Post Syndicated from Pop Chunhapanya original https://blog.cloudflare.com/ipfs-measurements/


We have been operating an IPFS gateway for the last four years. It started as a research experiment in 2018, providing end-to-end integrity with IPFS. A year later, we made IPFS content faster to fetch. Last year, we announced we were committed to making IPFS gateway part of our product offering. Through this process, we needed to inform our design decisions to know how our setup performed.
To this end, we’ve developed the IPFS Gateway monitor, an observability tool that runs various IPFS scenarios on a given gateway endpoint. In this post, you’ll learn how we use this tool and go over discoveries we made along the way.
Refresher on IPFS
IPFS is a distributed system for storing and accessing files, websites, applications, and data. It’s different from a traditional centralized file system in that IPFS is completely distributed. Any participant can join and leave at any time without the loss of overall performance.
However, in order to access any file in IPFS, users cannot just use web browsers. They need to run an IPFS node to access the file from IPFS using its own protocol. IPFS Gateways play the role of enabling users to do this using only web browsers.
Cloudflare provides an IPFS gateway at https://cloudflare-ipfs.com, so anyone can just access IPFS files by using the gateway URL in their browsers.
As IPFS and the Cloudflare IPFS Gateway have become more and more popular, we need a way to know how performant it is: how much time it takes to retrieve IPFS-hosted content and how reliable it is. However, IPFS gateways are not like normal websites which only receive HTTP requests and return HTTP responses. The gateways need to run IPFS nodes internally and sometimes do content routing and peer routing to find the nodes which provide IPFS contents. They sometimes also need to resolve IPNS names to discover the contents. So, in order to measure the performance, we need to do measurements many times for many scenarios.
Enter the IPFS Gateway monitor
IPFS Gateway monitor is this tool. It allows anyone to check the performance of their gateway and export it to the Prometheus monitoring system.
This monitor is composed of three independent binaries:
- ipfs-gw-measure is the tool that calls the gateway URL and does the measurement scenarios.
- ipfs-gw-monitor is a way to call the measurement tool multiple times.
- Prometheus Exporter exposes prometheus-readable metrics.
To interact with the IPFS network, the codebase also provides a way to start an IPFS node.
A scenario is a set of instructions a user performs given the state of our IPFS system. For instance, we want to know how fast newly uploaded content can be found by the gateway, or if popular content has a low query time. We’ll discuss more of this in the next section.
Putting this together, the system is the following.
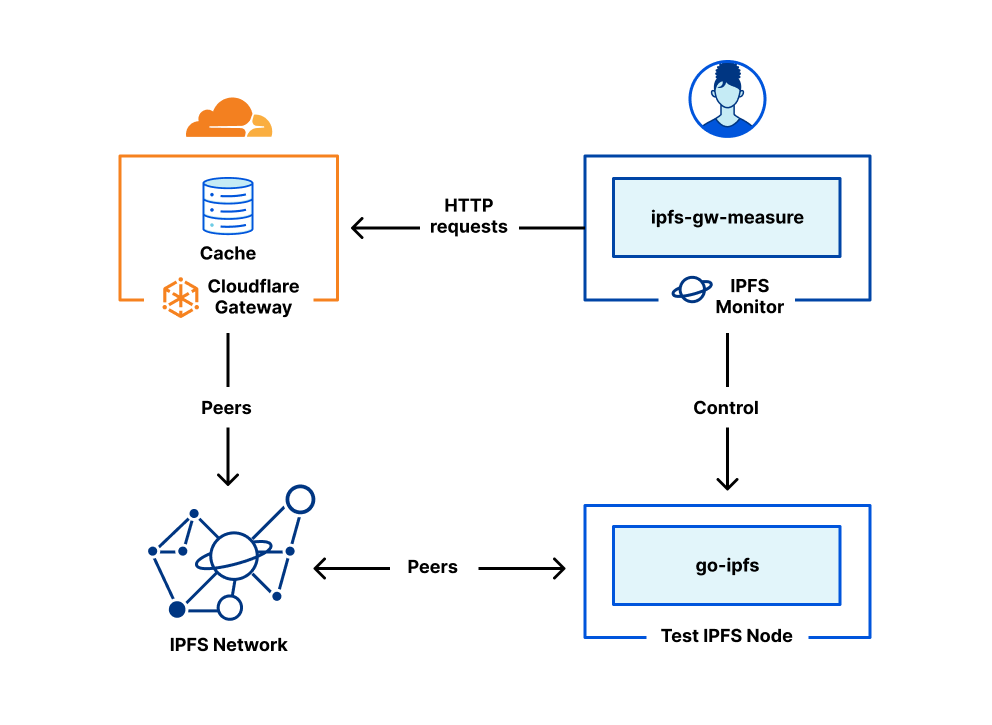
During this experience, we have operated both the IPFS Monitor, and a test IPFS node. The IPFS node allows the monitor to provide content to the IPFS network. This allows us to be sure that the content provided is fresh, and actually hosted. Peers have not been fixed, and leverage the IPFS default peer discovery mechanism.
