Post Syndicated from Mike Cohen original https://blog.rapid7.com/2023/08/31/untitled-7/

Carlos Canto contributed to this article.
Rapid7 is thrilled to announce version 0.7.0 of Velociraptor is now LIVE and available for download. The focus of this release was on improving user efficiency while also expanding and strengthening the library of VQL plug-ins and artifacts.
Let’s take a look at some of the interesting new features in detail.
GUI improvements
The GUI was updated in this release to improve user workflow and accessibility.
Enhanced client search
In previous versions, client information was written to the datastore in individual files (one file per client record). This works ok, as long as the number of clients is not too large and the filesystem is fast. This has become more critical as users are now deploying Velociraptor with larger deployment sizes, often in excess of 50k.
In this release, the client index was rewritten to store all client records in a single snapshot file, while managing this file in memory. This approach allows client searching to be extremely quick even for large numbers of clients well over 100k.
Additionally, it is now possible to display the total number of hits in each search giving a more comprehensive indication of the total number of clients.

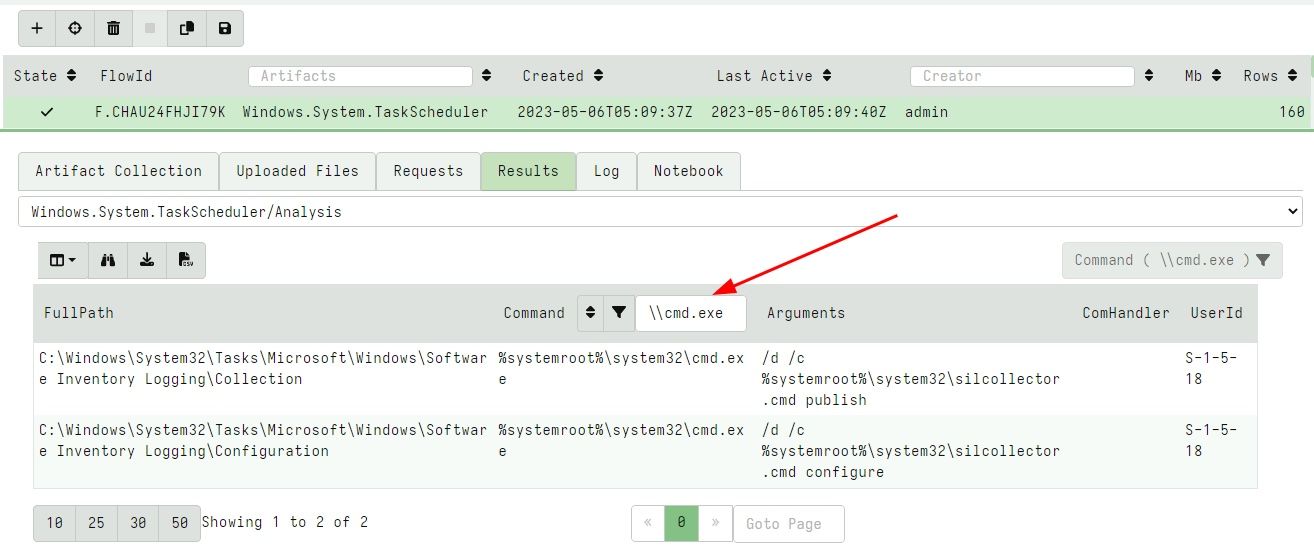
Paged table in Flows list
Velociraptor’s collections view shows the list of collections from the endpoint (or the server). Previously, the GUI limited this view to 100 previous collections. This meant that for heavily collected clients it was impossible to view older collections (without custom VQL).
In this release, the GUI was updated to include a paged table (with suitable filtering and sorting capabilities) so all collections can be accessed.
VQL Plugins and artifacts
Chrome artifacts
Version 0.7.0 added a leveldb parser and several artifacts around Chrome Session Storage. This allows analyzing data that is stored by Chrome locally for various web apps.
Lnk forensics
This release added a more comprehensive Lnk parser covering all known Lnk file features. You can access the Lnk file analysis using the `Windows.Forensics.Lnk` artifact.
Direct S3 accessor
Velociraptor’s accessors provide a way to apply the many plugins that operate on files to other domains. In particular, the glob() plugin allows searching the accessors for filename patterns.
In this release, Velociraptor adds an Amazon S3 accessor. This allows plugins to directly operate on S3 buckets. In particular the glob() plugin can be used to query bucket contents and read files from various buckets. This capability opens the door for sophisticated automation around S3 buckets.
