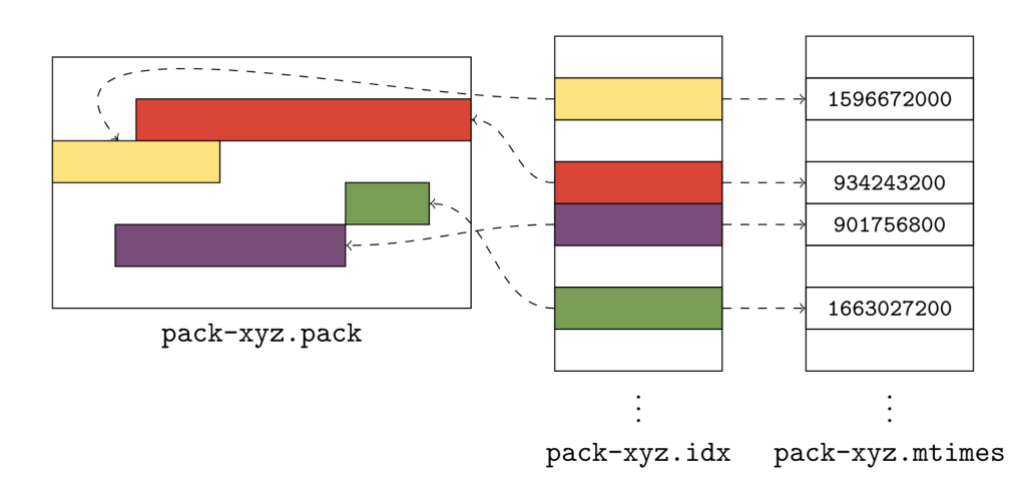
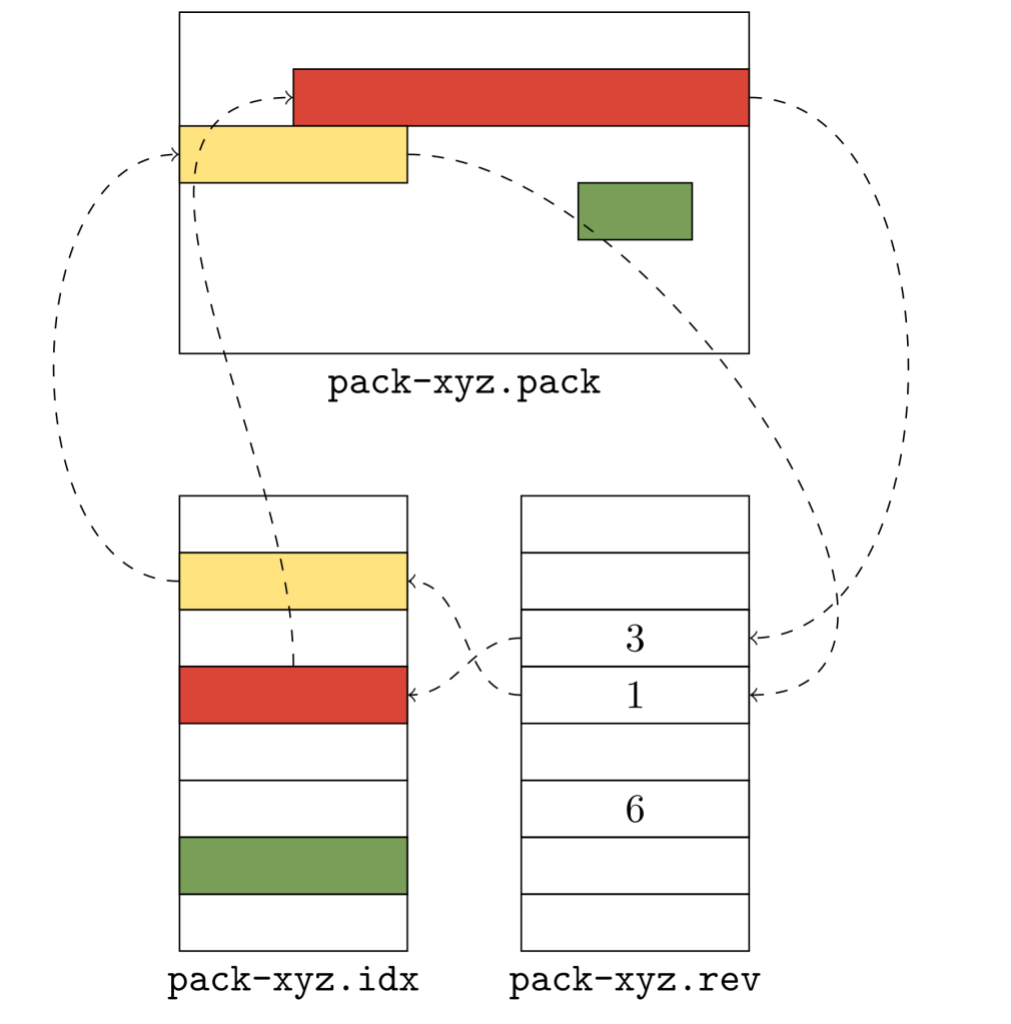
Post Syndicated from Taylor Blau original https://github.blog/2023-08-21-highlights-from-git-2-42/
The open source Git project just released Git 2.42 with features and bug fixes from over 78 contributors, 17 of them new. We last caught up with you on the latest in Git back when 2.41 was released.
To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.
Faster object traversals with bitmaps
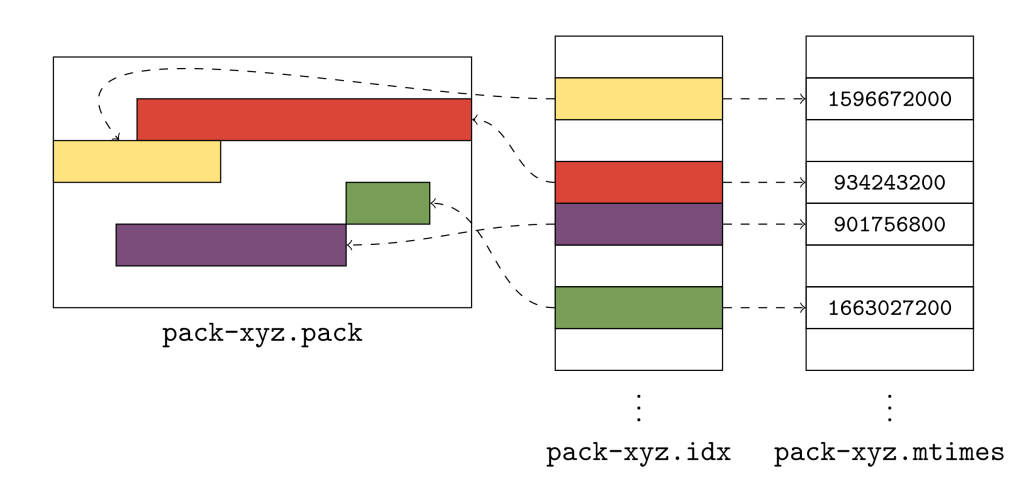
Many long-time readers of these blog posts will recall our coverage of reachability bitmaps. Most notably, we covered Git’s new multi-pack reachability bitmaps back in our coverage of the 2.34 release towards the end of 2021.
If this is your first time here, or you need a refresher on reachability bitmaps, don’t worry. Reachability bitmaps allow Git to quickly determine the result set of a reachability query, like when serving fetches or clones. Git stores a collection of bitmaps for a handful of commits. Each bit position is tied to a specific object, and the value of that bit indicates whether or not it is reachable from the given commit.
This often allows Git to compute the answers to reachability queries using bitmaps much more quickly than without, particularly for large repositories. For instance, if you want to know the set of objects unique to some branch relative to another, you can build up a bitmap for each endpoint (in this case, the branch we’re interested in, along with main), and compute the AND NOT between them. The resulting bitmap has bits set to “1” for exactly the set of objects unique to one side of the reachability query.
But what happens if one side doesn’t have bitmap coverage, or if the branch has moved on since the last time it was covered with a bitmap?
