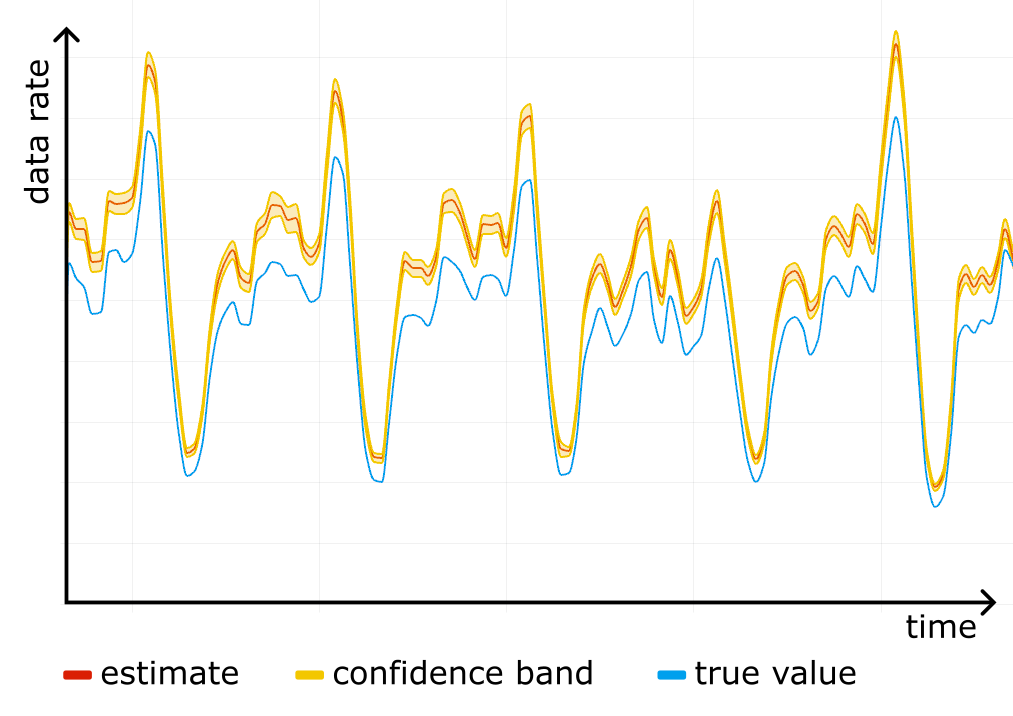
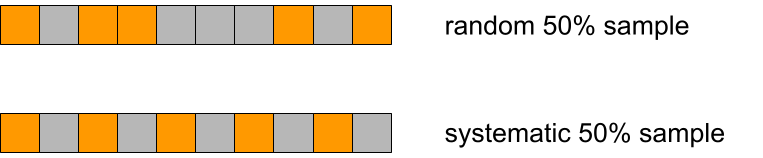Ten years ago, we launched our bug bounty program in partnership with HackerOne. Beyond a security initiative, it represented an open invitation to collaborative development.
As pioneers in Southeast Asia, we began the program with 23 initial researchers, and it has since evolved into a global community of security researchers.
The strategic structure and scope of our Bug Bounty Program, combined with our continuous innovation and experimentation, have successfully captured the attention of the global security research community. Over the past decade, we have partnered with more than 850 active security researchers from HackerOne’s community of over 2 million cybersecurity professionals worldwide. These dedicated researchers work alongside us across borders and time zones, forming a collaborative defense network that helps protect over 187 million users throughout Southeast Asia. Their ongoing participation demonstrates both the maturity of our program and the trust we’ve built within the security research community.
This milestone reflects the strength of shared purpose and our sustained partnership with the HackerOne platform. It demonstrates the value of human connection and the collective understanding that security is stronger through collaboration. Here’s to a decade of partnership and to many more years of building a safer future, one collaboration at a time!
Figure 1. Ten years of achievements with our HackerOne partnership.
Evolution and growth: Adapting to a dynamic threat landscape
Over the past ten years, our program has consistently adapted to the dynamic threat landscape and integrated invaluable feedback from our research community. We have grown from a private initiative to a program that consistently ranks among the top 20 worldwide and among the top 3 in Asia on HackerOne. Key milestones from our journey include:
Expanding our horizons: Our scope significantly broadened in 2023-2024, continuously adding new assets and prominently including financial services in Indonesia and AI systems. This expansion provides researchers with more avenues to contribute to Grab’s security.
Focused mobile security: We introduced a dedicated bounty table for mobile-specific issues, recognizing the unique challenges of mobile security.
Incentivizing excellence: We regularly experiment with campaigns of various types and targets, diversifying our reward methods to include both financial rewards and recognition.
Evolving vulnerability focus: We’ve observed a significant shift in the types of vulnerabilities reported over the decade, moving from foundational issues in early years to more sophisticated and emerging categories recently.
Figure 2. The journey of our bug bounty program.
The global stage: Connecting with the best
Our program’s success is deeply rooted in its vibrant global community, which we actively foster through continuous engagement. Our strategy extends beyond the platform to major live hacking events, including the ThreatCon Live Hacking Event 2023in Nepal and DEFCON 32’s Live Recon Village 2024 in Las Vegas. These initiatives have been instrumental in connecting us with a diverse pool of new talent and strengthening relationships with researchers across different continents. By meeting hackers where they are, we’ve not only brought new expertise into our ecosystem but also demonstrated our commitment to being an accessible and collaborative partner on a global scale.
The high participation and quality submissions from these events demonstrate the effectiveness of this approach. They’ve expanded our global security testing coverage and strengthened our standing within the worldwide cybersecurity community. Through ongoing interactions and submitted reports, we continue to see that security is a collaborative effort with no borders.
Exclusive anniversary celebrations: Global club campaigns
To commemorate our 10th anniversary, we launched three exclusive, invite-only campaigns with HackerOne’s regional clubs in Germany, Morocco, and India. These campaigns served as cultural exchanges, bringing fresh perspectives from outside our core Southeast Asian consumer markets. By engaging with these clubs, we expanded our researcher community and connected with security experts who understand different threat landscapes and methodologies, bringing outside perspectives to our systems.
In August, we also ran a broader anniversary campaign that drew significant participation from the researcher community, resulting in 461 submissions. xchopath was awarded the Best Hacker Bonus for their contributions during this campaign.
These campaigns expanded our global security testing coverage and strengthened relationships with international researcher communities. Beyond vulnerability reports, they functioned as knowledge-sharing initiatives. We connected directly with researchers to learn from their experience and feedback, creating a continuous loop of improvement. This international collaboration also informed our global expansion security strategy by providing insights into how different regions approach digital payments and authentication.
The anniversary campaigns allowed us to validate our security frameworks against diverse regulatory environments and advanced testing methodologies from established security markets, reinforcing our commitment to maintaining robust security standards.
Voices from our community
Behind every vulnerability report is a researcher who chose to help make Grab safer. Their perspectives reveal the human side of our security evolution. These individuals are not just cybersecurity experts; they are partners in our mission to protect millions of users and ensure a safe digital environment. Here are a few testimonies from participants in our past campaigns:
“The triage was very fast despite the time difference, which I really appreciated. The triaging experience was better than other programs. The huge scope and business portal with different user roles made it especially interesting to explore.” – ArtSec[H1 Germany club campaign participant]
“I liked that different countries have different features—this gives me more attack surface to explore. Response time was great, triage was very fast, and I appreciated Grab’s effort in providing fast responses. The scope was huge with a lot of wildcards for reconnaissance.” – Sicksec[H1 Morocco club campaign participant]
“More than 20 bugs were reported, and was particularly happy that bounties were being paid upon triage. The Germany team spent a lot of time on the educational part, especially for newcomers. Communication overall was very good, and the immediate response even outside working hours was really cool. SSO and authentication is my expertise and I liked that aspect of exploring the platform.” – Lauritz[H1 Germany club campaign participant]
The road ahead: Our commitment to a secure future
With a strong community of security researchers across countries and a decade of collaboration, we’ve built meaningful partnerships. Every vulnerability report represents trust, and every discovery reflects dedication to our shared mission. The program demonstrates our choice to build together rather than work in isolation, to protect rather than exploit, and to collaborate rather than compete.
While we celebrate our external community, the success of our program relies equally on our dedicated internal teams. Our cybersecurity teams form the operational foundation of this initiative. Their consistent responsiveness and researcher-focused approach have enabled vulnerability reporting to evolve into a genuine partnership, maintaining researcher trust and keeping Grab secure.
The next ten years will bring challenges we can’t yet imagine, from emerging threats in artificial intelligence to novel cryptographic approaches in a quantum-powered world. We will face them together as a community that spans cultures, time zones, and expertise.
Together, we’ll continue securing Southeast Asia’s digital future, one partnership, one discovery, one shared achievement at a time.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility, and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people every day to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
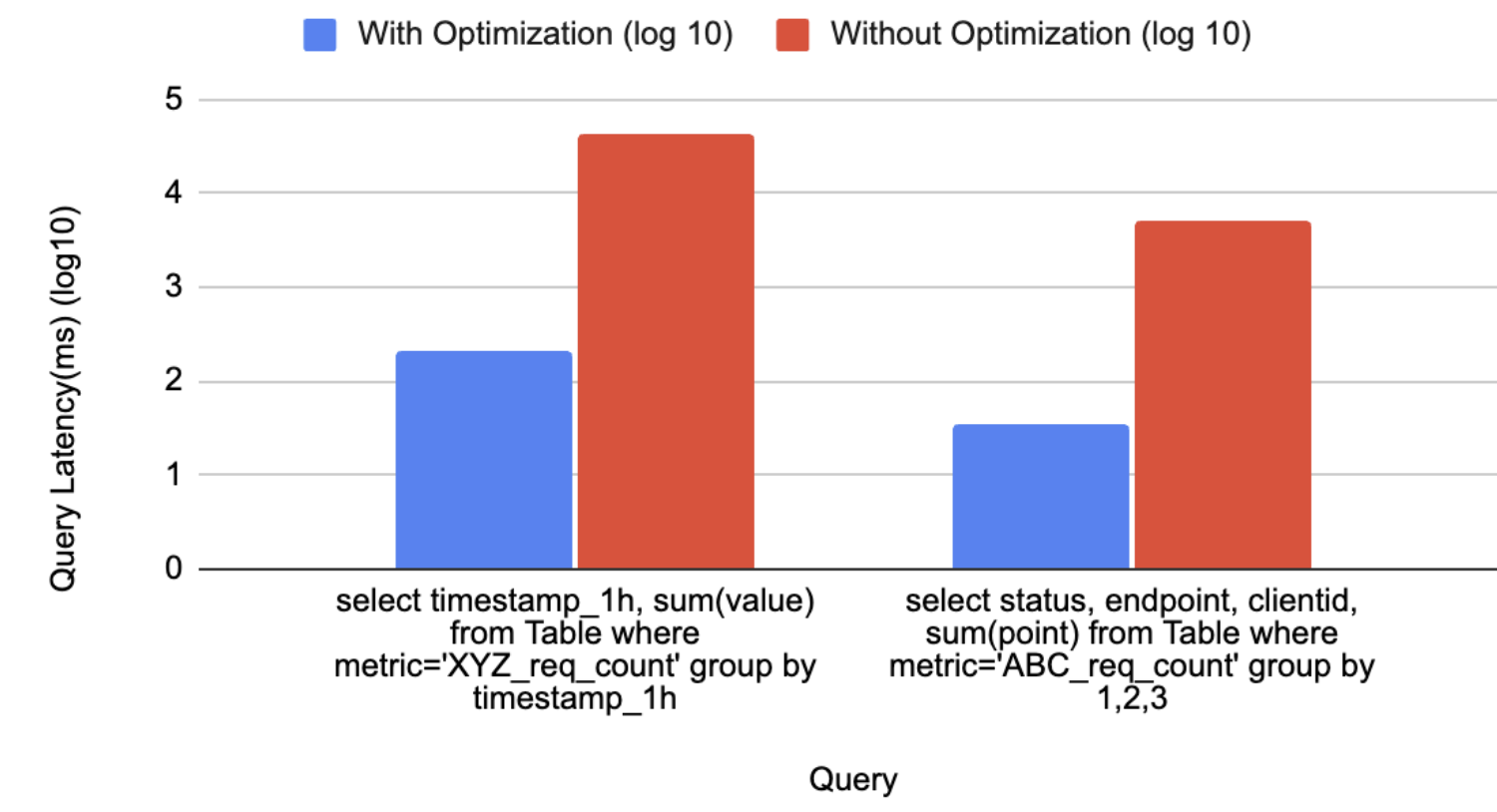
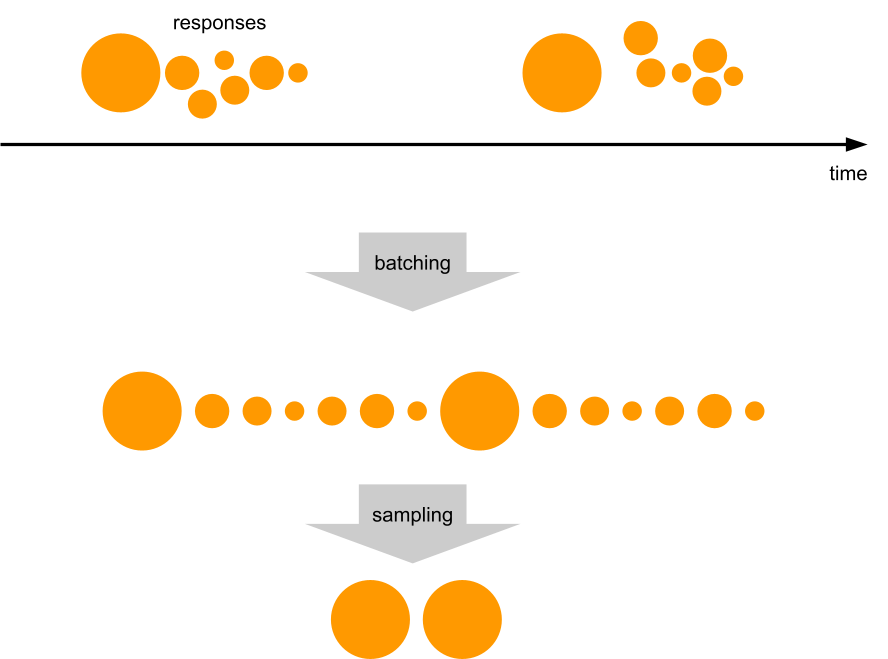
In today’s data-driven landscape, monitoring data quality has become a critical need for ensuring reliable and efficient data usage across domains. High-quality data is the backbone of AI innovation, driving efficiency and unlocking new opportunities. As decentralized data ownership grows, the ability to effectively monitor data quality is essential for maintaining reliability in data systems.
Kafka streams, as a vital component of real-time data processing, play a significant role in this ecosystem. However, unreliable data within Kafka streams can lead to errors and inefficiencies for downstream users, and monitoring the quality of data within these streams has always been a challenge. This blog introduces a solution that empowers stream users to define a data contract, specifying the rules that Kafka stream data must adhere to. By leveraging this user-defined data contract, the solution performs automated real-time data quality checks, identifies problematic data as it occurs, and promptly notifies stream owners. This ensures timely action, enabling effective monitoring and management of Kafka stream data quality while supporting the broader goals of data mesh and AI-driven innovation.
Problem statement
In the past, monitoring Kafka stream data processing lacked an effective solution for data quality validation. This limitation made it challenging to identify bad data, notify users in a timely manner, and prevent the cascading impact on downstream users from further escalating.
Challenges in syntactic and semantic issue identification:
Syntactic issues: Refers to schema mismatches between producers and consumers, which can lead to deserialization errors. While schema backward compatibility can be validated upon schema evolution, there are scenarios where the actual data in the Kafka topic does not align with the defined schema. For example, this can occur when a rogue Kafka producer is not using the expected schema for a given Kafka topic. Identifying the specific fields causing these syntactic issues is a typical challenge.
Semantic issues: Refers to inconsistencies or misalignments between producers and consumers about the expected pattern or significance of each field. Unlike Kafka stream schemas, which act as a data structure contract between producers and consumers, there is no existing framework for stakeholders to define and enforce field-level semantic rules, for example, the expected length or pattern of an identifier.
Timeliness challenge in data quality monitoring: There is no real-time mechanism to automatically validate data against predefined rules, timely identify quality issues, and promptly alert stream stakeholders. Without real-time stream validation, data quality issues can sometimes persist for periods of time, impacting various online and offline downstream systems before being discovered.
Observability challenge for troubleshooting bad data: Even when problematic data is identified, stream users face difficulties in pinpointing the exact “poison data” and understanding which fields are incompatible with the schema or violate semantic rules. This lack of visibility complicates Root Cause Analysis and resolution efforts.
Solution
Our Coban platform offers a standardized data quality test and observability solution at the platform level, consisting of the following components:
Data Contract Definition: Enables Kafka stream stakeholders to define contracts that include schema agreements, semantic rules that Kafka topic data must comply with, and Kafka stream ownership details for alerting and notifications.
Automated Test Execution: Provides a long running Test Runner to automatically execute real-time tests based on the defined contract.
Real-time Data Quality Issue Identification: Detects data issues at both syntactic and semantic levels in real-time.
Alerts and Result Observability: Alerts users, simplifying observation of data quality issues via the platform.
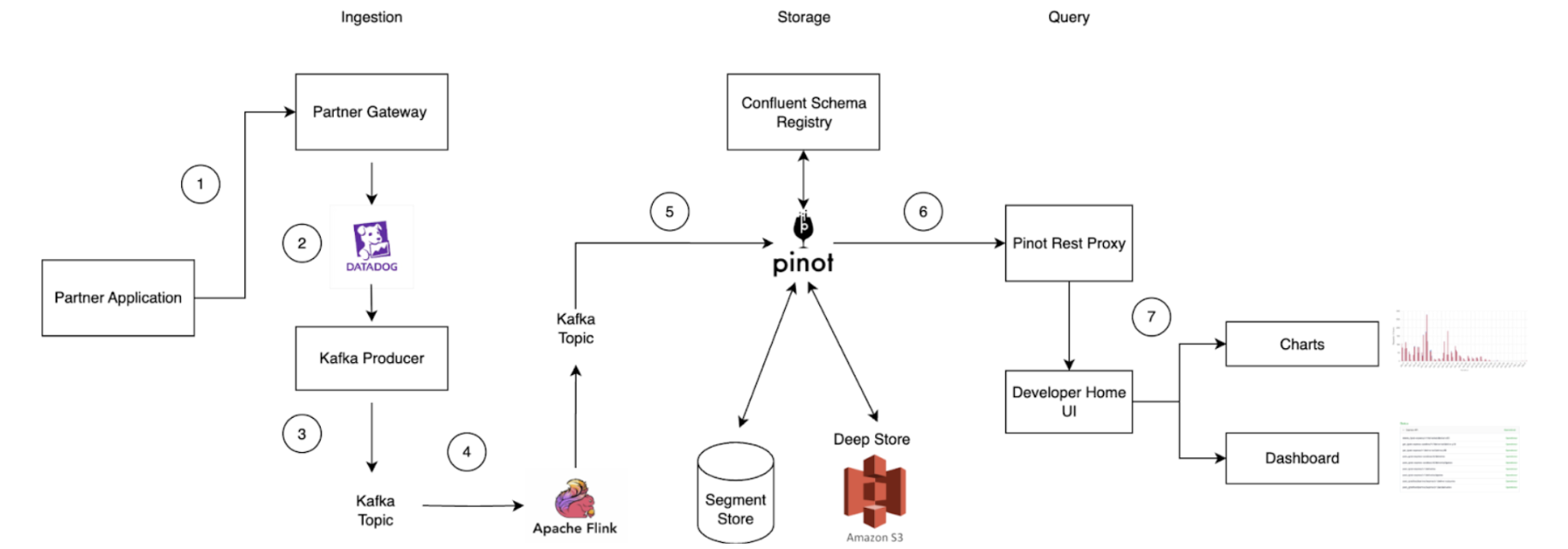
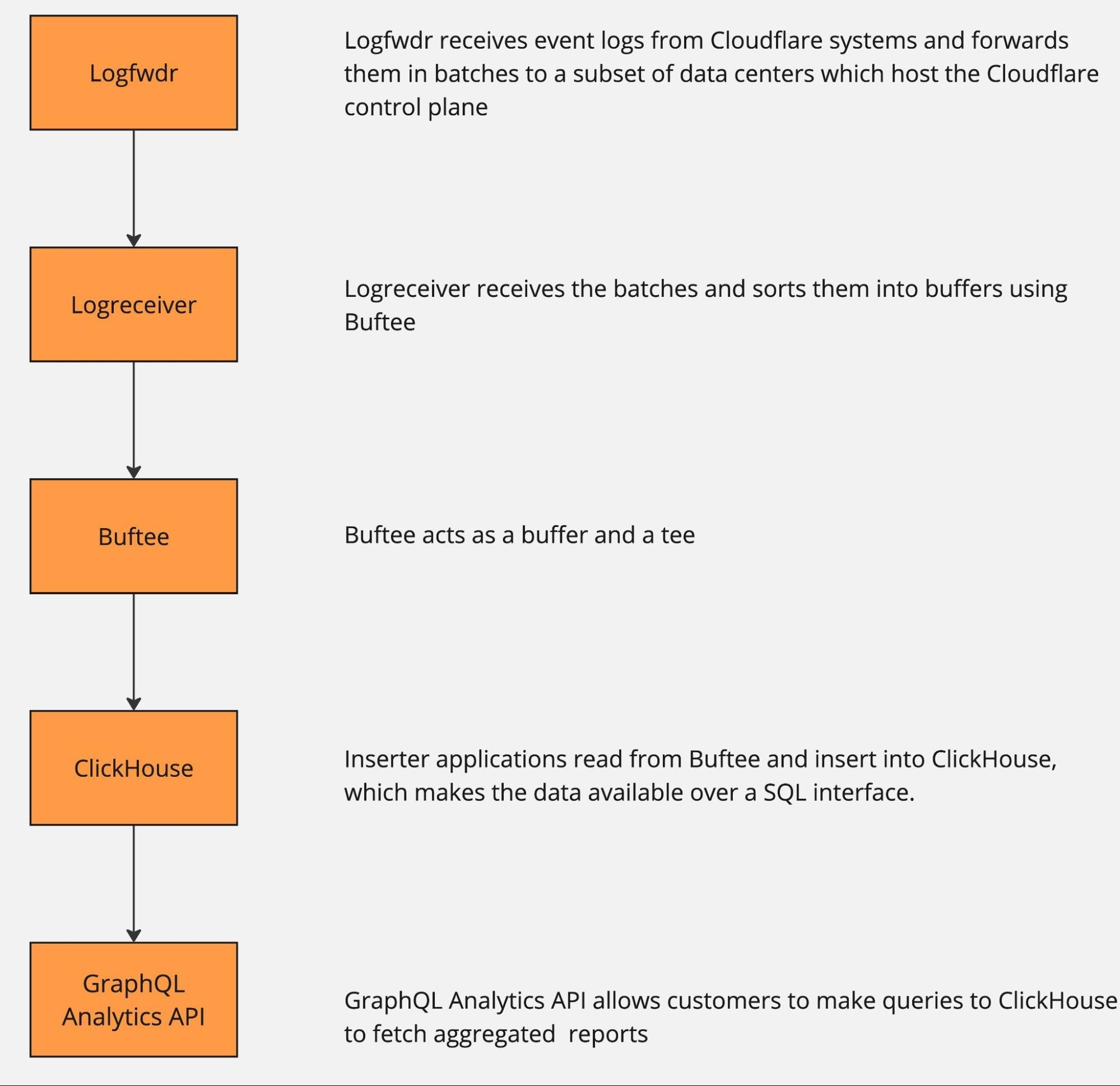
Architecture details
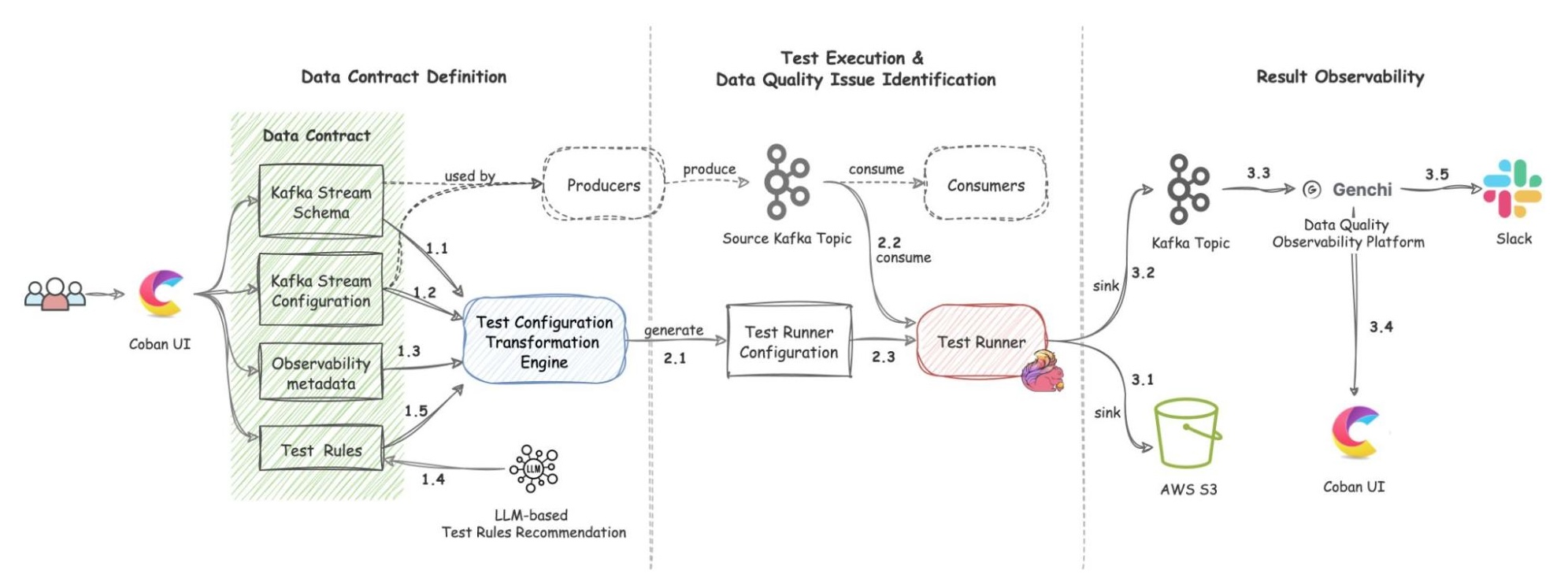
The solution includes three components: Data Contract Definition, Test Execution & Data Quality Issue Identification, and Result Observability as shown in the architecture diagram in figure 1. All mentions of “Flow” from here onwards refer to the corresponding processes illustrated in figure 1.
Figure 1. Real-time Kafka Stream Data Quality Monitoring Architecture diagram.
Data Contract Definition
The Coban Platform streamlines the process of defining Kafka stream data contracts, serving as a formal agreement among Kafka stream stakeholders. This includes the following components:
Kafka Stream Schema: Represents the schema used by the Kafka topic under test and helps the Test Runner to validate schema compatibility across data streams (Flow 1.1).
Kafka Stream Configuration: Encompasses essential configurations such as the endpoint and topic name, which the platform automatically populates (Flow 1.2).
Observability Metadata: Provides contact information for notifying Kafka stream stakeholders about data quality issues and includes alert configurations for monitoring (Flow 1.3).
Kafka Stream Semantic Test Rules: Empowers users to define intuitive semantic test rules at the field level. These rules include checks for string patterns, number ranges, constant values, etc. (Flow 1.5).
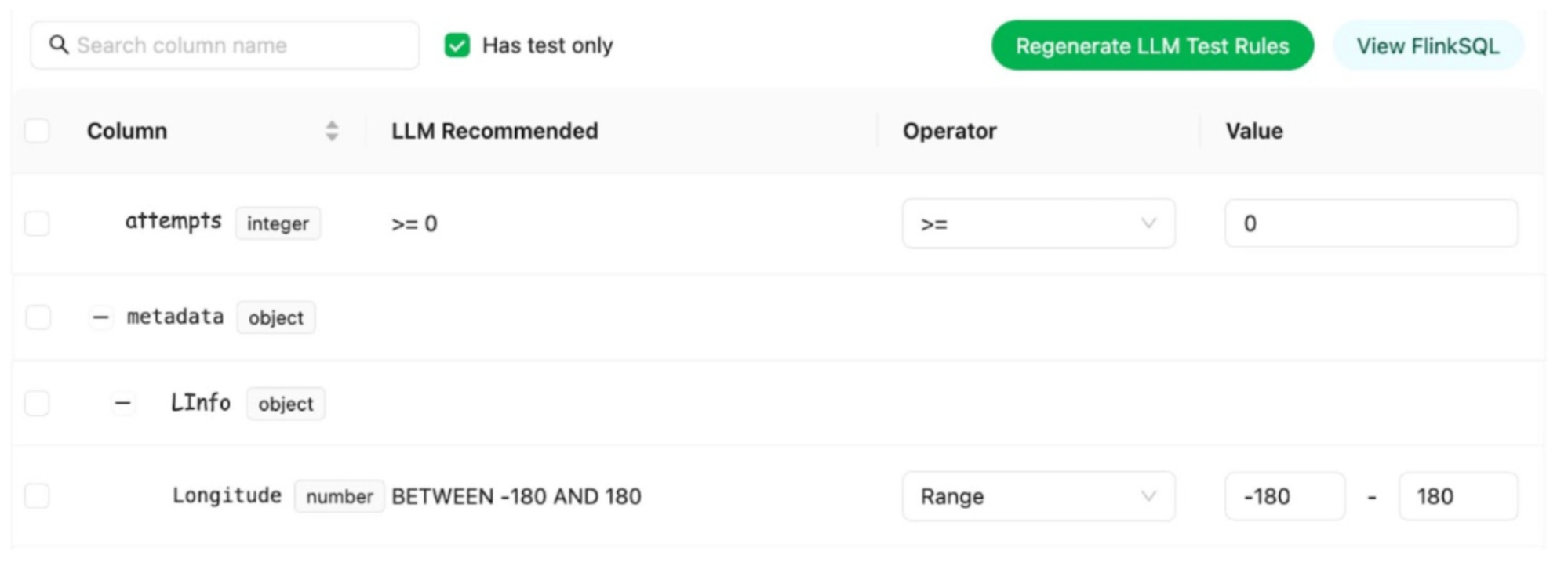
LLM-Based Semantic Test Rules Recommendation: Defining dozens if not hundreds of field-specific test rules can overwhelm users. To simplify this process, the Coban Platform uses LLM-based recommendations to predict semantic test rules using provided Kafka stream schemas and anonymized sample data (Flow 1.4). This feature helps users set up semantic rules efficiently, as demonstrated in the sample UI in figure 2.
Figure 2. Sample UI showcasing LLM-based Kafka stream schema field-level semantic test rules. Note that the data shown is entirely fictional.
Data Contract Transformation
Once defined, the Coban Platform’s transformation engine converts the data contract into configurations that the Test Runner can interpret (Flow 2.1). This transformation process includes:
Kafka Stream Schema: Translates the schema defined in the data contract into a schema reference that the Test Runner can parse.
Kafka Stream Configuration: Sets up the Kafka stream as a source for the Test Runner.
Observability metadata: Sets contact information as configurations of the Test Runner.
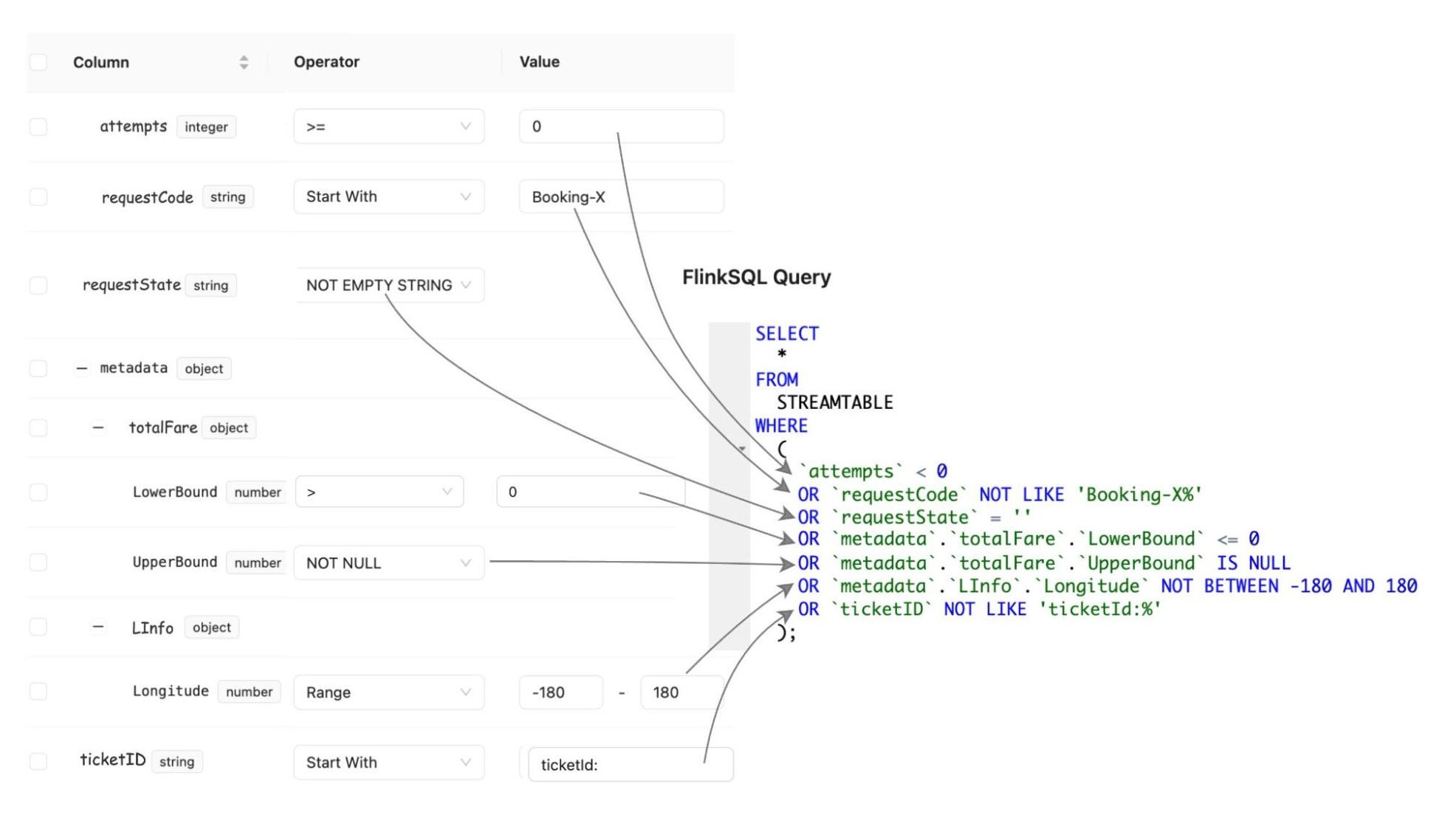
Kafka Stream Semantic Test Rules: Transforms human-readable semantic test rules into an inverse SQL query to capture the data that violates the defined rules.