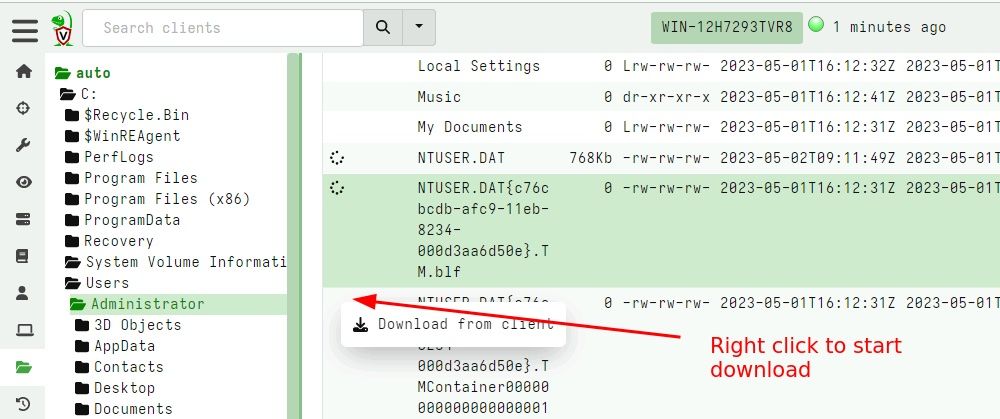
Volume Shadow Copies analysis
Windows Volume Shadow Service (VSS) is used to create snapshots of the drive at a specific point in time. Forensically, this can be very helpful as it captures a point-in-time view of the previous disk state (If the VSS is still around when we perform our analysis).
Velociraptor provides access to the different VSS volumes via the ntfs accessor, and many artifacts previously provided the ability to report files that differed between VSS snapshots.
In the 0.7.0 release, Velociraptor adds the ntfs_vss accessor. This accessor automatically considers different snapshots and deduplicates files that are identical in different snapshots. This makes it much easier to incorporate VSS analysis into your artifacts.
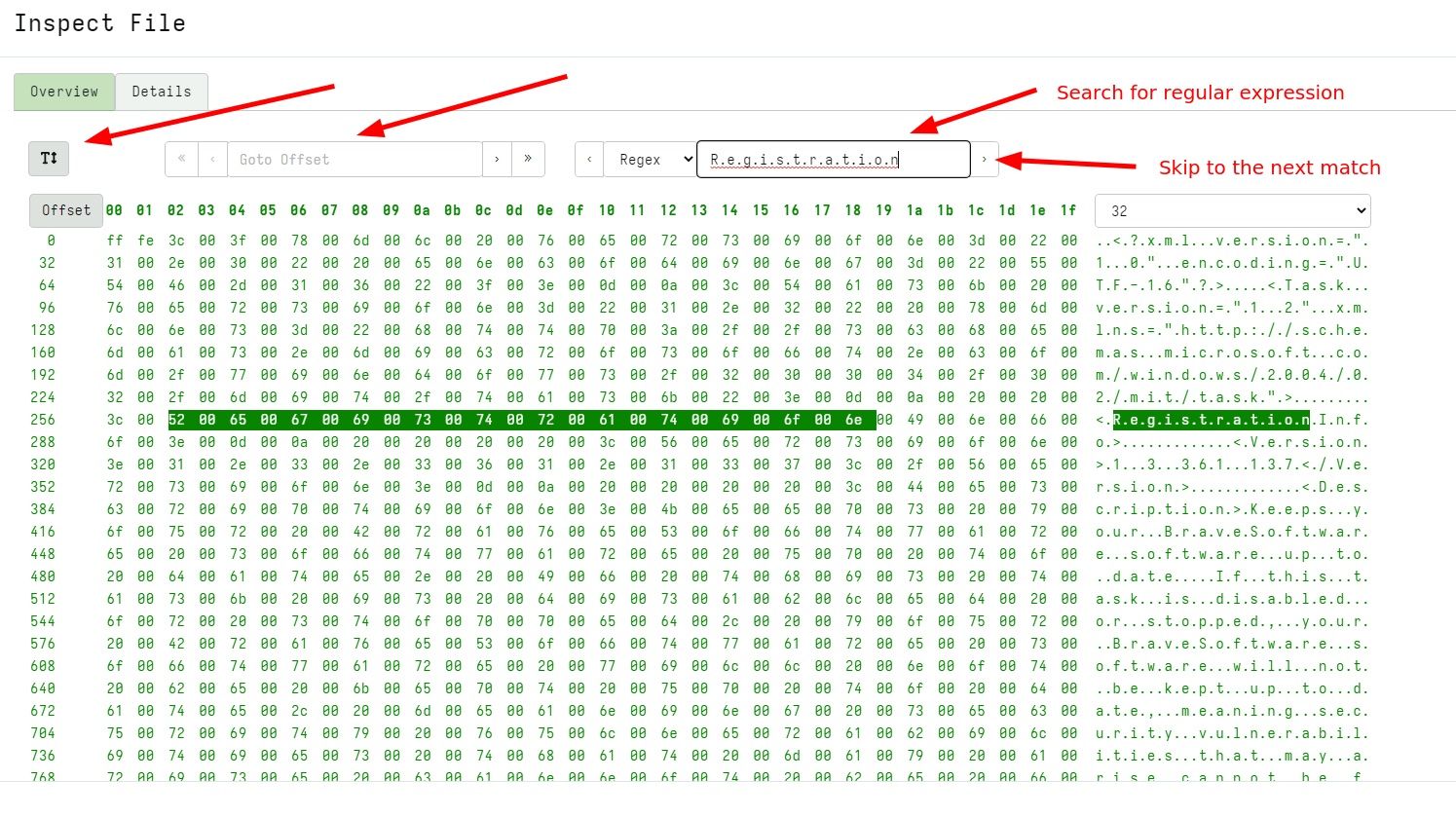
The SQLiteHunter project
Many artifacts consist of parsing SQLite files. For example, major browsers use SQLite files heavily. This release incorporates the SQLiteHunter artifact.