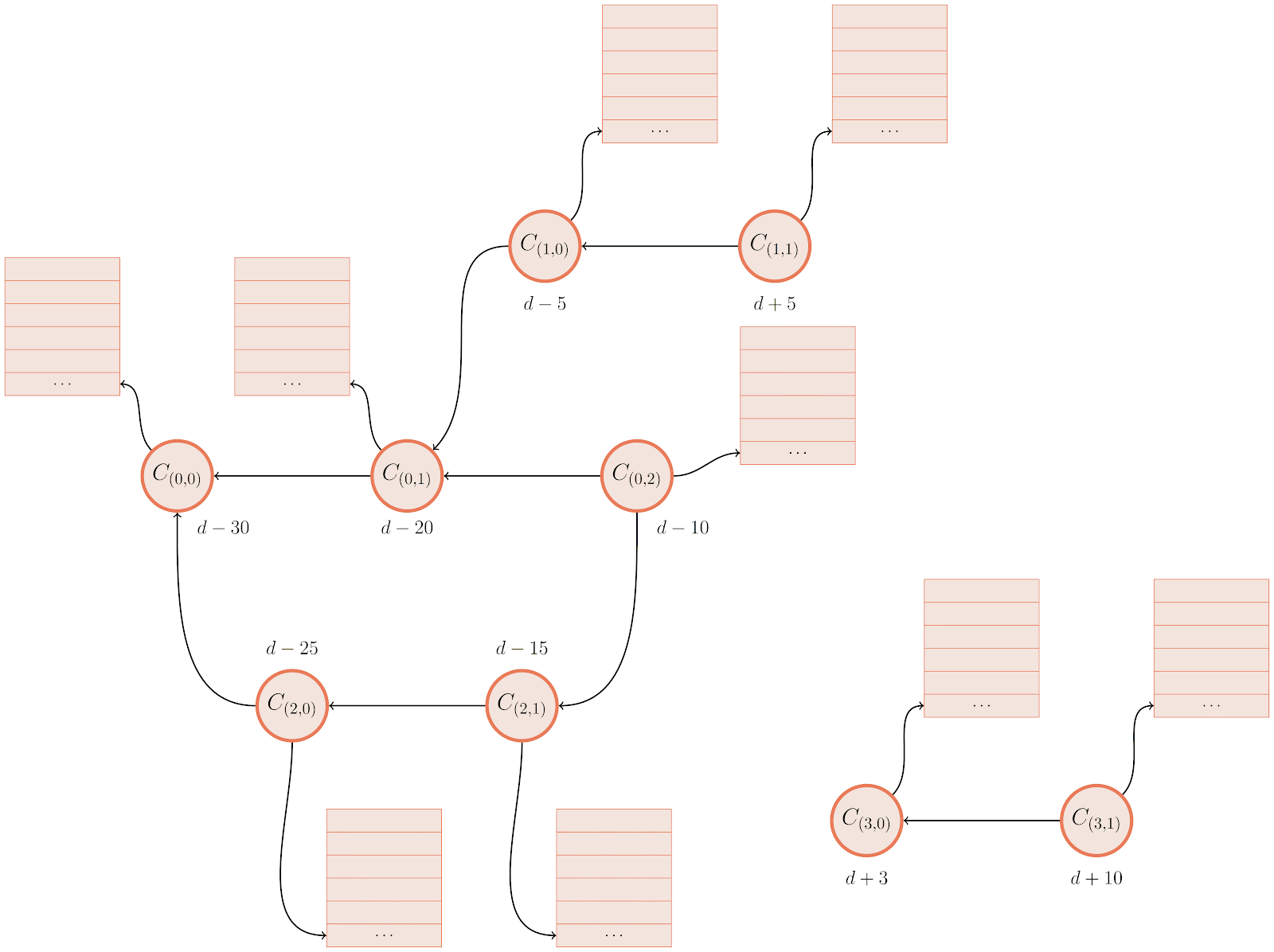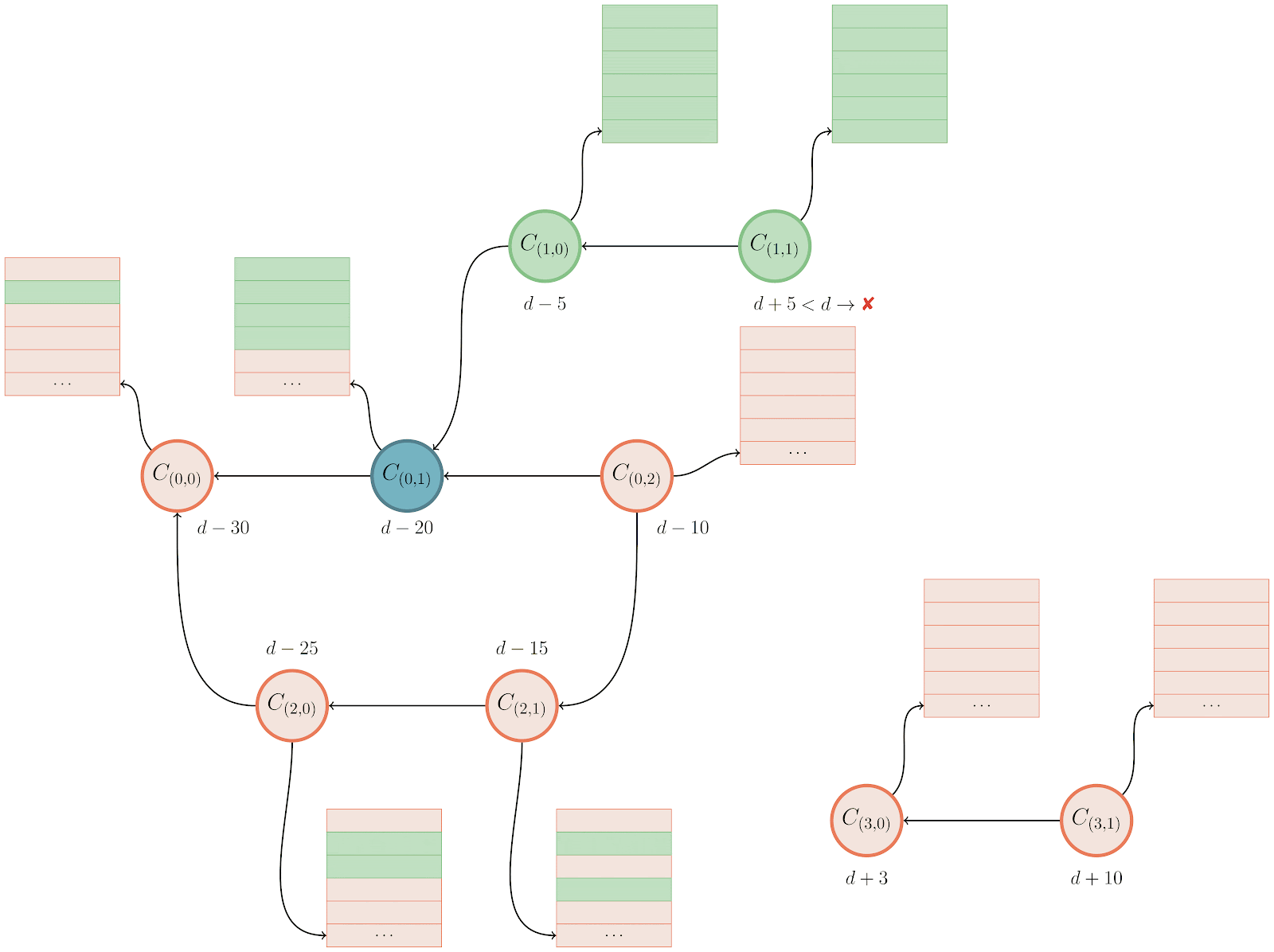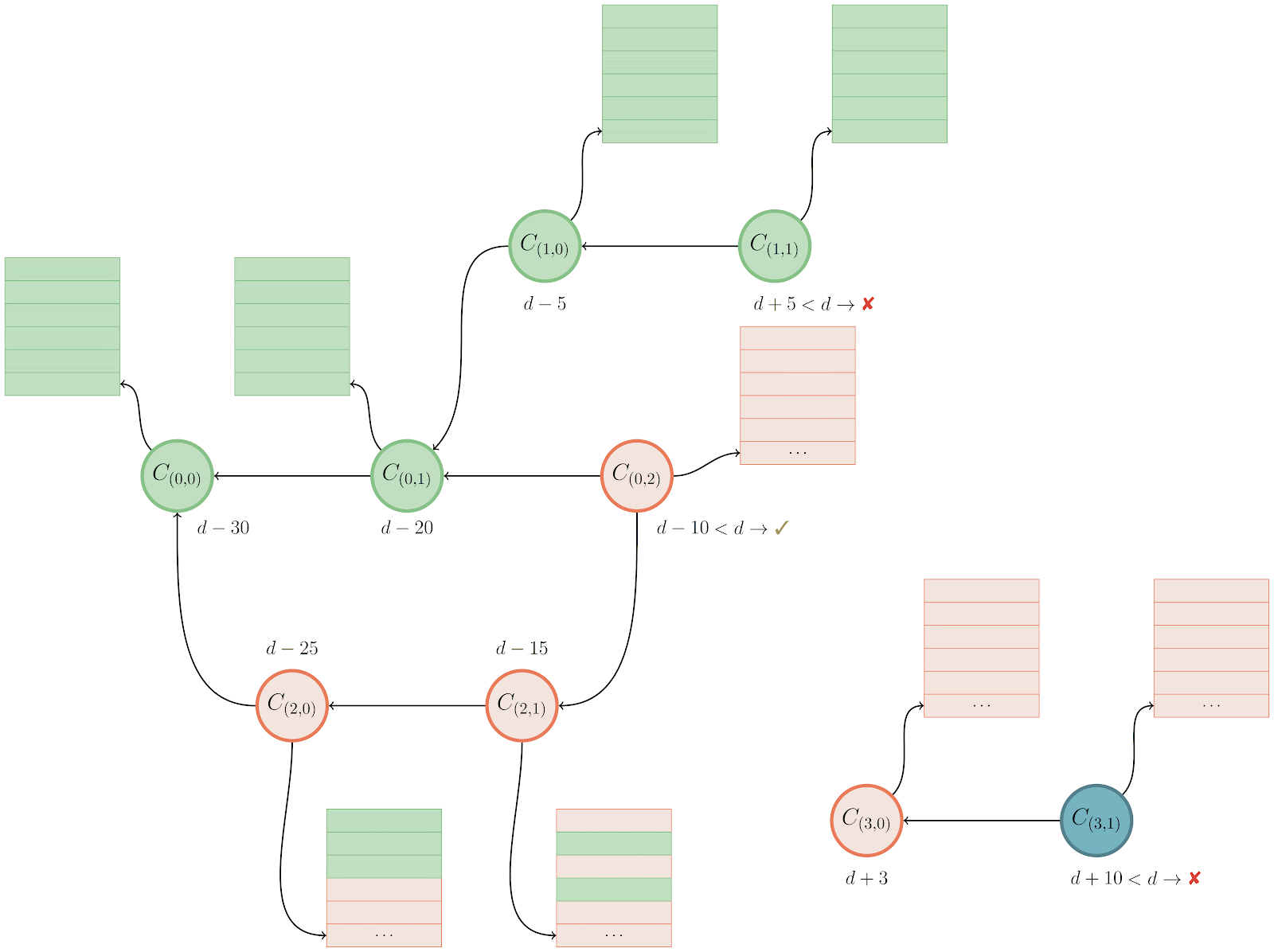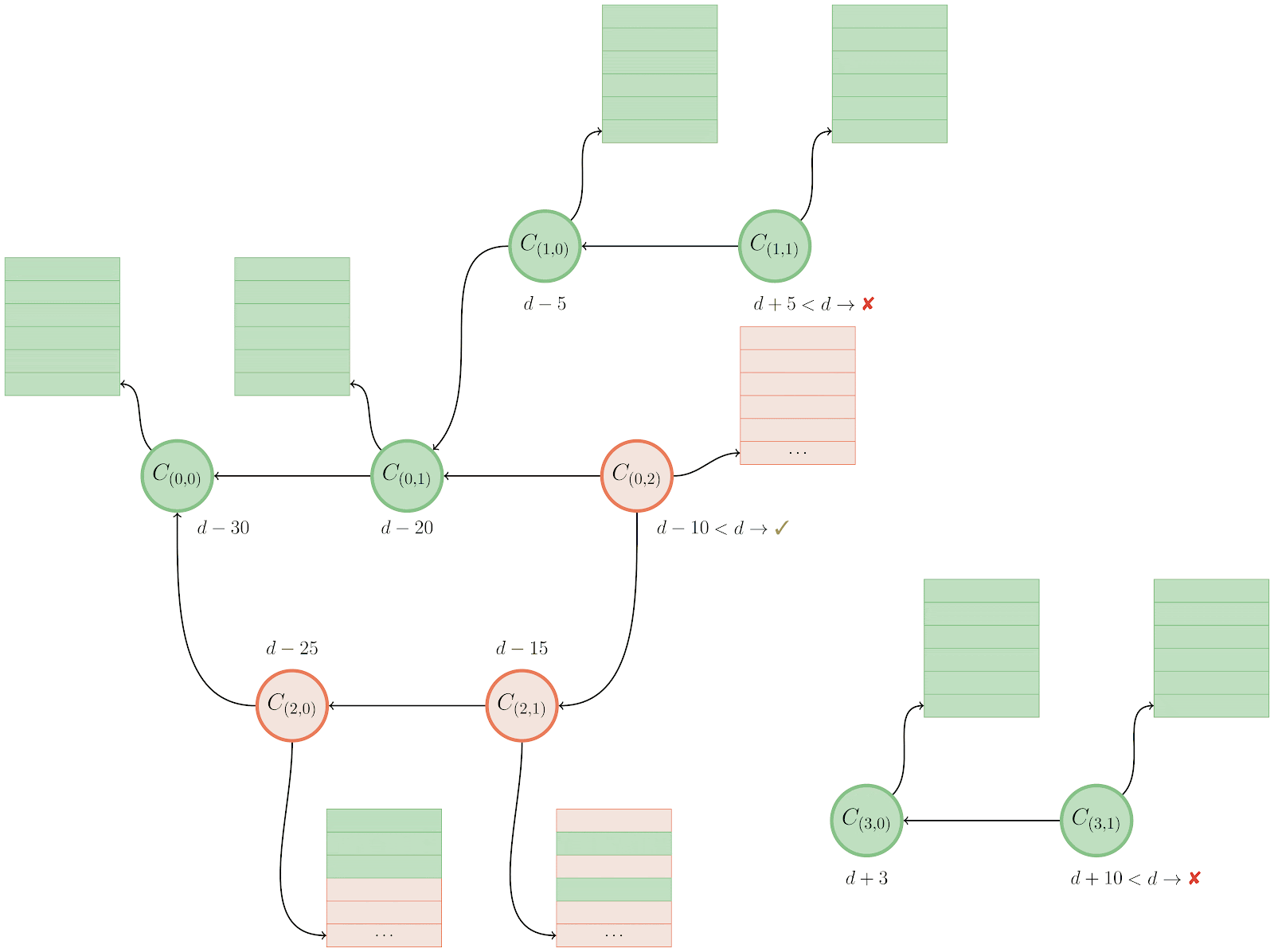
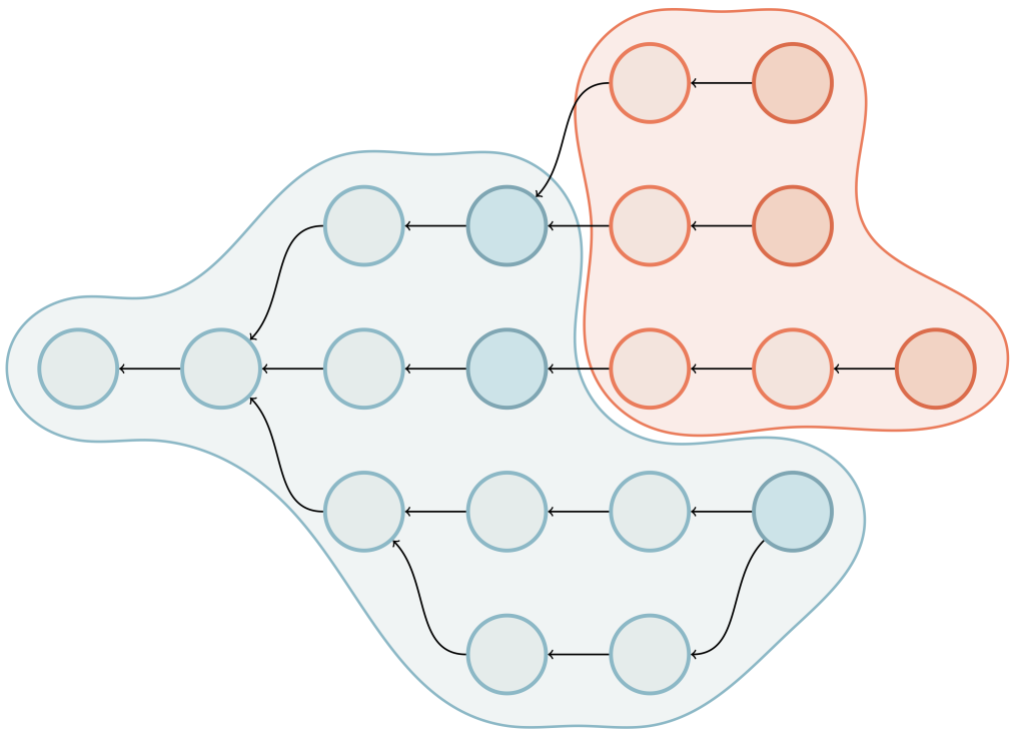
In previous versions of Git, the answer was that Git would build up a complete bitmap for all reachability tips relative to the query. It does so by walking backwards from each tip, assembling its own bitmap, and then stopping as soon as it finds an existing bitmap in history. Here’s an example of the existing traversal routine:

