Post Syndicated from Conner Goldstein original https://blog.rapid7.com/2025/04/29/deepening-the-mdr-partnership-rapid7-now-delivers-active-remediation-with-velociraptor/
Rapid7 is expanding its response capabilities to meet the demands and relentless pace of today’s threat landscape – and the operational needs of our customers.

Partnership means many things to us here at Rapid7. It means showing up with trusted expertise, providing clear guidance in moments of uncertainty, and helping security teams stay ahead of ever-evolving threats. Most of all, we see partnership as foundational to building security resilience – and that requires not only a proactive, risk-aware mindset but also the capability to respond when the inevitable happens.
As attacks grow faster, more complex, and more persistent, the need for decisive, transparent remediation has become more urgent – some estimates place the average time-to-ransom at just 16.88 hours1 – with that kind of speed, every moment matters. We pride our Managed Detection and Response (MDR) service on delivering best-in-class detection, investigation, and actionable response guidance. Now, we are evolving that partnership – and the strength of your security program – even further.
Introducing Active Remediation with Velociraptor
Powered by our best-in-class, open-source digital forensics and incident response (DFIR) tool, Rapid7 MDR analysts can take direct, approved remediation actions on your behalf – removing malware, terminating rogue processes, and restoring system integrity while minimizing the need to reimage affected endpoints unless it’s truly required. Every action is executed with precision, transparency, and within clearly defined boundaries.
This is more than a new capability. It’s a reflection of our commitment to move in lockstep with you – not just at the point of