Post Syndicated from Nikki Rouda original https://aws.amazon.com/blogs/big-data/zero-etl-how-aws-is-tackling-data-integration-challenges/
In this blog post, we show you how Amazon Web Services (AWS) is simplifying data integration with zero-ETL while realizing performance benefits and cost optimizations. As organizations gather data for analytics and AI, they are increasingly finding themselves caught in a complex web of extract, transform, and load (ETL) pipelines—the traditional backbone of data integration. While these pipelines still serve their purpose, they’ve also become a costly bottleneck, consuming valuable staff time and resources that could be better spent on innovation. Now, zero-ETL integrations are simplifying how businesses handle data integration. Zero-ETL can eliminate the need for complex data pipelines while still maintaining seamless data flow between your operational databases and analytics environments, including data warehouses, data lakes, and the combination of these into lakehouses.
Thousands of AWS customers have used zero-ETL to process petabytes of data with thousands of integrations. AWS customers are using integrations with services such as Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon Redshift, Amazon DynamoDB, and Amazon SageMaker, along with multiple third-party software as a service (SaaS) applications. These zero-ETL integrations are transforming data integration from a technical burden into a strategic advantage, so that businesses can focus on deriving actionable insights from their data.
The evolution of data integration
Traditionally, organizations have relied on ETL processes to move data between operational databases and analytics systems. This approach, while functional, presents several key challenges that can hinder an organization’s ability to derive timely insights from their data.
Building and maintaining ETL pipelines requires significant engineering resources, often diverting talent from core business initiatives. These pipelines need constant attention, updates, and optimization, creating an ongoing operational burden. As data volumes grow, updates happen faster, and schemas evolve, the complexity of these pipelines increases exponentially.
Pipeline failures can cause delays in data availability, impacting decision-making processes. When a pipeline breaks, it can take hours or even days to diagnose and fix the issue, during which time critical business decisions might be made with outdated information. This lag between data creation and availability for analysis can be a significant competitive disadvantage in fast-moving industries.
Complex transformations introduce potential points of failure, increasing the risk of data inconsistencies. Each transformation step is an opportunity for errors to creep in, whether through bugs in the transformation logic or unexpected edge cases in the data. Making sure of data quality and consistency across these transformations requires rigorous testing and validation processes.
Furthermore, as organizations add new data sources, the operational overhead of managing multiple pipelines increases exponentially. Each new source typically requires its own pipeline, complete with custom logic for extraction, transformation, and loading. This proliferation of pipelines can quickly become unwieldy, making it difficult to maintain a coherent data strategy across the organization.
How zero-ETL makes data accessible for analytics
AWS zero-ETL integrations provide automated, fully managed data replication from both AWS services and third-party applications to AWS data warehouses, data lakes, and lakehouses without requiring custom pipeline development. This innovative approach offers numerous benefits across several key areas, fundamentally changing how organizations approach data integration.
Simplified data architecture
Zero-ETL integrations offer low-code or no-code setup, which means that organizations can quickly establish data access and flows without specialized expertise. This democratization of data integration means that teams across the organization can set up and manage their own data integration, reducing bottlenecks and accelerating time-to-insight.
Zero-ETL integrations automatically handle data definition languages (DDLs), schema changes, and data type mapping, so that data in your analytics store is correct and complete. This data is immediately available for business consumption, helping to ensure consistency between source and target systems. This automatic mapping significantly reduces the risk of errors that can occur with manual mapping processes, helping to ensure that data types and structures are correctly translated between systems.
Built-in monitoring and error handling capabilities provide visibility into the replication process and help maintain data integrity. Administrators can set up alerts for specific conditions, such as replication lag or failed transfers, allowing for proactive management of the data integration process.
Zero-ETL integrations automatically handle full load and ongoing changes through change data capture (CDC) for quick access to the latest data. Organizations can use this dual capability to migrate existing data while also making sure that new data is continuously replicated, providing a seamless transition to the new integration model.
Near real-time analytics
With zero-ETL integrations, data is typically available in the target system within seconds or minutes of updates in the source system. This near real-time capability supports even high-volume transactional workloads, enabling timely insights for fast-moving businesses. For example, an ecommerce company can analyze purchase patterns almost immediately, enabling real-time inventory management and personalized recommendations.
The solution maintains consistent performance at scale, accommodating growing data volumes without degradation. As businesses grow and data volumes increase, the zero-ETL integration scales automatically, keeping performance consistent even as the demands on the system increase.
Built-in fault tolerance and recovery mechanisms help ensure high availability and data consistency. If an issue occurs during replication, manual or automatic retries of failed operations help resume from the last successful point, minimizing data loss and helping to ensure consistency between source and target systems.
Reduced operational burden
By eliminating the need for custom pipeline maintenance, zero-ETL integrations free up valuable engineering resources. Data engineers can focus on higher-value tasks such as data modeling, advanced analytics, and machine learning, rather than spending time on routine pipeline maintenance.
