Post Syndicated from Sohaib Katariwala original https://aws.amazon.com/blogs/big-data/trusted-identity-propagation-using-iam-identity-center-for-amazon-opensearch-service/
Enterprise customers of Amazon OpenSearch Service require comprehensive security controls with seamless authentication and authorization mechanisms when accessing data in provisioned domains and Amazon OpenSearch Serverless collections. Security teams within these organizations must not only maintain compliance with enterprise policies but also need to make sure that their users can access data securely, with robust identity management. AWS IAM Identity Center is a popular mechanism for identity management that provides single sign-on (SSO) capabilities for these enterprise customers. IAM Identity Center can use Security Assertion Markup Language (SAML) with both OpenSearch Service provisioned domains and OpenSearch Serverless. Now, by using trusted identity propagation, IAM Identity Center provides a new, direct method for accessing data in OpenSearch Service.
In this post, we outline how you can take advantage of this new access method to simplify data access using the OpenSearch UI and still maintain robust role-based access control for your OpenSearch data.
Trusted identity propagation overview
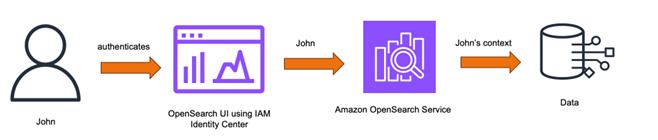
Trusted identity propagation in IAM Identity Center adds the identity context of a user to a role when accessing OpenSearch Service, which in turn uses this context to authorize and scope OpenSearch data access. This simplifies the authentication and authorization flow for customers because the applications access the data on their behalf. Users or user agents need not be present between the application and the backend services for this authorization to happen, unlike methods like SAML where a user agent needs to be present between these entities as a go-between