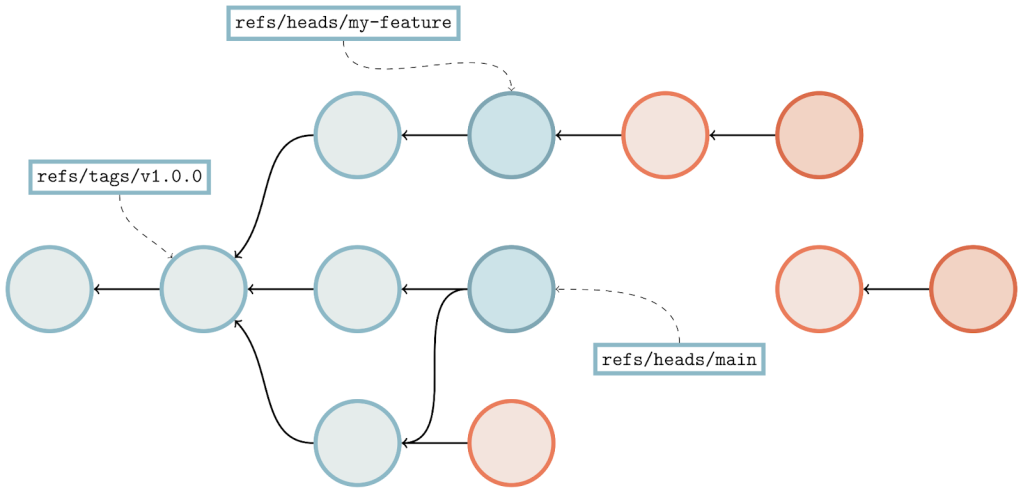
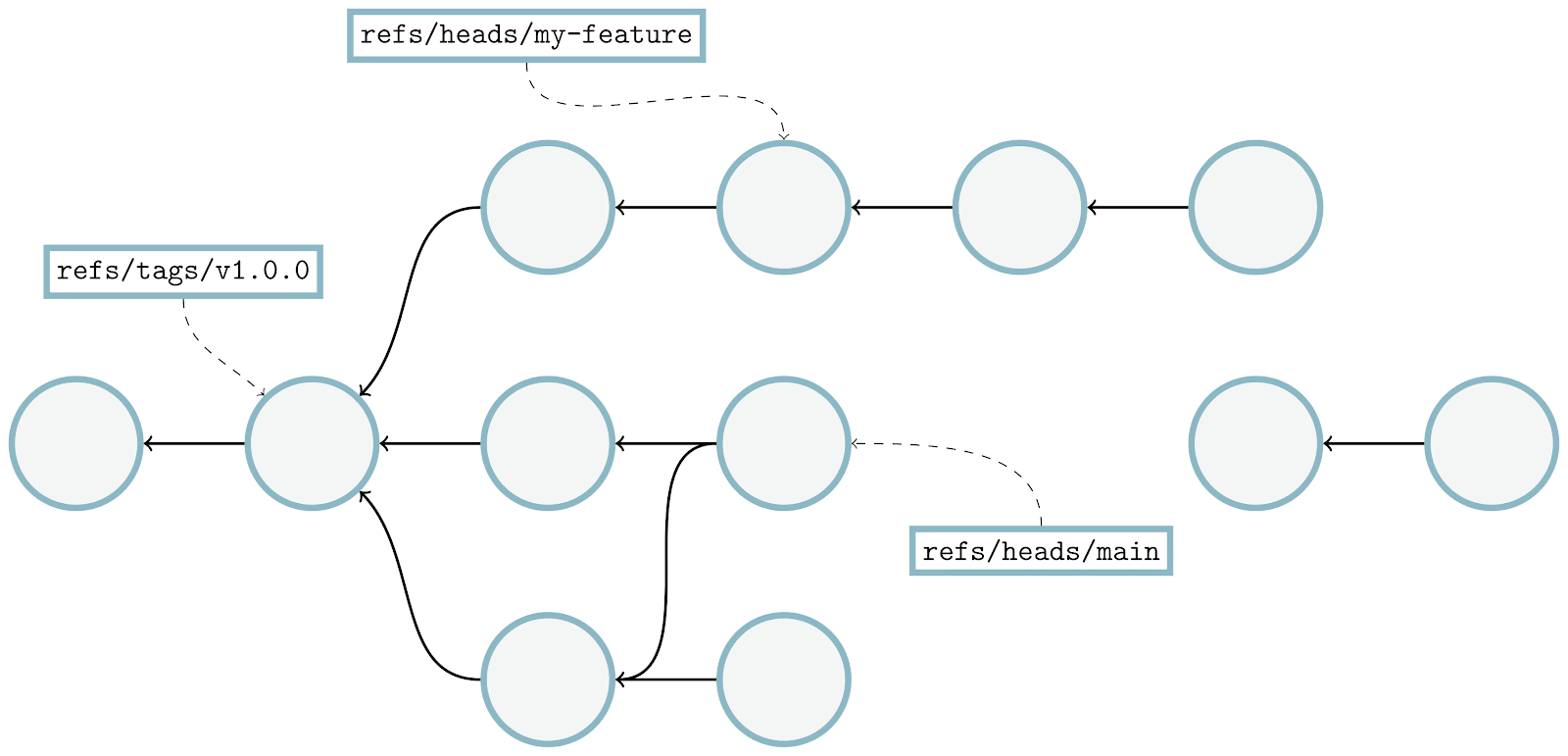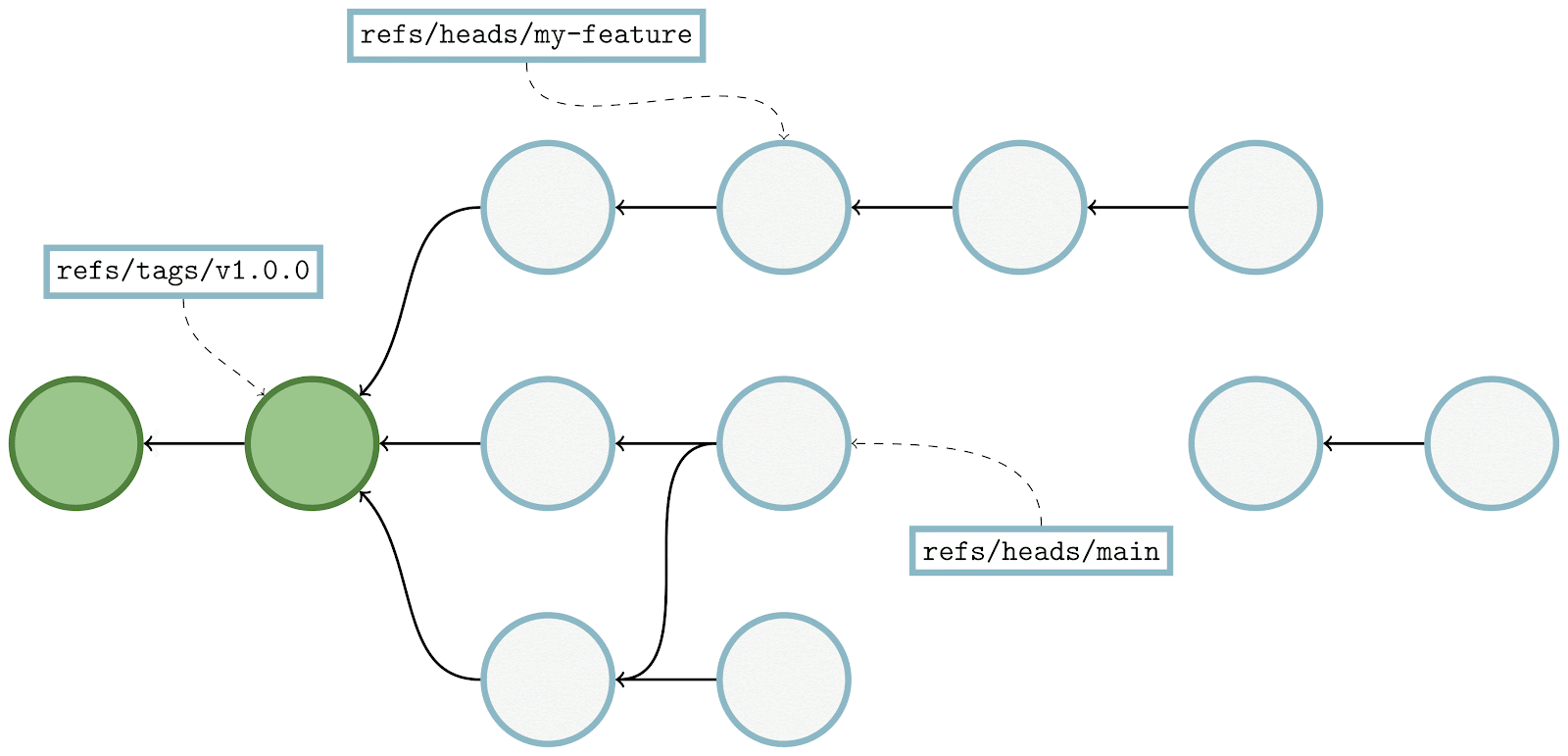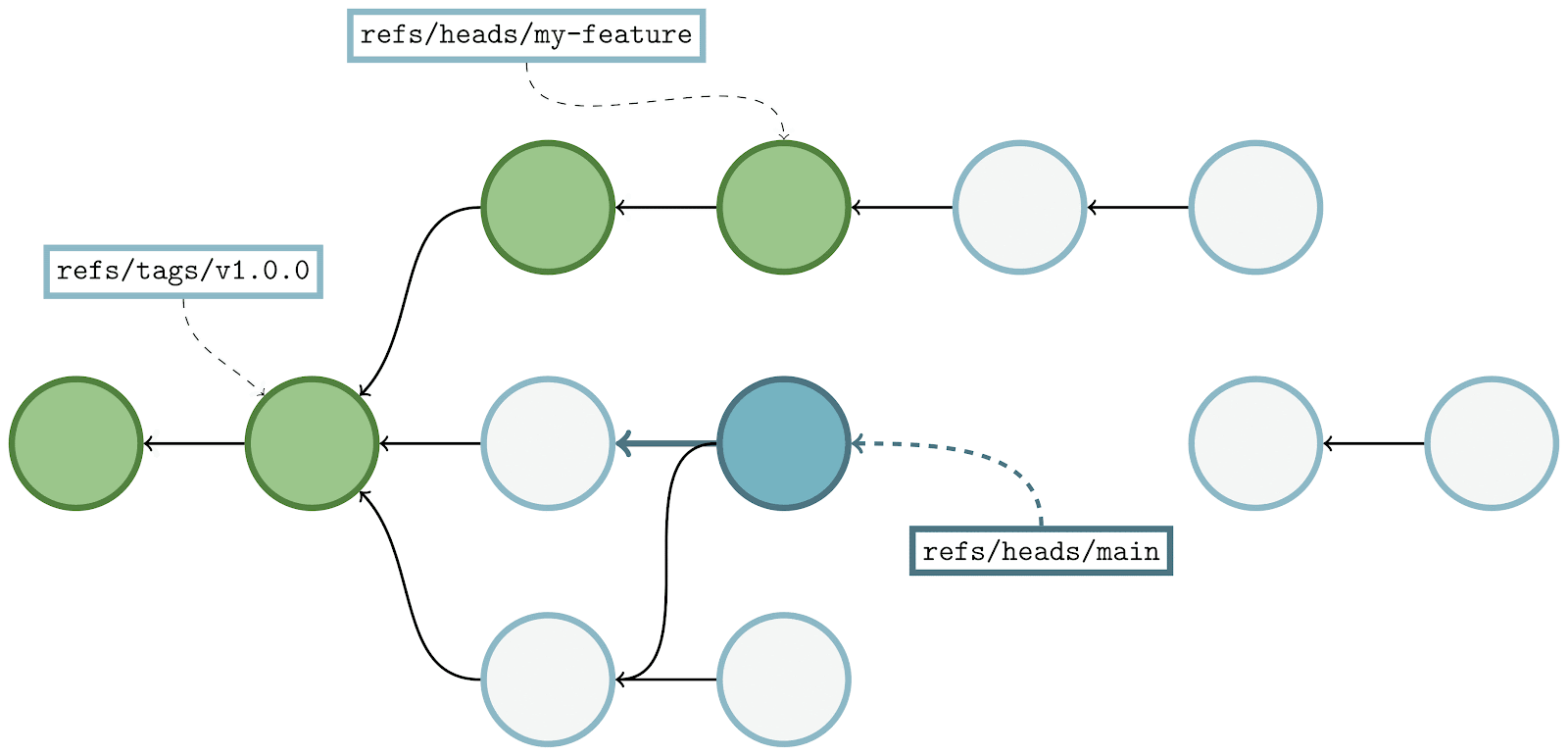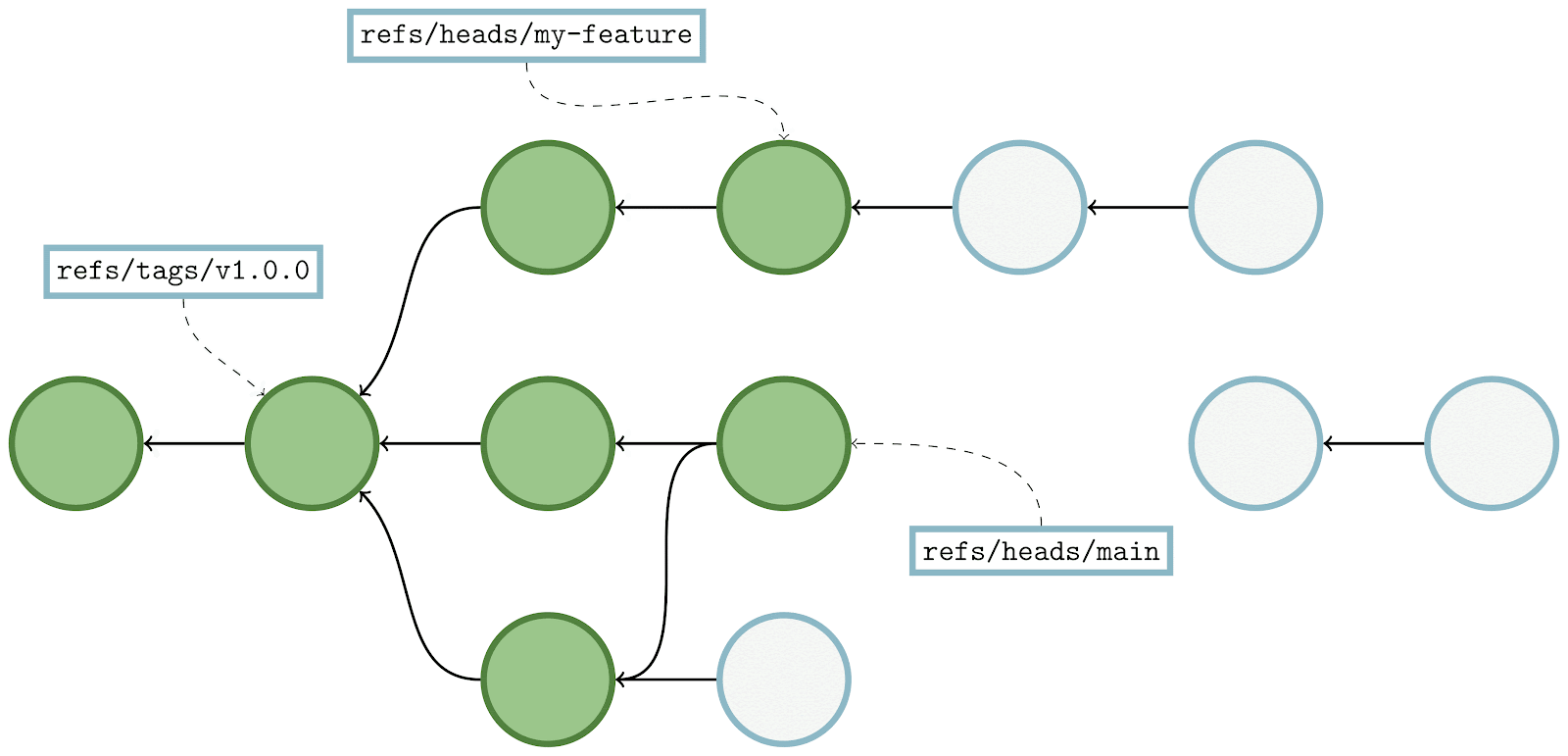
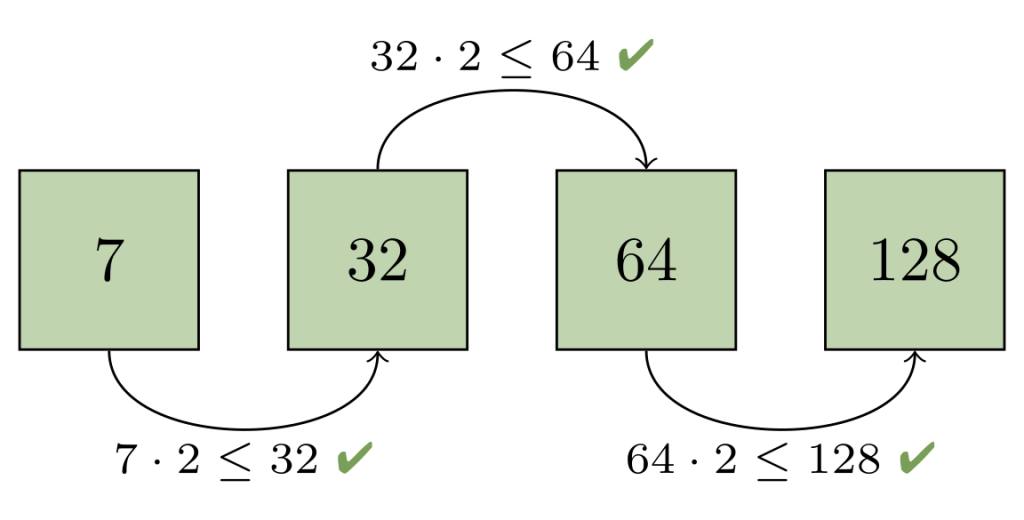
There’s a lot going on here, but let’s break it down. Above we have a commit graph, with five branches and one tag. Each of the commits are indicated by circles, and the references are indicated by squares pointing at their respective referents. Existing bitmaps can be found for both the v2.42.0 tag, and the branch bar.
In the above, we’re trying to compute the set of objects which are reachable from main, but aren’t reachable from any other branch. By inspection, it’s clear that the answer is {C₆, C₇}, but let’s step through how Git would arrive at the same result:
- For each branch that we want to exclude from the result set (in this case,
foo,bar,baz, andquux), we walk along the commit graph, marking each of the corresponding bits in ourhave‘s bitmap in the top-left. - If we happen to hit a portion of the graph that we’ve covered already, we can stop early. Likewise, if we find an existing bitmap (like what happens when we try to walk beginning at branch
bar), we canORin the bits from that commit’s bitmap into ourhave‘s set, and move on to the next branch. - Then, we repeat the same process for each branch we do want to keep (in this case, just
main), this time marking orORing bits into thehave‘s bitmap. - Finally, once we have a complete bitmap representing each side of the reachability query, we can compute the result by
AND NOTing the two bitmaps together, leaving us with the set of objects unique tomain.