detection, but all the way through to resolution. From unlimited incident response support to deeply collaborative investigations and tailored recommendations, Rapid7 has always prioritized being hands-on when you need us most. Active Remediation with Velociraptor extends that same principle to the final – and often most difficult – step: taking action on your behalf to eradicate threats.
Delivered with Precision, Transparency, and Trust
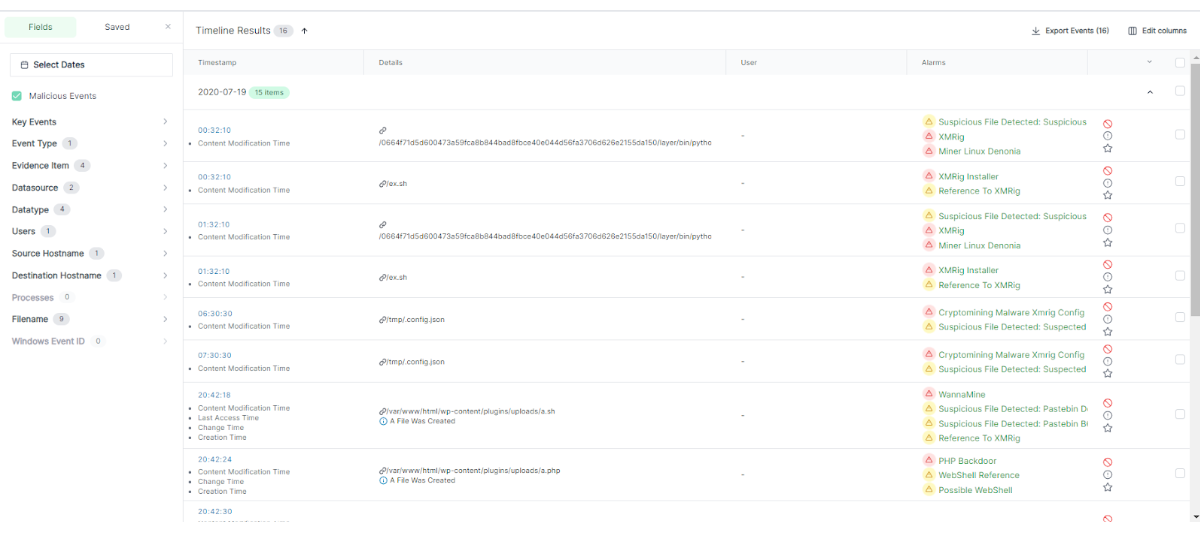
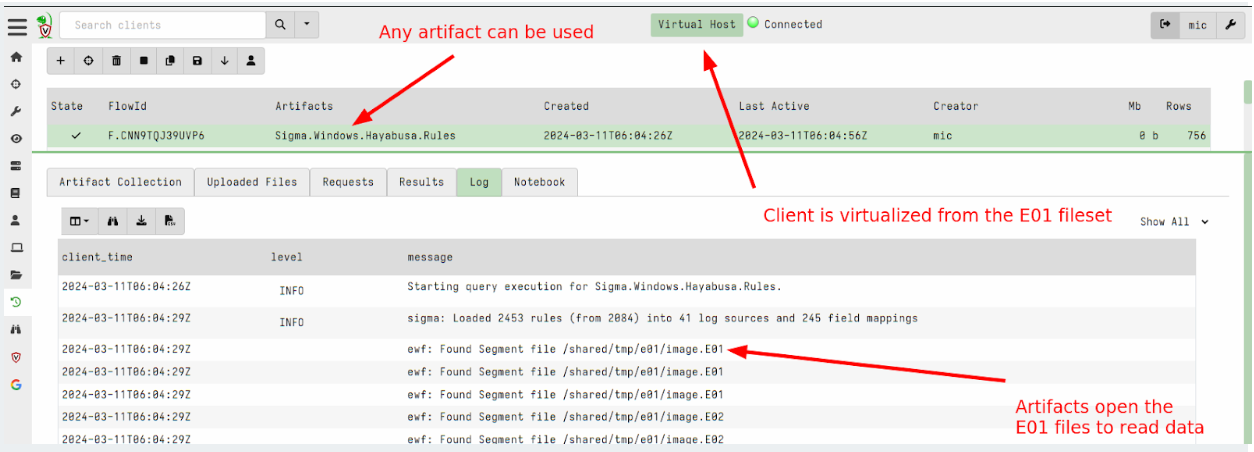
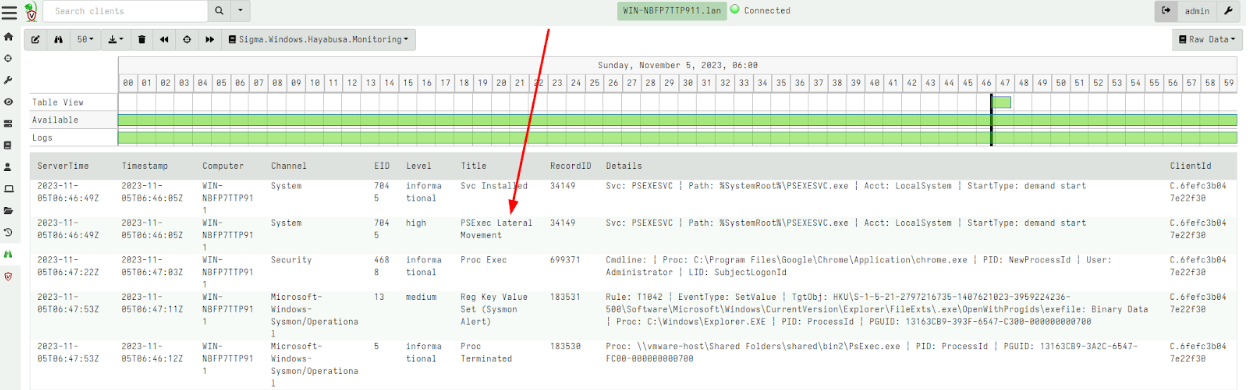
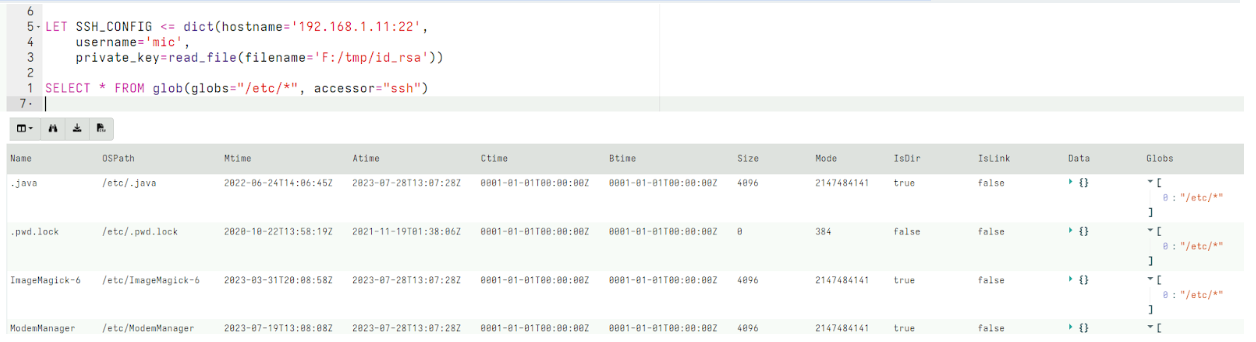