for exchanging assertions. This flexibility helps simplify accessing a wide variety of data sources such as data residing within the Amazon Virtual Private Cloud (Amazon VPC) of an OpenSearch Service domain, or an OpenSearch Serverless collection. By using the OpenSearch UI, you can additionally simplify the backend connections, resulting in seamless access to the data. The following figures shows how the identity propagation works with OpenSearch Service.
Prerequisites
Before starting to use IAM Identity Center with OpenSearch Service, there are a few options that you must enable. To start, set up an organization or account instance of IAM Identity Center following the instruction in this guide. For OpenSearch Service-provisioned domains, you must enable the IAM Identity Center (IDC) Authentication –new option. You can do this though AWS CloudFormation, OpenSearch REST API, AWS SDK, or the AWS Management Console.
To enable Identity Center using the console
- To add the capability for an existing provisioned domain, go to the OpenSearch Service console and navigate to the Security configuration tab and choose Edit.
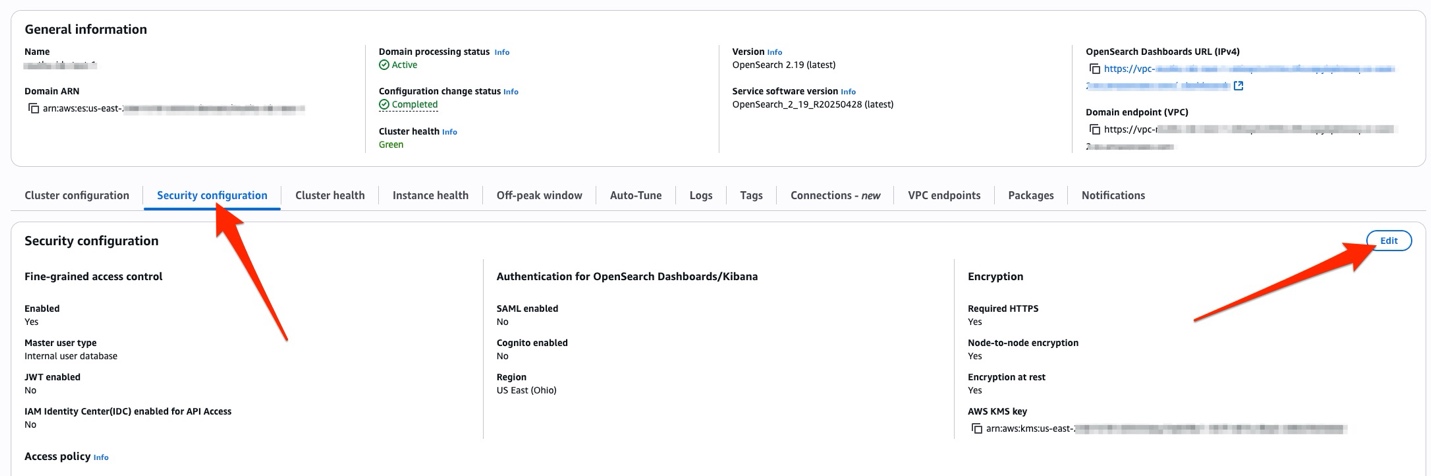
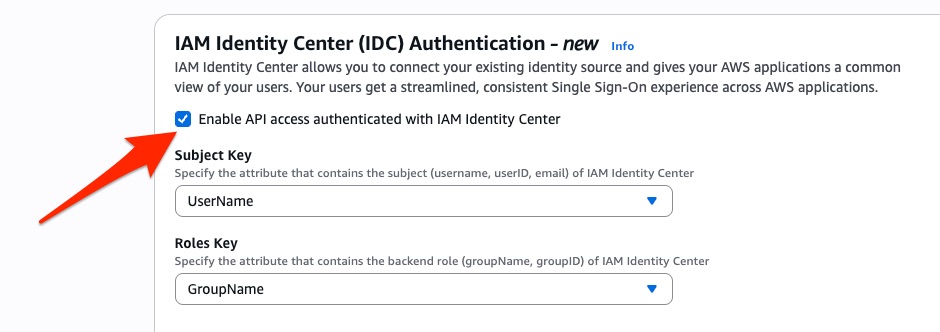
- After this step, or if you are creating new domain, select the check box for IAM Identity Center (IDC) Authentication – new.
- You have various options to choose for Subject Key and Roles Key depending upon how you want to establish your role-based access control discussed later in this post. For now, select UserName for Subject Key and GroupName for Roles Key.
- For OpenSearch Serverless, choose Serverless in the navigation pane, then Security and Authentication. Choose Edit in the IAM Identity Center (IdC) authentication – new section.
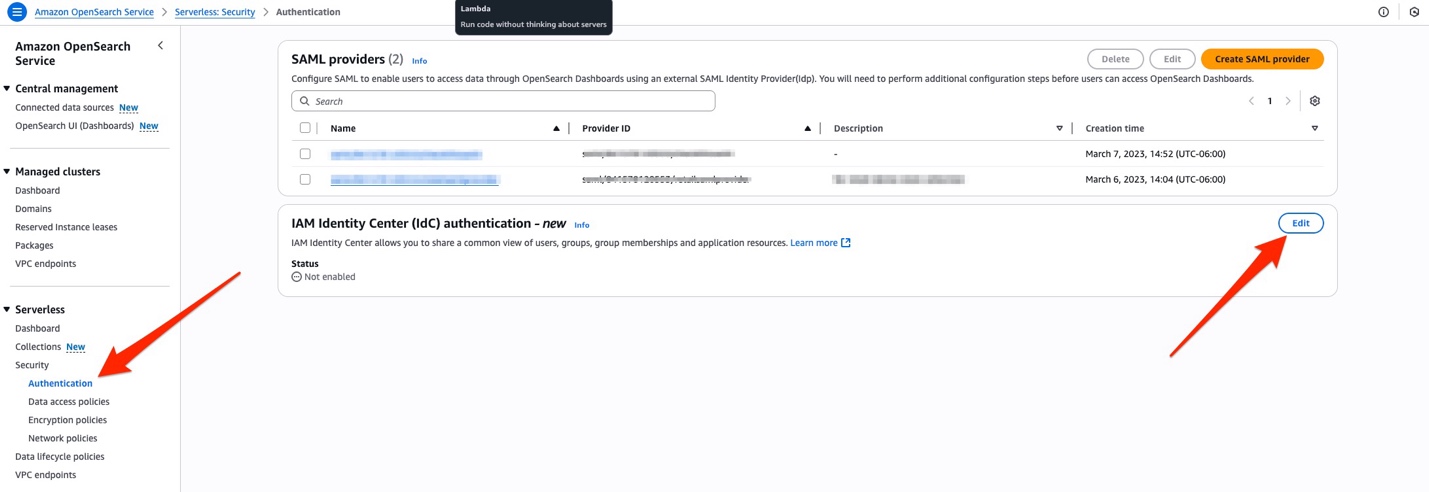
- Select the checkbox for Authenticate with IAM Identity Center, and then choose Save.

