Post Syndicated from Sneha Rao original https://aws.amazon.com/blogs/big-data/cross-account-lakehouse-governance-with-amazon-s3-tables-and-sagemaker-catalog/
Organizations increasingly face challenges when analyzing data stored across multiple AWS accounts and storage formats. Data teams often need to query both traditional Amazon Simple Storage Service (Amazon S3) objects and Apache Iceberg tables, leading to costly data duplication, potential inconsistencies, and complex permission management across accounts.
To address these challenges, you can combine Amazon S3 Tables, which provides native Apache Iceberg support within S3, with Amazon SageMaker Catalog for unified data governance. This solution supports secure cross-account data access without duplicating datasets or compromising security controls.
In this post, we walk you through a practical solution for secure, efficient cross-account data sharing and analysis. You’ll learn how to set up cross-account access to S3 Tables using federated catalogs in Amazon SageMaker, perform unified queries across accounts with Amazon Athena in Amazon SageMaker Unified Studio, and implement fine-grained access controls at the column level using AWS Lake Formation.
This post helps you establish proper governance and security controls for S3 Tables in a multi-account environment, enabling secure and efficient cross-account data access.
Solution overview
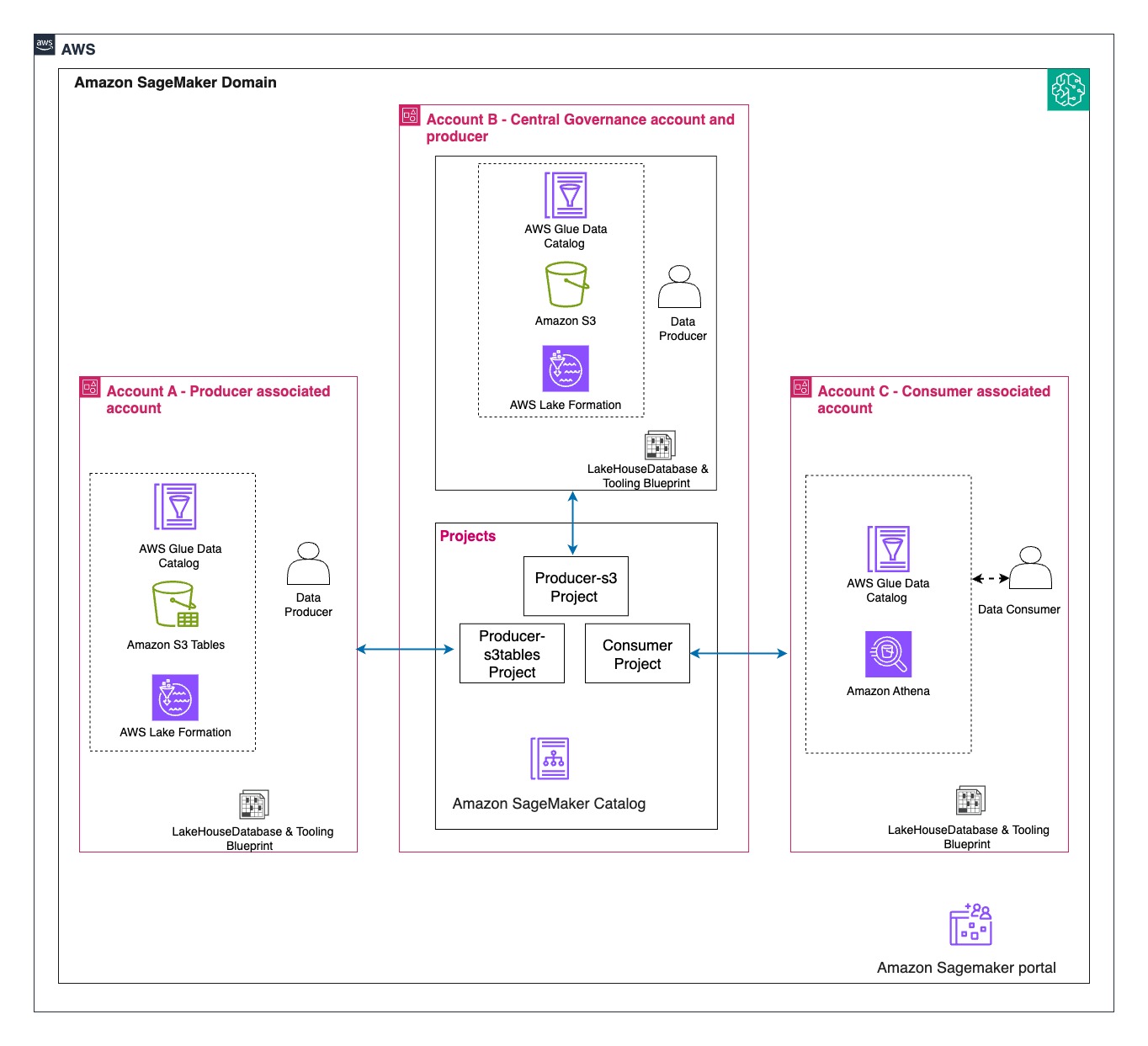
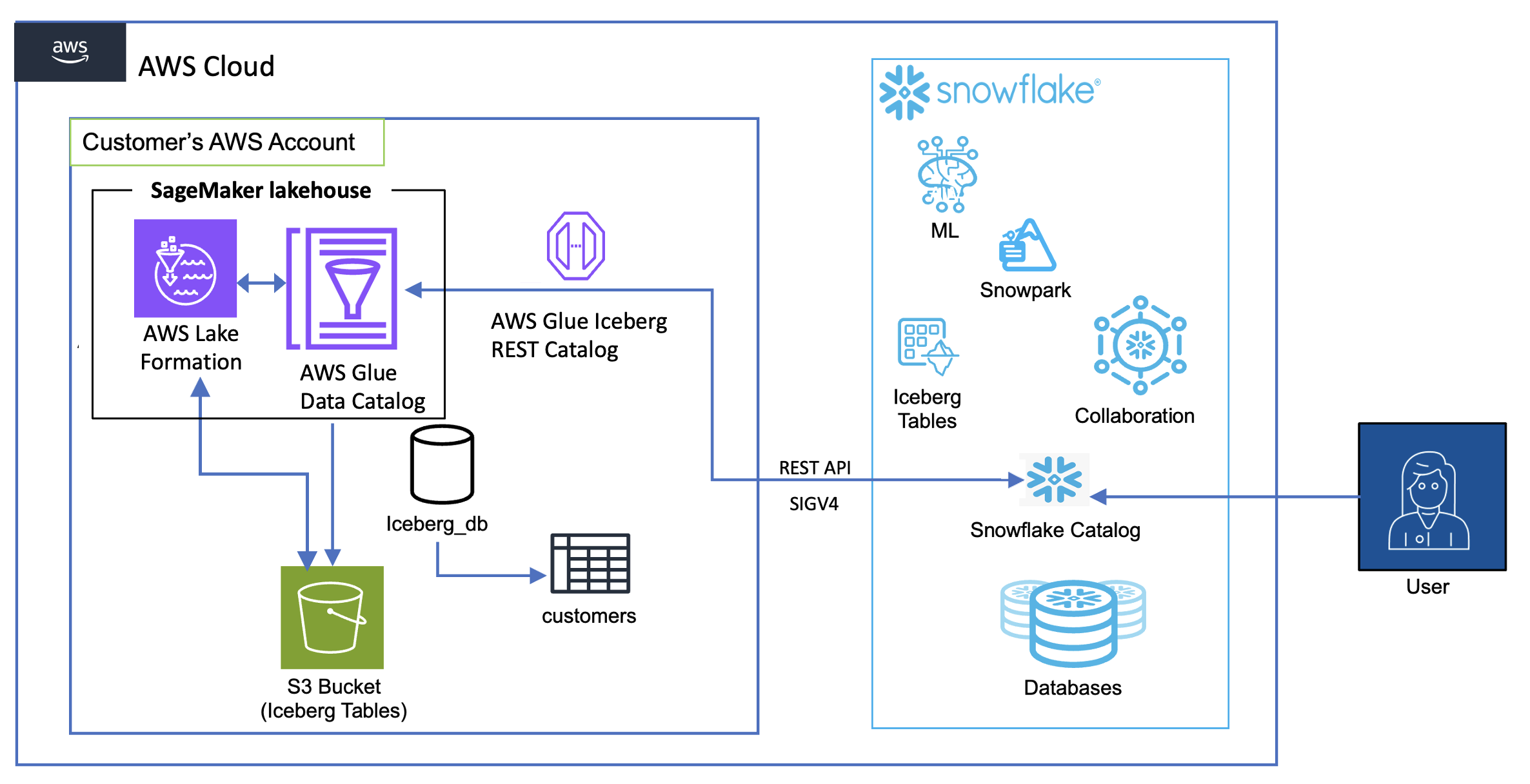
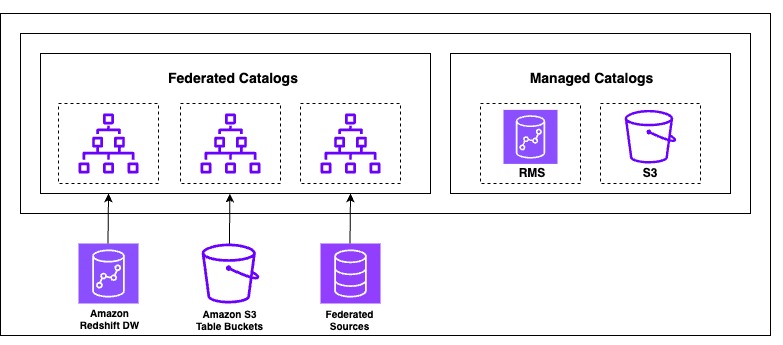
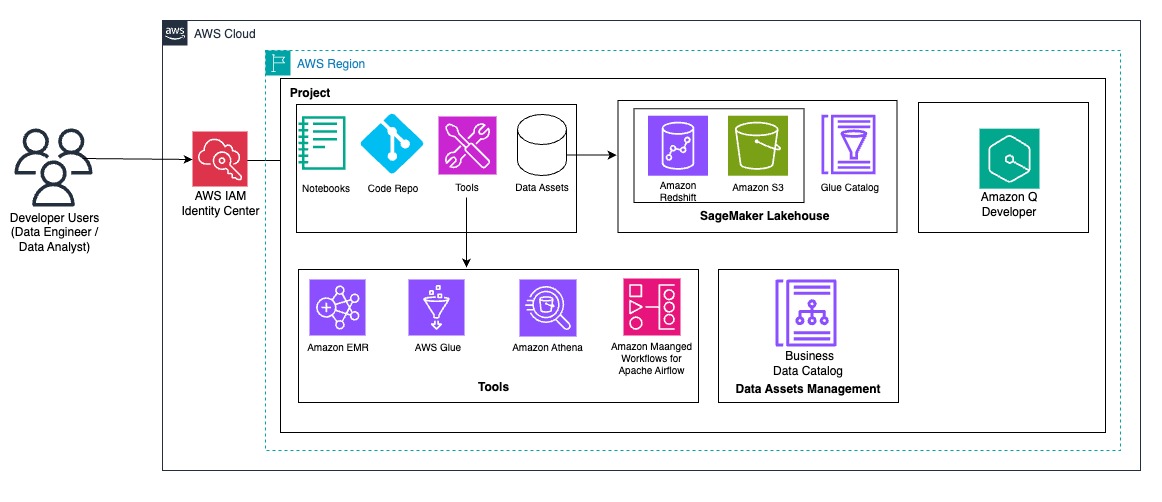
We walk you through implementing a three-account lakehouse governance architecture where you can securely share data. As shown in the following diagram, Account A serves as your data producer with S3 Tables, Account B acts as your central governance hub with SageMaker Catalog, and Account C represents your data consumers. We’ll demonstrate step-by-step how to configure cross-account access and implement governance controls so consumers can discover and query data from both S3 tables and traditional S3 buckets.
Prerequisite and Set up
In this post, we focus on how to do the cross account set up and how to onboard S3 Tables. All three accounts are in the same AWS Region. To implement this solution, you will need three individual accounts (A, B, C). The setup in the accounts should look like the following:
- Account A (Producer): Create an Amazon S3 Table on the account.
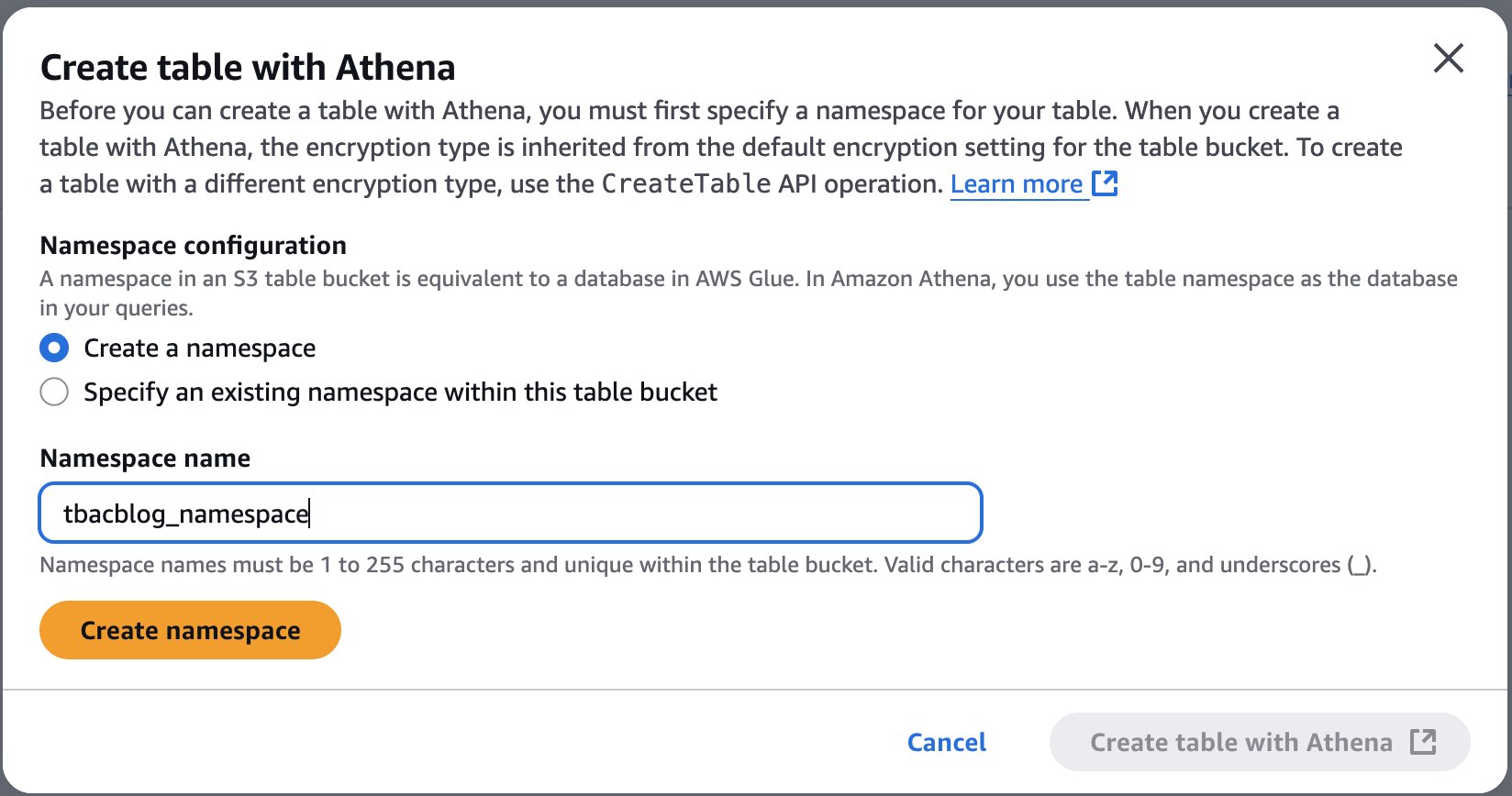
- Account B (Central governance and producer): This is another account where you have data in Amazon S3 buckets catalog via Glue Catalog. You would onboard these into domain portal.
- S3 cataloged in Glue Data Catalog.
- Create a SageMaker Domain in Account B.
- Account C (Consumer account): Identify an account where you have consumers query data using Athena to follow along.
The following are the high-level implementation steps for this solution:
Step 1: Configure cross-account association for governance.
Step 2: Create three Project Profiles in Account B pointing to tables in Account A, B, and C.
Step 3: Create three Projects.
Step 4: Set up permissions for Projects in AWS Lake Formation.
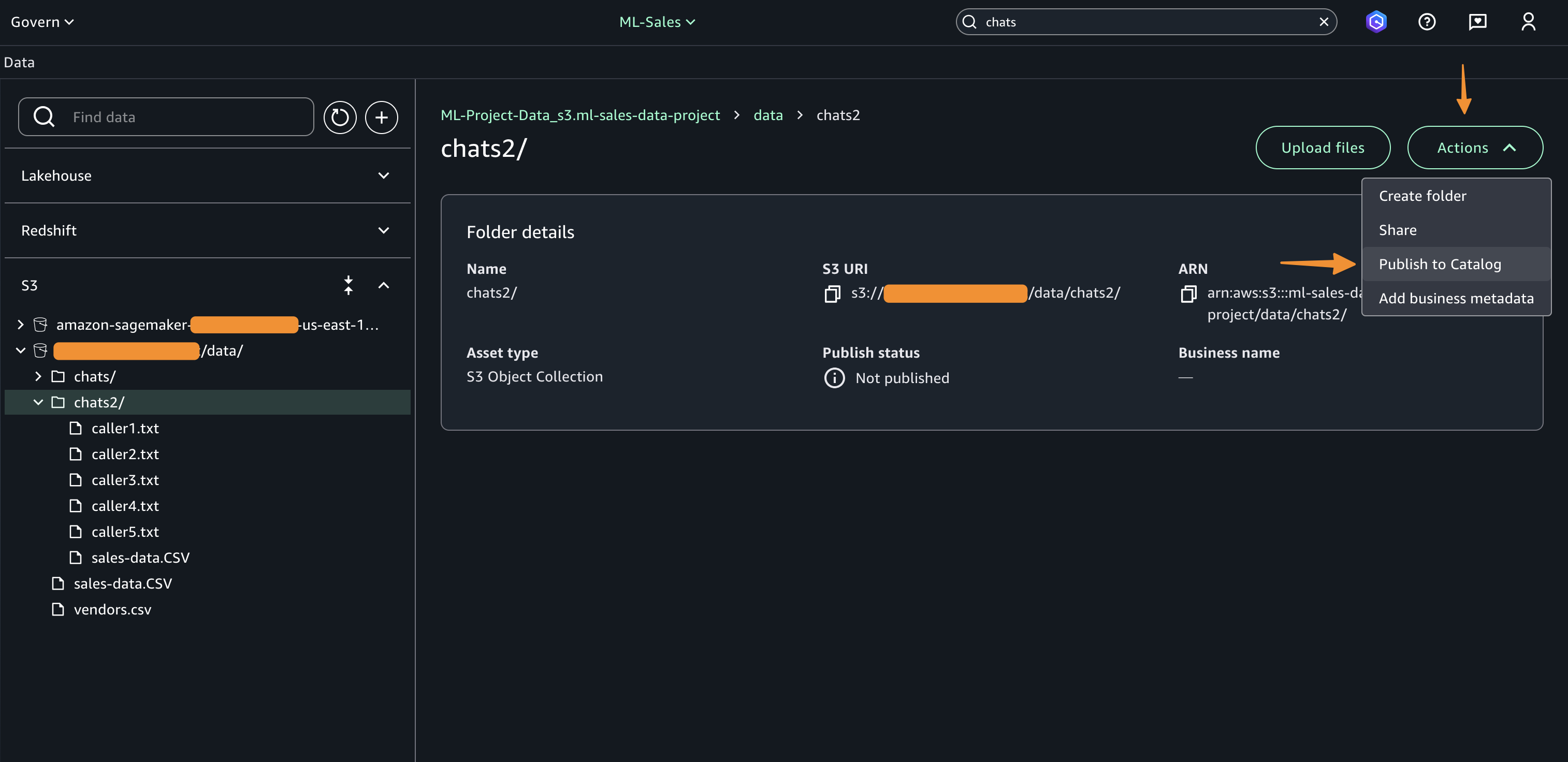
Step 5: In Account B, create Datasource to connect S3 Table from Account A and Glue Catalog Tables from Account B.
Step 6: Publish and Subscribe to asset.
Step 7: Query S3 table (Account A) and S3 (Account B) data together in SQL editor (Account C).
Step 1
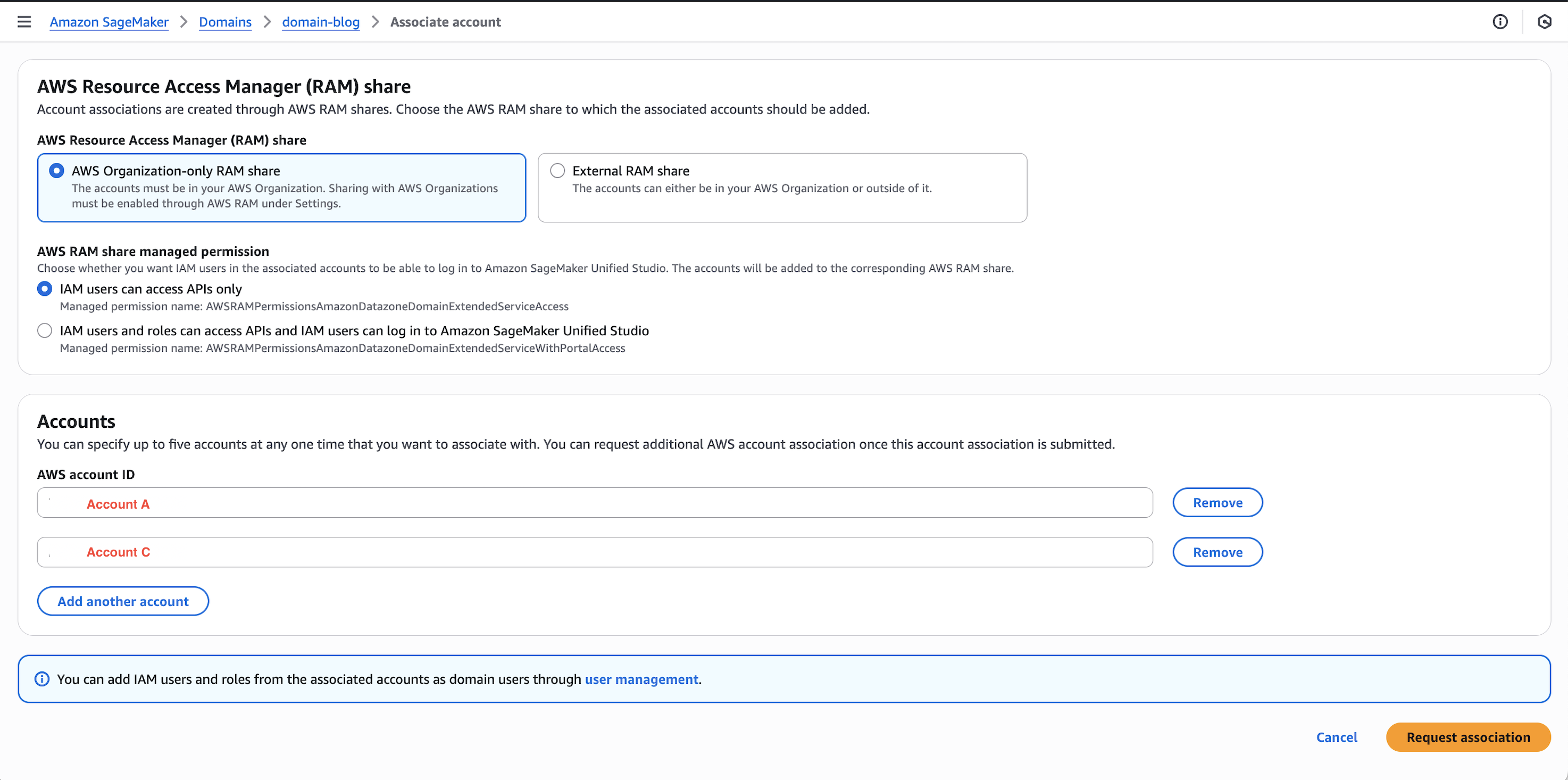
A. Configure cross-account association for governance
In this section, we associate Account A and C in the Governance account B.
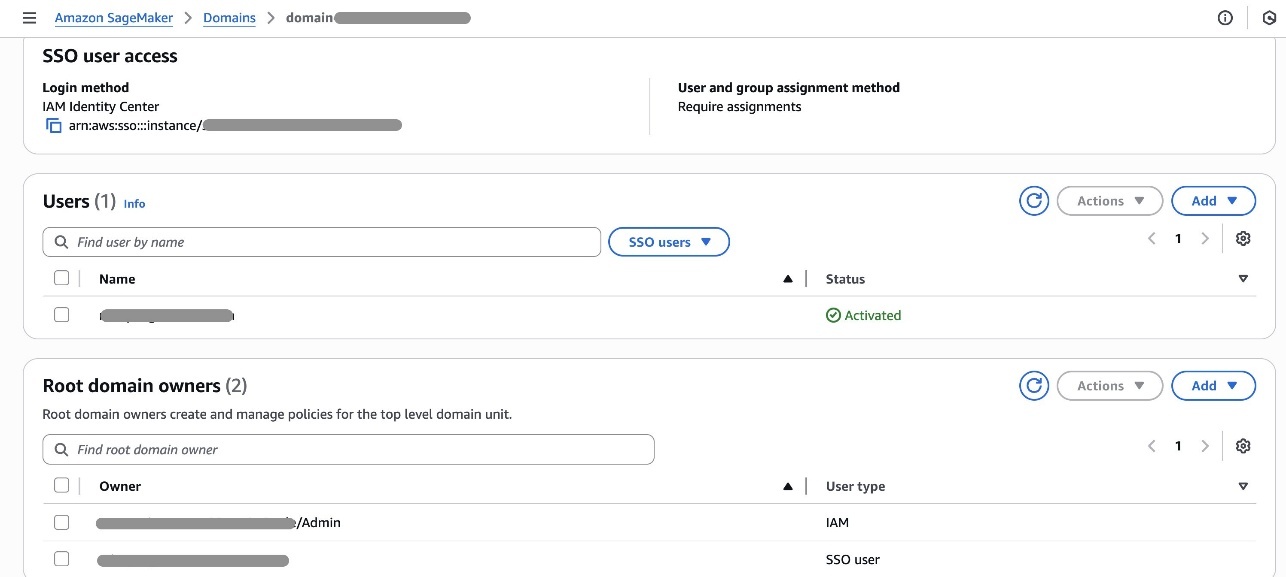
- Open the SageMaker Unified Studio console in Account B.
- Navigate to Domains, select your domain, then choose the Account associations tab.
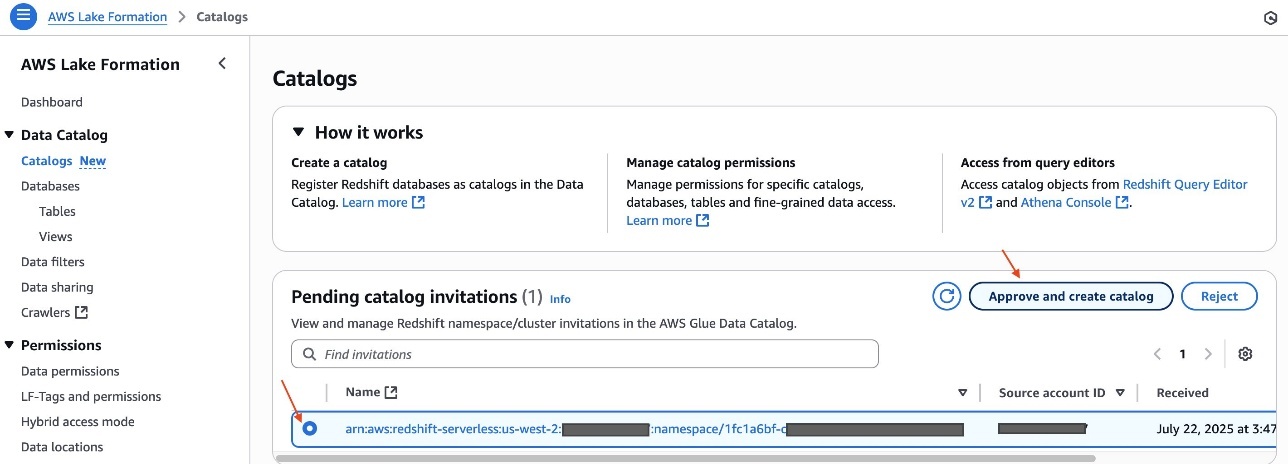
- Choose Request association and enter the Account IDs for Account A and Account C.
- Submit the association request and verify the accounts appear with “Requested” status.

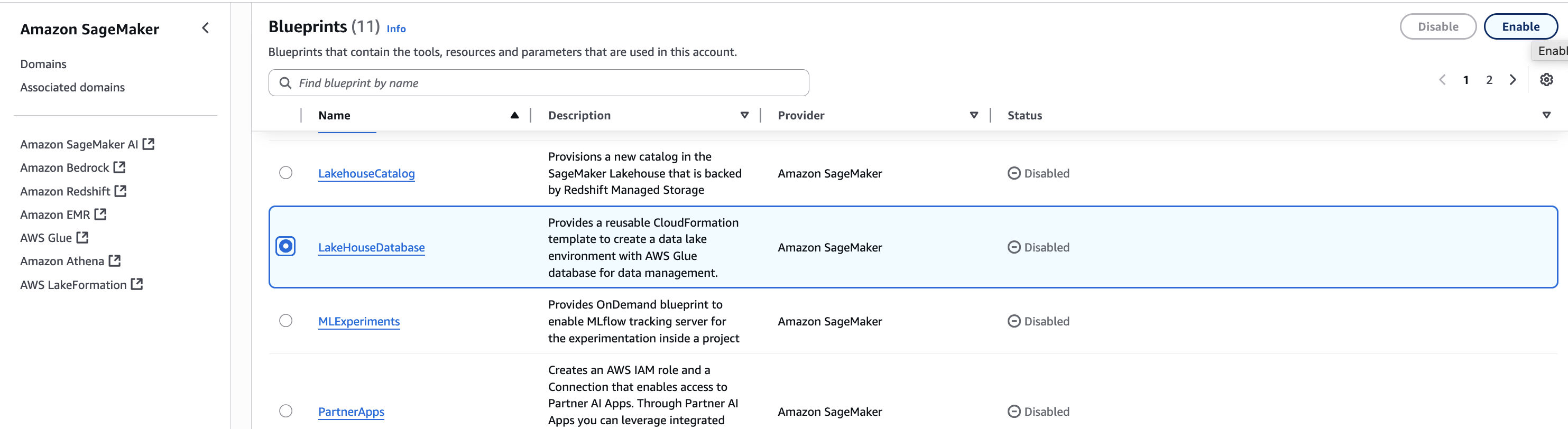
B. Enable Blueprints for your domain in Accounts A, B, and C
The LakeHouseDatabase blueprint enables SageMaker Unified Studio to securely manage, query, and share data from S3, Redshift, and other sources using open standards—so in this step, you enable it in Accounts A, B, and C to support unified data access and collaboration.
- In Account A, in the SageMaker console, navigate to your domain and select the Blueprints tab.
- Select the LakeHouseDatabase blueprint and choose Enable.