We can see that in the above, having existing bitmap coverage (as is the case with branch bar) is extremely beneficial, since they allow us to discover the set of objects reachable from a certain point in the graph immediately without having to open up and parse objects.
But what happens when bitmap coverage is sparse? In that case, we end up having to walk over many objects in order to find an existing bitmap. Oftentimes, the additional overhead of maintaining a series of bitmaps outweighs the benefits of using them in the first place, particularly when coverage is poor.
In this release, Git introduces a new variant of the bitmap traversal algorithm that often out performs the existing implementation, particularly when bitmap coverage is sparse.
The new algorithm represents the unwanted side of the reachability query as a bitmap from the query’s boundary, instead of the union of bitmap(s) from the individual tips on the unwanted side. The exact definition of what a query boundary is is slightly technical, but for our purposes you can think of it as the first commit in the wanted set of objects which is also reachable from at least one unwanted object.
In the above example, this is commit C₅, which is reachable from both main (which is in the wanted half of the reachability query) along with bar and baz (both of which are in the unwanted half). Let’s step through computing the same result using the boundary-based approach:

The approach here is similar to the above, but not quite the same. Here’s the process:
- We first discover the boundary commit(s), in this case
C₅. - We then walk backwards from the set of boundary commit(s) we just discovered until we find a reachability bitmap (or reach the beginning of history). At each stage along the walk, we mark the corresponding bit in the
have‘s bitmap. - Then, we build up a complete bitmap on the
want‘s side by starting a walk frommainuntil either we hit an existing bitmap, the beginning of history, or an object marked in the previous step. - Finally, as before, we compute the
AND NOTbetween the two bitmaps, and return the results.
When there are bitmaps close to the boundary commit(s), or the unwanted half of the query is large, this algorithm often vastly outperforms the existing traversal. In the toy example above, you can see we compute the answer much more quickly when using the boundary-based approach. But in real-world examples, between a 2- and 15-fold improvement can be observed between the two algorithms.
You can try out the new algorithm by running:
$ git repack -ad --write-bitmap-index
$ git config pack.useBitmapBoundaryTraversal true
in your repository (using Git 2.42), and then using git rev-list with the --use-bitmap-index flag.
[source]
Exclude references by pattern in for-each-ref
If you’ve ever scripted around Git before, you are likely familiar with its for-each-ref command. If not, you likely won’t be surprised to learn that this command is used to enumerate references in your repository, like so:
$ git for-each-ref --sort='-*committerdate' refs/tags
264b9b3b04610cb4c25e01c78d9a022c2e2cdf19 tag refs/tags/v2.42.0-rc2
570f1f74dee662d204b82407c99dcb0889e54117 tag refs/tags/v2.42.0-rc1
e8f04c21fdad4551047395d0b5ff997c67aedd90 tag refs/tags/v2.42.0-rc0
32d03a12c77c1c6e0bbd3f3cfe7f7c7deaf1dc5e tag refs/tags/v2.41.0
[...]
for-each-ref is extremely useful for listing references, finding which references point at a given object (with --points-at), which references have been merged into a given branch (with --merged), or which references contain a given commit (with --contains).
Git relies on the same machinery used by for-each-ref across many different components, including the reference advertisement phase of pushes. During a push, the Git server first advertises a list of references that it wants the client to know about, and the client can then exclude those objects (and anything reachable from them) from the packfile they generate during the push.
Suppose that you have some references that you don’t want to advertise to clients during a push? For example, GitHub maintains a pair of references for each open pull request, like refs/pull/NNN/head and refs/pull/NNN/merge, which aren’t advertised to pushers. Luckily, Git has a mechanism that allows server operators to exclude groups of references from the push advertisement phase by configuring the transfer.hideRefs variable.
Git implements the functionality configured by transfer.hideRefs by enumerating all references, and then inspecting each one to see whether or not it should advertise that reference to pushers. Here’s a toy example of a similar process:

Here, we want to list every reference that doesn’t begin with refs/pull/. In order to do that, Git enumerates each reference one-by-one, and performs a prefix comparison to determine whether or not to include it in the set.