- Select the checkbox for Authentication with IAM Identity Center under Single sign-on authentication, when creating an OpenSearch UI application. For step-by-step instructions on how to create an OpenSearch UI application, see Creating an OpenSearch UI application
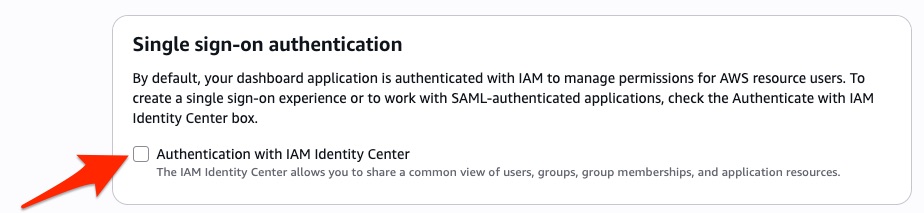
After these steps, you’re ready to configure IAM Identity Center by creating new users and groups, or by using existing user identities.
Propagating IAM Identity Center identities
Currently, adding single sign-on authentication with IAM Identity Center can be done while setting up a new OpenSearch UI application. Use the following steps to create a new OpenSearch UI application. Note that single sign-on currently cannot be turned on after an application is created. After single sign-on is enabled, you should see an AWS managed application under Applications in the Identity Center console.

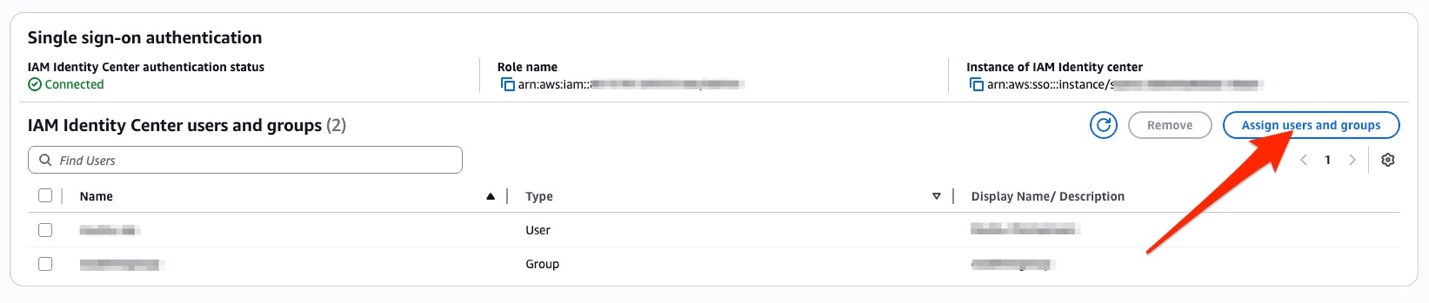
Assigning users and groups
After the application is created and the status shows as Active, you need to assign users and groups to the application. This assignment is important and recommended because these assignments determine the scope and permissions for data access within OpenSearch Service. To do this, select the application you created in the previous steps in the OpenSearch Service console. Here, you will see an option for IAM Identity Center user and groups under Single sign-on authentication. Choose Assign users and groups and select the appropriate Identity Center users and groups.
