Post Syndicated from Vinodh Subramanian original https://www.backblaze.com/blog/synology-cloud-backup-guide/

Synology network attached storage (NAS) devices are great for businesses. They enable easy collaboration, speed up restores, make your files accessible 24/7, and give you a level of data protection you probably didn’t have before. Essentially, a NAS device acts as a private cloud, offering centralized access and storage for everything from large files to ongoing projects.
That’s why it’s important to back up your Synology DiskStation to the cloud. While NAS offers a layer of redundancy on-premises if you happen to lose files, it doesn’t fully protect you from things like a natural disaster, a ransomware attack that infiltrates your backups, or multiple hard drive failures. Cloud backups are important for data redundancy and future data recovery, giving you easy access and fast restores.
To keep your data truly safe, the 3-2-1 backup strategy is the industry baseline. Using a 3-2-1 strategy with your NAS means you keep three copies of your data on two different media (like NAS and cloud storage), with one stored off-site. Backing your DiskStation up to the cloud is a great way to achieve that key off-site element. This setup protects against various risks, and ensures your data is available for recovery.
In this post, we’ll explain how to implement a 3-2-1 backup strategy for your Synology NAS, the benefits of backing up to cloud storage, options for backing up your DiskStation, and some practical examples of what you can do by pairing your NAS with cloud storage.
Synology NAS and a 3-2-1 Backup Strategy
The 3-2-1 backup strategy is simple and time-tested. If you are using your Synology NAS to connect and back up computers on your network, that’s the first step—you have two local copies of your data on different mediums. You’d accomplish this by creating a multi-version local copy.
While this setup might seem sufficient, your data is still at risk from NAS device failure. It remains co-located with your primary data, making it vulnerable to disasters or theft. To fully protect your data, you need a third, off-site backup copy.
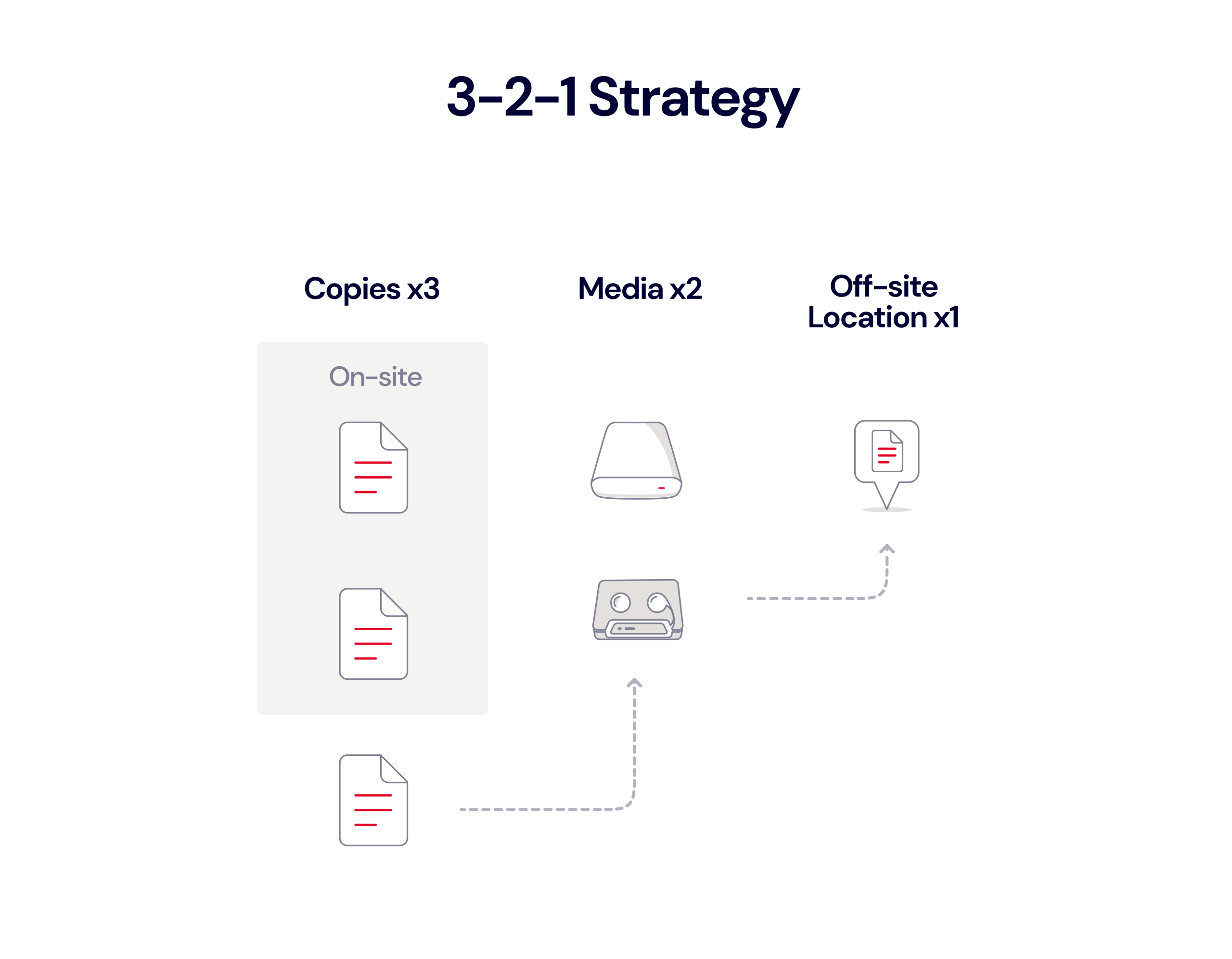
For your third copy, you could back up your Synology to an external desFor your third copy, you could back up your Synology to an external destination—either another Synology NAS, a file server, or a USB device. Each has pros and cons, and we’ll talk through them for argument’s sake.
