Post Syndicated from Dawn Parzych original https://blog.cloudflare.com/platform-week-2022-wrap-up/


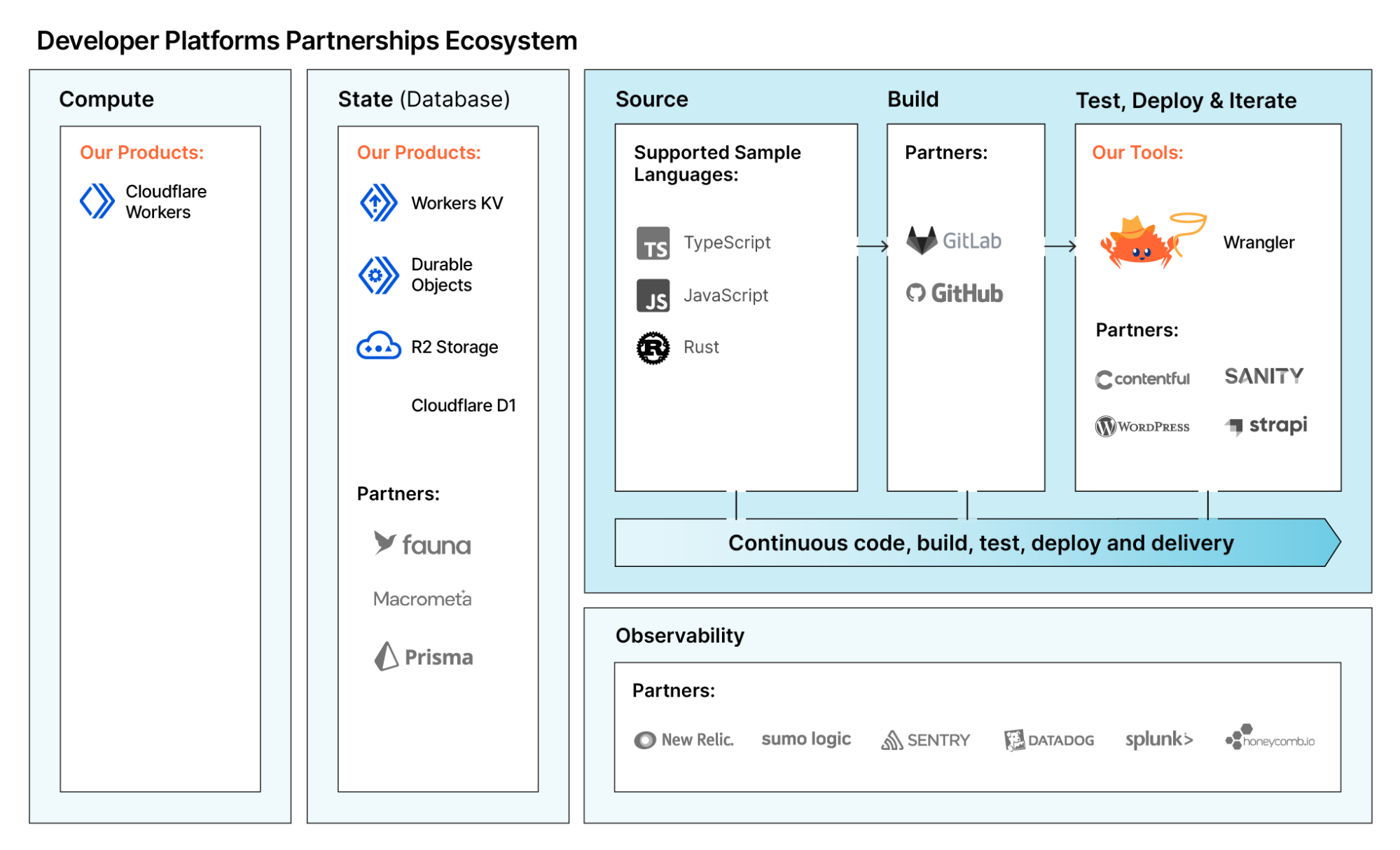
A comprehensive developer platform includes all the necessary storage, compute, and services to effectively deliver an application. Compute that runs globally and auto-scales to execute code without having to worry about the underlying infrastructure; storage for user information, objects, and key-value pairs; and all the related services including delivering video, optimizing images, managing third-party components, and capturing telemetry.
