Post Syndicated from Shashank Sharma original https://aws.amazon.com/blogs/big-data/sap-data-ingestion-and-replication-with-aws-glue-zero-etl/
Organizations increasingly want to ingest and gain faster access to insights from SAP systems without maintaining complex data pipelines. AWS Glue zero-ETL with SAP now supports data ingestion and replication from SAP data sources such as Operational Data Provisioning (ODP) managed SAP Business Warehouse (BW) extractors, Advanced Business Application Programming (ABAP), Core Data Services (CDS) views, and other non-ODP data sources. Zero-ETL data replication and schema synchronization writes extracted data to AWS services like Amazon Redshift, Amazon SageMaker lakehouse, and Amazon S3 Tables, alleviating the need for manual pipeline development. This creates a foundation for AI-driven insights when used with AWS services such as Amazon Q and Amazon Quick Suite, where you can use natural language queries to analyze SAP data, create AI agents for automation, and generate contextual insights across your enterprise data landscape.
In this post, we show how to create and monitor a zero-ETL integration with various ODP and non-ODP SAP sources.
Solution overview
The key component of SAP integration is the AWS Glue SAP OData connector, which is designed to work with the SAP data structures and protocols. The connector provides connectivity to ABAP-based SAP systems and adheres to the SAP security and governance frameworks. Key features of the AWS SAP connector include:
- Uses OData protocol for data extraction from various SAP NetWeaver systems
- Managed replication for complex SAP data models such as BW extractors (such as
2LIS_02_ITM) and CDS views (such asC_PURCHASEORDERITEMDEX) - Handles both ODP and non-ODP entities using the SAP change data capture (CDC) technology
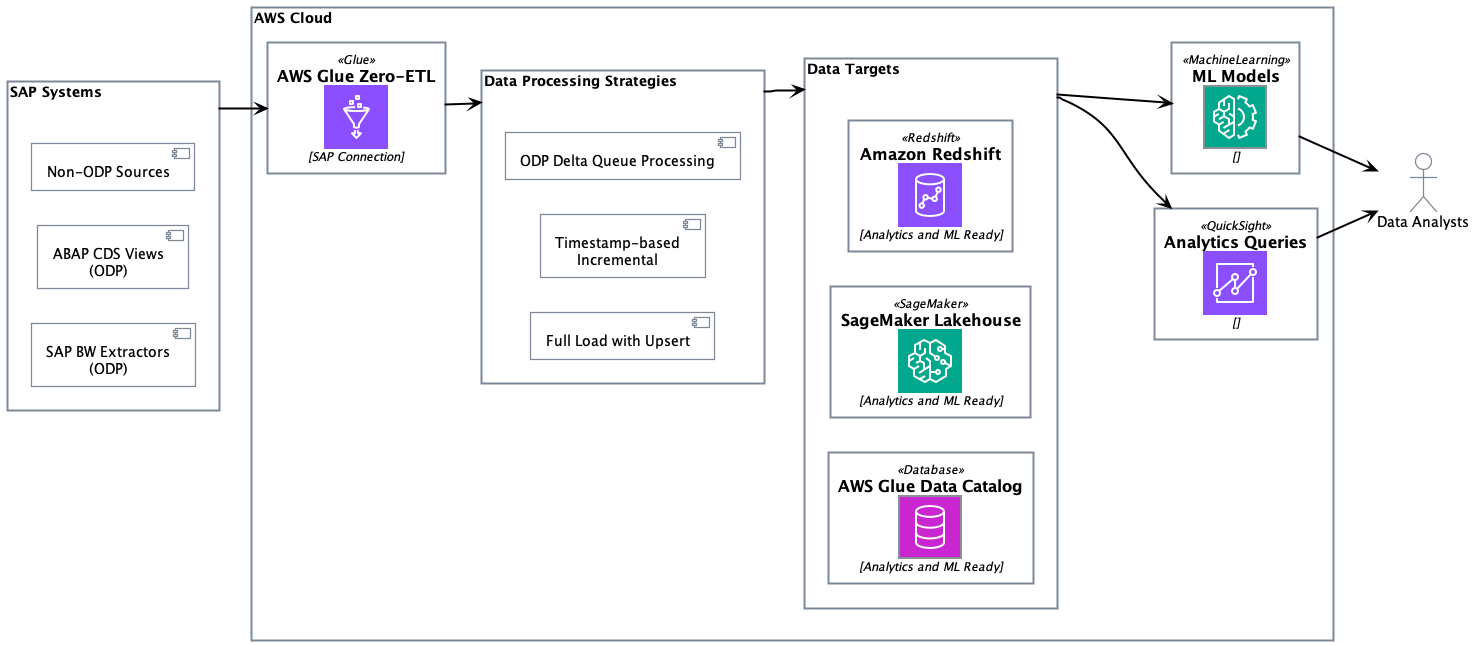
The SAP connector works with both AWS Glue Studio or AWS managed replication with zero-ETL. Self-managed replication in AWS Glue Studio provides full control over data processing units, replication frequencies, adjusting price-performance, page size, data filters, destinations, file formats, data transformation, and writing your own code with selected runtime. AWS managed data replication in zero-ETL removes burden of custom configurations and provides an AWS managed alternative, allowing replication frequencies between 15 minutes to 6 days. The following solution architecture demonstrates the approaches of ingesting ODP and non-ODP SAP data using zero-ETL from various SAP sources and writing to Amazon Redshift, SageMaker lakehouse, and S3 Tables.
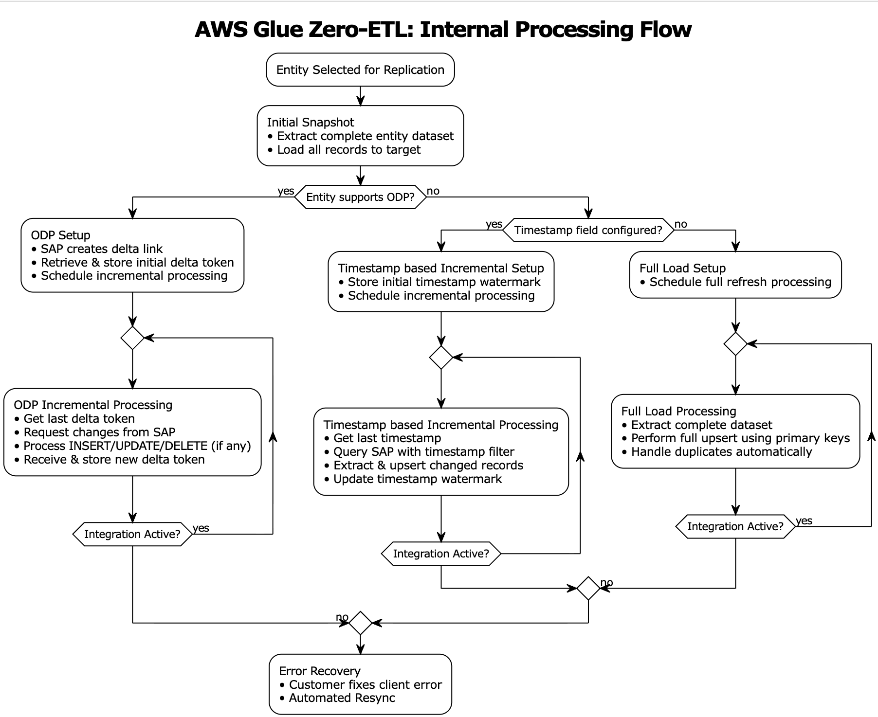
Change data capture for ODP sources
SAP ODP is a data extraction framework that enables incremental and data replication from SAP source systems to target systems. The ODP framework provides applications (subscribers) to request data from supported objects, such as BW extractors, CDS views, and BW objects, in an incremental manner.