Figure 3. Illustration of semantic test rules being converted from human-readable formats into inverse SQL queries.
Test Execution & Data Quality Issue Identification
Once the Test Configuration Transformation Engine generates the Test Runner configuration (Flow 2.1), the platform automatically deploys the Test Runner.
Test Runner
The Test Runner utilises FlinkSQL as the compute engine to execute the tests. FlinkSQL was selected for its flexibility in defining test rules as straightforward SQL statements, enabling our platform to efficiently convert data contracts into enforceable rules.
Test Execution Workflow And Problematic Data Identification
FlinkSQL consumes data from the Kafka topic under test (Flow 2.2) using its own consumer group, ensuring it doesn’t impact other consumers. It runs the inverse SQL query (Flow 2.3) to identify any data that violates the semantic rules or that is syntactically incorrect in the first place. Test Runner captures such data, packages it into a data quality issue event enriched with a test summary, the total count of bad records, and sample bad data, and publishes it to a dedicated Kafka topic (Flow 3.2). Additionally, the platform sinks all such data quality events to an AWS S3 bucket (Flow 3.1) to enable deeper observability and analysis.
Result Observability
Grab’s in-house data quality observability platform, Genchi, consumes problematic data captured by the Test Runner (Flow 3.3).
Alerting
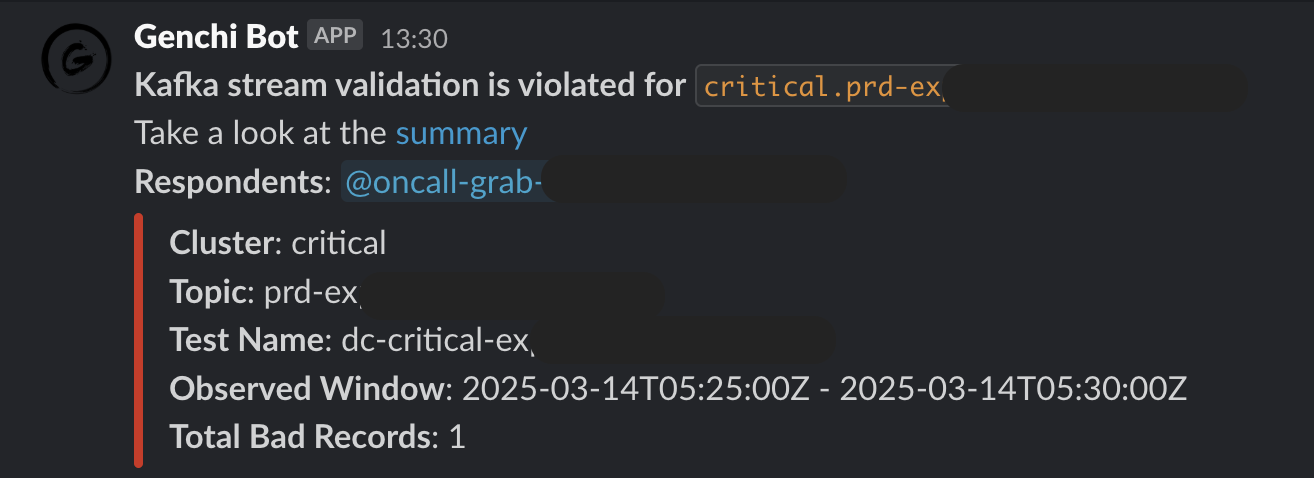
Genchi sends Slack notifications (Flow 3.5) to stream owners specified in the data contract observability metadata. These notifications include detailed information about stream issues, such as links to sample data in Coban UI, observed windows, counts of bad records, and other relevant details.
Figure 4. Sample Slack notifications
Observability
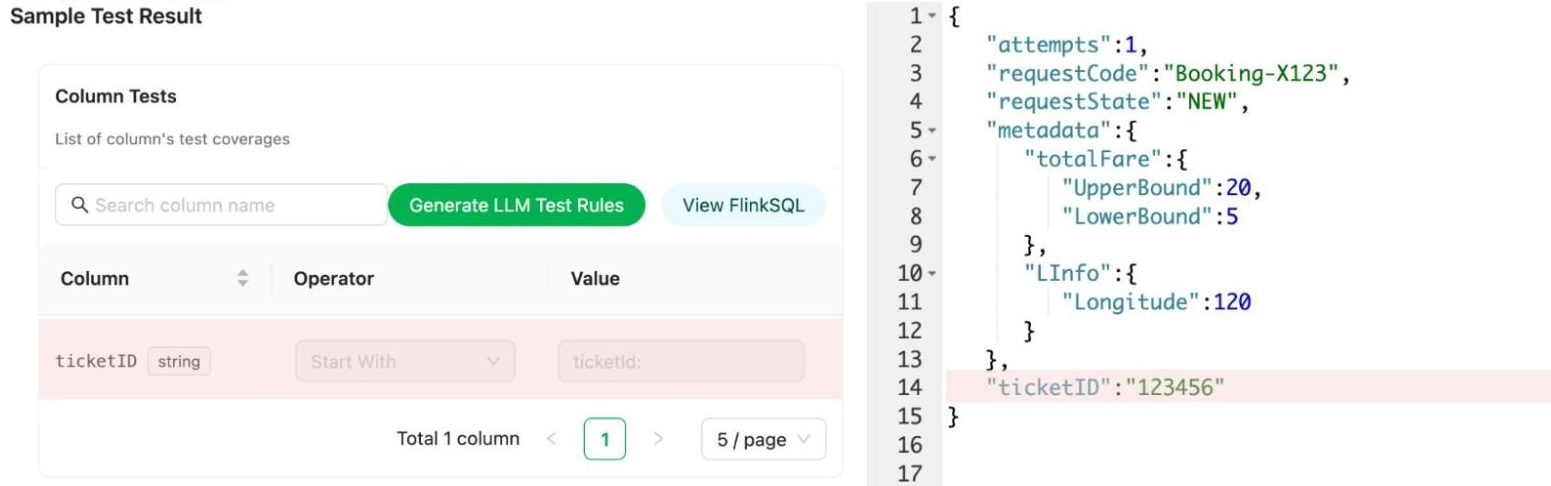
Users can access the Coban UI (Flow 3.4), displaying Kafka stream test rules and sample bad records, highlighting fields and values that violate rules.
Figure 5. In this Sample Test Result, the highlighted fields indicate violations of the semantic test rules.
Impact
Since its deployment earlier this year, the solution has enabled Kafka stream users to define contracts with syntactic and semantic rules, automate test execution, and alert users when problematic data is detected, prompting timely action. It has been actively monitoring data quality across 100+ critical Kafka topics. The solution offers the capability to immediately identify and halt the propagation of invalid data across multiple streams.
Conclusion
We implemented and rolled out a solution to assist Grab engineers in effectively monitoring data quality in their Kafka streams. This solution empowers them to establish syntactic and semantic tests for their data. Our platform’s automatic testing feature enables real-time tracking of data quality, with instant alerts for any discrepancies. Additionally, we provide detailed visibility into test results, facilitating the easy identification of specific data fields that violate the rules. This accelerates the process of diagnosing and resolving issues, allowing users to swiftly address production data challenges.
What’s next
While our current solution emphasizes monitoring the quality of Kafka streaming data, further exploration will focus on tracing producers to pinpoint the origin of problematic data, as well as enabling more advanced semantic tests such as cross-field validations. Additionally, we aim to expand monitoring capabilities to cover broader aspects like data completeness and freshness, and integrate with Gable AI to detect Data Transfer Object (DTO) changes and semantic regressions in Go producers upon committing code to the Git repository. These enhancements will pave the way for a more robust, multidimensional data quality testing solution across a wider range.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
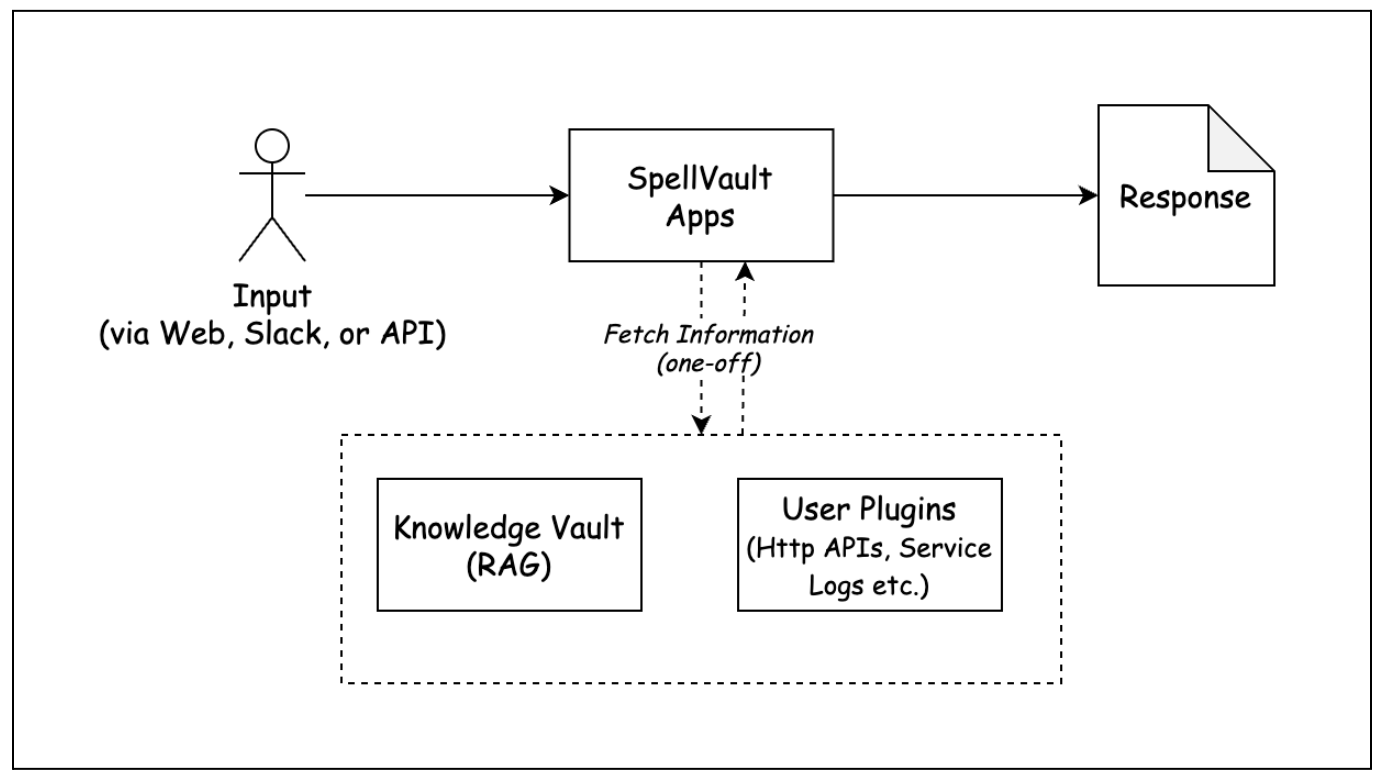
At Grab, innovation isn’t just about building new features; it’s about evolving our platforms to meet the changing needs of our users and the broader technological landscape. SpellVault, our internal AI platform, exemplifies this philosophy. When SpellVault was first launched, our vision was straightforward: empower everyone at Grab to effortlessly build and manage AI-powered apps without the need for coding. Built on the principles of Retrieval-Augmented Generation (RAG) and enhanced by plugin support, SpellVault rapidly evolved into a powerful productivity engine for the organization, enabling the creation of thousands of apps that drive automation, foster experimentation, and support production use cases.
As the AI landscape has evolved, SpellVault has grown alongside it. Initially launched as a straightforward no-code app builder for Large Language Models (LLMs), it has now evolved into a cutting-edge platform that embraces the agentic future—a future where AI goes beyond generating responses to reasoning, acting, and dynamically adapting through the use of tools and contextual understanding.
This article outlines SpellVault’s journey towards an agentic future and how we empower users to build AI Agents that are smarter, more adaptable, and ready for the future.
A no-code platform for building LLM apps
SpellVault was founded with a clear mission: to democratize access to AI for everyone at Grab, regardless of their technical expertise. Initially launched as a no-code LLM app builder, the platform was built on a foundation of RAG pipelines and basic plugin support.
Early on, we recognized that the true potential of AI apps extends beyond the capabilities of language models alone. Their real value lies in the ability to seamlessly interact with external systems and diverse data sources. This insight drove our commitment to minimizing barriers and ensuring users could access data from various sources with ease. From the very beginning, we centered our efforts on three key focus areas:
Comprehensive RAG solution with useful integrations
From the start, the SpellVault team prioritized enabling users to enhance their LLM apps with data through RAG. Rather than solely relying on the LLM’s internal information, we wanted the apps to ground their responses in up-to-date, contextually relevant, and factual information. SpellVault has built-in integrations with knowledge sources such as Wikis, Google Docs, as well as plain text and PDF uploads. These capabilities empower users to build assistants that reference relevant knowledge and provide more accurate, verifiable answers.
Plugins to fetch information on demand
To move beyond static knowledge retrieval, we needed a way for apps to act dynamically. This was made possible through SpellVault plugins—modular components that allow apps to interact with internal systems (e.g. service dashboards, incident trackers) and external APIs (e.g. search engines, weather data). Rather than being confined to their initial prompt and data, these plugins can fetch fresh information at runtime. From the available plugin types, users can create their own instances of plugins with custom settings, enabling highly specialized functionality tailored to their specific workflows. For instance, with SpellVault’s HTTP plugin, users can define custom endpoints and credentials, enabling their AI apps to make tailored HTTP calls during runtime. These custom plugins have become the backbone of many of our most impactful apps, empowering teams to seamlessly integrate SpellVault with their existing systems and processes.
Figure 1. SpellVault’s early architecture.
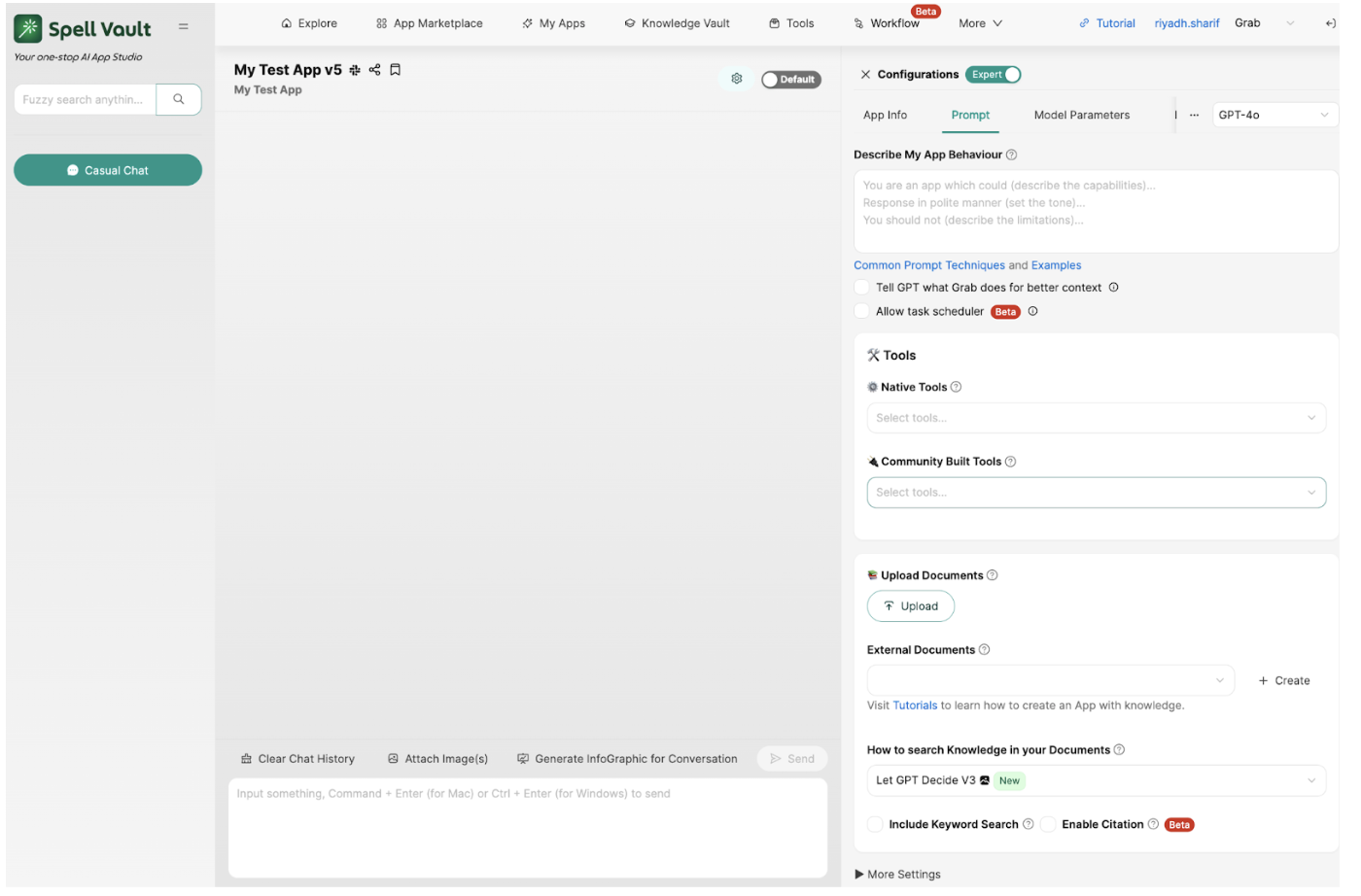
Making SpellVault accessible via common interfaces: Web, Slack, API
One of our primary goals was to make AI seamlessly accessible and useful within the tools users already use—whether it’s a browser or Slack. With SpellVault, users can make their AI apps in minutes and start using them via browser or Slack messaging immediately and intuitively, without requiring any additional setup. We also exposed APIs that enabled other internal services to integrate with SpellVault apps for a variety of use cases. This multi-channel approach ensured that SpellVault wasn’t just a standalone sandbox but a platform woven into existing tools and processes.
Users quickly adopted the platform, creating thousands of apps for internal productivity gains, automation, and even production use cases. The platform’s success validated our hypothesis that there was significant demand for democratized AI tools within the organization.
Figure 2. SpellVault’s web interface for LLM App configuration and chat.
Evolution over time
The AI landscape over the past few years has been defined by relentless change. New frameworks, execution paradigms, and standards have emerged in quick succession, each promising to make AI systems more powerful, more reliable, or more extensible. At Grab, we recognized that for SpellVault to stay relevant, it could not remain static. It needed to evolve in tandem with the ever-changing ecosystem, continuously incorporating valuable advancements while ensuring a seamless experience for our users.
This philosophy of continuous adaptation has guided SpellVault’s journey. From its early days as a simple RAG-powered app builder with a few plugins, the platform grew to support an extensive number of plugin types, richer execution models, and eventually a unified approach to tools. Each step was a response both to the needs of our users and to the shifting definition of what “building with AI” meant in practice. Rather than opting for a complete overhaul, SpellVault has embraced incremental advancements, ensuring that users can seamlessly benefit from new capabilities without disruption.
This approach to evolution has naturally positioned SpellVault to transition from a platform for LLM apps to one designed for AI agents. The following section delves into this transition in greater detail.
Expanding capabilities
Over time, we introduced numerous new capabilities to SpellVault, driven both by user feedback and our commitment to innovation and staying ahead of industry trends. For instance, we extended support for different plugin types, enabling integrations with tools like Slack and Kibana, and continuously added more integrations to enhance the platform’s versatility. We implemented auto-updates for users’ Knowledge Vaults, ensuring their data remained current. With more users building with the platform, ensuring the trustworthiness of responses generated by SpellVault apps became increasingly important. We included citation capability to mitigate some of that concern. Recognizing the need for more precise answers to mathematical problems, we developed a feature that enabled LLMs to solve such problems using Python runtime. Additionally, many users requested an automated way to trigger their LLM apps, which led to the creation of a Task Scheduler feature that allows LLMs to schedule actions based on natural language user input.
A significant milestone in SpellVault’s evolution was the introduction of “Workflow,” a drag-and-drop interface within the platform that empowered users to design deterministic workflows. These workflows enabled users to seamlessly combine various components from the SpellVault ecosystem—such as LLM calls, Python code execution, and Knowledge Vault lookups—in a predefined and structured manner. This enabled advanced use cases for many users.
Figure 3. Evolving tools landscape of SpellVault with increasing integrations.
Shifting the execution model
As SpellVault evolved, a fundamental shift took place in the way its apps were executed internally. We transitioned from our legacy executor system, which facilitated one-off information retrieval from the Knowledge Vault or user plugins, to a more advanced graph based executor. This empowered SpellVault’s app execution with nodes, edges, and states that supported branching, looping, and modularity. This laid the groundwork for more sophisticated agent behaviors, moving beyond the linear input-output paradigm.
This transformed all existing SpellVault apps into ‘Reasoning and Acting’ agents, better known as ReAct agents – a “one size fits many” solution that significantly enhanced the capabilities of these apps. By enabling them to leverage the Knowledge Vault and plugins in a more agentic and dynamic manner, the ReAct agent framework allowed apps to perform more complex tasks while seamlessly preserving their existing functionality, ensuring no disruption to their behavior.
In addition, the internal decoupling of the executor and prompt engineering components enabled us to design multiple execution pathways with ease. This allowed us to provide generic Deep Research capability to any SpellVault app via a simple UI checkbox, as well as sophisticated internal workflows that cater to high-ROI complex use cases like on-call alert analysis. The Deep Research capability came with SpellVault’s ability to search across internal information repositories (e.g., Slack messages, Wiki, Jira) within Grab, as well as searching online for relevant information.
Figure 4. SpellVault’s evolved architecture with more dynamic context gathering and advanced interaction modes.
Towards an agentic framework
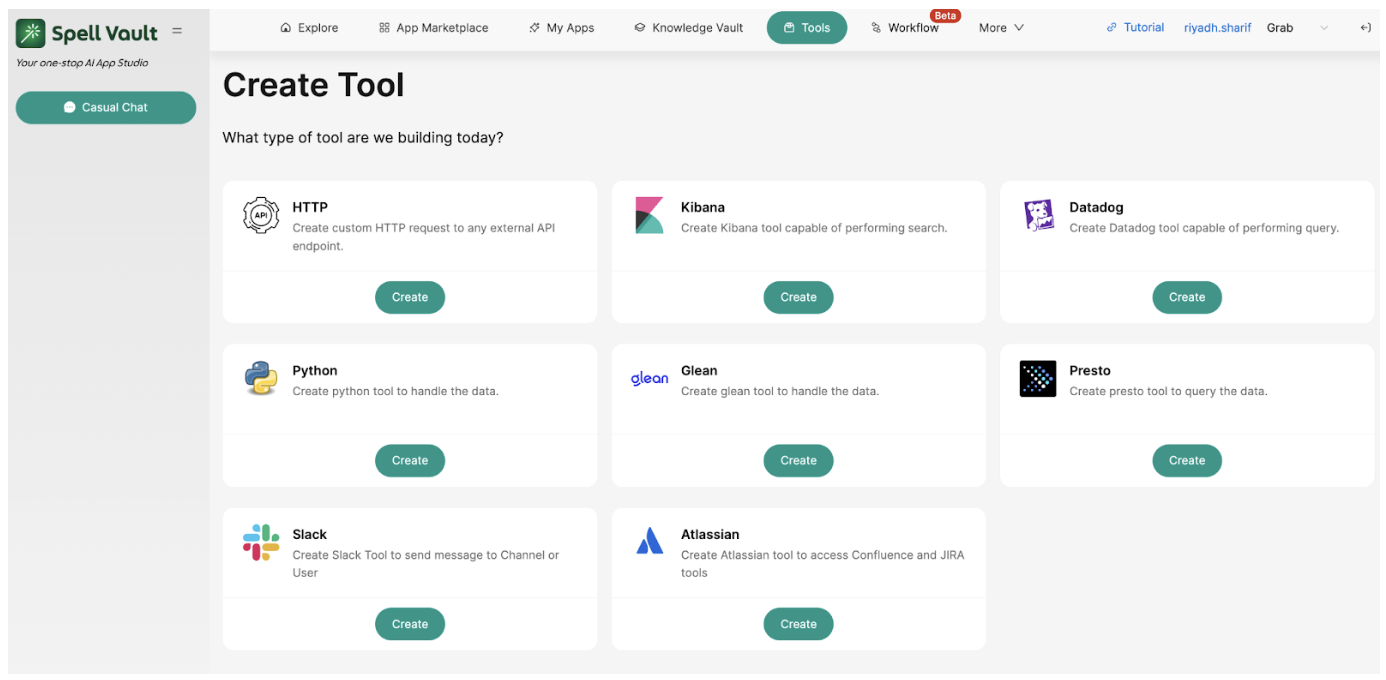
Over time, several capabilities were added to SpellVault, including features like Python code execution and internal repository search. Initially, these functionalities were integrated directly into the core PromptBuilder class. For users, these features were primarily accessible through simple checkboxes in the user interface. As SpellVault gradually transitioned towards giving more agency to user-crafted apps, we recognized that these capabilities should instead be positioned as “Tools” for LLMs to use with greater autonomy, similar to how ReAct agent–backed apps have been using SpellVault’s user plugins. We also understood that this shift could bring a clearer mental model for users where they were no longer simply toggling features but creating AI agents with access to a defined set of tools. The agents could then decide when and how to use those tools intelligently to accomplish tasks, making the overall experience more natural and intuitive.
This recognition led to the consolidation of these scattered capabilities into a unified framework called “Native Tools.” These Native Tools, along with SpellVault’s existing user plugins—rebranded as “Community Built Tools”—formed a comprehensive collection of tools that LLMs could dynamically invoke at runtime. Despite being grouped under the same umbrella, a key distinction was maintained: Native Tools required no user-specific configuration (e.g., performing internet searches), whereas Community Built Tools were custom, user-configured entities (e.g., invoking specific HTTP endpoints) created from available plugin types, often requiring credentials or other personalized settings.
This consolidation of capabilities under a unified Tools abstraction and enabling SpellVault apps to invoke them with greater autonomy marked a pivotal milestone in the platform’s evolution. It meaningfully shifted SpellVault toward making agentic behavior more natural, discoverable, and extensible for every app.
Figure 5. SpellVault’s Unified Tools housing both Native Tools and Community Built Tools.
SpellVault as an MCP service
As we streamlined SpellVault’s internal capabilities into a unified tools framework, we also turned our focus outward to align with industry standards. The growing adoption of the Model Context Protocol (MCP) presented an opportunity for agents and clients to seamlessly interact without requiring custom integrations. To remain at the forefront of innovation, we adapted SpellVault to function as an MCP service, enabling it to actively participate in this evolving ecosystem. This extension brought two key advancements:
SpellVault apps as MCP tools: Each app created in SpellVault can now be exposed through the MCP protocol. This allows other agents or MCP-compatible clients, such as IDEs or external orchestration frameworks, to treat a SpellVault app as a callable tool. Instead of living only inside our web user interface or Slack interface, these apps become accessible building blocks that other systems can invoke dynamically.
RAG as an MCP tool: We extended the same idea to our Knowledge Vaults. Through MCP, external clients can search, retrieve, and even add information to Vaults. This effectively turns SpellVault’s RAG pipeline into an MCP-native service, making contextual grounding available to agents beyond SpellVault itself.
While building the SpellVault MCP Server, we also created TinyMCP – a lightweight open-source Python library that adds MCP capabilities to an existing FastAPI app as just another router, instead of mounting a separate app.
By exposing both apps and RAG through MCP, we shifted SpellVault from being a self-contained platform to becoming an interoperable service provider in the agentic ecosystem. Users still benefit from the no-code simplicity inside SpellVault. However, the output of their work, apps, and knowledge, are now usable by other agents and tools outside of it.
Conclusion
SpellVault’s evolution shows how a platform can adapt with the AI landscape while staying true to its original mission of making powerful technology accessible to everyone. What began as a no-code builder for LLM apps has steadily expanded into an agentic platform – one where apps can act with more intelligence, agency, and context and interact with the systems around them.
This progress wasn’t the result of a single breakthrough, but of steady, incremental improvements that introduced new capabilities while preserving ease of use. By layering in these advancements thoughtfully but boldly, SpellVault has managed to support more sophisticated agentic behaviors without compromising its original goal of democratizing AI at Grab.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
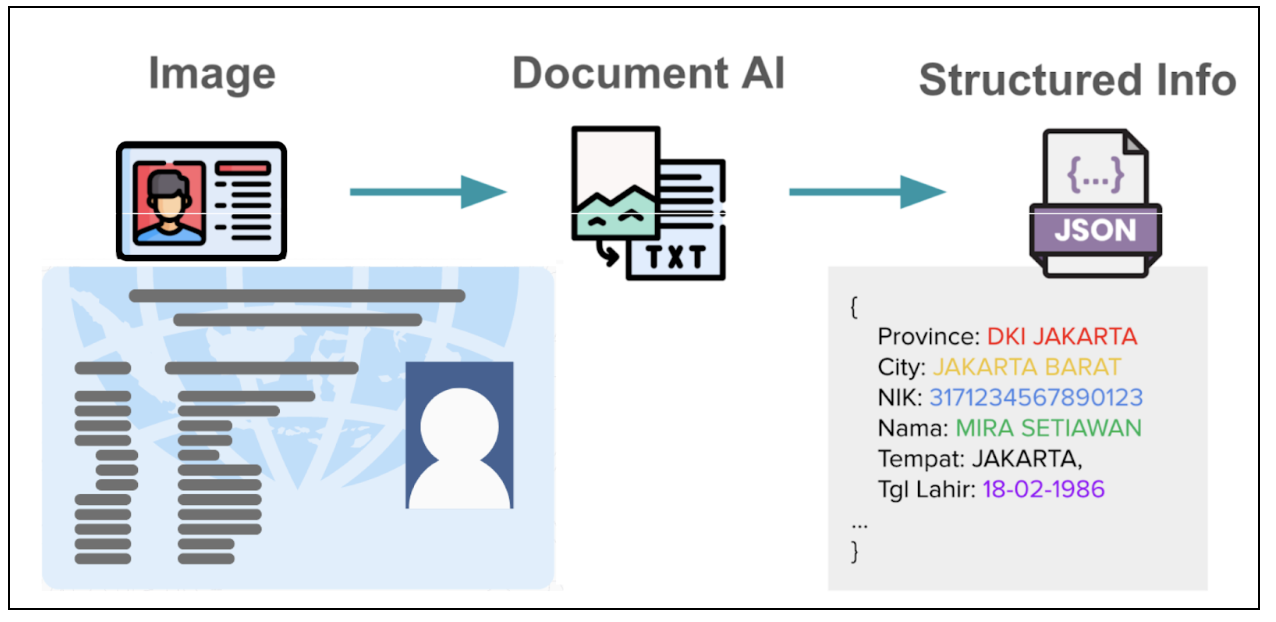
In the world of digital services, accurate extraction of information from user-submitted documents such as identification (ID) cards, driver’s licenses, and registration certificates is a critical first step for processes like electronic know-your-customer (eKYC). This task is especially challenging in Southeast Asia (SEA) due to the diversity of languages and document formats.
We began this journey to address the limitations of traditional Optical Character Recognition (OCR) systems, which struggled with the variety of document templates it had to process. While powerful proprietary Large Language Models (LLMs) were an option, they often fell short in understanding SEA languages, produced errors, hallucinations, and had high latency. On the other hand, open-sourced Vision LLMs were more efficient but not accurate enough for production.
This prompted us to fine-tune and ultimately develop a lightweight, specialized Vision LLM from the ground up. This blog is our account of the entire process.
Figure 1: Simplified overview of how Vision LLM works.
Background
What is a Vision LLM?
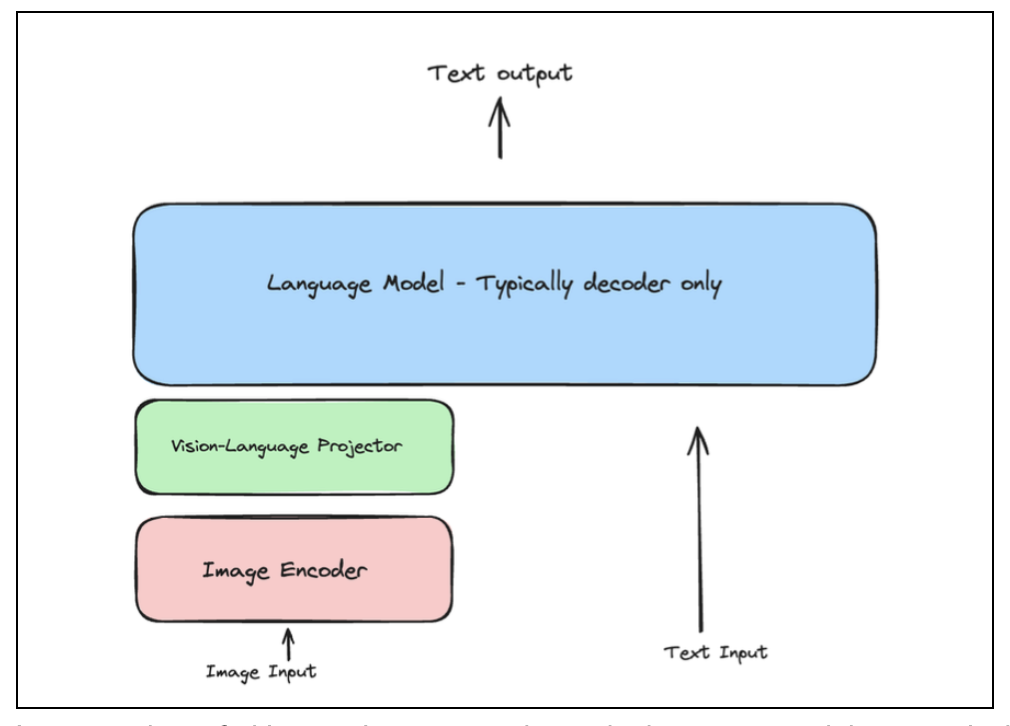
You’ve likely heard of LLMs that process text. You give the LLM a text prompt, and it responds with a text output. A Vision LLM takes this a step further by allowing the model to understand images. The basic architecture involves three key components:
Image encoder: This component ‘looks’ at an image and converts it into a numerical (vectorized) format.
Vision-language projector: It acts as a translator, converting the image’s numerical format into a representation that the language model can understand.
Language model: The familiar text-based model that processes the combined image and text input to generate a final text output.
Figure 2: Vision LLM basic architecture.
Choosing our base Vision LLM model
We evaluated a range of LLMs capable of performing OCR and Key Information Extraction (KIE). Our exploration of open-source options—including Qwen2VL, miniCPM, Llama3.2 Vision, Pixtral 12B, GOT-OCR2.0, and NVLM 1.0—led us to select Qwen2-VL 2B as our base multimodal LLM. This decision was driven by several critical factors:
Efficient size: It is small enough for full fine-tuning on GPUs with limited VRAM resources.
SEA language support: Its tokenizer is efficient for languages like Thai and Vietnamese, indicating decent native vocabulary coverage.