Whether you’re looking to modernize legacy backend infrastructure or are building a brand-new application from the ground up the Cloudflare Developer Platform provides all the building blocks you need to deliver an application on the edge.
Recently, during Platform Week, we made a number of announcements expanding what’s possible with the Developer Platform. Let’s take a look at some of the announcements we made and what this enables you to build. For a complete list visit the Platform Week hub.
Compute
The core of our compute offering is Workers, our serverless runtime. Workers integrates with other Cloudflare offerings helping you route requests, take action on bots, send an email, or route and filter emails, just to name a few.
There are times when you’ll want to use multiple Workers to perform an action, Workers now have the ability to call another Worker. And while that Worker is sitting idly you aren’t charged. If serverless computing is about paying for what you use, why should you be charged when a Worker is waiting for a response?
Serverless compute works great for an application that’s in production, but what about when you’re in development? You need the ability to run and test locally, that’s why we’ve announced that the Workers runtime will be available via an open-source license later this year.
But it’s not just the flexibility to run locally that’s important, the worry of vendor lock-in is real. You need the ability to move your application without significant efforts, that’s where the WinterCG comes in. Cloudflare is working with core contributors from Deno and Node.js to create server-side API standards to enable just this.
Storage
Applications, of course, cannot exist without storage. And when it comes to storage, there is no one-size-fits-all solution: object storage is great for images, but maybe not for storing user information; meanwhile, databases are great for storing user information, but not videos, and even when it comes to databases, there are so many kinds. Developers need a variety of storage solutions, there’s no one-size-fits all storage offering.
As of Platform Week we expanded our storage products, to include R2 (which is now in beta), and D1 SQLite database. These are in addition to the existing products, such as Workers KV, Durable Objects, and even Cloudflare’s cache!
You have the flexibility to choose the right tool for the task. Part of being flexible means, not encountering egress charges to access or move your data, and you should always have the ability to integrate with whichever tool you want.
Developer Services
The Developer Platform doesn’t end with the compute power and storage. It also includes a full range of services to build your Jamstack application, optimize the images you serve, and stream videos.