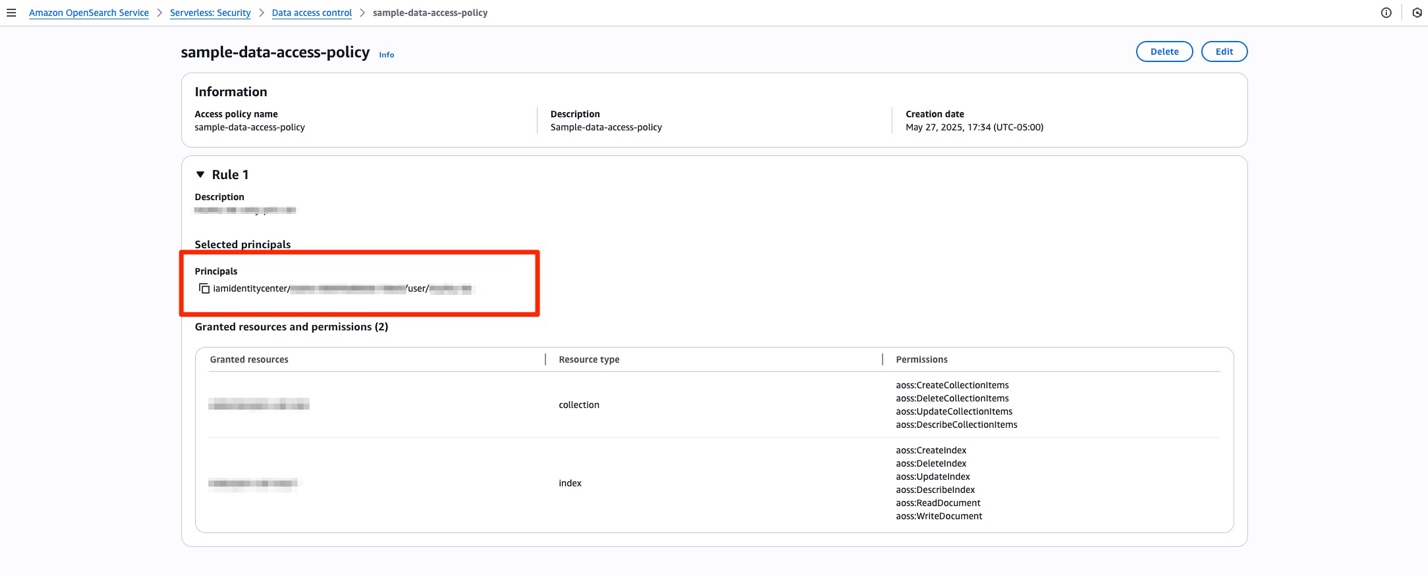
For OpenSearch Serverless, you must create a new data access policy or add a rule to an existing one to grant IAM Identity Center principals appropriate permissions to access the collections. For example, the following figure shows a data access policy that grants specific permissions to a one user with Rule 1 and provide a more restrictive permission to a group with Rule 2.
At this point your OpenSearch Service domains, OpenSearch Serverless collections and OpenSearch UI are set up for identity propagation.
Fine grained access control for IAM Identity Center identities
Fine grained access control is a role-based access control for OpenSearch Service that provides security at index, document, and field levels for provisioned domains. You can choose what aspects of identity context you propagate to OpenSearch Service. You can choose between UserId, UserName, and Email for your Subject keys, and GroupId and GroupName for your Roles key. This configuration is important because the values of the properties in the identity context are used to match exactly with the user and backend role mapping within OpenSearch Service provisioned domains. Note that if IAM Identity Center sign-on isn’t enabled, OpenSearch Service can only evaluate the request signature with AWS signature Version 4. This means that the role your OpenSearch UI will use won’t contain identity context for authorization. To complete authorization, add the values of the identity context fields to the OpenSearch role mapping. See Mapping roles to users under Managing permissions. Role mapping can be done using OpenSearch REST API, AWS SDK, or using OpenSearch Dashboards.
To map roles using OpenSearch Dashboards
- From the menu icon
 on the top left corner or your screen, select Management, Security, Roles, <Your role>.
on the top left corner or your screen, select Management, Security, Roles, <Your role>. - Choose the Mapped Users tab and select Manage mapping.