Dynamic resolution: Unlike models that require fixed-size image inputs, Qwen2-VL can process images in their native resolution. This is crucial for OCR tasks as it prevents the distortion of text characters that can happen when images are resized or cropped.
We benchmarked Qwen2VL and miniCPM on Grab’s dataset. Our initial findings showed low accuracy, mainly due to the limited coverage of SEA languages. This motivated us to fine-tune the model to improve OCR and KIE accuracy. Training the LLM can be a very data-intensive and GPU resource-intensive process. Due to this, we had to address these two concerns before progressing further:
Data: How do we use open source and internal data effectively to train the model?
Model: How do we customize the model to reduce latency but keep high accuracy?
Training dataset generation
Synthetic OCR dataset
We extracted the SEA languages text content from a large online text corpus—Common Crawl (internet dataset). Then, we used an in-house synthetic data pipeline to generate text images by rendering SEA text contents in various fonts, backgrounds and augmentations.
The dataset contains text in Bahasa Indonesia, Thai, Vietnamese, and English. Each image has a paragraph of random sentences extracted from the dataset as shown in Figure 3.
Figure 3: Two synthetic sample images in Thai language used for model training.
Documint: AI-powered, auto-labelling framework
Our experiments showed that applying document detection and orientation correction significantly improves OCR and information extraction. Now that we have an OCR dataset, we needed to generate a pre-processing dataset to further improve model training.
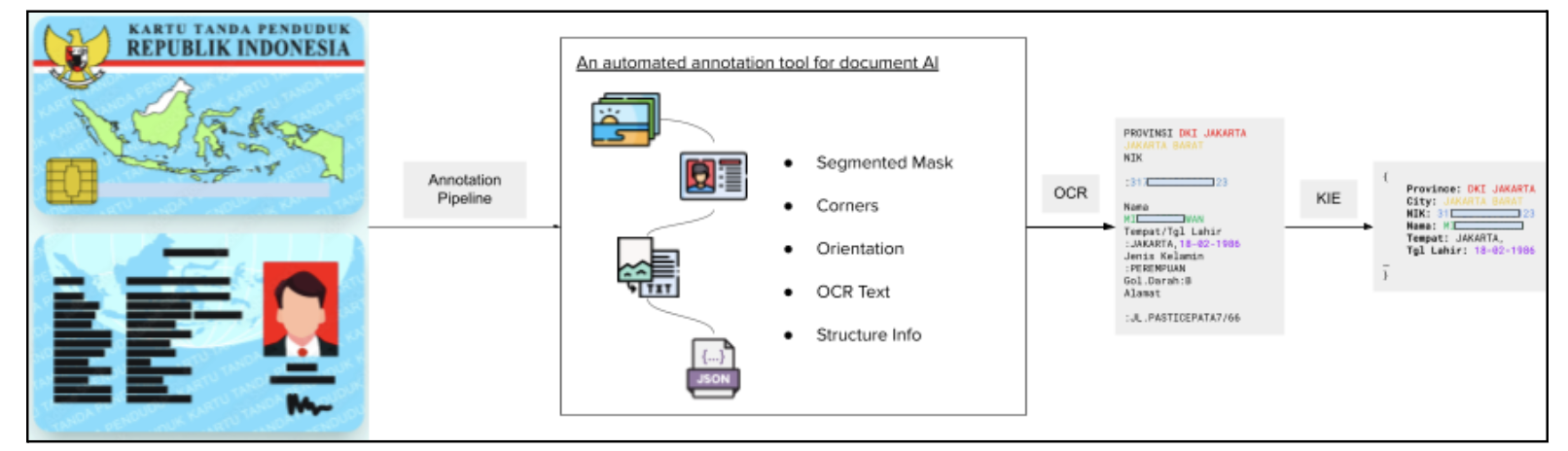
Documint is an internal platform developed by our team that creates an auto‑labelling and pre‑processing framework for document understanding. It prepares high‑quality, labelled datasets. Documint utilizes various submodules to effectively execute the full OCR and KIE task. We then used a pipeline with the large amount of Grab collected cards and documents to extract training labels. The data was further refined by a human reviewer to achieve high label accuracy.
Documint has four main modules:
Detection module: Detect the region from the full picture.
Orientation module: Gives correction angle (e.g. if document is upside down, 180 degrees).
OCR module: Returns text values in unstructured format.
KIE module: Returns JSON values from unstructured text.
Figure 4: Pipeline overview of Documint.
Experimentation
Phase 1: The LoRA experiment
Our first attempt in fine-tuning a Vision LLM involved fine-tuning an open-source model Qwen2VL, using a technique called Low-Rank Adaptation (LoRA). LoRA is efficient because it allows lightweight updates to the model’s parameters, minimizing the need for extensive computational resources.
We trained the model on our curated document data, which included various document templates in multiple languages. The performance was promising for documents with Latin scripts. Our experiment of LoRA fine-tuned Qwen2VL-2B achieved high field-level of accuracy for Indonesian documents.
However, the fine-tuned model still struggled with:
Documents containing non-Latin scripts like Thai and Vietnamese.
Unstructured layouts with small, dense text.
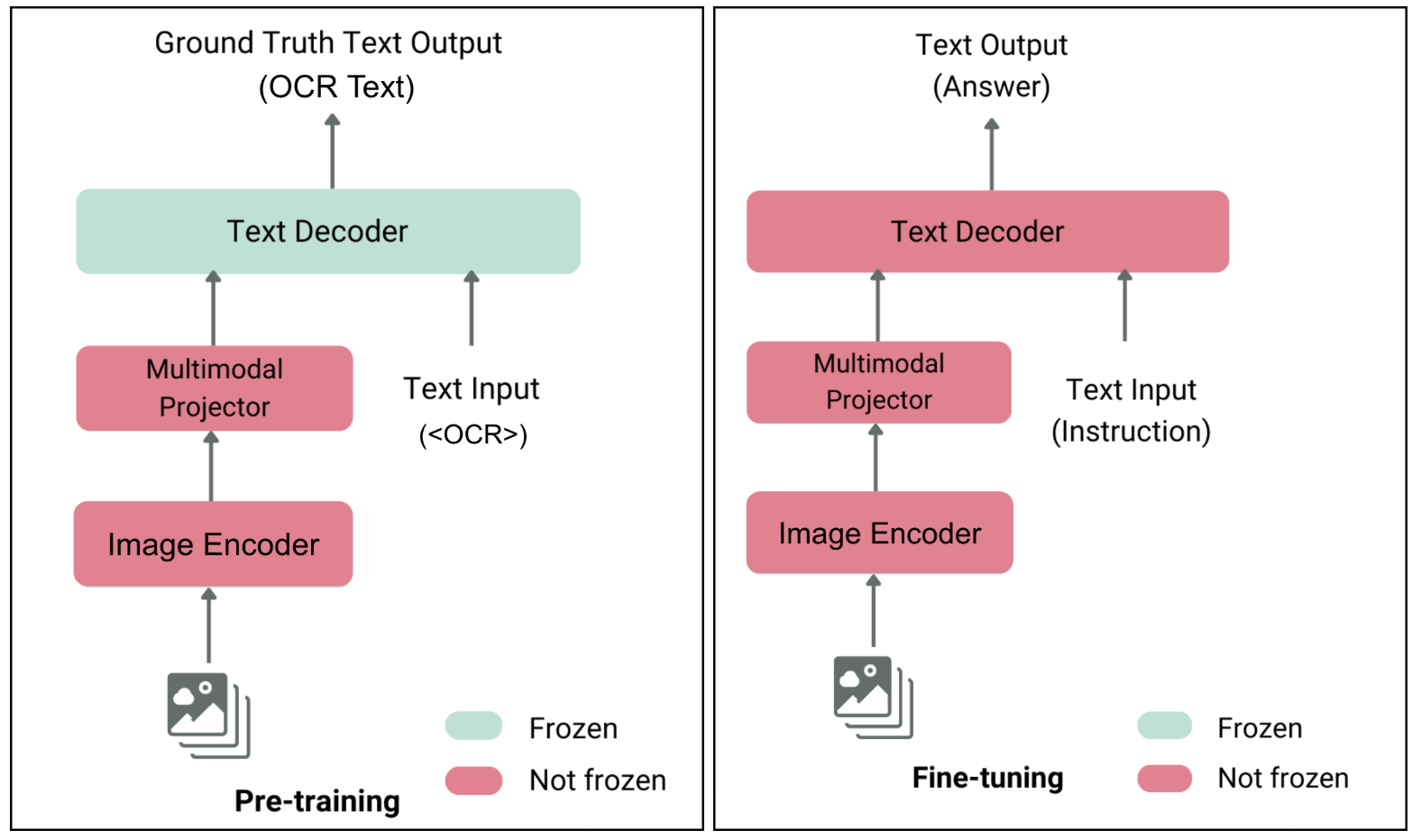
Phase 2: The power of full fine-tuning
Our experiments revealed a key limitation. While open-source Vision LLMs often have extensive multi-lingual corpus coverage for the LLM decoder’s pre-training, they lack visual text in SEA languages during vision encoder and joint training. This insight drove our decision to pursue full parameter fine-tuning for optimal results.
Figure 5: From left to right—two-stage training process.
Stage 1 – Continual pre-training: We first trained the vision components of the model using synthetic OCR datasets that we created for Bahasa Indonesia, Thai, Vietnamese, and English. This helps the model to learn the unique visual patterns of SEA scripts.
Stage 2 – Full-parameter fine-tuning: We then fine-tuned the entire model—vision encoder, projector, and language model—using our task-specific document data.
Results:
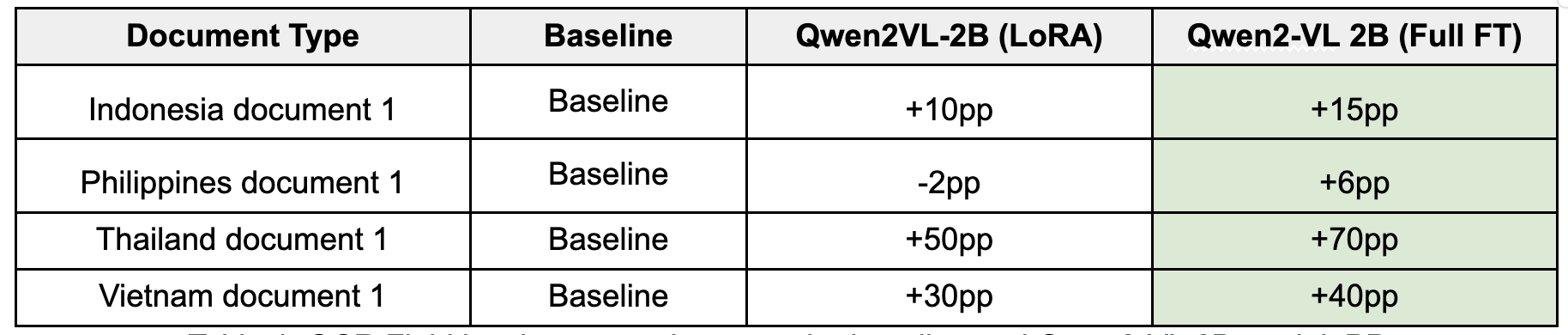
Table 1: OCR Field level accuracy between the baseline and Qwen2-VL 2B model. (pp: percentage points).
The fully fine-tuned Qwen2-VL 2B model delivered significant improvement, especially on documents that the LoRA model struggled with.
Thai document accuracy increased +70pp from baseline.
Vietnamese document accuracy rose +40pp from baseline.
Phase 3: Building a lightweight 1B model from scratch
While the Qwen2VL-2B model was a success, the full fine-tuning pushed the limits of GPUs. To optimize resources used and to create a model perfectly tailored to our needs, we decided to build a lightweight Vision LLM (~1B parameters) from scratch.
Our strategy was to combine the best parts of all models:
We took the powerful vision encoder from the larger Qwen2-VL 2B model.
We paired it with the compact and efficient language decoder from the Qwen2.5 0.5B model.
We connected them with an adjusted projector layer to ensure they could work together seamlessly.
This created a custom ~1B parameter Vision LLM optimized for training and deployment.
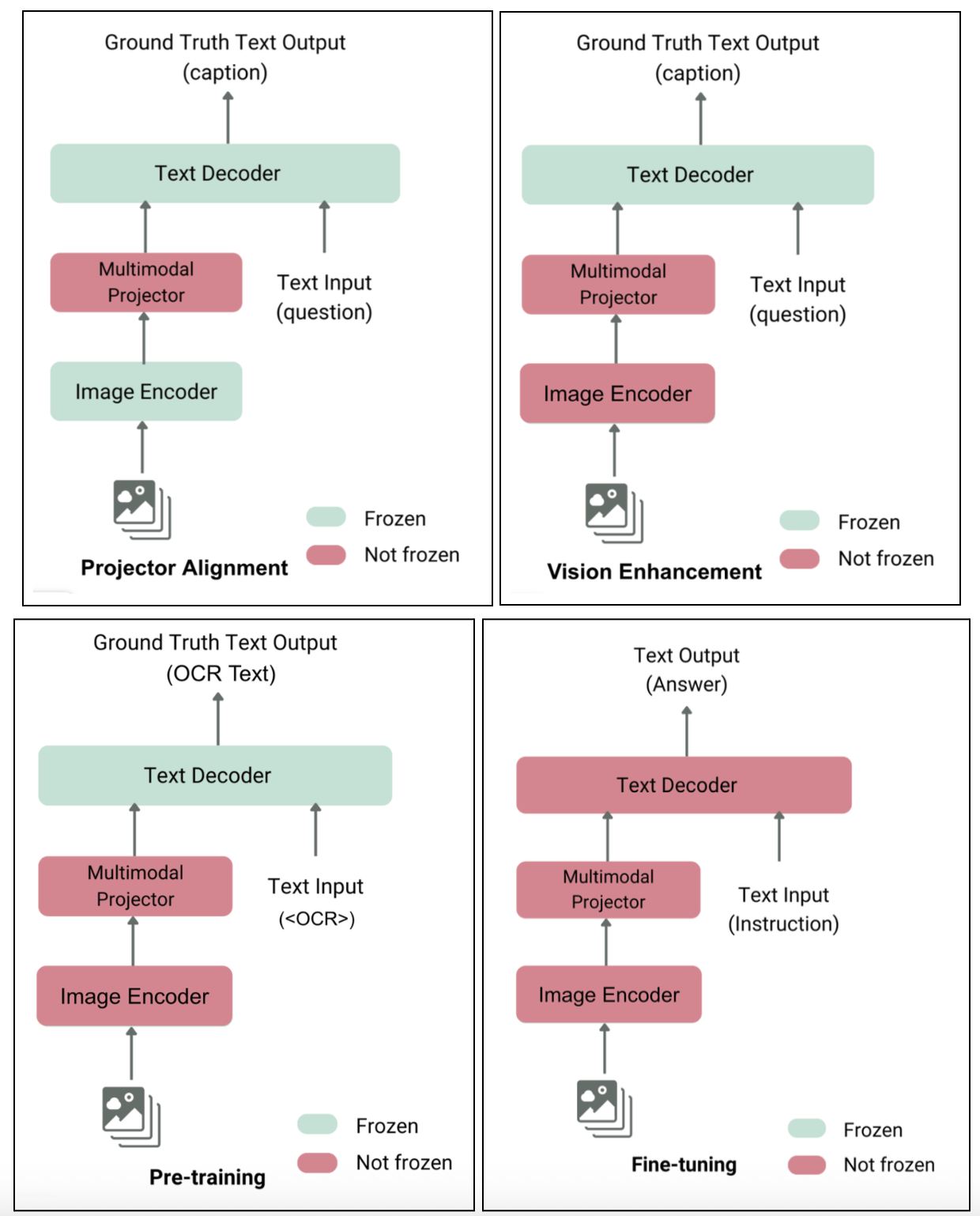
Four stages in training our custom model
We trained our new model using a comprehensive four-stage process as shown in Figure 6.
Figure 6: From left to right— four stages of model training.
Stage 1 – Projector alignment: The first step was to train the new projector layer to ensure the vision encoder and language decoder could communicate effectively.
Stage 2 – Vision tower enhancement: We then trained the vision encoder on a vast and diverse set of public multimodal datasets, covering tasks like visual Q&A, general OCR, and image captioning to improve its foundational visual understanding.
Stage 3 – Language-specific visual training: We trained the model on two types of synthetic OCR data. Without this stage, performance on non-Latin documents dropped by as much as 10%.
Stage 4 – Task-centric fine-tuning: Lastly, we performed full-parameter fine-tuning on our custom 1B model using our curated document dataset.
The final results are as follow:
Accuracy:
It achieved performance comparable to the larger 2B model, staying within a 3pp accuracy gap across most document types. The model also maintained strong generalization when trained on quality-augmented datasets.
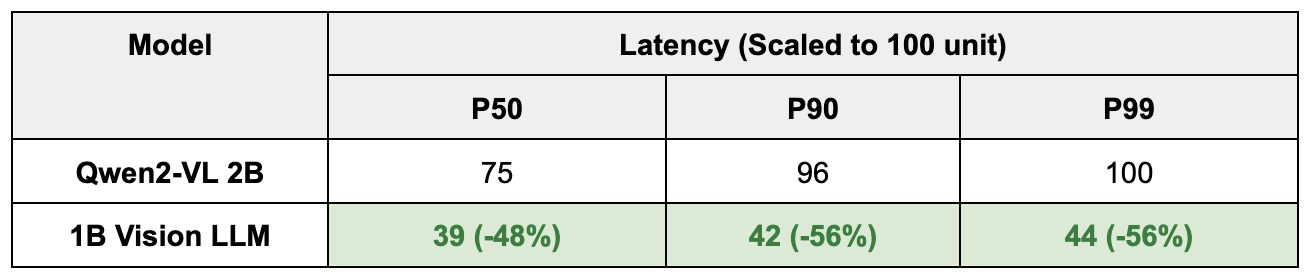
Latency:
The latency of our model far outperforms the 2B model, as well as traditional OCR models, as well as external APIs like chatGPT or Gemini. One of the biggest weaknesses we identified with external APIs was the P99 latency, which can easily be 3 to 4x the P50 latency, which would not be acceptable for Grab’s large scale rollouts.
Table 2: Performance comparison between Qwen2-VL 2B and 1B sized Vision LLM.
Key takeaways
Our work demonstrates that strategic training with high-quality data enables smaller, specialized models to achieve remarkable efficiency and effectiveness. Here are the critical insights from our extensive experiments:
Full fine-tuning is superior: For specialized, non-Latin script domains, full-parameter fine-tuning dramatically outperforms LoRA.
Lightweight models are effective: A smaller model (~1B) built from scratch and trained comprehensively can achieve near state-of-the-art results, validating the custom architecture.
Base model matters: Starting with a base model that has native support for your target languages is crucial for success.
Data is king: Meticulous dataset preprocessing and augmentation plays a critical role in achieving consistent and accurate results.
Native resolution is a game changer: A model that can handle dynamic image resolutions preserves text integrity, dramatically improves OCR capabilities.
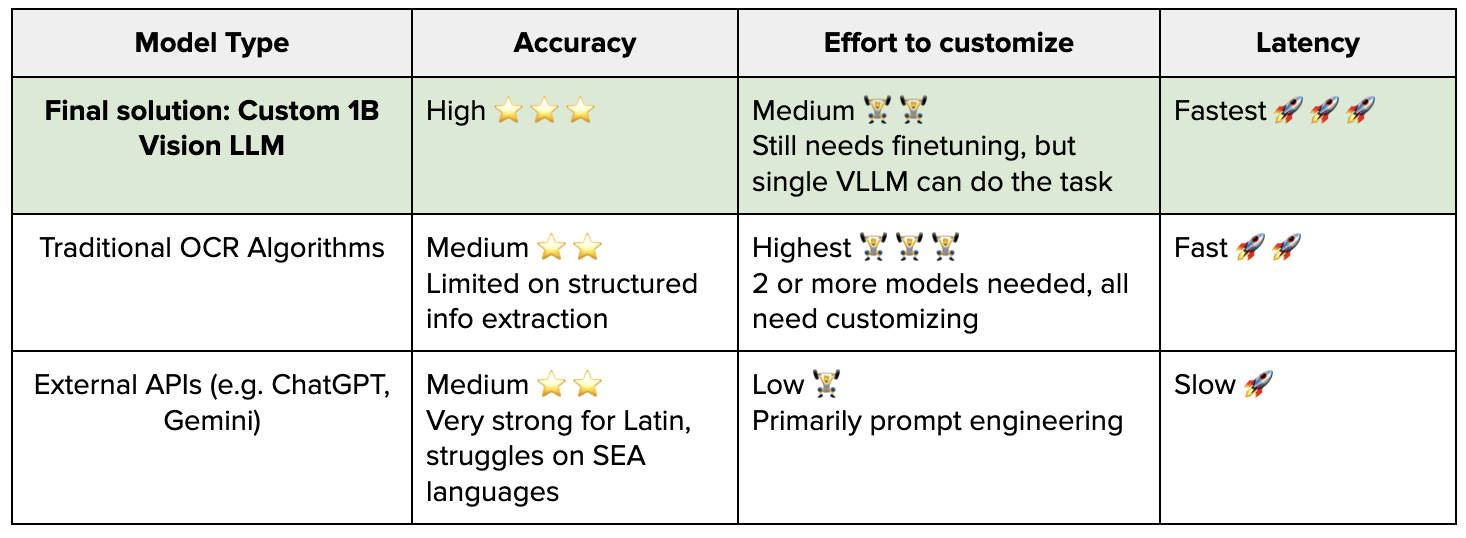
Our journey demonstrates that specialized Vision LLMs can effectively replace traditional OCR pipelines with a single, unified, highly accurate model—opening new possibilities for document processing at scale.
Table 3: Comparison of model types .
What’s next?
As we continue to enhance our Vision LLM capabilities, exciting developments are underway:
Smarter, more adaptable models: We’re developing Chain of Thought-based OCR and KIE models to strengthen generalisation capabilities and tackle even more diverse document scenarios.
Expanding across Southeast Asia: We’re extending support to all Grab markets, bringing our advanced document processing to Myanmar, Cambodia, and beyond.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As Grab transitions to derive more valuable insights from our wealth of operational data, we are witnessing a steep increase in stream-processing applications. Over the past year, the number of Flink applications grew 2.5 times, driven by interest in real-time stream processing and the improved accessibility of developing such applications with Flink SQL. At this scale, it has become crucial for the internal Flink platform team to provide a cost-effective and self-service offering that supports users of diverse backgrounds.
Background: Flink at Grab
Flink at Grab is deployed in application mode, each pipeline has its own isolated resources for JobManager and TaskManager. Flink pipeline creators control both application logic and deployment configuration that affect throughput and performance, including OSS configurations:
Number of TaskManagers and task slots per TaskManager
CPU cores per TaskManager
Memory per TaskManager
As pipeline creation has become more accessible, users of different backgrounds (analyst, data scientist, engineers, etc.) often struggle to choose a set of configurations that work for their applications. Many go through a long process of trial and error and still end up over-provisioning their applications, leading to huge resource waste. Moreover, pipeline behavior changes over time due to changes in application logic or data pattern, invalidating previous efforts in tuning and causing users to repeat the exercise.
In this article, we focus on addressing the challenge of efficient CPU provisioning for TaskManagers, as CPU constraints are a common bottleneck in our clusters. Our solution specifically targets Flink applications sourcing data from our message bus system (eg. Kafka, Change Data Capture Streams, DynamoDB Streams) , which represents the majority of our use cases. These workloads offer significant opportunities for cost savings due to their clear seasonal patterns, making them an ideal starting point for optimising autoscaling strategies.
Limits of reactive autoscaling
Our initial reactive setup
Our first automated solution relied on Flink’s Adaptive Scheduler in Reactive Mode. In this mode, each Flink application is deployed as its own individual Flink cluster running a dedicated job. The cluster greedily uses all available TaskManagers and scales its job parallelism accordingly. Running on Kubernetes, the cluster relies on Horizon Pod Autoscaler (HPA) to scale the number of TaskManager pods based on metrics such as CPU usage or custom metrics such as the pipeline’s consumer latency. While this solution was helpful initially, we quickly observed multiple issues with it.
It is important to note that while the below issues can be solved by fine-tuning, it is a tedious trial and error effort that only works for specific applications, requiring users to repeat the process for every pipeline they own.
Restart spike: root cause of many issues
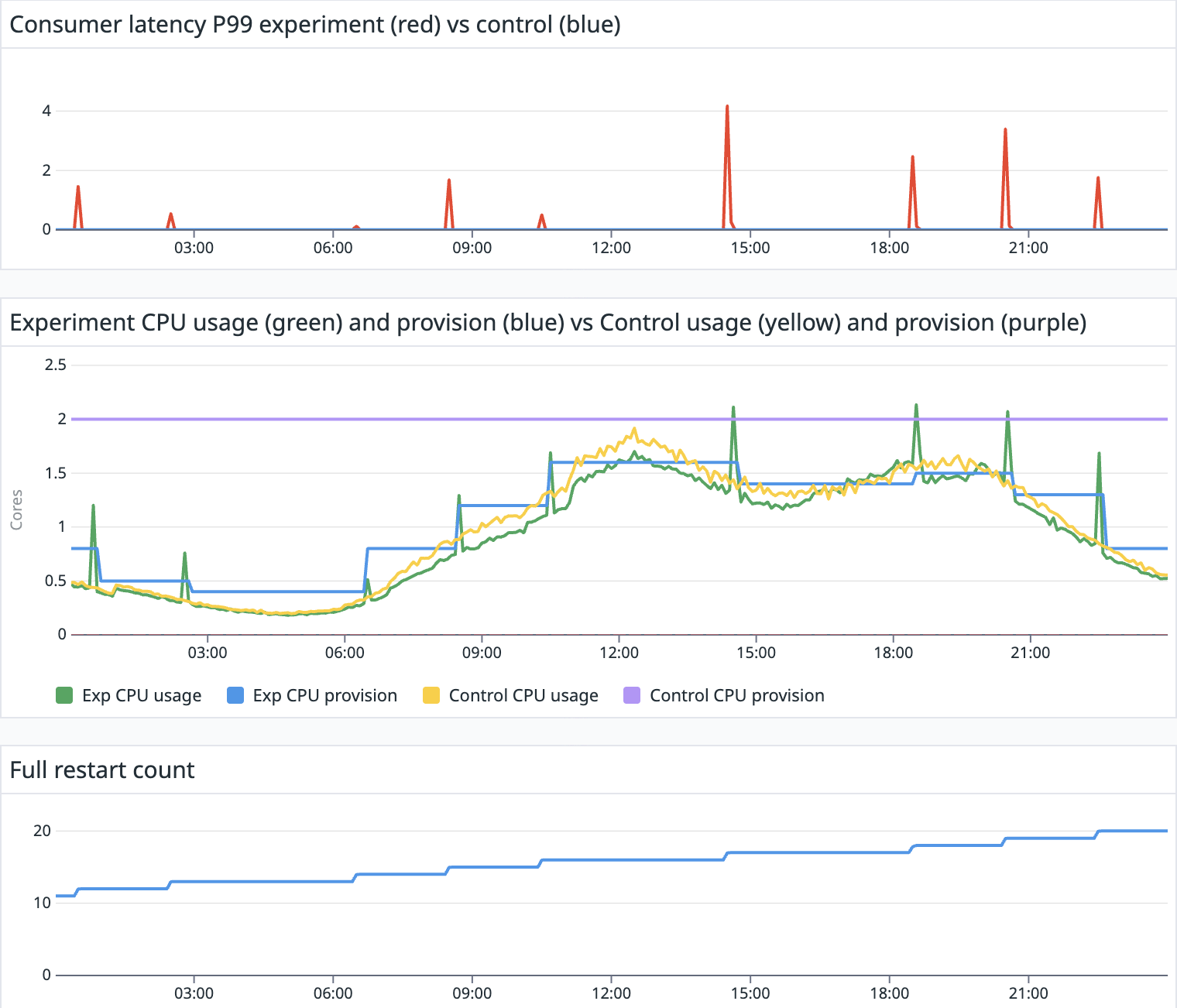
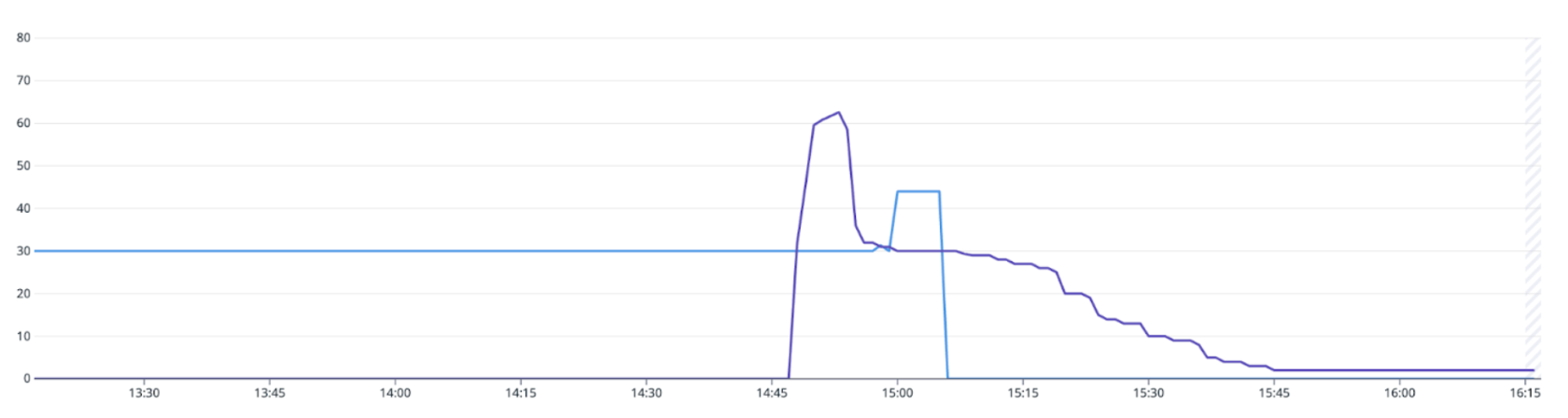
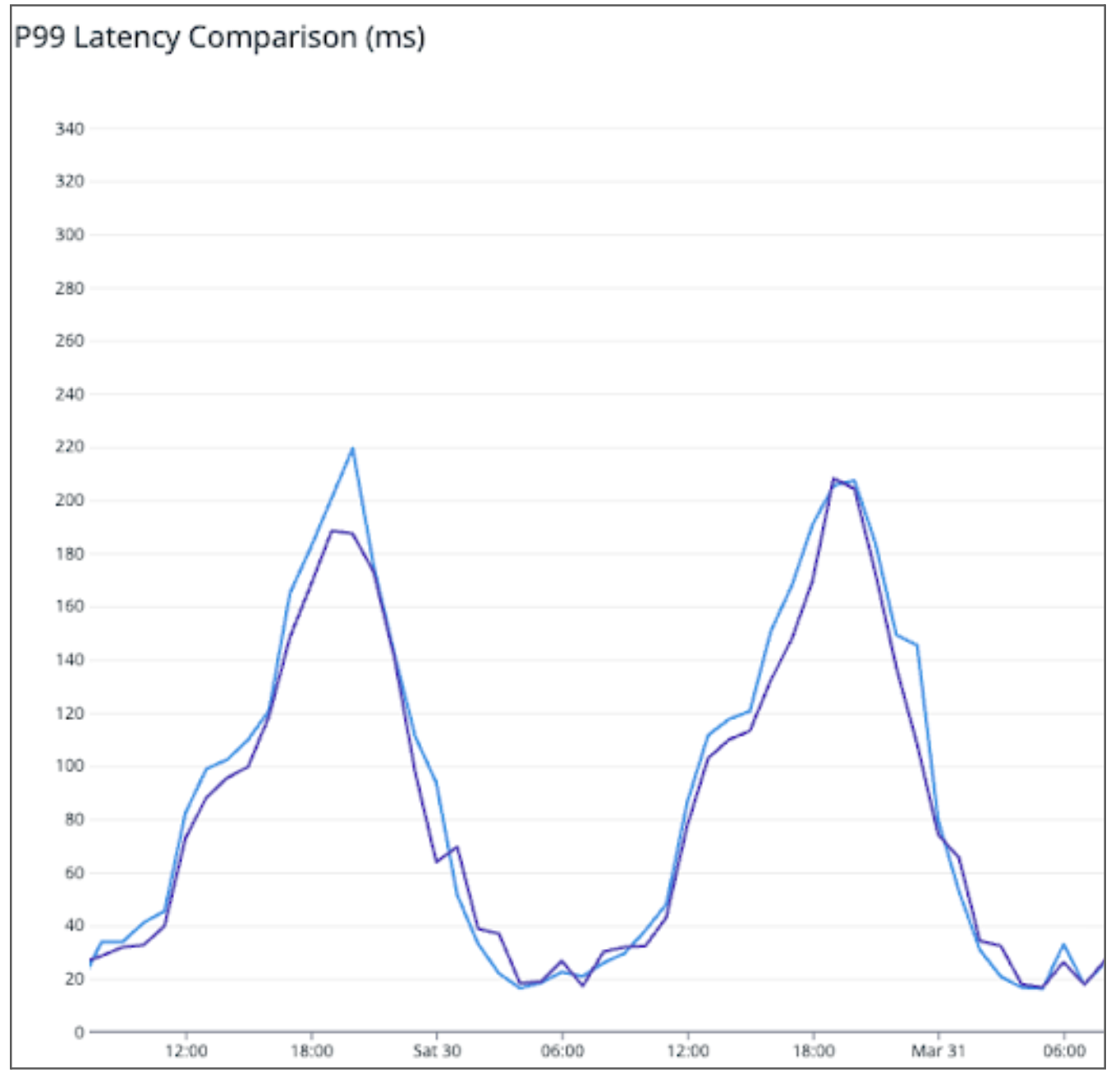
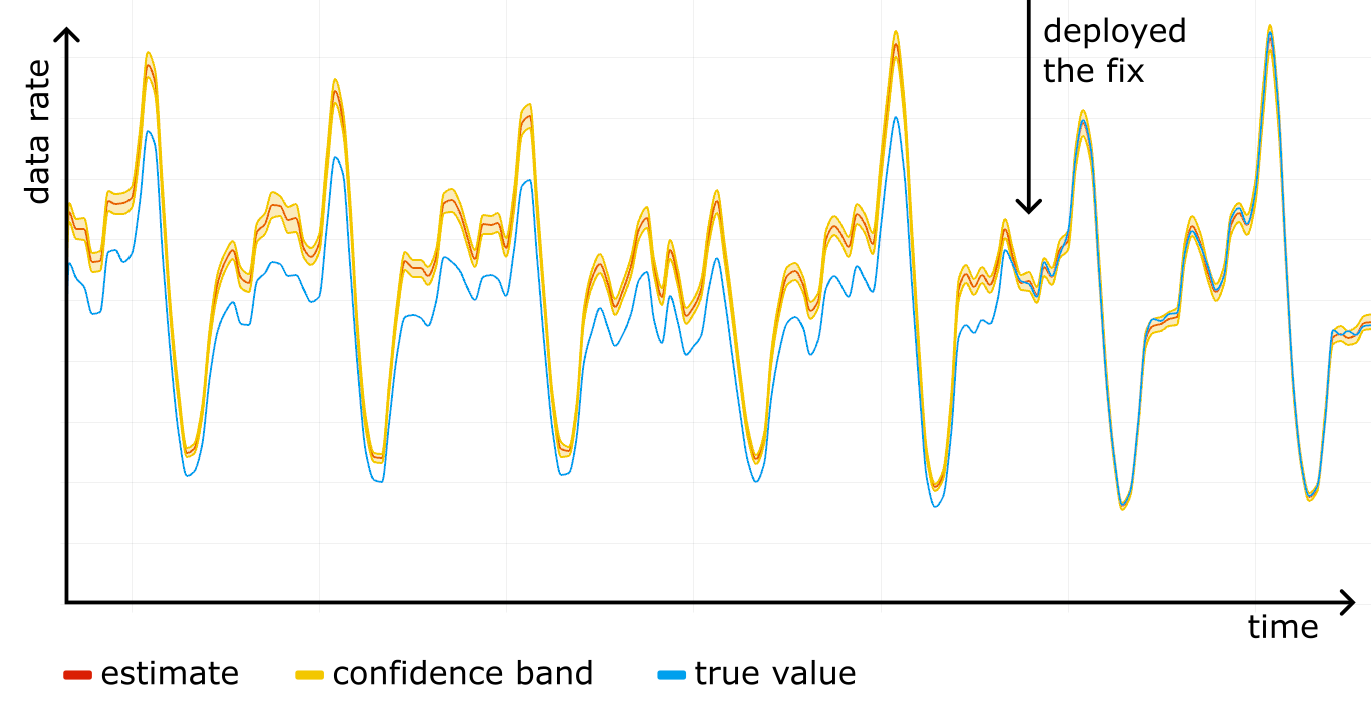
When autoscaling a Flink pipeline, the job restarts from the last checkpoint. This triggers an immediate spike in load, as the pipeline must reprocess records from the period between the last checkpoint and job restart, along with any new records that were backlogged at the source during the downtime. As a result, CPU usage and P99 consumer latency typically spikes after scaling events, for example, at 00:05 and 00:55, as shown in Figure 1. These spikes occur even though there is no change in source topic throughput. In this case, CPU usage surges from 0.5 cores to near provision limit of 2.5 cores, while consumer latency temporarily spiked from sub-second levels to as high as three minutes.