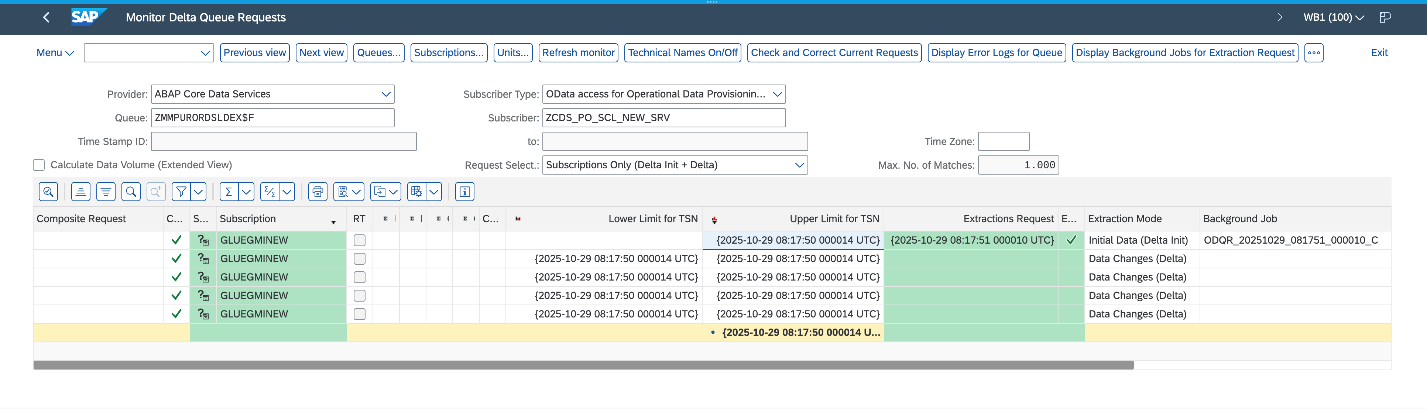
AWS Glue zero-ETL data ingestion begins with executing a full initial load of entity data to establish the baseline dataset in the target system. After the initial full load is complete, SAP provisions a delta queue known as Operational Delta Queue (ODQ), which captures data changes, including deletions. The delta token is sent to the subscriber during the initial load and persisted within the zero-ETL internal state management system.
The incremental processing retrieves the last stored delta token from the state store, then sends a delta change request to SAP using this token using the OData protocol. The system processes returned INSERT/UPDATE/DELETE operations through the SAP ODQ mechanism and receives a new delta token from SAP even in scenarios where no records were modified. This new token is persisted in the state management system after successful ingestion. In error scenarios, the system preserves the existing delta token state, enabling retry mechanics without data loss.
The following screenshot illustrates a successful initial load followed by four incremental data ingestions on the SAP system.
Change data capture for non-ODP sources
Non-ODP structures are OData services that are not ODP enabled. These are APIs, functions, views, or CDS views that are exposed directly without the ODP framework. Data is extracted using this mechanism; however, incremental data extraction depends on the nature of the object. If the object, for example, contains a “last modified date” field, it is used to track changes and provide incremental data extraction.
AWS Glue zero-ETL provides out-of-the-box incremental data extraction for non-ODP OData services, provided the entity includes a field to track changes (last modified date or time). For such SAP services, zero-ETL provides two approaches for data ingestion: timestamp-based incremental processing and full load.
Timestamp-based incremental processing
Timestamp-based incremental processing uses customers’ configured timestamp fields in zero-ETL to optimize the data extraction process. The zero-ETL system establishes a starting timestamp that serves as the foundation for subsequent incremental processing operations. This timestamp, known as the watermark, is crucial for facilitating data consistency. The query construction mechanism builds OData filters based on timestamp comparisons. These queries extract records that are created or modified since the last successful processing execution. The system’s watermark management functionality maintains tracking of the highest timestamp value from each processing cycle and uses this information as the starting point for subsequent executions. The zero-ETL system performs an upsert on the target using the configured primary keys. This approach facilitates proper handling of updates while maintaining data integrity. After each successful target system update, the watermark timestamp is advanced, creating a reliable checkpoint for future processing cycles.
However, the timestamp-based approach has a limitation: it can’t track physical deletions because SAP systems don’t maintain deletion timestamps. In scenarios where timestamp fields are either unavailable or not configured, the system transitions to a full load with upsert processing.
Full load
The full load approach serves as both a standalone approach and a fallback mechanism when timestamp-based processing is not feasible. This method involves extracting the complete entity dataset during each processing cycle, making it suitable for scenarios where change tracking is not available or required. The extracted dataset is upserted in the target system. The upsert processing logic handles both new record insertions and updates to existing records.
When to choose incremental or full load
The timestamp-based incremental processing approach offers optimal performance and resource utilization for large datasets with frequent updates. Data transfer volumes are reduced through the selective transfer of only modified records, resulting in reductions in network traffic. This optimization directly translates into lower operational costs. The full load with upsert facilitates data synchronization in scenarios where incremental processing is not feasible.
Together, these approaches form a complete solution for zero-ETL integration with non-ODP SAP structures, addressing the diverse requirements of enterprise data integration scenarios. Organizations using these approaches should evaluate their specific use cases, data volumes, and performance requirements when choosing between the two approaches.The following diagram illustrates the SAP data ingestion workflow.
Observing SAP zero-ETL integrations
AWS Glue maintains state management, logs, and metrics using Amazon CloudWatch logs. For instructions to configure observability, refer to Monitoring an integration. Make sure AWS Identity and Access Management (IAM) roles are configured for log delivery. The integration is monitored from both source ingestion and writing to the chosen target.
Monitoring source ingestion
The integration of AWS Glue zero-ETL with CloudWatch provides monitoring capabilities to track and troubleshoot the data integration processes. Through CloudWatch, you can access detailed logs, metrics, and events that help identify issues, monitor performance, and maintain operational health of your SAP data integrations. Let’s look at a few instances of success and error scenarios.
Scenario 1: Missing permissions on your role
This error occurred during a data integration process in AWS Glue when attempting to access SAP data. The connection encountered a CLIENT_ERROR with a 400 Bad Request status code, indicating that the role has missing permissions:
Scenario 2: Broken delta links
The CloudWatch log indicates an issue with missing delta tokens during data synchronization from SAP to AWS Glue. The error occurs when attempting to access the SAP sales document item table FactsOfCSDSLSDOCITMDX through the OData service. The absence of delta tokens, which are needed for incremental data loading and tracking changes, has resulted in a CLIENT_ERROR (400 Bad Request) when the system tried to open the data extraction API RODPS_REPL_ODP_OPEN:
Scenario 3: Client errors on SAP data ingestion
This CloudWatch log reveals a client exception scenario where the SAP entity EntityOf0VENDOR_ATTR is not located or accessed through the OData service. This CLIENT_ERROR occurs when the AWS Glue connector attempts to parse the response from the SAP system but fails, due to either the entity being non-existent in the source SAP system or the SAP instance being temporarily unavailable:
Monitoring target write
Zero-ETL employs monitoring mechanisms depending on the target system. For Amazon Redshift targets, it uses the svv_integration system view, which provides detailed information about integration status, job execution, and data movement statistics. When working with SageMaker lakehouse targets, zero-ETL tracks integration states through the zetl_integration_table_state table, which maintains metadata about synchronization status, timestamps, and execution details. Additionally, you can use CloudWatch logs to monitor the integration progress, capturing information about successful commits, metadata updates, and potential issues during the data writing process.
Scenario 1: Successful processing on SageMaker lakehouse target
The CloudWatch logs show successful data synchronization activity for the plant table using CDC mode. The first log entry (IngestionCompleted) confirms the successful completion of the ingestion process at timestamp 1757221555568, with a last sync timestamp of 1757220991999. The second log (IngestionTableStatistics) provides detailed statistics of the data modifications, showing that during this CDC sync 300 new records were inserted, 8 records were updated, and 2 records were deleted from the target database gluezetl. This level of detail helps in monitoring the volume and types of changes being propagated to the target system.