There is no additional infrastructure to manage, reducing complexity and cost. The zero-ETL integration runs on AWS-managed infrastructure, eliminating the need for customers to provision and manage servers, storage, or networking components for data integration.
The system automatically handles schema changes, adapting to evolving data structures without manual intervention. When a new column is added to a source table, for example, the zero-ETL integration will automatically detect this change and update the target schema accordingly, helping to ensure that the data remains in sync without any manual effort.
Native integration with AWS security controls helps ensure that data remains protected throughout the replication process. This includes support for encryption at rest and in transit, and integration with AWS Key Management Service (AWS KMS) for compliance with various regulatory standards.
Customer success with Zero-ETL
Since launch, zero-ETL integrations have seen rapid customer adoption. The versatility and benefits of zero-ETL integrations are demonstrated through diverse customer implementations across industries.
Yossi Shlomo, Director of Payment Systems Architecture at MassPay, a leading global payment solutions provider, stated, “Zero-ETL has been transformative for teams at MassPay. By using Amazon Aurora MySQL-Compatible Edition zero-ETL integration with Amazon Redshift, we’ve streamlined data flow from our core payment systems into analytics environments used for fraud detection, compliance case management, and business insights. This shift reduced latency by >90% and gives our teams near-instant access to critical data to optimize processes and decisions.” Because of this dramatic improvement in data freshness and availability, MassPay can make more timely and informed decisions, improving their service to customers and their competitive position in the market.
Available AWS service Integrations
AWS currently offers zero-ETL integrations designed to seamlessly connect popular AWS database services with Amazon Redshift, a fully managed data warehouse service. These include Amazon Aurora MySQL-Compatible, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon DynamoDB. This means that organizations can use the strengths of each service—the transactional capabilities of Aurora and Amazon RDS, the flexibility of DynamoDB, and the analytical power of Amazon Redshift—while minimizing the complexity of data movement between these systems.
Third-party integration support
Zero-ETL integrations have expanded beyond AWS services to support a wide range of third-party data too. AWS has zero-ETL integrations with sources including SAP OData, Salesforce, Salesforce Marketing Cloud Account Engagement, ServiceNow, Zendesk, and Zoho CRM, plus Facebook Ads and Instagram Ads. Targets include Amazon Redshift and a lakehouse with Amazon SageMaker.
Recent updates include:
- AWS Glue now supports zero-ETL integration from Amazon DynamoDB and eight SaaS applications to Amazon S3 Tables
- Amazon Aurora MySQL and Amazon RDS for MySQL integration with Amazon SageMaker is now available
Traditional relational databases from various vendors can also link to a lakehouse through zero-ETL integrations. This comprehensive support means that organizations can consolidate data from virtually any source into their AWS analytics environment without building custom integration pipelines. By using zero-ETL to break down data silos—even between multiple vendors’ solutions—and simplifying the data integration process, organizations can focus on deriving insights rather than managing complex data movements.
Additional integrations are in development to support more AWS services and data sources, further expanding the ecosystem. AWS is committed to continually expanding the range of zero-ETL integrations, responding to customer needs and evolving data landscapes.
Advanced features and capabilities of AWS zero-ETL
AWS zero-ETL capabilities include several sophisticated features that set them apart from other clouds. For example, by using the refresh interval control, you can customize how frequently data is synchronized, helping to ensure that analytics are based on data that is as current as necessary for each use case. Meanwhile, History Mode maintains historical versions of data, enabling trend analysis, insightful dashboards, and meeting audit requirements. You can also create type 2 slowly changing dimensions (SCD 2) tables in Amazon Redshift.
You can use the data filtering capabilities to selectively replicate specific objects and data subsets, optimizing storage use and focusing on the most relevant data. Comprehensive logging and monitoring features provide visibility into data movement and system health, so that administrators can quickly identify and address any issues.
You can also combine two primary integration approaches. Zero-ETL provides full data replication (movement) for comprehensive analytics in a central repository, complementing federation allows querying data in place when real-time access to source data is critical. You can use this flexibility to tailor your data integration strategy to your organization’s specific needs and use cases.
Getting started with zero-ETL
To begin using zero-ETL integrations, you should first identify your source database and target analytics service. This involves assessing your current data architecture and determining which data flows would benefit most from a zero-ETL approach.
Next, you need to configure the necessary permissions and networking requirements. This typically involves setting up either an AWS Identity and Access Management (IAM) identity or single sign-on using AWS IAM Identity Center and making sure that the source and target services can communicate securely.
As shown in the following image, after the prerequisites are in place, creating the integration is a click-through experience within the AWS Management Console. The intuitive interface guides you through the process, prompting you to specify source and target details, select tables for replication, and configure any additional options.
