Post Syndicated from Sudarshan Roy original https://aws.amazon.com/blogs/architecture/migrating-to-an-amazon-redshift-cloud-data-warehouse-from-microsoft-aps/
Before cloud data warehouses (CDWs), many organizations used hyper-converged infrastructure (HCI) for data analytics. HCIs pack storage, compute, networking, and management capabilities into a single “box” that you can plug into your data centers. However, because of its legacy architecture, an HCI is limited in how much it can scale storage and compute and continue to perform well and be cost-effective. Using an HCI can impact your business’s agility because you need to plan in advance, follow traditional purchase models, and maintain unused capacity and its associated costs. Additionally, HCIs are often proprietary and do not offer the same portability, customization, and integration options as with open-standards-based systems. Because of their proprietary nature, migrating HCIs to a CDW can present technical hurdles, which can impact your ability to realize the full potential of your data.
One of these hurdles includes using AWS Schema Conversion Tool (AWS SCT). AWS SCT is used to migrate data warehouses, and it supports several conversions. However, when you migrate Microsoft’s Analytics Platform System (APS) SQL Server Parallel Data Warehouse (PDW) platform using only AWS SCT, it results in connection errors due to the lack of server-side cursor support in Microsoft APS. In this blog post, we show you three approaches that use AWS SCT combined with other AWS services to migrate Microsoft’s Analytics Platform System (APS) SQL Server Parallel Data Warehouse (PDW) HCI platform to Amazon Redshift. These solutions will help you overcome elasticity, scalability, and agility constraints associated with proprietary HCI analytics platforms and future proof your analytics investment.
AWS Schema Conversion Tool
Though using AWS SCT only will result in server-side cursor errors, you can pair it with other AWS services to migrate your data warehouses to AWS. AWS SCT converts source database schema and code objects, including views, stored procedures, and functions, to be compatible with a target database. It highlights objects that require manual intervention. You can also scan your application source code for embedded SQL statements as part of database-schema conversion project. During this process, AWS SCT optimizes cloud-native code by converting legacy Oracle and SQL Server functions to their equivalent AWS service. This helps you modernize applications simultaneously. Once conversion is complete, AWS SCT can also migrate data.
Figure 1 shows a standard AWS SCT implementation architecture.

Figure 1. AWS SCT migration approach
The next section shows you how to pair AWS SCT with other AWS services to migrate a Microsoft APS PDW to Amazon Redshift CDW. We prove you a base approach and two extensions to use for data warehouses with larger datasets and longer release outage windows.
Migration approach using SQL Server on Amazon EC2
The base approach uses Amazon Elastic Compute Cloud (Amazon EC2) to host a SQL Server in a symmetric multi-processing (SMP) architecture that is supported by AWS SCT, as opposed to Microsoft’s APS PDW’s massively parallel processing (MPP) architecture. By changing the warehouse’s architecture from MPP to SMP and using AWS SCT, you’ll avoid server-side cursor support errors.
Here’s how you’ll set up the base approach (Figure 2):
- Set up the SMP SQL Server on Amazon EC2 and AWS SCT in your AWS account.
- Set up Microsoft tools, including SQL Server Data Tools (SSDT), remote table copy, and SQL Server Integration Services (SSIS).
- Use the Application Diagnostic Utility (ADU) and SSDT to connect and extract table lists, indexes, table definitions, view definitions, and stored procedures.
- Generate data description languages (DDLs) using step 3 outputs.
- Apply these DDLs to the SMP SQL Server on Amazon EC2.
- Run AWS SCT against the SMP SQL database to begin migrating schema and data to Amazon Redshift.
- Extract data using remote table copy from source, which copies data into the SMP SQL Server.
- Load this data into Amazon Redshift using AWS SCT or AWS Database Migration Service (AWS DMS).
- Use SSIS to load delta data from source to the SMP SQL Server on Amazon EC2.