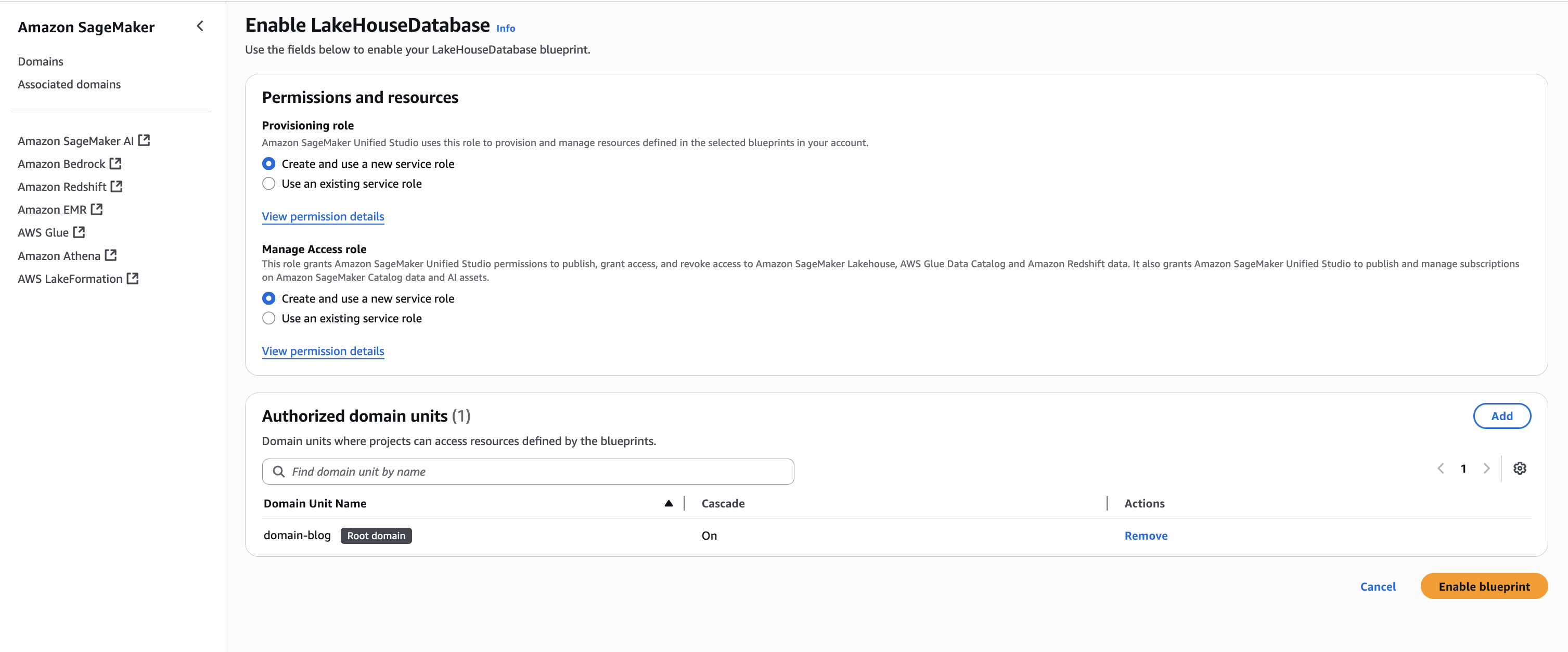
- Keeping the Permissions and resources section at the default settings, choose Enable Blueprint.

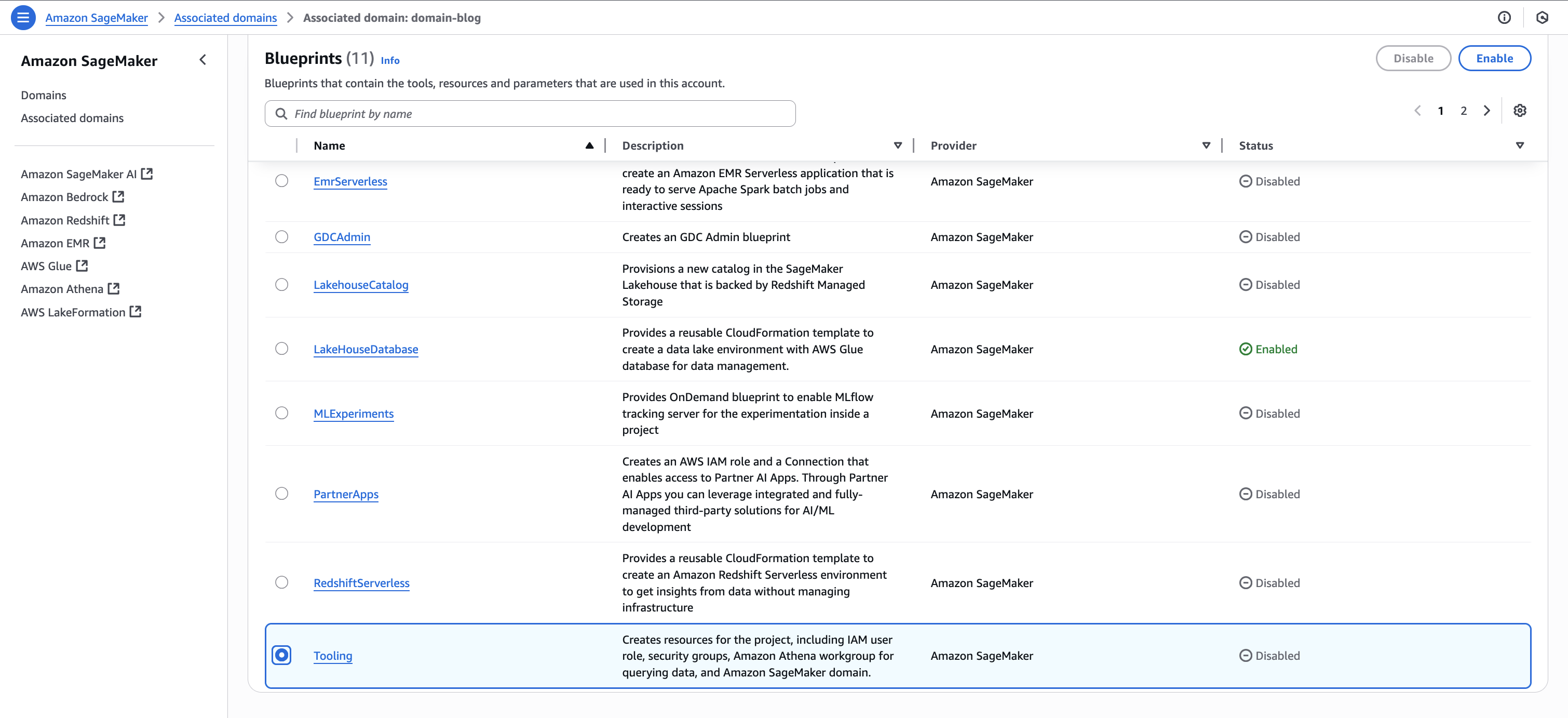
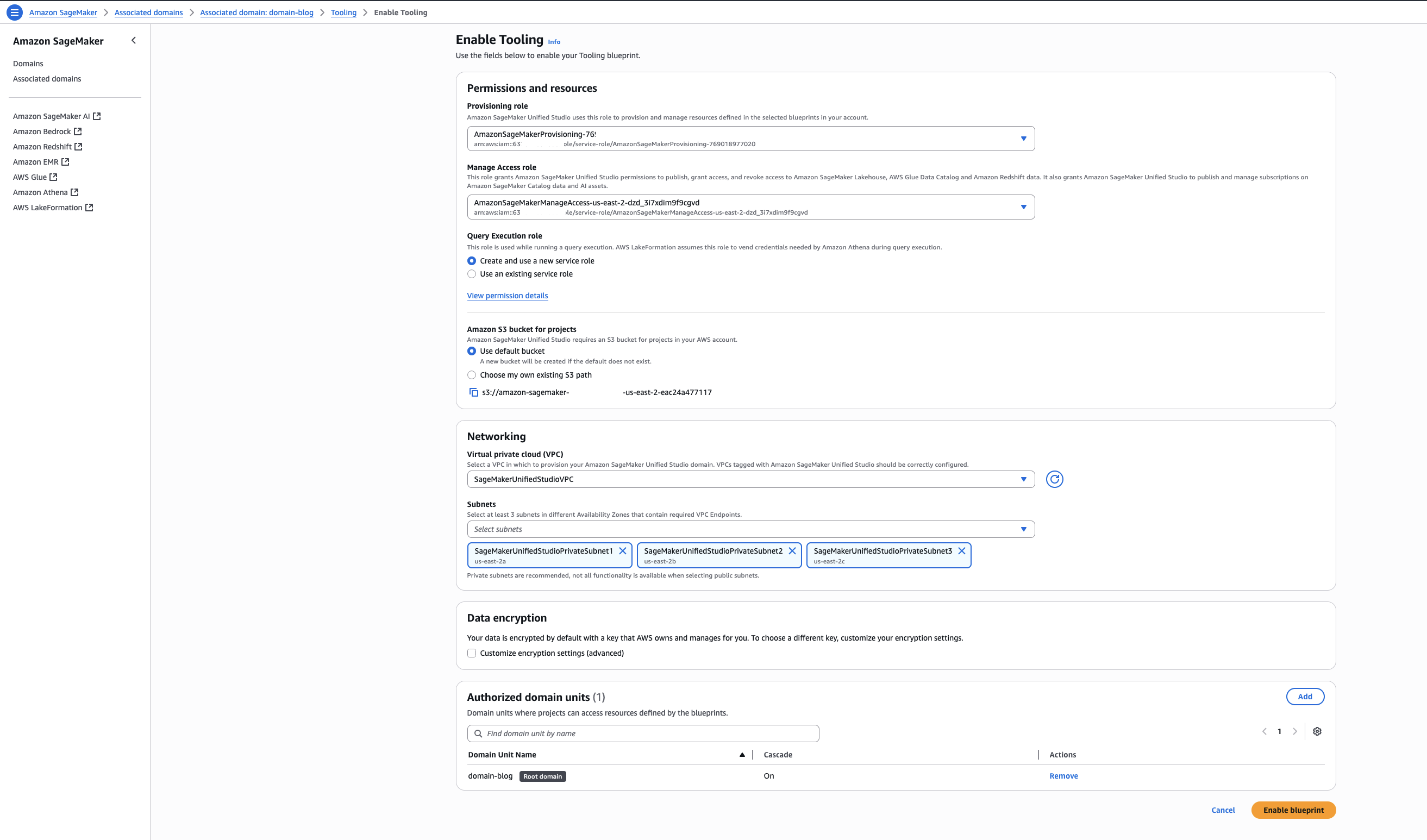
- Back on the blueprints screen, select the Tooling blueprint and choose Enable.

- Keeping the Permissions and resources section at the default settings, configure the Networking section with the desired VPC and subnet configurations.
- Choose Enable Blueprint.

- Repeat Step1.B and enable the same blueprints in Account B to make S3 data publishable and Account C so consumers can query the data using Athena.
Step 2: Create Project Profiles in Account B
Use the documentation to create three project profiles in Account B using the ‘LakeHouseDatabase’ Blueprint, with each profile configured for Accounts A, B, and C respectively. For this post, we use the following naming convention:
- datalake-project-profile-s3tables (for Account A)
- datalake-project-profile (for Account B)
- datalake-project-profile-consumer (for Account C)
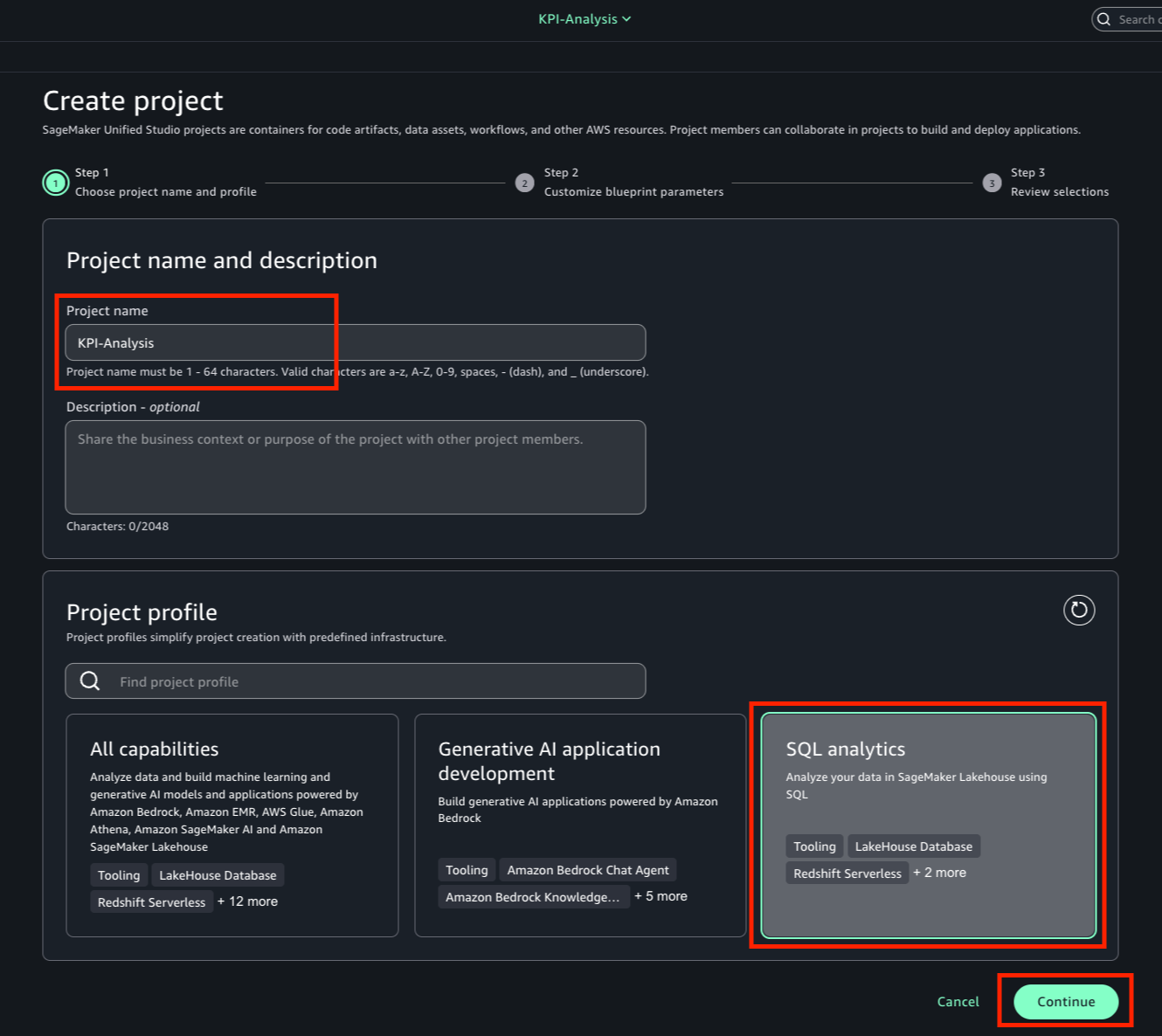
Step 3: Create three Projects for accounts A, B, and C
- Using the documentation, create one Project in each account. For this post, we use the following naming convention:
- ‘producer-s3tables’ – This is configured for Account A
- ‘producer-s3’ – This is configured for Account B
- ‘consumer’ – This is configured for Account C
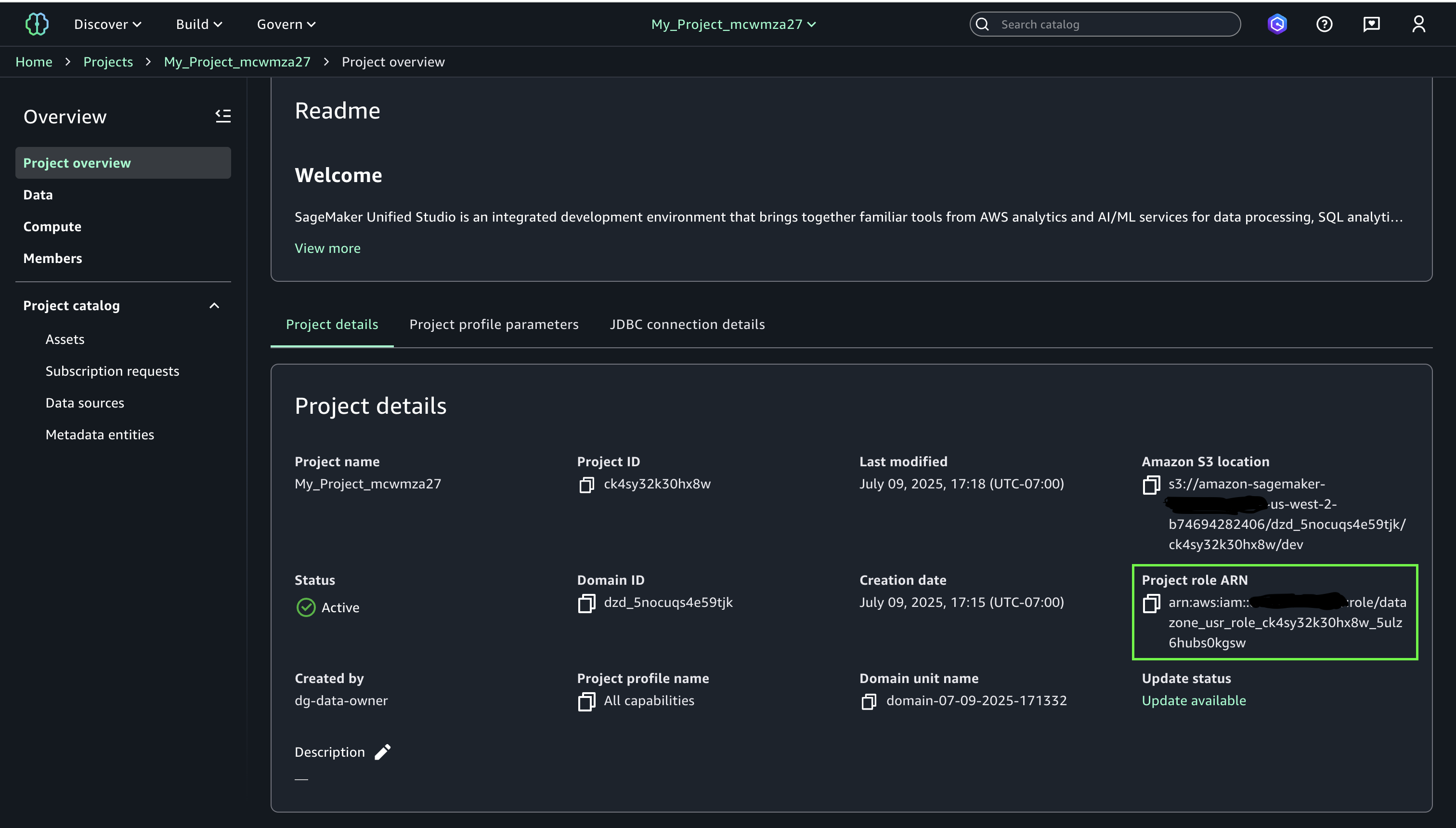
- After creating the Project, locate and make note of the Project role ARN listed under Project details on the project overview page.


