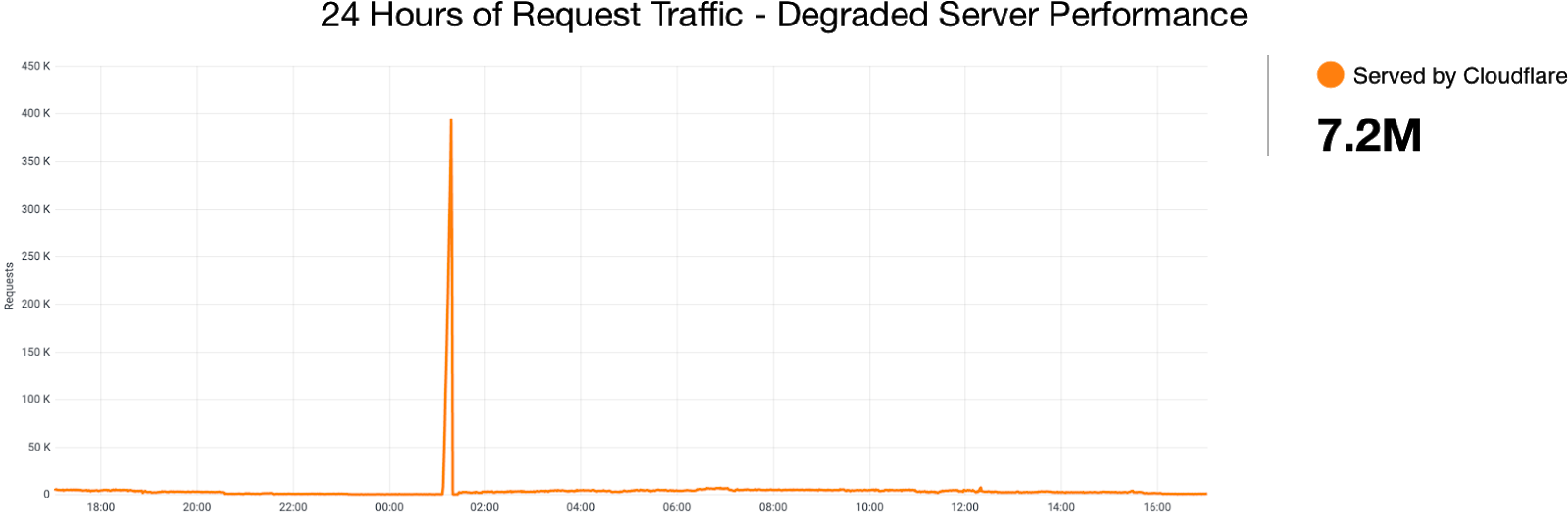
When this failsafe was first introduced, the potential list of customers was smaller than it is today. This small window of less than five minutes resulted in a massive spike in the number of customers whose logs were sent by Logfwdr.
Even given this massive overload, our systems would have continued to send logs if not for one additional problem. Remember that Buftee creates a separate buffer for each customer with their logs to be pushed. When Logfwdr began to send event logs for all customers, Buftee began to create buffers for each one as those logs arrived, and each buffer requires resources as well as the bookkeeping to maintain them. This massive increase, resulting in roughly 40 times more buffers, is not something we’ve provisioned Buftee clusters to handle. In the lead-up to impact, Buftee was managing 40 million buffers globally, as shown in the figure below.

A short temporary misconfiguration lasting just five minutes created a massive overload that took us several hours to fix and recover from. Because our backstops were not properly configured, the underlying systems became so overloaded that we could not interact with them normally. A full reset and restart was required.
The bug in the Logfwdr configuration system was easy to fix, but it’s the type of bug that was likely to happen at some point. We had planned for it by designing the original “fail open” behavior. However, we neglected to regularly test that the broader system was capable of handling a fail open event.
The bigger failure was that Buftee became unresponsive. Buftee’s purpose is to be a safeguard against bugs like this one. A huge increase in the number of buffers is a failure mode that we had predicted, and had put mechanisms in Buftee to prevent this failure from cascading. Our failure in this case was that we had not configured these mechanisms. Had they been configured correctly, Buftee would not have been overwhelmed.
It’s like having a seatbelt in a car, yet not fastening it. The seatbelt is there to protect you in case of an accident but if you don’t actually buckle it up, it’s not going to do its job when you need it. Similarly, while we had the safeguard of Buftee in place, we hadn’t ‘buckled it up’ by configuring the necessary settings. We’re very sorry this happened and are taking steps to prevent a recurrence as described below.
We’re creating alerts to ensure that these particular misconfigurations will be impossible to miss, and we are also addressing the specific bug and the associated tests that triggered this incident.
Just as importantly, we accept that mistakes and misconfigurations are inevitable. All our systems at Cloudflare need to respond to these predictably and gracefully. Currently, we conduct regular “cut tests” to ensure that these systems will cope with the loss of a datacenter or a network failure. In the future, we’ll also conduct regular “overload tests” to simulate the kind of cascade which happened in this incident to ensure that our production systems will handle them gracefully.
Logpush is a robust and flexible platform for customers who need to integrate their own logging and monitoring systems with Cloudflare. Different Logpush jobs can be deployed to support multiple destinations or, with filtering, multiple subsets of logs.