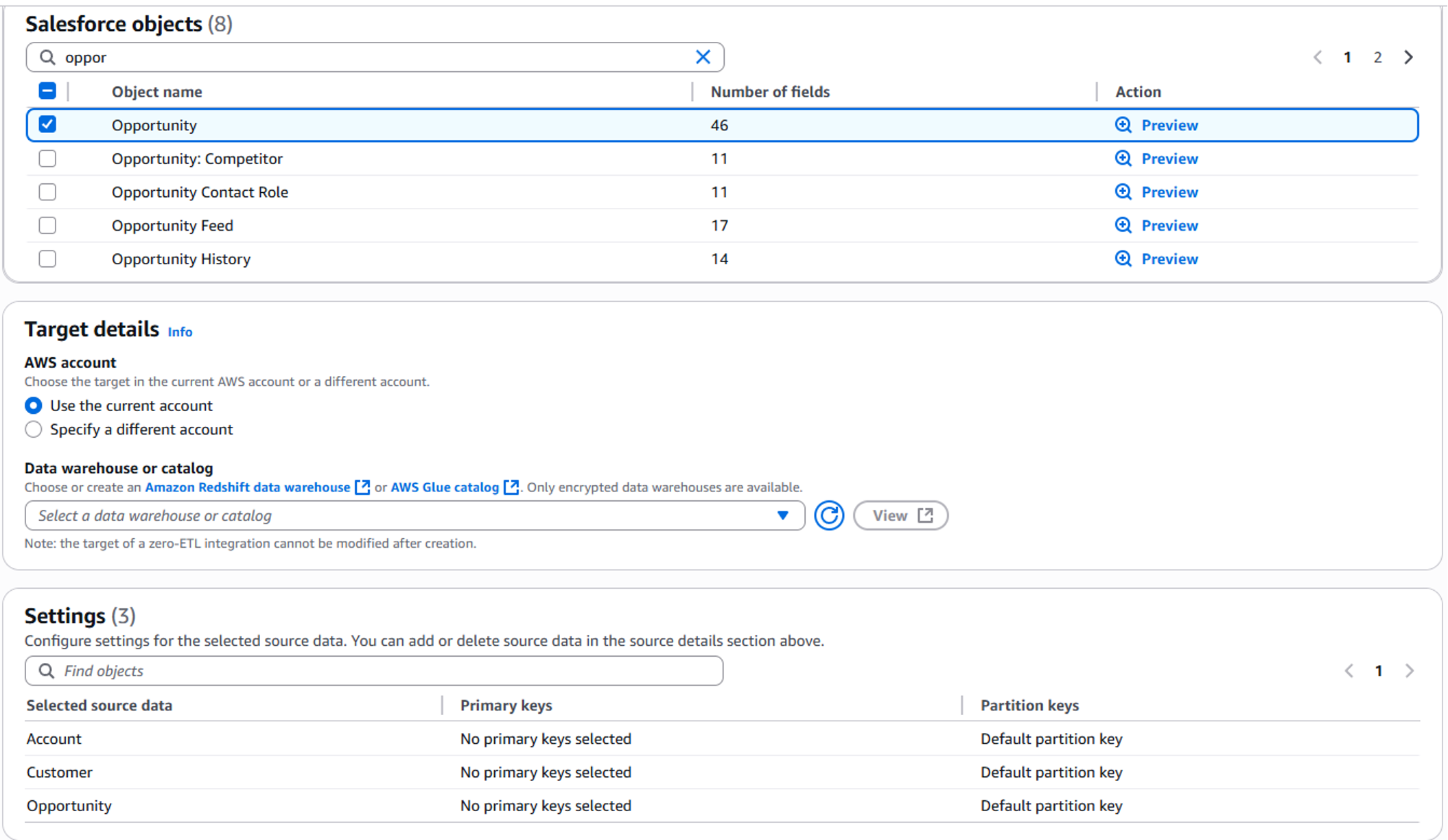
After setup, you can monitor replication status and performance to help ensure optimal operation. AWS provides detailed metrics and logs to help you track the health and performance of your zero-ETL integrations.
For detailed setup instructions, visit the AWS documentation for zero-ETL integrations, which provides step-by-step guides for each supported integration.
What’s ahead for zero-ETL
AWS has an active roadmap for support of additional AWS services and data sources, expanding the reach of zero-ETL integrations so that more customers can benefit from simplified data integration across a broader range of use cases.
Zero-ETL integrations represent a fundamental shift in how organizations approach data integration. Without the complexity of ETL pipelines, customers can focus on deriving value from their data rather than managing infrastructure. This approach aligns with the AWS commitment to simplifying cloud operations and empowering customers to innovate faster.
To learn more about zero-ETL integrations and how they can benefit your organization, see the following topics:
- For Aurora zero-ETL integrations, see Benefits, Key concepts, Limitations, Quotas, and Supported Regions of zero-ETL integrations
- For Amazon RDS zero-ETL integrations, see Benefits, Key concepts, Limitations, Quotas, and Supported Regions of zero-ETL
- For DynamoDB zero-ETL integrations, see DynamoDB zero-ETL integration with Amazon Redshift
- For zero-ETL integrations with applications, see Zero-ETL integrations
Get started today and discover how you can streamline your data operations and unlock the full potential of your data with AWS zero-ETL integrations.
 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.