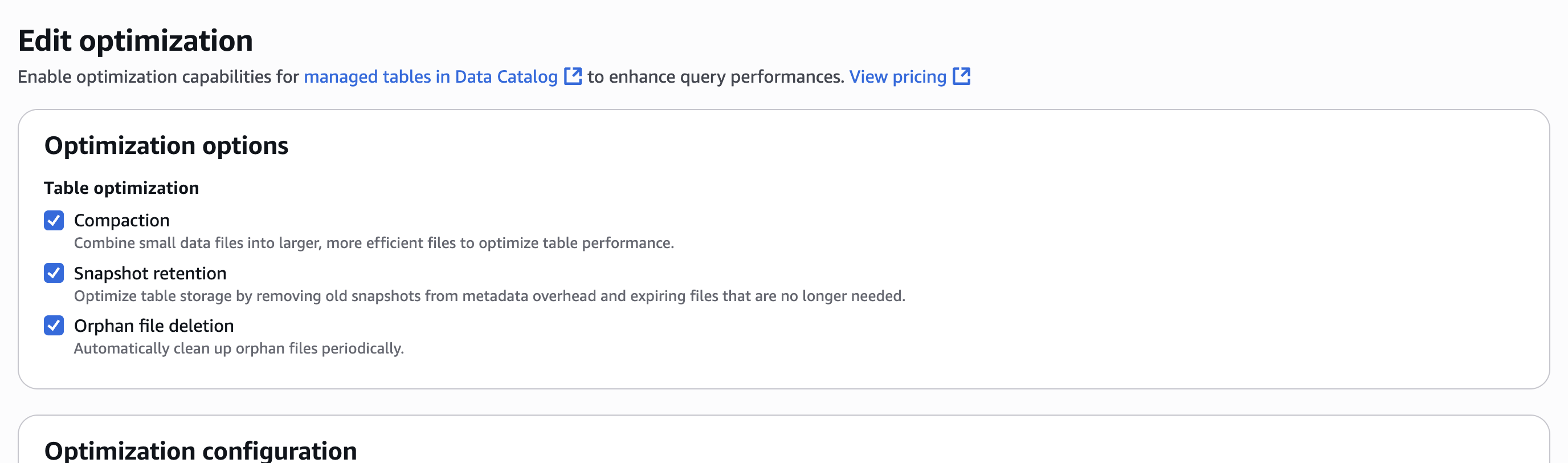
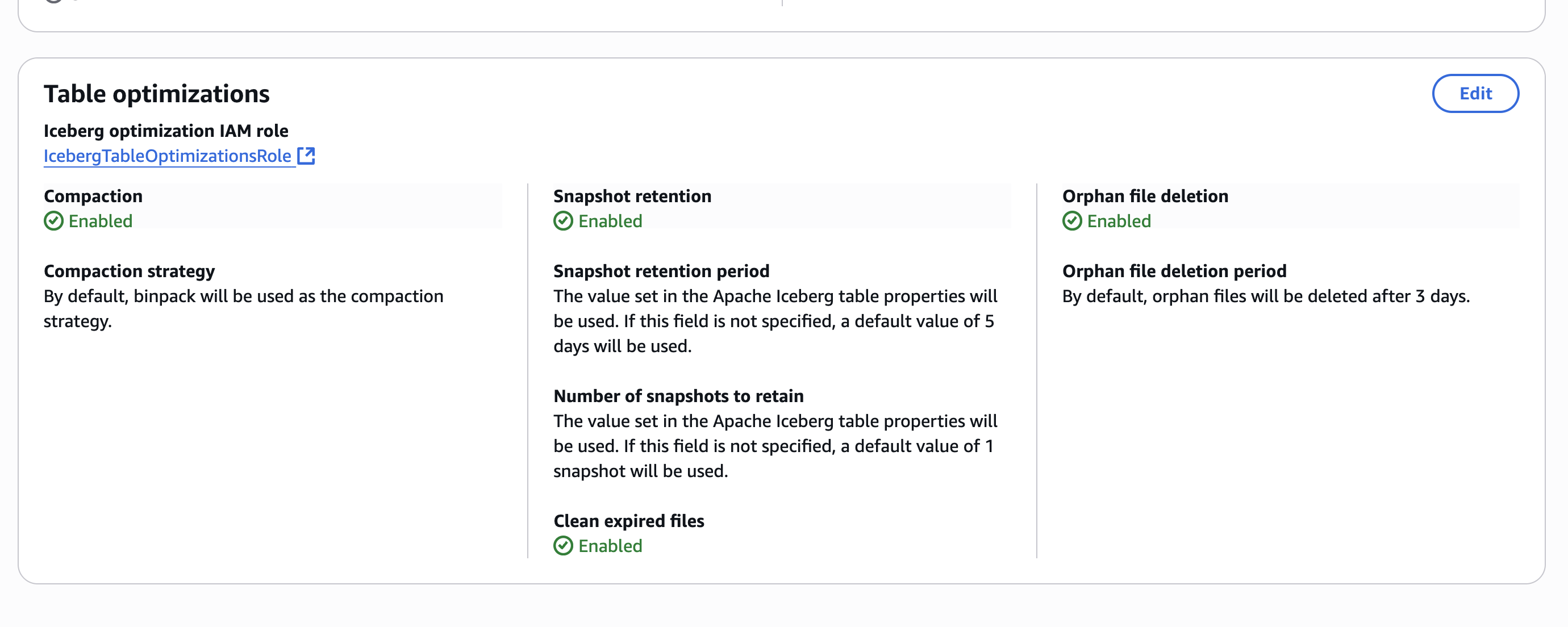
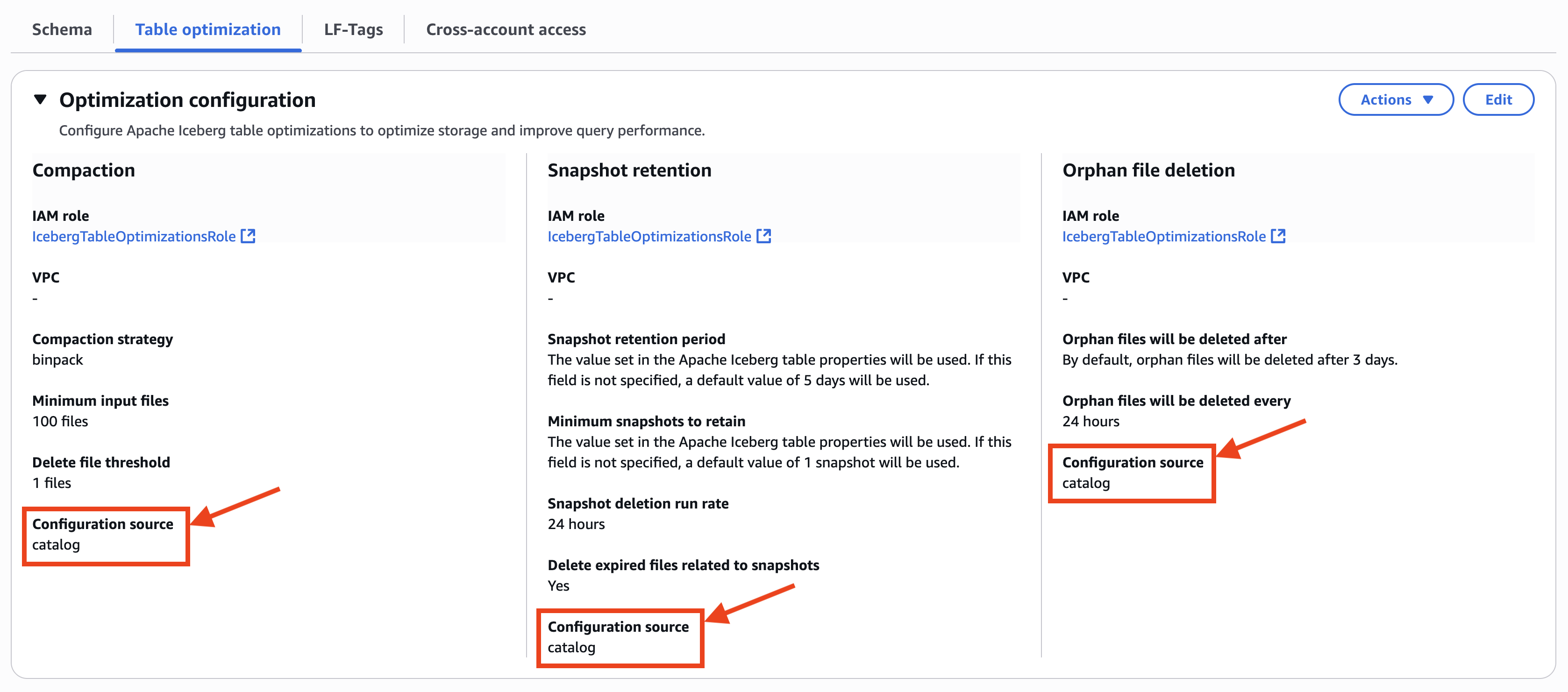
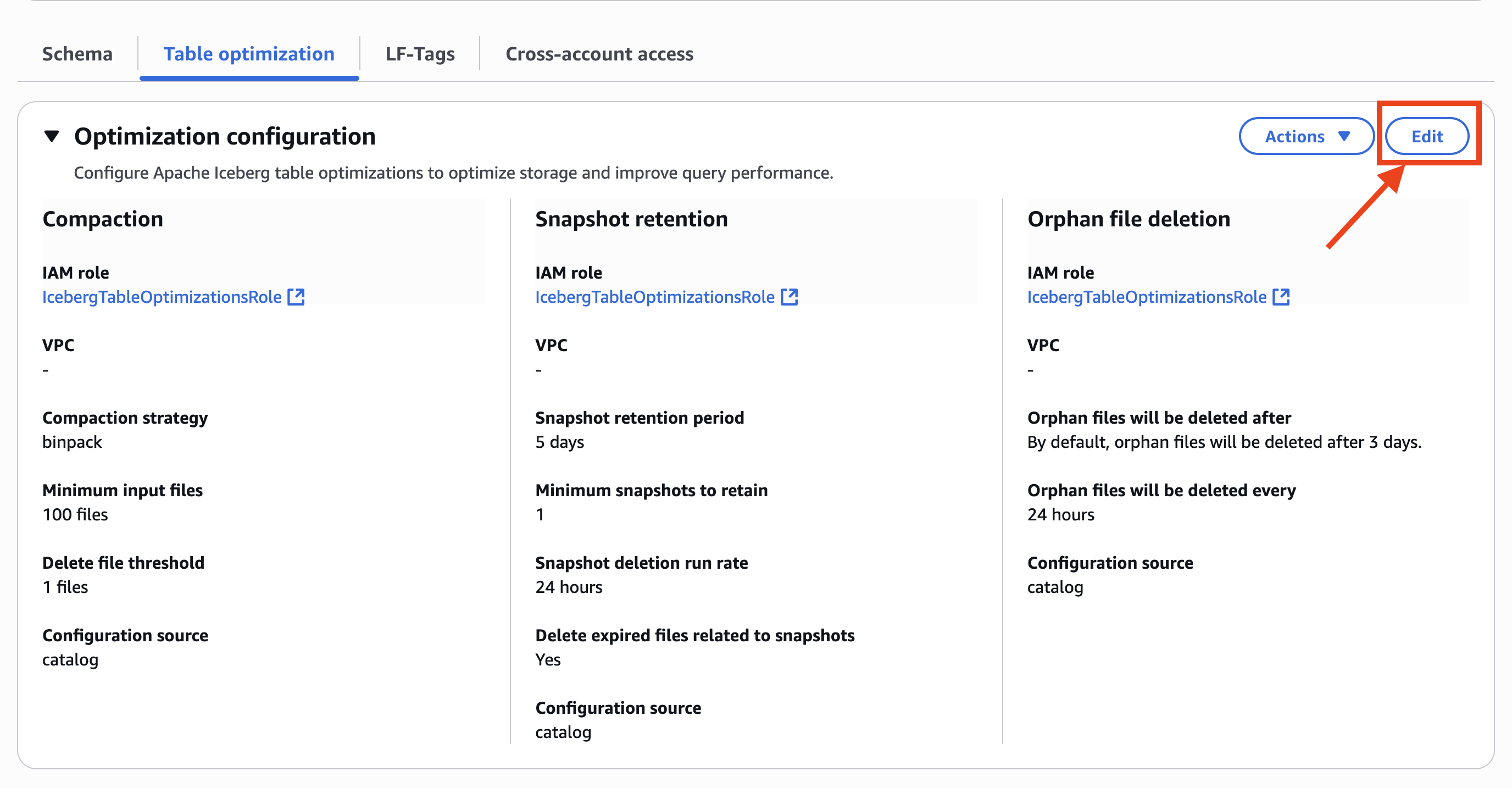
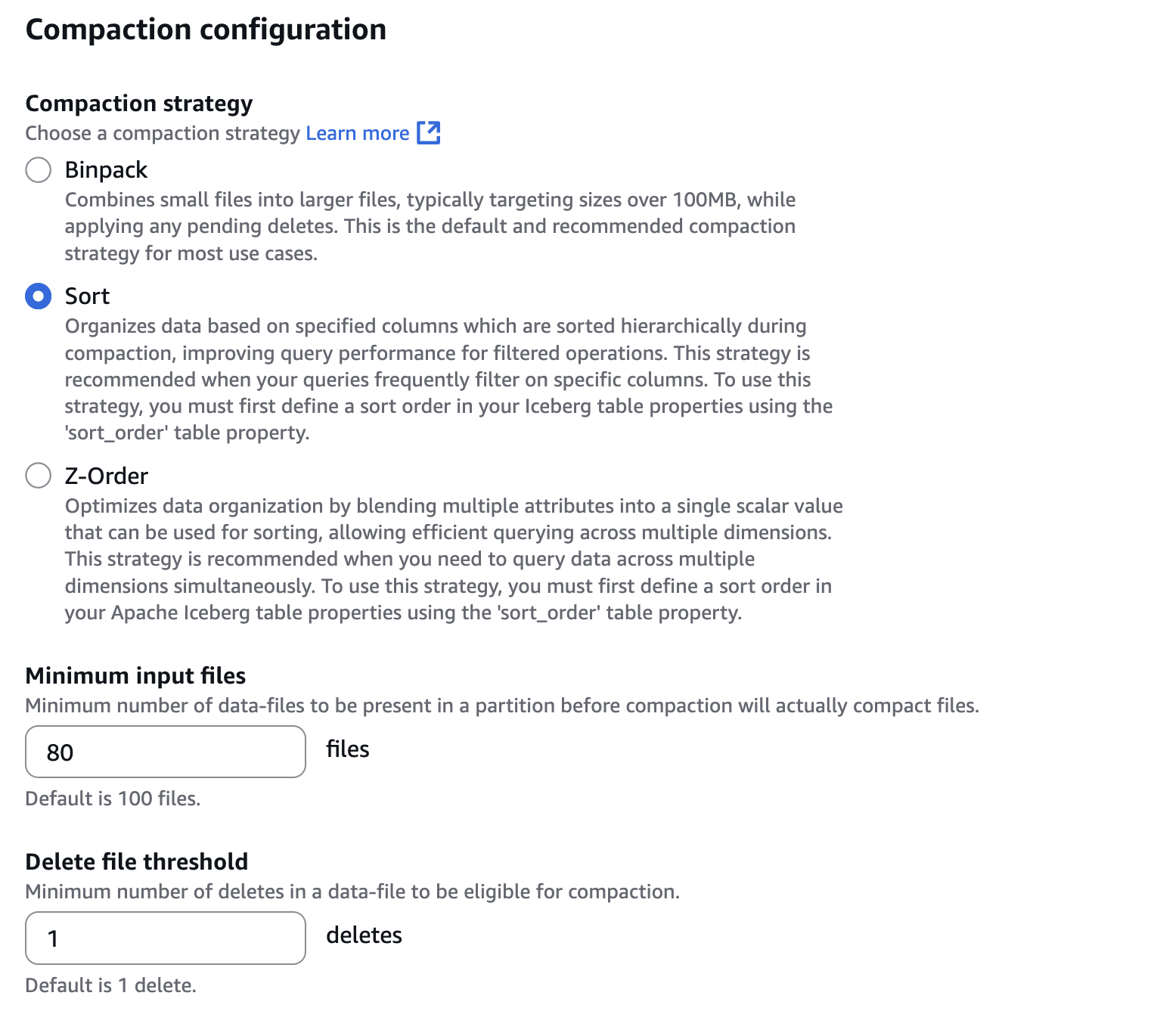
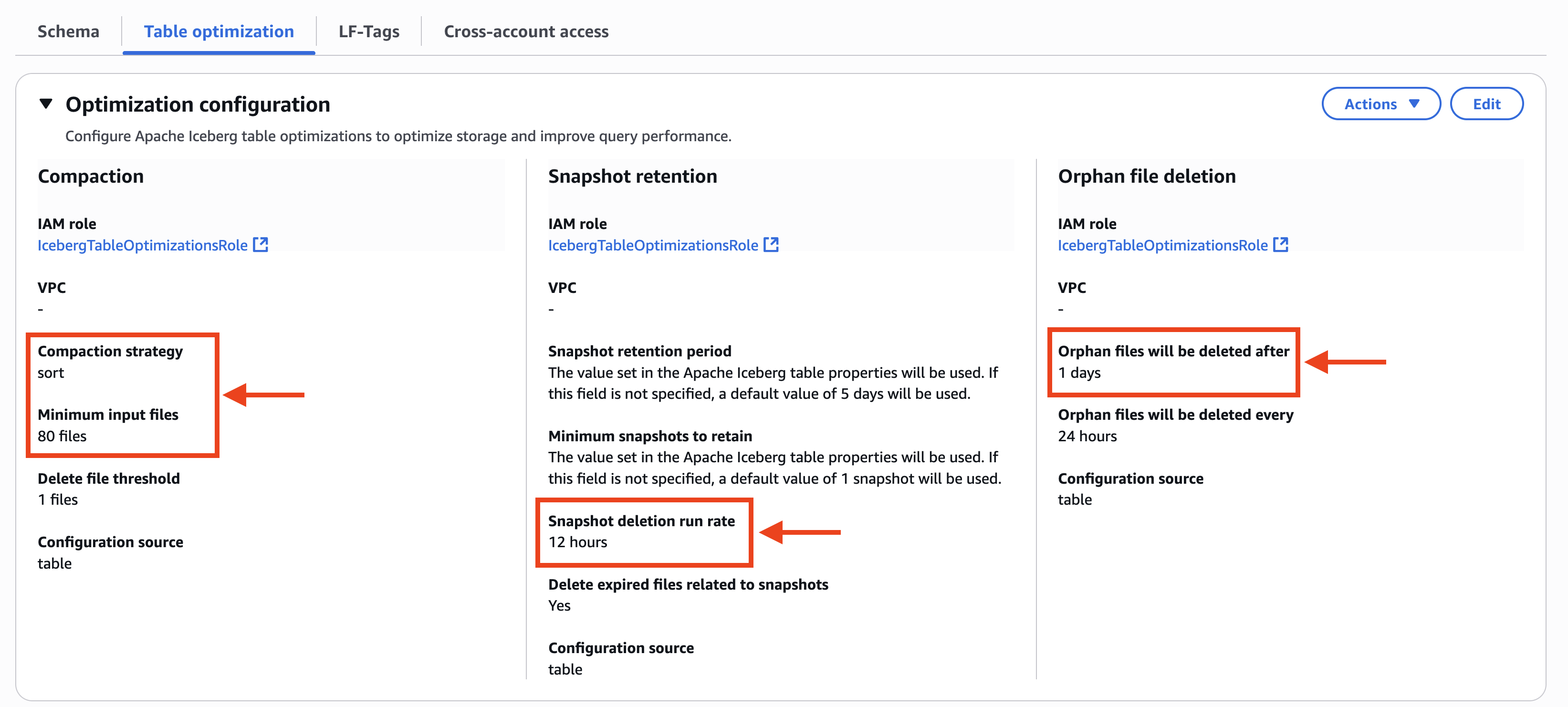
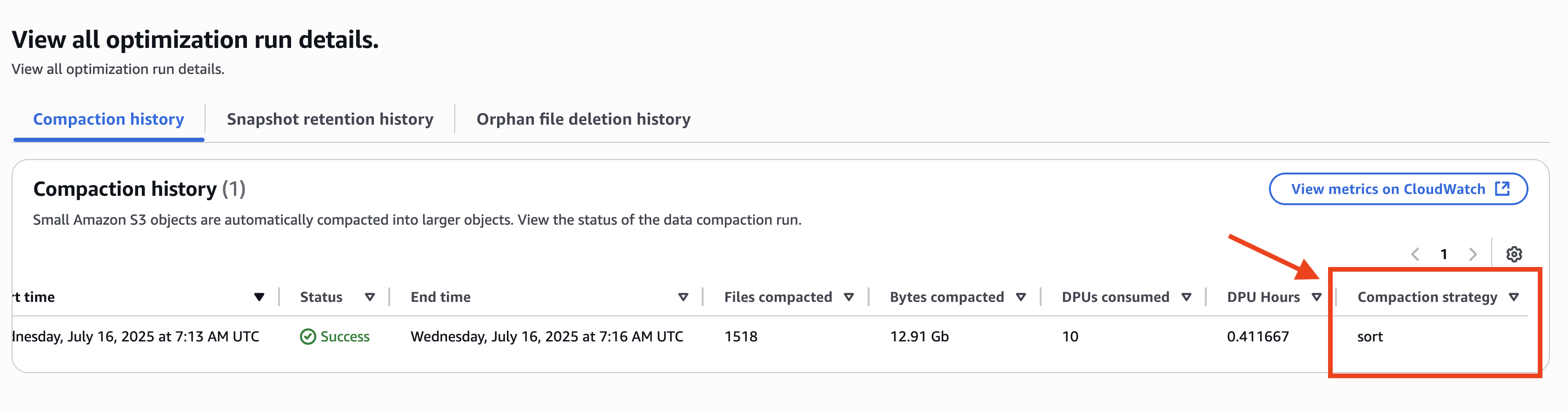
Step 4: Set up permissions for Projects in AWS Lake Formation
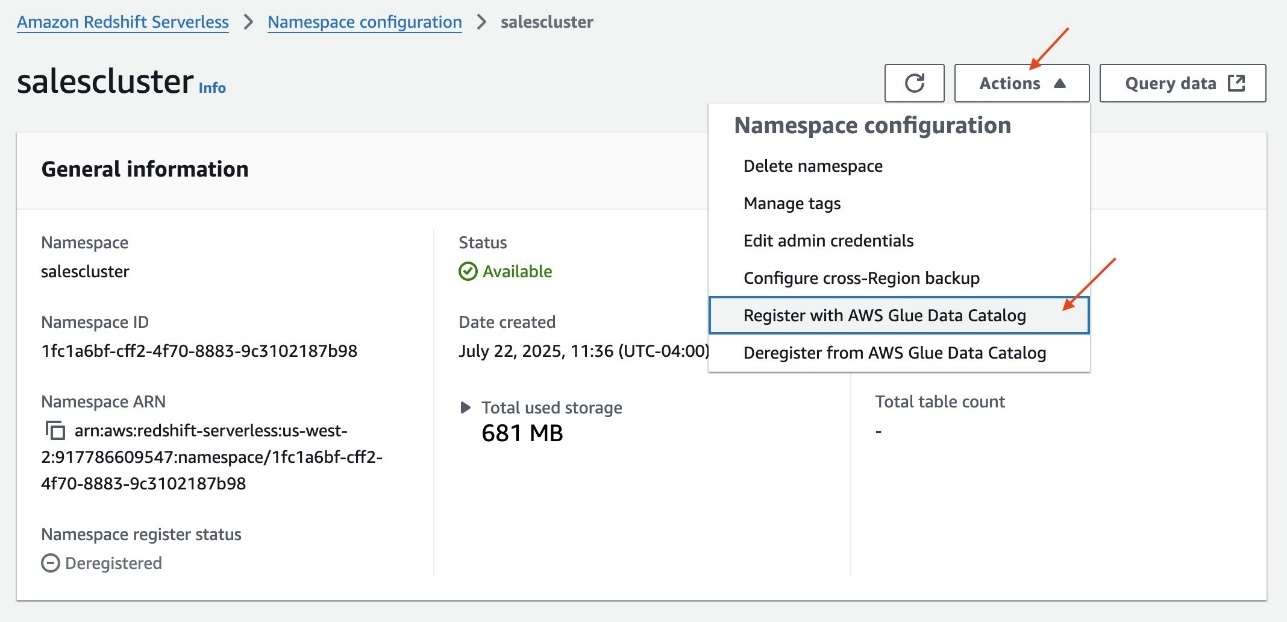
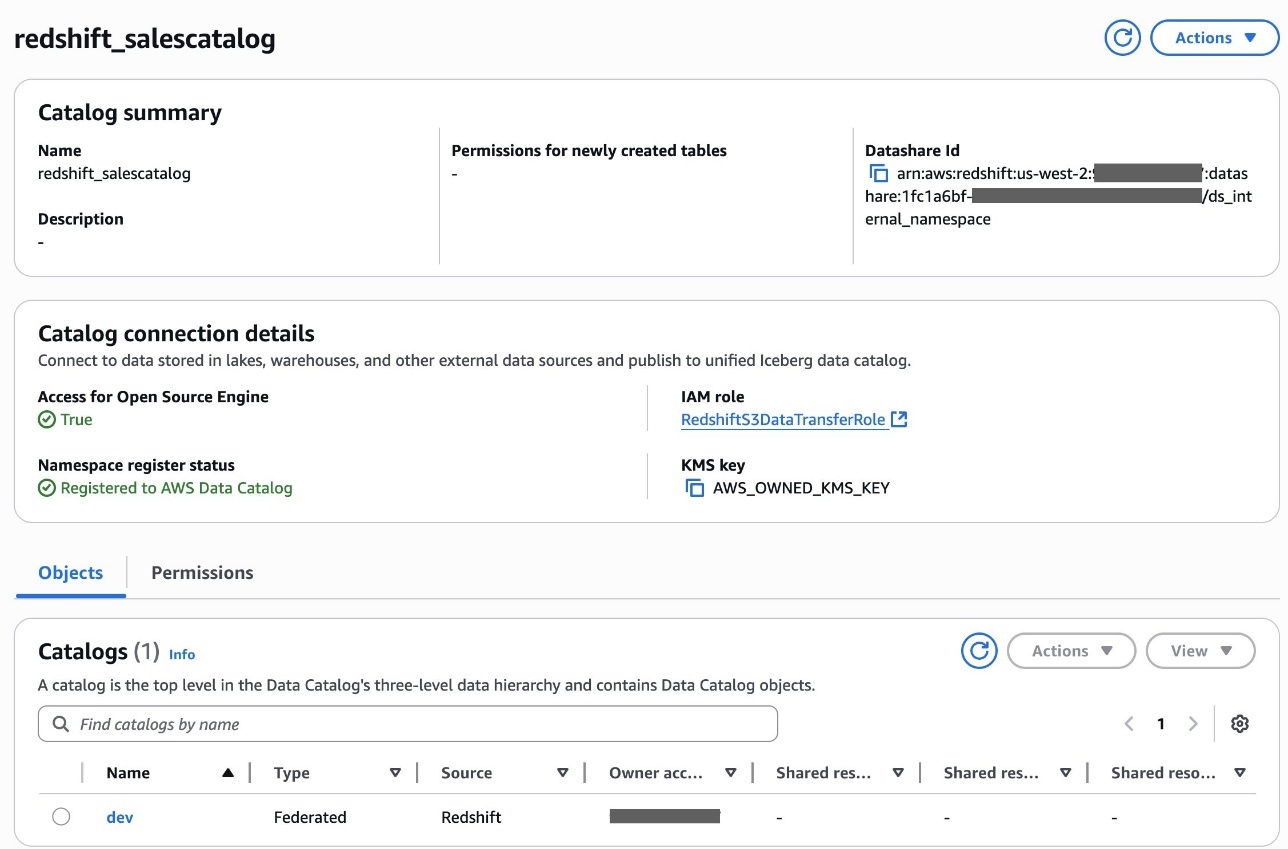
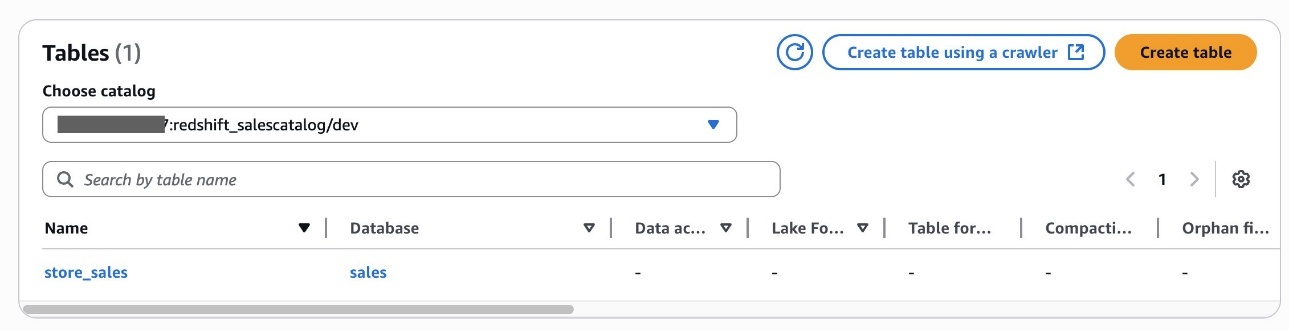
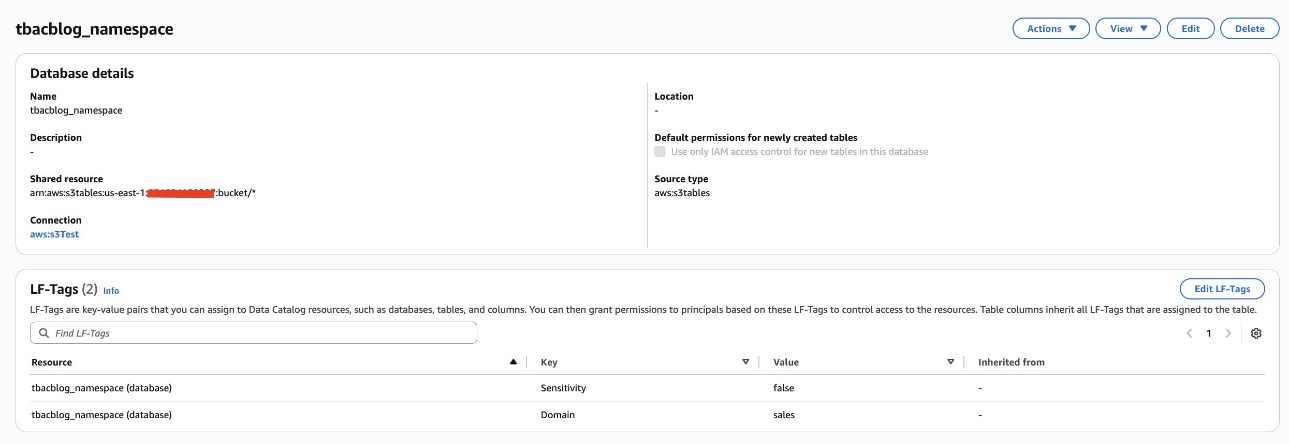
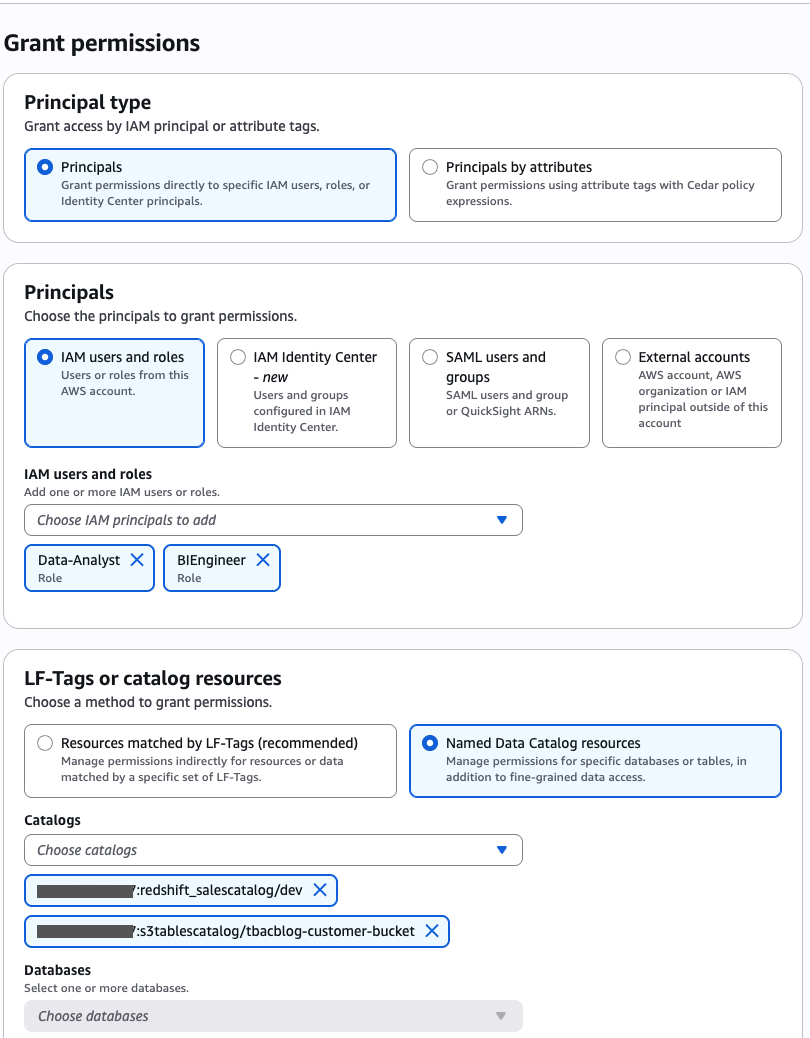
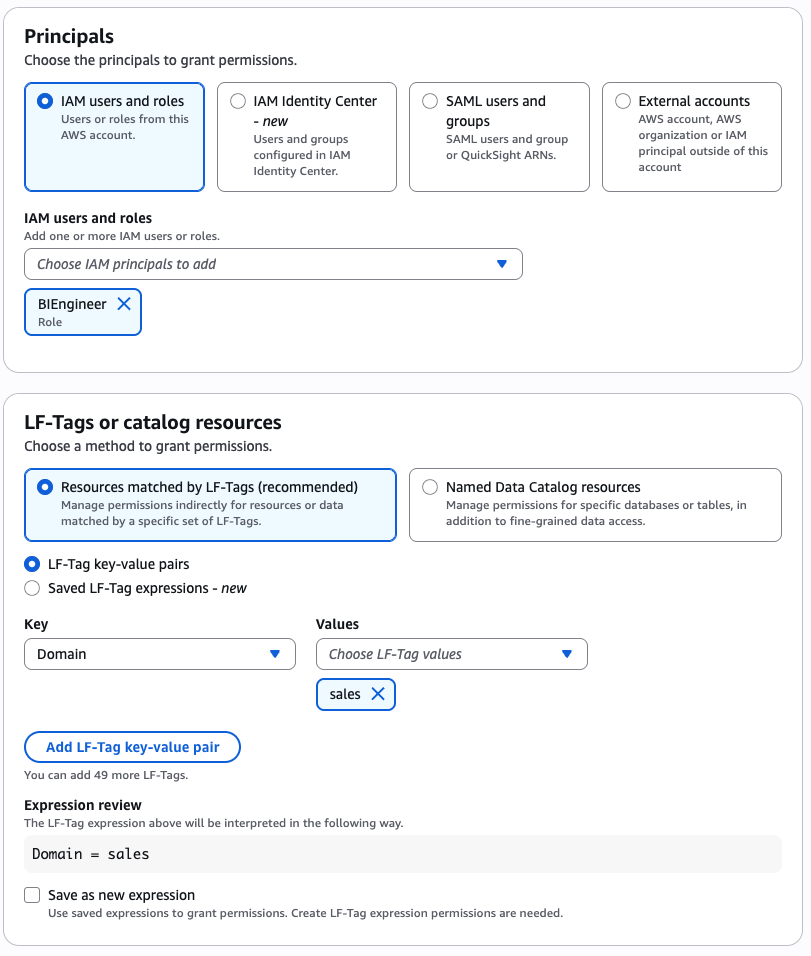
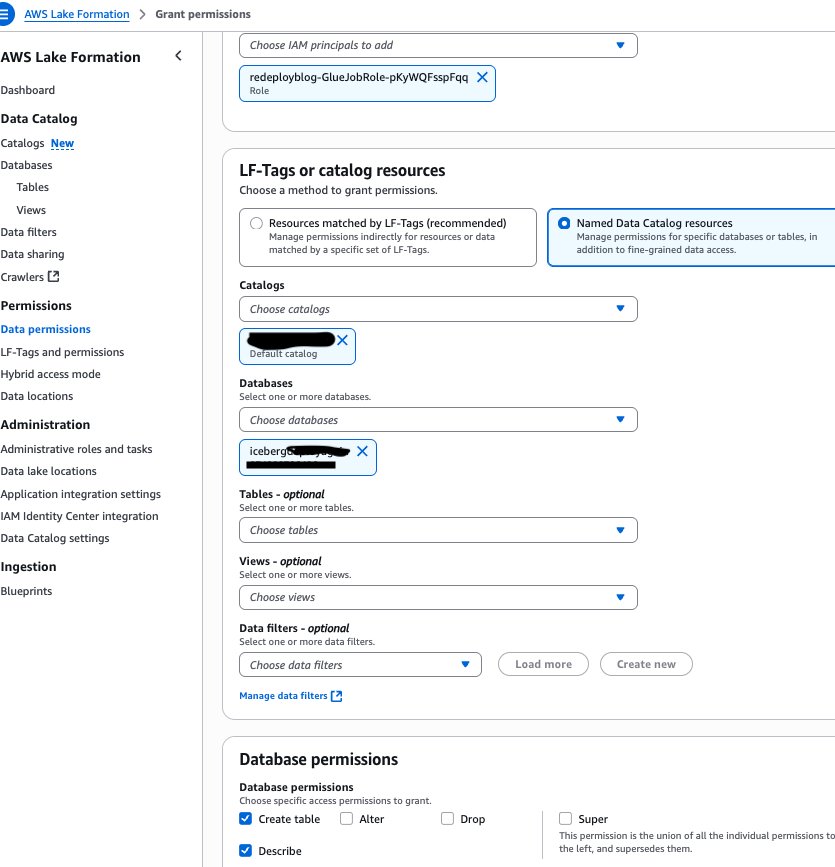
In Account A, onboard the S3 table in SageMaker Lakehouse and grant permissions to the project role:
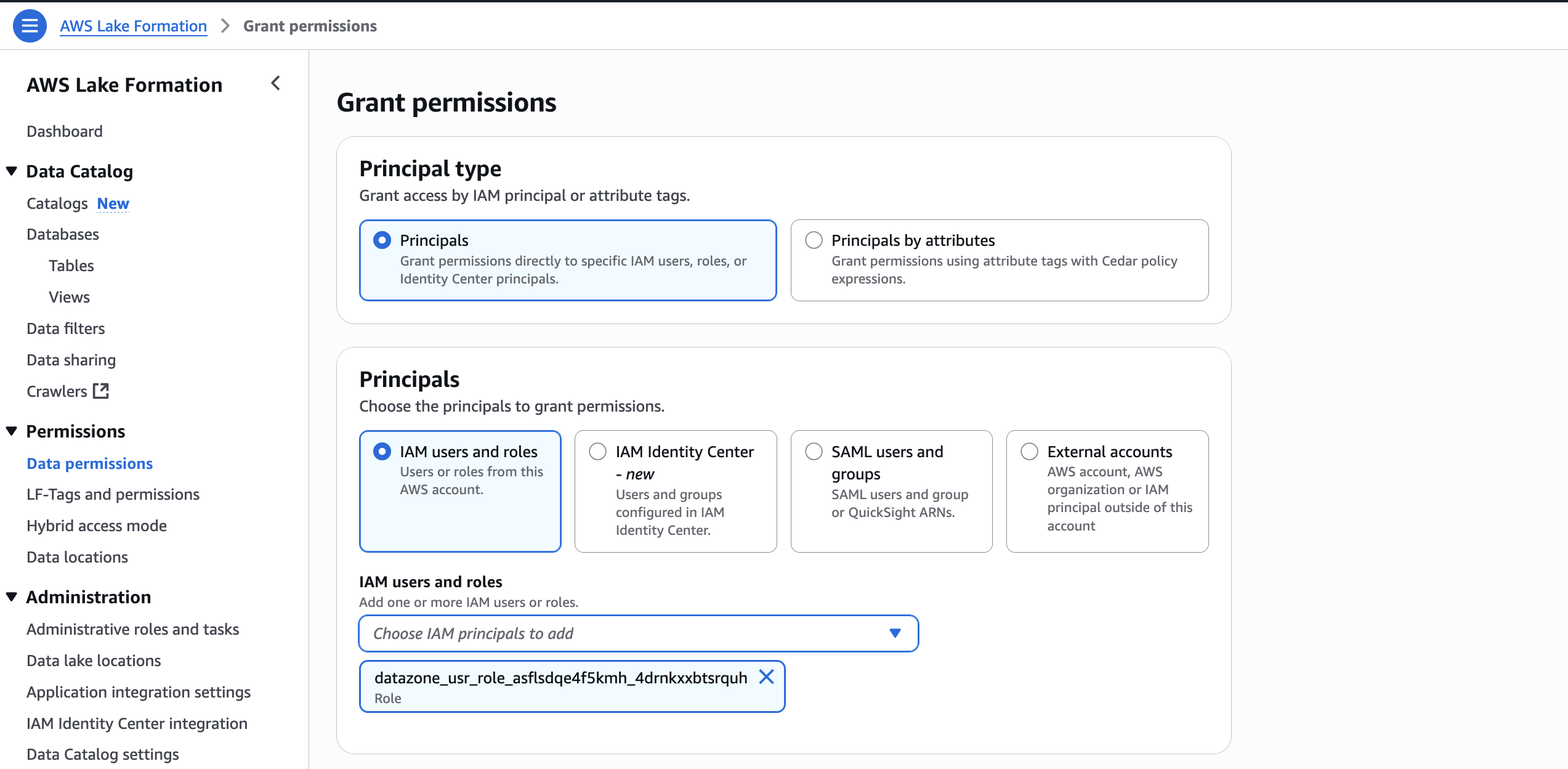
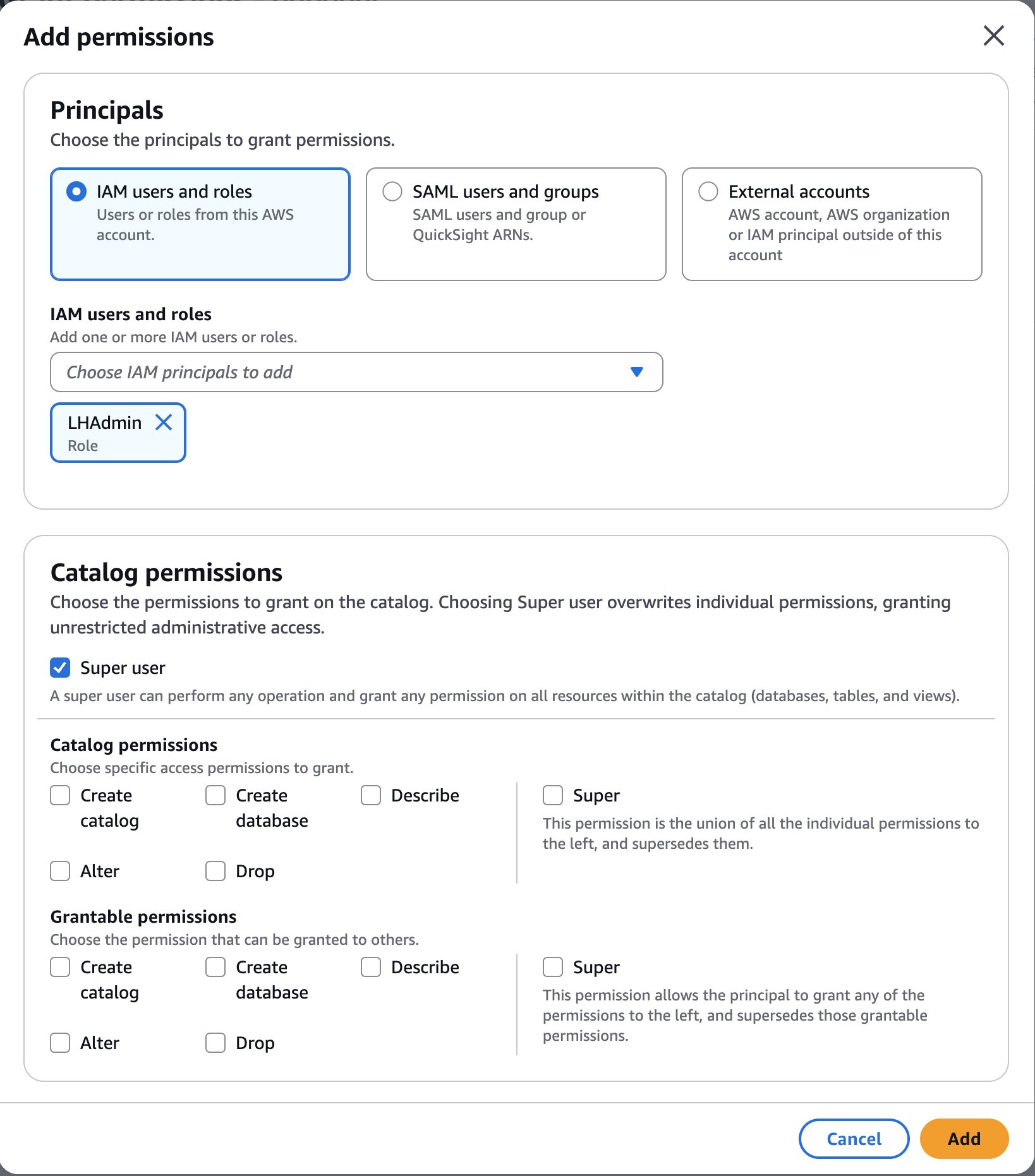
- In the AWS Lake Formation console, choose Permissions, choose Data permissions, and then choose Grant.
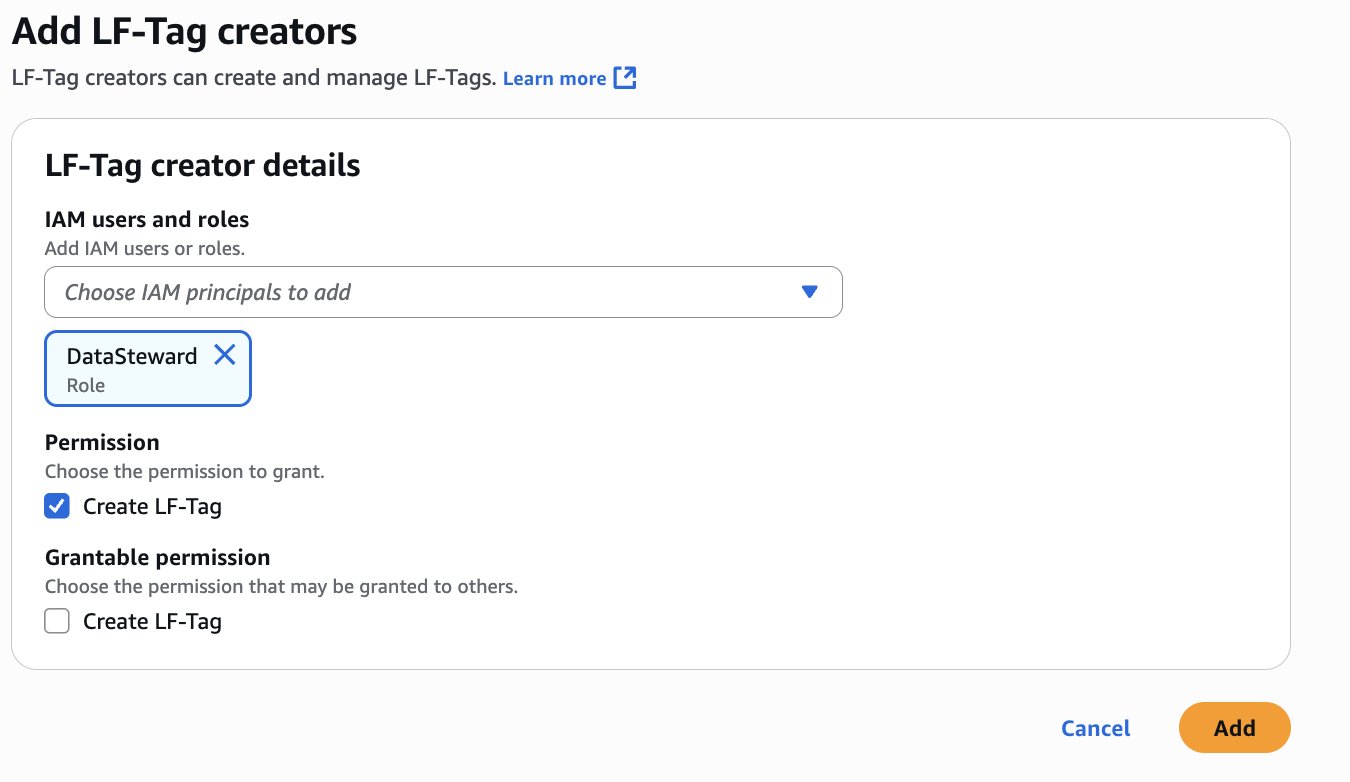
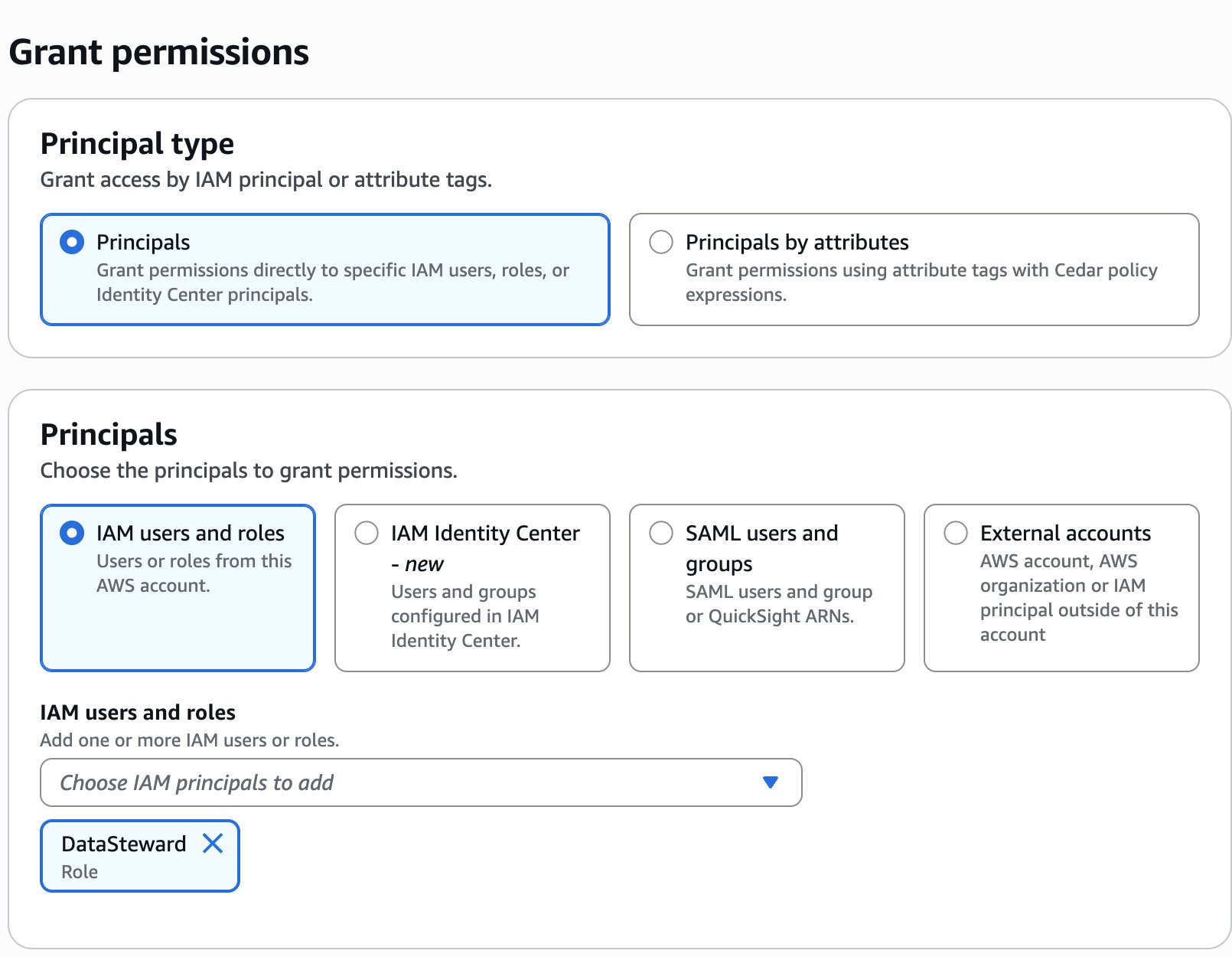
- Choose Principals, select IAM users and roles, then select the role generated by the project
producer-s3tablesin Step 3.