Scenario 2: Metrics on Amazon SageMaker lakehouse target
The zetl_integration_table_state table in SageMaker lakehouse provides a view of integration status and data modification metrics. In this example, the table shows a successful integration for an SAP CDS view table with integration ID 62b1164f-5b85-45e4-b8db-9aa7ab841e98 in the testdb database. The record indicates that at timestamp 1733000485999, there were 10 insertion records processed (recent_insert_record_count: 10), with no updates or deletions (both counts at 0). This table serves as a monitoring tool, providing a centralized view of integration states and detailed statistics about data modifications, making it straightforward to track and verify data synchronization activities in the lakehouse.
Scenario 3: Redshift monitoring system uses two views to track zero-ETL integration status
svv_integration provides a high-level overview of the integration status, showing that integration ID 03218b8a-9c95-4ec2-81ad-dd4d5398e42a has successfully replicated 18 tables with no failures, and the last checkpoint was at transaction sequence 1761289852999.
svv_integration_table_state offers table-level monitoring details, showing the status of individual tables within the integration. In this case, the SAP material group text entity table is in Synced state, with its last replication checkpoint matching the integration checkpoint (1761289852999). The table currently shows 0 rows and 0 size, suggesting it’s newly created.
These views together provide a comprehensive monitoring solution for tracking both overall integration health and individual table synchronization status in Amazon Redshift.
Prerequisites
In the following sections, we walk through the steps required to set up an SAP connection and using that connection to create a zero-ETL integration. Before implementing this solution, you must have the following in place:
- An SAP account
- An AWS account with administrator access
- Create an S3 Tables target and associate the S3 bucket sap_demo_table_bucket as a location of the database
- Update AWS Glue Data Catalog settings using the following IAM policy for fine-grained access control of the Data Catalog for zero-ETL
- Create an IAM role named
zero_etl_bulk_demo_role, to be used by zero-ETL to access data from your SAP account - Create the secret
zero_etl_bulk_demo_secretin AWS Secrets Manager to store SAP credentials
Create connection to SAP instance
To set up a connection to your SAP instance and provide data to access, complete the following steps:
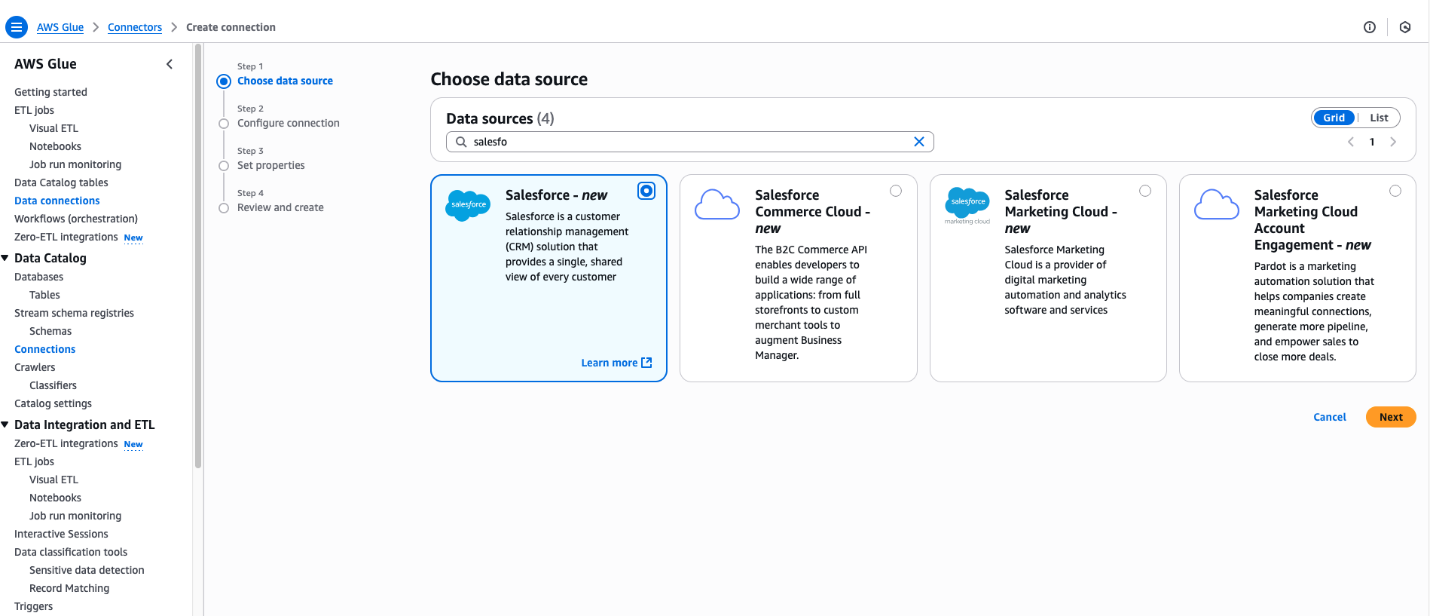
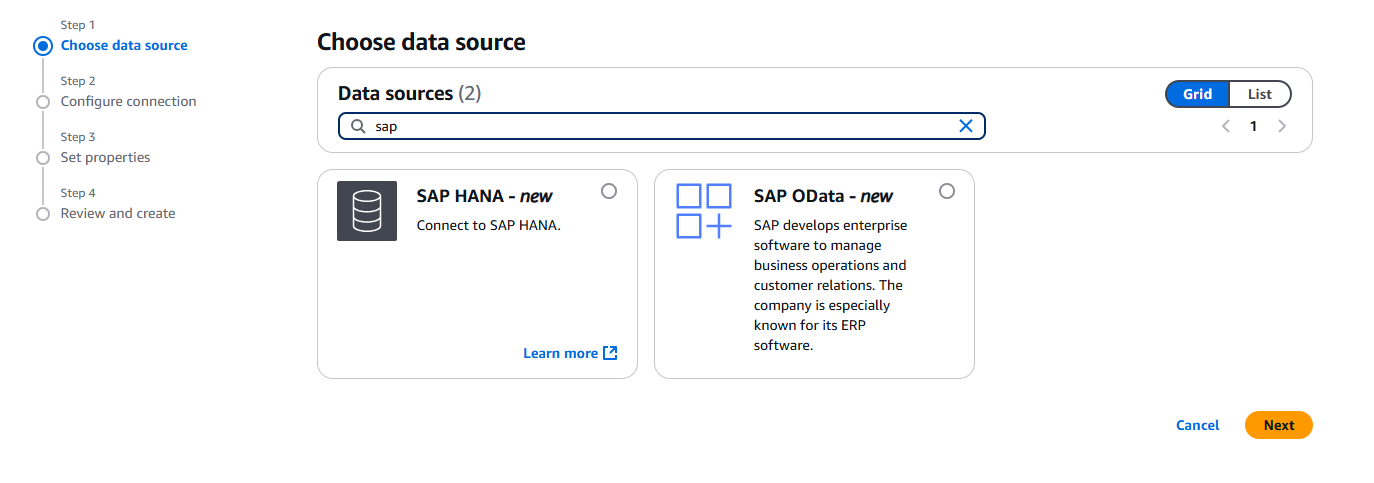
- On the AWS Glue console, in the navigation pane under Data catalog, choose Connections, then choose Create Connection.
- For Data sources, select SAP OData, then choose Next.