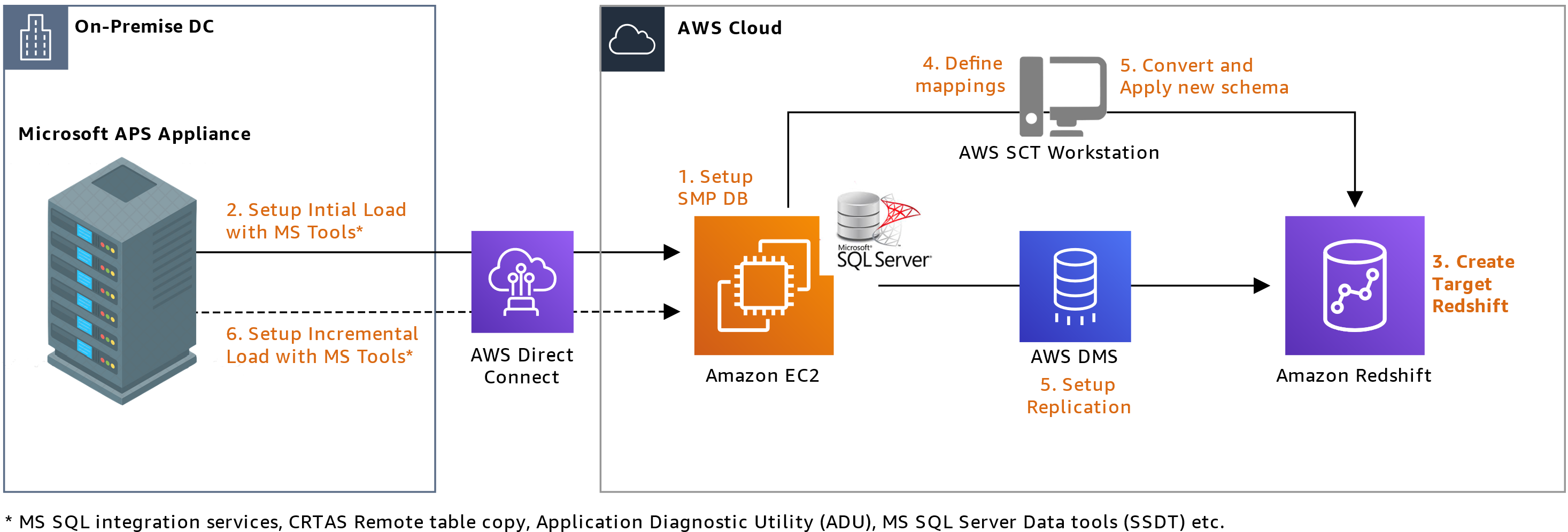
Figure 2. Base approach using SMP SQL Server on Amazon EC2
Extending the base approach
The base approach overcomes server-side issues you would have during a direct migration. However, many organizations host terabytes (TB) of data. To migrate such a large dataset, you’ll need to adjust your approach.
The following sections extend the base approach. They still use the base approach to convert the schema and procedures, but the dataset is handled via separate processes.
Extension 1: AWS Snowball Edge
Note: AWS Snowball Edge is a Region-specific service. Verify that the service is available in your Region before planning your migration. See Regional Table to verify availability.
Snowball Edge lets you transfer large datasets to the cloud at faster-than-network speeds. Each Snowball Edge device can hold up to 100 TB and uses 256-bit encryption and an industry-standard Trusted Platform Module to ensure security and full chain-of-custody for your data. Furthermore, higher volumes can be transferred by clustering 5–10 devices for increased durability and storage.
Extension 1 enhances the base approach to allow you to transfer large datasets (Figure 3) while simultaneously setting up an SMP SQL Server on Amazon EC2 for delta transfers. Here’s how you’ll set it up:
- Once Snowball Edge is enabled in the on-premises environment, it allows data transfer via network file system (NFS) endpoints. The device can then be used with standard Microsoft tools like SSIS, remote table copy, ADU, and SSDT.
- While the device is being shipped back to an AWS facility, you’ll set up an SMP SQL Server database on Amazon EC2 to replicate the base approach.
- After your data is converted, you’ll apply a converted schema to Amazon Redshift.
- Once the Snowball Edge arrives at the AWS facility, data is transferred to the SMP SQL Server database.
- You’ll subsequently run schema conversions and initial and delta loads per the base approach.