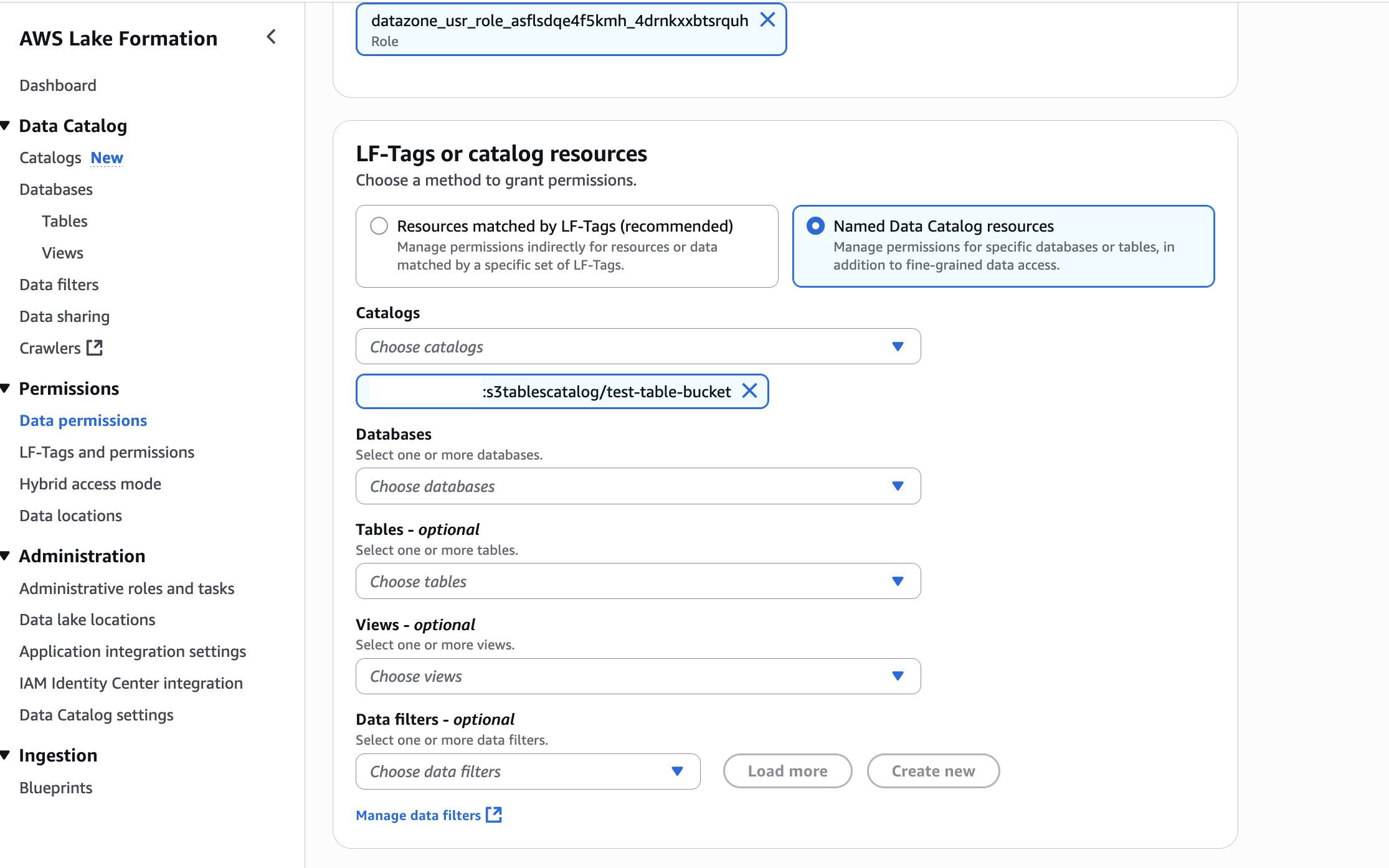
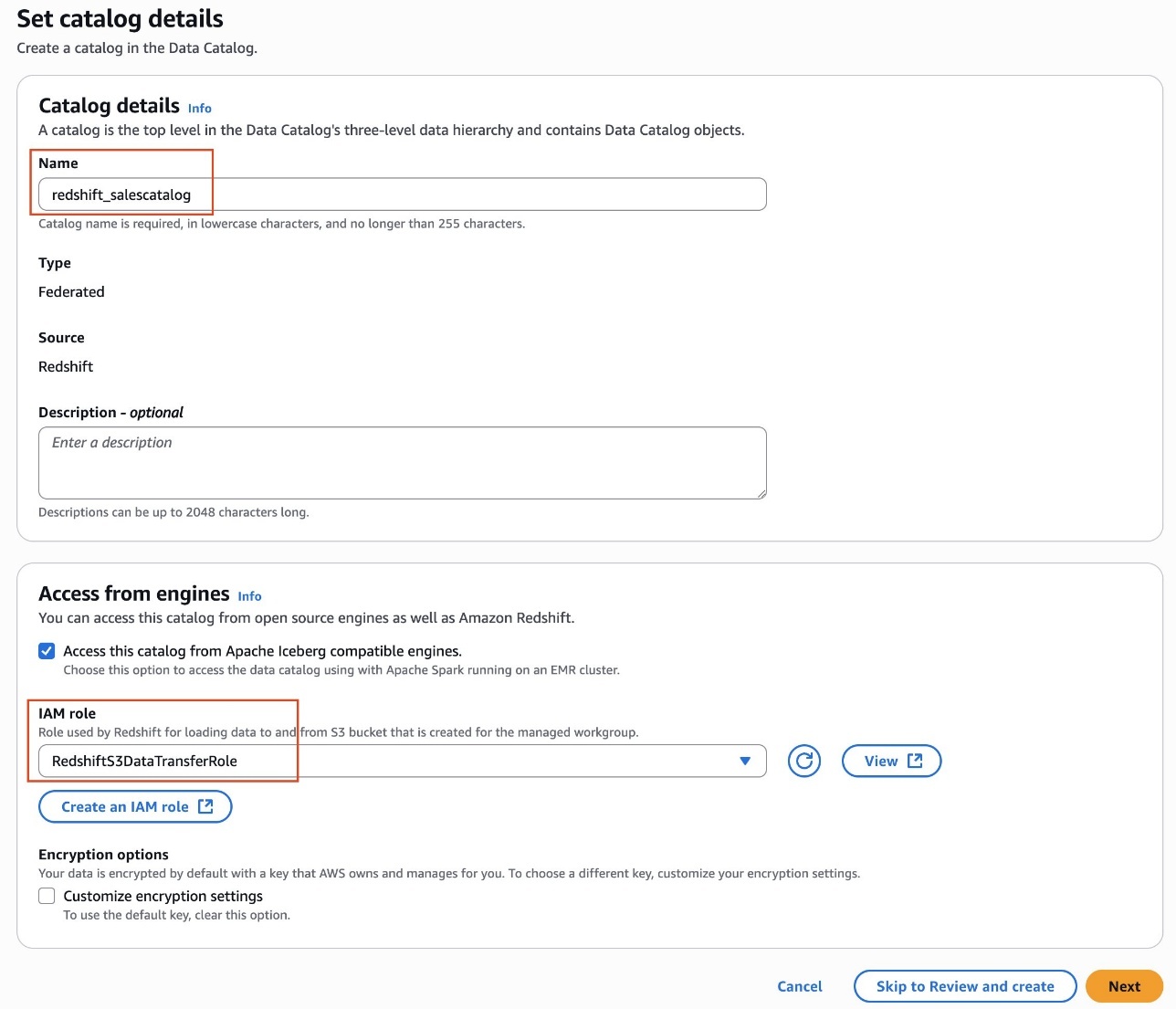
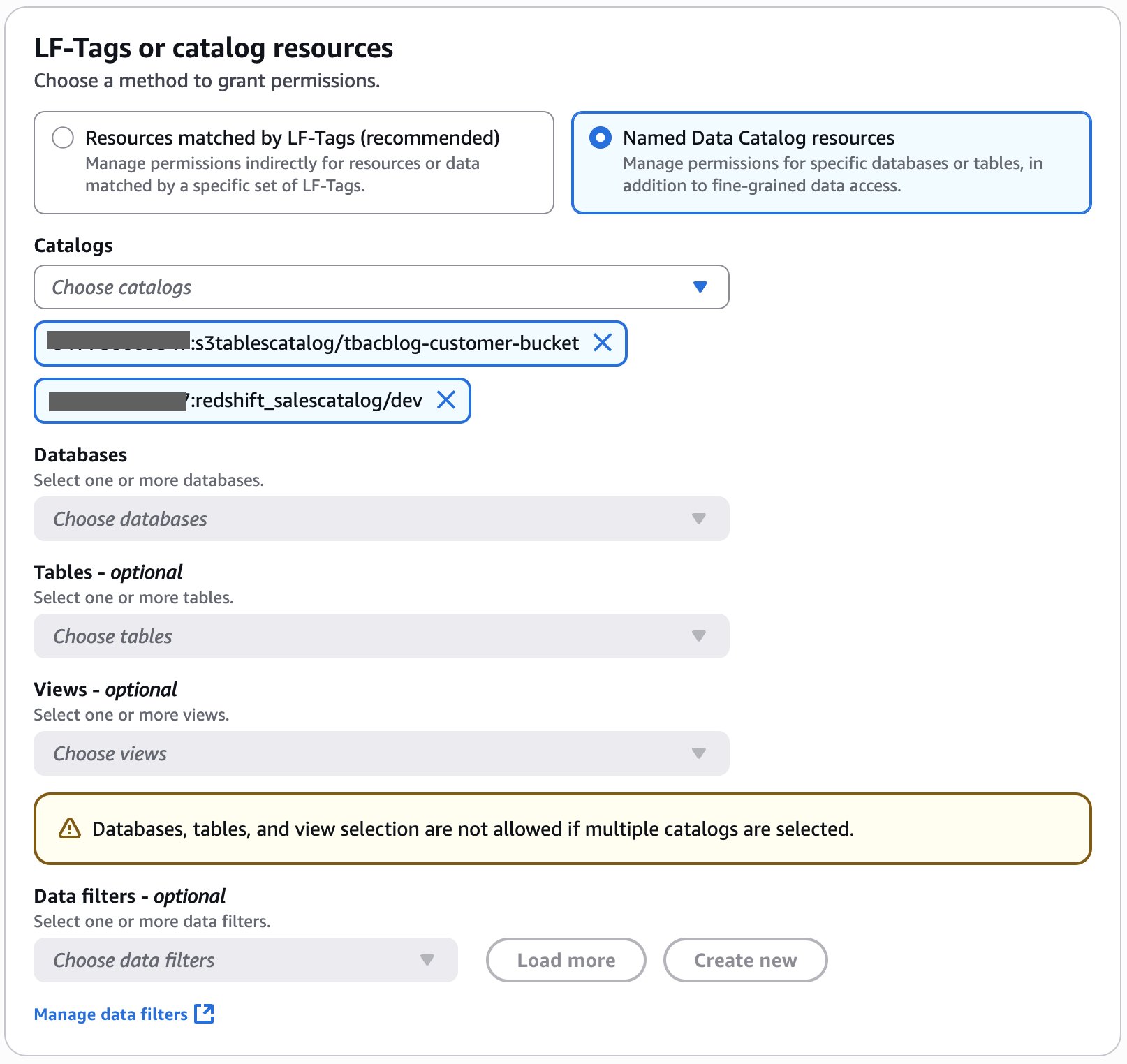
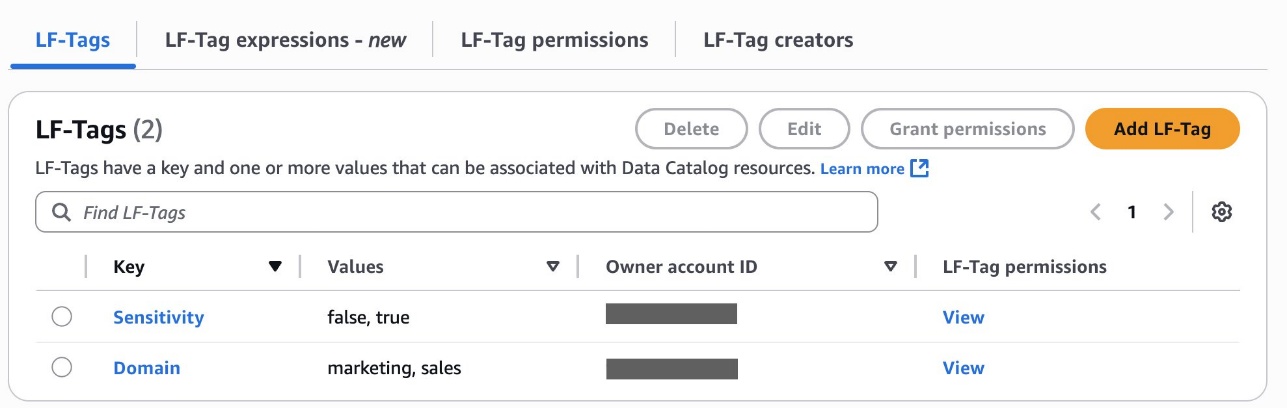
- In LF-Tags or catalog resources, choose Named data catalog resources, select the S3 table catalog from the Catalogs list.

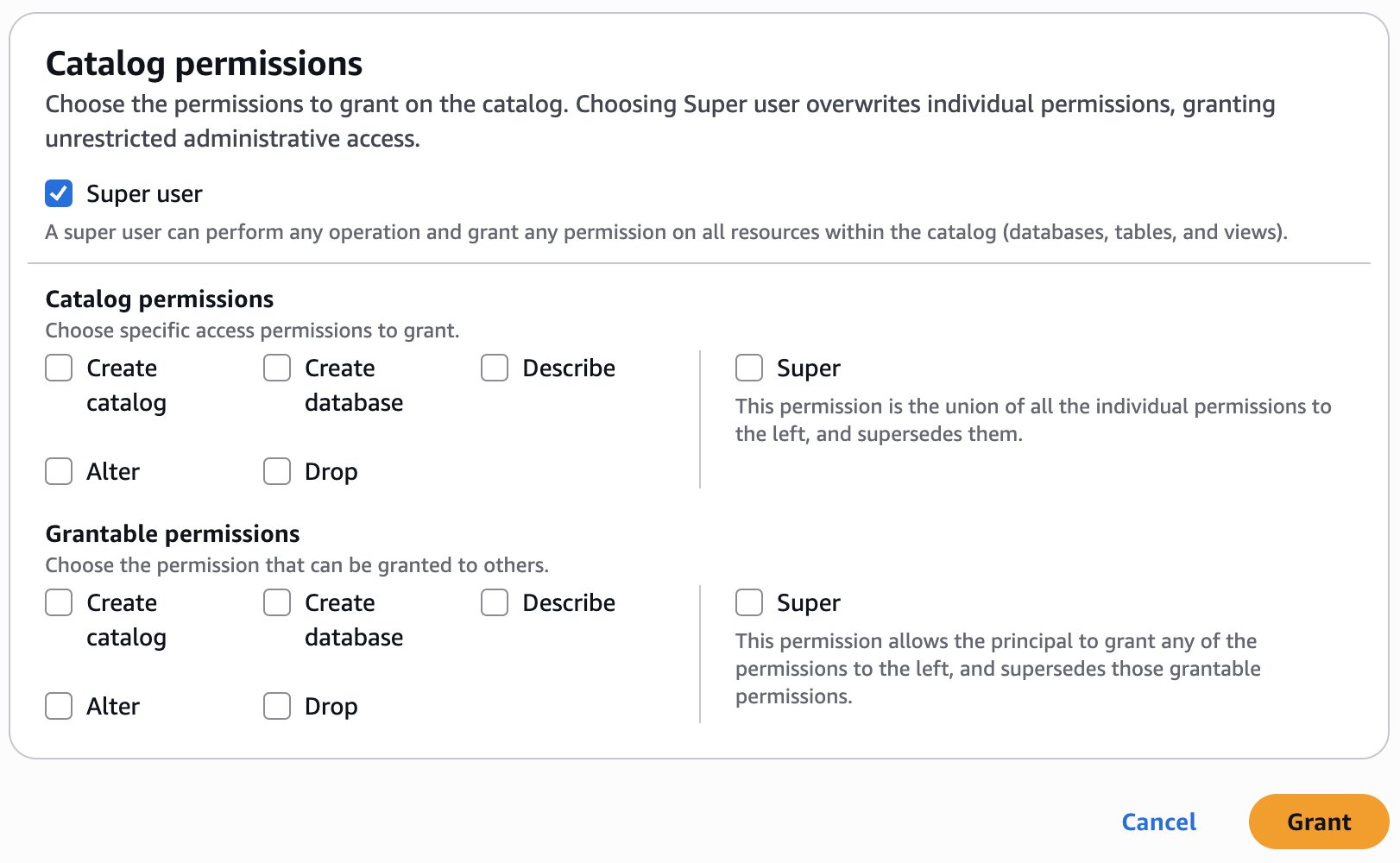
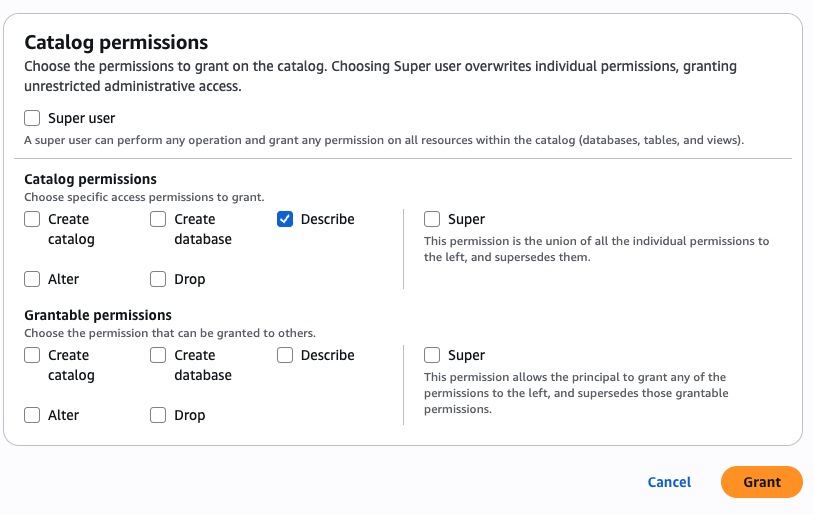
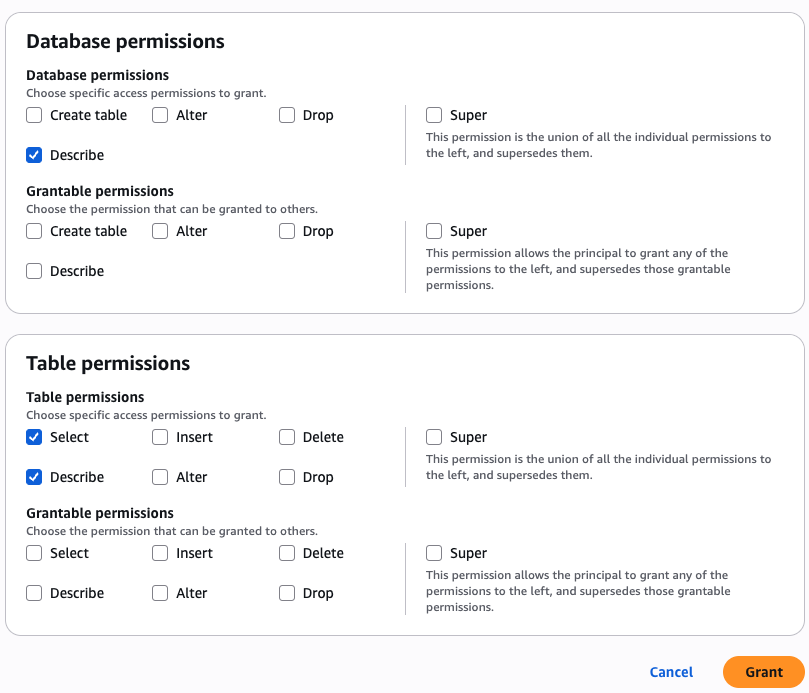
- In Catalog permissions, configure the Catalog permissions and grantable permissions. Choose Grant to apply the following permissions.