Figure 1: CPU usage and consumer latency spike after a pipeline restart.
Reactive spiral and fluctuation
Typically, HPA scales on metrics such as CPU usage, consumer latency, or backpressure crossing a defined threshold. The challenge arises if these thresholds are misconfigured. The HPA’s reactive nature, when combined with restart spikes, can become detrimental to your Flink application. It piles additional load onto a system that’s already degrading, further amplifying the problem.
Figure 2: A reactive scaling incident that demonstrates scaling fluctuations and restarts.
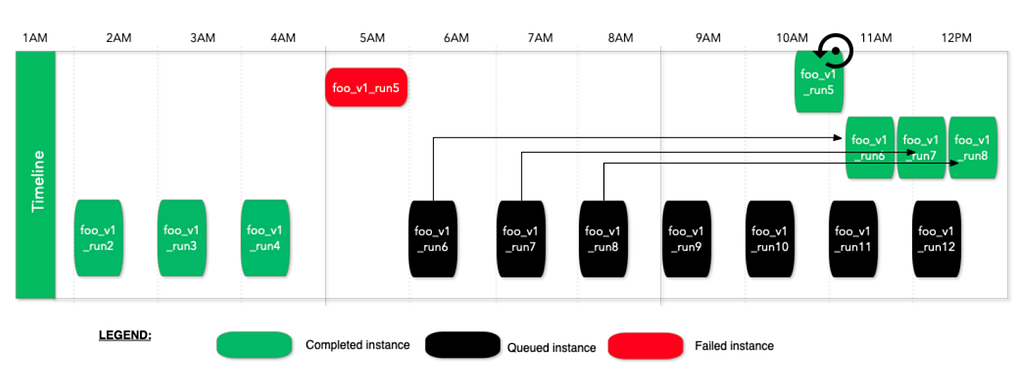
Figure 2 provides us a case study of reactive spiral and fluctuation, assuming we are having a pipeline that consumes a Kafka topic of 300 partitions:
07:00: As the source topic throughput increases, the P99 consumer latency rises due to insufficient processing power.
07:15: Reactive scaling is triggered, resulting in a scale out event. This is reflected in the increased TaskManager and task slot count. The pipeline continues to operate, as there is no increase in restart count.
07:30: As the P99 consumer latency remains high, reactive scaling continues to scale out incrementally. The records in rate by task rises rapidly as the pipeline reprocesses data from the checkpoint. During this period, the pipeline repeatedly restarts CPU usage drops significantly, and P99 consumer latency spikes to nearly one hour. This marks the onset of a spiral failure.
08:00: Reactive scaling reaches its upper limit of 300 slots, corresponding to the number of partitions in the source topic. This halts the spiral effect as it cannot scale out any further. Without disruption from autoscaling restart, the pipeline begins to process the backlog since the last successful checkpoint, as observed by the significant increase in records in rate by task. As the pipeline catches up, it eventually stabilizes, and the P99 consumer latency returns to normal levels.
08:30 – 10:15: The P99 consumer latency returns to normal levels, below the threshold. Reactive scaling triggers scale-in events despite the source topic throughput continuing to trend upward. During these scale-in events, P99 latency fluctuates, occasionally spiking up to 15 minutes. However, these fluctuations are not severe enough to prevent the repeated scale in process.
10:15: The P99 consumer latency rises again, triggering a scale-out event back to the upper limit of 300 slots.
11:15-11:45: Despite the source topic throughput maintaining an upward trend, the pipeline undergoes multiple scale-in events in quick succession, encounters latency issues due to reprocessing data from checkpoints, and scales out again shortly after. This is an example of fluctuation after scaling in, resulting in 6 restarts within a 30 minutes window.
Limited parallelism constraints
Even with HPA, we frequently encounter a bottleneck when trying to scale our applications’ throughput. This is primarily because some of our connectors, most notably the Kafka connector, don’t inherently support dynamic parallelism changes.
Kafka topics, by design, have a fixed number of partitions. This directly limits the number of parallel consumers we can run. Consequently, once we reach this maximum parallelism for our consumers, we often have to scale up resources, for example, increase memory/CPU per instance instead of scaling out (adding more instances).
Predictive Resource Advisor
Assumptions and hypothesis
To tackle the issue of reactive spirals and fluctuations, the new solution should have the following characteristics:
Vertical scaling: To tackle the issue of limited parallelism with our dependencies, we should be looking at vertical instead of horizontal scaling.
Predictive: Adjust CPU to scale up or down before demand spikes or dips occur, ensuring the system is prepared for changes in workload. This prevents artificial workload increases caused by processing backlogs on top of actual workload increase, further straining the system.
Deterministic: The CPU configuration must be precisely calculated based on the workload demand, ensuring predictable and consistent resource allocation. For a given workload, the calculated CPU value should remain the same every time, eliminating variability and uncertainty in scaling decisions.
Accurate: Determine the optimal CPU configuration required to handle workload demand in a single, precise calculation, avoiding the inefficiencies of multi-step, trial-and-error tuning.
Key observations
Our solution is conceptualized based on key observations of our Flink applications:
The CPU usage of Flink applications is primarily driven by the input load.
The input load of our Flink applications can be accurately forecasted using time-series forecasting techniques.
Time-based autoscaling that relies solely on historical CPU usage is not robust enough to adapt to evolving workloads. This approach also carries the risk of a negative self-amplifying feedback loop: each autoscaling restart causes a CPU usage spike (as illustrated in Figure 1), which, if anomalies are not properly handled, inflates subsequent CPU calculations.
Model formulation
We then formulate the relationship between CPU usage and input load using a regression model to provide a mathematical framework for predicting CPU requirements based on workload patterns, expressed as:
Ct = f(xt)
In this equation:
Ct represents the CPU required at a specific point in time.
xt represents the input workload at the corresponding point in time.
f() represents the regression function that maps the input load to the required CPU capacity.
Input load, represented by Kafka source topic throughput in our case, is chosen as the independent variable xt because it reflects true business demand and is entirely independent of Flink consumers. This metric is influenced solely by the business logic of upstream producers and remains unaffected by any changes or behaviors in the Flink consumer pipeline.
Proposed solution
Our predictive autoscaler operates through four key stages as shown in Figure 3.
Figure 3: The predictive autoscaling system operates through four key stages.
Stage 1: Workload forecast model
The workload forecast model is a time-series forecasting model trained on actual workload data, specifically source topic throughput from our Kafka cluster (1). This approach is particularly effective as our workload exhibits seasonal patterns. While historical data could be directly used as input for CPU prediction, time-series forecasting offers a more robust solution by enabling the model to account for organic traffic growth over time. Through periodic retraining, the model adapts to evolving workload trends, ensuring more accurate and reliable predictions for resource provisioning.
Stage 2: Resource prediction model
This follows the regression-based model Ct = f(xt) defined earlier. We use the same source topic throughput from our Kafka cluster (2a) as input feature xt, and the Flink application’s Kubernetes CPU usage metric (2b) as output label Ct for model training. To ensure clean and representative data for model training, we collect CPU usage metrics under conditions that simulate infinite resource availability. We include data exclusively from periods of continuous and stable operation, as determined by latency, uptime, and restart metrics (2b), eliminating biases caused by hardware limitations or disruptions.
Stage 3: Workload forecasting
To prepare for autoscaling, we forecast the workload for the future t-hour window (3) using our trained time-series forecast model.
Stage 4: Predict CPU usage
The forecasted workload (3) is fed into the resource prediction model to estimate the CPU usage required to handle that workload. The predicted value is then refined using custom safety feature adjustments to account for variability and ensure stability. This adjusted prediction is passed to the custom autoscaler controller, which evaluates the current CPU configuration of the TaskManager deployment. If the adjusted predicted value differs from the existing CPU configuration, the controller initiates vertical scaling to update the TaskManager deployment accordingly.
Proof of concept and results
Experiment setup
To validate our hypothesis, we present a deep dive into one of our experiments. This pipeline features complex business logic, aggregates from multiple Kafka sources, with a checkpoint interval of one minute and a maximum consumer latency of five minutes.
We set up an experimental pipeline with configurations identical to the production pipeline (the control). Both applications sourced data from the same Kafka topics but sank data to alternative topics to maintain isolation. The Predictive Resource Advisor was enabled on the experimental pipeline, while the control pipeline operated with fixed CPU provisioning.
Results
Figure 4 demonstrates a strong correlation between CPU usage (yellow, green) and the total Kafka topics throughput. The variable CPU provisioning (blue) for the experimental pipeline is calculated by our autoscaler models, which were trained exclusively on data collected from the experiment pipeline. The CPU usage trend of the experimental pipeline closely mirrors that of the control pipeline and remains aligned with the Kafka throughput trend. However, the experimental pipeline’s CPU provisioning is dynamically adjusted to more closely match its actual CPU usage, whereas the control pipeline maintains a static CPU allocation (purple). This illustrates the model’s effectiveness in dynamically adjusting CPU allocation to meet variable workload demands.
Figure 4: CPU usage closely correlates with source throughput for both the experimental and control pipelines.
Without autoscaler enabled, the control pipeline experienced no disruptions and maintained latency (blue) consistently below one second, which is not visible in Figure 5. On the other hand, the experiment pipeline latency (red) experienced a highest recorded peak latency of just over four minutes during a single disruption window. Other latency spikes observed were comparable to or lower than the three minutes peak latency previously identified as part of the restart spike issue analysis. The varied durations and amplitudes of these spikes showed some correlation with the heavy Kafka topic throughput during those periods. Importantly, there were only nine autoscaling events throughout the day, resulting in nine restarts for the experiment pipeline.
Figure 5: Autoscaling impacts service-level agreement requirements through latency spikes during scaling events.
Outcome
The Predictive Resource Advisor solution has been successfully deployed across more than 50% of applicable production applications, specifically those consuming from Kafka topics and exhibiting seasonal workload patterns with some tolerance for disruptions. This implementation has delivered significant results across three key areas, stability, efficiency, and user experience.
Stability
With autoscaling becoming more predictable and controllable, our Flink applications experience fewer disruptions caused by autoscaling fluctuations. The machine learning and predictive capabilities of the solution also ensure that applications remain operational during periods of increased workload by automatically learning and adapting to organic growth trends and workload surges.
Efficiency
Applications powered by the Predictive Resource Advisor demonstrated significant improvements in CPU provisioning, aligning CPU configuration more closely with actual requirements, particularly during low traffic periods. As a result of this optimization, on average, these applications made approximately >35% savings in cloud infrastructure cost.
User experience
The solution has simplified the deployment process for users, allowing them to simply deploy Flink applications with default configurations. The Predictive Resource Advisor automatically collects data, trains autoscaling models, and applies configuration changes, thus eliminating the need for manual fine-tuning. This significantly enhances the user experience by streamlining pipeline maintenance and enabling self-service capabilities, such as effortless onboarding. It empowers users to explore and derive value from real-time features with minimal effort.
What’s next?
Our journey doesn’t stop here. We’re continuously working to enhance our predictive autoscaler, with the following key areas of focus:
Tackling memory configuration (Predictive Resource Advisor’s next frontier)
Memory is critical yet often misconfigured that can lead to unrecoverable failures for example, OOMKilled. Our next major goal for the Predictive Resource Advisor is to take on memory tuning, completely removing the burden of complex memory configuration from our users and further empowering them.
Enhancing model accuracy
To further improve the robustness of our predictions, we are actively exploring advanced techniques in input feature engineering and anomaly detection, especially for workloads exhibiting frequent bursting patterns. By refining these aspects, we aim to extend the applicability of our solution to a broader range of Flink applications, including those connected to diverse sources such as change data capture systems or batch-like, spiky workloads, such as the Flink applications powering our real-time data lake.
Streamlining model training
We’re developing a more efficient model training workflow. A particularly exciting avenue we’re investigating is the use of pretrained time-series forecasting models based on large language model architectures.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Catwalk is Grab’s machine learning (ML) model serving platform, designed to enable data scientists and engineers in deploying production-ready inference APIs. Currently, Catwalk powers hundreds of ML models and online deployments. To accommodate this growth, the platform has adapted to the rapidly evolving machine learning technology landscape. This involved progressively integrating support for multiple frameworks such as ONNX, PyTorch, TensorFlow, and vLLM. While this approach initially worked for a limited number of frameworks, it soon became unsustainable as maintaining various inference engines, ensuring backward compatibility, and managing deprecated legacy components (such as the ONNX server) introduced significant technical debt. Over time, this resulted in degraded platform performance: with increased latency, reduced throughput, and escalating costs. These issues began to impact users, as larger models could no longer be served efficiently or cost-effectively by legacy components. Recognising the need for change, the team revisited the platform’s design to address these challenges.
Evaluation and implementation
After evaluating other industry-leading model serving platforms and studying best practices, we decided to conduct an in-depth analysis of NVIDIA Triton. Triton offers significant advantages as an inference engine, including:
Multi-framework support: Compatibility with major ML frameworks, including ONNX, PyTorch, and TensorFlow, ensuring versatility and broad applicability.
Unified inference interface: Provides a single, consistent API for various ML frameworks, simplifying user interaction and reducing overhead when switching between models or frameworks.
Hardware optimisation: Optimised for NVIDIA GPUs, Triton delivers strong performance on CPU-only environments and specialised instances like AWS Inferentia.
Up-to-date support: Continuously updated by upstream to support the latest optimisation and features from upstream ML frameworks, ensuring access to cutting-edge capabilities.
Advanced inference features: Includes capabilities like dynamic batching and model ensembling (model pipelining), which enhances throughput and efficiency for complex ML workflows.
Our extensive benchmarking demonstrated that NVIDIA Triton delivers substantial enhancements in both performance and service stability compared to our existing solutions.
We are now working towards consolidating the various inference engines we manage into a unified, all-in-one Triton engine, beginning with ONNX adoption as the first phase of implementation.
In this blog, we aim to share our journey of adopting Triton. From initial benchmarking results on one of Grab’s core models facing performance challenges, to the development of the “Triton manager”, a component designed to integrate Triton into our platform seamlessly and with minimal user disruption. Ultimately, more than 50% of online deployments were successfully migrated to Triton, with some of our critical systems achieving a 50% improvement in tail latency.
Exploratory benchmark results
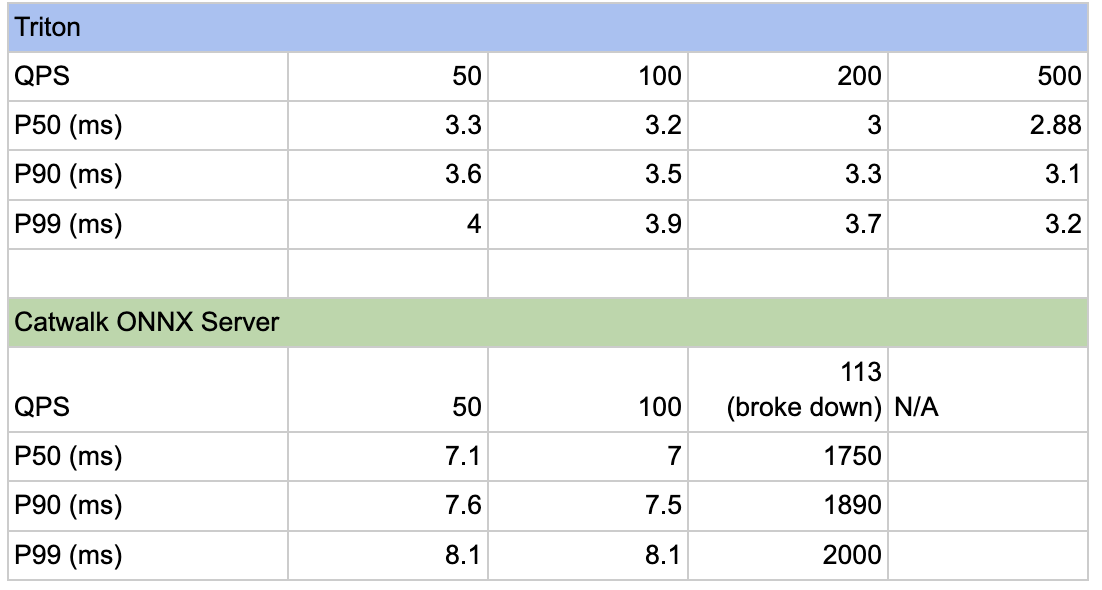
We conducted rigorous testing of Triton against our existing ONNX server under varying levels of request traffic.
Table 1: Benchmark results of Triton against Catwalk ONNX server.
During testing with a transformer-based model, Triton demonstrated the ability to handle at least 5 times the traffic while maintaining excellent latency. Additionally, its performance was further enhanced with features like batching enabled, and there is potential for even greater optimisation by converting the model to TensorRT, leveraging GPU support.
Through profiling, we learned that a handful of ONNX Runtime knobs have an outsized impact on throughput. One low-effort, high-return tweak is to set the intra-op thread count to match the number of physical CPU cores. In most cases, this single change yields a healthy performance lift, sparing us from time-consuming, model-by-model micro-optimisation.
Adopting Triton at scale
While the benchmark results clearly demonstrate Triton’s advantages, the primary challenge was ensuring a seamless migration, ideally with minimal user reactions. Given the high frequency of migrations within our company, even exceptional performance improvements are often insufficient to fully motivate internal users to adopt new systems. From our point of view, a successful migration required:
Maintaining API compatibility with existing systems.
Ensuring zero-downtime.
Preserving all existing functionality while adding new capabilities.
Minimising disruption to downstream services and users.
To streamline the migration process, we opted to manage it centrally within our platform, rather than relying on individual users to address the details themselves.
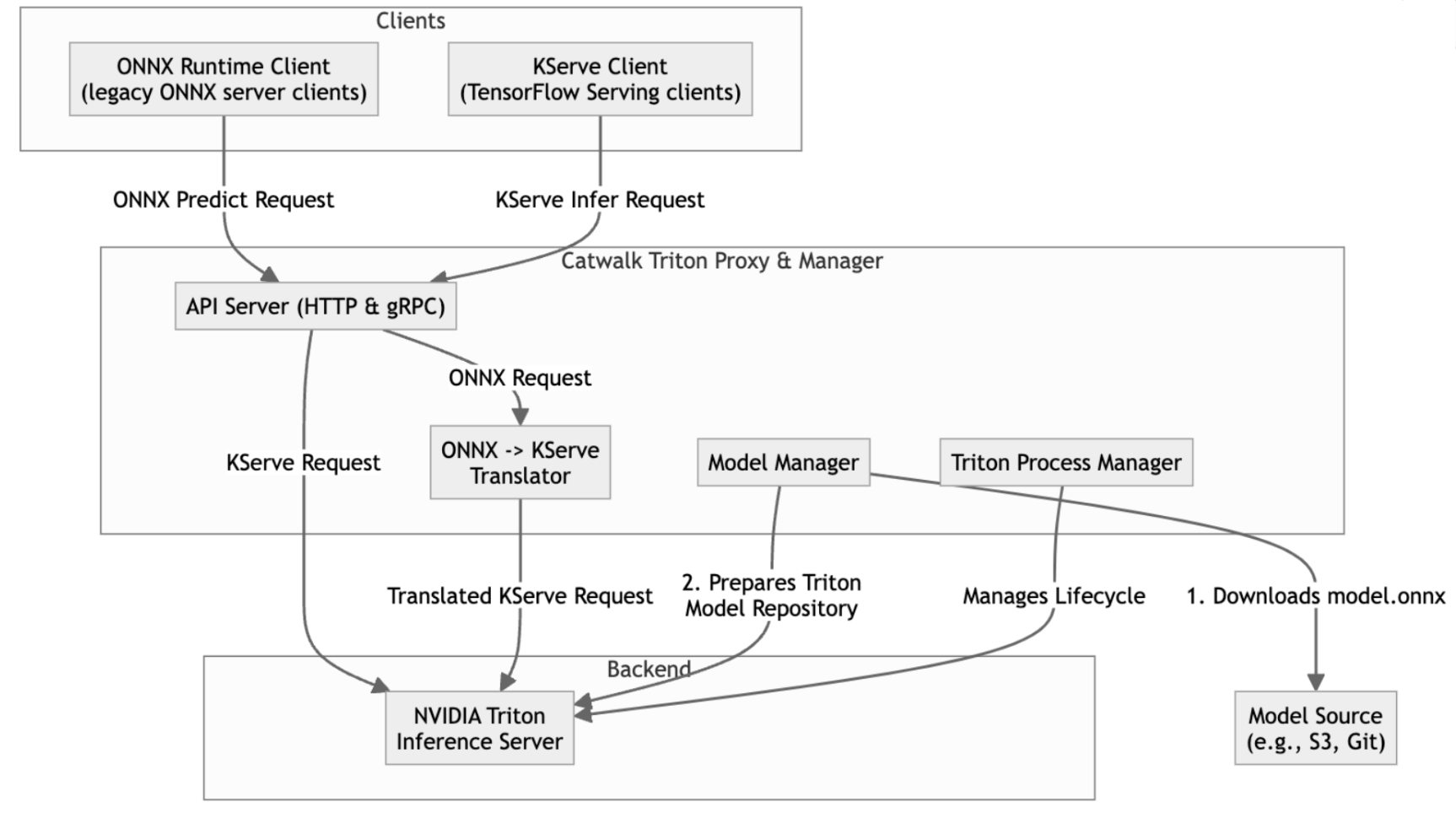
We landed on the idea of offering Triton to our users as a drop-in replacement for the old server, with the help of a new component, “Triton manager”. The Triton manager is a critical component that glues Triton to the Catwalk ecosystem. It consists of two major components: Triton server manager and Triton proxy.
Triton server manager is designed as the entry point of our Catwalk Triton. It downloads the model from remote storage, runs verification on the model files, prepares per-model configurations based on users’ customisation, and lastly it launches the Triton server. It also periodically checks the server’s health and provides observability overlooking the server’s status.
Triton proxy provides backward compatibility to the existing clients. It hosts endpoints that translate requests from the older API and forward them to the Triton server. The proxy layer plays a crucial role in facilitating a seamless transition from our legacy servers, eliminating the need for user code changes. The conversion logic is designed to prioritise performance, ensuring minimal overhead. Extensive benchmarks were conducted during development to validate and optimise its efficiency.
Figure 1: High-level architecture for Triton Inference Server (TIS) deployment at Catwalk.
Finally, a special mode in the Triton server manager is implemented to allow the Triton Inference Server (TIS) to be backward compatible with the command line interface of the existing ONNX runtime server used in Catwalk.
We plan to enhance the Triton Manager to ensure backward compatibility with other ML frameworks, as part of our efforts to onboard additional frameworks seamlessly.
Rollout result
Within just 10 days of Triton’s availability, we successfully rolled it out to over 50% of our online model deployments. Thanks to rigorous testing for backward compatibility, the rollout was seamless, with most users unaware of the transition while benefiting from the improved performance.
Triton’s impacts on critical models
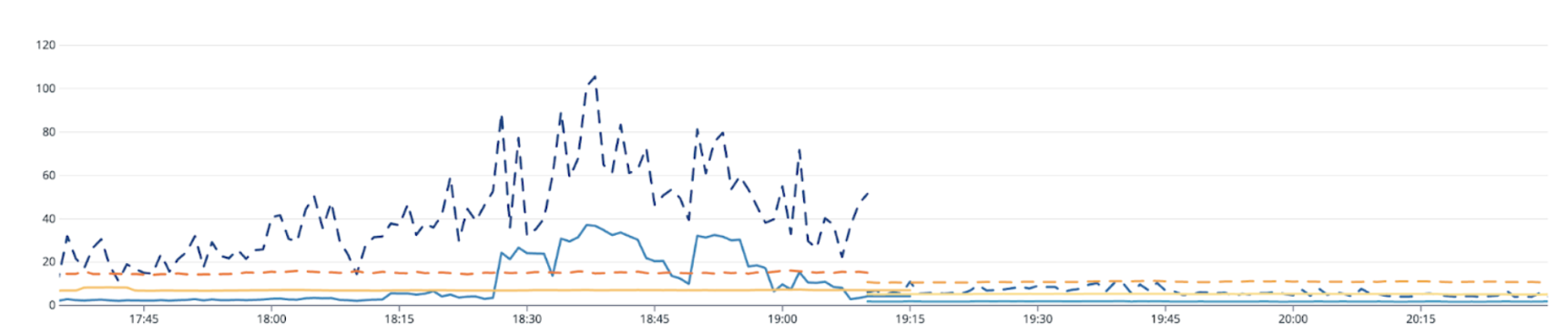
Figure 2: Latency before and after rollout in ms. Blue line: XGBoost-based model. Orange line: transformer-based model. Solid line: average. Dashed line: p99
We’ve observed significant performance improvements in our business-critical models that have high demands for stability. Latency improvements were consistently observed in all models, especially in the models that suffered from highly volatile request traffic. For some larger transformer models, the p90 latency decreased dramatically from 120ms to 20ms, and the average latency remained steady at 4ms. Smaller XGBoost models maintained their average latency at 2ms across regions.
Figure 3: Number of pods, before (blue line) and after (purple line) rollout in another model.
Triton has delivered significant cost savings for certain models, with some achieving over 90% reductions due to its advanced optimisations. These improvements have come alongside enhanced performance and reliability.
It is worth noting that Triton was initially rolled out with limited capabilities to prioritise backward compatibility and ensure a seamless migration. However, we’ve noticed that higher tail latency still remains an issue when facing request spikes for larger models in production. To address this, we are working on enabling batching through Triton to minimise tail latency during traffic surges. This effort will involve close collaboration with model owners to optimise the capacity of each Triton instance further.
Early cost impact of the migration
To gauge the financial upside of migrating to Triton, we took a snapshot of 11 production ML services that had already completed the migration. For every ML service, we compared its infrastructure spend over the 14 days before the cut-over with the 14 days after.
Despite the staggered migration dates, the trend was uniform: average spend fell by ~ 20% across this small cohort within 14 days. As more models and applications migrate, we expect the absolute dollar savings to scale proportionally.
Takeaways
Initial results are aligned with our benchmarks for the Triton migration. With improved performance and cost reduction, we expect model owners to either upgrade their model sizes or allow for higher Queries Per Second (QPS). While making further progress with the overall Triton migration, the model serving platform team will continue to monitor cost differences and provide consultation to model owners who seek further optimisation for their deployments.
Another key takeaway is the painless migration of Triton for our internal users. Rather than asking internal users to make necessary code changes, our team dedicated significant time to providing Triton as a drop-in inference engine to minimise any inconvenience of migration.
Big appreciation to Shengwei Pang from the Geo team, Khai Hung Do, Nhat Minh Nguyen, and Siddharth Pandey from the Catwalk team, along with Richard Ryu from the PM team and Padarn George Wilson for the sponsorship.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
We recently upgraded the Maestro engine to go beyond scalability and improved its performance by 100X! The overall overhead is reduced from seconds to milliseconds. We have updated the Maestro open source project with this improvement! Please visit the Maestro GitHub repository to get started. If you find it useful, please give us a star.
Introduction
In our previous blog post, we introduced Maestro as a horizontally scalable workflow orchestrator designed to manage large-scale Data/ML workflows at Netflix. Over the past two and a half years, Maestro has achieved its design goal and successfully supported massive workflows with hundreds of thousands of jobs, managing millions of executions daily. As the adoption of Maestro increases at Netflix, new use cases have emerged, driven by Netflix’s evolving business needs, such as Live, Ads, and Games. To meet these needs, some of the workflows are now scheduled on a sub-hourly basis. Additionally, Maestro is increasingly being used for low-latency use cases, such as ad hoc queries, beyond traditional daily or hourly scheduled ETL data pipeline use cases.
While Maestro excels in orchestrating various heterogeneous workflows and managing user end-to-end development experiences, users have experienced noticeable speedbumps (i.e. ten seconds overhead) from the Maestro engine during workflow executions and development, affecting overall efficiency and productivity. Although being fully scalable to support Netflix-scale use cases, the processing overhead from Maestro internal engine state transitions and lifecycle activities have become a bottleneck, particularly during development cycles. Users have expressed the need for a high performance workflow engine to support iterative development use cases.
To visualize our end users’ needs for the workflow orchestrator, we create a 5-layer structure graph shown below. Before the change, Maestro reached level 4 but faced challenges to satisfy the user’s needs in level 5. With the new engine design, Maestro is able to power the users to work with their highest capacity and spark joy for end users during their development over the Maestro.
Figure 1. A 5-layer structure showing needs for the workflow orchestrator.
In this blog post, we will share our new engine details, explain our design trade-off decisions, and share learnings from this redesign work.
Architectural Evolution of Maestro
Before the change
To understand the improvements, we will first revisit the original architecture of Maestro to understand why the overhead is high. The system was divided into three main layers, as illustrated in the diagram below. In the sections that follow we will explain each layer and the role it played in our performance optimization.
Figure 2. The architecture diagram before the evolution.
Maestro API and Step Runtime Layer
This layer offers seamless integrations with other Netflix services (e.g., compute engines like Spark and Trino). Using Maestro, thousands of practitioners build production workflows using a paved path to access platform services . They can focus primarily on their business logic while relying on Maestro to manage the lifecycle of jobs and workflows plus the integration with data platform services and required integrations such as for authentication, monitoring and alerting. This layer functioned efficiently without introducing significant overhead.
Maestro Engine Layer
The Maestro engine serves several crucial functions:
Managing the lifecycle of workflows, their steps and maintaining their state machines
Supporting all user actions (e.g., start, restart, stop, pause) on workflow and step entities
Translating complex Maestro workflow graphs into parallel flows, where each flow is an array of sequentially chained flow tasks, translating every step into a flow task, and then executing transformed flows using the internal flow engine
Acting as a middle layer to maintain isolation between the Maestro step runtime layer and the underlying flow engine layer
Implementing required data access patterns and writing Maestro data into the database
In terms of speed, this layer had acceptable overhead but faced edge cases (e.g. a step might be concurrently executed by two workers at the same time, causing race conditions) due to lacking a strong guarantee from the internal flow engine and the external distributed job queue.
Maestro Internal Flow Engine Layer
The Maestro internal flow engine performed 2 primary functions:
Calling task’s execution functions at a given interval.
Starting the next tasks in an array of sequential task flows (not a graph), if applicable.
This foundational layer was based on Netflix OSS Conductor 2.x (deprecated since Apr 2021), which requires a dedicated set of separate database tables and distributed job queues.
The existing implementation of this layer introduces an impactful overhead (e.g. a few seconds to tens of seconds overall delays). The lack of strong guarantees (e.g. exactly once publishing) from this layer leads to race conditions which cause stuck jobs or lost executions.
Options to consider
We have evaluated three options to address those existing issues:
Option 1: Implement an internal flow engine optimized for Maestro specific use cases
Option 2: Upgrade Conductor library to 4.0, which addresses the overheads and offers other improvements and enhancements compared with Conductor 2.X.
Option 3: Use Temporal as the internal flow engine
One aspect that influenced our assessment of option two is that Conductor 2 provided a final callback capability in the state machine that was contributed specifically for Maestro’s use case to ensure database synchronization between the Conductor and Maestro engine states. It would require porting this functionality to Conductor 4 though it had been dropped given no other Conductor use cases besides Maestro relied on this. By rewriting the flow engine it would allow removal of several complex internal databases and database synchronization requirements which was attractive for simplifying operational reliability. Given Maestro did not need the full set of state engine features offered by Conductor, this motivated us to consider a flow engine rewrite as a higher priority.
The decision for Temporal was more straightforward. Temporal is optimized towards facilitating inter-process orchestration and would involve calling an external service to interact with the Temporal flow engine. Given Maestro is operating greater than a million tasks per day, many of which are long running, we felt it was an unnecessary source of risk to couple the DAG engine execution with an external service call. If our requirements went beyond lightweight state transition management we might reconsider because Temporal is a very robust control plane orchestration system, but for our needs it introduced complexity and potential reliability weak spots when there was no direct need for the advanced feature set that it offered.
After considering Option 2 and Option 3, we developed more conviction that Maestro’s architecture could be greatly simplified by not using a full DAG evaluation engine and having to maintain the state machine for two systems (Maestro and Conductor/Temporal). Therefore, we have decided to go with Option 1.
After the change
To address these issues, we completely rewrote the Maestro internal flow engine layer to satisfy Maestro’s specific needs and optimize its performance. This new flow engine is lightweight with minimal dependencies, focusing on excelling in the two primary functions mentioned above. We also replaced existing distributed job queues with internal ones to provide a strong guarantee.
The new engine is highly performant, efficient, scalable, and fault-tolerant. It is the foundation for all upper components of Maestro and provides the following guarantees to avoid race conditions:
A single step should only be executed by a single worker at any given time
Step state should never be rolled back
Steps should always eventually run to a terminal state
The internal flow state should be eventually consistent with the Maestro workflow state
External API and user actions should not cause race conditions on the workflow execution
Here is the new architecture diagram after the change, which is much simpler with less dependencies:
Figure 3. The architecture diagram after the evolution.
