Post Syndicated from Ashley Whittaker original https://www.raspberrypi.org/blog/mars-clock/
A sci-fi writer wanted to add some realism to his fiction. The result: a Raspberry Pi-based Martian timepiece. Rosie Hattersley clocks in from the latest issue of The MagPi Magazine.

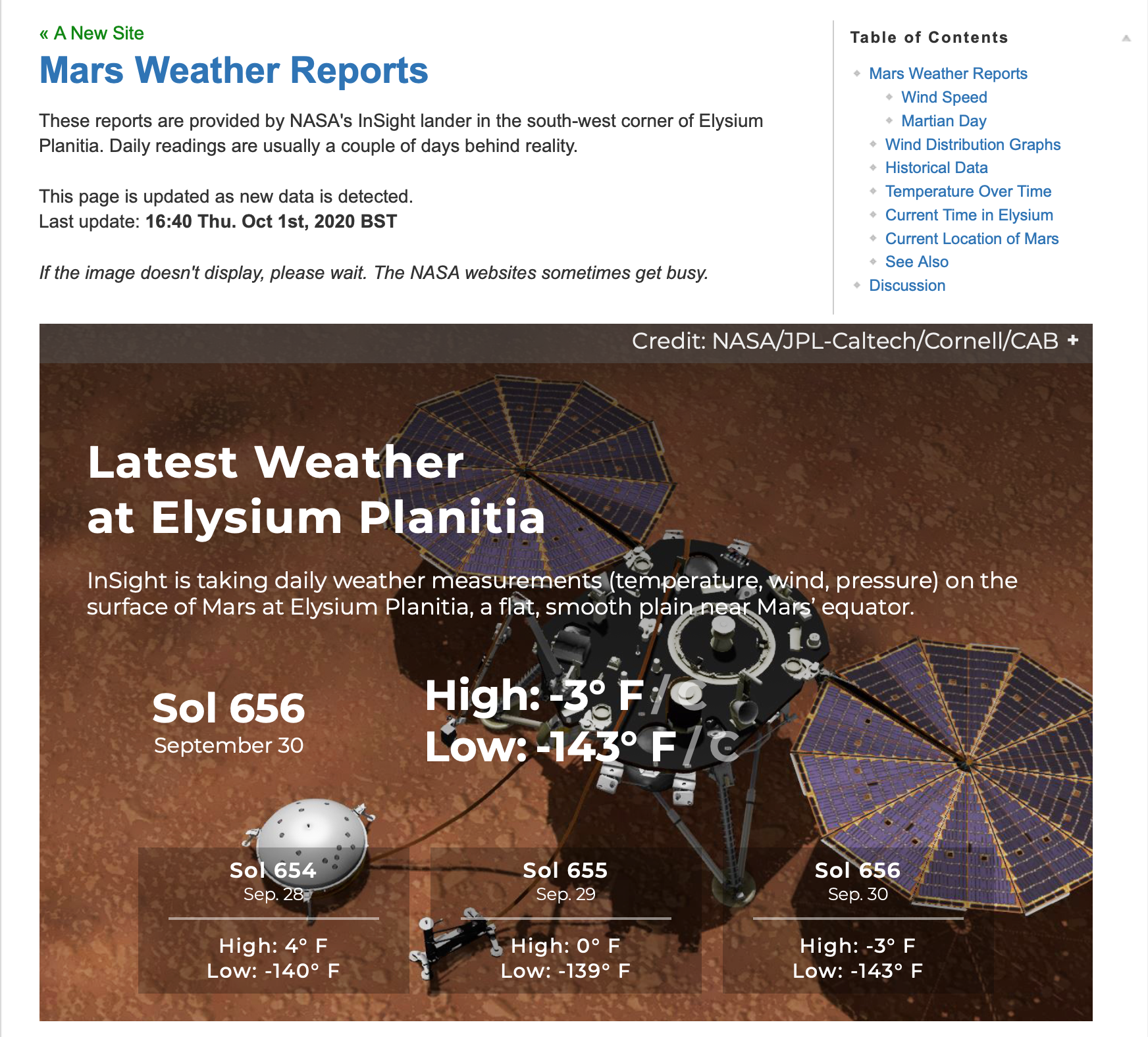
Ever since he first clapped eyes on Mars through the eyepiece of a telescope, Philip Ide has been obsessed with the Red Planet. He’s written several books based there and, many moons ago, set up a webpage showing the weather on Mars. This summer, Phil adapted his weather monitor and created a Raspberry Pi-powered Mars Clock.
Mission: Mars
After writing several clocks for his Mars Weather page, Phil wanted to make a physical clock: “something that could sit on my desk or such like, and tell the time on Mars.” It was to tell the time at any location on Mars, with presets for interesting locations “plus the sites of all the missions that made it to the surface – whether they pancaked or not.”

Another prerequisite was that the clock had to check for new mission file updates and IERS bulletins to see if a new leap second had been factored into Universal Coordinated Time.
“Martian seconds are longer,” explains Phil, “so everything was pointing at software rather than a mechanical device. Raspberry Pi was a shoo-in for the job”. However, he’d never used one.
“I’d written some software for calculating orbits and one of the target platforms was Raspberry Pi. I’d never actually seen it run on a Raspberry Pi but I knew it worked, so the door was already open.” He was able to check his data against a benchmark NASA provided. Knowing that the clocks on his Mars Weather page were accurate meant that Phil could focus on getting to grips with his new single-board computer.
He chose a 2GB Raspberry Pi 4 and official-inch touchscreen with a SmartiPi Touch 2 case. “Angles are everything,” he reasons. He also added a fan to lower the CPU temperature and extend the hardware’s life. Along with a power lead, the whole setup cost £130 from The Pi Hut.
Since his Mars Clock generates a lot of data, he made it skinnable so the user can choose which pieces of information to view at any one time. It can display two types of map – Viking or MOLA – depending on the co-ordinates for the clock. NASA provides a web map-tile service with many different data sets for Mars, so it should be possible to make the background an interactive map, allowing you to zoom in/out and scroll around. Getting these to work proved rather a headache as he hit incompatibilities with the libraries.
Learn through experience
Phil wrote most of the software himself, with the exception of libraries for the keyboard and FTP which he pulled from GitHub. Here’s all the code.

He used JavaScript running on the Node.js/Electron framework. “This made for rapid development and is cross-platform, so I could write and test it on Windows and then move it to the Raspberry Pi,” he says. With the basic code written, Phil set about paring it back, reducing the number and duration of CPU time-slices the clock needed when running. “I like optimised software,” he explains.
His decades as a computer programmer meant other aspects were straightforward. The hardware is more than capable, he says of his first ever experience of Raspberry Pi, and the SmartiPi case makers had done a brilliant job. Everything fit together and in just a few minutes his Raspberry Pi was working.

Since completing his Mars Clock Phil has added a pi-hole and a NAS to his Raspberry Pi setup and says his confidence using them is such that he’s now contemplating challenging himself to build an orrery (a mechanical model of the solar system). “I have decades of programming experience, but I was still learning new things as the project progressed,” he says. “The nerd factor of any given object increases exponentially if you make it yourself.”
The MagPi Magazine | Issue 99

Check out page 26 in the latest issue of The MagPi Magazine for a step-by-step and to learn more about the maker, Phillip. You can read a PDF copy for free on The MagPi Magazine website if you’re not already a subscriber.
The post Mars Clock appeared first on Raspberry Pi.