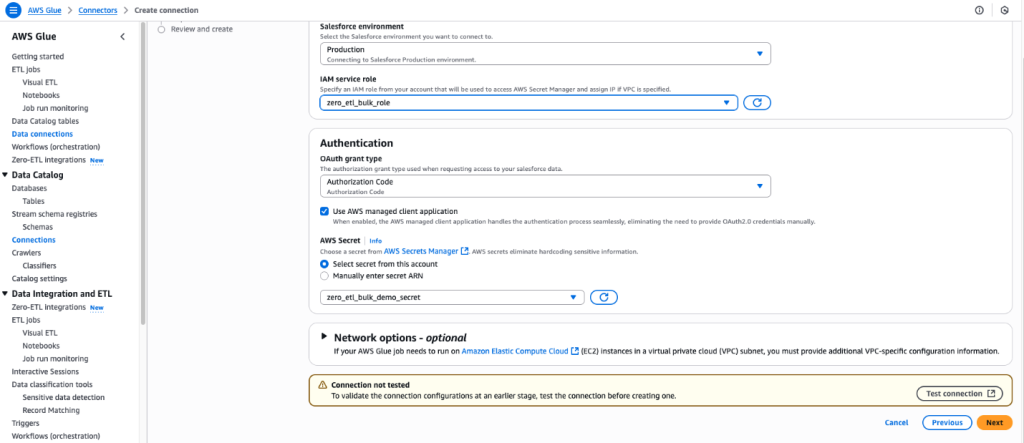
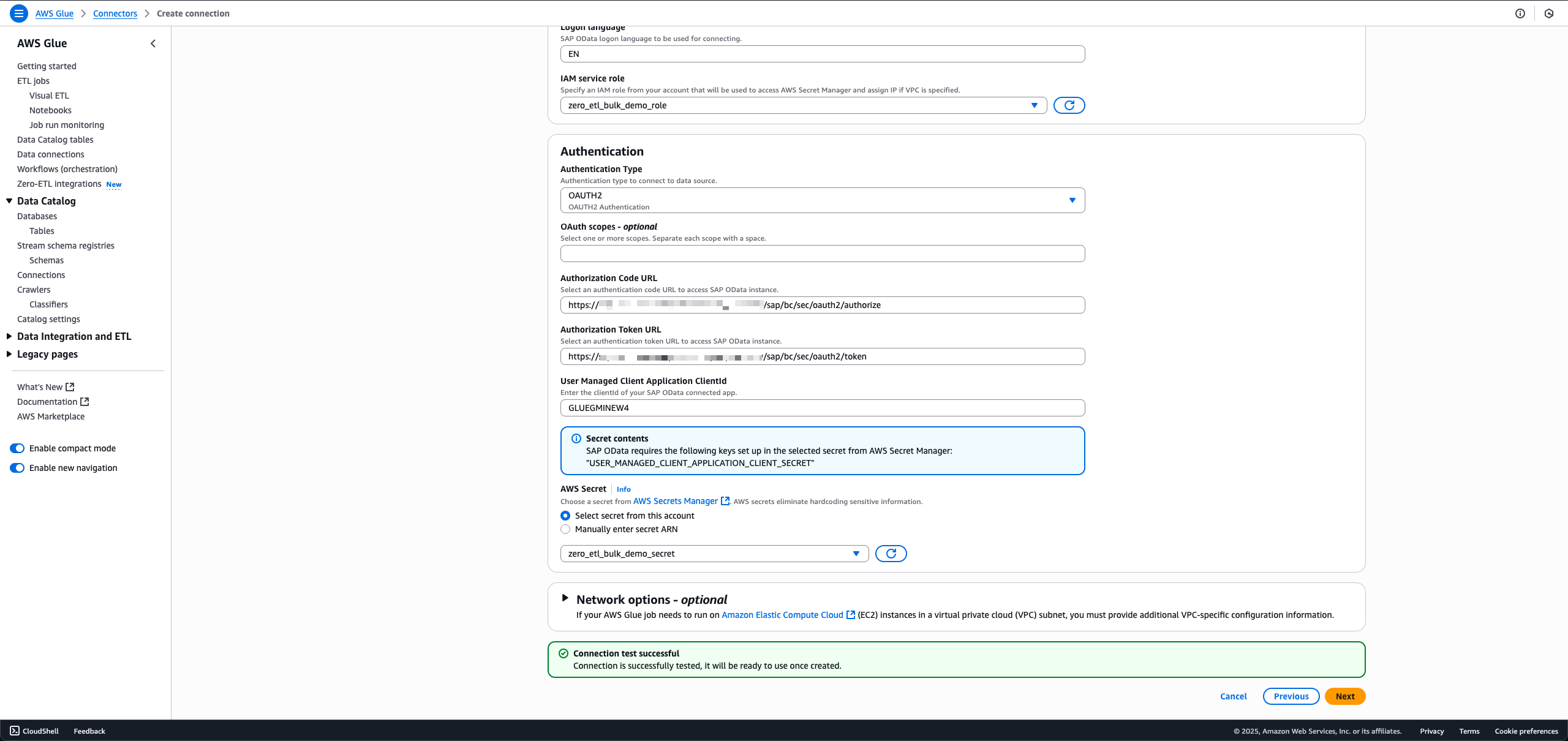
- Enter the SAP instance URL.
- For IAM service role, choose the role
zero_etl_bulk_demo_role(created as a prerequisite). - For Authentication Type, choose the authentication type that you’re using for SAP.
- For AWS Secret, choose the secret
zero_etl_bulk_demo_secret(created as a prerequisite). - Choose Next.

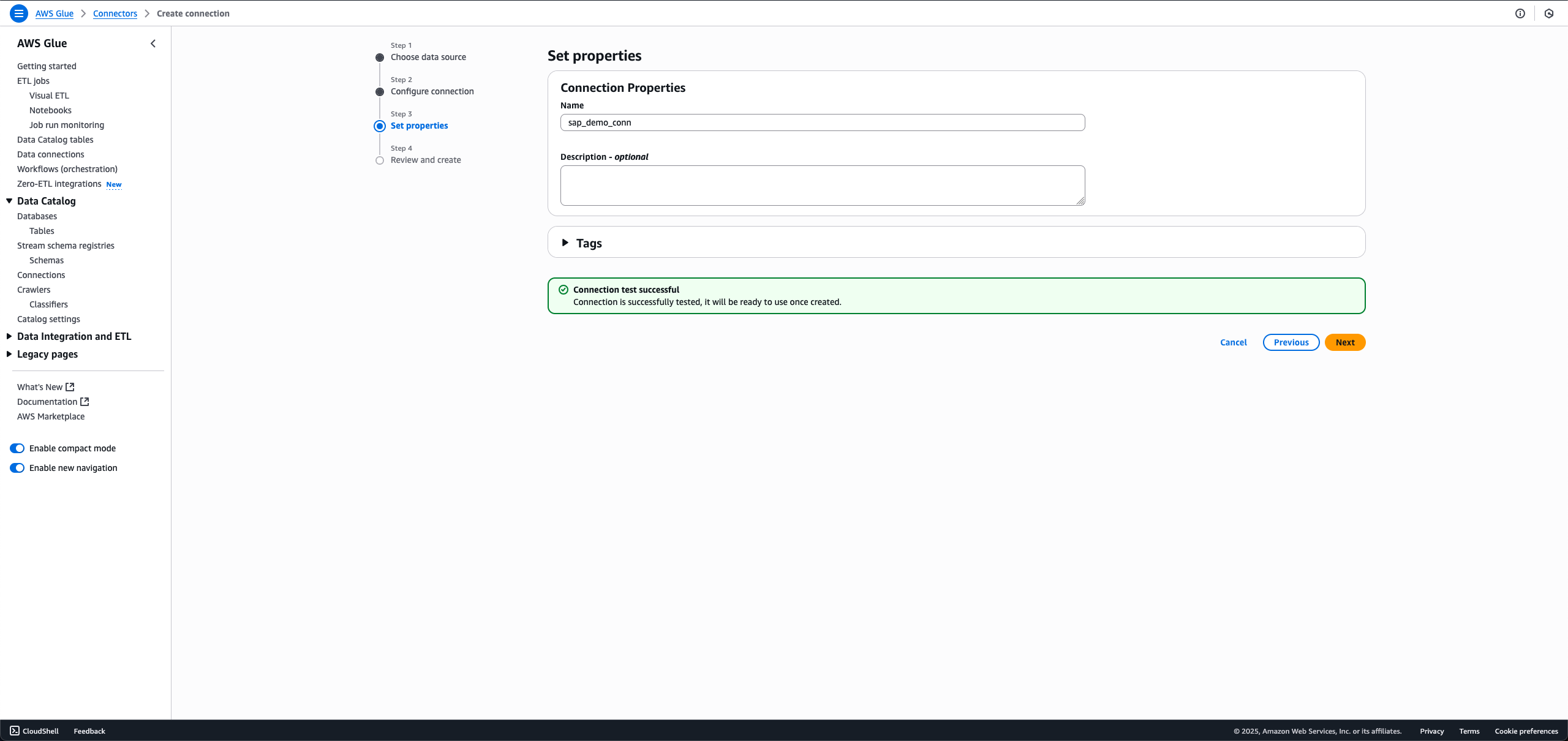
- For Name, enter a name, such as
sap_demo_conn. - Choose Next.