New Flow Engine Optimization
The new flow engine significantly boosts speed by maintaining state in memory. It ensures consistency by using Maestro engine’s database as the source of truth for workflow and step states. During bootstrapping, the flow engine rebuilds its in-memory state from the database, improving performance and simplifying the overall architecture. This is in contrast to the previous design in which multiple databases had to be reconciled against one another (Conductor’s tables and Maestro’s tables) or else suffer race conditions and rare orphaned job status.
The flow engine operates on in-memory flow states, resembling a write through caching pattern. Updates to workflow or step state in the database also update the in-memory flow state. If in-memory state is lost, the flow engine rebuilds it from the database, ensuring eventual consistency and resolving race conditions.
This design delivers lower latency and higher throughput, avoids inconsistencies from dual persistence, simplifies the architecture, and keeps the in‑memory view eventually consistent with the database.
Maintaining Scalability While Gaining Speed
With the new engine, we significantly boost performance by collocating flows and their tasks on the same node throughout their lifecycle. Therefore, states of a flow and its tasks will stay in a single node’s memory without persisting to the database. This stickiness and locality bring great performance benefits but inevitably impact scalability since tasks are no longer reassigned to a new worker of the whole cluster in each polling cycle.
To maintain horizontal scalability, we introduced a flow group concept to partition running flows into groups. In this way, each Maestro flow engine instance only needs to maintain ownership of groups rather than individual flows, reducing maintenance costs (e.g., heartbeat) and simplifying reconciliation by allowing each Maestro node to load flows for a group in batches. Each Maestro node claims ownership of a group of flows through a flow group actor and manages their entire lifecycle via child flow actors. If ownership is lost due to node failure or long JVM GC, another node can claim the group to resume flow executions by reconciling internal state from Maestro database. The following diagram illustrates the ownership maintenance.
Figure 4. Ownership maintenance sequence diagram.
Flow Partitioning
To efficiently distribute traffic, Maestro assigns a consistent group ID to flows/workflows by a simple stable ID assignment method, as shown in the diagram’s Partitioning Function box. We chose this simpler partitioning strategy over advanced ones, e.g. consistent hashing, primarily due to execution and reconciliation costs and consistency challenges in a distributed system.
Since Maestro decomposes workflows into hierarchical internal flows (e.g., foreach), parent flows need to interact with child flows across different groups. To enable this, the maximal group number from the parent, denoted as N’ in the diagram, is passed down to all child flows. This allows child flows, such as subworkflows or foreach iterations, to recompute their own group IDs and also ensures that a parent flow can always determine the group ID of its child flows using only their workflow identifiers.
Figure 5. Flow group partitioning mechanism diagram.
After a flow’s group ID is determined, the flow operator routes the flow request to the appropriate node. Each node owns a specific range of group IDs. For example, in the diagram, Node 1 owns groups 0, 1, and 2, while Node 3 owns groups 6, 7, and 8. The groups then contain the individual flows (e.g., Flow A, Flow B).
In this design, the group size is configurable and nodes can also have different group size configurations. The following diagram shows a flow group partitioning example while the maximal group number is changed during the engine execution without impacting any existing workflows.
Figure 6. A flow group partitioning example.
In short, Maestro flow engine shares the group info across the parent and child workflows to provide a flexible and stable partitioning mechanism to distribute work across the cluster.
Queue Optimization
We replaced both external distributed job queues in the existing system with internal ones, preserving the same fault‑tolerance and recovery guarantees while reducing latency and boosting throughput.
For the internal flow engine, the queue is a simple in‑memory Java blocking queue. It requires no persistence and can be rebuilt from Maestro state during reconciliation.
For the Maestro engine, we implemented a database‑backed in‑memory queue that provides exactly‑once publishing and at‑least‑once delivery guarantees, addressing multiple edge cases that previously required manual state correction.
This design is similar to the transactional outbox pattern. In the same transaction that updates Maestro tables, a row is inserted into the `maestro_queue` table. Upon transaction commit, the job is immediately pushed to a queue worker on the same node, eliminating polling latency. After successful processing, the worker deletes the row from the database. A periodic sweeper re-enqueues any rows whose timeout has expired, ensuring another worker picks them up if a worker stalls or a node fails.
This design handles failures cleanly. If the transaction fails, both data and message roll back atomically, no partial publishing. If a worker or node fails after commit, the timeout mechanism ensures the job is retried elsewhere. On restart, a node rebuilds its in‑memory queue from the queue table, providing at-least-once delivery guarantee.
To enhance scalability and avoid contention across event types, each event type is assigned a `queue_id`. Job messages are then partitioned by `queue_id`, optimizing performance and maintaining system efficiency under high load.
From Stateless Worker Model to Stateful Actor Model
Maestro previously used a shared-nothing stateless worker model with a polling mechanism. When a task started, its identifier was enqueued to a distributed task queue. A worker from the flow engine would pick the task identifier from the queue, load the complete states of the whole workflow (including the flow itself and every task), execute the task interface method once, write the updated task data back to the database, and put the task back in the queue with a polling delay. The worker would then forget this task and start polling the next one.
That architecture was simple and horizontally scalable (excluding database scalability considerations), but it had drawbacks. The process introduced considerable overhead due to polling intervals and state loading. The time spent in one polling cycle on distributed queues, loading complete states, and other DB queries was significant.
As Maestro engine decomposes complex workflow graphs into multiple flows, actions might involve multiple flows spanning multiple polling cycles, adding up to significant overhead (around ten seconds in the worst cases). Also, this design didn’t offer strong execution guarantees mainly because the distributed job queue could only provide at-least-once guarantees. Tasks might be dequeued and dispatched to multiple workers, workers might reset states in certain race conditions, or load stale states of other tasks and make incorrect decisions. For example, after a long garbage-collection pause or network hiccup, two workers can pick up the same task: one sets the task status as completed and then unblocks the downstream steps to move forward. However, the other worker, working off stale state, resets the task status back to running, leaving the whole workflow in a conflicting state.
In the new design, we developed a stateful actor model, keeping internal states in memory. All tasks of a workflow are collocated in the same Maestro node, providing the best performance as states are in the same JVM.
Actor-Based Model
The new flow engine fits well into an actor model. We also deliberately designed it to allow sharing certain local states (read-only) between parent, child, and sibling actors. This optimization gains performance benefits without losing thread safety due to Maestro’s use cases. We used Java 21’s virtual thread support to implement it with minimal dependencies.
The new actor-based flow engine is fully message/event-driven and can take actions immediately when events are received, eliminating polling interval delays. To maintain compatibility with the existing polling-based logic, we developed a wakeup mechanism. This model requires flow actors and their child task actors to be collocated in the same JVM for communication over the in-memory queue. Since the Maestro engine already decomposes large-scale workflow instances into many small flows, each flow has a limited number of tasks that fit well into memory.
Below is a high-level overview of the Maestro execution flow based on the actor model.
Figure 7. The high level overview of the Maestro execution.
When a workflow starts or during reconciliation, the flow engine inserts (if not existing) or loads the Maestro workflow and step instance from the database, transforming it into the internal flow and task state. This state remains in JVM memory until evicted (e.g., when the workflow instance reaches a terminal state).
A virtual thread is created for each entity (workflow instance or step attempt) as an actor to handle all updates or actions for this entity, ensuring thread safety and eliminating distributed locks and potential race conditions.
Each virtual thread actor contains an in-memory state, a thread-safe blocking queue, and a state machine to update states, ensuring thread safety and high efficiency.
Actors are organized hierarchically, with flow actors managing all their task actors. Flow actors and their task actors are kept in the same JVM for locality benefits, with the ability to relocate flow instances to other nodes if needed.
An event can wake up a virtual thread by pushing a message to the actor’s job queue, enabling Maestro to move toward an event-driven approach alongside the current polling-based approach.
A reconciliation process transforms the Maestro data model into the internal flow data.
Virtual Thread Based Implementation
We chose Java virtual threads to implement various actors (e.g. group actors and flow actors), which simplified the actor model implementation. With a smaller amount of code, we developed a fully functional and highly performant event-driven distributed flow engine. Virtual threads fit very well in use cases like state machine transitions within actors. They are lightweight enough to be created in a large number without Out-Of-Memory risks.
However, virtual threads can potentially deadlock. They’re not suitable for executing user-provided logic or complex step runtime logic that might depend on external libraries or services outside our control. To address this, we separate flow engine execution from task execution logic by adding a separate worker thread pool (not virtual threads) to run actual step runtime business logic like launching containers or making external API calls. Flow/task actors can wait indefinitely for the future of the thread poll executor to complete but don’t perform actual execution, allowing us to benefit from virtual threads while avoiding deadlock issues.
Figure 8. Virtual thread and worker thread separation.
Providing Strong Execution Guarantees
To provide strong execution guarantees, we implemented a generation ID-based solution to ensure that a single flow or task is executed by only one actor at any time, with states that never roll back and eventually reach a terminal state.
When a node claims a new group or a group with an expired heartbeat, it updates the database table row and increments the group generation ID. During node bootstrap, the group actor updates all its owned flows’ generation IDs while rebuilding internal flow states. When creating a new flow, the group actor verifies that the database generation ID matches its in-memory generation ID, otherwise rejecting the creation and reporting a retryable error to the caller. Please check the source code for the implementation details.
Figure 9. An example sequence diagram showing how generation id provides a strong guarantee.
Additionally, the new flow engine supports both event-driven execution and polling-based periodic reconciliation. Event-driven support allows us to extend polling intervals for state reconciliation at a very low cost, while polling-based reconciliation relaxes event delivery requirements to at-most-once.
Testing, Validation and Rollout
Migrating hundreds of thousands of Netflix data processing jobs to a new workflow engine required meticulous planning and execution to avoid data corruption, unexpected traffic patterns, and edge cases that could hinder performance gains. We adopted a principled approach to ensure a smooth transition:
Realistic Testing: Our testing mirrored real-world use cases as closely as possible.
Balanced Approach: We balanced the need for rapid delivery with comprehensive testing.
Minimal User Disruption: The goal was for users to be unaware of the underlying changes.
Clear Communication: For cases requiring user involvement, clear communication was provided.
Maestro Test Framework
To achieve our testing goals, we developed an adaptable testing framework for Maestro. This framework addresses the limitations of static unit and integration tests by providing a more dynamic and comprehensive approach, mimicking organic production traffic. It complements existing tests to instill confidence when rolling out major changes, such as new DAG engines.
The framework is designed to sample real user workflows, disconnecting business logic from external side effects like data reads or writes. This allows us to run workflow graphs of various shapes and sizes, reflecting the diverse use cases across Netflix. While system integrations are handled through deployment pipeline integration tests, the ability to exercise a wide variety of workflow topologies (e.g., parallel executions, for-each jobs, conditional branching and parameter passing between jobs) was crucial for ensuring the new flow engine’s correctness and performance.
The prototype workflow for the test framework focuses on auto-testing parameters, involving two main steps:
1. Caching Production Workflows:
Successful production instances are queried from a historical Maestro feed table over a specified period.
Run parameters, initiator, and instance IDs are extracted and organized into an instance data map.
YAML definitions and subworkflow IDs are pulled from S3 storage.
Both workflow definitions and instance data are cached on S3 for subsequent steps.
2. Pushing, Running, and Monitoring Workflows:
Cached workflow definitions and instance data are loaded.
Notebook-based jobs are replaced with custom notebooks, and certain job types (e.g., vanilla container runtime jobs, templated data movement jobs) and signal triggers are converted to a special no-op job type or skipped.
Abstract job types like Write-Audit-Publish are expressed as a single step template but are translated to multiple reified nodes of the DAG when executed. These are auto-translated into several custom notebook job types to replace the generated nodes.
Workflows and subworkflows are pushed, with only non-subworkflows being run using original production instance information.
1. In the parent workflow, each sub-workflow is replaced with a special no-op placeholder so that the overall topology is preserved but without executing any side-effects of child workflows and avoid cases using dynamic runtime parameter logic.
2. Each sub-workflow is then separately treated like a top-level parent workflow not initiated from its parent, to exercise the actual workflow steps of the sub-workflow.
The custom notebook internally compares all passed parameters for each job.
Workflow instances are monitored until termination (success or failure).
An email detailing failed workflow instances is generated.
Future phases of the test framework aim to expand support for native steps, more templates, Titus and Metaflow workflows, and include more robust signal testing. Further integration with the ecosystem, including dedicated Genie clusters for no-op jobs and DGS for our internal workflow UI feature verification, is also being explored.
Rollout Plan
Our rollout strategy prioritized minimal user disruption. We determined that an entire workflow, from its root instance, must reside in either the old or new flow engine, preventing mixed operations that could lead to complex failure modes and manual data reconciliation.
To facilitate this, we established a parallel infrastructure for the new workflow engine and leveraged our orchestrator gateway API to hide any routing or redirection logic from users. This approach provided excellent isolation for managing the migration. Initially, specific workflows could explicitly opt in via a system flag, allowing us to observe their execution and gain confidence. By scaling up traffic to the parallel infrastructure in direct proportion to what was scaled down from the original infrastructure, the dual infrastructure cost increase was negligible.
Once confident, we transitioned to a percentage-based cutover. In the event of a sustained failure in the new engine, our team could roll back a workflow by removing it from the new engine’s database and restarting it in the original stack. However, one consequence of rollback was that failed workflows had to restart from the beginning, recomputing previously successful steps, to ensure all artifacts were generated from a consistent flow engine.
Leveraging Maestro’s 10-day workflow timeout, we migrated users without disruption. Existing executions would either complete or time out. Upon restarting (due to failure/timeout) or triggering a new instance (due to success), the workflow would be picked up by the new engine. This effectively allowed us to gradually “drain” traffic from the old engine to the new one with no user involvement.
While the plan generally proceeded as expected with limited edge cases, we did encounter a few challenges:
Stuck Workflows: Around 50 workflows with defunct or incorrect ownership information entered a stuck state. In some cases, a backlog of queued instances behind a stuck instance created a race condition in which a new instance would be started immediately when an old instance was terminated, perpetually keeping the workflow on the old engine. For these, we proactively contacted users to negotiate manual stop-and-restart times, forcing them onto the new engine.
Configuration Discrepancies: A significant lesson learned was the importance of meticulous record-keeping and management of parallel infrastructure components. We discovered alerts, system flags, and feature flags configured for one stack but not the other. This led to a failure in a partner team’s system that dynamically rolled out a Python migration by analyzing workflow configurations. The absence of a required feature flag in the new engine stack caused the process to be silently skipped, resulting in incorrect Python version configurations for about 40 workflows. Although quickly remediated, this caused user inconvenience as affected workflows needed to be restarted and verified for no lingering data corruption issues. This issue also highlighted limitations in the testing framework since runtime configuration based on external API calls to the configuration service were not exercised in simulated workflow executions.
Despite these challenges, the migration was a success. We migrated over 60,000 active workflows generating over a million data processing tasks daily with almost no user involvement. By observing the flow engine’s lifecycle management latency, we validated a reduction in step launch overhead from around 5 seconds to 50 milliseconds. Workflow start overhead (incurred once per each workflow execution) also improved from 200 milliseconds to 50 milliseconds. Aggregating this over a million daily step executions translates to saving approximately 57 days of flow engine overhead per day, leading to a snappier user experience, more timely workflow status for data practitioners and greater overall task throughput for the same infrastructure scale.
We additionally realized significant benefits internally with reduced maintenance effort due to the new flow engine’s simplified set of database components. We were able to delete nearly 40TB of obsolete tables related to the previous stateless flow engine and saw a 90% reduction in internal database query traffic which had previously been a significant source of system alerts for the team.
Conclusion
The architectural evolution of Maestro represents a significant leap in performance, reducing overhead from seconds to milliseconds. This redesign with a stateful actor model not only enhances speed by 100X but also maintains scalability and reliability, ensuring Maestro continues to meet the diverse needs of Netflix’s data and ML workflows.
Key takeaways from this evolution include:
Performance matters: Even in a system designed for scale, the speed of individual operations significantly impacts user experience and productivity.
Simplicity wins: Reducing dependencies and simplifying architecture not only improved performance but also enhanced reliability and maintainability.
Strong guarantees are essential: Providing strong execution guarantees eliminates race conditions and edge cases that previously required manual intervention.
Locality optimizations pay off: Collocating related flows and tasks in the same JVM dramatically reduces overhead from the Maestro engine.
Modern language features help: Java 21’s virtual threads enabled an elegant actor-based implementation with minimal code complexity and dependencies.
We’re excited to share these improvements with the open-source community and look forward to seeing how Maestro continues to evolve. The performance gains we’ve achieved open new possibilities for low-latency workflow orchestration use cases while continuing to support the massive scale that Netflix and other organizations require.
Visit the Maestro GitHub repository to explore these improvements. If you have any questions, thoughts, or comments about Maestro, please feel free to create a GitHub issue in the Maestro repository. We are eager to hear from you. If you are passionate about solving large scale orchestration problems, please join us.
Acknowledgements
Special thanks to Big Data Orchestration team members for general contributions to Maestro and diligent review, discussion and incident response required to make this project successful: Davis Shepherd, Natallia Dzenisenka, Praneeth Yenugutala, Brittany Truong, Jonathan Indig, Deepak Ramalingam, Binbing Hou, Zhuoran Dong, Victor Dusa, and Gabriel Ikpaetuk — and and internal partners Yun Li and Romain Cledat.
Thank you to Anoop Panicker and Aravindan Ramkumar from our partner organization that leads Conductor development in Netflix. They helped us understand issues in Conductor 2.X that initially motivated the rearchitecture and helped provide context on later versions of Conductor that defined some of the core trade-offs for the decision to implement a custom DAG engine in Maestro.
We’d also like to thank our partners on the Data Security & Infrastructure and Engineering Support teams who helped identify and rapidly fix the configuration discrepancy error encountered during production rollout: Amer Hesson, Ye Ji, Sungmin Lee, Brandon Quan, Anmol Khurana, and Manav Garekar.
A special thanks also goes out to partners from the Data Experience team including Jeff Bothe, Justin Wei, and Andrew Seier. The flow engine speed improvement was actually so dramatic that it broke some integrations with our internal workflow UI that reported state transition durations. Our partners helped us catch and fix UI regressions before they shipped to avoid impact to users.
We also thank Prashanth Ramdas, Anjali Norwood, Eva Tse, Charles Zhao, Sumukh Shivaprakash, Joey Lynch, Harikrishna Menon, Marcelo Mayworm, Charles Smith and other leaders for their constructive feedback and guidance on the Maestro project.
How do you run SQL queries over petabytes of data… without a server?
We have an answer for that: R2 SQL, a serverless query engine that can sift through enormous datasets and return results in seconds.
This post details the architecture and techniques that make this possible. We’ll walk through our Query Planner, which uses R2 Data Catalog to prune terabytes of data before reading a single byte, and explain how we distribute the work across Cloudflare’s global network, Workers and R2 for massively parallel execution.
From catalog to query
During Developer Week 2025, we launched R2 Data Catalog, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket. Iceberg is an open table format that provides critical database features like transactions and schema evolution for petabyte-scale object storage. It gives you a reliable catalog of your data, but it doesn’t provide a way to query it.
Until now, reading your R2 Data Catalog required setting up a separate service like Apache Spark or Trino. Operating these engines at scale is not easy: you need to provision clusters, manage resource usage, and be responsible for their availability, none of which contributes to the primary goal of getting value from your data.
R2 SQL removes that step entirely. It’s a serverless query engine that executes retrieval SQL queries against your Iceberg tables, right where your data lives.
Designing a query engine for petabytes
Object storage is fundamentally different from a traditional database’s storage. A database is structured by design; R2 is an ocean of objects, where a single logical table can be composed of potentially millions of individual files, large and small, with more arriving every second.
Apache Iceberg provides a powerful layer of logical organization on top of this reality. It works by managing the table’s state as an immutable series of snapshots, creating a reliable, structured view of the table by manipulating lightweight metadata files instead of rewriting the data files themselves.
However, this logical structure doesn’t change the underlying physical challenge: an efficient query engine must still find the specific data it needs within that vast collection of files, and this requires overcoming two major technical hurdles:
The I/O problem: A core challenge for query efficiency is minimizing the amount of data read from storage. A brute-force approach of reading every object is simply not viable. The primary goal is to read only the data that is absolutely necessary.
The Compute problem: The amount of data that does need to be read can still be enormous. We need a way to give the right amount of compute power to a query, which might be massive, for just a few seconds, and then scale it down to zero instantly to avoid waste.
Our architecture for R2 SQL is designed to solve these two problems with a two-phase approach: a Query Planner that uses metadata to intelligently prune the search space, and a Query Execution system that distributes the work across Cloudflare’s global network to process the data in parallel.
Query Planner
The most efficient way to process data is to avoid reading it in the first place. This is the core strategy of the R2 SQL Query Planner. Instead of exhaustively scanning every file, the planner makes use of the metadata structure provided by R2 Data Catalog to prune the search space, that is, to avoid reading huge swathes of data irrelevant to a query.
This is a top-down investigation where the planner navigates the hierarchy of Iceberg metadata layers, using stats at each level to build a fast plan, specifying exactly which byte ranges the query engine needs to read.
What do we mean by “stats”?
When we say the planner uses “stats” we are referring to summary metadata that Iceberg stores about the contents of the data files. These statistics create a coarse map of the data, allowing the planner to make decisions about which files to read, and which to ignore, without opening them.
There are two primary levels of statistics the planner uses for pruning:
Partition-level stats: Stored in the Iceberg manifest list, these stats describe the range of partition values for all the data in a given Iceberg manifest file. For a partition on day(event_timestamp), this would be the earliest and latest day present in the files tracked by that manifest.
Column-level stats: Stored in the manifest files, these are more granular stats about each individual data file. Data files in R2 Data Catalog are formatted using the Apache Parquet. For every column of a Parquet file, the manifest stores key information like:
The minimum and maximum values. If a query asks for http_status = 500, and a file’s stats show its http_status column has a min of 200 and a max of 404, that entire file can be skipped.
A count of null values. This allows the planner to skip files when a query specifically looks for non-null values (e.g., WHERE error_code IS NOT NULL) and the file’s metadata reports that all values for error_code are null.
Now, let’s see how the planner uses these stats as it walks through the metadata layers.
Pruning the search space
The pruning process is a top-down investigation that happens in three main steps:
Table metadata and the current snapshot
The planner begins by asking the catalog for the location of the current table metadata. This is a JSON file containing the table’s current schema, partition specs, and a log of all historical snapshots. The planner then fetches the latest snapshot to work with.
2. Manifest list and partition pruning
The current snapshot points to a single Iceberg manifest list. The planner reads this file and uses the partition-level stats for each entry to perform the first, most powerful pruning step, discarding any manifests whose partition value ranges don’t satisfy the query. For a table partitioned by day(event_timestamp), the planner can use the min/max values in the manifest list to immediately discard any manifests that don’t contain data for the days relevant to the query.
3. Manifests and file-level pruning
For the remaining manifests, the planner reads each one to get a list of the actual Parquet data files. These manifest files contain more granular, column-level stats for each individual data file they track. This allows for a second pruning step, discarding entire data files that cannot possibly contain rows matching the query’s filters.
4. File row-group pruning
Finally, for the specific data files that are still candidates, the Query Planner uses statistics stored inside Parquet file’s footers to skip over entire row groups.
The result of this multi-layer pruning is a precise list of Parquet files, and of row groups within those Parquet files. These become the query work units that are dispatched to the Query Execution system for processing.
The Planning pipeline
In R2 SQL, the multi-layer pruning we’ve described so far isn’t a monolithic process. For a table with millions of files, the metadata can be too large to process before starting any real work. Waiting for a complete plan would introduce significant latency.
Instead, R2 SQL treats planning and execution together as a concurrent pipeline. The planner’s job is to produce a stream of work units for the executor to consume as soon as they are available.
The planner’s investigation begins with two fetches to get a map of the table’s structure: one for the table’s snapshot and another for the manifest list.
Starting execution as early as possible
From that point on, the query is processed in a streaming fashion. As the Query Planner reads through the manifest files and subsequently the data files they point to and prunes them, it immediately emits any matching data files/row groups as work units to the execution queue.
This pipeline structure ensures the compute nodes can begin the expensive work of data I/O almost instantly, long before the planner has finished its full investigation.
On top of this pipeline model, the planner adds a crucial optimization: deliberate ordering. The manifest files are not streamed in an arbitrary sequence. Instead, the planner processes them in an order matching by the query’s ORDER BY clause, guided by the metadata stats. This ensures that the data most likely to contain the desired results is processed first.
These two concepts work together to address query latency from both ends of the query pipeline.
The streamed planning pipeline lets us start crunching data as soon as possible, minimizing the delay before the first byte is processed. At the other end of the pipeline, the deliberate ordering of that work lets us finish early by finding a definitive result without scanning the entire dataset.
The next section explains the mechanics behind this “finish early” strategy.
Stopping early: how to finish without reading everything
Thanks to the Query Planner streaming work units in an order matching the ORDER BY clause, the Query Execution system first processes the data that is most likely to be in the final result set.
This prioritization happens at two levels of the metadata hierarchy:
Manifest ordering: The planner first inspects the manifest list. Using the partition stats for each manifest (e.g., the latest timestamp in that group of files), it decides which entire manifest files to stream first.
Parquet file ordering: As it reads each manifest, it then uses the more granular column-level stats to decide the processing order of the individual Parquet files within that manifest.
This ensures a constantly prioritized stream of work units is sent to the execution engine. This prioritized stream is what allows us to stop the query early.
For instance, with a query like … ORDER BY timestamp DESC LIMIT 5, as the execution engine processes work units and sends back results, the planner does two things concurrently:
It maintains a bounded heap of the best 5 results seen so far, constantly comparing new results to the oldest timestamp in the heap.
It keeps a “high-water mark” on the stream itself. Thanks to the metadata, it always knows the absolute latest timestamp of any data file that has not yet been processed.
The planner is constantly comparing the state of the heap to the water mark of the remaining stream. The moment the oldest timestamp in our Top 5 heap is newer than the high-water mark of the remaining stream, the entire query can be stopped.
At that point, we can prove no remaining work unit could possibly contain a result that would make it into the top 5. The pipeline is halted, and a complete, correct result is returned to the user, often after reading only a fraction of the potentially matching data.
Currently, R2 SQL supports ordering on columns that are part of the table’s partition key only. This is a limitation we are working on lifting in the future.
Architecture
Query Execution
Query Planner streams the query work in bite-sized pieces called row groups. A single Parquet file usually contains multiple row groups, but most of the time only a few of them contain relevant data. Splitting query work into row groups allows R2 SQL to only read small parts of potentially multi-GB Parquet files.
The server that receives the user’s request and performs query planning assumes the role of query coordinator. It distributes the work across query workers and aggregates results before returning them to the user.
Cloudflare’s network is vast, and many servers can be in maintenance at the same time. The query coordinator contacts Cloudflare’s internal API to make sure only healthy, fully functioning servers are picked for query execution. Connections between coordinator and query worker go through Cloudflare Argo Smart Routing to ensure fast, reliable connectivity.
Servers that receive query execution requests from the coordinator assume the role of query workers. Query workers serve as a point of horizontal scalability in R2 SQL. With a higher number of query workers, R2 SQL can process queries faster by distributing the work among many servers. That’s especially true for queries covering large amounts of files.
Both the coordinator and query workers run on Cloudflare’s distributed network, ensuring R2 SQL has plenty of compute power and I/O throughput to handle analytical workloads.
Each query worker receives a batch of row groups from the coordinator as well as an SQL query to run on it. Additionally, the coordinator sends serialized metadata about Parquet files containing the row groups. Thanks to that, query workers know exact byte offsets where each row group is located in the Parquet file without the need to read this information from R2.
Apache DataFusion
Internally, each query worker uses Apache DataFusion to run SQL queries against row groups. DataFusion is an open-source analytical query engine written in Rust. It is built around the concept of partitions. A query is split into multiple concurrent independent streams, each working on its own partition of data.
Partitions in DataFusion are similar to partitions in Iceberg, but serve a different purpose. In Iceberg, partitions are a way to physically organize data on object storage. In DataFusion, partitions organize in-memory data for query processing. While logically they are similar – rows grouped together based on some logic – in practice, a partition in Iceberg doesn’t always correspond to a partition in DataFusion.
DataFusion partitions map perfectly to the R2 SQL query worker’s data model because each row group can be considered its own independent partition. Thanks to that, each row group is processed in parallel.
At the same time, since row groups usually contain at least 1000 rows, R2 SQL benefits from vectorized execution. Each DataFusion partition stream can execute the SQL query on multiple rows in one go, amortizing the overhead of query interpretation.
There are two ends of the spectrum when it comes to query execution: processing all rows sequentially in one big batch and processing each individual row in parallel. Sequential processing creates a so-called “tight loop”, which is usually more CPU cache friendly. In addition to that, we can significantly reduce interpretation overhead, as processing a large number of rows at a time in batches means that we go through the query plan less often. Completely parallel processing doesn’t allow us to do these things, but makes use of multiple CPU cores to finish the query faster.
DataFusion’s architecture allows us to achieve a balance on this scale, reaping benefits from both ends. For each data partition, we gain better CPU cache locality and amortized interpretation overhead. At the same time, since many partitions are processed in parallel, we distribute the workload between multiple CPUs, cutting the execution time further.
In addition to the smart query execution model, DataFusion also provides first-class Parquet support.
As a file format, Parquet has multiple optimizations designed specifically for query engines. Parquet is a column-based format, meaning that each column is physically separated from others. This separation allows better compression ratios, but it also allows the query engine to read columns selectively. If the query only ever uses five columns, we can only read them and skip reading the remaining fifty. This massively reduces the amount of data we need to read from R2 and the CPU time spent on decompression.
DataFusion does exactly that. Using R2 ranged reads, it is able to read parts of the Parquet files containing the requested columns, skipping the rest.
DataFusion’s optimizer also allows us to push down any filters to the lowest levels of the query plan. In other words, we can apply filters right as we are reading values from Parquet files. This allows us to skip materialization of results we know for sure won’t be returned to the user, cutting the query execution time further.
Returning query results
Once the query worker finishes computing results, it returns them to the coordinator through the gRPC protocol.
R2 SQL uses Apache Arrow for internal representation of query results. Arrow is an in-memory format that efficiently represents arrays of structured data. It is also used by DataFusion during query execution to represent partitions of data.
In addition to being an in-memory format, Arrow also defines the Arrow IPC serialization format. Arrow IPC isn’t designed for long-term storage of the data, but for inter-process communication, which is exactly what query workers and the coordinator do over the network. The query worker serializes all the results into the Arrow IPC format and embeds them into the gRPC response. The coordinator in turn deserializes results and can return to working on Arrow arrays.
Future plans
While R2 SQL is currently quite good at executing filter queries, we also plan to rapidly add new capabilities over the coming months. This includes, but is not limited to, adding:
Support for complex aggregations in a distributed and scalable fashion;
Tools to help provide visibility in query execution to help developers improve performance;
Support for many of the configuration options Apache Iceberg supports.
In addition to that, we have plans to improve our developer experience by allowing users to query their R2 Data Catalogs using R2 SQL from the Cloudflare Dashboard.
Given Cloudflare’s distributed compute, network capabilities, and ecosystem of developer tools, we have the opportunity to build something truly unique here. We are exploring different kinds of indexes to make R2 SQL queries even faster and provide more functionality such as full text search, geospatial queries, and more.
Try it now!
It’s early days for R2 SQL, but we’re excited for users to get their hands on it. R2 SQL is available in open beta today! Head over to ourgetting started guide to learn how to create an end-to-end data pipeline that processes and delivers events to an R2 Data Catalog table, which can then be queried with R2 SQL.
We’re excited to see what you build! Come share your feedback with us on ourDeveloper Discord.
Grab operates as a dynamic ecosystem involving partners and various service providers, necessitating real-time intelligence and decision-making for seamless integration and service delivery. To facilitate this, GrabDeveloper serves as Grab’s centralized platform for developers and partners. It supports API integration, partner onboarding, and product management. It also provides tech support through staging and production portals with detailed documentation.
Working alongside Developer Home, Partner Gateway acts as Grab’s secure interface for exposing APIs to third-party entities. It enables seamless interactions between Grab’s hosted services and external consumers, such as mobile apps, web browsers, and partners. Partner Gateway enhances the experience by offering advanced metrics tracking through time-series charts and dashboards. Partner Gateway delivers actionable insights that ensure high performance, reliability, and user satisfaction in application integrations with Grab services.
Use cases
Let’s explore GrabDeveloper integration use cases with one of our partners, whom we’ll refer to as “Alpha.” Alpha is a company that specializes in producing and distributing a diverse range of perishable goods. To optimize their operations, time-series charts tracking API traffic request status codes and average API response times play a crucial role.
API traffic request service status codes chart
Time-series charts tracking API traffic request status codes offer valuable insights into the performance and reliability of APIs used for managing supply chain logistics, customer orders, and distribution networks. By monitoring these status codes, Alpha can promptly detect and resolve disruptions or failures in their digital systems, ensuring seamless operations and minimizing downtime.
Figure 1: API traffic chart from 5th Jan 2025 to 4th Mar 2025.
API average response times chart
Analyzing average response times helps the company maintain efficient communication between various systems, enhancing the speed and reliability of transactions and data exchanges. This proactive monitoring supports Alpha in delivering consistent, high-quality service to customers and partners, ultimately contributing to improved operational efficiency and customer satisfaction.
Analyzing average response times enables a company to ensure efficient communication across various systems, enhancing transaction speed and data exchange reliability. Proactive monitoring helps Alpha deliver consistent, high-quality service to customers and partners, boosting operational efficiency and customer satisfaction.
Figure 2: Average response time chart from 12 Mar 2025 3am to 12 Mar 2025 3pm (Endpoints are mocked for security purposes).
Endpoint status dashboard
For Alpha, the endpoint status dashboard delivers real-time insights into API performance, enabling swift issue resolution and seamless integration with the company’s systems. The dashboard enhances service reliability, supports business operations, and ensures uninterrupted data exchange, all of which are critical for Alpha’s business processes and customer satisfaction. Furthermore, the transparency and reliability provided by the dashboard strengthens trust in the partnership, ensuring Alpha to confidently rely on the integration to drive their digital initiatives and operational goals.
Figure 3: Endpoint status dashboard of express API for company Alpha. *Endpoints are mocked for security purposes.
Why choose Apache Pinot and what is it?
To accommodate these use cases, we need a backend storage system engineered for low-latency queries across a wide range of temporal intervals, spanning from one-hour snapshots to 30-day retrospective analyses, whereby it could contain up to ~6.8 billion rows of data in a 30 day period for a particular dataset. This led us to choose Apache Pinot for these use cases, a distributed Online Analytical Processing (OLAP) system designed for low-latency analytical queries on large-scale data with millisecond query latencies.
Apache Pinot is a real-time distributed OLAP datastore designed to deliver low-latency analytics on large-scale data. It is optimized for high-throughput ingestion and real-time query processing making it ideal for scenarios such as user-facing analytics, dashboards, and anomaly detection. Apache Pinot supports complex queries, including aggregations and filtering. It delivers sub-second response times by leveraging techniques like columnar storage, indexing, and data partitioning to achieve efficient query execution.
