Post Syndicated from Grab Tech original https://engineering.grab.com/app-moduralisation-at-scale
Grab a coffee ☕️, sit back and enjoy reading. 😃
Wanna know how we improved our app’s build time performance and developer experience at Grab? Continue reading…
Where it all began
Imagine you are working on an app that grows continuously as more and more features are added to it, it becomes challenging to manage the code at some point. Code conflicts increase due to coupling, development slows down, releases take longer to ship, collaboration becomes difficult, and so on.
Grab superapp is one such app that offers many services like booking taxis, ordering food, payments using an e-wallet, transferring money to friends/families, paying at merchants, and many more, across Southeast Asia.
Grab app followed a monolithic architecture initially where the entire code was held in a single module containing all the UI and business logic for almost all of its features. But as the app grew, new developers were hired, and more features were built, it became difficult to work on the codebase. We had to think of better ways to maintain the codebase, and that’s when the team decided to modularise the app to solve the issues faced.
What is Modularisation?
Breaking the monolithic app module into smaller, independent, and interchangeable modules to segregate functionality so that every module is responsible for executing a specific functionality and will contain everything necessary to execute that functionality.
Modularising the Grab app was not an easy task as it brought many challenges along with it because of its complicated structure due to the high amount of code coupling.
Approach and Design
We divided the task into the following sub-tasks to ensure that only one out of many functionalities in the app was impacted at a time.
- Setting up the infrastructure by creating Base/Core modules for Networking, Analytics, Experimentation, Storage, Config, and so on.
- Building Shared Library modules for Styling, Common-UI, Utils, etc.
- Incrementally building Feature modules for user-facing features like Payments Home, Wallet Top Up, Peer-to-Merchant (P2M) Payments, GrabCard and many others.
- Creating Kit modules for the feature to feature module communication. This step helped us in building the feature modules in parallel.
- Finally, the App module is used as a hub to connect all the other modules together using dependency injection (Dagger).

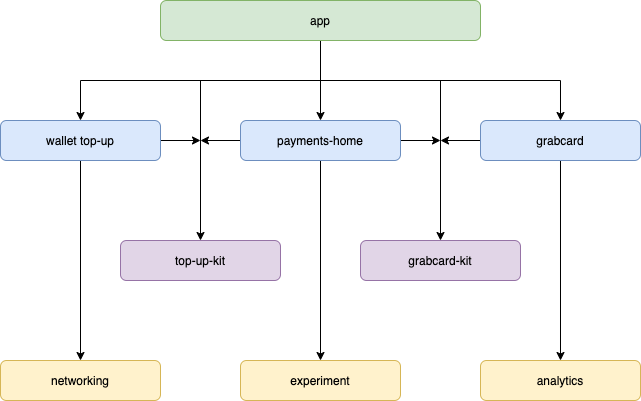
In the above diagram, payments-home, wallet top-up, and grabcard are different features provided by the Grab app. top-up-kit and grabcard-kit are bridges that expose functionalities from topup and grabcard modules to the payments-home module, respectively.
In the process of modularising the Grab app, we ensured that a feature module did not directly depend on other feature modules so that they could be built in parallel using the available CPU cores of the machine, hence reducing the overall build time of the app.
With the Kit module approach, we separated our code into independent layers by depending only on abstractions instead of concrete implementation.
Modularisation Benefits
- Faster build times and hence faster CI: Gradle build system compiles only the changed modules and uses the binaries of all the non-affected modules from its cache. So the compilation becomes faster. Moreover, independent modules are run in parallel on different threads.
- Fine dependency graph: Dependencies of a module are well defined.
- Reusability across other apps: Modules can be used across different apps by converting them into an AAR SDK.
- Scale and maintainability: Teams can work independently on the modules owned by them without blocking each other.
- Well-defined code ownership: Clear responsibility on who owns which code.
Limitations
- Requires more effort and time to modularise an app.
- Separate configuration files to be maintained for each module.
- Gradle sync time starts to grow.
- IDE becomes very slow and its memory usage goes up a lot.
- Parallel execution of the module depends on the machine’s capabilities.
Where we are now
There are more than 1,000 modules in the Grab app and are still counting.
At Grab, we have many sub-teams which take care of different features available in the app. Grab Financial Group (GFG) is one such sub-team that handles everything related to payments in the app. For example: P2P & P2M money transfers, e-Wallet activation, KYC, and so on.