- Back up to another Synology NAS: If you recently upgraded to a new device, you could store the third copy of your data on your old DiskStation. You get to put the old one to use, and you know it’s compatible.
- Back up to a file server: Backing your Synology NAS up to a file server is also an option, but it will take up more storage space for caching than backing up to another DiskStation.
- Back up to a USB device: Backing up to a USB device has some limited advantages—the format of your data is readable, so you can plug the USB in anywhere and access your data. However, USB backup won’t back up applications or system files, and it’s a manual rather than an automated process.
With any of these options, you’ll need to physically move your backup device—the old Synology, file server, or USB-connected device—to another location, ideally more than a few miles away, to truly achieve a 3-2-1 backup.
However, backing up your Synology NAS DiskStation to the cloud means you achieve a 3-2-1 strategy without the need to physically separate your backup copies. Backing up your Synology NAS to the cloud means you have both convenience and robust data redundancy.
The Benefits of Backing Up Your Synology DiskStation to the Cloud
In addition to avoiding the lift of a physical move, backing up Synology NAS to the cloud offers a number of other benefits, too, including:
- Avoiding data loss: A cloud backup protects against physical disasters, such as floods, hurricanes, and fires, that could compromise your NAS and data on individual workstations. Because the NAS is always connected to your machines, it’s also at risk of infection from ransomware attacks. And finally, the hard drives in your NAS can fail. Because your NAS is likely set up in a RAID configuration, one drive failure might not affect your data. But, while one drive is down, your data is at a higher risk. If another drive were to fail, you could lose data. Having an off-site backup in cloud storage significantly reduces this risk.
- Accessibility: With your data in the cloud, your backups are accessible from anywhere. If you’re away from your desk or office and you need to retrieve a file, you can simply log in to your cloud instance and retrieve it remotely.
- Security: Cloud vendors typically protect customer data by encrypting it as it travels to its final destination and/or when it’s at rest on the vendors’ storage servers. Encryption protocols differ between cloud vendors, so make sure to understand them as you’re evaluating cloud providers, especially if your organization has specific security requirements.
- Automation: Your Synology NAS comes with built-in backup utilities, so you can configure a backup schedule for automated cloud backups . This saves time and ensures your data is always up-to-date.
- Scalability: As your data grows, your cloud backups grow with it. With cloud storage, there’s no need to invest in or maintain additional hardware to ensure your data is properly backed up.
- Rapid Data Recovery: Cloud storage often offers shorter recovery times than traditional methods, particularly if your NAS device fails or data needs to be restored urgently. Cloud storage solutions can streamline data retrieval, allowing quick access to backed-up files and minimizing downtime.
- Multi-Cloud Options: Many cloud providers support multi-cloud setups, allowing you to back up your Synology NAS to multiple cloud destinations. This added redundancy can be a valuable safeguard against any single provider outages, helping to ensure continuous data availability.
- File Versioning: Some cloud storage services support file versioning, which is the ability to keep previous versions of files. This is particularly useful if files are accidentally modified or deleted. It can help you restore earlier versions without losing valuable information.
Options for Backing Up Your Synology NAS
Synology offers various backup utilities and methods to protect your data, each suited to different backup needs and environments.
