Post Syndicated from Sai Sriparasa original https://aws.amazon.com/blogs/big-data/securing-access-to-emr-clusters-using-aws-systems-manager/
Organizations need to secure infrastructure when enabling access to engineers to build applications. Opening SSH inbound ports on instances to enable engineer access introduces the risk of a malicious entity running unauthorized commands. Using a Bastion host or jump server is a common approach used to allow engineer access to Amazon EMR cluster instances by enabling SSH inbound ports. In this post, we present a more secure way to access your EMR cluster launched in a private subnet that eliminates the need to open inbound ports or use a Bastion host.
We strive to answer the following three questions in this post:
- Why use AWS Systems Manager Session Manager with Amazon EMR?
- Who can use Session Manager?
- How can Session Manager be configured on Amazon EMR?
After answering these questions, we will walk you through configuring Amazon EMR with Session Manager and creating an AWS Identity and Access Management (IAM) policy to enable Session Manager capabilities on Amazon EMR. We also walk you through the steps required to configure secure tunneling to access Hadoop application web interfaces such as YARN Resource Manager and, Spark Job Server.
Creating an IAM role
AWS Systems Manager provides a unified user interface so you can view and manage your Amazon Elastic Compute Cloud (Amazon EC2) instances. Session Manager provides secure and auditable instance management. Systems Manager integration with IAM provides centralized access control to your EMR cluster. By default, Systems Manager doesn’t have permissions to perform actions on cluster instances. You must grant access by attaching an IAM role on the instance. Before you get started, create an IAM service role for cluster EC2 instances with the least privilege access policy.
- Create an IAM service role (Amazon EMR role for Amazon EC2) for cluster EC2 instances and attach the AWS managed Systems Manager core instance (AmazonSSMManagedInstanceCore) policy.
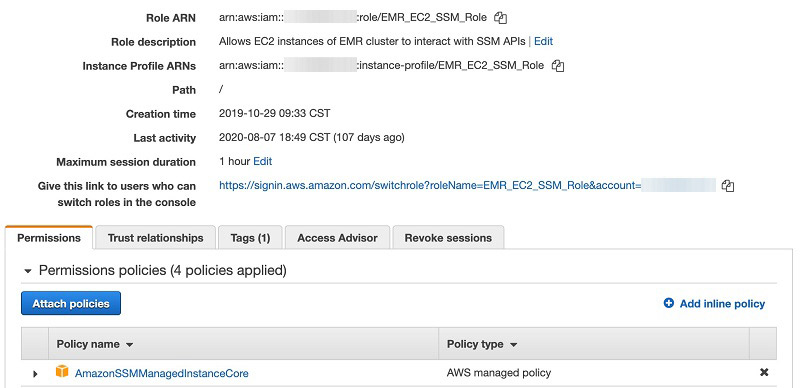
- Create an IAM policy with least privilege to allow the principal to initiate a Session Manager session on Amazon EMR cluster instances:
- Attach the least privilege policy to the IAM principal (role or user).
How Amazon EMR works with AWS Systems Manager Agent
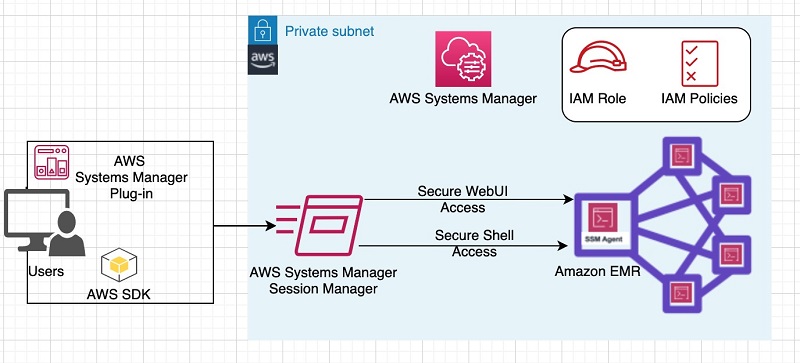
You can install and configure AWS Systems Manager Agent (SSM Agent) on Amazon EMR cluster node(s) using bootstrap actions. SSM Agent makes it possible for Session Manager to update, manage and configure these resources. Session Manager is available at no additional cost to manage Amazon EC2 instances, for cost on additional features refer Systems Manager pricing page. The agent processes requests from the Session Manager service in the AWS Cloud, and then runs them as specified in the user request. You can achieve dynamic port forwarding by installing the Systems Manager plug-in on a local computer. IAM policies provide centralized access control on the EMR cluster.