Pages simplifies the build and deploy process for Jamstack applications. Too much time is spent waiting. Waiting for builds to compile, when only a few lines of code were changed only to find out there was an error. Pages now reduces your waiting time with a new build infrastructure, and the ability to view logs as a build is in progress to immediately see if something has gone wrong. (And speaking of logs, did you know you can store your logs on R2?)
To get started with Pages, you can either use our Git-integrations or deploy pre-built assets directly. Functionality on your static sites can be extended via Workers or the new Pages Plugins.
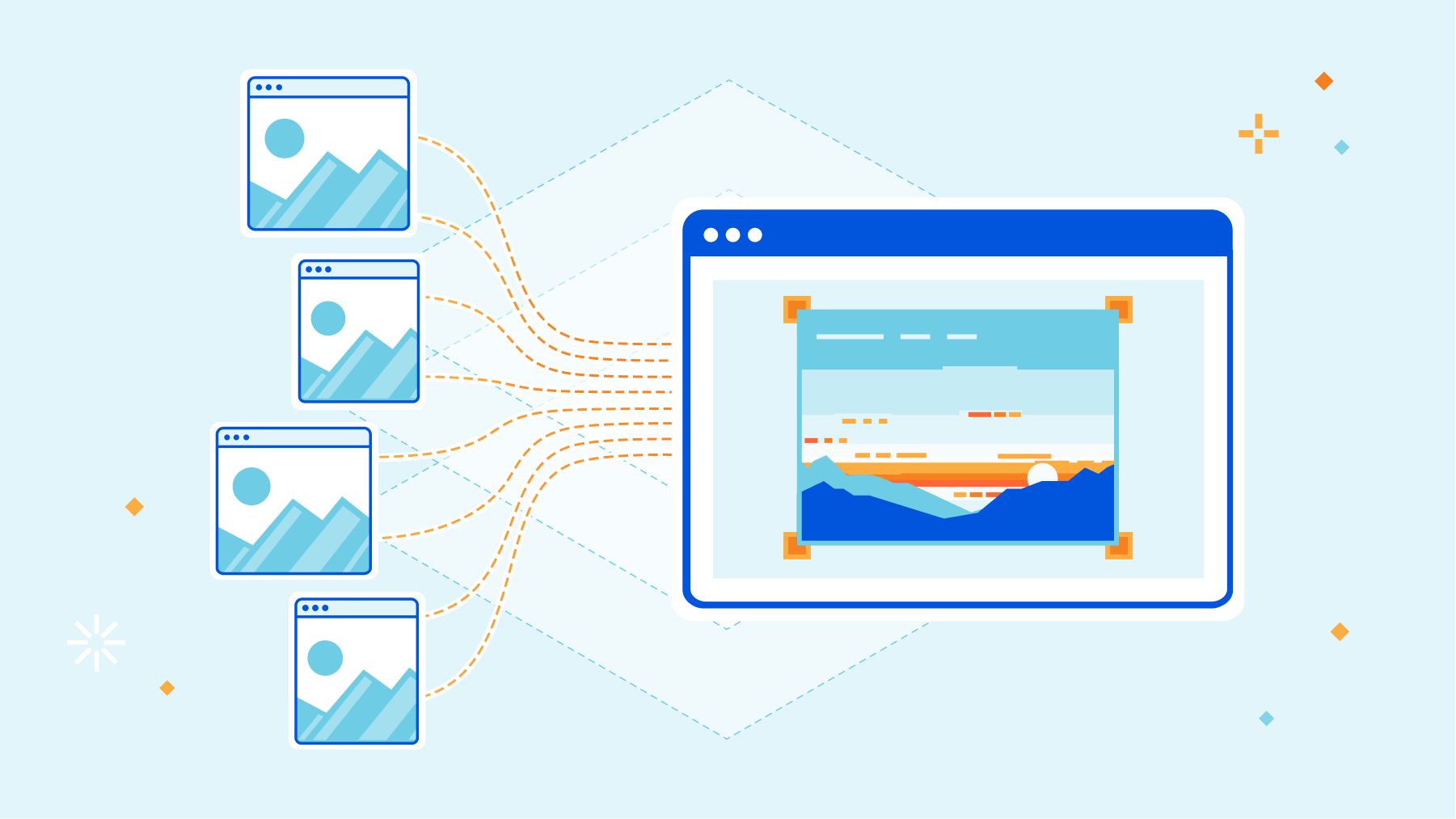
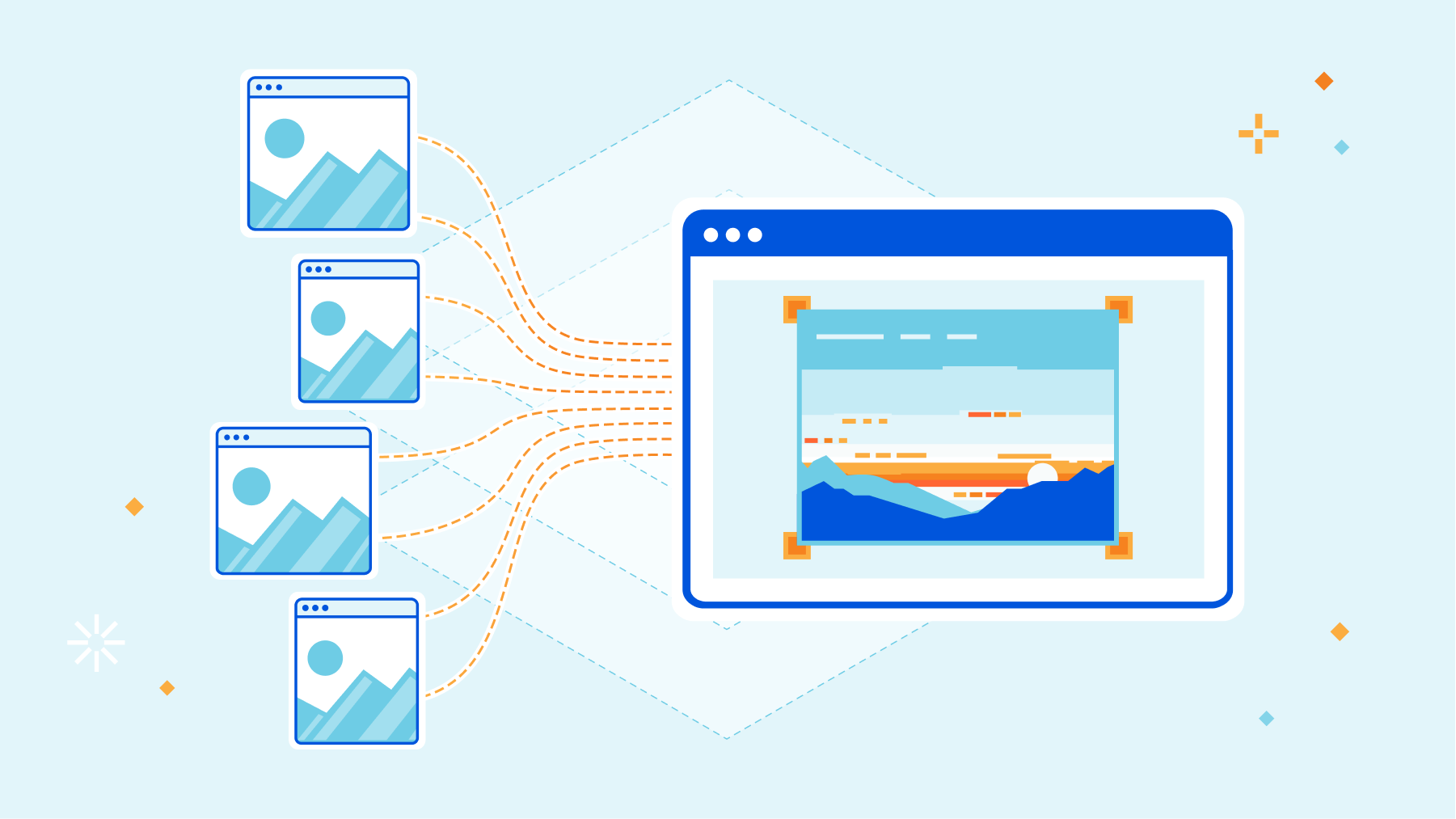
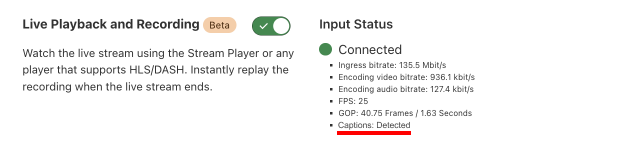
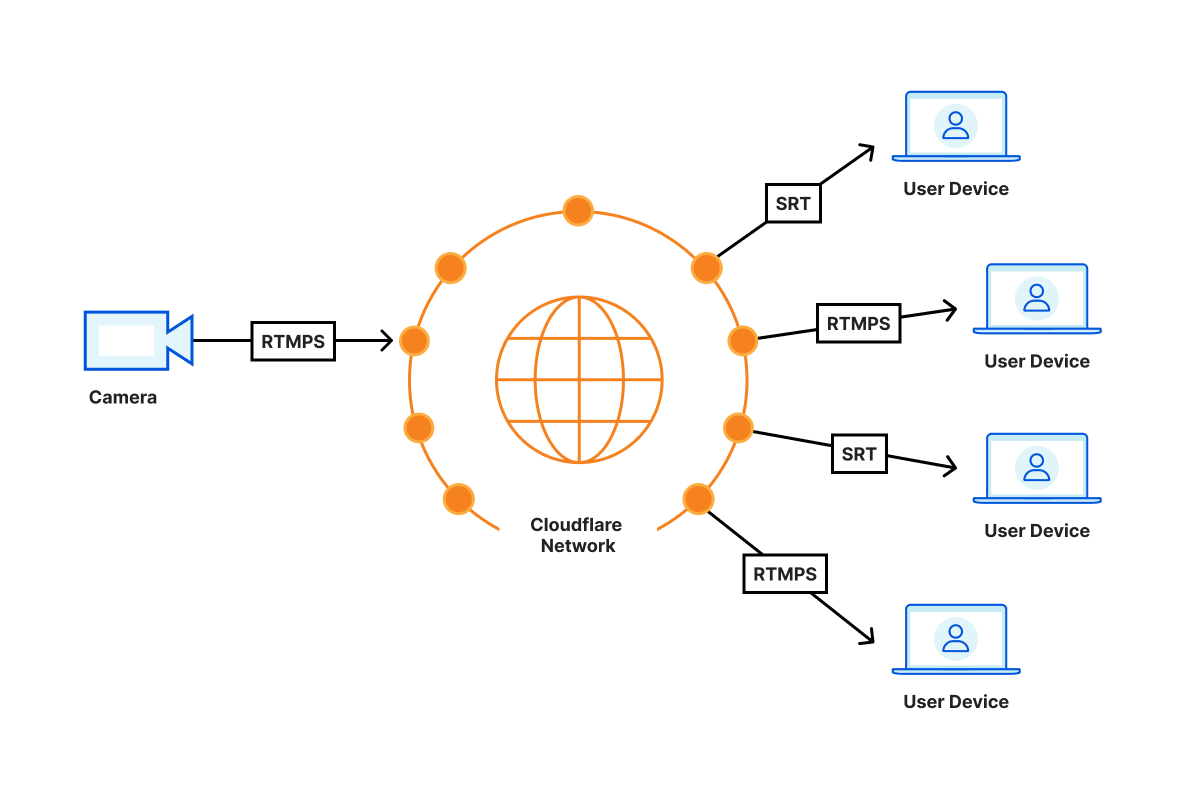
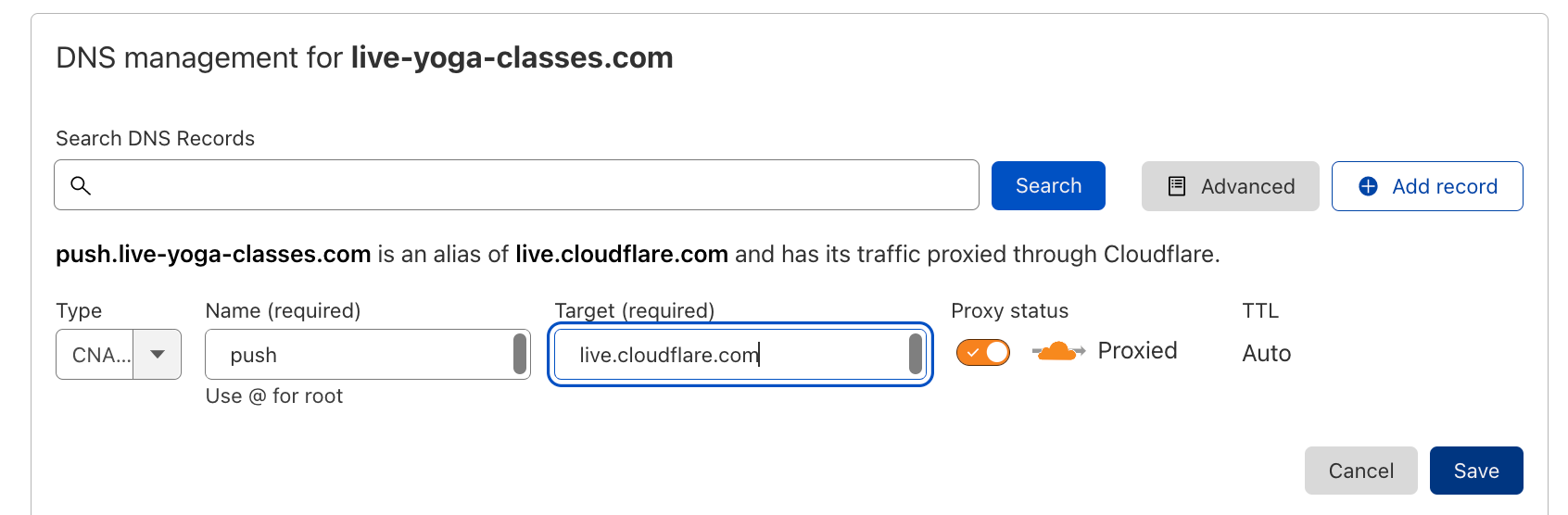
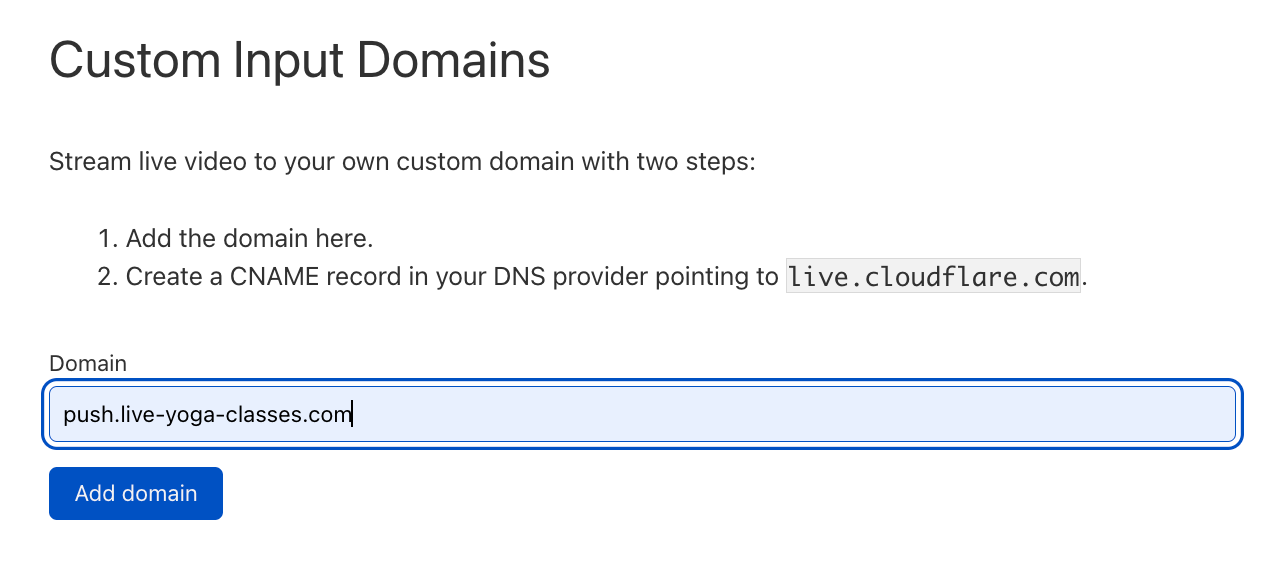
If you don’t have a Jamstack application, we still have services related to media (which is an essential part of any website). Store, resize, and optimize your Images or deliver live streams.
In addition to building and delivering the applications there is a host of observability solutions to view how everything is performing. The reliability of your systems is impacted when you don’t have visibility into how they are performing. We continue to expand the tools available to track performance of your applications through internal tools and