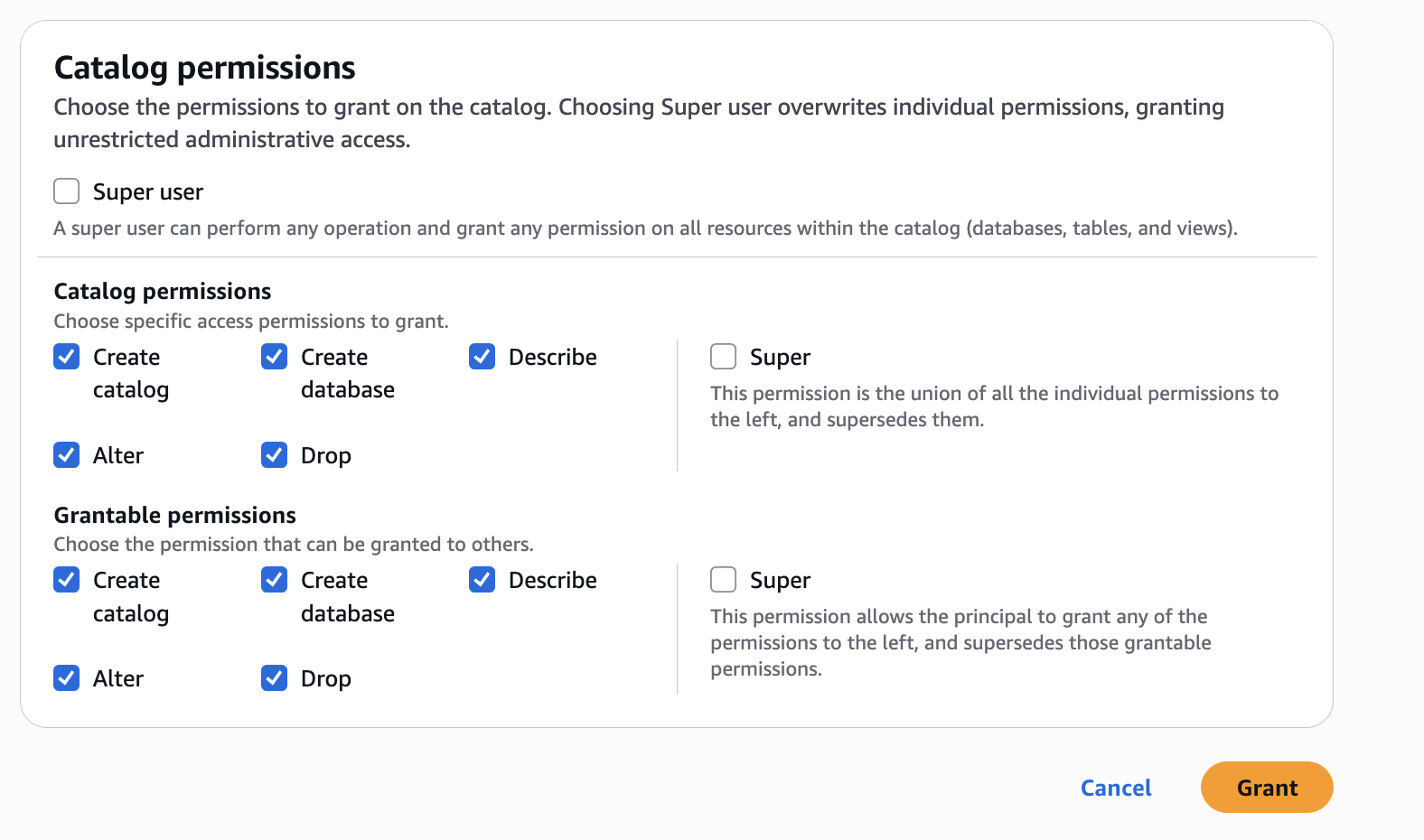
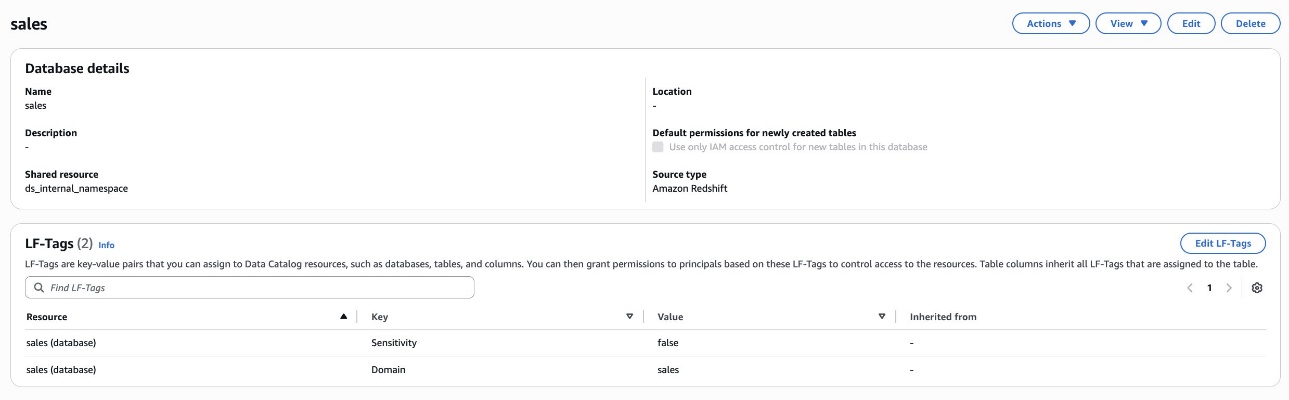
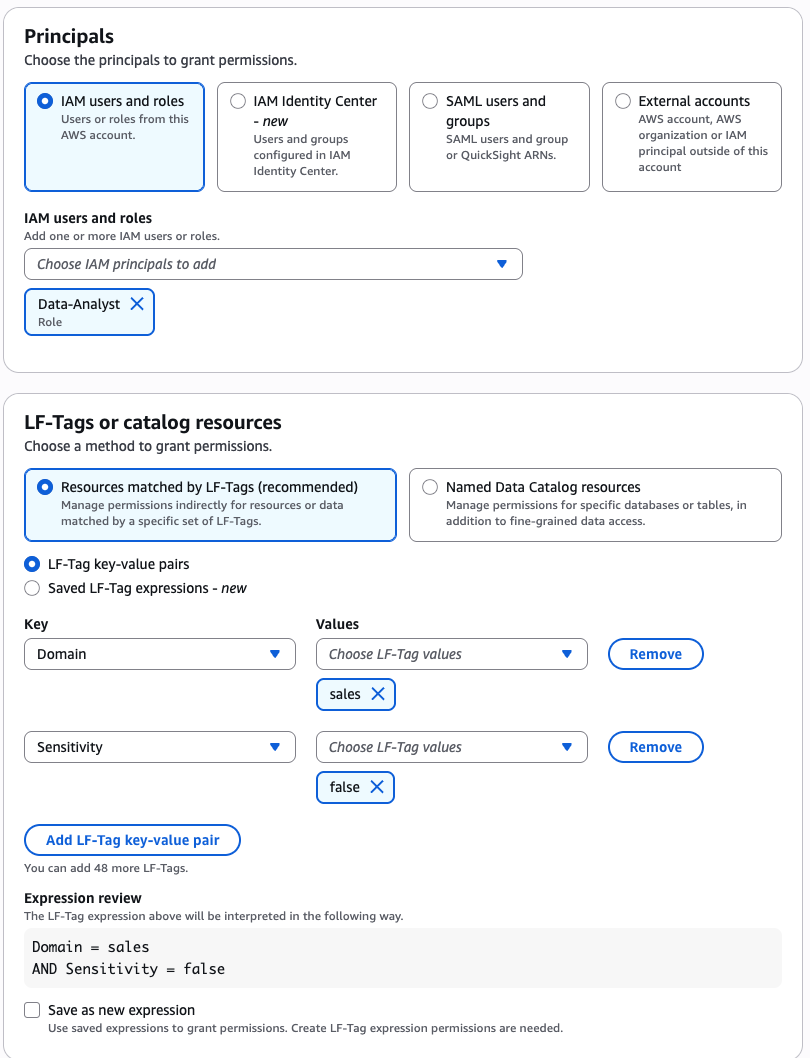
In Account A, we repeat these steps for grant permissions to the database:
- In the AWS Lake Formation console, choose Permissions, choose Data permissions, and then choose Grant.
- Choose Principals, select IAM users and roles, then select the role generated by the project
producer-s3tablesin Step 3.
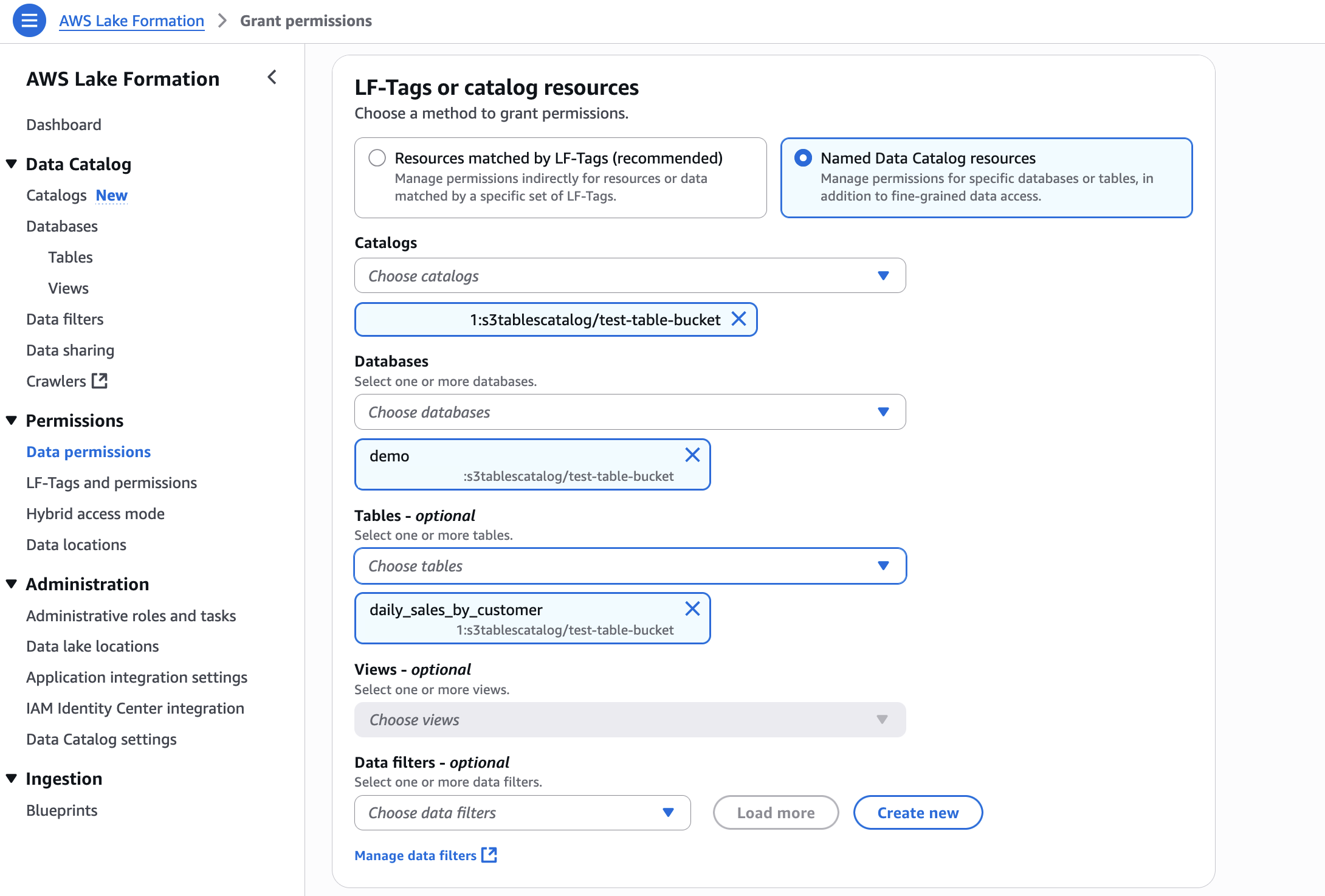
- In LF-Tags or catalog resources, choose Named data catalog resources, choose both the S3 table catalog and database from their respective dropdown lists.

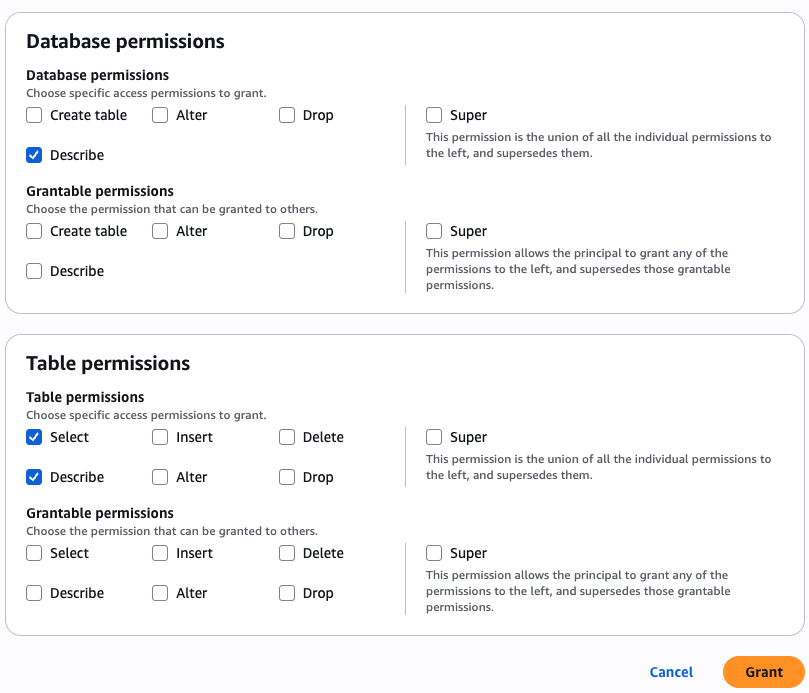
- Configure database permissions and grantable permissions. Choose Grant to apply the following permissions.

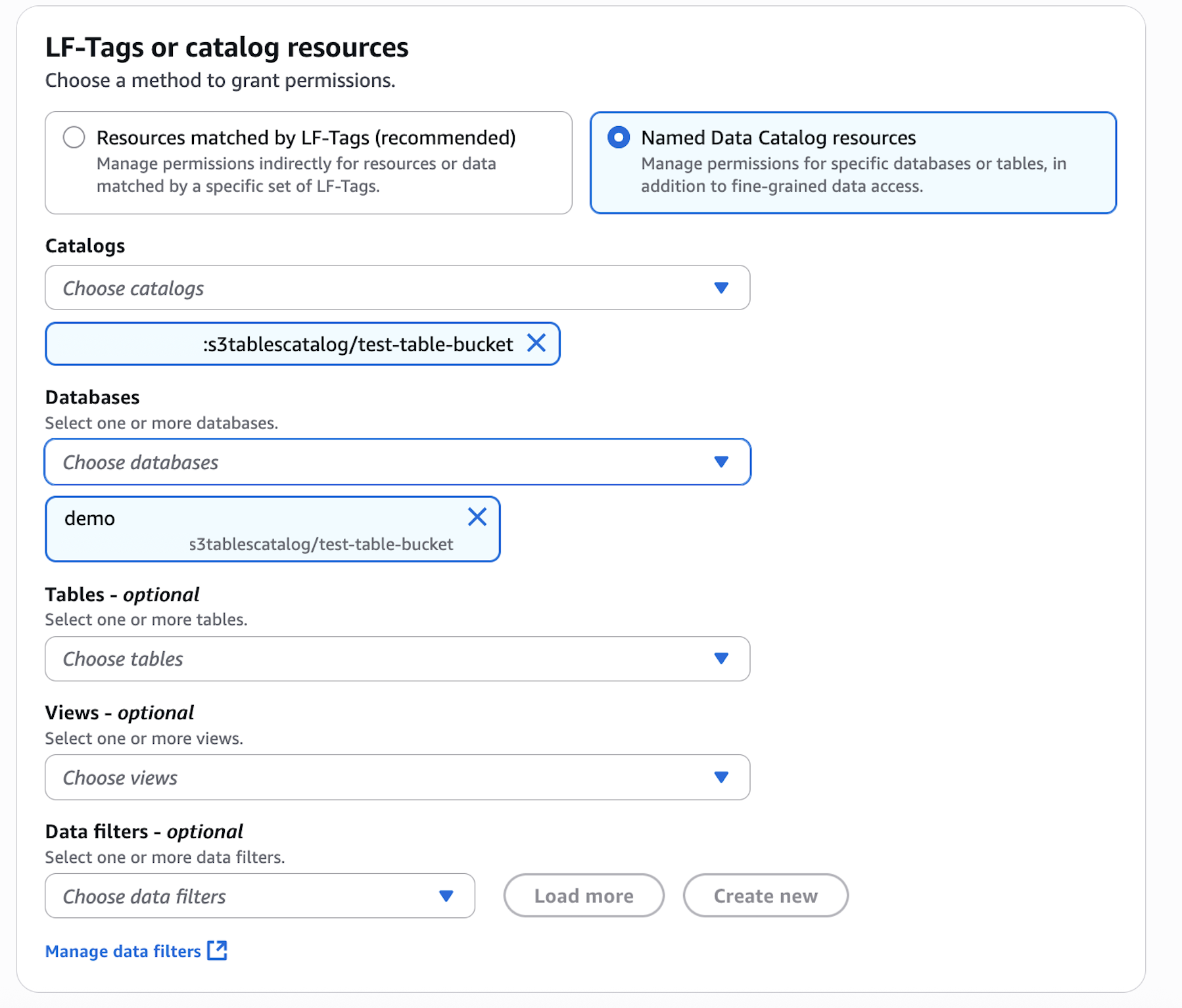
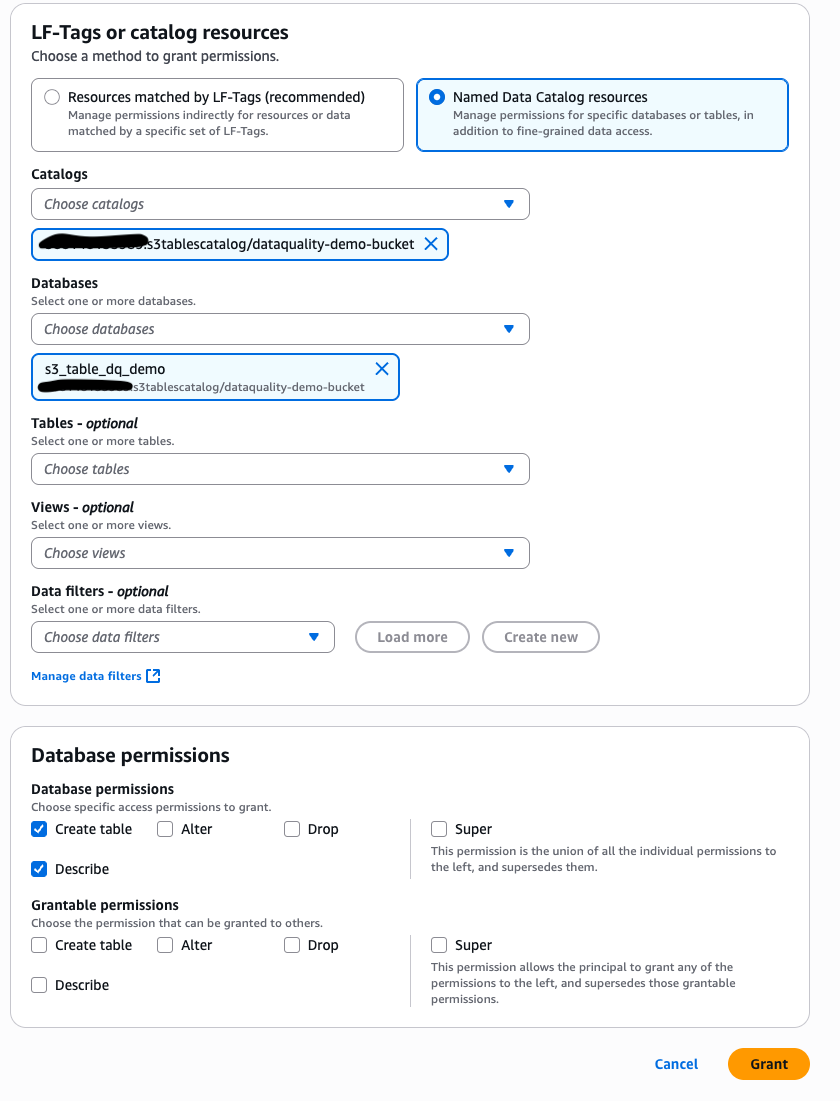
In Account A, repeat these steps for grant permissions to the table in the database:
- In the AWS Lake Formation console, choose Permissions, choose Data permissions, and then choose Grant.
- Choose Principals, select IAM users and roles, then select the role generated by the project
producer-s3tablesin Step 3.
- In LF-Tags or catalog resources, choose Named data catalog resources, choose both the S3 table catalog, database, and S3 table from their respective dropdown lists.

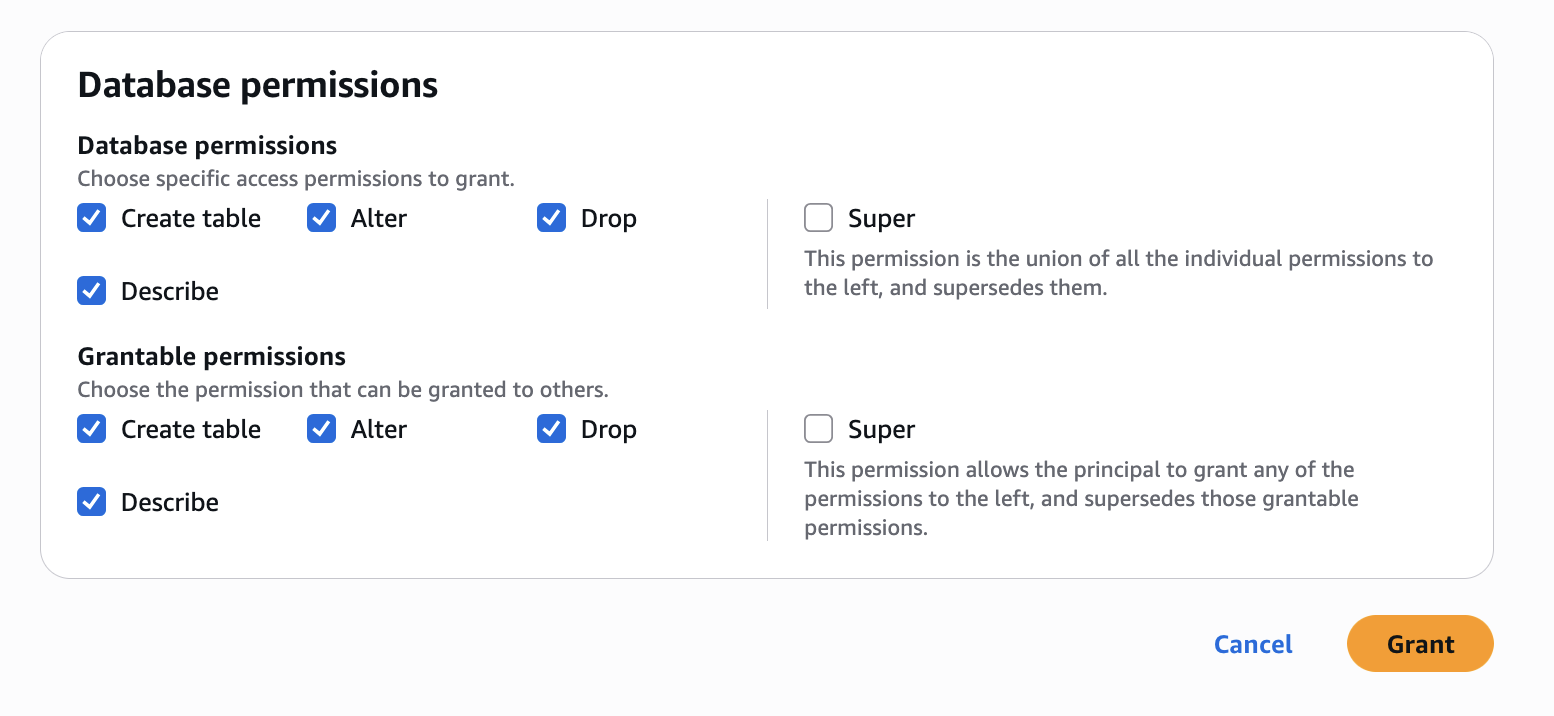
- Configure table permissions and grantable permissions. Choose Grant to apply the following permissions.

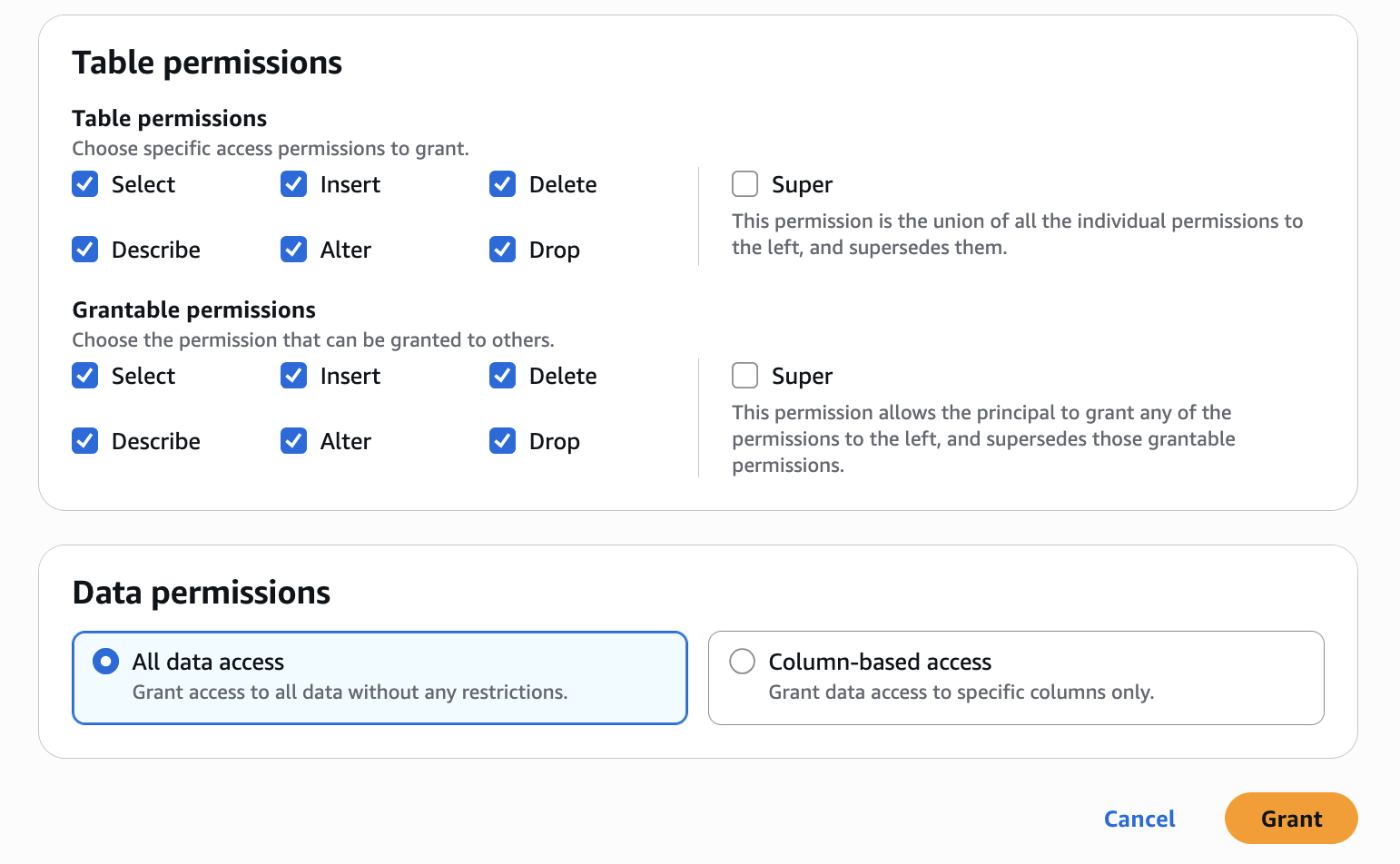
Repeat Step 4 in Accounts B to onboard S3 to SageMaker Lakehouse and grant the necessary permissions to the role created by your project for Account B.
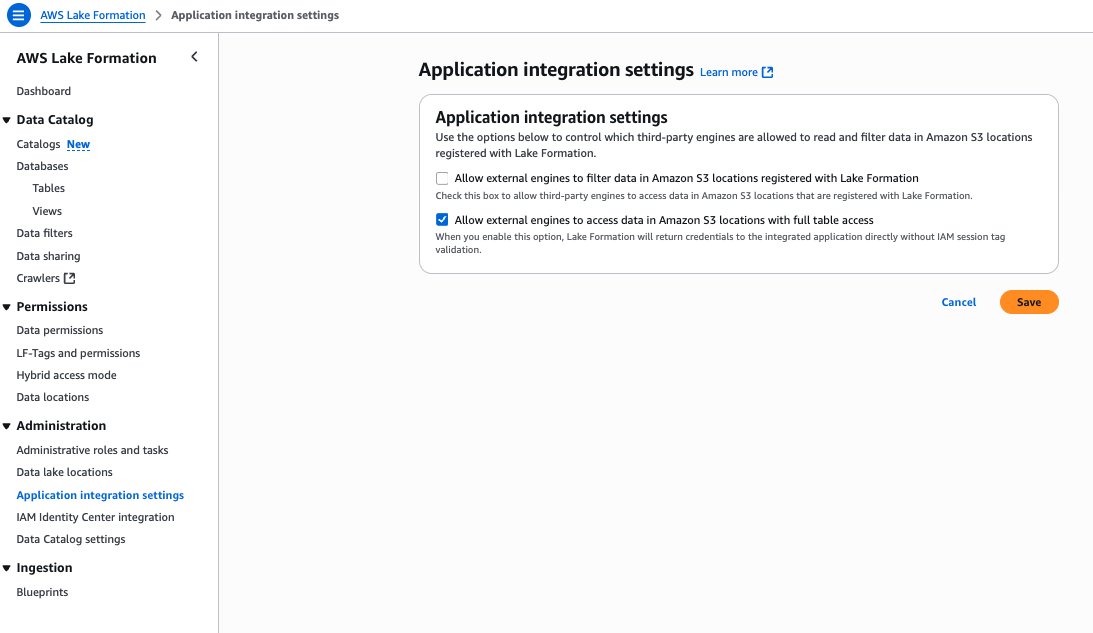
Step 5: Create Datasource and onboard S3 Table from Account A and Glue Catalog Tables from Account B
To enable unified access and cross-account analytics with data lineage tracking, you’ll connect your SageMaker Unified Studio project to S3 tables from both accounts:
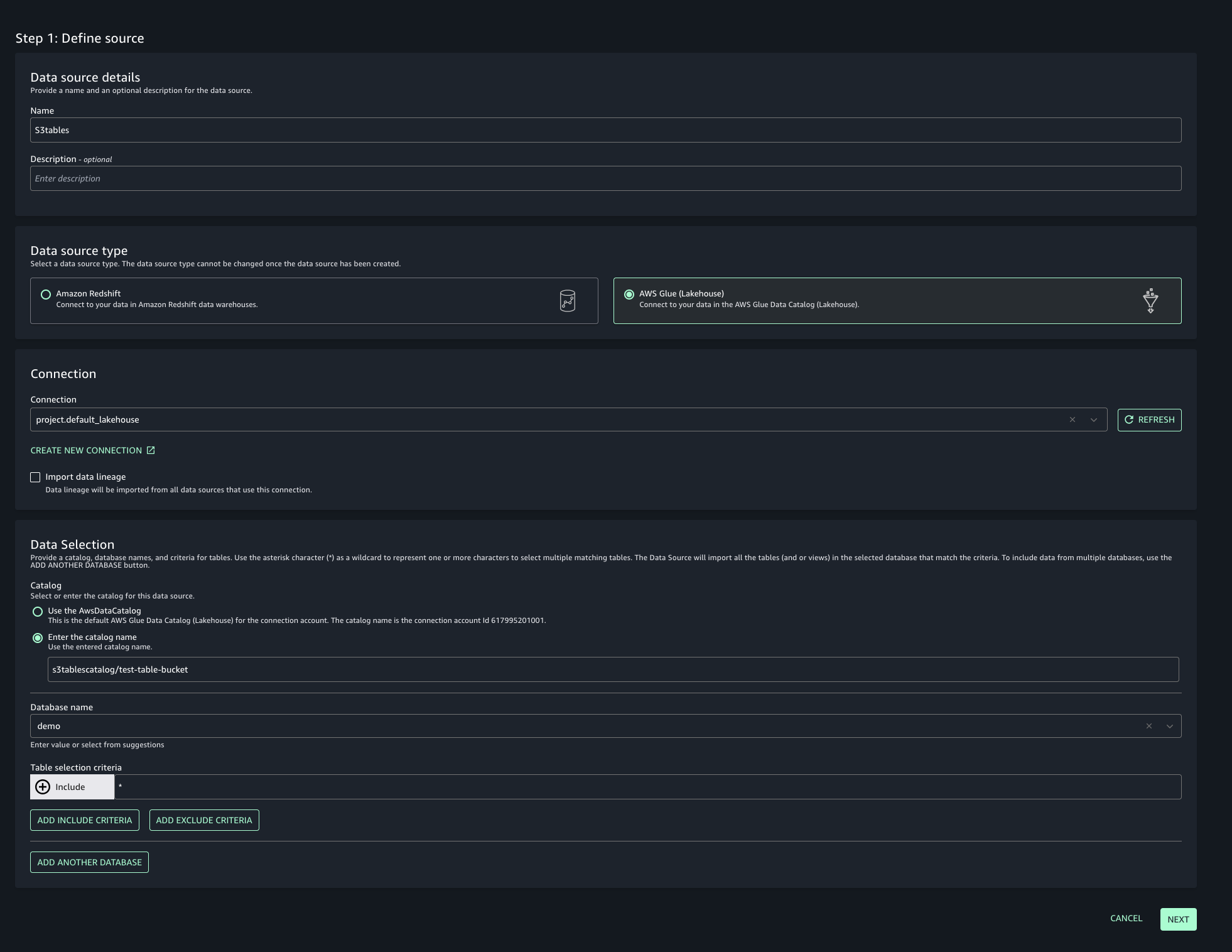
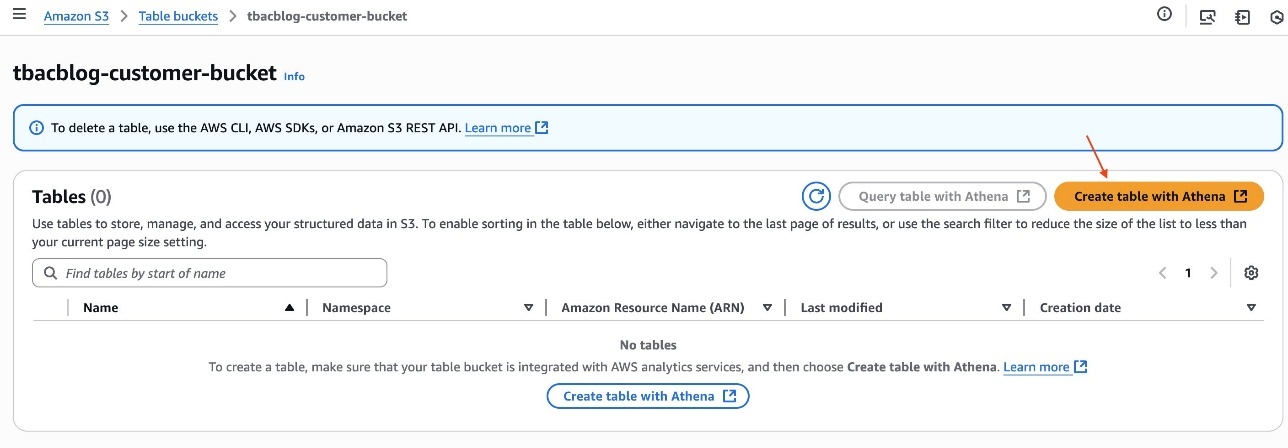
- Navigate to your project in SageMaker Unified Studio, select Data sources under the Project catalog section and choose Create data source.
- Enter a name, description, and select AWS Glue as the Data source type. Under Data selection, specify the S3 table catalog name.