The following diagram illustrates a high-level integration of AWS Systems Manager interaction with an EMR cluster.
Configuring SSM Agent on an EMR Cluster:
To configure SSM Agent on your cluster, complete the following steps:
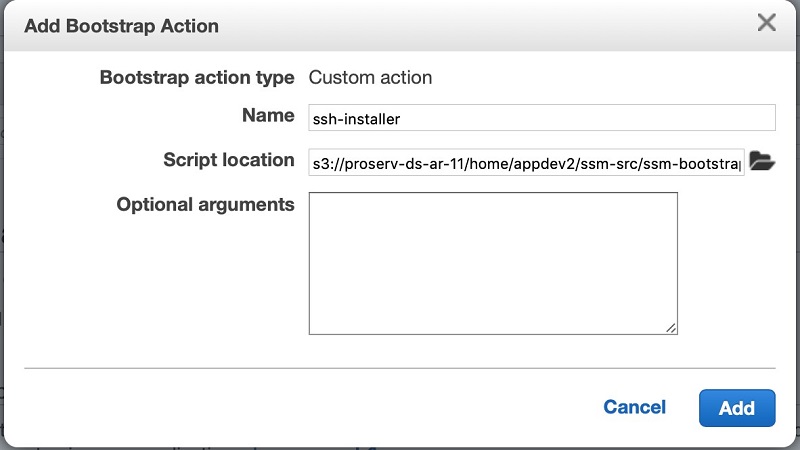
- While launching the EMR cluster, in the Bootstrap Actions section, choose add bootstrap action.
- Choose “Custom action”.
- Add a bootstrap action to run the following script from Amazon Simple Storage Service (Amazon S3) to install and configure SSM Agent on Amazon EMR cluster instances.
SSM Agent expects localhost entry in the hosts file to allow traffic redirection from a local computer to the EMR cluster instance when dynamic port forwarding is used.
- In the Security Options section, under Permissions, select Custom.
- For EMR role, choose IAM role you created.
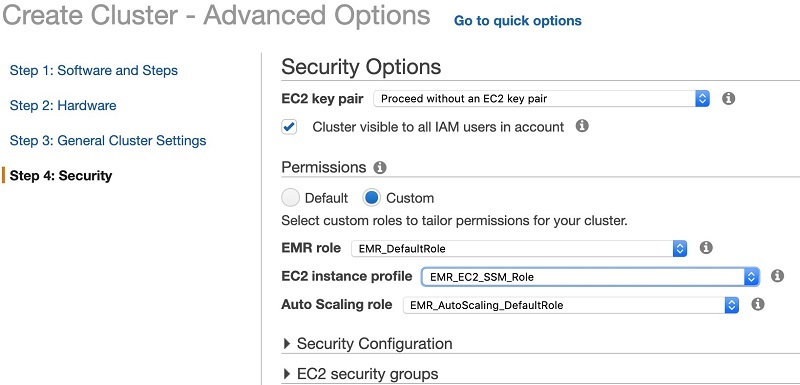
- After the cluster successfully launches, on the Session Manager console, choose Managed Instances.
- Select your cluster instance
- On the Actions menu, choose Start Session

Dynamic port forwarding to access Hadoop applications web UIs
To gain access to Hadoop applications web UIs such as YARN Resource Manager, Spark Job Server, and more on the Amazon EMR primary node, you create a secure tunnel between your computer and the Amazon EMR primary node using Session Manager. By doing so, you avoid needing to create and manage a SOCKS proxy and other add-ons such as FoxyProxy etc.
Before configuring port forwarding on your laptop, you must install the System Manager CLI extension (version 1.1.26.0 or more recent).
When the prerequisites are met, you use the StartPortForwardingSession feature to create secure tunneling onto EMR cluster instances.