Data ingestion process
Figure 4: Data ingestion process.
API call initiation: An API call is made on the partner application and routed through the Partner Gateway.
Metric tracking: Dimensions such as client ID, partner ID, status code, endpoint, metric name, timestamp, and value (which is the metric) are tracked and uploaded to Datadog, a cloud-based monitoring platform.
Kafka message transformation: Within the partner gateway code, an Apache Kafka Producer converts these metrics into Kafka messages and stores them in a Kafka Topic. Grab utilizes Protobuf for serialization and deserialization of Kafka messages. Since Grab’s Golang Kafka ecosystem does not use the Confluent Schema Registry, Kafka messages must be serialized with a magic byte which indicates that they are using Confluent’s Schema Registry, followed by the Schema ID.
Serialization via Apache Flink: Serialization is managed using Apache Flink, an open-source stream processing framework. This ensures compatibility with the Confluent Schema Registry Protobuf Decoder plugin on Apache Pinot. The messages are then written to a separate Kafka Topic.
Ingestion to Apache Pinot: Messages from the Kafka Topic containing the magic byte are ingested directly into Pinot, which references the Confluent Schema Registry to accurately deserialize the messages.
Query execution: Queries on the Pinot table can be executed via the Pinot Rest Proxy API.
Data visualization: Users can view their project charts and dashboards on the GrabDeveloper Home UI, where data points are retrieved from queries executed in step 6.
Challenges faced
During the initial setup, we encountered significant performance challenges when executing aggregation queries on large datasets exceeding 150GB. Specifically, attempts to retrieve and process data for periods ranging from 20 to 30 days resulted in frequent timeout issues as the queries took longer than 10 seconds. This was particularly concerning as it compromised our ability to meet our Service Level Agreement (SLA) of delivering query results within 300 milliseconds. The existing query infrastructure struggled to efficiently manage the volume and complexity of data within the required timeframe, necessitating optimization efforts to improve performance and reliability.
Solution
Drawing from the insights gained on the limitations of our initial solutions, we implemented these strategic optimizations to significantly enhance our table’s performance.
Partitioning by metric name
Improved data locality: Partitioning the Kafka Topic by metric name ensures that related data is grouped together. When a query filters on a specific metric, Pinot can directly access the relevant partitions, minimizing the need to scan unrelated data. This significantly reduces I/O overhead and processing time.
Efficient query pruning: By physically partitioning data, only the servers holding the relevant partitions are queried. This leads to more efficient query pruning, as irrelevant data is excluded early in the process, further optimizing performance.
Enhanced parallel processing: Partitioning enables Pinot to distribute queries across multiple nodes, allowing different metrics to be processed in parallel. This leverages distributed computing resources, accelerating query execution and improving scalability for large datasets.
Column based on aggregation intervals
Table 1
Facilitates time-based aggregations: Rounded time columns (e.g., Timestamp_1h for hourly intervals) group data into coarser time buckets, enabling efficient aggregations such as hourly or daily metrics. This simplifies indexing and optimizes storage by precomputing aggregates for specific time intervals.
Efficient data filtering: Rounded time columns allow for precise filtering of data within specific aggregation intervals. For example, the query SELECT SUM(Value) FROM Table WHERE Timestamp_1h = '2025-01-20 01:00:00' can exclude irrelevant columns (e.g., column 2) and focus only on rows within the specified time interval, further enhancing query efficiency.
Utilizing the Star-tree index in Apache Pinot
The Star-tree Index in Apache Pinot is an advanced indexing structure that enhances query performance by pre-aggregating data across multiple dimensions (e.g., D1, D2). It features a hierarchical tree with a root node, leaf nodes (holding up to T records), and non-leaf nodes that split into child nodes when exceeding T records. Special star nodes store pre-aggregated records by omitting the splitting dimension. The tree is constructed based on a dimensionSplitOrder, dictating node splitting at each level.
dimensionsSplitOrder: This specifies the order in which dimensions are split at each level of the tree. The order is “Metric”, “Endpoint”, “Timestamp_1h”. This means the tree will first split by Metric, then by Endpoint, and finally by Timestamp_1h.
skipStarNodeCreationForDimensions: This array is empty, indicating that star nodes will be created for all dimensions specified in the split order. No dimensions are omitted from star node creation.
functionColumnPairs: This specifies the aggregation functions to be applied to columns when creating star nodes. The configuration includes “AVG__Value”, meaning the average of the “Value” column will be calculated and stored in star nodes.
maxLeafRecords: This is set to 1, indicating that each leaf node will contain only one record. If a node exceeds this number, it will split into child nodes.
Star-tree diagram
Figure 5: Star-tree Index Structure.
Components:
Root node (orange): This is the starting point for traversing the tree structure.
Leaf node (blue): These nodes contain up to a configurable number of records, denoted by T. In this configuration, maxLeafRecords is set to 1, meaning each leaf node will contain a maximum of one record.
Non-leaf node (green): These nodes will split into child nodes if they exceed the maxLeafRecords threshold. Since maxLeafRecords is set to 1, any node with more than one record will split.
Star-node (yellow): These nodes store pre-aggregated records by omitting the dimension used for splitting at that level. This helps in reducing the data size and improving query performance.
Example:
A practical explanation of the start-tree diagram would be to display the star-tree documents in a table format along with the sample queries used to retrieve the data.
Figure 6: Chart of query latency with and without optimization.
The graph above in Figure 6, provides a comparison analysis of query performance, showcasing the significant improvements achieved through the implemented optimization solutions. The query execution times are significantly reduced, as evidenced by the logarithmic scale values.
For the first query which calculates the latency for a particular aggregation interval, the log scale indicates a reduction from 4.64 to 2.32, translating to a decrease in query latency from 43,713 to 209 milliseconds.
Similarly, the second query, which aggregates the sum of the latency based on the tags for a particular metric, shows a log scale reduction from 3.71 to 1.54, with query latency improving from 5,072 to 35 milliseconds. These results underscore the efficacy of optimization in enhancing query performance, enabling faster data retrieval and processing
Tradeoffs
Star-tree indexes in Apache Pinot are designed to significantly enhance query performance by pre-computing aggregations. This approach allows for rapid query execution by utilizing pre-calculated results, rather than computing aggregations on-the-fly. However, this performance boost comes with a tradeoff in terms of storage space.
Before implementing the Star-tree index, the total storage size for 30 days of data was approximately 192GB. With the Star-tree index, this increased to 373GB, nearly doubling the storage requirements. Despite the increase in storage, the performance benefits substantially outweigh the costs associated with additional storage.
The cost impact is relatively minor. We utilize AWS gp3 EBS volumes, which roughly cost $14.48 USD monthly for the extra table (calculated as 0.08 USD x 181 GB). This cost is considered insignificant when compared to the substantial gains in query performance. Alternatively, precomputing the metrics via an ETL job is also feasible; however, it is less cost-effective due to the additional expenses required to maintain the pipeline.
The decision to use Star-tree indexes is justified by the dramatic improvement in query speed, which enhances user experience and efficiency. The modest increase in storage costs is a worthwhile investment for achieving optimal performance.
Conclusion
In conclusion, Grab’s integration of Apache Pinot as a backend solution within the Partner Gateway represents a forward-thinking strategy to meet the evolving demands of real-time analytics. Apache Pinot’s ability to deliver low-latency queries empowers our partners with immediate, actionable insights into API performance that enhances their integration experience and operational efficiency. This is crucial for partners who require rapid data access to make informed decisions and optimize their services.
The adoption of Star-tree indexing within Pinot further refines our analytics infrastructure by strategically balancing the trade-offs between query latency and storage costs. This optimization ensures Partner Gateway can support a diverse range of use cases with subsecond query latencies while maintaining high performance and reliability in service delivery reinforcing Grab’s commitment to delivering superior performance across its ecosystem.
Ultimately, the integration of Apache Pinot enhances Grab’s real-time analytics capabilities while empowering the company to drive innovation and consistently deliver exceptional service to both partners and users.
Credits to Manh Nguyen from the Coban Infrastructure Team, Michael Wengle from the Midas Team and Yuqi Wang from the DevHome team.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
At Netflix, data engineering has always been a critical function to enable the business’s ability to understand content, power recommendations, and drive business decisions. Traditionally, the function centered on building robust tables and pipelines to capture facts, derive metrics, and provide well modeled data products to their partners in analytics & data science functions. But as Netflix’s studio and content production scaled, so too have the challenges — and opportunities — of working with complex media data.
Today, we’re excited to share how our team is formalizing a new specialization of data engineering at Netflix: Media ML Data Engineering. This evolution is embodied in our latest collaboration with our platform teams, the Media Data Lake, which is designed to harness the full potential of media assets (video, audio, subtitles, scripts, and more) and enable the latest advances in machine learning, including latest transformer model architecture. As part of this initiative, we’re intentionally applying data engineering best practices — ensuring that our approach is both innovative and grounded in proven methodologies.
The Evolution: From Traditional Tables to Media Tables
Traditional data engineering at Netflix focused on building structured tables for metrics, dashboards, and data science models. These tables were primarily structured text or numerical fields, ideal for business intelligence, analytics and statistical modeling.
However, the nature of media data is fundamentally different:
It’s multi-modal (video, audio, text, images).
It contains derived fields from media (embeddings, captions, transcriptions…etc)
It’s unstructured and massive in scale when parsed out.
It’s deeply intertwined with creative workflows and business asset lineage.
As our studio operations (see below) expanded, we saw the need for a new approach — one that could provide centralized, standardized, and scalable access to all types of media assets and their metadata for both analytical and machine learning workflows.
The Rise of Media ML Data Engineering
Enter Media ML Data Engineering — a new specialization at Netflix that bridges the gap between traditional data engineering and the unique demands of media-centric machine learning. This role sits at the intersection of data engineering, ML infrastructure, and media production. Our mission is to provide seamless access to media assets and derived data (including outputs from machine learning models) for researchers, data scientists, and other downstream data consumers.
Key Responsibilities
Centralized Media Data Access: Building, cataloging and maintaining the data and pipelines that populates the Media Data Lake, a data platform for storing and serving media assets and their metadata.
Asset Standardization: Standardizing media assets across modalities (video, images, audio, text) to ensure consistency and quality for ML applications in partnership with domain engineering teams.
Metadata Management: Unifying and enriching asset metadata, making it easier to track asset lineage, quality, and coverage.
ML-Ready Data: Exposing large corpora of assets for early-stage algorithm exploration, benchmarking, and productionization.
Collaboration: Partnering closely with domain experts, algorithm researchers, upstream content engineering teams and (machine learning & data) platform colleagues to ensure our data meets real-world needs.
This new role is essential for bridging the gap between creative media workflows and the technical demands of cutting-edge ML.
Introducing the Media Data Lake
To enable the next generation of media analytics and machine learning, we are building the Media Data Lake at Netflix — a data lake designed specifically for media assets at Netflix using LanceDB. We have partnered with our data platform team on integrating LanceDB into our Big Data Platform.
Architecture and Key Components
Media Table: The core of the Media Data Lake, this structured dataset captures essential metadata and references to all media assets. It’s designed to be extensible, supporting both traditional metadata and outputs from ML models (including transformer-based embeddings, media understanding research and more).
Data Model: We are developing a robust data model to standardize how media assets and their attributes are represented, making it easier to query and join across schemas.
Data API: An pythonic interface that will provide programmatic access to the Media Table, supporting both interactive exploration and automated workflows.
UI Components: Off-the-shelf UI interfaces enable teams to visually explore assets in the media data lake, accelerating discovery and iteration for ICs.
Online and Offline System Architecture: Real-time access for lightweight queries and exploration of raw media assets; scalable large batch processing for ML training, benchmarking, and research.
Compute: distributed batch inference layer capable of processing using GPUs and media data processing at scale using CPUs.
Starting Small with New Technology
Our initial focus this past year has been on delivering a “data pond” — a mini-version of the Media Data Lake targeted at video/audio datasets for early stage model training, evaluation and research. All data for this phase comes from AMP, our internal asset management system and annotation store, and the scope is intentionally small to ensure a solid, extensible foundation could be built while introducing a new technology into the company. We are able to perform data exploration of the raw media assets to build up an intuitive understanding of the media via lightweight queries to AMP.
Media Tables: The New Foundation for ML and Innovation
One of the most exciting developments is the rise of media tables — structured datasets that not only capture traditional metadata, but also include the outputs of advanced ML models.
These media tables power a range of innovative applications, such as:
Translation & Audio Quality Measures: Managing audio clips and features via text-to-speech models for engineering localization quality metrics.
Media Fidelity Restoration: Research on restoration of videos to HDR for remastering and other image technology use-cases.
Story Understanding and Content Embedding: Structuring narrative elements extracted from textual evidence and video of a title to increase operational efficiency in title launch preparation and ratings, e.g. detection of smoking, gore, NSFW scenes in our titles.
Media Search: Leverage multi-modal vector search to find similar keyframes, shots, dialogue to facilitate research and experimentation.
These tables built on top of LanceDB are designed to scale, support complex queries, and serve both research and other data science & analytical needs.
The Human Side: New Roles and Collaboration
Media ML Data Engineering is a team sport. Our data engineers partner with domain experts, data scientists, ML researchers, upstream business ops and content engineering teams to ensure our data solutions are fit for purpose. We also work closely with our friendly platform teams to ensure technological breakthroughs that are beneficial beyond our small corner of the universe could become horizontal abstractions that benefit the rest of Netflix. This collaborative model enables rapid iteration, high data quality, innovative use cases and technology re-use.
Looking Ahead
The evolution from traditional data engineering to Media ML data engineering — anchored by our media data lake — is unlocking new frontiers for Netflix:
Richer, more accurate ML models trained on high-quality, standardized media data.
Supercharge ML Model evaluations via quick iteration cycles on the data.
Faster experimentation and productization of new AI-powered features.
Deeper insights into our content and creative workflows via metrics constructed from Media ML algorithms inferred features.
As we continue to grow the media data lake, be on the lookout for subsequent blog posts sharing our learnings and tools with the broader media ml & data engineering community.
At Grab, our journey towards a more robust and scalable data ecosystem has been a continuous evolution.
Considering the size of our data lake and complexity of our ecosystem, with businesses spanning across ride hailing, food delivery, and financial services, we have been long past the point where a single centrally managed data warehouse could serve all these data needs. Over its first decade, Grab experienced dramatic growth. Like most growing businesses, teams in Grab prioritised delivering new features to meet the demands of their users. This meant that the task of data maintenance had to take a back seat so that development and stabilisation works can be focused to keep up with the growth. However, to prepare Grab for the next 10 years, especially for a future where AI is likely to play an important role, our leadership understood the need for high quality data foundation and gave a mandate to our data teams to uplevel our entire enterprise data ecosystem.
Acknowledging the rising need for data-driven insights and the continuous expansion of our data repository, we initiated our data mesh journey, named the Signals Marketplace, in 2024.
However, this journey was far from simple. We encountered several critical challenges that required a significant transformation in our approach to data management. Some of the challenges encountered include:
High volume and variety of data being generated: Grab’s diverse operations created both opportunities and complexities. Effectively harnessing this wealth of information required a scalable, streamlined and accessible approach.
Gaps in data ownership: As our data landscape expanded, maintaining data quality and reliability became increasingly difficult without clear lines of ownership and accountability. This often led to ad-hoc discussions and delays in resolving data related issues. Since it was difficult to trust the reliability of an existing pipeline, teams were likely to create duplicate pipelines just so they have something they can control.
Unscalable reliance on central Data Engineering (DE) team: Our traditional reliance on a central DE team to curate and serve all data needs was becoming a bottleneck. This centralised model struggled to keep pace with the distributed nature of data creation and consumption across various product and engineering teams.
Lack of communication between data consumers and producers: Data producers are unaware of downstream dependencies of their data which led to several instances of critical pipelines breaking because of upstream changes.
No single source of truth: While we did have a central data warehouse, it still left a lot of data gaps across Grab’s many business lines. Teams would struggle to identify the correct data definitions and reliable sources of truth.
Varied sophistication of data practitioners: Different teams have different levels of expertise in regards to data. Some teams had dedicated data engineers, but many didn’t.
To address these challenges, we made a strategic decision to adopt a data mesh architecture. Data mesh is a decentralised approach to data management that treats data as a product, owned and served by domain specific teams. This paradigm shift empowers teams closest to the data to take responsibility for its quality, reliability, and accessibility.
Our primary goal in adopting a data mesh was to significantly increase the reusability and reliability of our data assets across the organisation. By fostering a culture of data ownership and providing the necessary tools and processes, we aimed to unlock the full potential of our data to drive innovation and better serve our users and partners.
Certification
A cornerstone of our data mesh implementation is the concept of data certification. We believe that clearly identifying high quality, trustworthy datasets is crucial for both data producers and consumers.
Why certification?
Certification offers significant benefits to both sides of the data ecosystem. Data producers can clearly define and communicate the expectations and guarantees associated with their certified data assets, like defining Service Level Agreements (SLAs) for engineering services. This includes aspects like schema, data quality, and freshness. For data consumers, certification provides the confidence to readily discover and utilise these assets. Knowing that they come with stronger reliability guarantees and clear documentation, data consumers can confidently “shop” for certified data products, reducing the need for extensive validation and ad-hoc inquiries.
Figure 1: Concept of data certification
To achieve widespread data certification, we focused on several key enablers:
Ownership: Establishing decentralised ownership and accountability is fundamental and non-trivial. We clearly identified teams which we call Data Domains, individuals responsible as Business Data Owners (BDOs), and Technical Data Owners (TDOs) for the upkeep, usability, documentation, and associated Scheduled Large Orders (SLOs) of each data product. This step was bootstrapped by leveraging the identification of the data asset creator’s team. However, if the creator had changed teams or left the company, the initial mapping of Domain <> Data Asset needs to be reviewed by the Domain Leads.
Data contract: We introduced data contracts as formal agreements between data producers and consumers. These contracts define the schema, SLA guarantees (including freshness, completeness, and retention policies), notice period for changes, and communication channels for a data product. Data certification helps set clear expectations and ensures reliability across data pipelines.
Data operational excellence
To further enhance accountability and ensure adherence to data contracts, we implemented automated Data Production Incidents (DPIs) for breached contracts. When data quality tests are done on data availability, timeliness, consistency, completeness, accuracy, validity, or other reliability guarantees fail, a DPI ticket is automatically created and assigned to the TDO. This system aims to standardise and drive accountability in investigating and fixing issues related to reliability guarantees within Data Contracts. The goal is for teams to acknowledge and fix the root cause of the DPIs.
Operationalisation and outcomes
To drive the adoption of data certification and the principles of data mesh across Grab, we focused on the following north star metric: percentage of queries hitting certified assets (%). This metric serves as a direct indicator of the reusability and trust in our certified data products. It also helps teams prioritise their certification efforts towards the most frequently used tables. It essentially pushes every data team in two synergistic directions:
To certify their most used datasets.
To query only certified datasets as much as possible.
Operationalisation
The successful operationalisation of our data mesh and certification efforts relied on several key factors listed below:
Executive buy-in: Strong leadership support was crucial in driving this organisational change and emphasising the importance of data as a product.
Organisation-wide push with clear measurable reporting: We implemented an organisation-wide initiative with clearly defined goals and measurable targets for data certification. Progress is tracked and reported to ensure accountability and drive momentum.
Dashboard to guide Grabbers target most used tables: Dashboards and tooling likely within Hubble, provided visibility into data usage patterns, guiding teams to prioritise the certification of their most popular and impactful datasets.
Outcomes
As a result of these efforts, we have observed significant positive outcomes:
75% of Grab queries hitting certified assets: We achieved a significant milestone with 75% of Grab’s data queries now targeting certified assets. This indicates a strong adoption of certified data products and a growing trust in their reliability.
Active deprecation of assets: The focus on data ownership and the push for certification has also led to increased visibility into our data landscape, allowing us to identify and actively deprecate redundant and duplicated data assets. Deprecated tables increases 400% year over year (YoY). This not only improves efficiency but also reduces the complexity and cost of maintaining our data infrastructure.
Accelerated innovation and cross-domain reusability: Prior to data mesh, every team often resorted to building their own data sources which leads to lower quality outcomes and slower turn around time. Today, internet of things datasets (IoT) like weather data collected by one team can now be reused by another team to optimise marketplace decisions — a practical step toward a more connected data ecosystem.
Beyond these individual instances, we observe a convergence across Grab towards most used datasets, with the number of P80 datasets (the top 80% of Grab’s most used data) reducing by over 58% since the start of the campaign.
What’s next
While we have made significant strides in our data mesh journey, we recognise that this is an ongoing evolution. This progress wouldn’t be as smooth sailing without the platforms we build for data management and observability. In our next article, we will be delving into the enhancements for crucial tooling and platforms like Genchi (in-house data quality observational tool) and Hubble (metadata management platform, built on DataHub and Grab proprietary technology), which underpin our data mesh vision and enable greater data reliability and reusability.
Massive credits to Grab’s leadership, Mohan Krishnan and Nikhil Dwarakanath, as well as Data owners on driving this Grab-wide effort to build strong data foundations in Grab. Grab’s data mesh would not have been possible without the commitment of all data owners to certify and curate their data products.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The Cloudflare Business Intelligence team manages a petabyte-scale data lake and ingests thousands of tables every day from many different sources. These include internal databases such as Postgres and ClickHouse, as well as external SaaS applications such as Salesforce. These tasks are often complex and tables may have hundreds of millions or billions of rows of new data each day. They are also business-critical for product decisions, growth plannings, and internal monitoring. In total, about 141 billion rows are ingested every day.
As Cloudflare has grown, the data has become ever larger and more complex. Our existing Extract Load Transform (ELT) solution could no longer meet our technical and business requirements. After evaluating other common ELT solutions, we concluded that their performance generally did not surpass our current system, either.
It became clear that we needed to build our own framework to cope with our unique requirements — and so Jetflow was born.
What we achieved
Over 100x efficiency improvement in GB-s:
Our longest running job with 19 billion rows was taking 48 hours using 300 GB of memory, and now completes in 5.5 hours using 4 GB of memory
We estimate that ingestion of 50 TB from Postgres via Jetflow could cost under $100 based on rates published by commercial cloud providers
>10x performance improvement:
Our largest dataset was ingesting 60-80,000 rows per second, this is now 2-5 million rows per second per database connection.
In addition, these numbers scale well with multiple database connections for some databases.
Extensibility:
The modular design makes it easy to extend and test. Today Jetflow works with ClickHouse, Postgres, Kafka, many different SaaS APIs, Google BigQuery and many others. It has continued to work well and remain flexible with the addition of new use cases.
How did we do this?
Requirements
The first step to designing our new framework had to be a clear understanding of the problems we were aiming to solve, with clear requirements to stop us creating new ones.
Performant & efficient
We needed to be able to move more data in less time as some ingestion jobs were taking ~24 hours, and our data will only grow. The data should be ingested in a streaming fashion and use less memory and compute resources than our existing solution.
Backwards compatible
Given the daily ingestion of thousands of tables, the chosen solution needed to allow for the migration of individual tables as needed. Due to our usage of Spark downstream and Spark’s limitations in merging desperate Parquet schemas, the chosen solution had to offer the flexibility to generate the precise schemas needed for each case to match legacy.
We also required seamless integration with our custom metadata system, used for dependency checks and job status information.
Ease of use
We want a configuration file that can be version-controlled, without introducing bottlenecks on repositories with many concurrent changes.
To increase accessibility for different roles within the team, another requirement was no-code (or configuration as code) in the vast majority of cases. Users should not have to worry about availability or translation of data types between source and target systems, or writing new code for each new ingestion. The configuration needed should also be minimal — for example, data schema should be inferred from the source system and not need to be supplied by the user.
Customizable
Striking a balance with the no-code requirement above, although we want a low bar of entry we also want to have the option to tune and override options if desired, with a flexible and optional configuration layer. For example, writing Parquet files is often more expensive than reading from the database, so we want to be able to allocate more resources and concurrency as needed.
Additionally, we wanted to allow for control over where the work is executed, with the ability to spin up concurrent workers in different threads, different containers, or on different machines. The execution of workers and communication of data was abstracted away with an interface, and different implementations can be written and injected, controlled via the job configuration.
Testable
We wanted a solution capable of running locally in a containerized environment, which would allow us to write tests for every stage of the pipeline. With “black box” solutions, testing often means validating the output after making a change, which is a slow feedback loop, risks not testing all edge cases as there isn’t good visibility of all code paths internally, and makes debugging issues painful.
Designing a flexible framework
To build a truly flexible framework, we broke the pipeline down into distinct stages, and then create a config layer to define the composition of the pipeline from these stages, and any configuration overrides. Every pipeline configuration that makes sense logically should execute correctly, and users should not be able to create pipeline configs that do not work.
Pipeline configuration
This led us to a design where we created stages which were classified according to the meaningfully different categories of:
Consumers
Transformers
Loaders
The pipeline was constructed via a YAML file that required a consumer, zero or more transformers, and at least one loader. Consumers create a data stream (via reading from the source system), Transformers (e.g. data transformations, validations) take a data stream input and output a data stream conforming to the same API so that they can be chained, and Loaders have the same data streaming interface, but are the stages with persistent effects — i.e. stages where data is saved to an external system.
This modular design means that each stage is independently testable, with shared behaviour (such as error handling and concurrency) inherited from shared base stages, significantly decreasing development time for new use cases and increasing confidence in code correctness.
Data divisions
Next, we designed a breakdown for the data that would allow the pipeline to be idempotent both on whole pipeline re-run and also on internal retry of any data partition due to transient error. We decided on a design that let us parallelize processing, while maintaining meaningful data divisions that allowed the pipeline to perform cleanups of data where required for a retry.
RunInstance: the least granular division, corresponding to a business unit for a single run of the pipeline (e.g. one month/day/hour of data).
Partition: a division of the RunInstance that allows each row to be allocated to a partition in a way that is deterministic and self-evident from the row data without external state, and is therefore idempotent on retry. (e.g. an accountId range, a 10-minute interval)
Batch: a division of the partition data that is non-deterministic and used only to break the data down into smaller chunks for streaming/parallel processing for faster processing with fewer resources. (e.g. 10k rows, 50 MB)
The options that the user configures in the consumer stage YAML both construct the query that is used to retrieve the data from the source system, and also encode the semantic meaning of this data division in a system agnostic way, so that later stages understand what this data represents — e.g. this partition contains the data for all accounts IDs 0-500. This means that we can do targeted data cleanup and avoid, for example, duplicate data entries if a single data partition is retried due to error.
Framework implementation
Standard internal state for stage compatibility
Our most common use case is something like read from a database, convert to Parquet format, and then save to object storage, with each of these steps being a separate stage. As more use cases were onboarded to Jetflow, we had to make sure that if someone wrote a new stage it would be compatible with the other stages. We don’t want to create a situation where new code needs to be written for every output format and target system, or you end up with a custom pipeline for every different use case.
The way we have solved this problem is by having our stage extractor class only allow output data in a single format. This means as long as any downstream stages support this format as in the input and output format they would be compatible with the rest of the pipeline. This seems obvious in retrospect, but internally was a painful learning experience, as we originally created a custom type system and struggled with stage interoperability.
For this internal format, we chose to use Arrow, an in-memory columnar data format. The key benefits of this format for us are:
Arrow ecosystem: Many data projects now support Arrow as an output format. This means when we write extractor stages for new data sources, it is often trivial to produce Arrow output.
No serialisation overhead: This makes it easy to move Arrow data between machines and even programming languages with minimum overhead. Jetflow was designed from the start to have the flexibility to be able to run in a wide range of systems via a job controller interface, so this efficiency in data transmission means there’s minimal compromise on performance when creating distributed implementations.
Reserve memory in large fixed-size batches to avoid memory allocations: As Go is a garbage collected (GC) language and GC cycle times are affected mostly by the number of objects rather than the sizes of those objects, fewer heap objects reduces CPU time spent garbage collecting significantly, even if the total size is the same. As the number of objects to scan, and possibly collect, during a GC cycle increases with the number of allocations, if we have 8192 rows with 10 columns each, Arrow would only require us to do 10 allocations versus the 8192 allocations of most drivers that allocate on a row by row basis, meaning fewer objects and lower GC cycle times with Arrow.
Converting rows to columns
Another important performance optimization was reducing the number of conversion steps that happen when reading and processing data. Most data ingestion frameworks internally represent data as rows. In our case, we are mostly writing data in Parquet format, which is column based. When reading data from column-based sources (e.g. ClickHouse, where most drivers receive RowBinary format), converting into row-based memory representations for the specific language implementation is inefficient. This is then converted again from rows to columns to write Parquet files. These conversions result in a significant performance impact.
Jetflow instead reads data from column-based sources in columnar formats (e.g. for ClickHouse-native Block format) and then copies this data into Arrow column format. Parquet files are then written directly from Arrow columns. The simplification of this process improves performance.
Writing each pipelines stage
Case study: ClickHouse
When testing an initial version of Jetflow, we discoveredthat due to the architecture of ClickHouse, using additional connections would not be of any benefit, since ClickHouse was reading faster than we were receiving data. It should then be possible, with a more optimized database driver, to take better advantage of that single connection to read a much larger number of rows per second, without needing additional connections.
Initially, a custom database driver was written for ClickHouse, but we ended up switching to the excellent ch-go low level library, which directly reads Blocks from ClickHouse in a columnar format. This had a dramatic effect on performance in comparison to the standard Go driver. Combined with the framework optimisations above, we now ingest millions of rows per second with a single ClickHouse connection.
A valuable lesson learned is that as with any software, tradeoffs are often made for the sake of convenience or a common use case that may not match your own. Most database drivers tend not to be optimized for reading large batches of rows, and have high per-row overhead.
Case study: Postgres
For Postgres, we use the excellent jackc/pgx driver, but instead of using the database/sql Scan interface, we directly receive the raw bytes for each row and use the jackc/pgx internal scan functions for each Postgres OID (Object Identifier) type.
The database/sql Scan interface in Go uses reflection to understand the type passed to the function and then also uses reflection to set each field with the column value received from Postgres. In typical scenarios, this is fast enough and easy to use, but falls short for our use cases in terms of performance. The jackc/pgx driver reuses the row bytes produced each time the next Postgres row is requested, resulting in zero allocations per row. This allows us to write high-performance, low-allocation code within Jetflow. With this design, we are able to achieve nearly 600,000 rows per second per Postgres connection for most tables, with very low memory usage.
Conclusion
As of early July 2025, the team ingests 77 billion records per day via Jetflow. The remaining jobs are in the process of being migrated to Jetflow, which will bring the total daily ingestion to 141 billion records. The framework has allowed us to ingest tables in cases that would not otherwise have been possible, and provided significant cost savings due to ingestions running for less time and with fewer resources.
In the future, we plan to open source the project, and if you are interested in joining our team to help develop tools like this, then open roles can be found at https://www.cloudflare.com/careers/jobs/.
The Integrity Data Platform (IDP) team decided to rewrite one of our heavy Queries Per Second (QPS) Golang microservices in Rust. It resulted in 70% infrastructure savings at a similar performance, but was not without its pitfalls. This article will elaborate on:
How we picked what to rewrite in Rust.
Approach taken to tackle the rewrite.
The pitfalls and speed bumps along the way.
Was it worthwhile?
Introduction
Grab is predominantly based on a microservice architecture, with the vast majority of microservices being hosted in a monorepo and written in Golang. It has served the company well so far, as the “simplicity” of Golang allows developers to ramp up and iterate quickly.
However, Rust has seen some gradual adoption across the company. Starting with a few minor CLIs, which then progressed to notable success with a Rust-based reverse proxy in Catwalk for model serving. Additionally, a growing community of Rust enthusiasts within the organisation has expressed interest in advocating for and expanding the adoption of Rust more proactively.
After achieving success with several projects on the ML platform and addressing concerns about Rust’s ability to handle traffic at scale, the next logical step was to assess the Return on Investment (ROI) of rewriting a Golang microservice in Rust.
Background
Rust has the reputation of being highly efficient yet poses a steep learning curve. Rust is often touted to perform close to C, doing away with garbage collection while remaining memory safe through strict compile checks and the borrow checker. It is loved by developers for having rich features like being multi-paradigm (supporting both functional and OOP style), having a rich type system, and doing away with nil pointers and errors.
However, regardless of how well regarded a certain language is in the industry, rewrites of any system should always be considered very carefully. When it comes to “legacy software”, there is a prevalent assumption that rewriting legacy software is a solution to eliminate technical debt and phase out legacy systems. The reality is often more nuanced.
Legacy code occurs when the developers who originally wrote the code are no longer working on the project. There are often business logic and edge-cases baked into complex legacy codebases of which the context has been lost over time. In practice, rewrites frequently take longer than anticipated and tend to reintroduce bugs and edge cases that must be identified and resolved all over again.
Rewriting vs refactoring has been written at length across the internet, you can read more about it here.
The trade-offs of rewriting need to be properly weighed and balanced. It must take into consideration:
How much engineering bandwidth goes into the rewrite?
What is the complexity of the rewrite?
What tangible benefits are brought about by the rewrite?
Rewriting a system solely for the purpose of “rewriting it in Rust” is not a strong enough business justification.
A legitimate concern was the steep learning curve of Rust, coupled with the risk of having only one team member proficient in the language, which would make its adoption unsustainable.
Therefore, we established a set of guidelines to follow when identifying a suitable system for a potential rewrite:
The system must be “simple” enough in functionality. For example, it has one or two main functionalities that can be rewritten in a reasonable amount of time and have its complexity constrained.
The system targeted should have large enough traffic such that cost savings brought about by adopting Rust is something tangible when balanced against the effort.
The members of the team must be comfortable and willing to pick up the language and achieve a certain level of familiarity to make maintaining the service sustainable.
Finding the right service
The ideal service should have a sufficiently large infrastructure footprint to justify the potential cost savings, while also being straightforward in functionality to minimise time spent on handling edge cases and complex business logic.
Looking across the stack of microservices in Integrity, Counter Service stands out. As its name implies, Counter Service is a service that “counts” and serves the counters for ML models and fraud rules. The original service has two primary functionalities:
Consuming from streams, counting events and writing to Scylla.
Exposing Google Remote Procedure Call (GRPC) endpoints to query from Scylla (and Redis) and return counts of events based on query keys. For example, BatchRead. BatchRead’s functionality of Counter Service serves up to tens of thousands of QPS at peak and is fairly constrained in functionality. Hence, it fulfilled our target criteria of being “simple” in functionality yet serving a large enough amount of traffic that justifies the ROI of a rewrite.
Figure 1: BatchRead flow of Counter Service, reading data from Scylla, DynamoDB, Redis, MySQL and serving the counters through GRPC.
Rewrite approach
There are a few ways to approach a rewrite in another language. One popular way is to convert your code line by line. If the languages are close enough, it might even be possible to programmatically convert your code like C2Rust.
We decided not to use such an approach for our rewrite. The major reason is that idiomatic Golang was not necessarily idiomatic Rust. We wanted to approach this rewrite with a fresh perspective and treat this as a true rewrite.
We treated the application like a black box, with the interfaces well defined, like GRPC endpoints and contracts. Similar to a function, you could call the API and get a deterministic result, and we had the data that was stored in Scylla.
Based on how we understood the application to work based on its specs and contract, we chose to rewrite the application logic from scratch to meet the API contract and to get as close as identical outputs from the new black box.