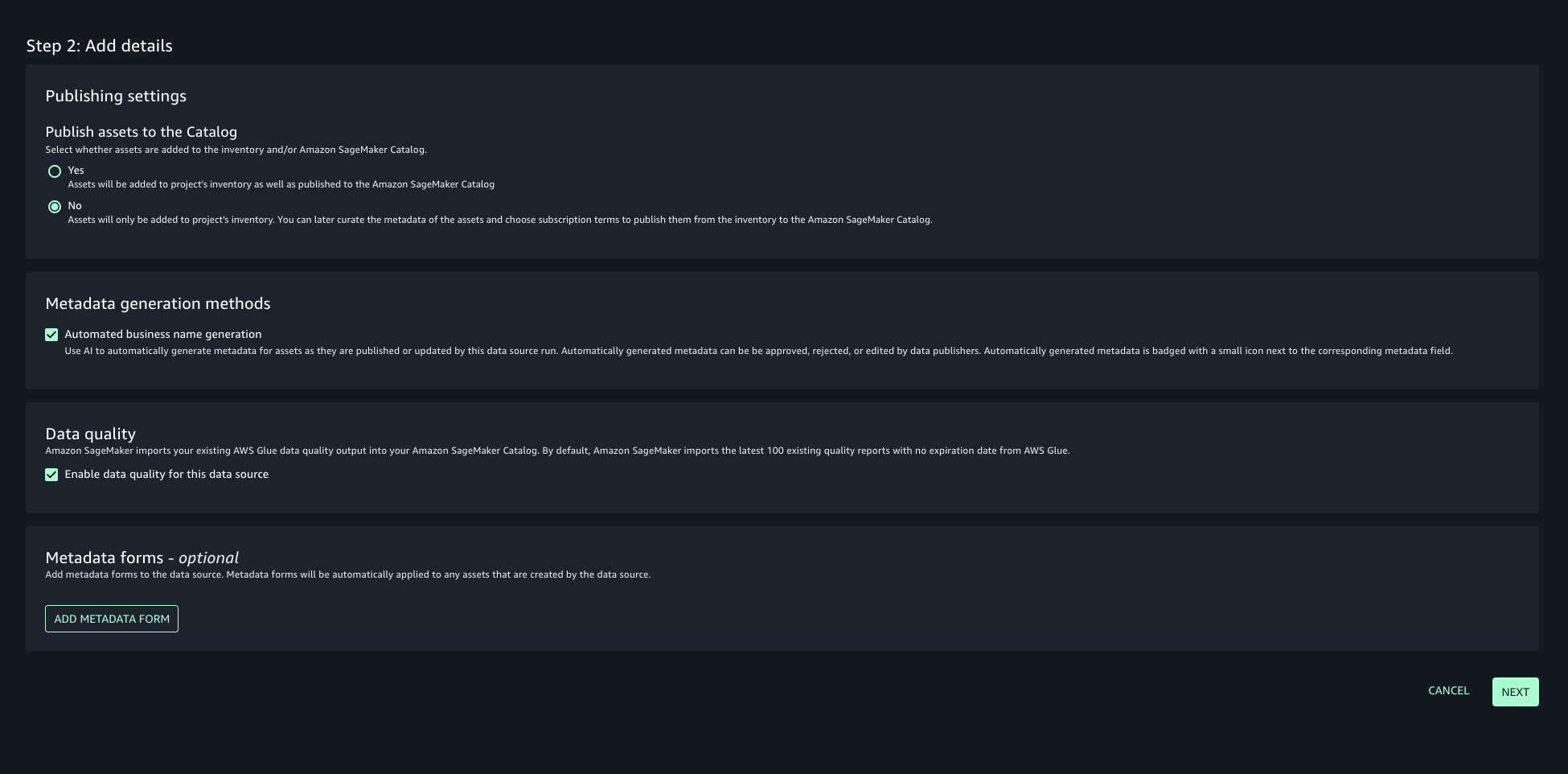
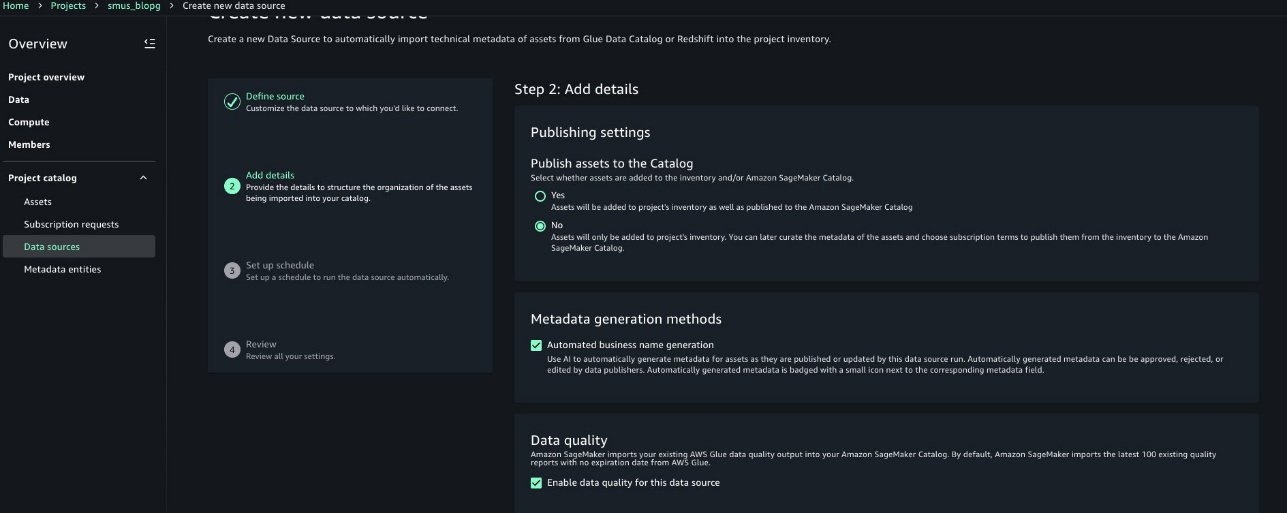
- In this post, we will keep the Publishing setting and Metadata settings as the default configuration.

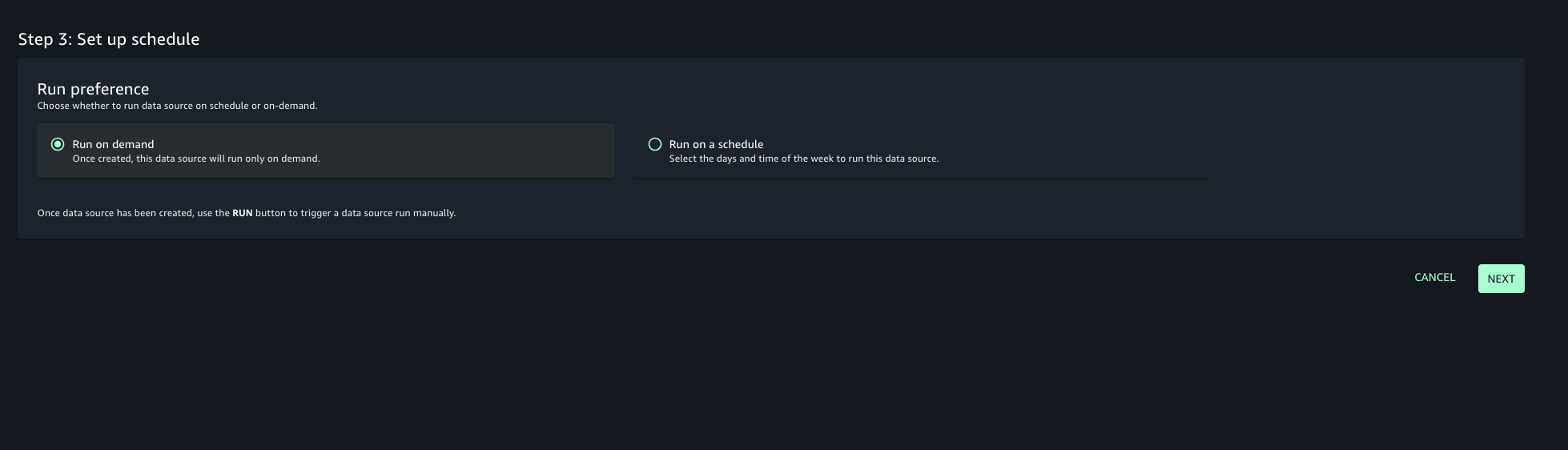
- Choose the run preference as Run on demand to manually initiate data source runs.

- Configure any optional connection settings, such as importing data lineage or setting up data quality options. Review your configuration and create the data source.

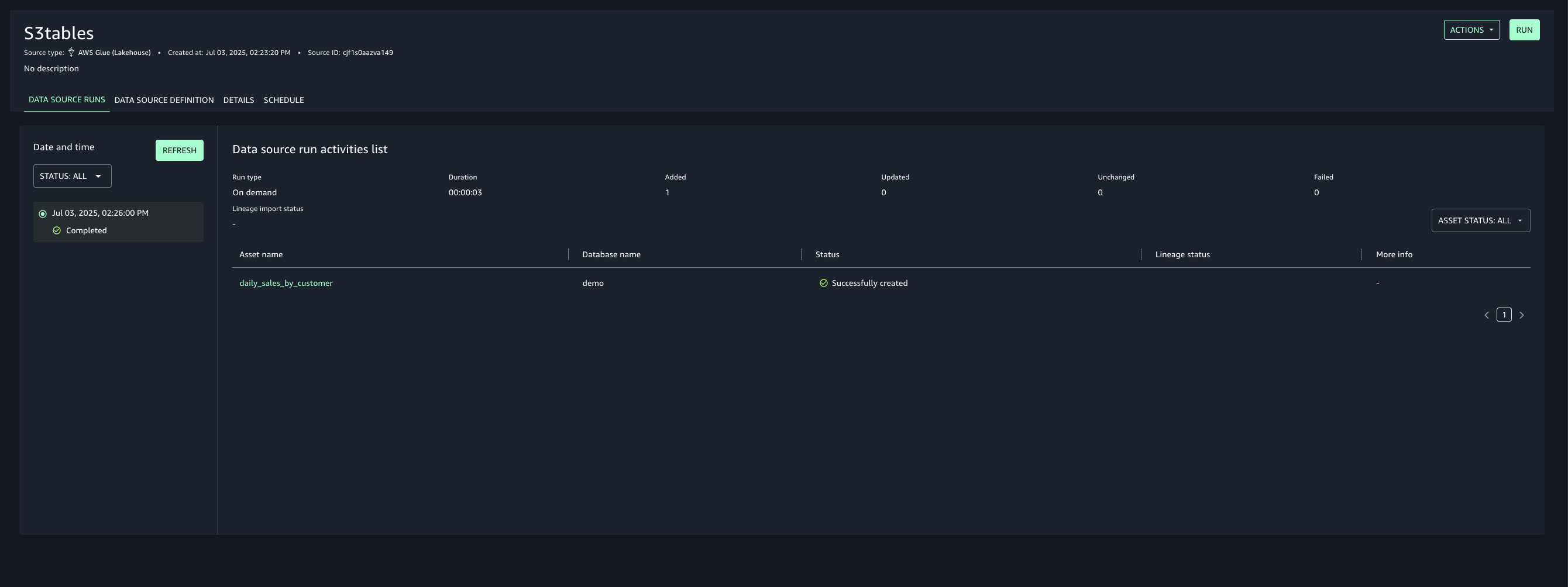
- Once created, run the data source to import the Glue assets into your project’s inventory.

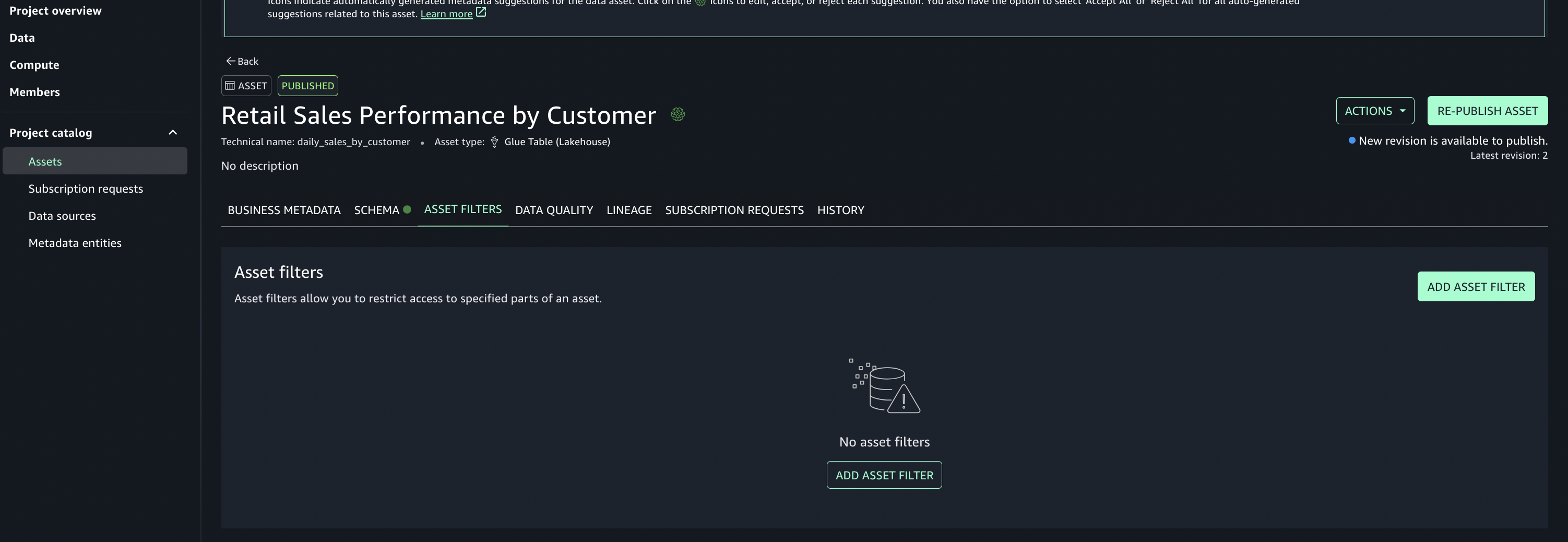
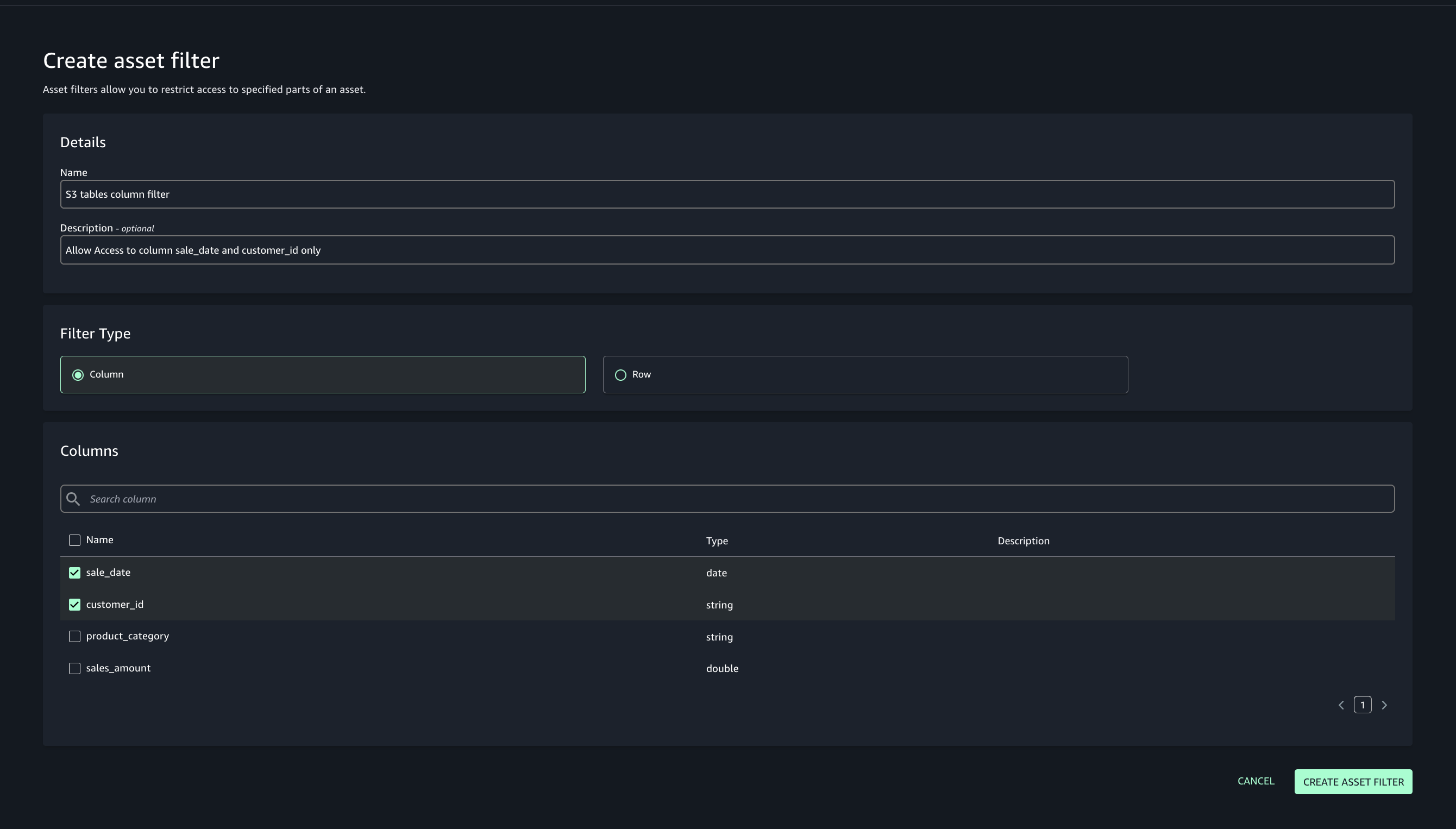
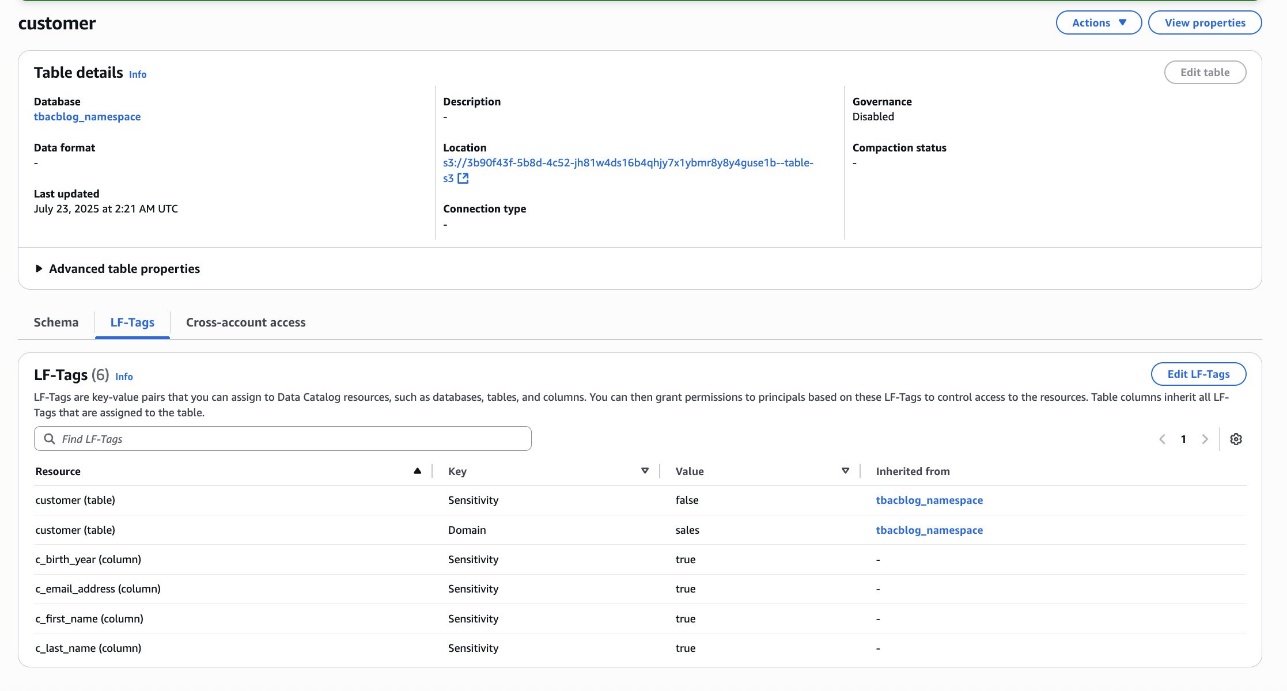
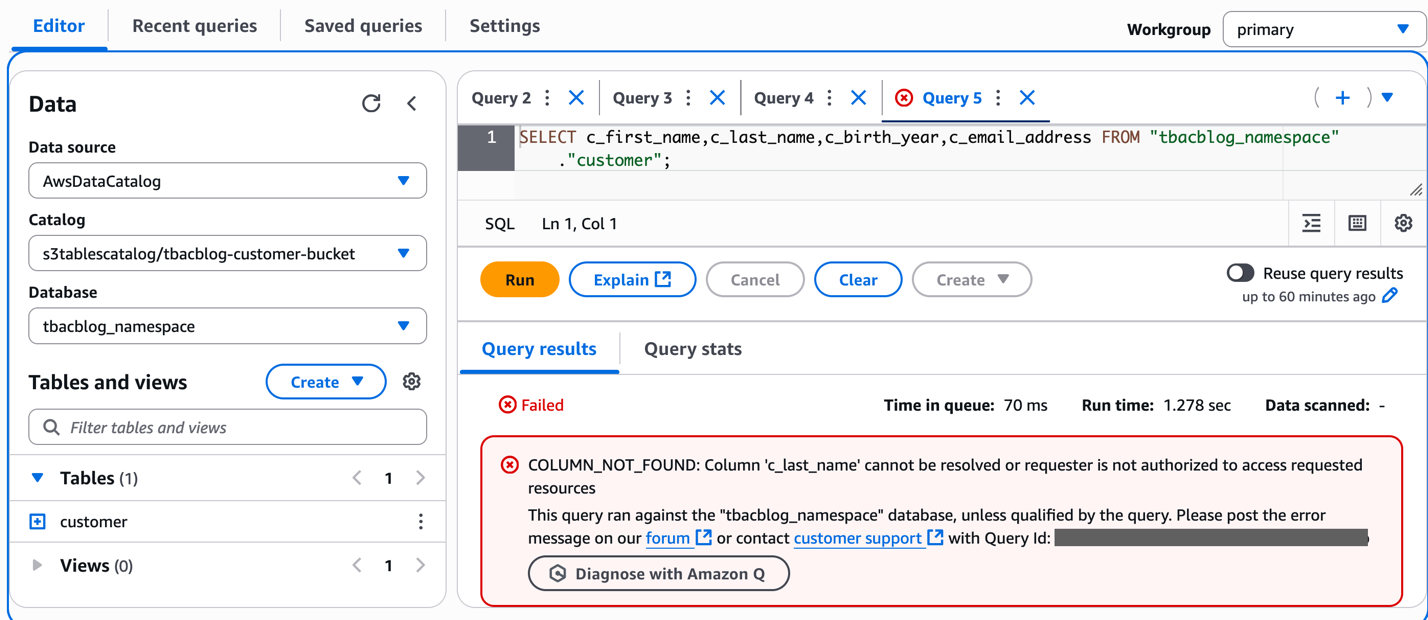
- Add asset filter to restrict consumer access, On the Asset filters tab, choose Add asset filter.

- Select Column as the filter type, choose the columns for consumer access, and create the asset filter.

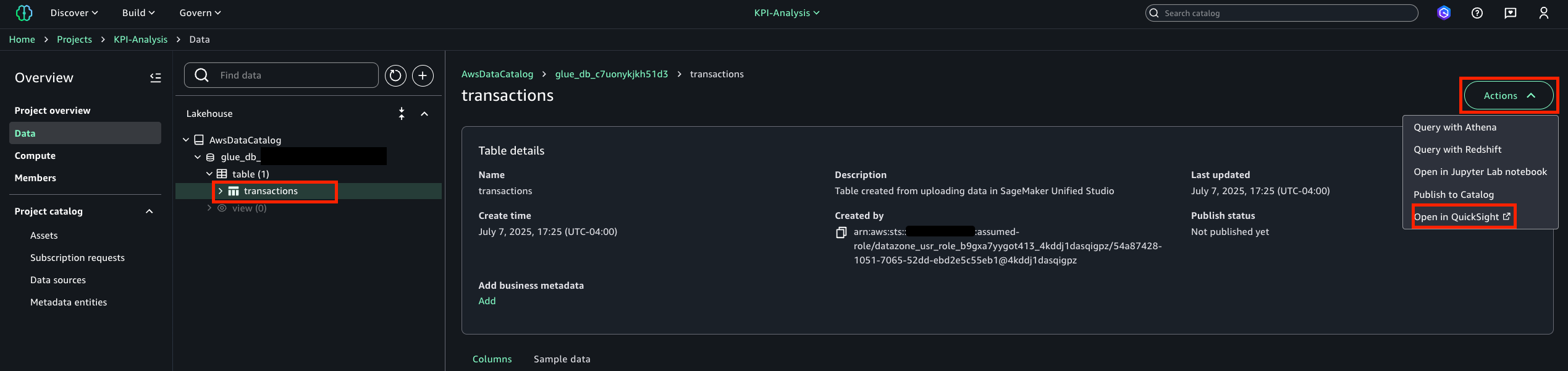
- Select the assets created and choose Publish assets to the SageMaker Unified Studio catalog to make them discoverable by other users.

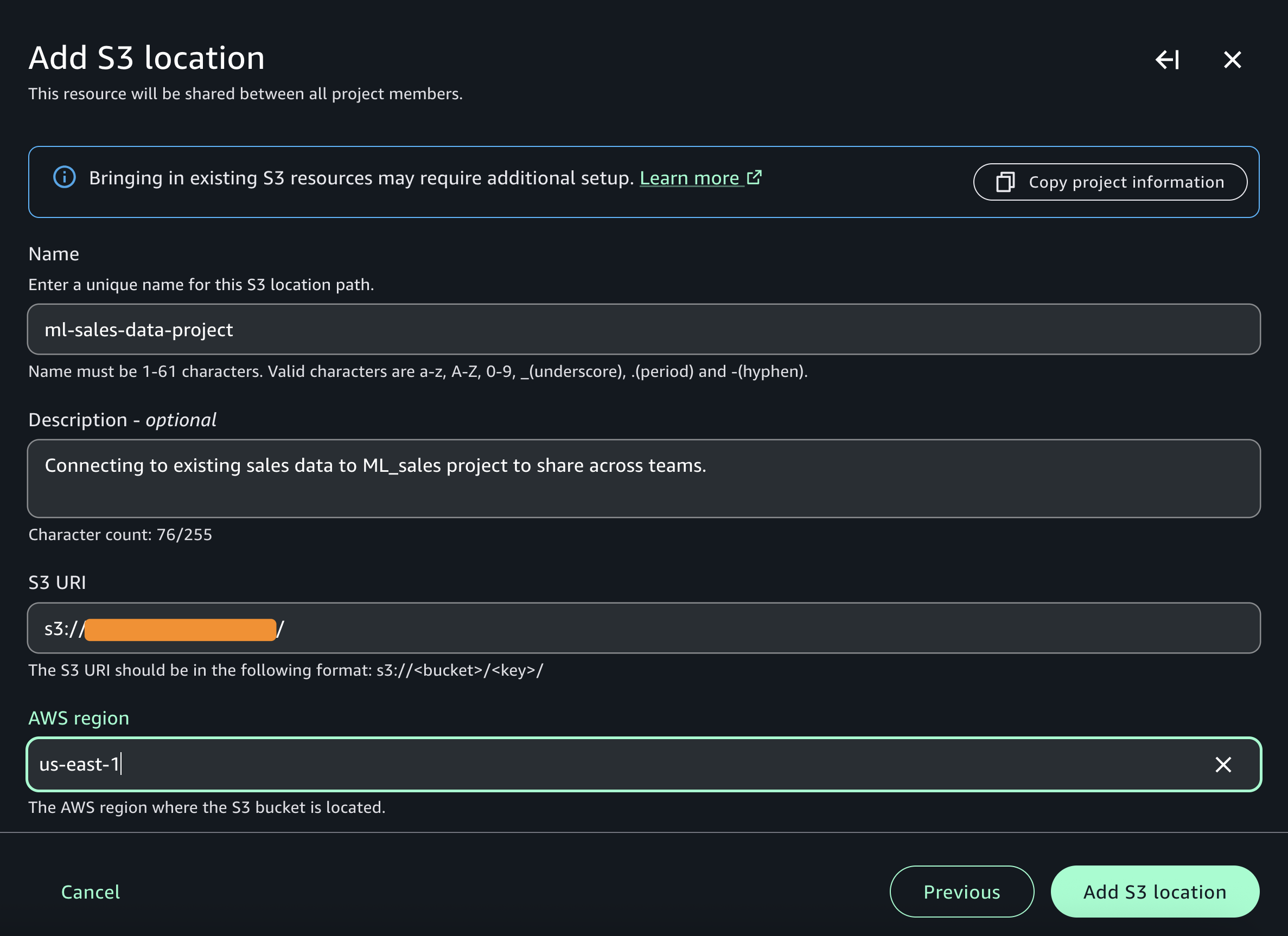
- Use the documentation to add Glue catalog as data source for S3.
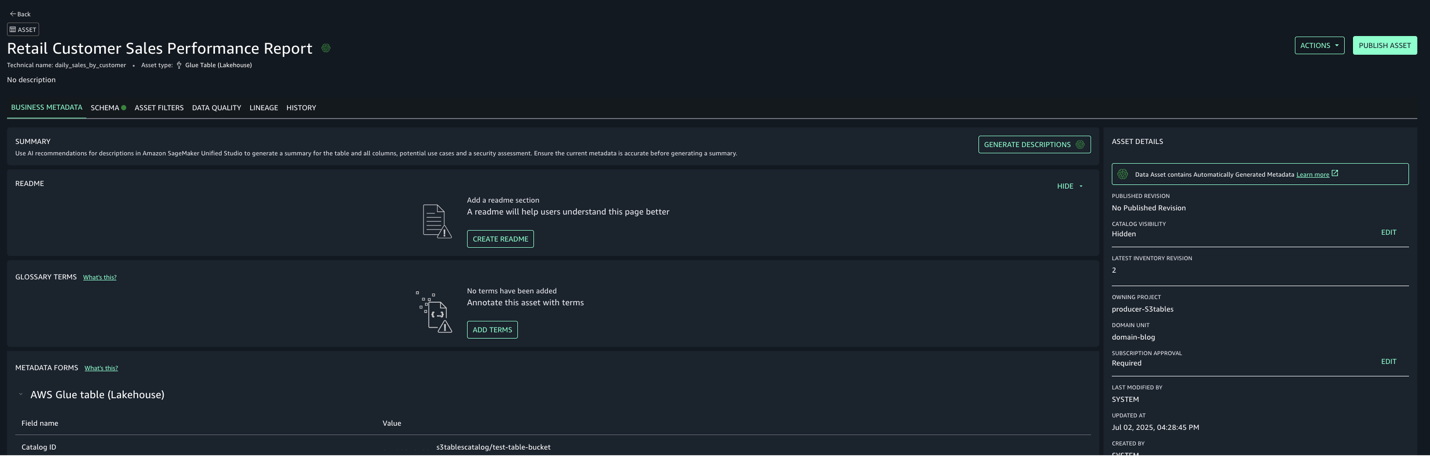
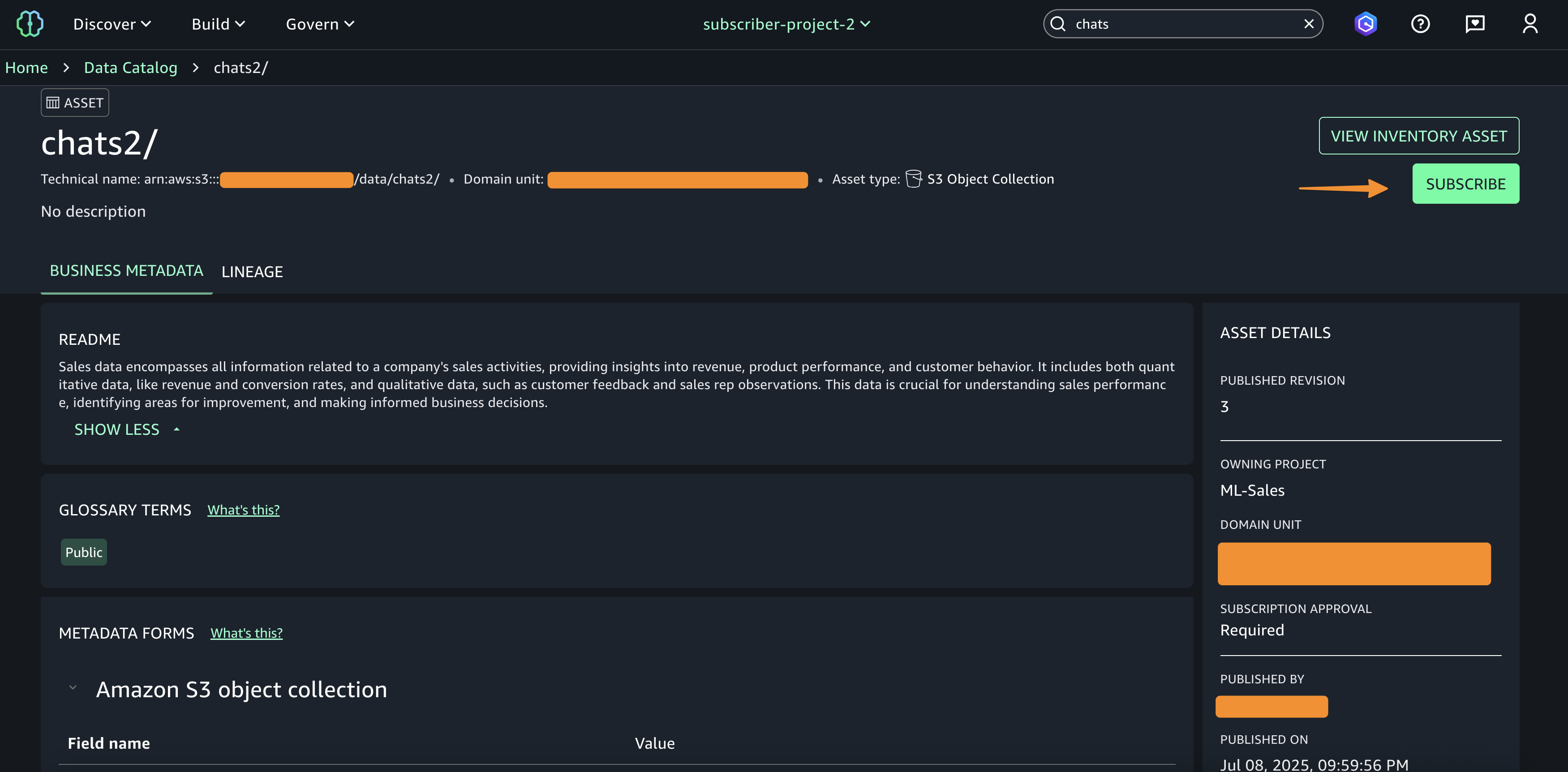
Step 6: Subscribe to the asset from Consumer account in Account C
In Account C, enable the consumer teams to discover, request, and subscribe to those assets for secure, governed data sharing and collaboration across projects.
- In SageMaker Unified Studio, select the consumer project.
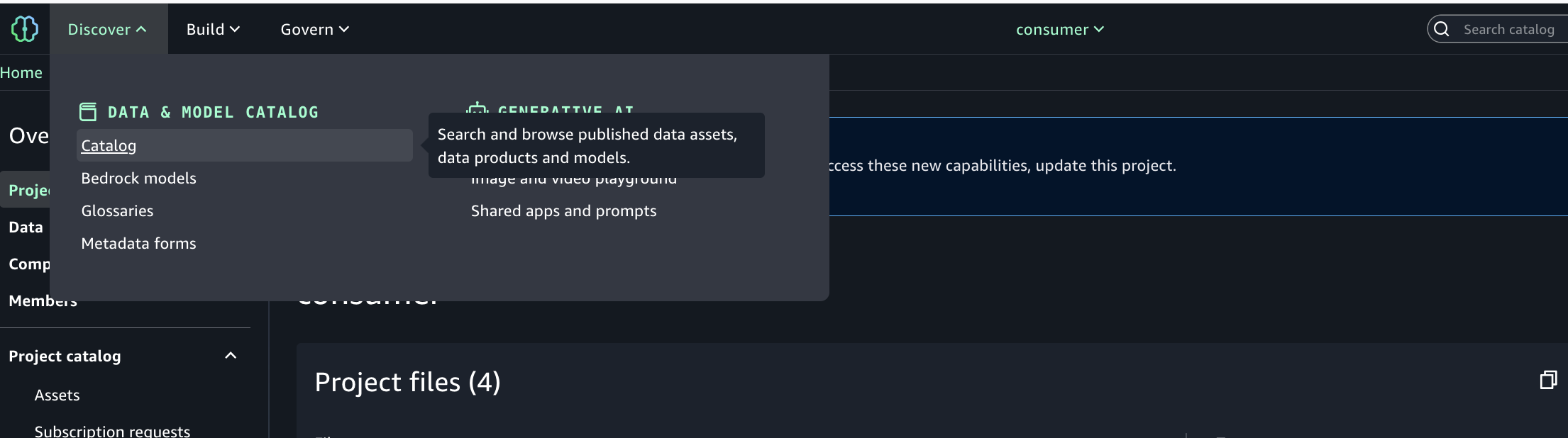
- Use the Discover menu (top navigation) and go to Catalog.