Create zero-ETL integration
To create the zero-ETL integration, complete the following steps:
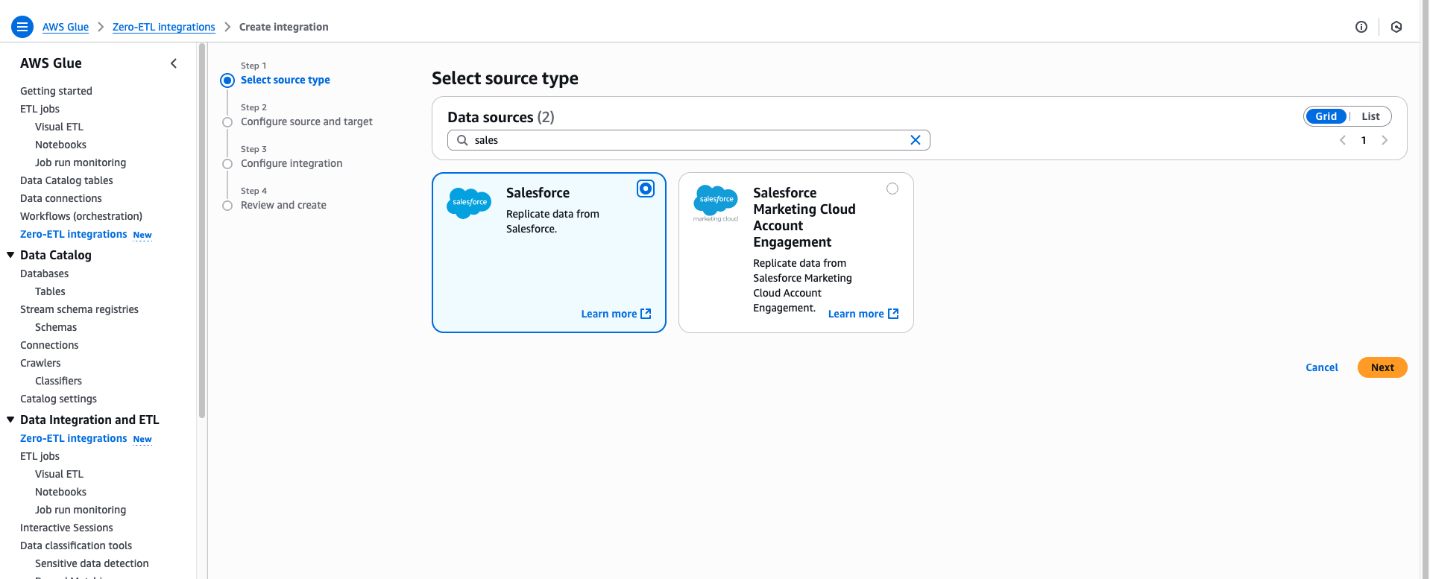
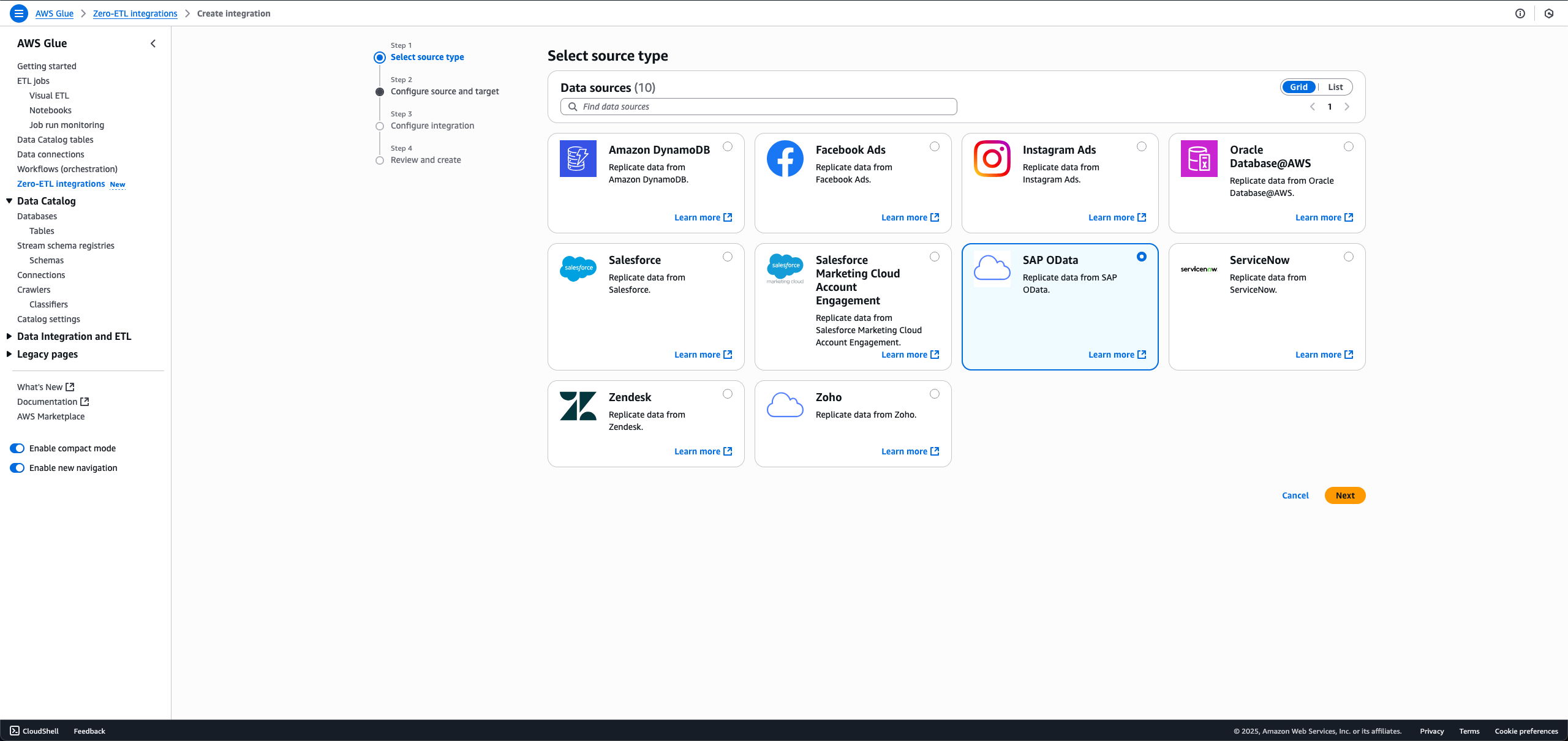
- On the AWS Glue console, in the navigation pane under Data catalog, choose Zero-ETL integrations, then choose Create zero-ETL integration.
- For Data source, select SAP OData, then choose Next.
- Choose the connection name and IAM role that you created in the previous step.