For repositories that have a small number of hidden references, this isn’t such a big deal. But what if you have thousands, tens of thousands, or even more hidden references? Performing that many prefix comparisons only to throw out a reference as hidden can easily become costly.
In Git 2.42, there is a new mechanism to more efficiently exclude references. Instead of inspecting each reference one-by-one, Git first locates the start and end of each excluded region in its packed-refs file. Once it has this information, it creates a jump list allowing it to skip over whole regions of excluded references in a single step, rather than discarding them one by one, like so:

Like the previous example, we still want to discard all of the refs/pull references from the result set. To do so, Git finds the first reference beginning with refs/pull (if one exists), and then performs a modified binary search to find the location of the first reference after all of the ones beginning with refs/pull.
It can then use this information (indicated by the dotted yellow arrow) to avoid looking at the refs/pull hierarchy entirely, providing a measurable speed-up over inspecting and discarding each hidden reference individually.
In Git 2.42, you can try out this new functionality with git for-each-ref‘s new --exclude option. This release also uses this new mechanism to improve the reference advertisement above, as well as analogous components for fetching. In extreme examples, this can provide a 20-fold improvement in the CPU cost of advertising references during a push.
Git 2.42 also comes with a pair of new options in the git pack-refs command, which is responsible for updating the packed-refs file with any new loose references that aren’t stored. In certain scenarios (such as a reference being frequently updated or deleted), it can be useful to exclude those references from ever entering the packed-refs file in the first place.
git pack-refs now understands how to tweak the set of references it packs using its new --include and --exclude flags.
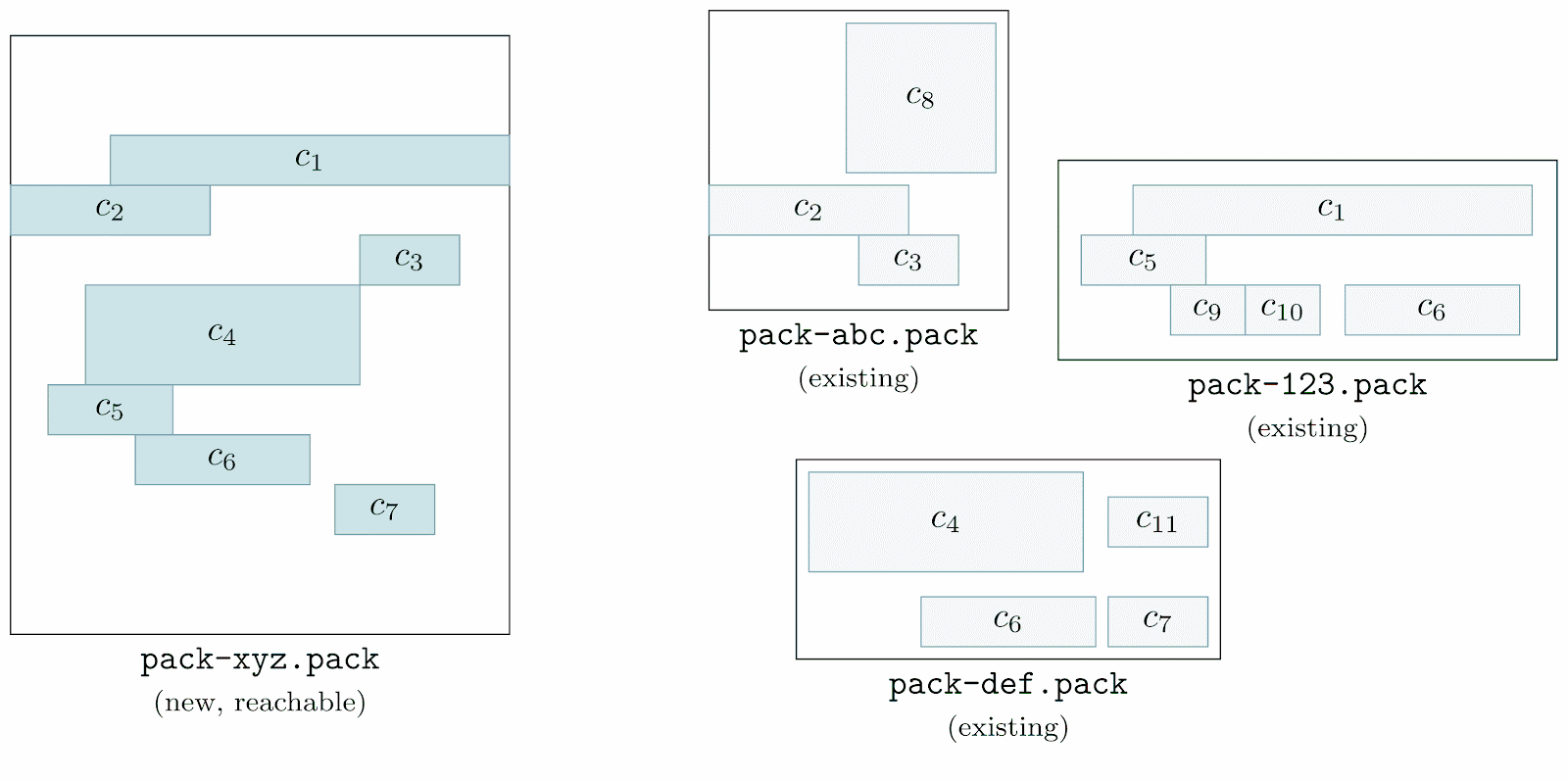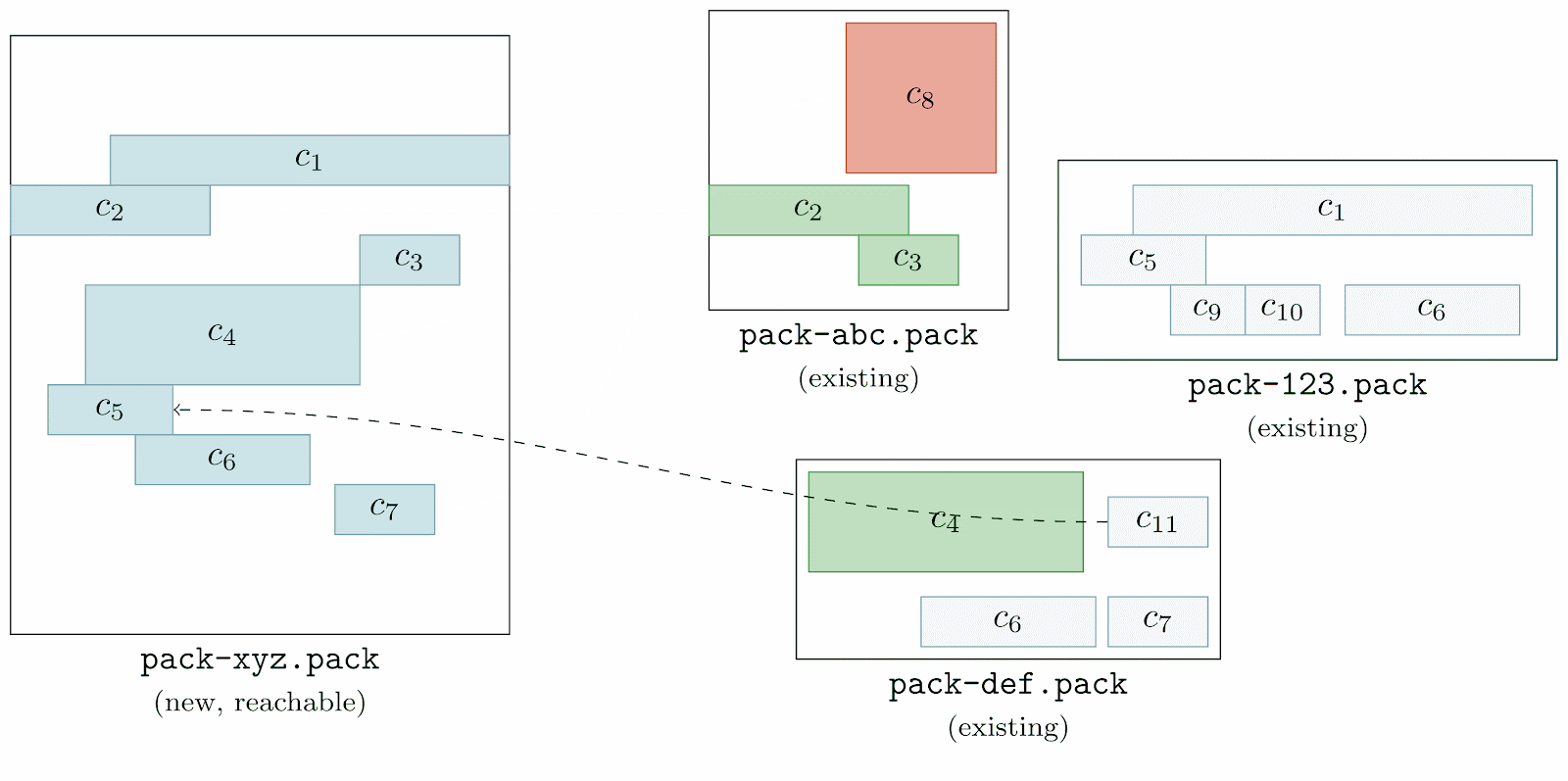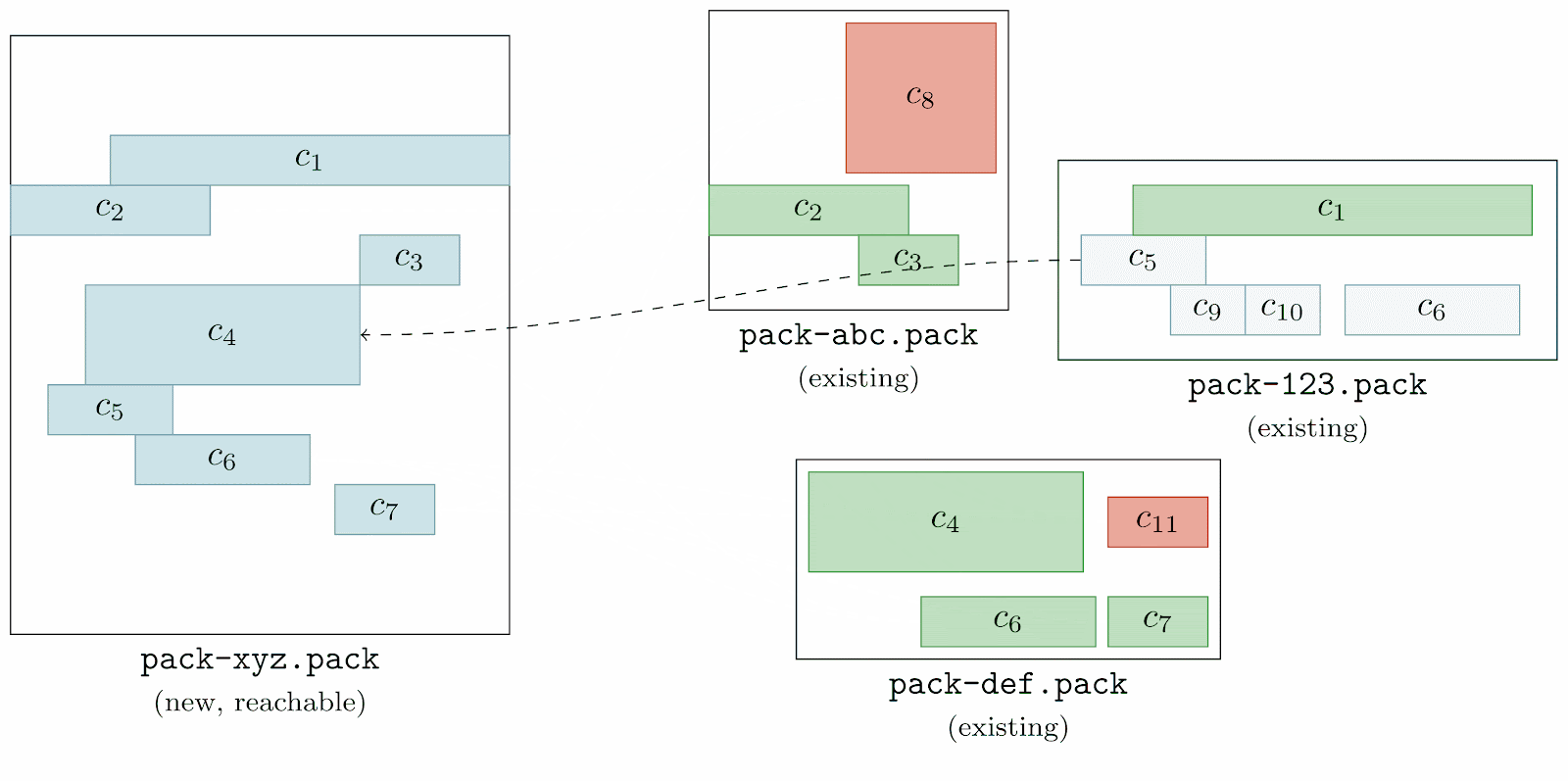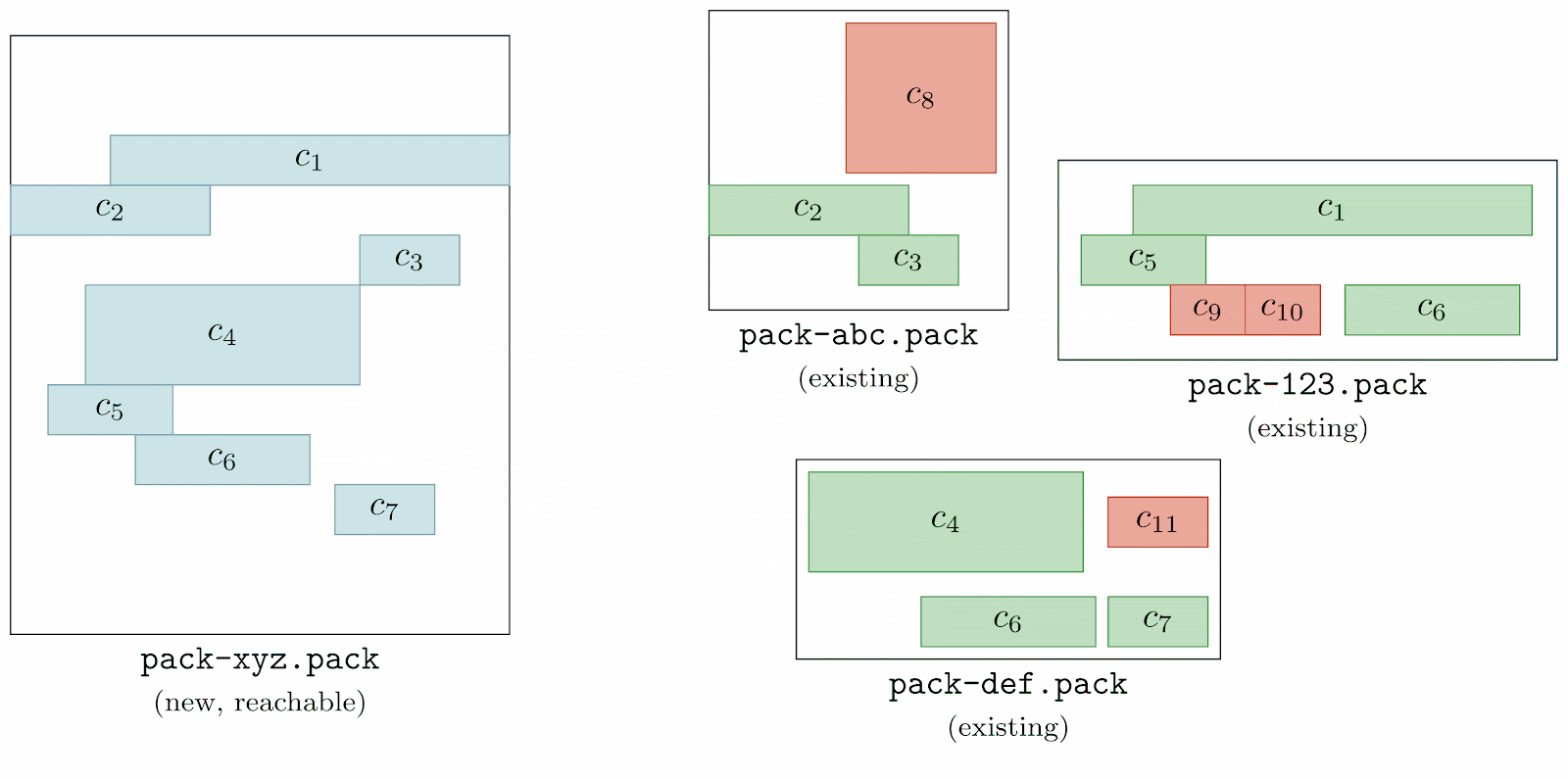
Preserving precious objects from garbage collection
In our last set of release highlights, we talked about a new mechanism for collecting unreachable objects in Git known as cruft packs. Git uses cruft packs to collect and track the age of unreachable objects in your repository, gradually letting them age out before eventually being pruned from your repository.
But Git doesn’t simply delete every unreachable object (unless you tell it to with --prune=now). Instead, it will delete every object except those that meet one of the below criteria:
- The object is reachable, in which case it cannot be deleted ever.
- The object is unreachable, but was modified after the pruning cutoff.
- The object is unreachable, and hasn’t been modified since the pruning cutoff, but is reachable via some other unreachable object which has been modified recently.
But what do you do if you want to hold onto an object (or many objects) which are both unreachable and haven’t been modified since the pruning cutoff?
Historically, the only answer to this question was that you should point a reference at those object(s). That works if you have a relatively small set of objects you want to hold on to. But what if you have more precious objects than you could feasibly keep track of with references?
Git 2.42 introduces a new mechanism to preserve unreachable objects, regardless of whether or not they have been modified recently. Using the new gc.recentObjectsHook configuration, you can configure external program(s) that Git will run any time it is about to perform a pruning garbage collection. Each configured program is allowed to print out a line-delimited sequence of object IDs, each of which is immune to pruning, regardless of its age.
Even if you haven’t started using cruft packs yet, this new configuration option works even when using loose objects to hold unreachable objects which have not yet aged out of your repository.
This makes it possible to store a potentially large set of unreachable objects which you want to retain in your repository indefinitely using an external mechanism, like a SQLite database. To try out this new feature for yourself, you can run:
$ git config gc.recentObjectsHook /path/to/your/program
$ git gc --prune=<approxidate>
- If you’ve read these blog posts before, you may recall our coverage of the sparse index feature, which allows you to check out a narrow cone of your repository instead of the whole thing.
Over time, many commands have gained support for working with the sparse index. For commands that lacked support for the sparse index, invoking those commands would cause your repository to expand the index to cover the entire repository, which can be a potentially expensive operation.
This release, the