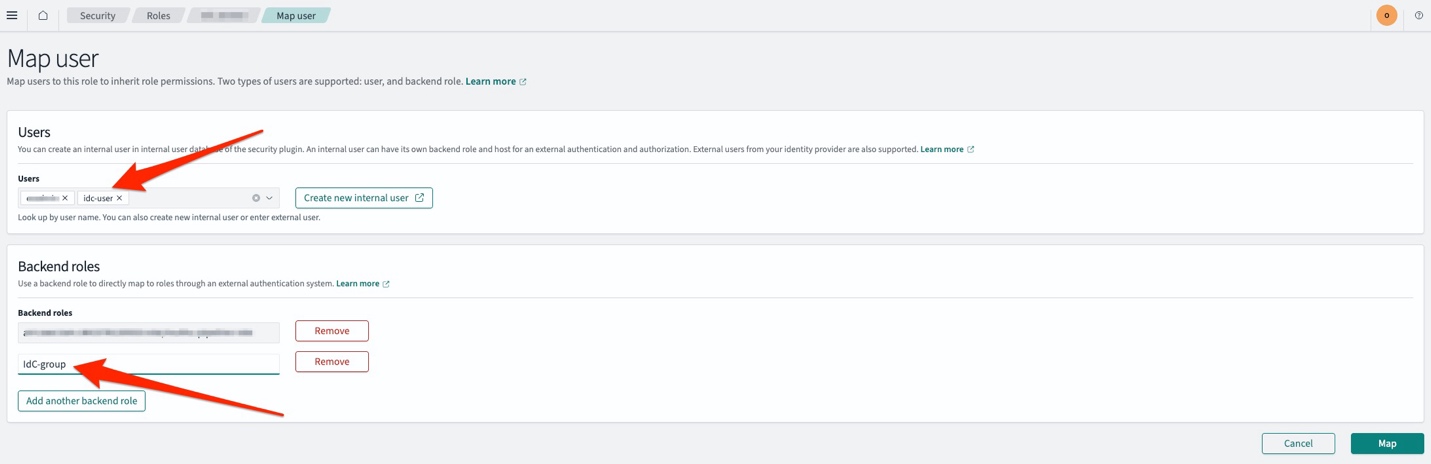
- When mapping the role, make sure that you enter the values corresponding to the Subject key. This value must be the same as in your identity context. Additionally, use the Roles key to assign access-based IAM Identity Center groups.
With OpenSearch Serverless, the granularity of access control is at the index level so you will need to add additional rules in the Data Access Policy to control principals who can access collections or indices within a collection.
Verifying identity propagation
The final step is to verify identity propagation.
- Open the OpenSearch UI application and select IAM Identity Center from the Login drop down.
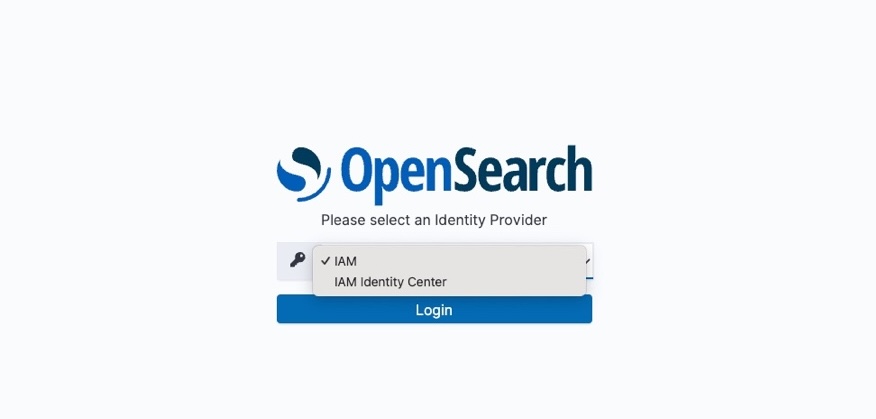
- After you complete the login process with IAM Identity Center, the OpenSearch UI will open. Choose the user icon in the lower left corner of the screen to verify that it’s your correct principal from Identity Center. It should match the Identity Center property you chose earlier.