1. Hyper Backup
Hyper Backup is Synology’s built-in backup utility for backing up to any number of external destinations, including public clouds. It enables you to back up not just data stored on your NAS, but also applications and system configurations.
It offers incremental backups to help you manage your storage footprint. After your initial backup, using incremental backups means only files that have been changed will be updated.
It also offers cross-file deduplication to help you further manage your storage footprint. Hyper Backup allows you to back up to external devices as well as cloud services.
2. Cloud Sync
In addition to Hyper Backup, Synology also offers Cloud Sync, which is important for those who need real-time collaboration and file syncing capabilities. Keep in mind that sync is not the same as backup–Cloud Sync does not support application and system configuration file backups, and it only keeps the current version of your files. If someone accidentally deletes that file, it’s gone. If you’re not sure if you’re looking for backup or sync, you can read about the differences between them in this post.
3. Snapshot replication
If your Synology model supports the Btrfs file system, using Snapshot Replication is a bit faster both on the backup side and the restore side than Hyper Backup. Snapshot Replication allows you to back up to the same Synology NAS or another Synology NAS, but not to the cloud.
4. USB copy
USB Copy only copies your data, not applications or system configuration files. It does not support cross-file deduplication, so you might end up with duplicate copies of your files. Additionally, this method is manual, and will require you to be responsible for regular backups as opposed to automating them with Hyper Backup or Snapshot Replication.

What You Can Do With Cloud Sync, Hyper Backup, and Cloud Storage
Using Hyper Backup and Cloud Sync together gives you total control over what gets backed up to cloud storage—you can synchronize in the cloud as little or as much as you want. This flexible approach allows you to customize your backup plan and protect your Synology NAS data based on priority and needs.
Here are some practical examples of what you can do with Cloud Sync, Hyper Backup, and cloud storage working together.
1. Sync or Back Up the Entire Contents of Your DiskStation to the Cloud
The DiskStation has excellent fault-tolerance—it can continue operating even when individual drive units fail. However, for comprehensive protection, syncing and backing up the entire DiskStation to cloud storage ensures that your data remains secure during a disaster or system failure.
2. Sync or Back Up Your Most Important Media Files
If you’re storing essential media files—like videos, music, and photos—on your DiskStation, Cloud Sync or Hyper Backup can ensure these valuable files are safely stored in the cloud. Synology NAS offers data redundancy on-premises, but cloud storage provides an additional off-site backup layer for further protection.
3. Back Up Time Machine
For Mac operations, Synology allows the DiskStation to serve as a network-based Time Machine backup. With Hyper Backup, you can synchronize Time Machine files to the cloud so that in the event of a critical failure, your Time Machine backups are securely stored off-site, ready for a seamless restoration.
Ready to Give It a Try?
Hyper Backup allows you to choose from any number of cloud storage providers as a backup destination, and Backblaze B2 Cloud Storage is one of them.If you haven’t given cloud storage a try yet, you can get started now, and make sure your NAS is synced or backed up securely to the cloud.
FAQs About Synology NAS
Hyper Backup is Synology’s built-in backup utility for backing up to any number of external destinations, including public clouds. It enables you to back up not just data stored on your NAS, but also applications and system configurations. Additionally, It offers cross-file deduplication to help you further manage your storage footprint and avoid duplicates.
Synology offers a lot of options for backing up your device, including to local volumes, external devices, other Synology systems, rsync servers, or public cloud services like Backblaze B2. The best way to back up your Synology NAS depends on many different factors, but the most important thing to remember is that you should follow a 3-2-1 backup strategy. That means keeping three copies of your data on two different media (i.e. devices) with one off-site. Backing up to the cloud is a great option for data redundancy and long-term protection when handling your off-site backups.
Yes, with Hyper Backup, you can set up automatic backups to many public clouds, including Backblaze B2. It offers incremental backups to help you manage your storage footprint. After your initial backup, using incremental backups means only files that have been changed will be updated.
Synology is compatible with many public cloud providers, including Backblaze B2, Microsoft Azure, Google Cloud Platform, Amazon S3, and Synology C2 Storage.
The amount of cloud storage space needed for your Synology NAS backup depends on factors like the total data size, frequency of backups, and retention policies. Calculate your NAS data size, estimate growth, and choose a cloud plan accordingly. Hyper Backup provides storage estimates, helping you select the right amount of cloud storage space for secure, scalable data backups.
The post How to Back Up Your Synology NAS to the Cloud | Backblaze appeared first on Backblaze Blog | Cloud Storage & Cloud Backup