diff-treecommand joined the group of commands with full support for the sparse index, meaning that you can now usediff-treewithout expanding your index.This work was contributed by Shuqi Liang, one of the Git project’s Google Summer of Code (GSoC) students. You can read more about their project here, and follow along with their progress on their blog.
[source]
-
If you’ve gotten this far in the blog post and thought that we were done talking about
git for-each-ref, think again! This release enhancesfor-each-ref‘s--formatoption with a handful of new ways to format a reference.The first set of new options enables
for-each-refto show a handful of GPG-related information about commits at reference tips. You can ask for the GPG signature directly, or individual components of it, like its grade, the signer, key, fingerprint, and so on. For example,$ git for-each-ref --format='%(refname) %(signature:key)' \ --sort=v:refname 'refs/remotes/origin/release-*' | tac refs/remotes/origin/release-3.1 4AEE18F83AFDEB23 refs/remotes/origin/release-3.0 4AEE18F83AFDEB23 refs/remotes/origin/release-2.13 4AEE18F83AFDEB23 [...]This work was contributed by Kousik Sanagavarapu, another GSoC student working on Git! You can read more about their project here, and keep up to date with their work on their blog.
-
Earlier in this post, we talked about
git rev-list, a low-level utility for listing the set of objects contained in some query.In our early examples, we discussed a straightforward case of listing objects unique to one branch. But
git rev-listsupports much more complex modifiers, like--branches,--tags,--remotes, and more.In addition to specifying modifiers like these on the command-line,
git rev-listhas a--stdinmode which allows for reading a line-delimited sequence of commits (optionally prefixed with^, indicating objects reachable from those commit(s) should be excluded) from the command’s standard input.Previously, support for
--stdinextended only to referring to commits by their object ID, without support for more complex modifiers like the ones listed earlier. In Git 2.42,git rev-list --stdincan now accept the same set of modifiers given on the command line, making it much more useful when scripting.[source]
-
Picture this: you’re working away on your repository, typing up a tag message for a tag named
foo. Suppose that in the background, you have some repeating task that fetches new commits from your remote repository. If you happen to fetch a tagfoo/barwhile writing the tag message forfoo, Git will complain that you cannot have both tagfooandfoo/bar.OK, so far so good: Git does not support this kind of tag hierarchy1. But what happened to your tag message? In previous versions of Git, you’d be out of luck, since your in-progress message at
$GIT_DIR/TAG_EDITMSGis deleted before the error is displayed. In Git 2.42, Git delays deleting theTAG_EDITMSGuntil after the tag is successfully written, allowing you to recover your work later on.[source]
-
In other
git tag-related news, this release comes with a fix for a subtle bug that appeared when listing tags.git tagcan list existing tags with the-loption (or when invoked with no arguments). You can further refine those results to only show tags which point at a given object with the--points-atoption.But what if you have one or more tags that point at the given object through one or more other tags instead of directly? Previous versions of Git would fail to report those tags. Git 2.42 addresses this by dereferencing tags through multiple layers before determining whether or not it points to a given object.
[source]
-
Finally, back in Git 2.38,
git cat-file --batchpicked up a new-zflag, allowing you to specifyNUL-delimited input instead of delimiting your input with a standard newline. This flag is useful when issuing queries which themselves contain newlines, like trying to read the contents of some blob by path, if the path contains newlines.But the new
-zoption only changed the rules forgit cat-file‘s input, leaving the output still delimited by newlines. Ordinarily, this won’t cause any problems. But ifgit cat-filecan’t locate an object, it will print out ” missing”, followed by a newline.If the given query itself contains a newline, the result is unparseable. To address this,
git cat-filehas a new mode,-Z(as opposed to its lowercase variant,-z) which changes both the input and output to beNUL-delimited.[source]
The rest of the iceberg
That’s just a sample of changes from the latest release. For more, check out the release notes for 2.42, or any previous version in the Git repository.
Notes
-
Doing so would introduce a directory/file-conflict. Since Git stores loose tags at paths like
$GIT_DIR/refs/tags/foo/bar, it would be impossible to store a tag foo, since it would need to live at$GIT_DIR/refs/tags/foo, which already exists as a directory. ↩
The post Highlights from Git 2.42 appeared first on The GitHub Blog.