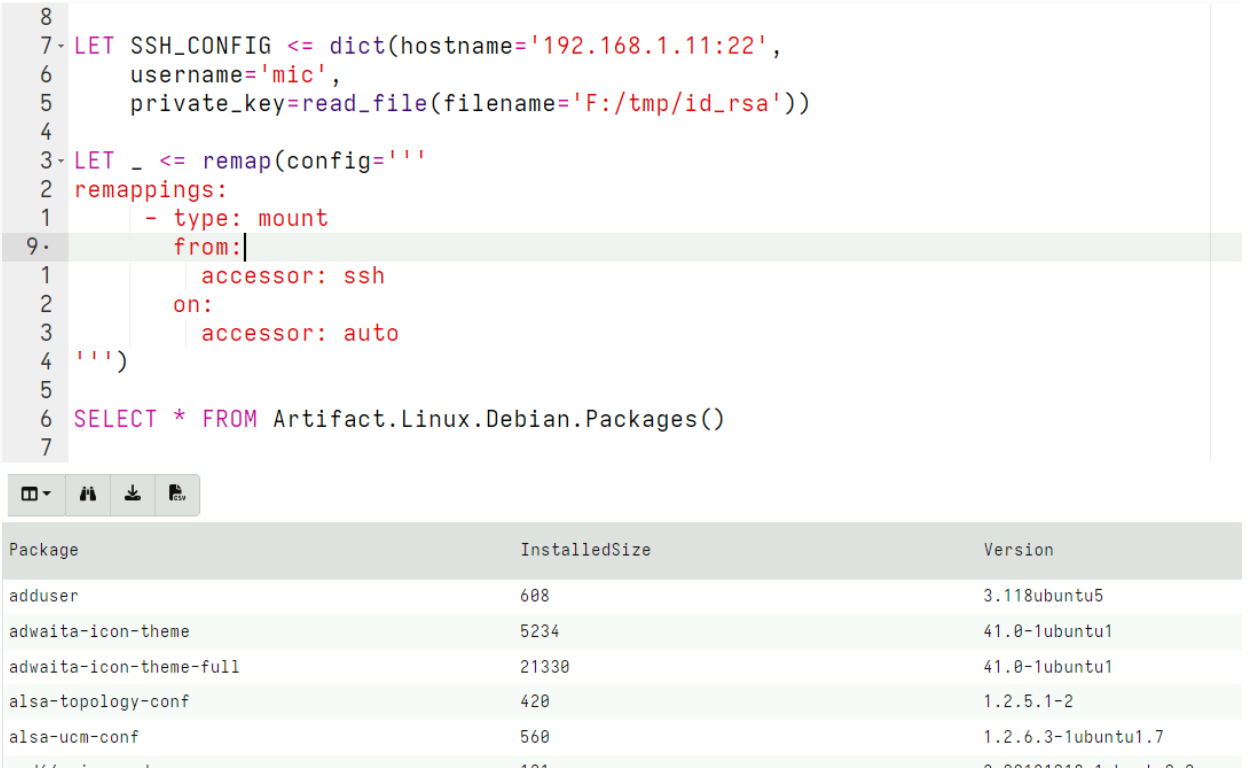
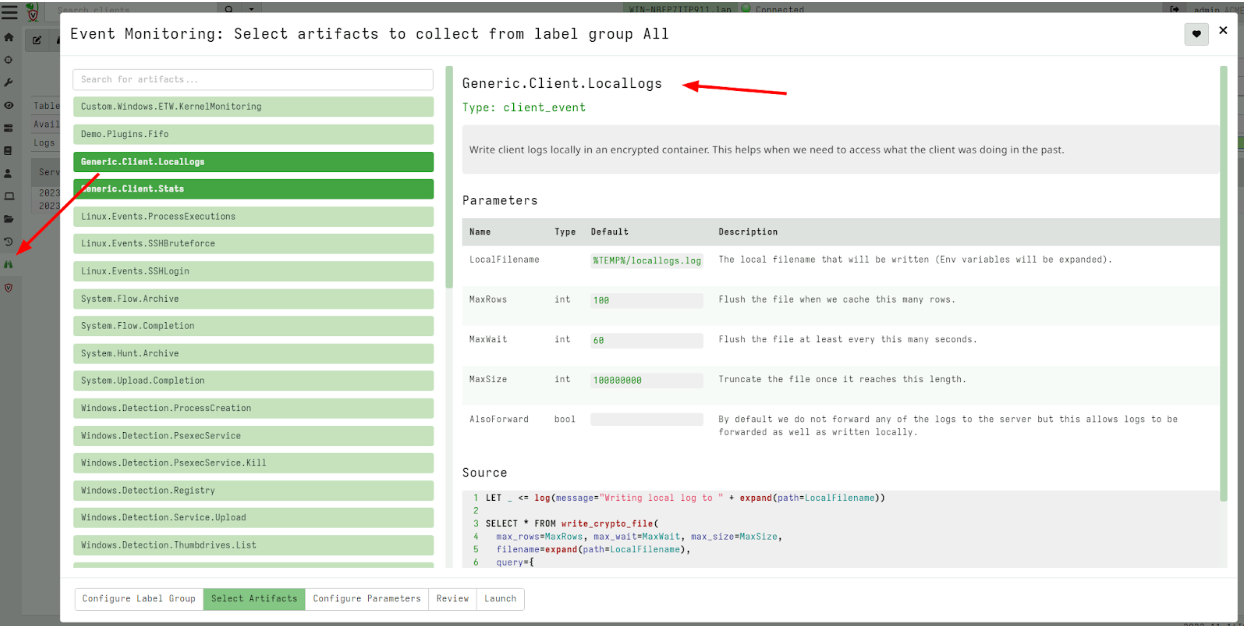
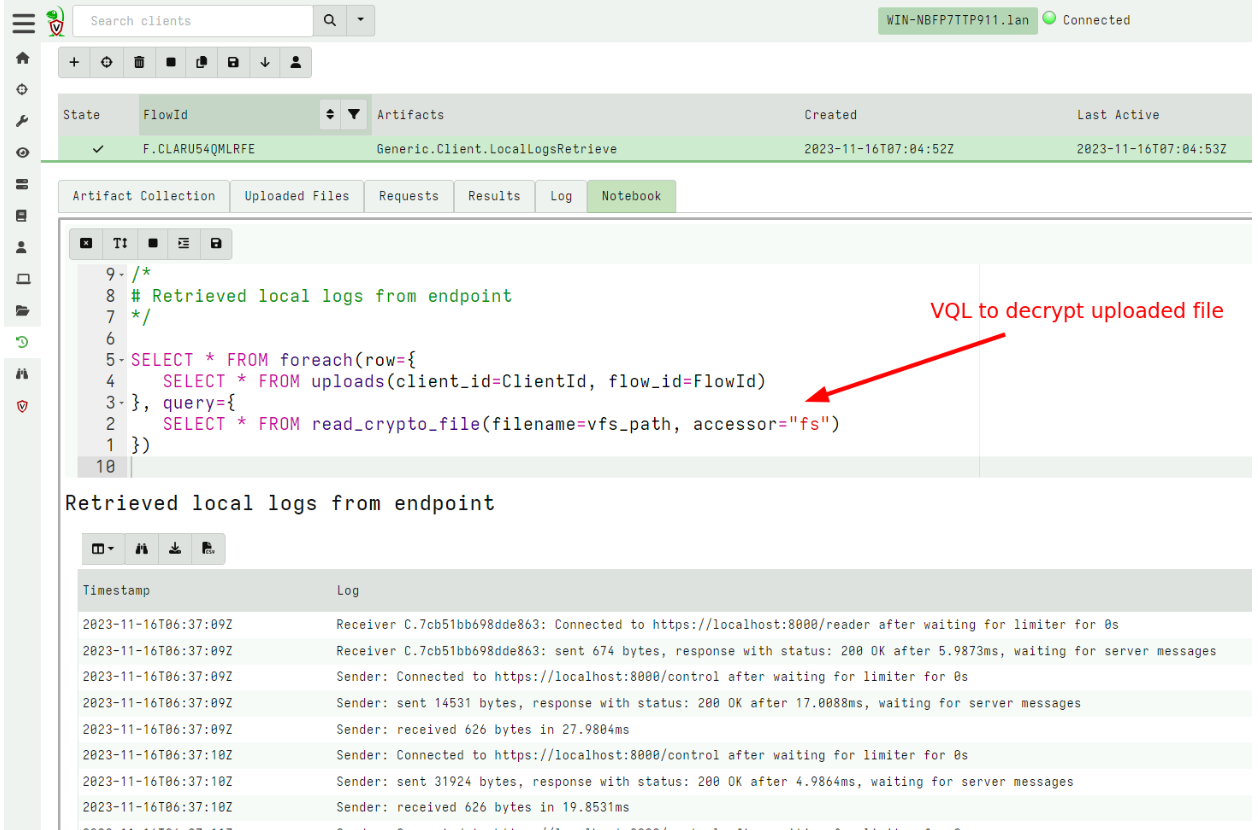
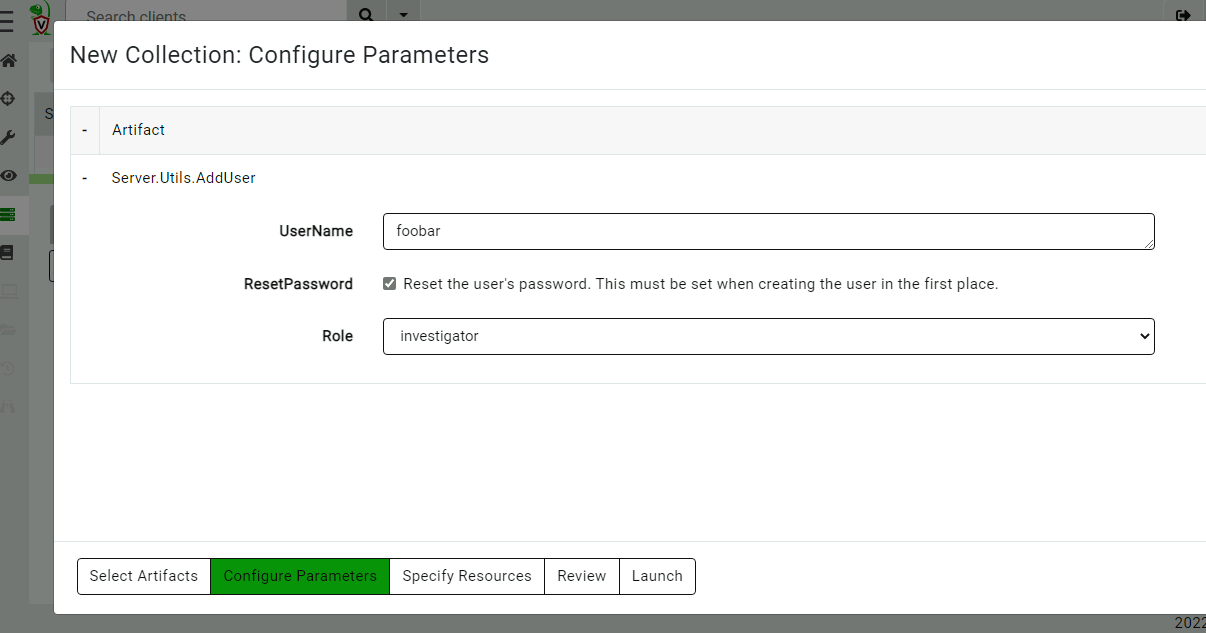
Active Remediation with Velociraptor is designed not just to take action, but to take the right action, the right way. Every remediation workflow is executed by Rapid7’s expert analysts using Velociraptor’s purpose-built query language (VQL) – a DFIR language engineered for precision, traceability, and scale. This allows the analyst to target specific artifacts, processes, and configurations – avoiding the blunt-force actions that often lead to full endpoint reimaging.