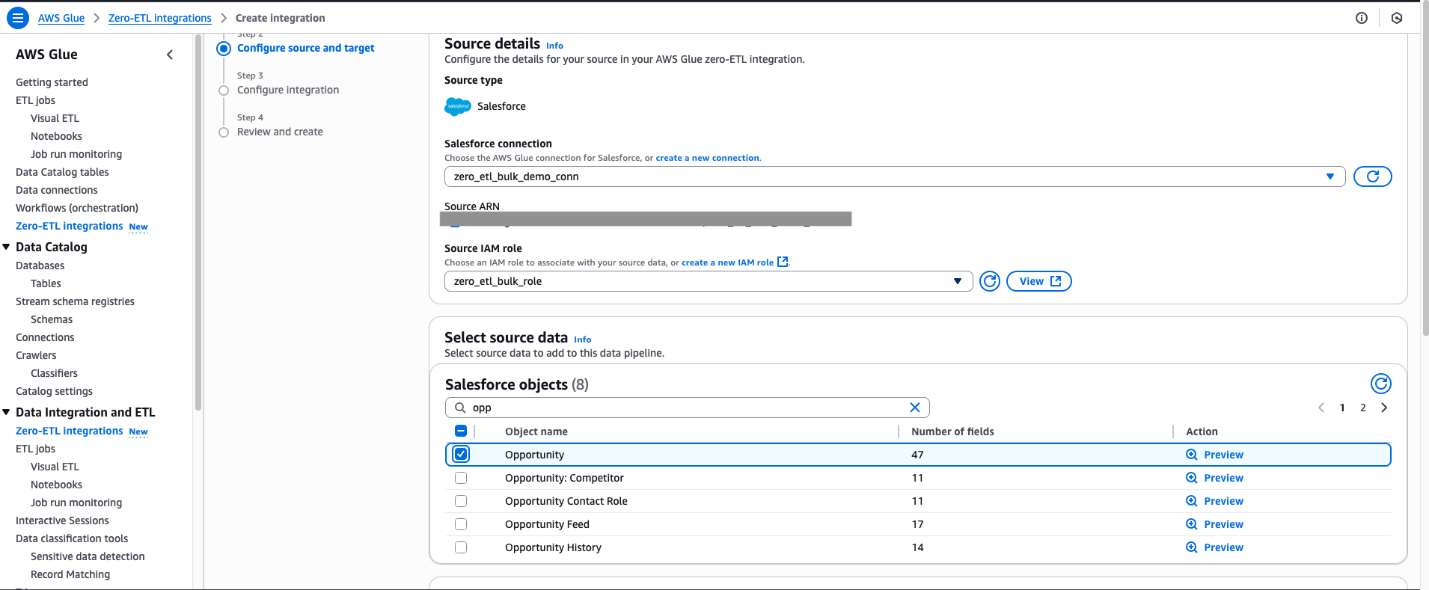
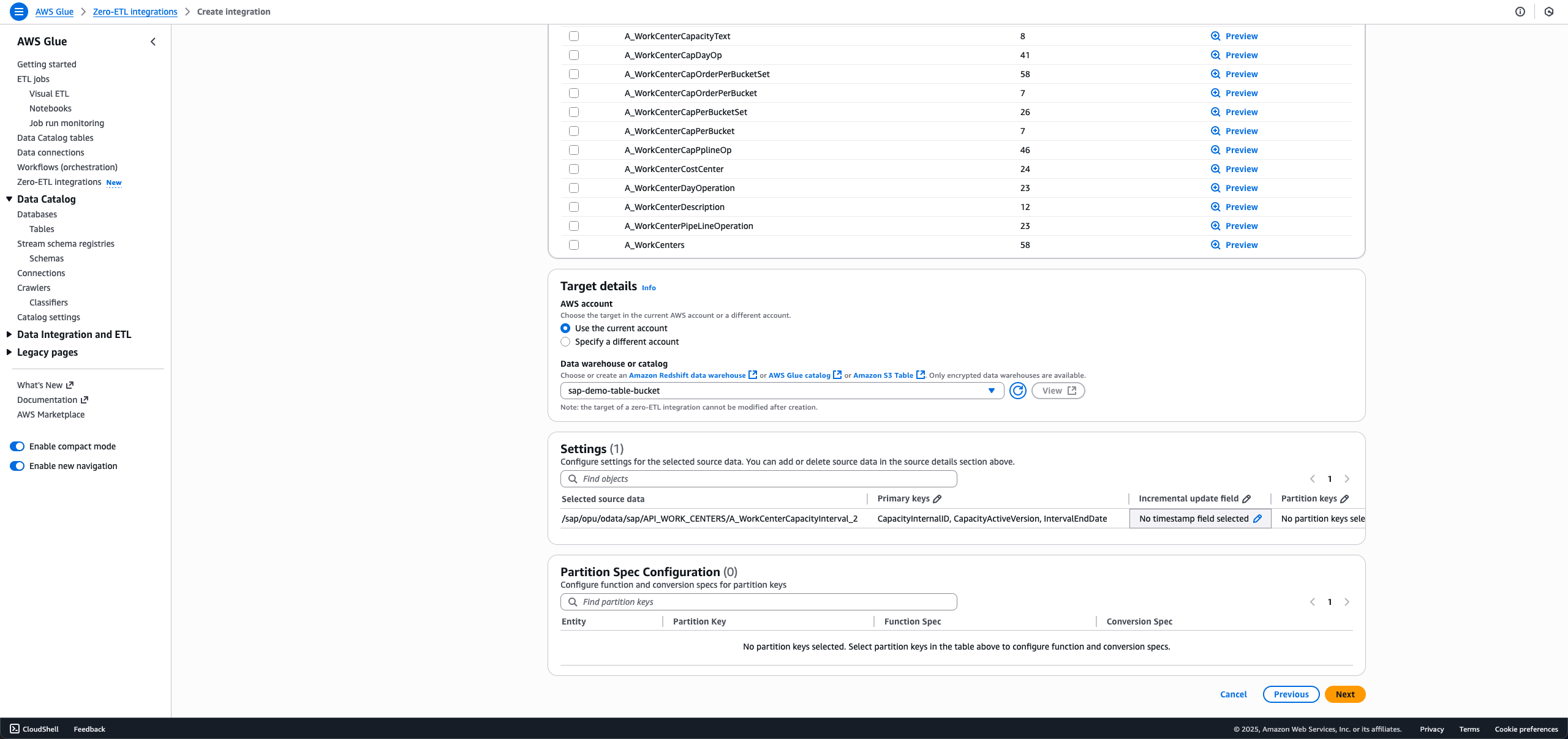
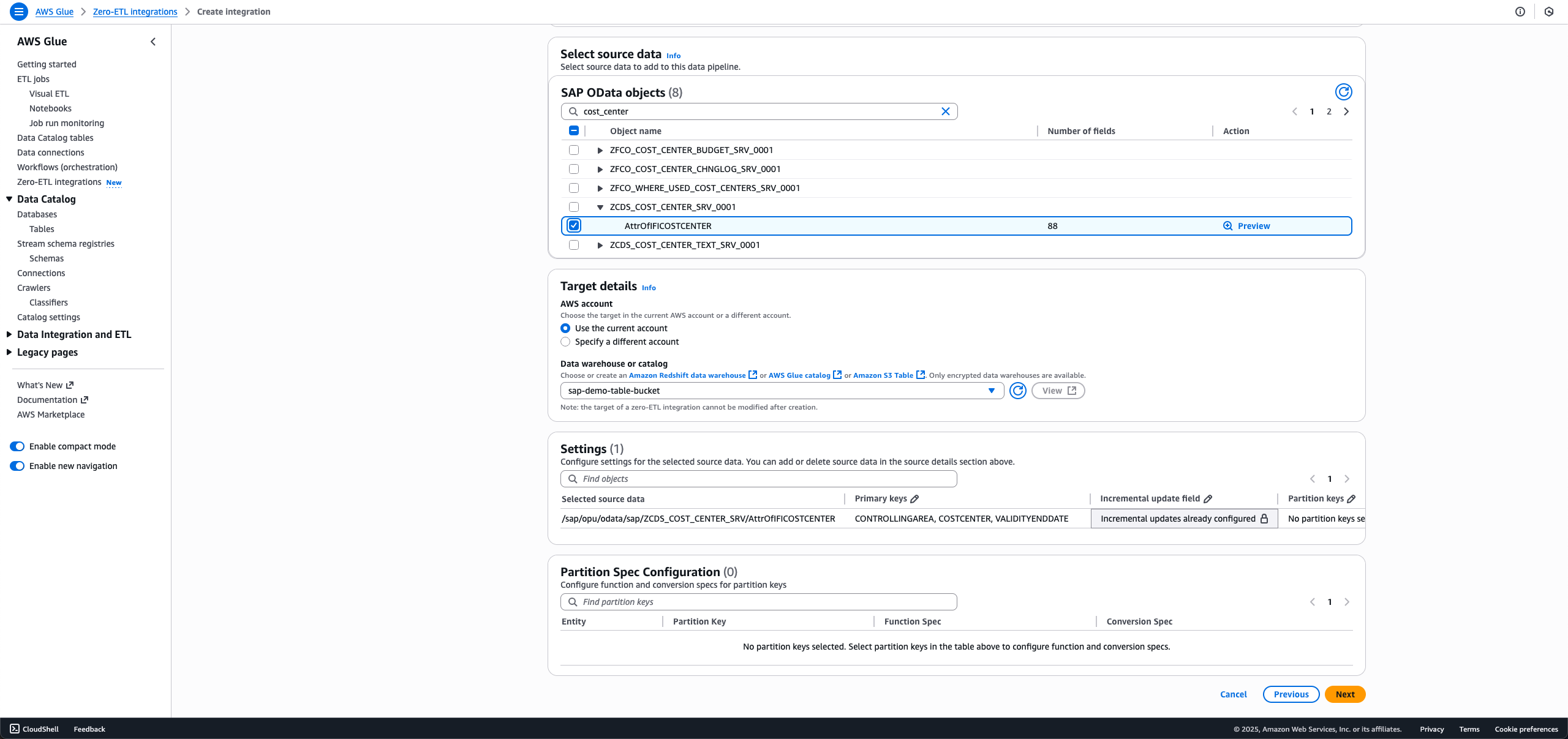
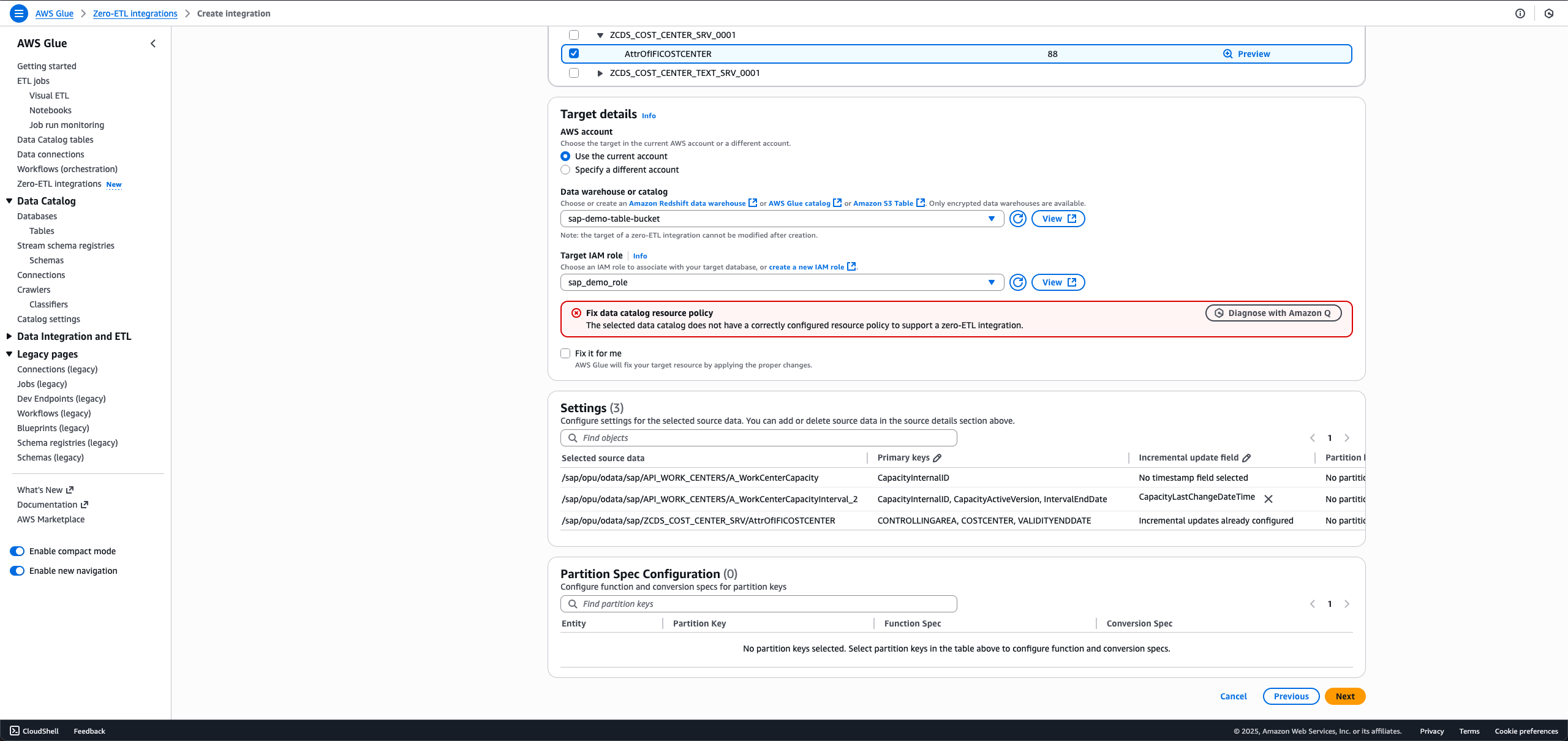
- Choose the SAP objects you want in your integration. The non-ODP objects are either configured for full load or incremental load, and ODP objects are automatically configured for incremental ingestion.
- For full load, leave Incremental update field set as No timestamp field selected.