SQLiteHunter is a one stop shop for finding and analyzing SQLite files such as browser artifacts and OS internal files. Although the project started with SQLite files, it now automates a lot of artifacts such as WebCacheV01 parsing and the Windows Search Service – aka Windows.edb (which are ESE based parsers).
This one artifact combines and makes obsolete many distinct older artifacts.
More info can be found at https://github.com/Velocidex/SQLiteHunter.
Glob plugin improvements
The glob() plugin may be the most used plugin in VQL, as it allows for the efficient search of filenames in the filesystem. While the glob() plugin can accept a list of glob expressions so the filesystem walk can be optimized as much as possible, it was previously difficult to know why a particular reported file was chosen.
In this release, the glob() plugin reports the list of glob expressions that caused the match to be reported. This allows callers to more easily combine several file searches into the same plugin call.
URL style paths
In very old versions of Velociraptor, nested paths could be represented as URL objects. Until now, a backwards compatible layer was used to continue supporting this behavior. In the latest release, URL style paths are no longer supported. Instead, use the pathspec() function to build proper OSPath objects.
Server improvements
Velociraptor offers automatic use of Let’s Encrypt certificates. However, Let’s Encrypt can only issue certificates for port 443. This means that the frontend service (which is used to communicate with clients) has to share the same port as the GUI port (which is used to serve the GUI application). This makes it hard to create firewall rules to filter access to the frontend and not to the GUI when used in this configuration.
In the 0.7.0 release, Velociraptor offers the GUI.allowed_cidr option. If specified, the list of CIDR addresses will specify the source IP acceptable to the server for connections to the GUI application (for example 192.168.1.0/24).
This filtering only applies to the GUI and forms an additional layer of security protecting the GUI application (in addition to the usual authentication methods).
Better handling of out of disk errors
Velociraptor can collect data very quickly and sometimes this results in a full disk. Previously, a full disk error could cause file corruption and data loss. In this release, the server monitors its free disk level and disables file writing when the disk is too full. This avoids data corruption when the disk fills up. When space is freed the server will automatically start writing again.
The offline collector
The offline collector is a pre-configured binary which can be used to automatically collect any artifacts into a ZIP file and optionally upload the file to a remote system like a cloud bucket or SMB share.
Previously, Velociraptor would embed the configuration file into the binary so it only needed to be executed (e.g. double clicked). While this method is still supported on Windows, it turned out that on MacOS this is no longer supported as binaries can not be modified after build. Even on Windows, embedding the configuration will invalidate the signature.
In this release, we added a generic collector:

This collector will embed the configuration into a shell script instead of the Velociraptor binary. Users can then launch the offline collector using the unmodified official binary by specifying the --embedded_config flag:
velociraptor-v0.7.0-windows-amd64.exe -- --embedded_config Collector_velociraptor-collector

While the method is required for MacOS, it can also be used for Windows in order to preserve the binary signature.
Conclusions
There are many more new features and bug fixes in the 0.7.0 release. If you’re interested in any of these new features, we welcome you to take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Finally, don’t forget to register for VeloCON 2023, taking place on Wednesday September 13, 2023. VeloCON is a one-day virtual event which includes fascinating discussions, tech talks and the opportunity to get to know real members of the Velociraptor community. It’s a forum to share experiences in using and developing Velociraptor to address the needs of the wider DFIR landscape and an opportunity to take a look ahead at the future of our platform.