- You stay in control – Remediation is performed based on clearly defined and approved scopes and parameters aligned to your security policies.
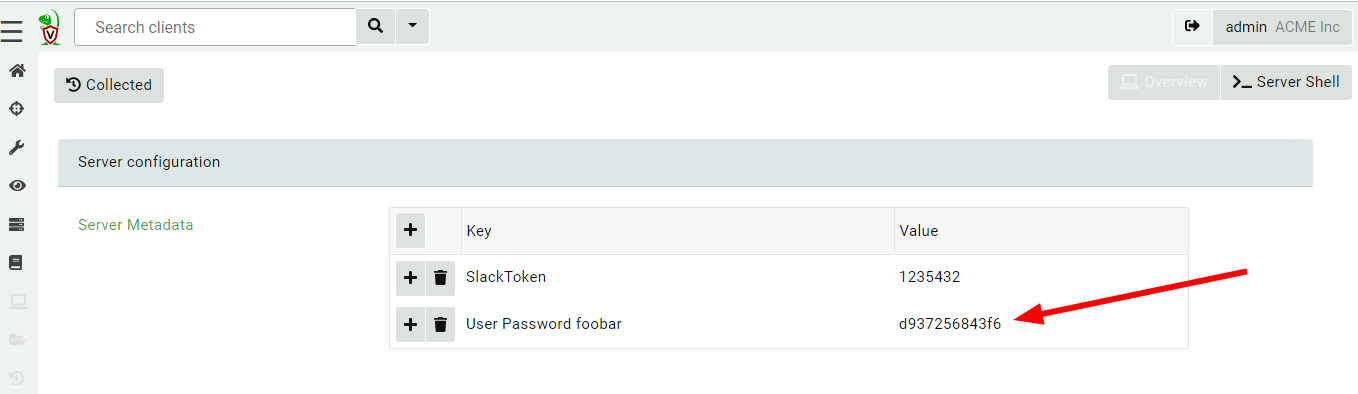
- You see what we do – Every action is logged, auditable, and built using readable logic within Velociraptor, with full visibility provided through detailed post-incident reports.
- You gain precision without disruption – Remove only what’s malicious and reverse unauthorized configurations without pulling systems offline or fully reimaging machines.
Rapid7’s New Response Workflow

- Alert detection: Identify malicious activity across customer endpoints and network.
- Active Response: Quarantine affected endpoints to stem the spread of the attack.
- Rapid7 investigation: SOC validates threat, determines scope, and develops response plan.
- Active Remediation with Velociraptor: Rapid7 analysts remove malicious artifacts with precision.
- Mitigation guidance: Recommendations to help your team prevent threat reemergence.