Cloudflare IPFS Gateway is treated as an opaque system. The monitor performs end-to-end tests by contacting the gateway via its public API, either https://cloudflare-ipfs.com or via a custom domain registered with the gateway.
The following scenarios have been run on consumer hardware in March. They are not representative of all IPFS users. All values provided below have been sourced against Cloudflare’s IPFS gateway endpoint.
First scenarios: Gateway to serve immutable IPFS contents
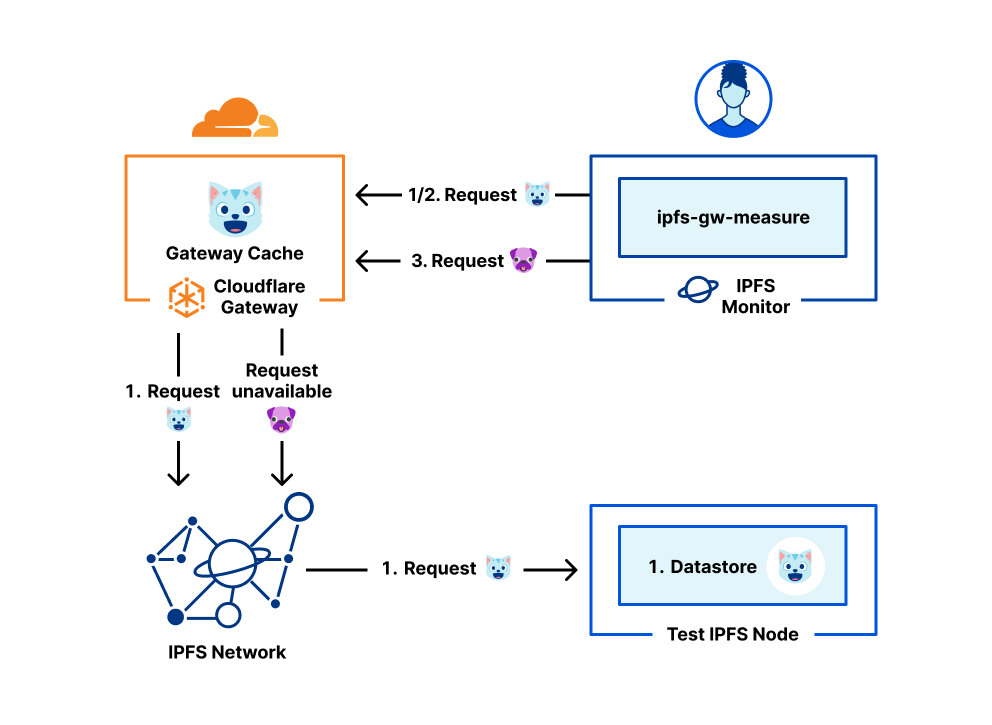
IPFS contents are the most primitive contents being served by the IPFS network and IPFS gateways. By their nature, they are immutable and addressable only by the hash of the content. Users can access the IPFS contents by putting the Content IDentifier (CID) in the URL path of the gateway. For example, ipfs://bafybeig7hluox6xefqdgmwcntvsguxcziw2oeogg2fbvygex2aj6qcfo64. We measure three common scenarios that users will often encounter.