OSS library support
We started out by mapping out the key external dependencies and checking how well they were supported in the Rust ecosystem and in open source.
All the functionality we need is available through libraries in the Rust ecosystem. However, we found that some libraries are not particularly “popular,” as indicated by their relatively low number of GitHub stars.
The practical concern with using less “popular” libraries is the risk of limited community support or potential abandonment over time. That said, if an “unpopular” library is officially maintained by the associated open-source project—for instance, the Scylla driver has only about 500 stars but is officially provided by the Scylla project—we would need to ensure confidence that it will continue to receive active support.
Out of the list of libraries above, the “unpopular” and unofficial libraries can be narrowed down to two libraries:
Datadog – Cadence
Redis – Fred
For Datadog, there is no “official” Datadog Rust client. Yet, we picked Cadence as the API looked intuitive and the features we needed were already supported.
In regards to Redis, after testing it, we discovered that the support was not up to par with our requirements. We then opted for a newer and less popular library, fred.rs that seemed to be actively being developed by the community.
Company specific internal libraries
With the vast majority of microservices being written in Golang, most internal libraries are also written in Golang. Opting to rewrite a service in Rust means we are not able to use these internal libraries.
Examples include:
An internal configuration library that utilises Go Templates to template configurations for different environments (staging and production).
The internal configuration library has its own wrappers and injectors to pull and render secrets.
To overcome this gap and re-use Go Templates and configuration language, we decided to write a simple wrapper and parser using the nom parser combinator to parse the templates and render the config.
Nom poses a steep learning curve. But once familiarised, it is flexible and performant enough to build an equivalent to the internal library. Parser combinators are an interesting subset of tooling that allows you to create some fairly elegant parsers.
Road bumps
The borrow checker
One of the most striking paradigm shifts for developers transitioning to Rust is adapting to the strict rules of the borrow checker, which enforces that variables cannot be reused multiple times unless explicitly cloned or borrowed.
Interestingly, the borrow checker was not the biggest hurdle for new developers. The key is to avoid introducing lifetimes too early in the development process, as this can lead to premature code optimisation.
In many cases, adding a few clones (and occasionally Arcs) can help new developers get up to speed and iterate more quickly during development. The resulting code is usually “fast” enough for initial purposes. After that, the code can be revisited to eliminate unnecessary clones for improved performance. An efficient approach to this can be taken by using Flamegraph to profile your code and identify memory allocation bottlenecks.
Async gotchas
When rewriting Golang logic in Rust, there are fundamental differences in how they treat concurrency and parallelism.
One of Golang’s most remarkable strengths is its ability to deliver high-performance concurrency while preserving simplicity.
There are two fundamental approaches to concurrency in programming languages, namely:
Preemptive scheduling (stackful coroutines).
Cooperative scheduling (stackless coroutines).
Preemptive vs cooperative scheduling is an in-depth topic with the gist of it being, Golang uses preemptive scheduling and each “Goroutine” has a stack that needs a runtime. The Golang scheduler has the power to “preempt” and “freeze” functions and switch to another stack like stackful coroutine. This is a gross oversimplification of the nuances. For more details, this is a good introduction to the topic.
Rust opts for cooperative scheduling whereby it has no runtime and each coroutine does not maintain a stack. Hence, it has no ability to “freeze” a function and swap context. This allows Rust to be more efficient in terms of memory and resources, as it maintains a state machine. However, the consequence is that this moves the complexity up the stack to the programming language itself. Similar to Javascript, functions are “coloured”, and the developer has to explicitly annotate their functions to be async or sync. Await points need to be explicitly called and control needs to be “yielded” (i.e. cooperative and stackless) so the Rust program knows when it is allowed to stop and swap between coroutines. To read more on this, refer to this and this article for the history of async Rust.
Needing to annotate a function is a classic complaint that is addressed in the article “What Colour is Your Function” that highlights developers’ responsibility to explicitly colour their function and consciously think about blocking vs non-blocking code.
Contrast this with Golang, where you simply need to add the go keyword without thinking about which code might block the execution and use channels to communicate across Goroutines. Golang allows the developer to achieve high performance without much cognitive overhead.
This is especially important for developers new to Rust. As the lack of experience in async and blocking code can be somewhat of a footgun. In the initial rewrite of Rust, we made an amateur mistake of using a synchronous Redis function to call the Redis cache. It resulted in the application performing poorly until we corrected it with the non-blocking asynchronous version using the Fred redis library.
Impact
Following the eventful process of rewriting the service from the ground up in Rust, the outcomes proved to be quite intriguing.
Shadowing traffic to both services as seen in Figure 2, the P99 latency is similar (or perhaps even slightly worse) in the Rust service compared to the original Golang one.
Figure 2: P99 latency comparison between the Golang service (purple) and Rust service (blue).
Normalising the QPS and resource consumption, we see from Table 2 that Rust consumes ~20% of the resources of the original Golang application, resulting in 5x savings in terms of resource consumption.
Table 2: Comparison of resource consumption between Rust and Golang service.
Service
Indicative QPS
Resources
Original Golang Service
1,000
20 Cores
New Rust Service
1,000
4.5 Cores
Learnings and conclusion
The outcomes and insights from this rewrite have been eye-opening, debunking certain myths while also validating others.
Myth 1: Rust is blazingly fast! Faster than Golang!
Verdict: Disproved.
Golang is “fast enough” for most use cases. It’s a mature language built with concurrency at its core, and it performs exceptionally well in its intended domain. While Rust can outperform Golang due to its higher performance ceiling and finer-grained control, rewriting a Golang service in Rust solely for performance improvements is unlikely to yield significant benefits.
Myth 2: Rust is more efficient than Golang
Verdict: True.
Rewriting a Golang service in Rust will probably give you 50% savings in compute. Rust does fulfill its promise of being memory safe without garbage collection, allowing it to be one of the more efficient languages out there. This is in line with other discoveries in the market.
Myth 3: The learning curve of Rust is too high
Verdict: It depends.
Pure synchronous Rust is fine. As long as you don’t overcomplicate the code and only clone what is needed, it is mostly true. The language is easy enough to pick up for most experienced developers. Even with cloning sprinkled in, the code is usually “fast enough”. The compiler is a good teacher, the compiler error messages are amazing, and if your code compiles, it probably works. Also, the Clippy linter is amazing.
However, introducing async can be challenging. Async is something quite different from what you would encounter in other languages like Go. Improper use of blocking code in async code can result in nuanced bugs that can catch inexperienced Rust developers off-guard.
Evaluating the worth of the rewrite
Yes, the effort was worth it for this service. The trade-off between development effort spent and the cost savings were justified.
As a side effect, the service is 80% cheaper and probably more bug free, as Rust eliminates a class of common Golang errors like Null pointers and concurrent map writes by virtue of the design of the language. If your code compiles, you usually have the confidence that it will work as you expect due to the language being more explicit.
Would we encourage choosing Rust over Golang for new microservices? Absolutely, as the resulting service is likely to be at least 50% more efficient than its Go counterpart. However, this decision presents an important and exciting opportunity for management and leaders to invest in empowering their engineers by equipping them with the skills to master Rust’s unique concepts, such as Async and Lifetimes. While the initial development pace might be slower as the team builds proficiency, this investment can unlock long-term benefits. Once the workforce is skilled in Rust, development speed should align with expectations, and the resulting systems are likely to be more stable and secure, thanks to Rust’s inherent safety features.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Imagine scrolling through Netflix, where each movie poster or promotional banner competes for your attention. Every image you hover over isn’t just a visual placeholder; it’s a critical data point that fuels our sophisticated personalization engine. At Netflix, we call these images ‘impressions,’ and they play a pivotal role in transforming your interaction from simple browsing into an immersive binge-watching experience, all tailored to your unique tastes.
Capturing these moments and turning them into a personalized journey is no simple feat. It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profile’s exposure. This nuanced integration of data and technology empowers us to offer bespoke content recommendations.
In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily. We will explore the challenges we encounter and unveil how we are building a resilient solution that transforms these client-side impressions into a personalized content discovery experience for every Netflix viewer.
Impressions on homepage
Why do we need impression history?
Enhanced Personalization
To tailor recommendations more effectively, it’s crucial to track what content a user has already encountered. Having impression history helps us achieve this by allowing us to identify content that has been displayed on the homepage but not engaged with, helping us deliver fresh, engaging recommendations.
Frequency Capping
By maintaining a history of impressions, we can implement frequency capping to prevent over-exposure to the same content. This ensures users aren’t repeatedly shown identical options, keeping the viewing experience vibrant and reducing the risk of frustration or disengagement.
Highlighting New Releases
For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. We can experiment with different content placements or promotional strategies to boost visibility and engagement.
Analytical Insights
Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy.
Architecture Overview
The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. This foundational dataset is essential, as it supports various downstream workflows and enables a multitude of use cases.
Collecting Raw Impression Events
As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. This queue ensures we are consistently capturing raw events from our global user base.
After raw events are collected into a centralized queue, a custom event extractor processes this data to identify and extract all impression events. These extracted events are then routed to an Apache Kafka topic for immediate processing needs and simultaneously stored in an Apache Iceberg table for long-term retention and historical analysis. This dual-path approach leverages Kafka’s capability for low-latency streaming and Iceberg’s efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability.
Collecting raw impression events
Filtering & Enriching Raw Impressions
Once the raw impression events are queued, a stateless Apache Flink job takes charge, meticulously processing this data. It filters out any invalid entries and enriches the valid ones with additional metadata, such as show or movie title details, and the specific page and row location where each impression was presented to users. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflix’s impression data. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention.
Impression Source-of-Truth architecture
Ensuring High Quality Impressions
Maintaining the highest quality of impressions is a top priority. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression. These metrics include everything from validating identifiers to checking that essential columns are properly filled. The data collected feeds into a comprehensive quality dashboard and supports a tiered threshold-based alerting system. These alerts promptly notify us of any potential issues, enabling us to swiftly address regressions. Additionally, while enriching the data, we ensure that all columns are in agreement with each other, offering in-place corrections wherever possible to deliver accurate data.
Dashboard showing mismatch count between two columns- entityId and videoId
Configuration
We handle a staggering volume of 1 to 1.5 million impression events globally every second, with each event approximately 1.2KB in size. To efficiently process this massive influx in real-time, we employ Apache Flink for its low-latency stream processing capabilities, which seamlessly integrates both batch and stream processing to facilitate efficient backfilling of historical data and ensure consistency across real-time and historical analyses. Our Flink configuration includes 8 task managers per region, each equipped with 8 CPU cores and 32GB of memory, operating at a parallelism of 48, allowing us to handle the necessary scale and speed for seamless performance delivery. The Flink job’s sink is equipped with a data mesh connector, as detailed in our Data Mesh platform which has two outputs: Kafka and Iceberg. This setup allows for efficient streaming of real-time data through Kafka and the preservation of historical data in Iceberg, providing a comprehensive and flexible data processing and storage solution.
Raw impressions records per second
We utilize the ‘island model’ for deploying our Flink jobs, where all dependencies for a given application reside within a single region. This approach ensures high availability by isolating regions, so if one becomes degraded, others remain unaffected, allowing traffic to be shifted between regions to maintain service continuity. Thus, all data in one region is processed by the Flink job deployed within that region.
Future Work
Addressing the Challenge of Unschematized Events
Allowing raw events to land on our centralized processing queue unschematized offers significant flexibility, but it also introduces challenges. Without a defined schema, it can be difficult to determine whether missing data was intentional or due to a logging error. We are investigating solutions to introduce schema management that maintains flexibility while providing clarity.
Automating Performance Tuning with Autoscalers
Tuning the performance of our Apache Flink jobs is currently a manual process. The next step is to integrate with autoscalers, which can dynamically adjust resources based on workload demands. This integration will not only optimize performance but also ensure more efficient resource utilization.
Improving Data Quality Alerts
Right now, there’s a lot of business rules dictating when a data quality alert needs to be fired. This leads to a lot of false positives that require manual judgement. A lot of times it is difficult to track changes leading to regression due to inadequate data lineage information. We are investing in building a comprehensive data quality platform that more intelligently identifies anomalies in our impression stream, keeps track of data lineage and data governance, and also, generates alerts notifying producers of any regressions. This approach will enhance efficiency, reduce manual oversight, and ensure a higher standard of data integrity.
Conclusion
Creating a reliable source of truth for impressions is a complex but essential task that enhances personalization and discovery experience. Stay tuned for the next part of this series, where we’ll delve into how we use this SOT dataset to create a microservice that provides impression histories. We invite you to share your thoughts in the comments and continue with us on this journey of discovering impressions.
Acknowledgments
We are genuinely grateful to our amazing colleagues whose contributions were essential to the success of Impressions: Julian Jaffe, Bryan Keller, Yun Wang, Brandon Bremen, Kyle Alford, Ron Brown and Shriya Arora.
Cloudflare’s network provides an enormous array of services to our customers. We collect and deliver associated data to customers in the form of event logs and aggregated analytics. As of December 2024, our data pipeline is ingesting up to 706M events per second generated by Cloudflare’s services, and that represents 100x growth since our 2018 data pipeline blog post.
At peak, we are moving 107 GiB/s of compressed data, either pushing it directly to customers or subjecting it to additional queueing and batching.
All of these data streams power things like Logs, Analytics, and billing, as well as other products, such as training machine learning models for bot detection. This blog post is focused on techniques we use to efficiently and accurately deal with the high volume of data we ingest for our Analytics products. A previous blog post provides a deeper dive into the data pipeline for Logs.
The pipeline can be roughly described by the following diagram.
The data pipeline has multiple stages, and each can and will naturally break or slow down because of hardware failures or misconfiguration. And when that happens, there is just too much data to be able to buffer it all for very long. Eventually some will get dropped, causing gaps in analytics and a degraded product experience unless proper mitigations are in place.
Dropping data to retain information
How does one retain valuable information from more than half a billion events per second, when some must be dropped? Drop it in a controlled way, by downsampling.
Here is a visual analogy showing the difference between uncontrolled data loss and downsampling. In both cases the same number of pixels were delivered. One is a higher resolution view of just a small portion of a popular painting, while the other shows the full painting, albeit blurry and highly pixelated.
As we noted above, any point in the pipeline can fail, so we want the ability to downsample at any point as needed. Some services proactively downsample data at the source before it even hits Logfwdr. This makes the information extracted from that data a little bit blurry, but much more useful than what otherwise would be delivered: random chunks of the original with gaps in between, or even nothing at all. The amount of “blur” is outside our control (we make our best effort to deliver full data), but there is a robust way to estimate it, as discussed in the next section.
Logfwdr can decide to downsample data sitting in the buffer when it overflows. Logfwdr handles many data streams at once, so we need to prioritize them by assigning each data stream a weight and then applying max-min fairness to better utilize the buffer. It allows each data stream to store as much as it needs, as long as the whole buffer is not saturated. Once it is saturated, streams divide it fairly according to their weighted size.
In our implementation (Go), each data stream is driven by a goroutine, and they cooperate via channels. They consult a single tracker object every time they allocate and deallocate memory. The tracker uses a max-heap to always know who the heaviest participant is and what the total usage is. Whenever the total usage goes over the limit, the tracker repeatedly sends the “please shed some load” signal to the heaviest participant, until the usage is again under the limit.
The effect of this is that healthy streams, which buffer a tiny amount, allocate whatever they need without losses. But any lagging streams split the remaining memory allowance fairly.
We downsample more or less uniformly, by always taking some of the least downsampled batches from the buffer (using min-heap to find those) and merging them together upon downsampling.
Merging keeps the batches roughly the same size and their number under control.
Downsampling is cheap, but since data in the buffer is compressed, it causes recompression, which is the single most expensive thing we do to the data. But using extra CPU time is the last thing you want to do when the system is under heavy load! We compensate for the recompression costs by starting to downsample the fresh data as well (before it gets compressed for the first time) whenever the stream is in the “shed the load” state.
We called this approach “bottomless buffers”, because you can squeeze effectively infinite amounts of data in there, and it will just automatically be thinned out. Bottomless buffers resemble reservoir sampling, where the buffer is the reservoir and the population comes as the input stream. But there are some differences. First is that in our pipeline the input stream of data never ends, while reservoir sampling assumes it ends to finalize the sample. Secondly, the resulting sample also never ends.
Let’s look at the next stage in the pipeline: Logreceiver. It sits in front of a distributed queue. The purpose of logreceiver is to partition each stream of data by a key that makes it easier for Logpush, Analytics inserters, or some other process to consume.
Logreceiver proactively performs adaptive sampling of analytics. This improves the accuracy of analytics for small customers (receiving on the order of 10 events per day), while more aggressively downsampling large customers (millions of events per second). Logreceiver then pushes the same data at multiple resolutions (100%, 10%, 1%, etc.) into different topics in the distributed queue. This allows it to keep pushing something rather than nothing when the queue is overloaded, by just skipping writing the high-resolution samples of data.
The same goes for Inserters: they can skip reading or writing high-resolution data. The Analytics APIs can skip reading high resolution data. The analytical database might be unable to read high resolution data because of overload or degraded cluster state or because there is just too much to read (very wide time range or very large customer). Adaptively dropping to lower resolutions allows the APIs to return some results in all of those cases.
Extracting value from downsampled data
Okay, we have some downsampled data in the analytical database. It looks like the original data, but with some rows missing. How do we make sense of it? How do we know if the results can be trusted?
Let’s look at the math.
Since the amount of sampling can vary over time and between nodes in the distributed system, we need to store this information along with the data. With each event $x_i$ we store its sample interval, which is the reciprocal to its inclusion probability $\pi_i = \frac{1}{\text{sample interval}}$. For example, if we sample 1 in every 1,000 events, each of the events included in the resulting sample will have its $\pi_i = 0.001$, so the sample interval will be 1,000. When we further downsample that batch of data, the inclusion probabilities (and the sample intervals) multiply together: a 1 in 1,000 sample from a 1 in 1,000 sample is a 1 in 1,000,000 sample of the original population. The sample interval of an event can also be interpreted roughly as the number of original events that this event represents, so in the literature it is known as weight $w_i = \frac{1}{\pi_i}$.
We rely on the Horvitz-Thompson estimator (HT, paper) in order to derive analytics about $x_i$. It gives two estimates: the analytical estimate (e.g. the population total or size) and the estimate of the variance of that estimate. The latter enables us to figure out how accurate the results are by building confidence intervals. They define ranges that cover the true value with a given probability (confidence level). A typical confidence level is 0.95, at which a confidence interval (a, b) tells that you can be 95% sure the true SUM or COUNT is between a and b.
So far, we know how to use the HT estimator for doing SUM, COUNT, and AVG.
Given a sample of size $n$, consisting of values $x_i$ and their inclusion probabilities $\pi_i$, the HT estimator for the population total (i.e. SUM) would be
where $\pi_{ij}$ is the probability of both $i$-th and $j$-th events being sampled together.
We use Poisson sampling, where each event is subjected to an independent Bernoulli trial (“coin toss”) which determines whether the event becomes part of the sample. Since each trial is independent, we can equate $\pi_{ij} = \pi_i \pi_j$, which when plugged in the variance estimator above turns the right-hand sum to zero:
if we could, but the original population size $N$ is not known, it is not stored anywhere, and it is not even possible to store because of custom filtering at query time. Plugging $\widehat{C}$ instead of $N$ only partially works. It gives a valid estimator for the mean itself, but not for its variance, so the constructed confidence intervals are unusable.
In all cases the corresponding pair of estimates are used as the $\mu$ and $\sigma^2$ of the normal distribution (because of the central limit theorem), and then the bounds for the confidence interval (of confidence level ) are:
We do not know the N, but there is a workaround: simultaneous confidence intervals. Construct confidence intervals for SUM and COUNT independently, and then combine them into a confidence interval for AVG. This is known as the Bonferroni method. It requires generating wider (half the “inconfidence”) intervals for SUM and COUNT. Here is a simplified visual representation, but the actual estimator will have to take into account the possibility of the orange area going below zero.
In SQL, the estimators and confidence intervals look like this:
WITH sum(x * _sample_interval) AS t,
sum(x * x * _sample_interval * (_sample_interval - 1)) AS vt,
sum(_sample_interval) AS c,
sum(_sample_interval * (_sample_interval - 1)) AS vc,
-- ClickHouse does not expose the erf⁻¹ function, so we precompute some magic numbers,
-- (only for 95% confidence, will be different otherwise):
-- 1.959963984540054 = Φ⁻¹((1+0.950)/2) = √2 * erf⁻¹(0.950)
-- 2.241402727604945 = Φ⁻¹((1+0.975)/2) = √2 * erf⁻¹(0.975)
1.959963984540054 * sqrt(vt) AS err950_t,
1.959963984540054 * sqrt(vc) AS err950_c,
2.241402727604945 * sqrt(vt) AS err975_t,
2.241402727604945 * sqrt(vc) AS err975_c
SELECT t - err950_t AS lo_total,
t AS est_total,
t + err950_t AS hi_total,
c - err950_c AS lo_count,
c AS est_count,
c + err950_c AS hi_count,
(t - err975_t) / (c + err975_c) AS lo_average,
t / c AS est_average,
(t + err975_t) / (c - err975_c) AS hi_average
FROM ...
Construct a confidence interval for each timeslot on the timeseries, and you get a confidence band, clearly showing the accuracy of the analytics. The figure below shows an example of such a band in shading around the line.
Sampling is easy to screw up
We started using confidence bands on our internal dashboards, and after a while noticed something scary: a systematic error! For one particular website the “total bytes served” estimate was higher than the true control value obtained from rollups, and the confidence bands were way off. See the figure below, where the true value (blue line) is outside the yellow confidence band at all times.
We checked the stored data for corruption, it was fine. We checked the math in the queries, it was fine. It was only after reading through the source code for all of the systems responsible for sampling that we found a candidate for the root cause.
We used simple random sampling everywhere, basically “tossing a coin” for each event, but in Logreceiver sampling was done differently. Instead of sampling randomly it would perform systematic sampling by picking events at equal intervals starting from the first one in the batch.
Why would that be a problem?
There are two reasons. The first is that we can no longer claim $\pi_{ij} = \pi_i \pi_j$, so the simplified variance estimator stops working and confidence intervals cannot be trusted. But even worse, the estimator for the total becomes biased. To understand why exactly, we wrote a short repro code in Python:
import itertools
def take_every(src, period):
for i, x in enumerate(src):
if i % period == 0:
yield x
pattern = [10, 1, 1, 1, 1, 1]
sample_interval = 10 # bad if it has common factors with len(pattern)
true_mean = sum(pattern) / len(pattern)
orig = itertools.cycle(pattern)
sample_size = 10000
sample = itertools.islice(take_every(orig, sample_interval), sample_size)
sample_mean = sum(sample) / sample_size
print(f"{true_mean=} {sample_mean=}")
After playing with different values for pattern and sample_interval in the code above, we realized where the bias was coming from.
Imagine a person opening a huge generated HTML page with many small/cached resources, such as icons. The first response will be big, immediately followed by a burst of small responses. If the website is not visited that much, responses will tend to end up all together at the start of a batch in Logfwdr. Logreceiver does not cut batches, only concatenates them. The first response remains first, so it always gets picked and skews the estimate up.
We checked the hypothesis against the raw unsampled data that we happened to have because that particular website was also using one of the Logs products. We took all events in a given time range, and grouped them by cutting at gaps of at least one minute. In each group, we ranked all events by time and looked at the variable of interest (response size in bytes), and put it on a scatter plot against the rank inside the group.
A clear pattern! The first response is much more likely to be larger than average.
We fixed the issue by making Logreceiver shuffle the data before sampling. As we rolled out the fix, the estimation and the true value converged.
Now, after battle testing it for a while, we are confident the HT estimator is implemented properly and we are using the correct sampling process.
Using Cloudflare’s analytics APIs to query sampled data
We already power most of our analytics datasets with sampled data. For example, the Workers Analytics Engine exposes the sample interval in SQL, allowing our customers to build their own dashboards with confidence bands. In the GraphQL API, all of the data nodes that have “Adaptive” in their name are based on sampled data, and the sample interval is exposed as a field there as well, though it is not possible to build confidence intervals from that alone. We are working on exposing confidence intervals in the GraphQL API, and as an experiment have added them to the count and edgeResponseBytes (sum) fields on the httpRequestsAdaptiveGroups nodes. This is available under confidence(level: X).
The query above asks for the estimates and the 95% confidence intervals for SUM(edgeResponseBytes) and COUNT. The results will also show the sample size, which is good to know, as we rely on the central limit theorem to build the confidence intervals, thus small samples don’t work very well.
The response shows the estimated count is 96947, and we are 95% confident that the true count lies in the range 96874.24 to 97019.76. Similarly, the estimate and range for the sum of response bytes are provided.
The estimates are based on a sample size of 96294 rows, which is plenty of samples to calculate good confidence intervals.
Conclusion
We have discussed what kept our data pipeline scalable and resilient despite doubling in size every 1.5 years, how the math works, and how it is easy to mess up. We are constantly working on better ways to keep the data pipeline, and the products based on it, useful to our customers. If you are interested in doing things like that and want to help us build a better Internet, check out our careers page.
On November 14, 2024, Cloudflare experienced an incident which impacted the majority of customers using Cloudflare Logs. During the roughly 3.5 hours that these services were impacted, about 55% of the logs we normally send to customers were not sent and were lost. We’re very sorry this happened, and we are working to ensure that a similar issue doesn’t happen again.
This blog post explains what happened and what we’re doing to prevent recurrences. Also, the systems involved and the particular class of failure we experienced will hopefully be of interest to engineering teams beyond those specifically using these products.
Failures within systems at scale are inevitable, and it’s essential that subsystems protect themselves from failures in other parts of the larger system to prevent cascades. In this case, a misconfiguration in one part of the system caused a cascading overload in another part of the system, which was itself misconfigured. Had it been properly configured, it could have prevented the loss of logs.
Background
Cloudflare’s network is a globally distributed system enabling and supporting a wide variety of services. Every part of this system generates event logs which contain detailed metadata about what’s happening with our systems around the world. For example, an event log is generated for every request to Cloudflare’s CDN. Cloudflare Logs makes these event logs available to customers, who use them in a number of ways, including compliance, observability, and accounting.
On a typical day, Cloudflare sends about 4.5 trillion individual event logs to customers. Although this represents less than 10% of the over 50 trillion total customer event logs processed, it presents unique challenges of scale when building a reliable and fault-tolerant system.
System architecture
Cloudflare’s network is composed of tens of thousands of individual servers, network hardware components, and specialized software programs located in over 330 cities around the world. Although Cloudflare’s Edge Log Delivery product will send customers their event logs directly from each server, most customers opt not to do this because doing so will create significant complication and cost at the receiving end.
By analogy, imagine the postal service ringing your doorbell once for each letter instead of once for each packet of letters. With thousands or millions of letters each second, the number of separate transactions that would entail becomes prohibitive.
Fortunately, we also offer Logpush, which collects and pushes logs to customers in more predictable file sizes and which scales automatically with usage. In order to provide this feature several services work together to collect and push the logs, as illustrated in the diagram below:
Logfwdr
Logfwdr is an internal service written in Golang that accepts event logs from internal services running across Cloudflare’s global network and forwards them in batches to a service called Logreceiver. Logfwdr handles many different types of event logs, and one of its responsibilities is to determine which event logs should be forwarded and where they should be sent based on the type of event log, which customers it represents, and associated rules about where it should be processed. Configuration is provided to Logfwdr to enable it to make these determinations.
Logreceiver
Logreceiver (also written in Golang) accepts the batches of logs from across Cloudflare’s global network and further sorts them depending on the type of event and its purpose. For Cloudflare Logs, Logreceiver demultiplexes the batches into per-customer batches and forwards them to be buffered by Buftee. Currently, Logreceiver is handling about 45 PB (uncompressed) of customer event logs each day.
Buftee
It’s common for data pipelines to include a buffer. Producers and consumers of the data might be operating at different cadences, and parts of the pipeline will experience variances in how quickly they can process information. Using a buffer makes it easier to manage these situations, and helps to prevent data loss if downstream consumers are broken. It’s also convenient to have a buffer that supports multiple downstream consumers with different cadences (like the pipe fitting function of a tee.)
At Cloudflare, we use an internal system called Buftee (written in Golang) to support this combined function. Buftee is a highly distributed system which supports a large number of named “buffers”. It supports operating on named “prefixes” (collections of buffers) as well as multiple representations/resolutions of the same time-indexed dataset. Using Buftee makes it possible for Cloudflare to handle extremely high throughput very efficiently.
For Cloudflare Logs, Buftee provides buffers for each Logpush job, containing 100% of the logs generated by the zone or account referenced by each job. This means that failure to process one customer’s job will not affect progress on another customer’s job. Handling buffers in this way avoids “head of line” blocking and also enables us to encrypt and delete each customer’s data separately if needed.
Buftee typically handles over 1 million buffers globally. The following is a snapshot of the number of buffers managed by Buftee servers in the period just prior to the incident.
Logpush
Logpush is a Golang service which reads logs from Buftee buffers and pushes the results in batches to various destinations configured by customers. A batch could end up, for example, as a file in R2. Each job has a unique configuration, and only jobs that are active and configured will be pushed. Currently, we push over 600 million such batches each day.
What happened
On November 14, 2024, we made a change to support an additional dataset for Logpush. This required adding a new configuration to be provided to Logfwdr in order for it to know which customers’ logs to forward for this new stream. Every few minutes, a separate system re-generates the configuration used by Logfwdr to decide which logs need to be forwarded. A bug in this system resulted in a blank configuration being provided to Logfwdr.
This bug essentially informed Logfwdr that no customers had logs configured to be pushed. The team quickly noticed the mistake and reverted the change in under five minutes.
Unfortunately, this first mistake triggered a second, latent bug in Logfwdr itself. A failsafe introduced in the early days of this feature, when traffic was much lower, was configured to “fail open”. This failsafe was designed to protect against a situation when this specific Logfwdr configuration was unavailable (as in this case) by transmitting events for all customers instead of just those who had configured a Logpush job. This was intended to prevent the loss of logs at the expense of sending more logs than strictly necessary when individual hosts were prevented from getting the configuration due to intermittent networking errors, for example.
When this failsafe was first introduced, the potential list of customers was smaller than it is today. This small window of less than five minutes resulted in a massive spikein the number of customers whose logs were sent by Logfwdr.
Even given this massive overload, our systems would have continued to send logs if not for one additional problem. Remember that Buftee creates a separate buffer for each customer with their logs to be pushed. When Logfwdr began to send event logs for all customers, Buftee began to create buffers for each one as those logs arrived, and each buffer requires resources as well as the bookkeeping to maintain them. This massive increase, resulting in roughly 40 times more buffers, is not something we’ve provisioned Buftee clusters to handle. In the lead-up to impact, Buftee was managing 40 million buffers globally, as shown in the figure below.
A short temporary misconfiguration lasting just five minutes created a massive overload that took us several hours to fix and recover from. Because our backstops were not properly configured, the underlying systems became so overloaded that we could not interact with them normally. A full reset and restart was required.
Root causes
The bug in the Logfwdr configuration system was easy to fix, but it’s the type of bug that was likely to happen at some point. We had planned for it by designing the original “fail open” behavior. However, we neglected to regularly test that the broader system was capable of handling a fail open event.
The bigger failure was that Buftee became unresponsive. Buftee’s purpose is to be a safeguard against bugs like this one. A huge increase in the number of buffers is a failure mode that we had predicted, and had put mechanisms in Buftee to prevent this failure from cascading. Our failure in this case was that we had not configured these mechanisms. Had they been configured correctly, Buftee would not have been overwhelmed.
It’s like having a seatbelt in a car, yet not fastening it. The seatbelt is there to protect you in case of an accident but if you don’t actually buckle it up, it’s not going to do its job when you need it. Similarly, while we had the safeguard of Buftee in place, we hadn’t ‘buckled it up’ by configuring the necessary settings. We’re very sorry this happened and are taking steps to prevent a recurrence as described below.
Going forward
We’re creating alerts to ensure that these particular misconfigurations will be impossible to miss, and we are also addressing the specific bug and the associated tests that triggered this incident.
Just as importantly, we accept that mistakes and misconfigurations are inevitable. All our systems at Cloudflare need to respond to these predictably and gracefully. Currently, we conduct regular “cut tests” to ensure that these systems will cope with the loss of a datacenter or a network failure. In the future, we’ll also conduct regular “overload tests” to simulate the kind of cascade which happened in this incident to ensure that our production systems will handle them gracefully.
Logpush is a robust and flexible platform for customers who need to integrate their own logging and monitoring systems with Cloudflare. Different Logpush jobs can be deployed to support multiple destinations or, with filtering, multiple subsets of logs.
We are thrilled to announce that the Maestro source code is now open to the public! Please visit the Maestro GitHub repository to get started. If you find it useful, please give us a star.
What is Maestro
Maestro is a general-purpose, horizontally scalable workflow orchestrator designed to manage large-scale workflows such as data pipelines and machine learning model training pipelines. It oversees the entire lifecycle of a workflow, from start to finish, including retries, queuing, task distribution to compute engines, etc.. Users can package their business logic in various formats such as Docker images, notebooks, bash script, SQL, Python, and more. Unlike traditional workflow orchestrators that only support Directed Acyclic Graphs (DAGs), Maestro supports both acyclic and cyclic workflows and also includes multiple reusable patterns, including foreach loops, subworkflow, and conditional branch, etc.
Our Journey with Maestro
Since we first introduced Maestro in this blog post, we have successfully migrated hundreds of thousands of workflows to it on behalf of users with minimal interruption. The transition was seamless, and Maestro has met our design goals by handling our ever-growing workloads. Over the past year, we’ve seen a remarkable 87.5% increase in executed jobs. Maestro now launches thousands of workflow instances and runs half a million jobs daily on average, and has completed around 2 million jobs on particularly busy days.
Scalability and Versatility
Maestro is a fully managed workflow orchestrator that provides Workflow-as-a-Service to thousands of end users, applications, and services at Netflix. It supports a wide range of workflow use cases, including ETL pipelines, ML workflows, AB test pipelines, pipelines to move data between different storages, etc. Maestro’s horizontal scalability ensures it can manage both a large number of workflows and a large number of jobs within a single workflow.
At Netflix, workflows are intricately connected. Splitting them into smaller groups and managing them across different clusters adds unnecessary complexity and degrades the user experience. This approach also requires additional mechanisms to coordinate these fragmented workflows. Since Netflix’s data tables are housed in a single data warehouse, we believe a single orchestrator should handle all workflows accessing it.
Join us on this exciting journey by exploring the Maestro GitHub repository and contributing to its ongoing development. Your support and feedback are invaluable as we continue to improve the Maestro project.
Introducing Maestro
Netflix Maestro offers a comprehensive set of features designed to meet the diverse needs of both engineers and non-engineers. It includes the common functions and reusable patterns applicable to various use cases in a loosely coupled way.
A workflow definition is defined in a JSON format. Maestro combines user-supplied fields with those managed by Maestro to form a flexible and powerful orchestration definition. An example can be found in the Maestro repository wiki.