Remediating in the Real World
Our approach brings analyst-led, logic-driven remediation into live environments – solving the post-containment challenges security teams face every day. Unlike session-based access that relies on endpoints being on and connected to the internet, Rapid7 are delivering remediation that meets the auditability, practicality, and scalability needs of the real world:
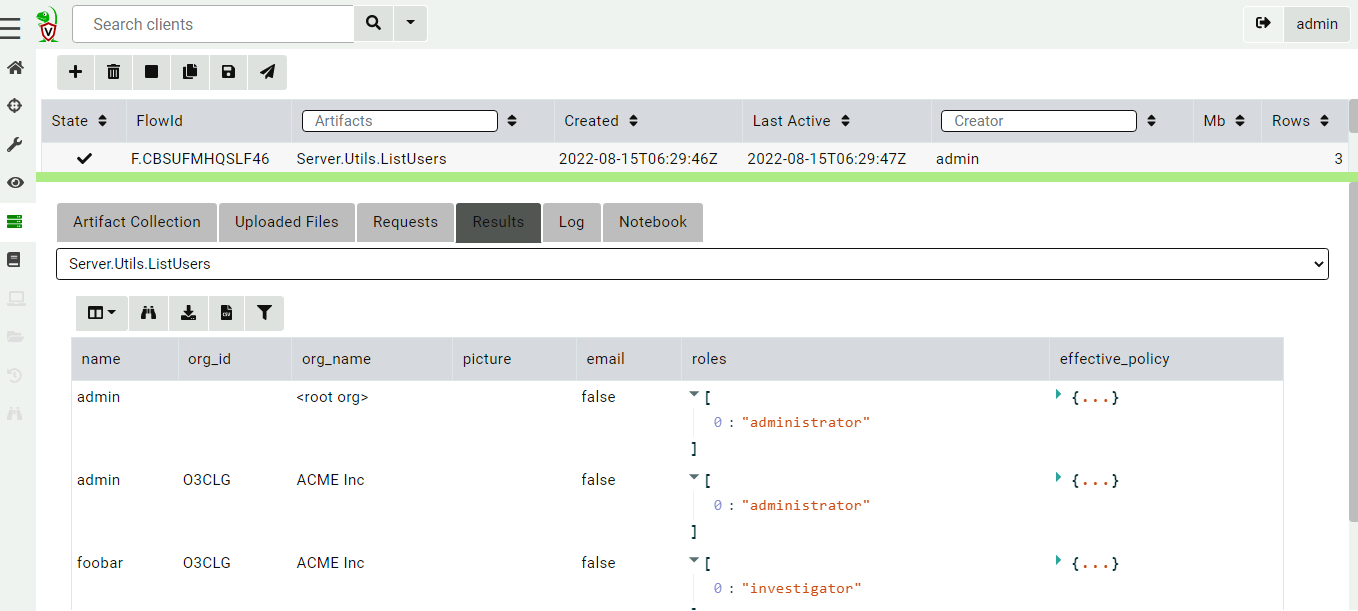
- Targeted threat removal without reimaging: Identify and remove only malicious artifacts – files, processes, persistence mechanisms, or unauthorized configurations – linked to a confirmed threat.
- Outcome: Your endpoints stay online and productive, while the threat is neutralized with minimal disruption. Avoiding unnecessary reimaging means faster recovery, reduced IT workload, and less downtime for end users.
- Controlled execution with transparent logic: Every remediation workflow is written in VQL – visible and reviewable by customers before deployment. There’s no scripting or ‘trust us’ execution.
- Outcome: Builds trust and accountability into the remediation process. You get full visibility into every action, supporting compliance requirements and reducing uncertainty in regulated environments.