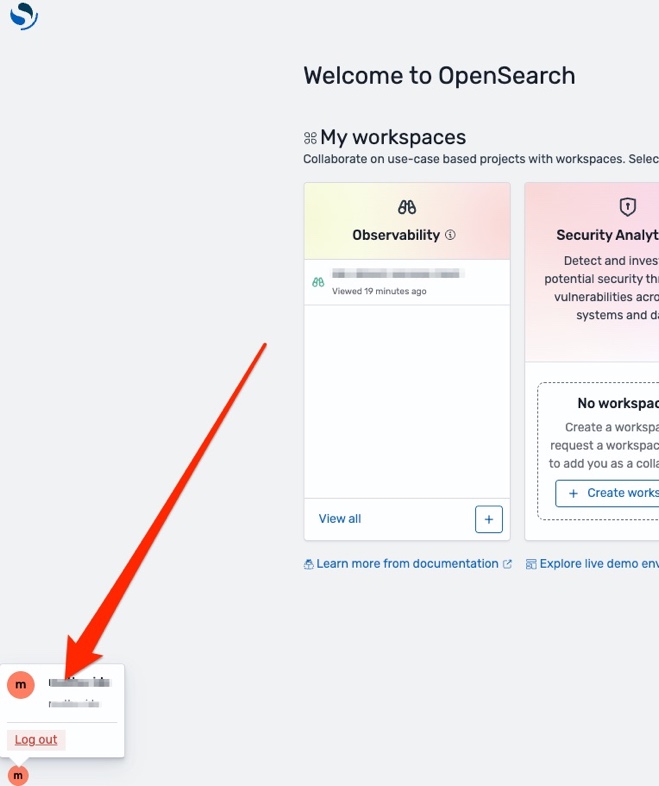
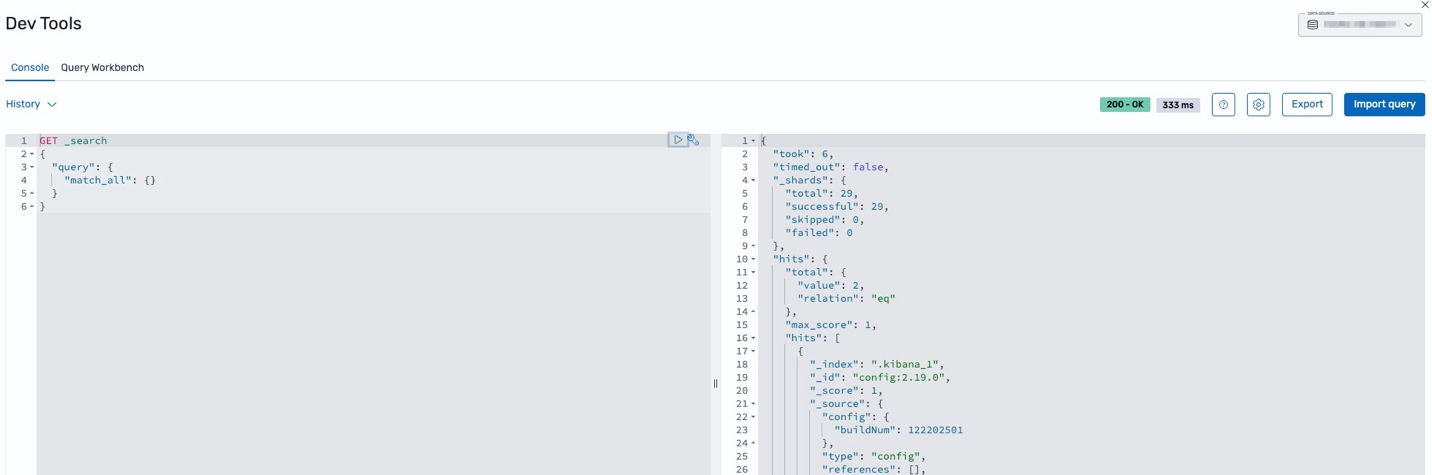
- To verify correct identity propagation, choose the Dev tools
 icon just above the user profile icon in the bottom left corner of the screen.
icon just above the user profile icon in the bottom left corner of the screen. - Select the correct OpenSearch domain or OpenSearch Serverless collection data source in the top right corner of the screen and run a
_searchquery. You should see results from the data source confirming that the identity is correctly propagated to OpenSearch Service.
Conclusion
In this post, we showed you how to use Trusted Identity Propagation using IAM Identity Center for Amazon OpenSearch Service, providing a streamlined approach to secure data access while maintaining robust access controls. This solution offers several key benefits:
- Simplified authentication: By eliminating the need for user agents between applications and backend services, the solution streamlines the authentication process compared to traditional SAML-based approaches.
- Enhanced security: The integration maintains comprehensive security controls while providing seamless authentication and authorization mechanisms for both OpenSearch Service provisioned domains and Amazon OpenSearch Serverless collections.
- Flexible identity management: Organizations can use existing IAM Identity Center implementations to manage user access, making it easier to maintain compliance with enterprise security policies.
- Fine-grained access control: The solution supports detailed access control at the index, document, and field level for provisioned domains, allowing organizations to implement precise security measures.
Get started implementing this solution in your environment today!
For more information about identity management and security best practices with OpenSearch Service, we recommend:
- Identity Center Trusted Identity Propagation Support for Amazon OpenSearch Service
- Getting Started with IAM Identity Center
- Amazon OpenSearch Service Security Best Practices
- OpenSearch UI overview
About the authors
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
 Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
 Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books. Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems. Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards. Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.
Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.