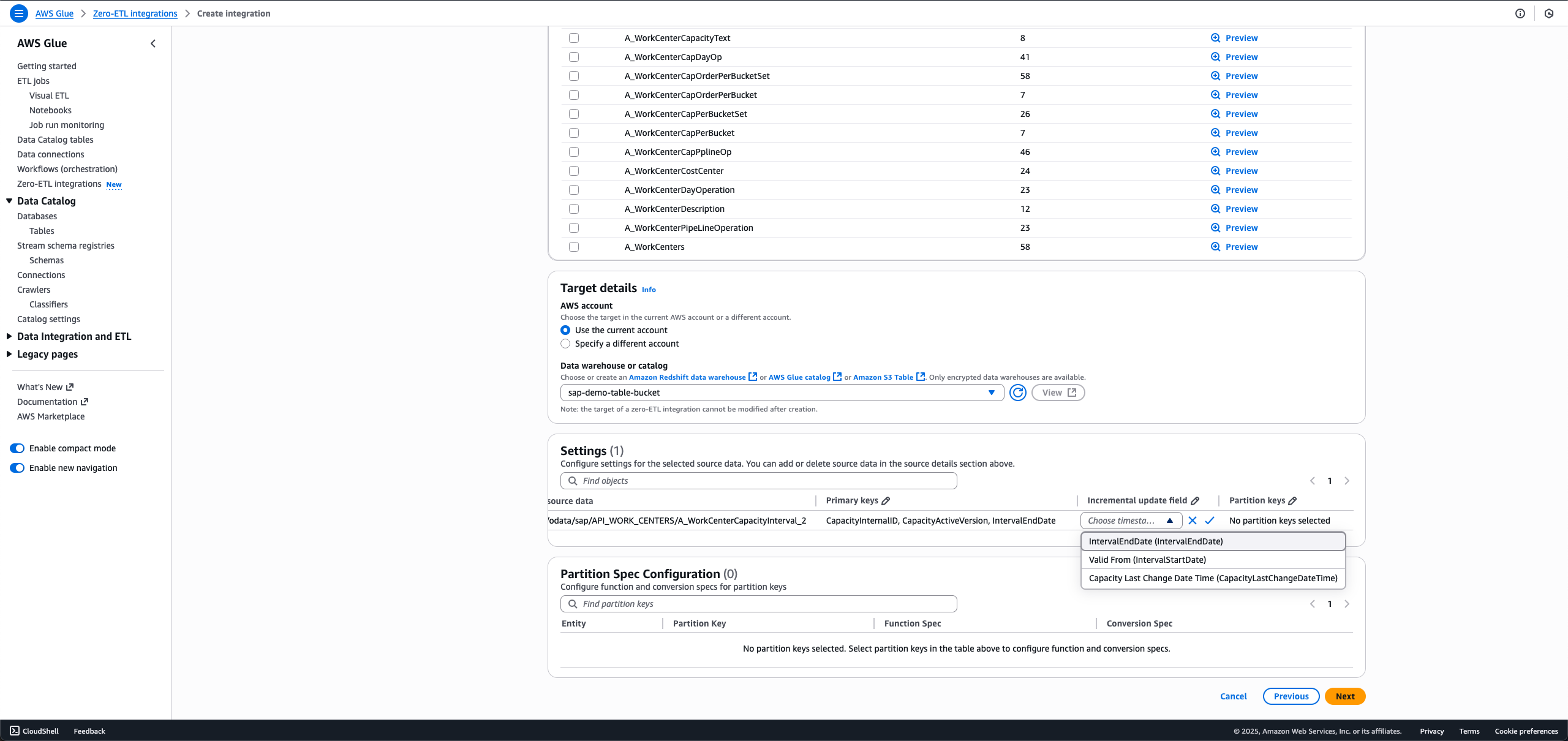
- For incremental load, choose the edit icon for Incremental update field and choose a timestamp field.
- For ODP entities that offer delta token, the incremental update field is pre-selected, and no customer action is necessary.
When making a new integration using the same SAP connection and entity in the data filter, you will not be able to select a different incremental update field from the first integration.
- For full load, leave Incremental update field set as No timestamp field selected.
- For Target details, choose
sap_demo_table_bucket(created as a prerequisite). - For Target IAM role, choose sap_demo_role (created as a prerequisite).
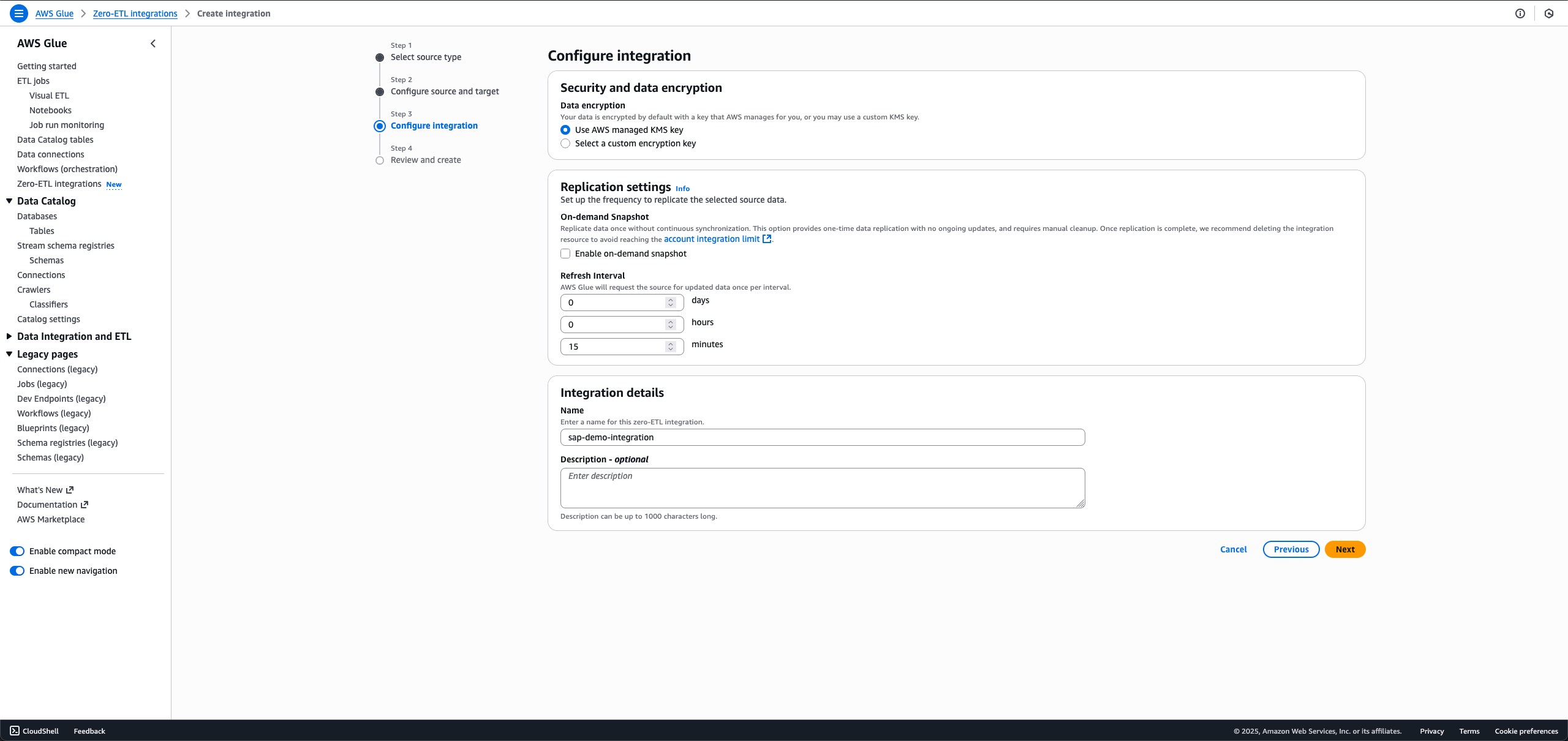
- Choose Next.
- In the Integration details section, for Name, enter sap-demo-integration.
- Choose Next.
- Review the details and choose Create and launch integration.
The newly created integration is shown as Active in about a minute.
Clean up
To clean up your resources, complete the following steps. This process will permanently delete the resources created in this post; back up important data before proceeding.
- Delete the zero-ETL integration
sap-demo-integration. - Delete the S3 Tables target bucket
sap_demo_table_bucket. - Delete the Data Catalog connection
sap_demo_conn. - Delete the Secrets Manager secret
zero_etl_bulk_demo_secret.
Conclusion
You can now transform your SAP data analytics without the complexity of traditional ETL processes. With AWS Glue zero-ETL, you can gain immediate access to your SAP data while maintaining its structure across S3 Tables, SageMaker lakehouse, and Amazon Redshift. Your teams can use ACID-compliant storage with time travel capabilities, schema evolution, and concurrent reads/writes at scale, while keeping data in cost-effective cloud storage. The solution’s AI capabilities through Amazon Q and SageMaker can help your business create on-demand data products, run text-to-SQL queries, and deploy AI agents using Amazon Bedrock and Quick Suite.
To learn more, refer to the following resources:
- AWS Glue Documentation
- Zero-ETL integrations
- Connecting to SAP OData
- Amazon SageMaker lakehouse
- Configuring Amazon S3 tables as a target
- Amazon Q Documentation
- Amazon Quick Suite Documentation
Ready to modernize your SAP data strategy? Explore AWS Glue zero-ETL and enrich your organization’s data analytics capabilities.