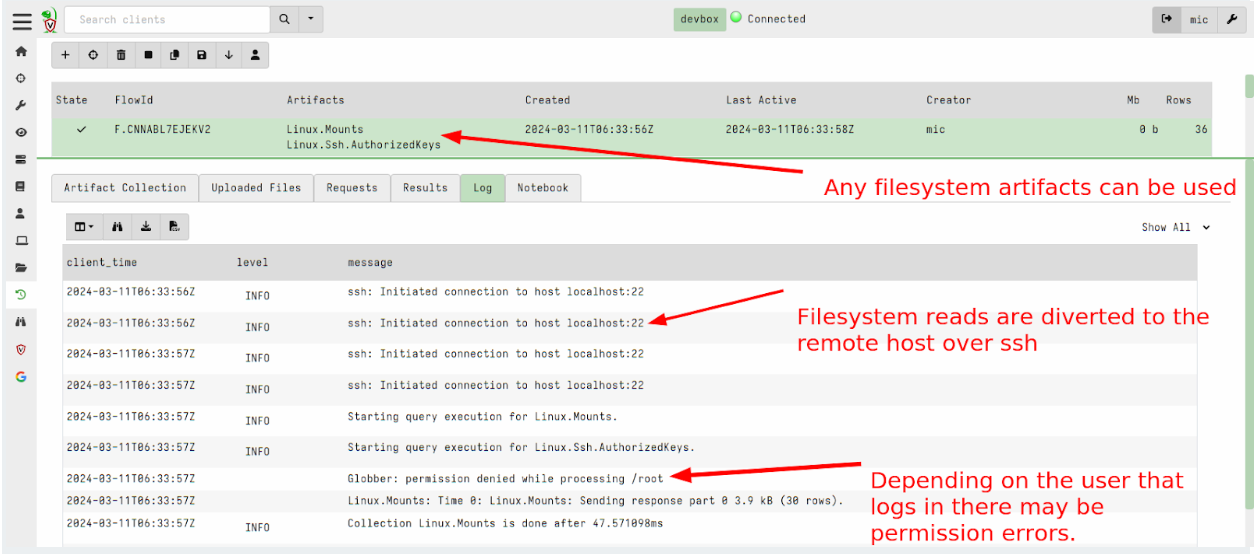
- Distributed remediation across endpoints: When multiple endpoints are compromised by a single campaign – such as credential theft malware – we will queue high-fidelity remediation workflows across many machines simultaneously – even if some are offline.
- Outcome: Lays the foundation for consistent threat removal across your environment without manual intervention or system-by-system cleanup. This enables a timely, coordinated response that keeps pace with fast-moving attacks.
- Reducing friction between security and IT teams
Rather than working through lengthy remediation steps with your IT team, we execute the most critical actions directly – within approved scope – and document every step. - Outcome: Fewer delays and less back-and-forth between teams. With Rapid7 handling the complete, end-to-end lifecycle of an alert, internal teams stay focused on business priorities, knowing remediation is being executed safely and effectively.
Setting the stage for remediation with Active Response
Remediation begins with strategic containment and detailed investigation. Rapid7’s Active Response enables rules-based quarantining of affected endpoints in the immediate aftermath of a credible threat detection. This stops lateral movement before it begins and preserves the system state for investigation.
Active Remediation builds directly on this foundation. By first containing the threat, we can then investigate confidently and move quickly to identify and remove malicious artifacts – mitigating the risk of reinfection or spread. The integrated workflow – from containment to investigation to remediation – helps ensure our response is not only fast, but precise.
Together, Active Response and Active Remediation form the cornerstone of a continuous response pipeline that reduces attacker dwell time, limits impact, and restores normal operations faster.
Unlimited incident response – now deeper than ever
Rapid7 MDR customers have long relied on Rapid7’s unlimited DFIR support to guide them through the most critical moments of a threat. That hands-on expertise – delivered without surprise fees, hourly caps, or the need to navigate third-party providers and tools – is a defining part of how we ensure customers receive the fastest, most comprehensive response possible.
Active Remediation builds on that foundation by closing the final gap in the response lifecycle. Where detection, containment, and investigation have long been Rapid7’s strengths, we can now fully execute on the next step: resolving the threat. This combination of expert-led triage with decisive, hands-on remediation, delivers a more unified, end-to-end response – minimizing delays, reducing reliance on your internal resources, and accelerating your path to recovery. It’s not just about reacting faster – it’s about responding smarter, start to finish.
More than a capability – it’s a commitment
The Rapid7 MDR service has always been built around standing shoulder to shoulder with our customers, especially when it matters most. As we expand this partnership through the finale of the detection and response lifecycle – taking action to remove threats, reduce disruption, and accelerate recovery – we do it with the same transparency, accountability, and respect for your control that defines every part of the Rapid7 experience. In the name of building true security resilience, partnership doesn’t end with guidance – it means staying with you all the way through to resolution. Active Remediation with Velociraptor is in closed early access and will roll out to MDR customers in mid-May. To learn more, please contact your account team or Cybersecurity Advisor.