The first one is when users fetch popular content which has a high probability of being found in our cache already. During our experiment, we measured a response time for such content is around 116ms.
The second one is the case where the users create and upload the content to the IPFS network, such as via the integration between Cloudflare Pages and IPFS (LINK TO BLOG). This scenario is a lot slower than the first because the content is not in our cache yet, and it takes some time to discover the content. The content that we upload during this measurement is a random piece of 32-byte content.
The last measurement is when users try to download content that does not exist. This one is the slowest. Because of the nature of content routing of IPFS, there is no indication that tells us that content doesn’t exist. So, setting the timeout is the only way to tell if the content exists or not. Currently, the Cloudflare IPFS gateway has a timeout of around five minutes.
| Scenarios | Min (s) | Max (s) | Avg (s) | |
|---|---|---|---|---|
| 1 | ipfs/newly-created-content | 0.276 | 343 | 44.4 |
| 2 | ipfs/in-cache-content | 0.0825 | 0.539 | 0.116 |
| 3 | ipfs/unavailable-cid | 90 | 341 | 279 |
Second scenarios: Gateway to serve mutable IPNS named contents
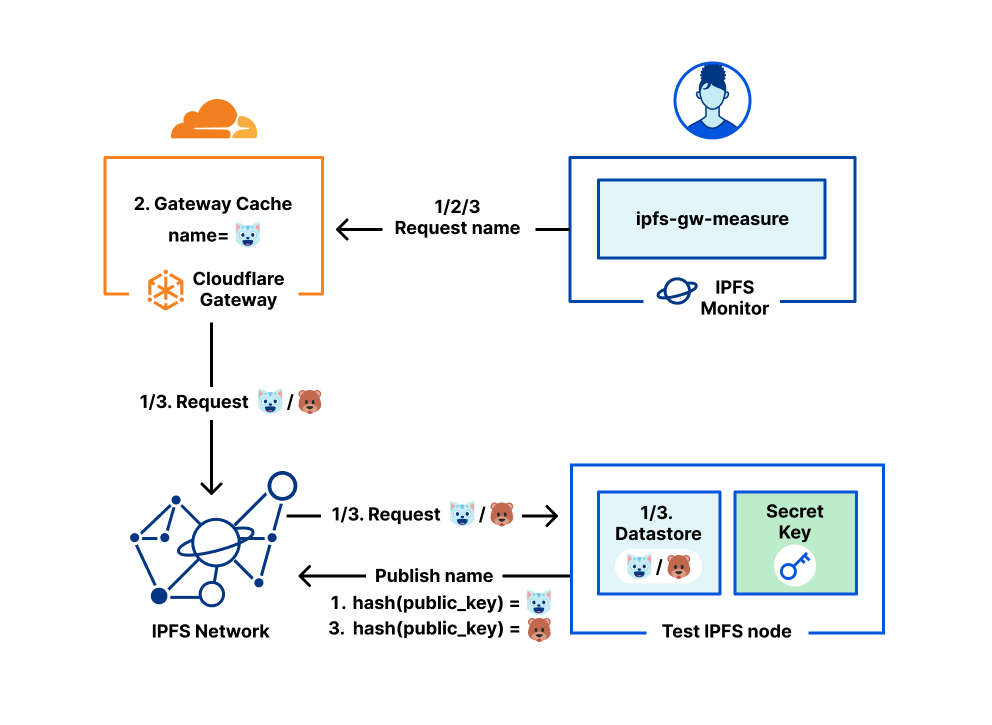
Since IPFS contents are immutable, when users want to change the content, the only way to do so is to create new content and distribute the new CID to other users. Sometimes distributing the new CID is hard, and is out of scope of IPFS. The InterPlanetary Naming System (IPNS) tries to solve this. IPNS is a naming system that — instead of locating the content using the CID — allows users to locate the content using the IPNS name instead. This name is a hash of a user’s public key. Internally, IPNS maintains a section of the IPFS DHT which maps from a name to a CID. Therefore, when the users want to download the contents using names through the gateway, the gateway has to first resolve the name to get the CID, then use the CID to query the IPFS content as usual.