partnerships. Logpush for Workers, Pub/sub, and Workers Analytics Engine are the latest additions giving you the ability to publish, gather, and process events, telemetry or sensor data, and create visualizations from the data.
Application and network services
The benefits of building on the Cloudflare Developer Platform is the interoperability of solutions within our application and network services.
With the beta release of R2 we also announced Cache Reserve. When content is expired or evicted from our CDN a cache reserve can be configured in R2 to stay in-network and avoid having to pay egress fees refreshing content from the origin.
Connectivity and communication across distributed systems requires network address translation. Magic NAT makes it easy for systems to communicate across private subnets with overlapping IP space without having to backhaul traffic, deploy gateways in multiple zones, incur fees, or deal with latency.
Ecosystem of providers
It’s not enough to have a suite of tools and services, you need to integrate and extend them with your existing vendors. The Developer Platform Ecosystem exists to do exactly this. We continue to expand our directory giving you the peace of mind that the Cloudflare Developer Platform will work for you.
How this all fits together
Whether you want to modify requests or responses on their way to or from the origin, build a Jamstack application, or build an entire dynamic application without any origin the Cloudflare Developer Platform has what you need. Instead of serving your application from a single region where your servers are, you can serve your application from “Region Earth.”
The applications you can build are limitless with compute, storage, and comprehensive developer services. Build your app, maintain state, upload your images directly to R2 and have them optimized via Images before being delivered by the CDN.
Unnecessary human decisions such as which region your objects should be stored in, become system decisions when the region is chosen automatically based on a request. When cached content is expired or evicted from cache, Cache Reserve is there to retrieve the object locally from R2 instead of traversing the Internet to the origin.
Once you have the application up and running you can visualize events and telemetry to ensure a reliable and fast application.
Here’s a small sample of what you can do with the Developer Platform:
- Build a collaborative app like a multi-player Wordle game.
- Deliver a newsletter, allow users to sign up using Oauth. Or aggregate articles into a newsfeed.
- Create a website with up-to-date train departures and arrivals.
With over 35 announcements made during Platform Week we can’t wait to see what you’re going to build.
















































{kind=link}
{kind=link}
{kind=link}