The following code demonstrates port forwarding from your laptop local port [8158] to a remote port [8080] on an EMR instance to access the Hadoop Resource Manager web UI:
Restricting IAM principal access based on Instance Tags
In a multi-tenant Amazon EMR cluster environment, you can restrict access to Amazon EMR cluster instances based on specific Amazon EC2 tags. In the following example code, the IAM principal (IAM user or role) is allowed to start a session on any instance (Resource: arn:aws:ec2:*:*:instance/*) with the condition that the instance is a QACluster (ssm:resourceTag/ClusterType: QACluster).
If the IAM principal initiates a session to an instance that isn’t tagged or that has any tag other than ClusterType: QACluster, the execution results show is not authorized to perform ssm:StartSession.
Restricting access to root-level commands on instance
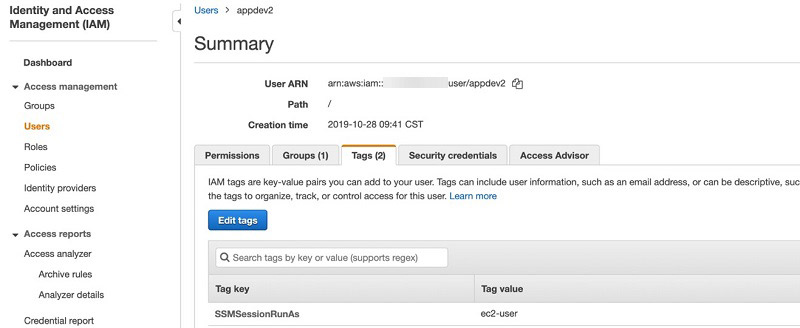
You can change the default user login behavior to restrict elevated permissions (root login) on a given user’s session. By default, sessions are launched using the credentials of a system-generated ssm-user. You can instead launch sessions using credentials of an operating system account by tagging an IAM user or role with the tag key SSMSessionRunAs or specify an operating system user name. Updates to Session Manager preferences enables this support.
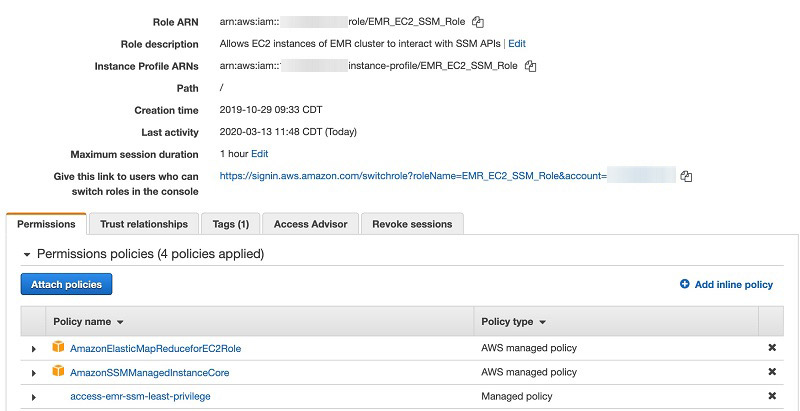
The following screenshots show a configuration for the IAM user appdev2, who is always allowed to start a session with ec2-user instead of the default ssm-user.

Conclusion
Amazon EMR with Session Manager can greatly improve your confidence in security and audit posture by centralizing access control and mitigating risk of managing access keys and inbound ports. It also reduces the overall cost, because as you get free from intermediate Bastion hosts.
About the Authors
 Sai Sriparasa is a Sr. Big Data & Security Consultant with AWS Professional Services. He works with our customers to provide strategic and tactical big data solutions with an emphasis on automation, operations, governance & security on AWS. In his spare time, he follows sports and current affairs.
Sai Sriparasa is a Sr. Big Data & Security Consultant with AWS Professional Services. He works with our customers to provide strategic and tactical big data solutions with an emphasis on automation, operations, governance & security on AWS. In his spare time, he follows sports and current affairs.
 Ravi Kadiri is a security data architect at AWS, focused on helping customers build secure data lake solutions using native AWS security services. He enjoys using his experience as a Big Data architect to provide guidance and technical expertise on Big Data & Analytics space. His interests include staying fit, traveling and spend time with friends & family.
Ravi Kadiri is a security data architect at AWS, focused on helping customers build secure data lake solutions using native AWS security services. He enjoys using his experience as a Big Data architect to provide guidance and technical expertise on Big Data & Analytics space. His interests include staying fit, traveling and spend time with friends & family.