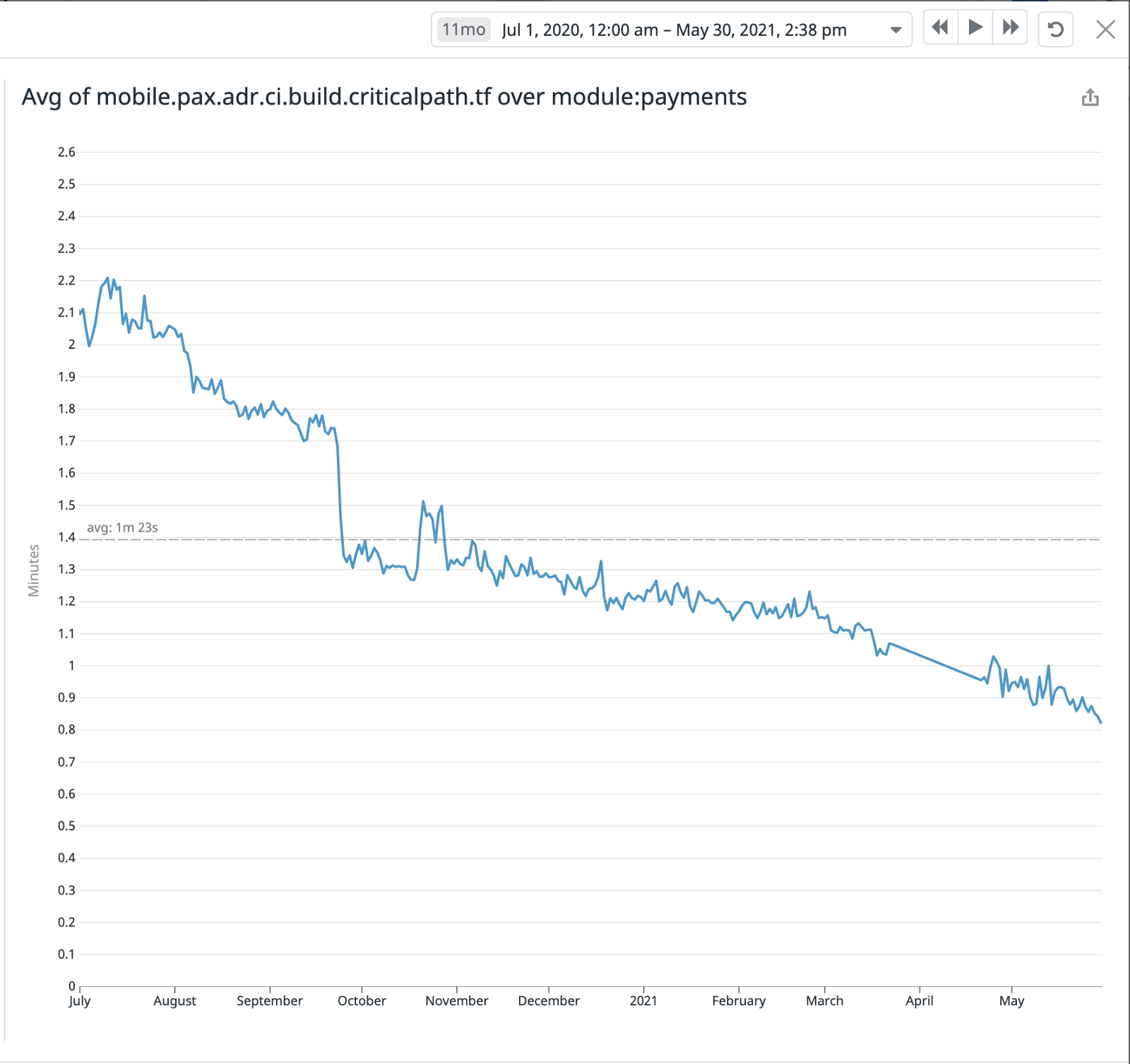
We started modularising payments further in July 2020 as it was already bombarded with too many features and it was difficult for the team to work on the single payments module. The result of payments modularisation is shown in the following chart.

As of today, we have about 200+ modules in GFG and more than 95% of the modules take less than 15s to build.
Conclusion
Modularisation has helped us a lot in reducing the overall build time of the app and also, in improving the developer experience by breaking dependencies and allowing us to define code ownership. Having said that, modularisation is not an easy or a small task, especially for large projects with legacy code. However, with careful planning and the right design, modularisation can help in forming a well-structured and maintainable project.
Hope you enjoyed reading. Don’t forget to 👏.
References:
- https://proandroiddev.com/build-a-modular-android-app-architecture-25342d99de82
- https://medium.com/google-developer-experts/modularizing-android-applications-9e2d18f244a0
- https://medium.com/@mydogtom/modularization-part-1-application-structure-overview-9e465909a9bc
Join Us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!