A Maestro workflow definition comprises two main sections: properties and versioned workflow including its metadata. Properties include author and owner information, and execution settings. Maestro preserves key properties across workflow versions, such as author and owner information, run strategy, and concurrency settings. This consistency simplifies management and aids in trouble-shootings. If the ownership of the current workflow changes, the new owner can claim the ownership of the workflows without creating a new workflow version. Users can also enable the triggering or alerting features for a given workflow over the properties.
Versioned workflow includes attributes like a unique identifier, name, description, tags, timeout settings, and criticality levels (low, medium, high) for prioritization. Each workflow change creates a new version, enabling tracking and easy reversion, with the active or the latest version used by default. A workflow consists of steps, which are the nodes in the workflow graph defined by users. Steps can represent jobs, another workflow using subworkflow step, or a loop using foreach step. Steps consist of unique identifiers, step types, tags, input and output step parameters, step dependencies, retry policies, and failure mode, step outputs, etc. Maestro supports configurable retry policies based on error types to enhance step resilience.
This high-level overview of Netflix Maestro’s workflow definition and properties highlights its flexibility to define complex workflows. Next, we dive into some of the useful features in the following sections.
Workflow Run Strategy
Users want to automate data pipelines while retaining control over the execution order. This is crucial when workflows cannot run in parallel or must halt current executions when new ones occur. Maestro uses predefined run strategies to decide whether a workflow instance should run or not. Here is the list of predefined run strategies Maestro offers.
Sequential Run Strategy This is the default strategy used by maestro, which runs workflows one at a time based on a First-In-First-Out (FIFO) order. With this run strategy, Maestro runs workflows in the order they are triggered. Note that an execution does not depend on the previous states. Once a workflow instance reaches one of the terminal states, whether succeeded or not, Maestro will start the next one in the queue.
Strict Sequential Run Strategy With this run strategy, Maestro will run workflows in the order they are triggered but block execution if there’s a blocking error in the workflow instance history. Newly triggered workflow instances are queued until the error is resolved by manually restarting the failed instances or marking the failed ones unblocked.
In the above example, run5 fails at 5AM, then later runs are queued but do not run. When someone manually marks run5 unblocked or restarts it, then the workflow execution will resume. This run strategy is useful for time insensitive but business critical workflows. This gives the workflow owners the option to review the failures at a later time and unblock the executions after verifying the correctness.
First-only Run Strategy With this run strategy, Maestro ensures that the running workflow is complete before queueing a new workflow instance. If a new workflow instance is queued while the current one is still running, Maestro will remove the queued instance. Maestro will execute a new workflow instance only if there is no workflow instance currently running, effectively turning off queuing with this run strategy. This approach helps to avoid idempotency issues by not queuing new workflow instances.
Last-only Run Strategy With this run strategy, Maestro ensures the running workflow is the latest triggered one and keeps only the last instance. If a new workflow instance is queued while there is an existing workflow instance already running, Maestro will stop the running instance and execute the newly triggered one. This is useful if a workflow is designed to always process the latest data, such as processing the latest snapshot of an entire table each time.
Parallel with Concurrency Limit Run Strategy With this run strategy, Maestro will run multiple triggered workflow instances in parallel, constrained by a predefined concurrency limit. This helps to fan out and distribute the execution, enabling the processing of large amounts of data within the time limit. A common use case for this strategy is for backfilling the old data.
Parameters and Expression Language Support
In Maestro, parameters play an important role. Maestro supports dynamic parameters with code injection, which is super useful and powerful. This feature significantly enhances the flexibility and dynamism of workflows, allowing using parameters to control execution logic and enable state sharing between workflows and their steps, as well as between upstream and downstream steps. Together with other Maestro features, it makes the defining of workflows dynamic and enables users to define parameterized workflows for complex use cases.
However, code injection introduces significant security and safety concerns. For example, users might unintentionally write an infinite loop that creates an array and appends items to it, eventually crashing the server with out-of-memory (OOM) issues. While one approach could be to ask users to embed the injected code within their business logic instead of the workflow definition, this would impose additional work on users and tightly couple their business logic with the workflow. In certain cases, this approach blocks users to design some complex parameterized workflows.
To mitigate these risks and assist users to build parameterized workflows, we developed our own customized expression language parser, a simple, secure, and safe expression language (SEL). SEL supports code injection while incorporating validations during syntax tree parsing to protect the system. It leverages the Java Security Manager to restrict access, ensuring a secure and controlled environment for code execution.
Simple, Secure, and Safe Expression Language (SEL) SEL is a homemade simple, secure, and safe expression language (SEL) to address the risks associated with code injection within Maestro parameterized workflows. It is a simple expression language and the grammar and syntax follow JLS (Java Language Specifications). SEL supports a subset of JLS, focusing on Maestro use cases. For example, it supports data types for all Maestro parameter types, raising errors, datetime handling, and many predefined utility methods. SEL also includes additional runtime checks, such as loop iteration limits, array size checks, object memory size limits and so on, to enhance security and reliability. For more details about SEL, please refer to the Maestro GitHub documentation.
Output Parameters To further enhance parameter support, Maestro allows for callable step execution, which returns output parameters from user execution back to the system. The output data is transmitted to Maestro via its REST API, ensuring that the step runtime does not have direct access to the Maestro database. This approach significantly reduces security concerns.
Parameterized Workflows Thanks to the powerful parameter support, users can easily create parameterized workflows in addition to static ones. Users enjoy defining parameterized workflows because they are easy to manage and troubleshoot while being powerful enough to solve complex use cases.
Static workflows are simple and easy to use but come with limitations. Often, users have to duplicate the same workflow multiple times to accommodate minor changes. Additionally, workflow and jobs cannot share the states without using parameters.
On the other hand, completely dynamic workflows can be challenging to manage and support. They are difficult to debug or troubleshoot and hard to be reused by others.
Parameterized workflows strike a balance by being initialized step by step at runtime based on user defined parameters. This approach provides great flexibility for users to control the execution at runtime while remaining easy to manage and understand.
As we described in the previous Maestro blog post, parameter support enables the creation of complex parameterized workflows, such as backfill data pipelines.
Workflow Execution Patterns
Maestro provides multiple useful building blocks that allow users to easily define dataflow patterns or other workflow patterns. It provides support for common patterns directly within the Maestro engine. Direct engine support not only enables us to optimize these patterns but also ensures a consistent approach to implementing them. Next, we will talk about the three major building blocks that Maestro provides.
Foreach Support In Maestro, the foreach pattern is modeled as a dedicated step within the original workflow definition. Each iteration of the foreach loop is internally treated as a separate workflow instance, which scales similarly as any other Maestro workflow based on the step executions (i.e. a sub-graph) defined within the foreach definition block. The execution of sub-graph within a foreach step is delegated to a separate workflow instance. Foreach step then monitors and collects the status of these foreach workflow instances, each managing the execution of a single iteration. For more details, please refer to our previous Maestro blog post.
The foreach pattern is frequently used to repeatedly run the same jobs with different parameters, such as data backfilling or machine learning model tuning. It would be tedious and time consuming to request users to explicitly define each iteration in the workflow definition (potentially hundreds of thousands of iterations). Additionally, users would need to create new workflows if the foreach range changes, further complicating the process.
Conditional Branch Support The conditional branch feature allows subsequent steps to run only if specific conditions in the upstream step are met. These conditions are defined using the SEL expression language, which is evaluated at runtime. Combined with other building blocks, users can build powerful workflows, e.g. doing some remediation if the audit check step fails and then run the job again.
Subworkflow Support The subworkflow feature allows a workflow step to run another workflow, enabling the sharing of common functions across multiple workflows. This effectively enables “workflow as a function” and allows users to build a graph of workflows. For example, we have observed complex workflows consisting of hundreds of subworkflows to process data across hundreds tables, where subworkflows are provided by multiple teams.
These patterns can be combined together to build composite patterns for complex workflow use cases. For instance, we can loop over a set of subworkflows or run nested foreach loops. One example that Maestro users developed is an auto-recovery workflow that utilizes both conditional branch and subworkflow features to handle errors and retry jobs automatically.
In this example, subworkflow `job1` runs another workflow consisting of extract-transform-load (ETL) and audit jobs. Next, a status check job leverages the Maestro parameter and SEL support to retrieve the status of the previous job. Based on this status, it can decide whether to complete the workflow or to run a recovery job to address any data issues. After resolving the issue, it then executes subworkflow `job2`, which runs the same workflow as subworkflow `job1`.
Step Runtime and Step Parameter
Step Runtime Interface In Maestro, we use step runtime to describe a job at execution time. The step runtime interface defines two pieces of information:
A set of basic APIs to control the behavior of a step instance at execution runtime.
Some simple data structures to track step runtime state and execution result.
Maestro offers a few step runtime implementations such as foreach step runtime, subworkflow step runtime (mentioned in previous section). Each implementation defines its own logic for start, execute and terminate operations. At runtime, these operations control the way to initialize a step instance, perform the business logic and terminate the execution under certain conditions (i.e. manual intervention by users).
Also, Maestro step runtime internally keeps track of runtime state as well as the execution result of the step. The runtime state is used to determine the next state transition of the step and tell if it has failed or terminated. The execution result hosts both step artifacts and the timeline of step execution history, which are accessible by subsequent steps.
Step Parameter Merging To control step behavior in a dynamic way, Maestro supports both runtime parameters and tags injection in step runtime. This makes a Maestro step more flexible to absorb runtime changes (i.e. overridden parameters) before actually being started. Maestro internally maintains a step parameter map that is initially empty and is updated by merging step parameters in the order below:
Default General Parameters: Parameters merging starts from default parameters that in general every step should have. For example, workflow_instance_id, step_instance_uuid, step_attempt_id and step_id are required parameters for each maestro step. They are internally reserved by maestro and cannot be passed by users.
Injected Parameters: Maestro then merges injected parameters (if present) into the parameter map. The injected parameters come from step runtime, which are dynamically generated based on step schema. Each type of step can have its own schema with specific parameters associated with this step. The step schema can evolve independently with no need to update Maestro code.
Default Typed Parameters: After injecting runtime parameters, Maestro tries to merge default parameters that are related to a specific type of step. For example, foreach step has loop_params and loop_index default parameters which are internally set by maestro and used for foreach step only.
Workflow and Step Info Parameters: These parameters contain information about step and the workflow it belongs to. This can be identity information, i.e. workflow_id and will be merged to step parameter map if present.
Undefined New Parameters: When starting or restarting a maestro workflow instance, users can specify new step parameters that are not present in initial step definition. ParamsManager merges these parameters to ensure they are available at execution time.
Step Definition Parameters: These step parameters are defined by users at definition time and get merged if they are not empty.
Run and Restart Parameters: When starting or restarting a maestro workflow instance, users can override defined parameters by providing run or restart parameters. These two types of parameters are merged at the end so that step runtime can see the most recent and accurate parameter space.
The parameters merging logic can be visualized in the diagram below.
Step Dependencies and Signals
Steps in the Maestro execution workflow graph can express execution dependencies using step dependencies. A step dependency specifies the data-related conditions required by a step to start execution. These conditions are usually defined based on signals, which are pieces of messages carrying information such as parameter values and can be published through step outputs or external systems like SNS or Kafka messages.
Signals in Maestro serve both signal trigger pattern and signal dependencies (a publisher-subscriber) pattern. One step can publish an output signal (a sample example) that can unblock the execution of multiple other steps that depend on it. A signal definition includes a list of mapped parameters, allowing Maestro to perform “signal matching” on a subset of fields. Additionally, Maestro supports signal operators like <, >, etc., on signal parameter values.
Netflix has built various abstractions on top of the concept of signals. For instance, a ETL workflow can update a table with data and send signals that unblock steps in downstream workflows dependent on that data. Maestro supports “signal lineage,” which allows users to navigate all historical instances of signals and the workflow steps that match (i.e. publishing or consuming) those signals. Signal triggering guarantees exactly-once execution for the workflow subscribing a signal or a set of joined signals. This approach is efficient, as it conserves resources by only executing the workflow or step when the specified conditions in the signals are met. A signal service is implemented for those advanced abstractions. Please refer to the Maestro blog for further details on it.
Breakpoint
Maestro allows users to set breakpoints on workflow steps, functioning similarly to code-level breakpoints in an IDE. When a workflow instance executes and reaches a step with a breakpoint, that step enters a “paused” state. This halts the workflow graph’s progression until a user manually resumes from the breakpoint. If multiple instances of a workflow step are paused at a breakpoint, resuming one instance will only affect that specific instance, leaving the others in a paused state. Deleting the breakpoint will cause all paused step instances to resume.
This feature is particularly useful during the initial development of a workflow, allowing users to inspect step executions and output data. It is also beneficial when running a step multiple times in a “foreach” pattern with various input parameters. Setting a single breakpoint on a step will cause all iterations of the foreach loop to pause at that step for debugging purposes. Additionally, the breakpoint feature allows human intervention during the workflow execution and can also be used for other purposes, e.g. supporting mutating step states while the workflow is running.
Timeline
Maestro includes a step execution timeline, capturing all significant events such as execution state machine changes and the reasoning behind them. This feature is useful for debugging, providing insights into the status of a step. For example, it logs transitions such as “Created” and “Evaluating params”, etc. An example of a timeline is included here for reference. The implemented step runtimes can add the timeline events into the timeline to surface the execution information to the end users.
Retry Policies
Maestro supports retry policies for steps that reach a terminal state due to failure. Users can specify the number of retries and configure retry policies, including delays between retries and exponential backoff strategies, in addition to fixed interval retries. Maestro distinguishes between two types of retries: “platform” and “user.” Platform retries address platform-level errors unrelated to user logic, while user retries are for user-defined conditions. Each type can have its own set of retry policies.
Automatic retries are beneficial for handling transient errors that can be resolved without user intervention. Maestro provides the flexibility to set retries to zero for non-idempotent steps to avoid retry. This feature ensures that users have control over how retries are managed based on their specific requirements.
Aggregated View
Because a workflow instance can have multiple runs, it is important for users to see an aggregated state of all steps in the workflow instance. Aggregated view is computed by merging base aggregated view with current runs instance step statuses. For example, as you can see on the figure below simulating a simple case, there is a first run, where step1 and step2 succeeded, step3 failed, and step4 and step5 have not started. When the user restarts the run, the run starts from step3 in run 2 with step1 and step2 skipped which succeeded in the previous run. After all steps succeed, the aggregated view shows the run states for all steps.
Rollup
Rollup provides a high-level summary of a workflow instance, detailing the status of each step and the count of steps in each status. It flattens steps across the current instance and any nested non-inline workflows like subworkflows or foreach steps. For instance, if a successful workflow has three steps, one of which is a subworkflow corresponding to a five-step workflow, the rollup will indicate that seven steps succeeded. Only leaf steps are counted in the rollup, as other steps serve merely as pointers to concrete workflows.
Rollup also retains references to any non-successful steps, offering a clear overview of step statuses and facilitating easy navigation to problematic steps, even within nested workflows. The aggregated rollup for a workflow instance is calculated by combining the current run’s runtime data with a base rollup. The current state is derived from the statuses of active steps, including aggregated rollups for foreach and subworkflow steps. The base rollup is established when the workflow instance begins and includes statuses of inline steps (excluding foreach and subworkflows) from the previous run that are not part of the current run.
For subworkflow steps, the rollup simply reflects the rollup of the subworkflow instance. For foreach steps, the rollup combines the base rollup of the foreach step with the current state rollup. The base is derived from the previous run’s aggregated rollup, excluding the iterations to be restarted in the new run. The current state is periodically updated by aggregating rollups of running iterations until all iterations reach a terminal state.
Due to these processes, the rollup model is eventually consistent. While the figure below illustrates a straightforward example of rollup, the calculations can become complex and recursive, especially with multiple levels of nested foreaches and subworkflows.
Maestro Event Publishing
When workflow definition, workflow instance or step instance is changed, Maestro generates an event, processes it internally and publishes the processed event to external system(s). Maestro has both internal and external events. The internal event tracks changes within the life cycle of workflow, workflow instance or step instance. It is published to an internal queue and processed within Maestro. After internal events are processed, some of them will be transformed into external event and sent out to the external queue (i.e. SNS, Kafka). The external event carries maestro status change information for downstream services. The event publishing flow is illustrated in the diagram below:
As shown in the diagram, the Maestro event processor bridges the two aforementioned Maestro events. It listens on the internal queue to get the published internal events. Within the processor, the internal job event is processed based on its type and gets converted to an external event if needed. The notification publisher at the end emits the external event so that downstream services can consume.
The downstream services are mostly event-driven. The Maestro event carries the most useful message for downstream services to capture different changes in Maestro. In general, these changes can be classified into two categories: workflow change and instance status change. The workflow change event is associated with actions at workflow level, i.e definition or properties of a workflow has changed. Meanwhile, instance status change tracks status transition on workflow instance or step instance.
Get Started with Maestro
Maestro has been extensively used within Netflix, and today, we are excited to make the Maestro source code publicly available. We hope that the scalability and usability that Maestro offers can expedite workflow development outside Netflix. We invite you to try Maestro, use it within your organization, and contribute to its development.
You can find the Maestro code repository at github.com/Netflix/maestro. If you have any questions, thoughts, or comments about Maestro, please feel free to create a GitHub issue in the Maestro repository. We are eager to hear from you.
We are taking workflow orchestration to the next level and constantly solving new problems and challenges, please stay tuned for updates. If you are passionate about solving large scale orchestration problems, please join us.
Acknowledgements
Thanks to other Maestro team members, Binbing Hou, Zhuoran Dong, Brittany Truong, Deepak Ramalingam, Moctar Ba, for their contributions to the Maestro project. Thanks to our Product Manager Ashim Pokharel for driving the strategy and requirements. We’d also like to thank Andrew Seier, Romain Cledat, Olek Gorajek, and other stunning colleagues at Netflix for their contributions to the Maestro project. We also thank Prashanth Ramdas, Eva Tse, David Noor, Charles Smith and other leaders of Netflix engineering organizations for their constructive feedback and suggestions on the Maestro project.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024
The Data Engineering Open Forum at Netflix on April 18th, 2024.
At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale. Netflix is not the only place where data engineers are solving challenging problems with creative solutions. On April 18th, 2024, we hosted the inaugural Data Engineering Open Forum at our Los Gatos office, bringing together data engineers from various industries to share, learn, and connect.
At the conference, our speakers share their unique perspectives on modern developments, immediate challenges, and future prospects of data engineering. We are excited to share the recordings of talks from the conference with the rest of the world.
Summary: At Netflix, hundreds of thousands of workflows and millions of jobs are running every day on our big data platform, but diagnosing and remediating job failures can impose considerable operational burdens. To handle errors efficiently, Netflix developed a rule-based classifier for error classification called “Pensive.” However, as the system has increased in scale and complexity, Pensive has been facing challenges due to its limited support for operational automation, especially for handling memory configuration errors and unclassified errors. To address these challenges, we have developed a new feature called “Auto Remediation,” which integrates the rules-based classifier with an ML service.
Automating the Data Architect: Generative AI for Enterprise Data Modeling
Speaker: Jide Ogunjobi (Founder & CTO at Context Data)
Summary: As organizations accumulate ever-larger stores of data across disparate systems, efficiently querying and gaining insights from enterprise data remain ongoing challenges. To address this, we propose developing an intelligent agent that can automatically discover, map, and query all data within an enterprise. This “Enterprise Data Model/Architect Agent” employs generative AI techniques for autonomous enterprise data modeling and architecture.
Tulika Bhatt, Senior Data Engineer at Netflix, shared how her team manages impression data at scale.
Speaker:Tulika Bhatt (Senior Data Engineer at Netflix)
Summary: Netflix generates approximately 18 billion impressions daily. These impressions significantly influence a viewer’s browsing experience, as they are essential for powering video ranker algorithms and computing adaptive pages, With the evolution of user interfaces to be more responsive to in-session interactions, coupled with the growing demand for real-time adaptive recommendations, it has become highly imperative that these impressions are provided on a near real-time basis. This talk will delve into the creative solutions Netflix deploys to manage this high-volume, real-time data requirement while balancing scalability and cost.
Reflections on Building a Data Platform From the Ground Up in a Post-GDPR World
Summary: The requirements for creating a new data warehouse in the post-GDPR world are significantly different from those of the pre-GDPR world, such as the need to prioritize sensitive data protection and regulatory compliance over performance and cost. In this talk, Jessica Larson shares her takeaways from building a new data platform post-GDPR.
Unbundling the Data Warehouse: The Case for Independent Storage
Speaker: Jason Reid (Co-founder & Head of Product at Tabular)
Summary: Unbundling a data warehouse means splitting it into constituent and modular components that interact via open standard interfaces. In this talk, Jason Reid discusses the pros and cons of both data warehouse bundling and unbundling in terms of performance, governance, and flexibility, and he examines how the trend of data warehouse unbundling will impact the data engineering landscape in the next 5 years.
Clark Wright, Staff Analytics Engineer at Airbnb, talked about the concept of Data Quality Score at Airbnb.
Data Quality Score: How We Evolved the Data Quality Strategy at Airbnb
Speaker: Clark Wright (Staff Analytics Engineer at Airbnb)
Summary: Recently, Airbnb published a post to their Tech Blog called Data Quality Score: The next chapter of data quality at Airbnb. In this talk, Clark Wright shares the narrative of how data practitioners at Airbnb recognized the need for higher-quality data and then proposed, conceptualized, and launched Airbnb’s first Data Quality Score.
Speaker: Iaroslav Zeigerman (Co-Founder and Chief Architect at Tobiko Data)
Summary: The development and evolution of data pipelines are hindered by outdated tooling compared to software development. Creating new development environments is cumbersome: Populating them with data is compute-intensive, and the deployment process is error-prone, leading to higher costs, slower iteration, and unreliable data. SQLMesh, an open-source project born from our collective experience at companies like Airbnb, Apple, Google, and Netflix, is designed to handle the complexities of evolving data pipelines at an internet scale. In this talk, Iaroslav Zeigerman discusses challenges faced by data practitioners today and how core SQLMesh concepts solve them.
If you are interested in attending a future Data Engineering Open Forum, we highly recommend you join our Google Group to stay tuned to event announcements.
Earlier this summer Netflix held our first-ever Data Engineering Forum. Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
You can find each of the talks below with a short description of each, or you can go straight to the playlist on YouTube here.
Chris Stephens, Data Engineer, Content & Studio and Pedro Duarte, Software Engineer, Consolidated Logging walk engineers new to Netflix through the building blocks of the Netflix Data Engineering stack. Learn more about how batch and streaming data pipelines are built at Netflix.
Lee Woodridge and Pallavi Phadnis, Data Engineers at Netflix, talk about how you can apply different processing strategies for your batch pipelines by implementing generic abstractions to help scale, be more efficient, handle late-arriving data, and be more fault tolerant.
Mark Cho, Guil Pires and Sujay Jain, Engineers from the Netflix Data Platform talk about how a managed Streaming SQL using Apache Flink can help unlock new Stream Processing use cases at Netflix. You can read more about Data Mesh, Netflix’s next-generation stream processing platform, here
Holden Karau, OSS Engineer, Data Platform Engineering, talks about the importance of reliable data pipelines and how to build them covering tools from testing to validation and auditing. The talk uses Apache Spark as an example, but the concepts generalize regardless of your specific tools.
Tristan Reid, software engineer, shares experiences about the Knowledge Management project at Netflix, which seeks to leverage language modeling techniques and metadata from internal systems to improve the impact of the >100K memos that circulate within the company.
Abhinaya Shetty and Bharath Mummadisetty, Data Engineers from Netflix’s Membership Data Engineering team, introduce Psyberg, an incremental ETL framework. Learn about how Psyberg leverages Iceberg metadata to handle late-arriving data, and improves data pipelines while simplifying on-call life!
Judit Lantos, Data Engineer, Member Experience Data Engineering, shares a case study to demonstrate an effective approach for optimizing complex ETL jobs.
In the last 2 decades, Netflix has revolutionized the way video content is consumed, however, there is significant work to be done in revolutionizing how movies and tv shows are made. In this video, Sr. Data Engineers Amanual Kahsay and Dao Mi showcase how data and insights are being utilized to accomplish such a vision.
We hope that our fellow members of the Data Engineering Community find these videos useful and engaging. Please follow our Netflix Data Twitter account for updates and notifications of future Data Engineering Summits!
Like many other companies, Grab uses marketing communications to notify users of promotions or other news. If a user receives these notifications from multiple companies, it would be a form of information overload and they might even start considering these communications as spam. Over time, this could lead to some users revoking their consent to receive marketing communications altogether. Hence, it is important to find a rate-limited solution that sends the right amount of communications to our users.
Background
In Grab, marketing emails and push notifications are part of carefully designed campaigns to ensure that users get the right notifications (i.e. based on past orders or usage patterns). Trident is Grab’s in-house tool to compose these campaigns so that they run efficiently at scale. An example of a campaign is scheduling a marketing email blast to 10 million users at 4 pm. Read more about Trident’s architecture here.
Trident relies on Hedwig, another in-house service, to deliver the messages to users. Hedwig does the heavy lifting of delivering large amounts of emails and push notifications to users while maintaining a high query per second (QPS) rate and minimal delay. The following high-level architectural illustration demonstrates the interaction between Trident and Hedwig.
Diagram of data interaction between Trident and Hedwig
The aim is to regulate the number of marketing comms sent to users daily and weekly, tailored based on their interaction patterns with the Grab superapp.
Solution
Based on their interaction patterns with our superapp, we have clustered users into a few segments.
For example:
New: Users recently signed up to the Grab app but haven’t taken any rides yet.
Active: Users who took rides in the past month.
With these metrics, we came up with optimal daily and weekly frequency limit values for each clustered user segment. The solution discussed in this article ensures that the comms sent to a user do not exceed the daily and weekly thresholds for the segment. This is also called frequency capping.
However, frequency capping can be split into two sub-problems:
Efficient storage of clustered user data
With a huge customer base of over 270 million users, storing the user segment membership information has to be cost-efficient and memory-sleek. Querying the segment to which a user belongs should also have minimal latency.
Persistent tracking of comms sent per user
To stay within the daily and weekly thresholds, we need to actively track the number of comms sent to each user, which can be referred to make rate limiting decisions. The rate limiting logic should also have minimal latency, be cost efficient, and not take up too much memory storage.
Optimising storage of user segment data
The problem here is figuring out which segment a particular user belongs to and ensuring that the user doesn’t appear in more than one segment. There are two options that suit our needs and we’ll explain more about each option, as well as what was the best option for us.
Bloom filter
A Bloom filter is a space-efficient probabilistic data structure that addresses this problem well. Simply put, Bloom filters internally use arrays to track memberships of the elements.
For our scenario, each user segment would need its own bloom filter. We used this bloom filter calculator to estimate the memory required for each bloom filter. We found that we needed approximately 1 GB of memory and 23 hash functions to accurately represent the membership information of 270 million users in an array. Additionally, this method guarantees a false positive rate of 1.0E-7, which means 1 in 1 million elements may get wrong membership results because of hash collision.
With Grab’s existing segments, this approach needs 4GB of memory, which may increase as we increase the number of segments in the future. Moreover, the potential hash collision needs to be handled by increasing the memory size with even more hash functions. Another thing to note is that Bloom filters do not support deletion so every time a change needs to be done, you need to create a new version of the Bloom filter. Although Bloom filters have many advantages, these shortcomings led us to explore another approach.
Roaring bitmaps Roaring bitmaps are sets of unsigned integers consisting of containers of disjoint subsets, which can store large amounts of data in a compressed form. Essentially, roaring bitmaps could reduce memory storage significantly and overcome the hash collision problem. To understand the intuition behind this, first, we need to know how bitmaps work and the possible drawbacks behind it.
To represent a list of numbers as a bitmap, we first need to create an array with a size equivalent to the largest element in the list. For every element in the list, we then mark the bit value as 1 in the corresponding index in the array. While bitmaps work very well for storing integers in closer intervals, they occupy more space and become sparse when storing integer ranges with uneven distribution, as shown in the image below.
Diagram of bitmaps with uneven distribution
To reduce memory footprint and improve the performance of bitmaps, there are compression techniques such as Run-Length Encoding (RLE), and Word Aligned Hybrid (WAH). However, this would require additional effort to implement, whereas using roaring bitmaps would solve these issues.
Roaring bitmaps’ hybrid data storage approach offers the following advantages:
Faster set operations (union, intersection, differencing).
Better compression ratio when handling mixed datasets (both dense and sparse data distribution).
Ability to scale to large datasets without significant performance loss.
To summarise, roaring bitmaps can store positive integers from 0 to (2^32)-1. Each positive integer value is converted to a 32-bit binary, where the 16 Most Significant Bits (MSB) are used as the key and the remaining 16 Least Significant Bits (LSB) are represented as the value. The values are then stored in an array, a bitmap, or used to run containers with RLE encoding data structures.
If the number of integers mapped to the key is less than 4096, then all the integers are stored in an array in sorted order and converted into a bitmap container in the runtime as the size exceeds. Roaring bitmap analyses the distribution of set bits in the bitmap container i.e. if the continuous interval of set bits is more than a given threshold, the bitmap container can be more efficiently represented using the RLE container. Internally, the RLE container uses an array where the even indices store the beginning of the runs and the odd indices represent the length of the runs. This enables the roaring bitmap to dynamically switch between the containers to optimise storage and performance.
The following diagram shows how a set of elements with different distributions are stored in roaring bitmaps.
Diagram of how roaring bitmaps store elements with different distributions
In Grab, we developed a microservice that abstracts roaring bitmaps implementations and provides an API to check set membership and enumeration of elements in the sets. Check out this blog to learn more about it.
Distributed rate limiting
The second part of the problem involves rate limiting the number of communication messages sent to users on a daily or weekly basis and each segment has specific daily and weekly limits. By utilising roaring bitmaps, we can determine the segment to which a user belongs. After identifying the appropriate segment, we will apply the personalised limits to the user using a distributed rate limiter, which will be discussed in further detail in the following sections.
Choosing the right datastore
Based on our use case, Amazon ElasticCache for Redis and DynamoDB were two viable options for storing the sent communication messages count per user. However, we decided to choose Redis due to a number of factors:
Higher throughput at lower latency – Redis shards data across nodes in the cluster.
Cost-effective – Usage of Lua script reduces unnecessary data transfer overheads.
Better at handling spiky rate limiting workloads at scale.
Distributed rate limiter
To appropriately limit the comms our users receive, we needed a rate limiting algorithm, which could execute directly in the datastore cluster, then return the results in the application logic for further processing. The two rate limiting algorithms we considered were the sliding window rate limiter and sliding log rate limiter.
The sliding window rate limiter algorithm divides time into a fixed-size window (we defined this as 1 minute) and counts the number of requests within each window. On the other hand, the sliding log maintains a log of each request timestamp and counts the number of requests between two timestamp ranges, providing a more fine-grained method of rate limiting. Although sliding log consumes more memory to store the log of request timestamp, we opted for the sliding log approach as the accuracy of the rate limiting was more important than memory consumption.
The sliding log rate limiter utilises a Redis sorted set data structure to efficiently track and organise request logs. Each timestamp in milliseconds is stored as a unique member in the set. The score assigned to each member represents the corresponding timestamp, allowing for easy sorting in ascending order. This design choice optimises the speed of search operations when querying for the total request count within specific time ranges.
Sliding Log Rate limiter Algorithm:
Input:
# user specific redis key where the request timestamp logs are stored as sorted set
keys => user_redis_key
# limit_value is the limit that needs to be applied for the user
# start_time_in_millis is the starting point of the time window
# end_time_in_millis is the ending point of the time window
# current_time_in_millis is the current time the request is sent
# eviction_time_in_millis, members in the set whose value is less than this will be evicted from the set
args => limit_value, start_time_in_millis, end_time_in_millis, current_time_in_millis, eviction_time_in_millis
Output:
# 0 means not_allowed and 1 means allowed
response => 0 / 1
Logic:
# zcount fetches the count of the request timestamp logs falling between the start and the end timestamp
request_count = zcount user_redis_key start_time_in_millis end_time_in_millis
response = 0
# if the count of request logs is less than allowed limits then record the usage by adding current timestamp in sorted set
if request_count < limit_value then
zadd user_redis_key current_time_in_millis current_time_in_millis
response = 1
# zremrangebyscore removes the members in the sorted set whose score is less than eviction_time_in_millis
zremrangebyscore user_redis_key -inf eviction_time_in_millis
return response
This algorithm takes O(log n) time complexity, where n is the number of request logs stored in the sorted set. It is not possible to evict entries in the sorted set like how we have time-to-live (TTL) for Redis keys. To prevent the size of the sorted set from increasing over time, we have a fixed variable eviction_time_in_millis that is passed to the script. The zremrangebyscore command then deletes members from the sorted set whose score is less than eviction_time_in_millis in O(log n) time complexity.
Lua script optimisations
In Redis Cluster mode, all Redis keys accessed by a Lua script must be present on the same node, and they should be passed as part of the KEYS input array of the script. If the script attempts to access keys located on different nodes within the cluster, a CROSSSLOT error will be thrown. Redis keys, or userIDs, are distributed across multiple nodes in the cluster so it is not feasible to send a batch of userIDs within the same Lua script for rate limiting, as this might result in a CROSSSLOT error.
Invoking a separate Lua script call for each user is a possible approach, but it incurs a significant number of network calls, which can be optimised further with the following approach:
Upload the Lua script into the Redis server during the server startup with the SCRIPT LOAD command and we get the SHA1 hash of the script if the upload is successful.
The SHA1 hash can then be used to invoke the Lua script with the EVALSHA command passing the keys and arguments as script input.
Redis pipelining takes in multiple EVALSHA commands that call the Lua script and each invocation corresponds to a userID for getting the rate limiting result.
Redis pipelining groups the EVALSHA Redis commands with Redis keys located on the same nodes internally. It then sends the grouped commands in a single network call to the relevant nodes within the Redis cluster and provides the rate limiting outcome to the client.
Since Redis operates on a single thread, any long-running Lua script can cause other Redis commands to be blocked until the script completes execution. Thus, it’s optimal for the Lua script to execute in under 5 milliseconds. Additionally, the current time is passed as an argument to the script to account for potential variations in time when the script is executed on a node’s replica, which could be caused by clock drift.
By bringing together roaring bitmaps and the distributed rate limiter, this is what our final solution looks like:
Our final solution using roaring bitmaps and distributed rate limiter
The roaring bitmaps structure is serialised and stored in an AWS S3 bucket, which is then downloaded in the instance during server startup. After which, triggering a user segment membership check can simply be done with a local method call. The configuration service manages the mapping information between the segment and allowed rate limiting values.
Whenever a marketing message needs to be sent to a user, we first find the segment to which the user belongs, retrieve the defined rate limiting values from the configuration service, then execute the Lua script to get the rate limiting decision. If there is enough quota available for the user, we send the comms.
The architecture of the messaging service looks something like this:
Architecture of the messaging service
Impact
In addition to decreasing the unsubscription rate, there was a significant enhancement in the latency of sending communications. Eliminating redundant communications also alleviated the system load, resulting in a reduction of the delay between the scheduled time and the actual send time of comms.
Conclusion
Applying rate limiters to safeguard our services is not only a standard practice but also a necessary process. Many times, this can be achieved by configuring the rate limiters at the instance level. The need for rate limiters for business logic may not be as common, but when you need it, the solution must be lightning-fast, and capable of seamlessly operating within a distributed environment.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.