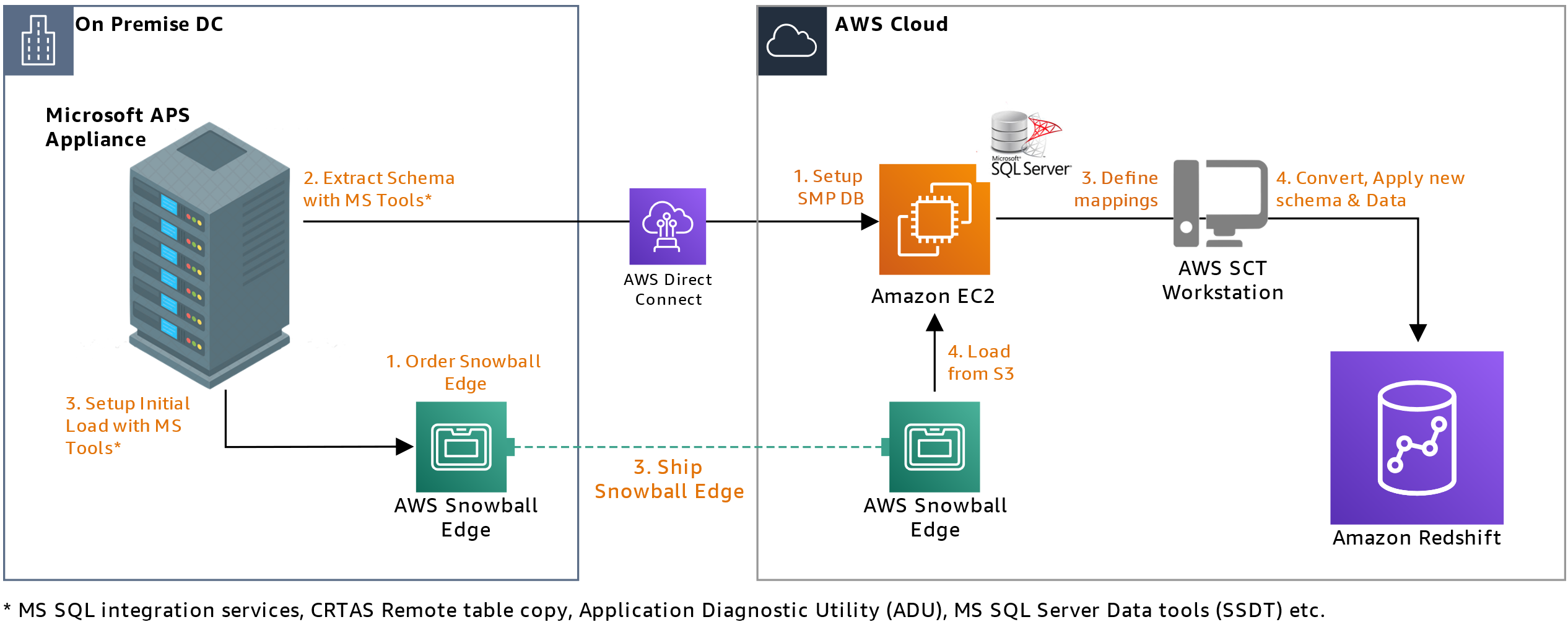
Figure 3. Solution extension that uses Snowball Edge for large datasets
Note: Where sequence numbers overlap in the diagram is a suggestion to possible parallel execution
Extension 1 transfers initial load and later applies delta load. This adds time to the project because of longer cutover release schedules. Additionally, you’ll need to plan for multiple separate outages, Snowball lead times, and release management timelines.
Note that not all analytics systems are classified as business-critical systems, so they can withstand a longer outage, typically 1-2 days. This gives you an opportunity to use AWS DataSync as an additional extension to complete initial and delta load in a single release window.
Extension 2: AWS DataSync
DataSync speeds up data transfer between on-premises environments and AWS. It uses a purpose-built network protocol and a parallel, multi-threaded architecture to accelerate your transfers.
Figure 4 shows the solution extension, which works as follows:
- Create SMP MS SQL Server on EC2 and the DDL, as shown in the base approach.
- Deploy DataSync agent(s) in your on-premises environment.
- Provision and mount an NFS volume on the source analytics platform and DataSync agent(s).
- Define a DataSync transfer task after the agents are registered.
- Extract initial load from source onto the NFS mount that will be uploaded to Amazon Simple Storage Service (Amazon S3).
- Load data extracts into the SMP SQL Server on Amazon EC2 instance (created using base approach).
- Run delta loads per base approach, or continue using solution extension for delta loads.

Figure 4. Solution extension that uses DataSync for large datasets
Note: where sequence numbers overlap in the diagram is a suggestion to possible parallel execution
Transfer rates for DataSync depend on the amount of data, I/O, and network bandwidth available. A single DataSync agent can fully utilize a 10 gigabit per second (Gbps) AWS Direct Connect link to copy data from on-premises to AWS. As such, depending on initial load size, transfer window calculations must be done prior to finalizing transfer windows.
Conclusion
The approach and its extensions mentioned in this blog post provide mechanisms to migrate your Microsoft APS workloads to an Amazon Redshift CDW. They enable elasticity, scalability, and agility for your workload to future proof your analytics investment.