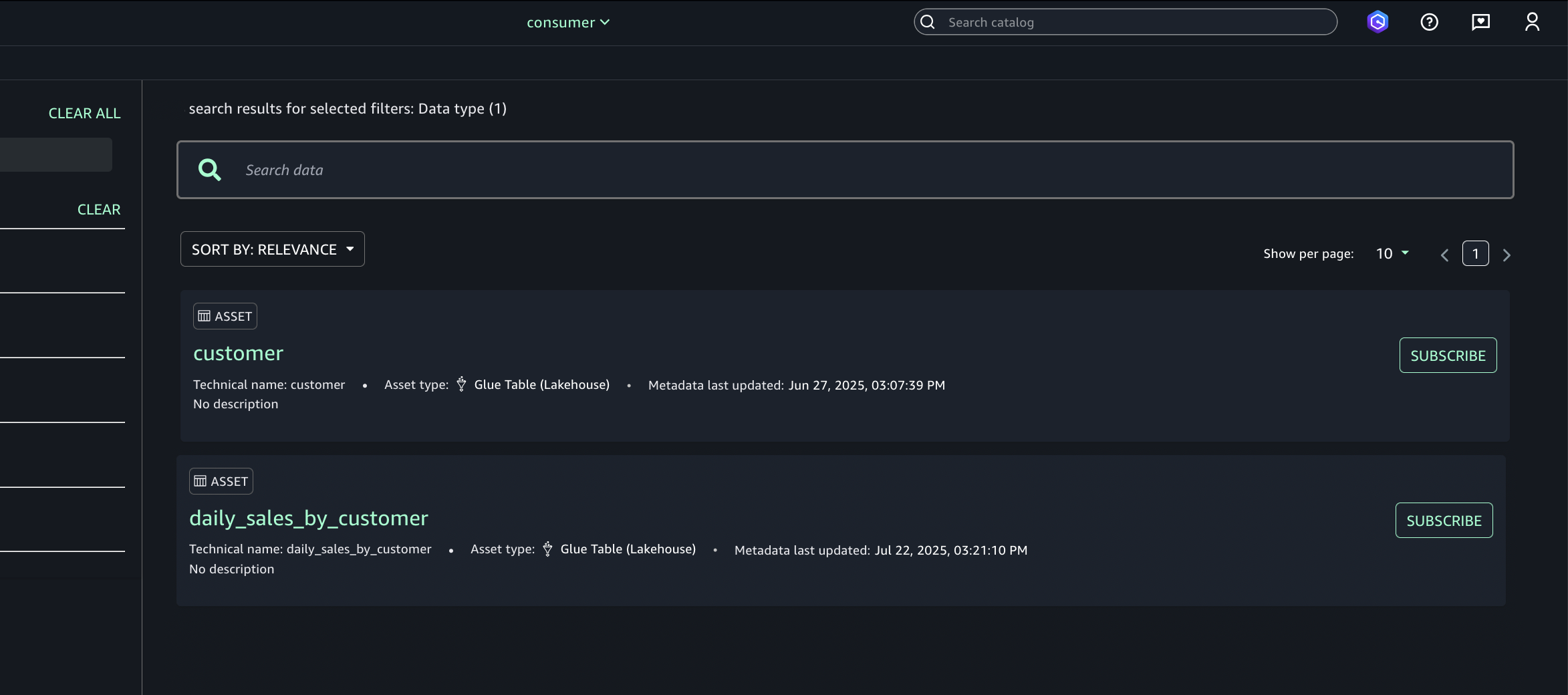
- Browse or search for the published asset (S3 tables from Account A).

- Select the desired asset (S3 tables from Account A) and choose Subscribe.

- In the subscription pop-up:
- Choose the target project for asset access.
- Provide a short justification for the access request.
- Submit the subscription request.
- Repeat step 6 to enable the consumer (Account C) teams to discover assets in Account B.
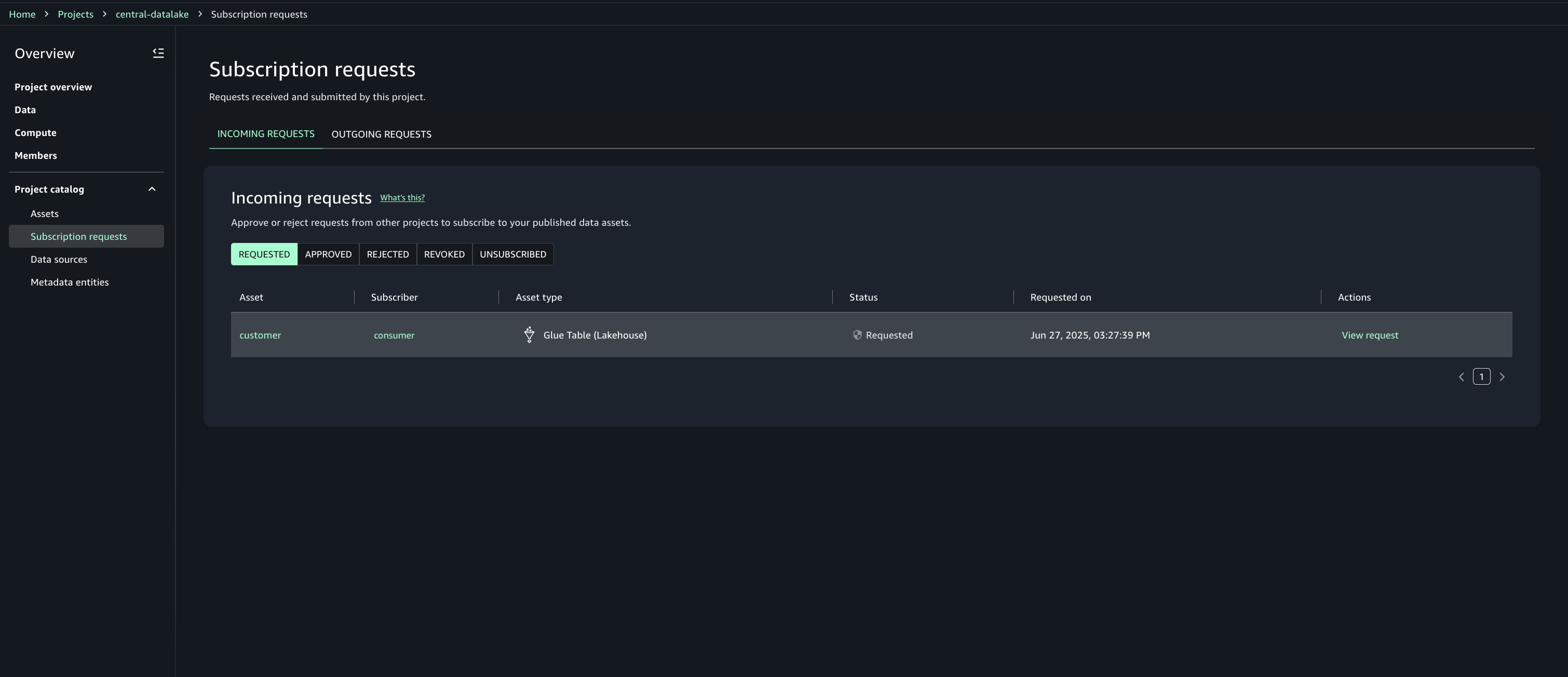
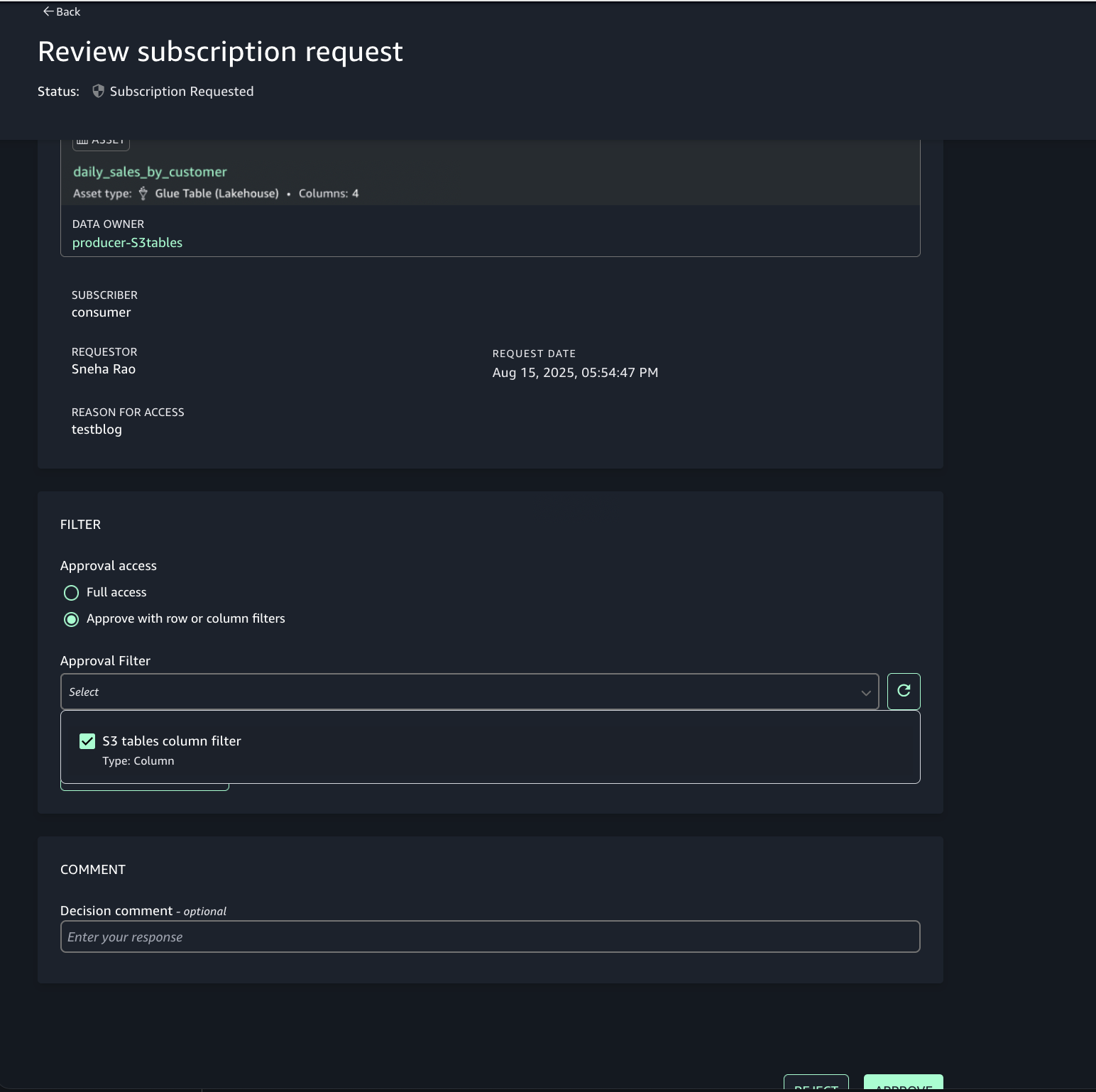
Approve or reject a subscription request
- In Account A, open the SageMaker Unified Studio portal.
- Under Project catalog, Subscription requests, Incoming requests tab locate and view the subscription request.

- Review the requester and justification.
- Choose the option to approve with row and column filters. For this post, we use the filter that we created earlier.

- Repeat step 6 to enable the consumer (Account C) teams to discover assets in Account B.
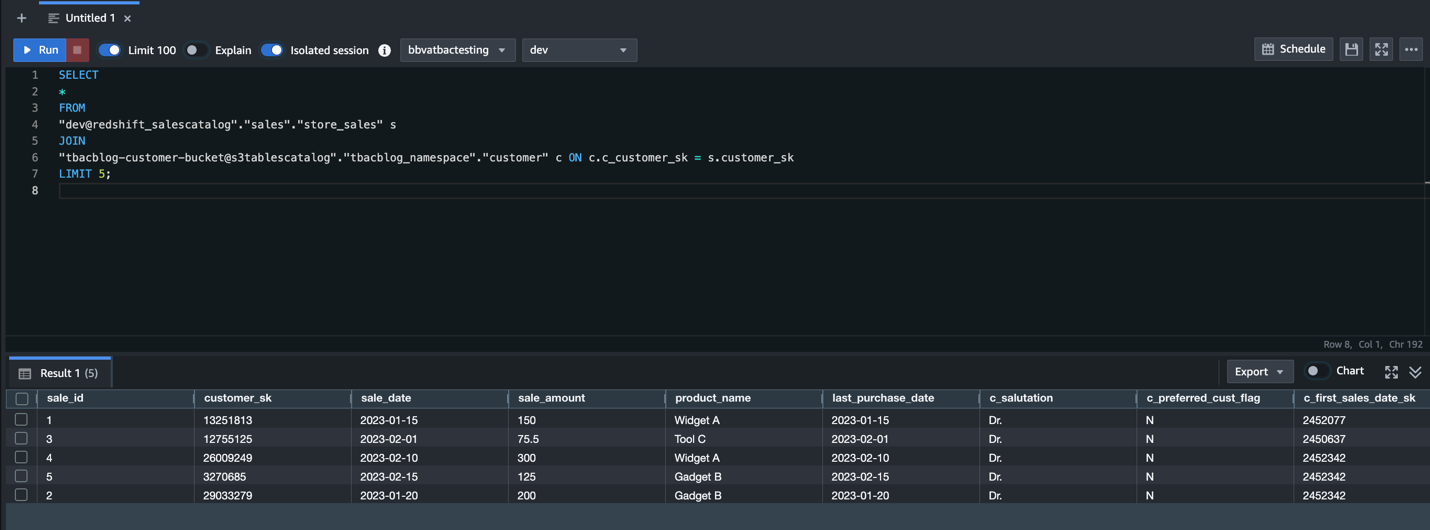
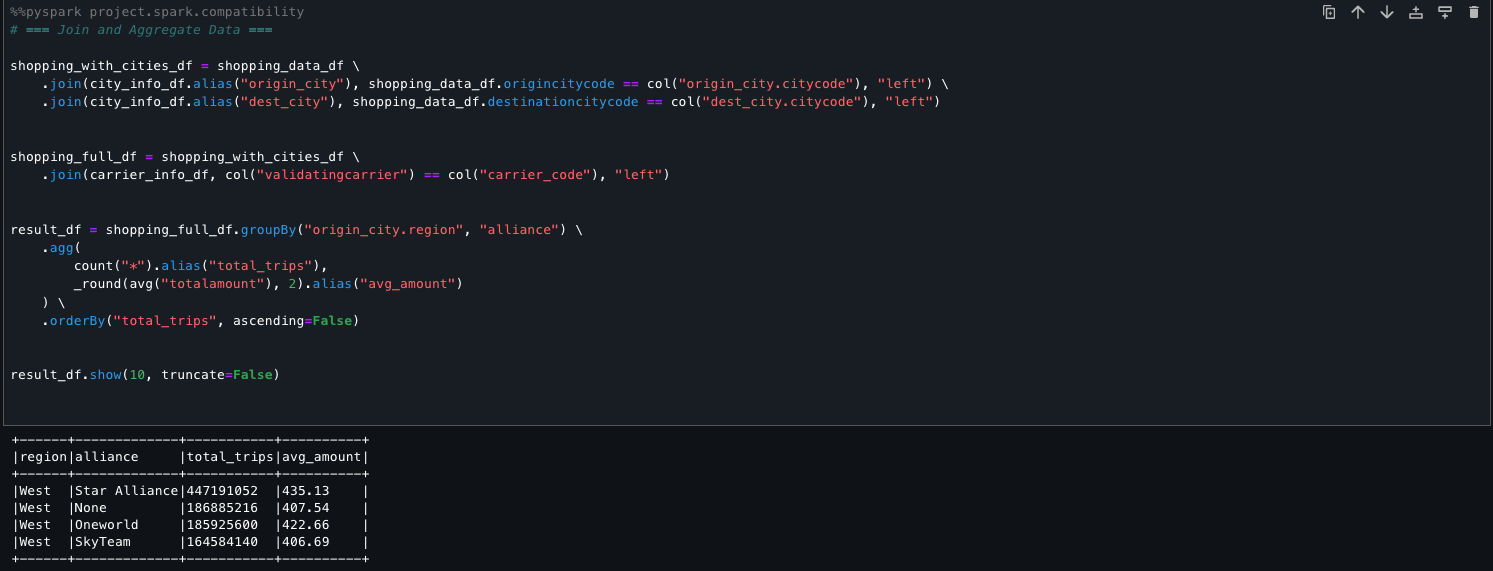
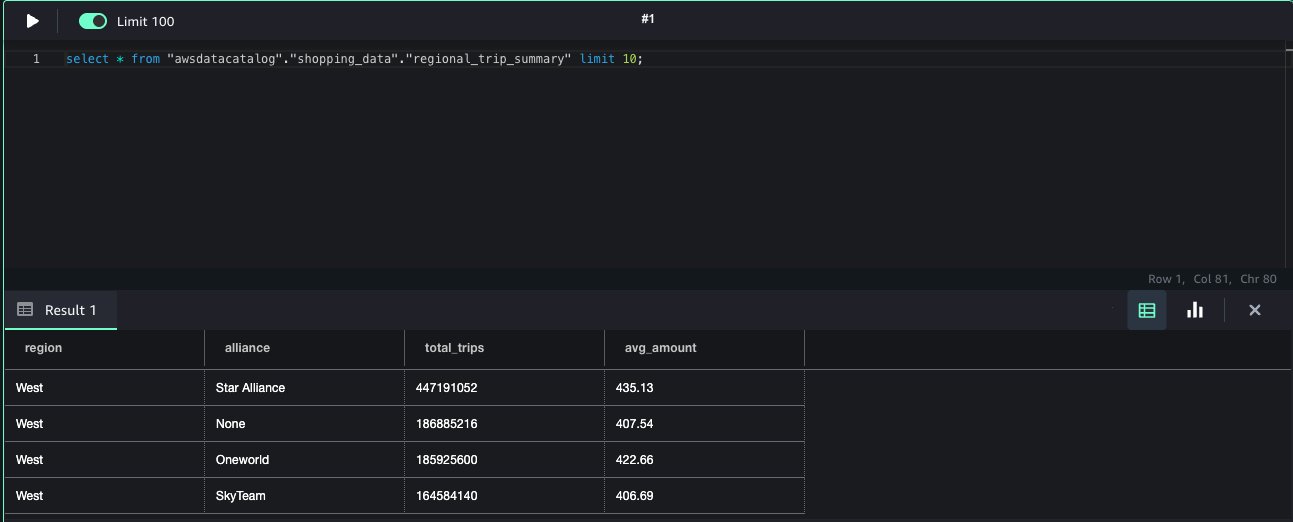
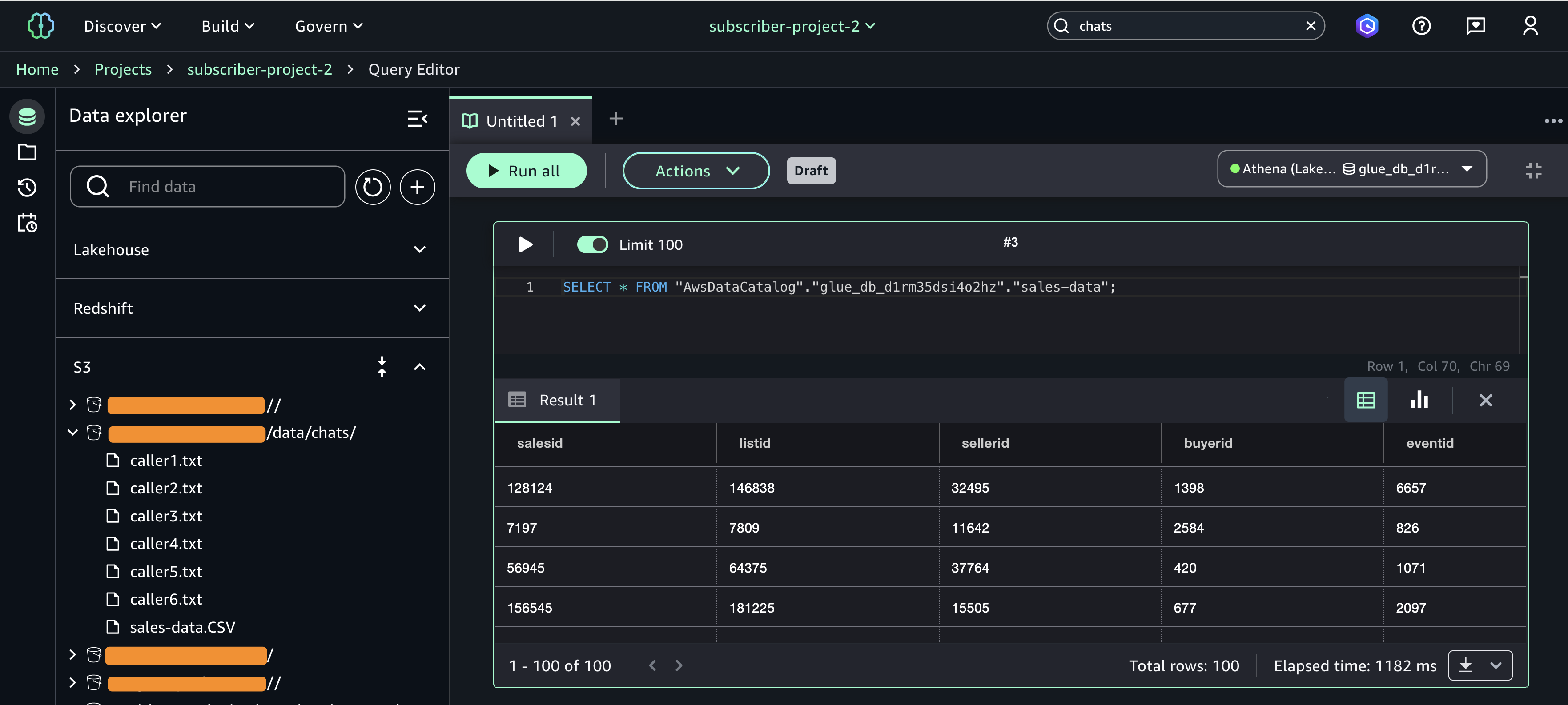
Step 7: Analyze S3 table and S3 data together in query editor
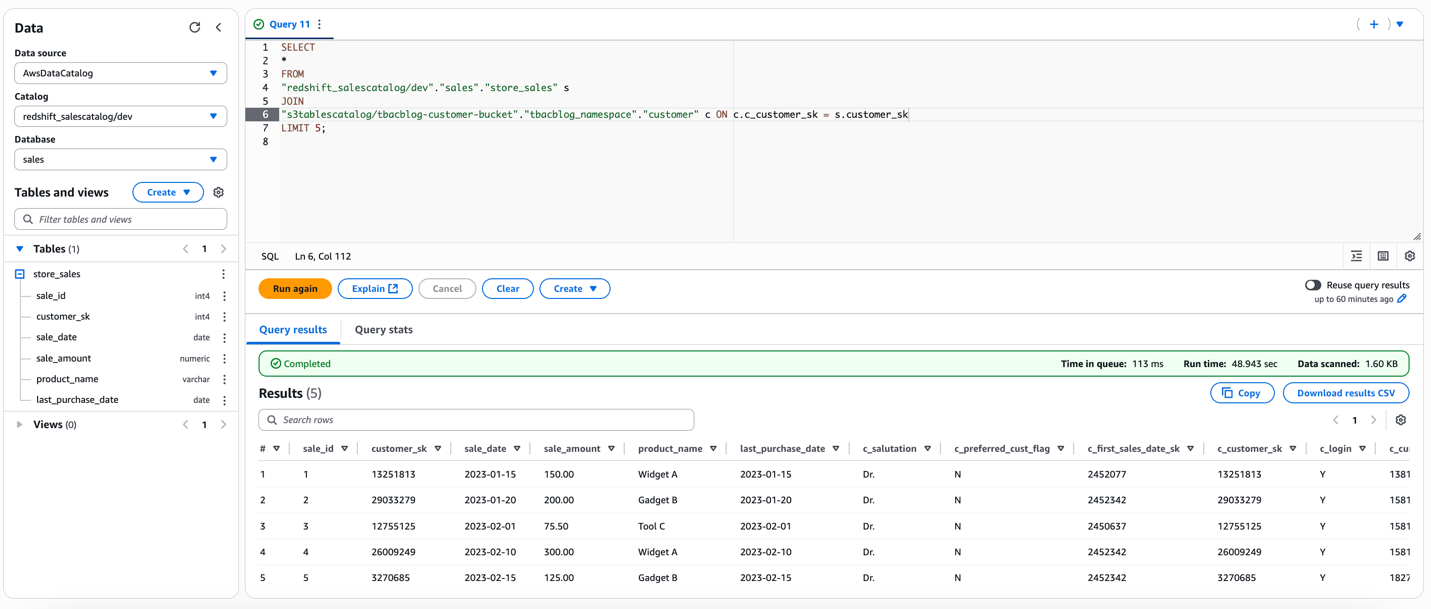
Account C (consumer) now has full access to the customer data in S3 from Account B, and the daily_sales_by_customer data in S3 tables from Account A with restricted columns. Both datasets contain a common column Customer_id.
To generate combined insights, assets from Account A and Account B can be queried and joined on Customer_id.
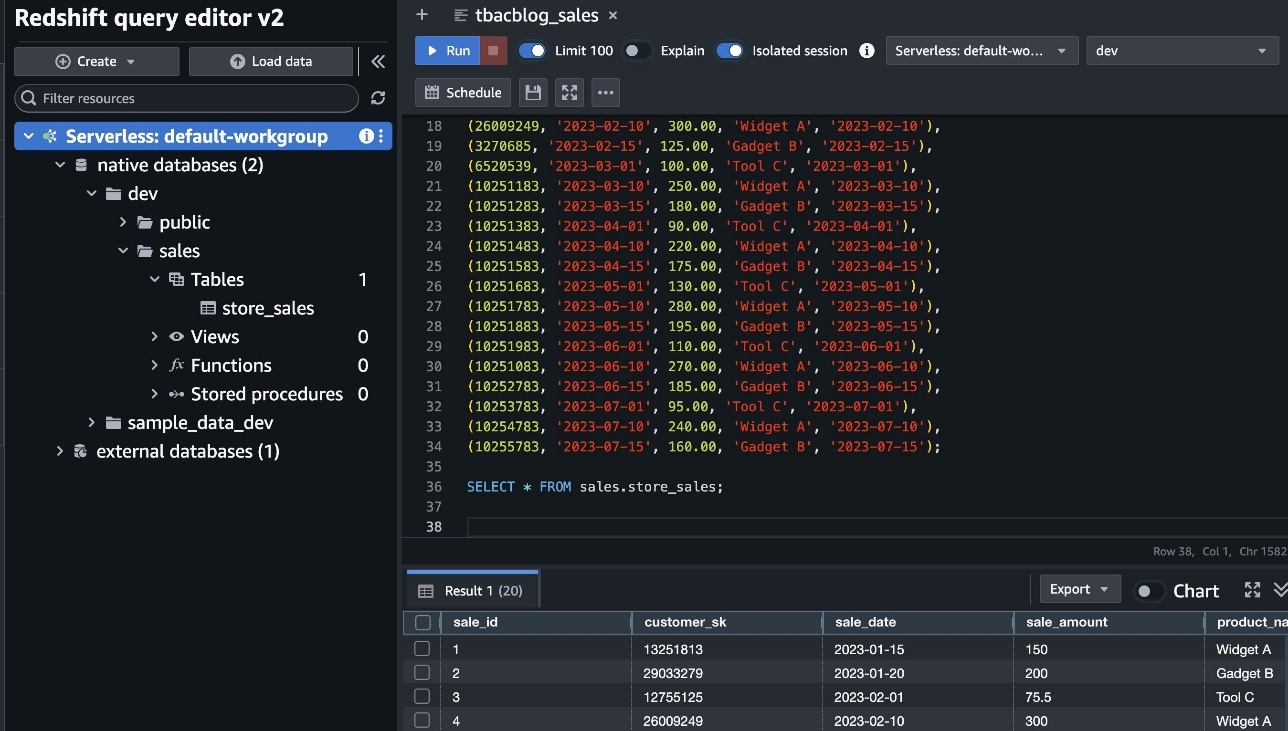
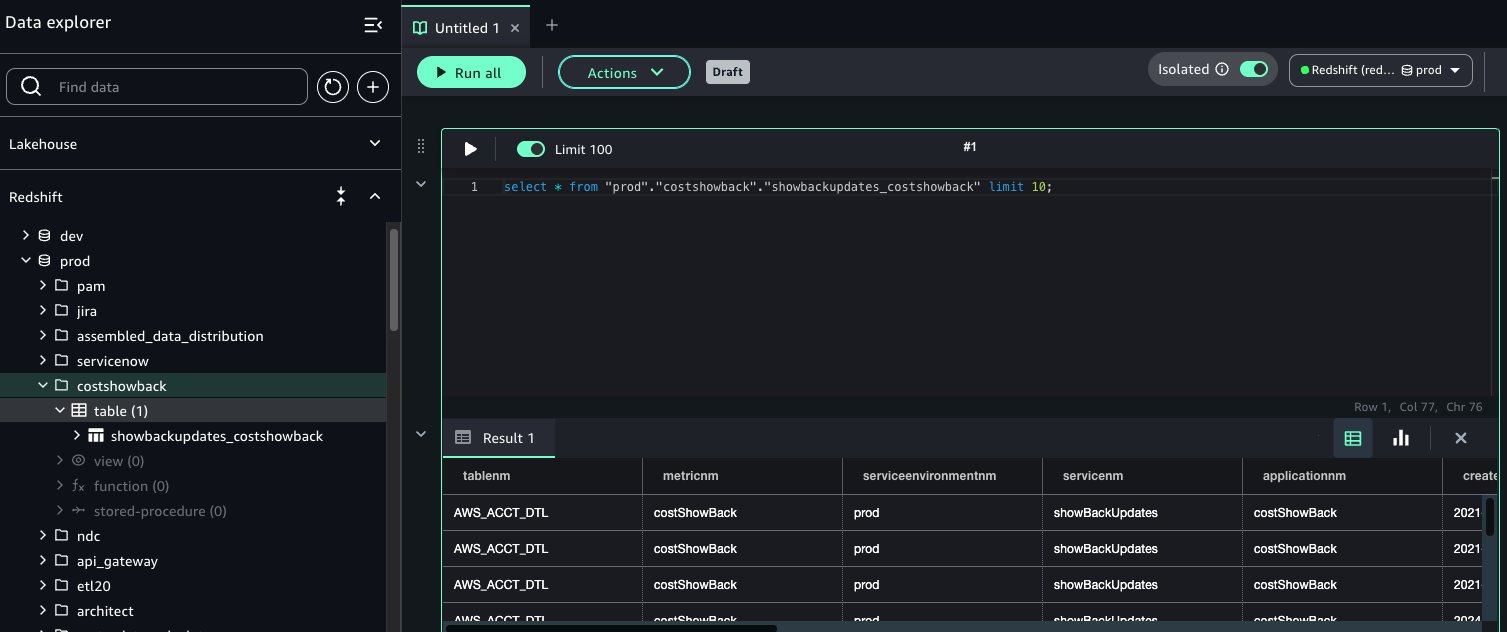
- In SageMaker Unified Studio (consumer project in Account C), go to the Build section and select Query Editor.