The example for fetching the IPNS named content is at ipns://k51qzi5uqu5diu2krtwp4jbt9u824cid3a4gbdybhgoekmcz4zhd5ivntan5ey
We measured many scenarios for IPNS as shown in the table below. Three scenarios are similar to the ones involving IPFS contents. There are two more scenarios added: the first one is measuring the response time when users query the gateway using an existing IPNS name, and the second one is measuring the response time when users query the gateway immediately after new content is published under the name.
| Scenarios | Min (s) | Max (s) | Avg (s) | |
|---|---|---|---|---|
| 1 | ipns/newly-created-name | 5.50 | 110 | 33.7 |
| 2 | ipns/existing-name | 7.19 | 113 | 28.0 |
| 3 | ipns/republished-name | 5.62 | 80.4 | 43.8 |
| 4 | ipns/in-cache-content | 0.0353 | 0.0886 | 0.0503 |
| 5 | ipns/unavailable-name | 60.0 | 146 | 81.0 |
Third scenarios: Gateway to serve DNSLink websites
Even though users can use IPNS to provide others a stable address to fetch the content, the address can still be hard to remember. This is what DNSLink is for. Users can address their content using DNSLink, which is just a normal domain name in the Domain Name System (DNS). As a domain owner, you only have to create a TXT record with the value dnslink=/ipfs/baf…1, and your domain can be fetched from a gateway.
There are two ways to access the DNSLink websites using the gateway. The first way is to access the website using the domain name as a URL hostname, for example, https://ipfs.example.com. The second way is to put the domain name as a URL path, for example, https://cloudflare-ipfs.com/ipns/ipfs.example.com.
| Scenarios | Min (s) | Max (s) | Avg (s) | |
|---|---|---|---|---|
| 1 | dnslink/ipfs-domain-as-url-hostname | 0.251 | 18.6 | 0.831 |
| 2 | dnslink/ipfs-domain-as-url-path | 0.148 | 1.70 | 0.346 |
| 3 | dnslink/ipns-domain-as-url-hostname | 7.87 | 44.2 | 21.0 |
| 4 | dnslink/ipns-domain-as-url-path | 6.87 | 72.6 | 19.0 |
What does this mean for regular IPFS users?
These measurements highlight that IPFS content is fetched best when cached. This is an order of magnitude faster than fetching new content. This result is expected as content publication on IPFS can take time for nodes to retrieve, as highlighted in previous studies. Then, when it comes to naming IPFS resources, leveraging DNSLink appears to be the faster strategy. This is likely due to the poor connection of the IPFS node used in this setup, preventing IPNS name from propagating rapidly. Overall, IPNS names would benefit from using a resolver to speed up resolution without losing the trust they provide.
As we mentioned in September, IPFS use has seen important growth. So has our tooling. The IPFS Gateway monitor can be found on GitHub, and we will keep looking at improving this first set of metrics.
At the time of writing, using IPFS via a gateway seems to provide lower retrieval times, while allowing for finer grain control over security settings in the browser context. This configuration preserves the content validity properties offered by IPFS, but reduces the number of nodes a user is peering with to one: the gateway. Ideally, we would like users to peer with Cloudflare because we’re offering the best service, while still having the possibility to retrieve content from external sources if they want to. We’ll be conducting more measurements to better understand how to best leverage Cloudflare presence in 270 cities to better serve the IPFS network.