- Run the following SQL query to join the assets from Account B and Account A on the common column Customer_id, enabling unified cross-account analytics.

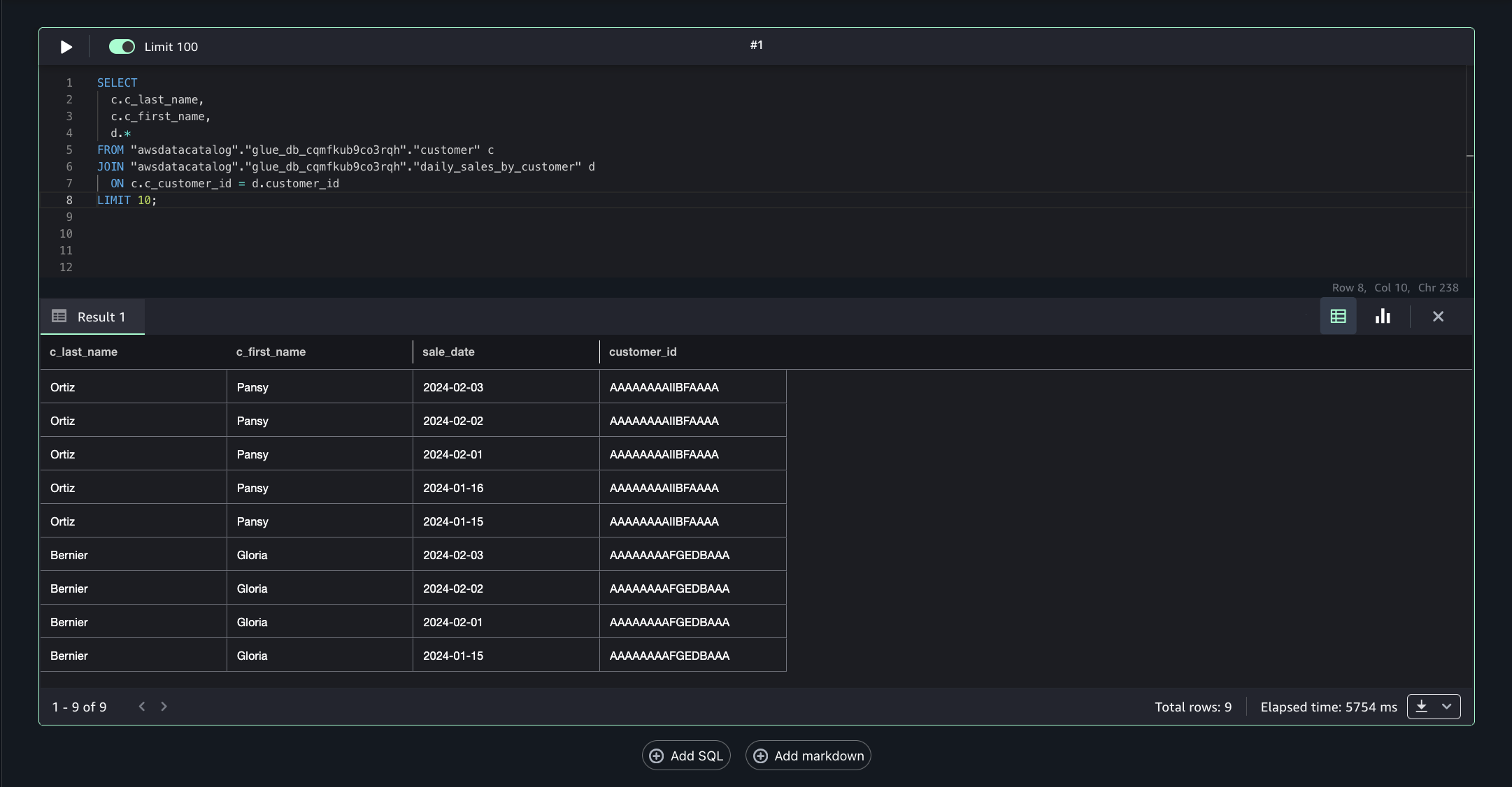
This approach allows combining filtered, governed data from multiple accounts into a single query for comprehensive insights.
Clean up
To avoid ongoing charges, clean up the resources created during this walkthrough. Complete these steps in the specified order to facilitate proper resource deletion. You might need to add respective delete permissions for databases, table buckets, and tables if your IAM user or role doesn’t already have them.
- Delete any created IAM roles or policies.
- Delete all the projects you created in the SageMaker Unified Studio domain.
- Delete the SageMaker Unified Studio domain you created.
Conclusion
In this post, we explored how Amazon SageMaker Catalog integrates with S3 Tables to provide comprehensive data governance in cross-account environments. We demonstrated how data publishers can onboard S3 Tables to SageMaker Lakehouse while data consumers can efficiently search, request access, and leverage approved datasets for analytics and AI development.
The integration between SageMaker Catalog, S3 Tables, and AWS AWS Lake Formation creates a unified governance framework that eliminates data silos while maintaining robust security controls. Through automated subscription workflows and fine-grained access permissions, organizations can implement self-service data access without compromising compliance or data quality.
 Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.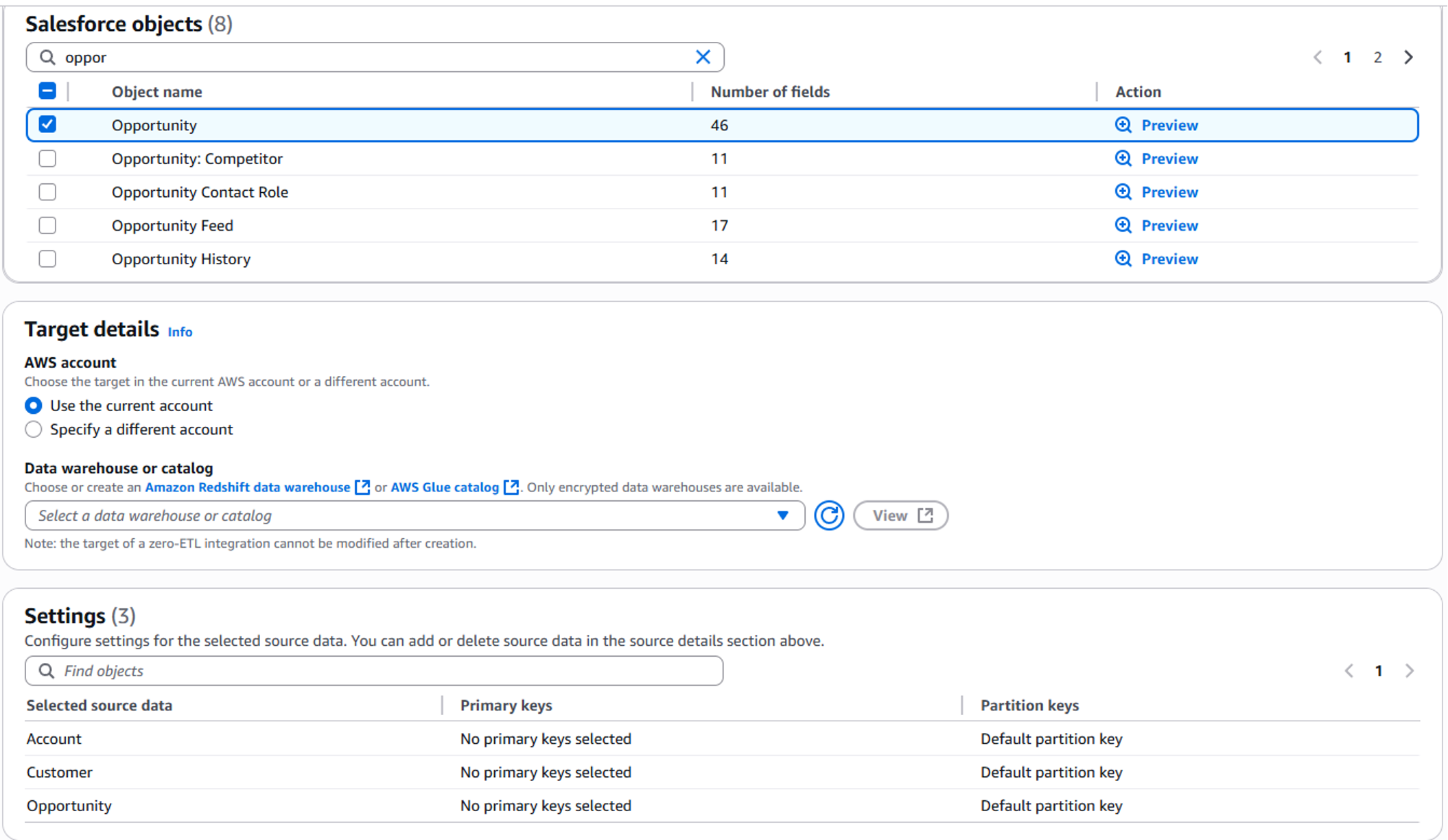
 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.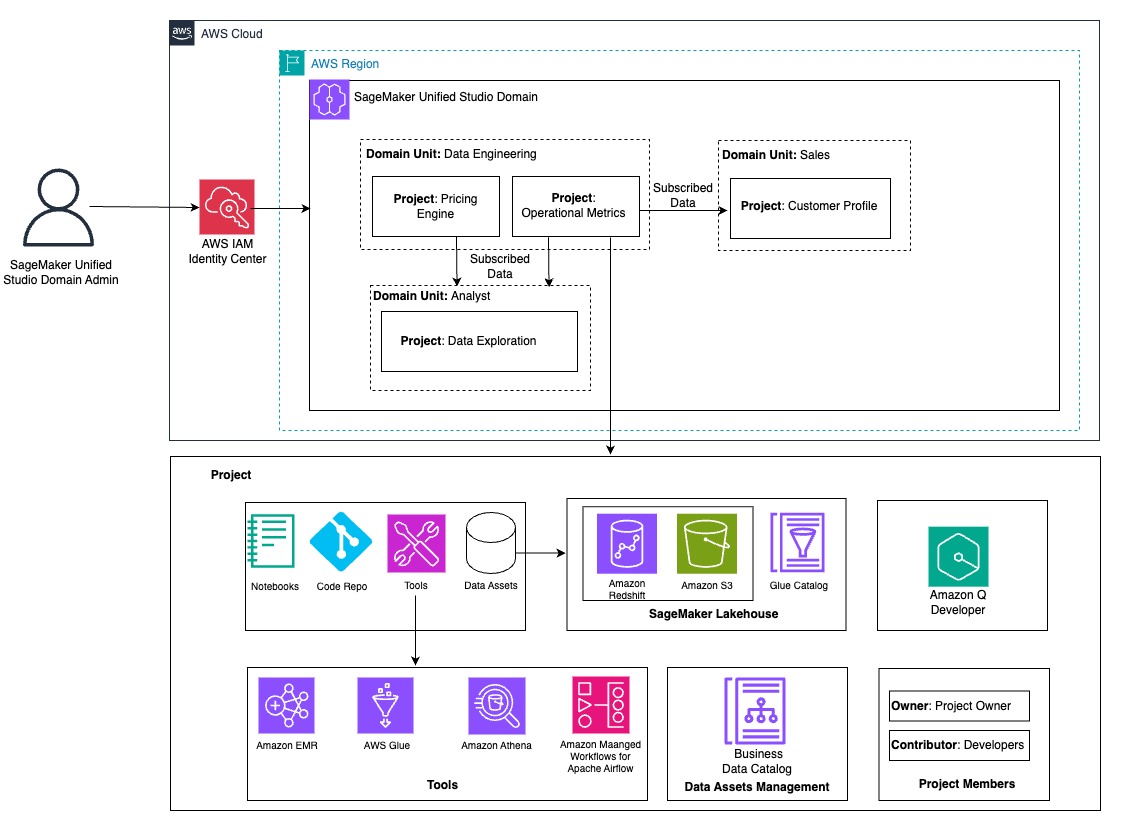

 Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS.
Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS. Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement. Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.
Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.


 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home. Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike. Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data. Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.
Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.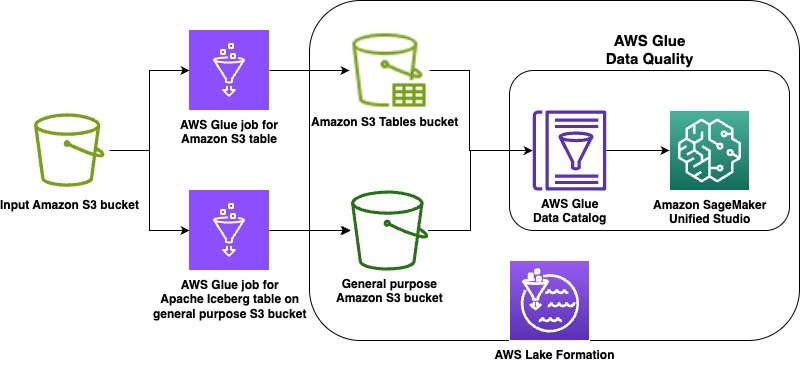

 Brody Pearman is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use AWS Glue ETL to transform and create their data lakes on AWS while maintaining high data quality. In his free time, he enjoys watching football with his friends and walking his dog.
Brody Pearman is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use AWS Glue ETL to transform and create their data lakes on AWS while maintaining high data quality. In his free time, he enjoys watching football with his friends and walking his dog. Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management.
Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management. Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets. Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse architecture, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse architecture, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.



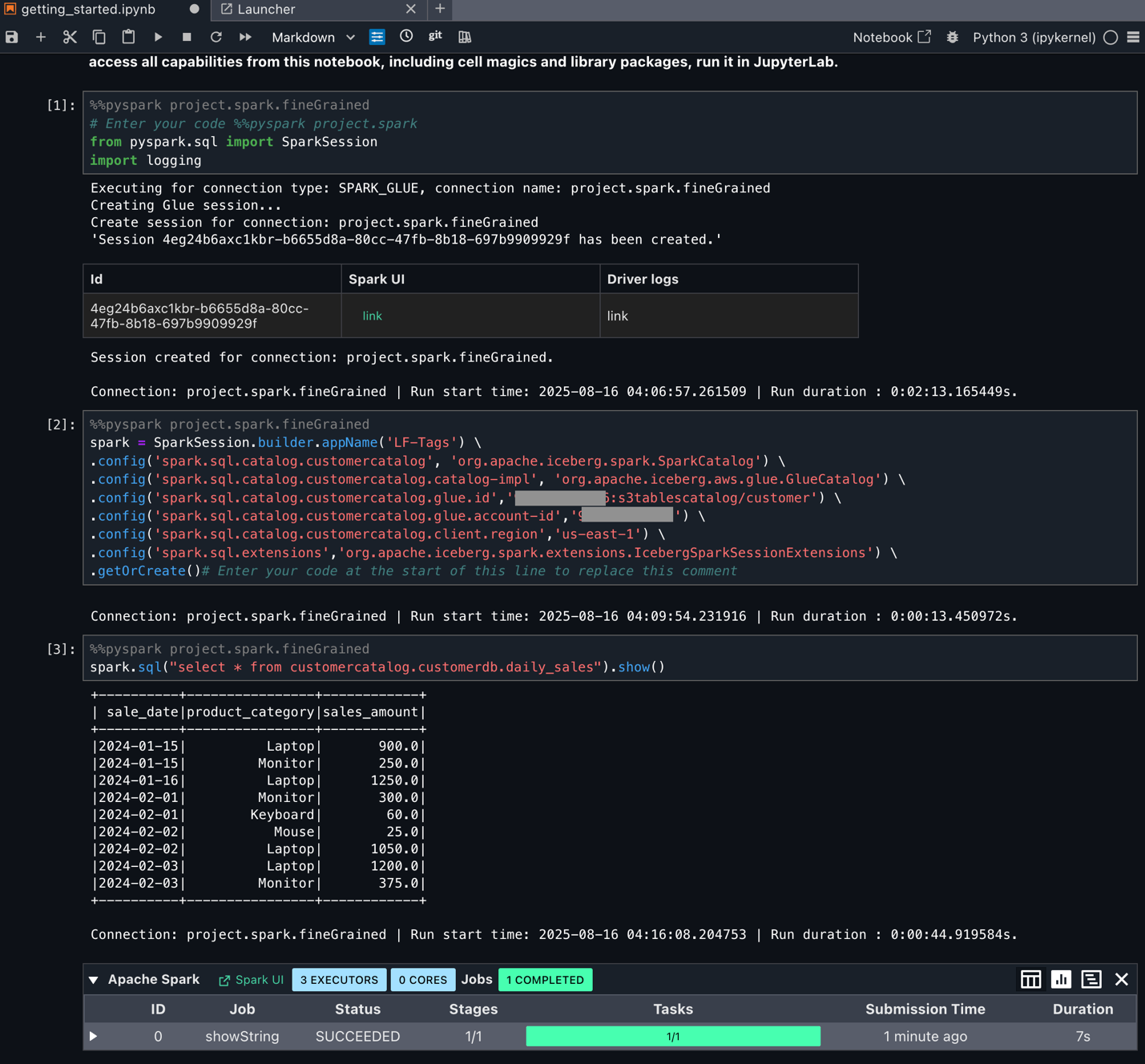
 The following screenshot shows an example of the Spark UI.
The following screenshot shows an example of the Spark UI.  The following screenshot shows an example of the driver logs.
The following screenshot shows an example of the driver logs.  The following screenshot shows the Executors tab, which provides access to the driver and executor logs.
The following screenshot shows the Executors tab, which provides access to the driver and executor logs. 



 In the following example, we run some TPC-DS SQL statements that are used for performance and benchmarks:
In the following example, we run some TPC-DS SQL statements that are used for performance and benchmarks:





 Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions. Abhilash is a senior specialist solutions architect at Amazon Web Services (AWS), helping public sector customers on their cloud journey with a focus on AWS Data and AI services. Outside of work, Abhilash enjoys learning new technologies, watching movies, and visiting new places.
Abhilash is a senior specialist solutions architect at Amazon Web Services (AWS), helping public sector customers on their cloud journey with a focus on AWS Data and AI services. Outside of work, Abhilash enjoys learning new technologies, watching movies, and visiting new places.

















 If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
 Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music. Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.
Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies. Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.
Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.













 This policy uses all the resources, which shouldn’t be used in production workload. To deploy this setup in production, restrict it to only specific zero-ETL integration resources by adding a
This policy uses all the resources, which shouldn’t be used in production workload. To deploy this setup in production, restrict it to only specific zero-ETL integration resources by adding a 

 The following code is an example of permissions for catalog settings:
The following code is an example of permissions for catalog settings:

































 Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga. Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with AWS. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life sciences, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with AWS. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life sciences, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Yadgiri Pottabhathini is a Senior Analytics Specialist Solutions Architect in the media and entertainment sector. He specializes in assisting enterprise customers with their data and analytics cloud transformation initiatives, while providing guidance on accelerating their Generative AI adoption through the development of data foundations and modern data strategies that leverage open-source frameworks and technologies.
Yadgiri Pottabhathini is a Senior Analytics Specialist Solutions Architect in the media and entertainment sector. He specializes in assisting enterprise customers with their data and analytics cloud transformation initiatives, while providing guidance on accelerating their Generative AI adoption through the development of data foundations and modern data strategies that leverage open-source frameworks and technologies. Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at AWS in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including Data Mesh, Data Lakehouse, and Generative AI, enabling customers to build scalable and innovative solutions on AWS.
Junpei Ozono is a Sr. Go-to-market (GTM) Data & AI solutions architect at AWS in Japan. He drives technical market creation for data and AI solutions while collaborating with global teams to develop scalable GTM motions. He guides organizations in designing and implementing innovative data-driven architectures powered by AWS services, helping customers accelerate their cloud transformation journey through modern data and AI solutions. His expertise spans across modern data architectures including Data Mesh, Data Lakehouse, and Generative AI, enabling customers to build scalable and innovative solutions on AWS.


















 Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Phaneendra Vuliyaragoli is a Product Management Lead for Amazon Data Firehose at AWS. In this role, Phaneendra leads the product and go-to-market strategy for Amazon Data Firehose.
Phaneendra Vuliyaragoli is a Product Management Lead for Amazon Data Firehose at AWS. In this role, Phaneendra leads the product and go-to-market strategy for Amazon Data Firehose. Maria Ho is a Product Marketing Manager for Streaming and Messaging services at AWS. She works with services including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon MQ, Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS).
Maria Ho is a Product Marketing Manager for Streaming and Messaging services at AWS. She works with services including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon MQ, Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS).
























 Stefano Sandonà is a Senior Big Data Specialist Solution Architect at Amazon Web Services (AWS). Passionate about data, distributed systems, and security, he helps customers worldwide architect high-performance, efficient, and secure data solutions.
Stefano Sandonà is a Senior Big Data Specialist Solution Architect at Amazon Web Services (AWS). Passionate about data, distributed systems, and security, he helps customers worldwide architect high-performance, efficient, and secure data solutions. Derek Liu is a Senior Solutions Architect based out of Vancouver, BC. He enjoys helping customers solve big data challenges through Amazon Web Services (AWS) analytic services.
Derek Liu is a Senior Solutions Architect based out of Vancouver, BC. He enjoys helping customers solve big data challenges through Amazon Web Services (AWS) analytic services. Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services (AWS). He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services (AWS). He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to data analytics and AI in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to data analytics and AI in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.






















 Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters. Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on  Harsh Singh is a Software Dev. Engineer at AWS based in the Bay Area. He currently works with the Amazon DataZone team, enhancing security for Amazon DataZone and SageMaker Unified Studio while developing features that help customers achieve their data, analytics, and AI goals faster. With a background in building ML and analytics systems at scale, Harsh enjoys solving complex problems in data engineering, AI/ML, and security. Outside of work, he can be found hiking the west coast trails and exploring new cuisines.
Harsh Singh is a Software Dev. Engineer at AWS based in the Bay Area. He currently works with the Amazon DataZone team, enhancing security for Amazon DataZone and SageMaker Unified Studio while developing features that help customers achieve their data, analytics, and AI goals faster. With a background in building ML and analytics systems at scale, Harsh enjoys solving complex problems in data engineering, AI/ML, and security. Outside of work, he can be found hiking the west coast trails and exploring new cuisines.












































































 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. She can be reached via
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. She can be reached via  Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is also the author of the book
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is also the author of the book  Sakti Mishra is a Principal Data and AI Solutions Architect at AWS, where he helps customers modernize their data architecture and define end-to end-data strategies, including data security, accessibility, governance, and more. He is also the author of
Sakti Mishra is a Principal Data and AI Solutions Architect at AWS, where he helps customers modernize their data architecture and define end-to end-data strategies, including data security, accessibility, governance, and more. He is also the author of  Daiyan Alamgir is a Principal Frontend Engineer on the Amazon SageMaker Unified Studio team based in New York.
Daiyan Alamgir is a Principal Frontend Engineer on the Amazon SageMaker Unified Studio team based in New York. Vipin Mohan is a Principal Product Manager at AWS, leading the launch of generative AI capabilities in Amazon SageMaker Unified Studio. He is committed to shaping impactful products by working backward from customer insights, championing user-focused solutions, and delivering scalable results.
Vipin Mohan is a Principal Product Manager at AWS, leading the launch of generative AI capabilities in Amazon SageMaker Unified Studio. He is committed to shaping impactful products by working backward from customer insights, championing user-focused solutions, and delivering scalable results. Chanu Damarla is a Principal Product Manager on the Amazon SageMaker Unified Studio team. He works with customers around the globe to translate business and technical requirements into products that delight customers and enable them to be more productive with their data, analytics, and AI.
Chanu Damarla is a Principal Product Manager on the Amazon SageMaker Unified Studio team. He works with customers around the globe to translate business and technical requirements into products that delight customers and enable them to be more productive with their data, analytics, and AI.


























 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.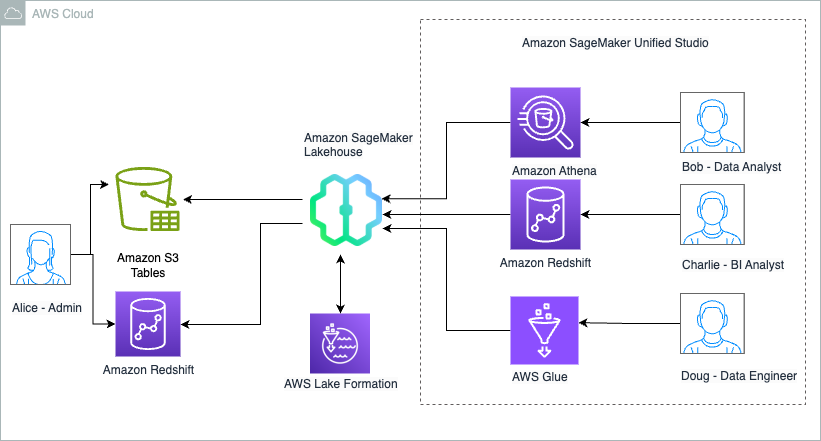










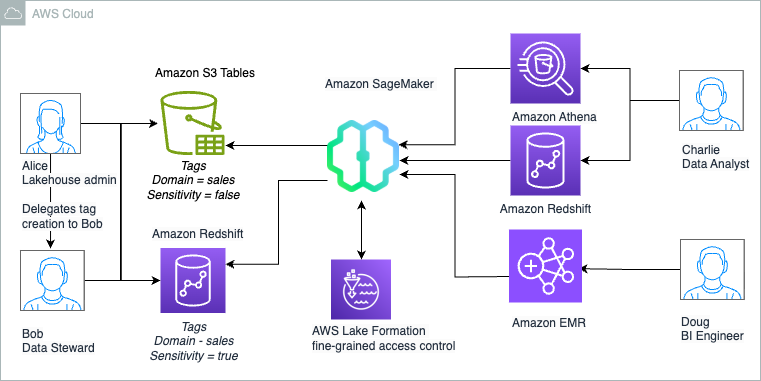
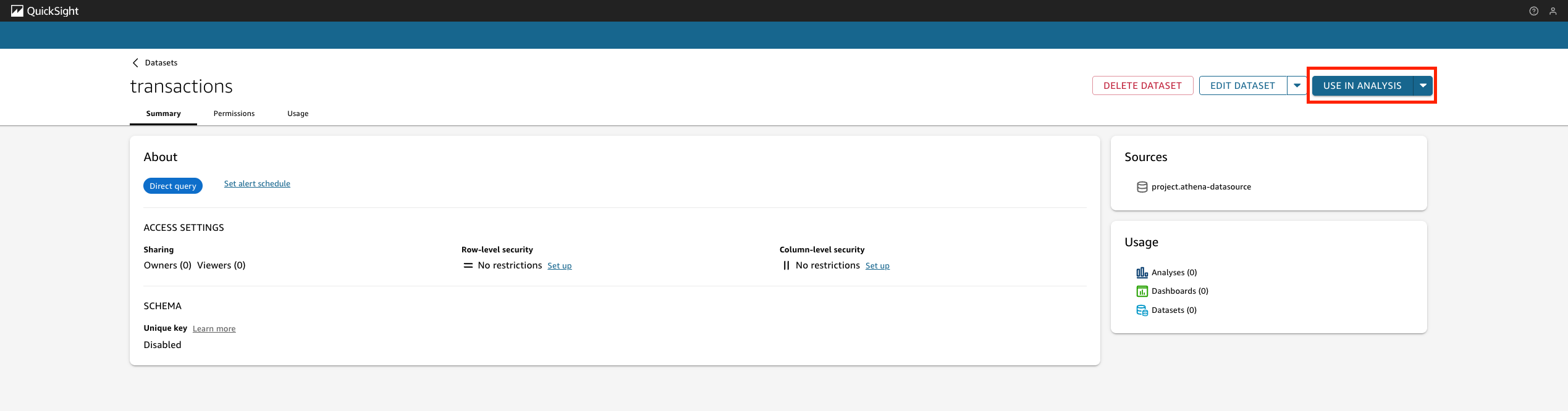
 Charlie can now further update the SQL query and use it to power QuickSight dashboards that can be shared with Sales team members.
Charlie can now further update the SQL query and use it to power QuickSight dashboards that can be shared with Sales team members.
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.