Moonhack is a free, international coding challenge for young people run online every year by Code Club Australia, powered by our partner the Telstra Foundation. The yearly challenge is open to young people worldwide, and in 2023, over 44,500 young people registered to take part.
Moonhack 2024 runs from 14 to 31 October. This year’s theme is taken from World Space Week 2024: climate change. As always, the projects cater for everyone from brand-new beginners to more experienced coders. And young people have a chance to win a prize for their submitted project!
We caught up with Kaye North, Community and Engagement Manager at Code Club Australia, to find out more.
What to expect from Moonhack in 2024
For this year’s projects, Kaye told us that she collaborated with farmers, scientists, and young people from across Australia to cover diverse topics related to climate change and space. The projects will help participants learn about topics from how people who work in agriculture use climate data to increase crop yields and practise sustainable farming, to the impact of rising global temperatures on sea life populations.
Kaye also hopes to help young people understand the role of satellite data related to climate change, such as the data NASA collects and shares via satellite. Satellite data on rising sea levels, called out in United Nations Sustainable Development Goal 13, forms the basis of one of the Moonhack projects this year.
Moonhack participants will be able to code with Scratch, micro:bit, or Python. They can also take on a project brief where they may choose their favourite programming language and even include physical computing if they wish.
All six projects will be available from 1 September when registration opens, and projects can be submitted until 30 November.
Inspiring young people to create a better future
Climate change is an issue that affects everyone, and for many young people it’s a source of concern. Kaye’s aim this year is to show small changes young people can make to contribute to a big, global impact.
“Moonhack’s question this year is ‘Can we create calls to action through our coding to influence others to make better choices, or even inform them of things that they didn’t know that they can share with others?’” – Kaye North, Code Club Australia
Moonhack support for volunteers, teachers and parents
This year’s Moonhack includes new resources to help educators and mentors who are supporting young people to take part:
You can access support guides on the Moonhack website now
Once the projects go live on 1 September, Kaye will share project blogs and host online codealongs
Moonhack is a free global, online coding challenge by our partner Code Club Australia, powered by Telstra Foundation. It runs once a year for young learners worldwide. In 2022, almost 44,000 young people from 63 countries registered to take part.
This year, Moonhack will happen from 10 to 26 October, to coincide with World Space Week 2023. The challenge is open to all young learners, wherever they are in the world, and features six brand-new projects that focus on space and innovation. We caught up with Kaye North, Community and Engagement Manager at Code Club Australia, to find out more.
What’s new for 2023?
Moonhack 2023 offers access to engaging new projects for Scratch, micro:bit, and Python. For the first time ever, young people will also have the option to follow a project brief to code their own solution to a space-based issue, using a programming language of their choice.
In keeping with this year’s theme — which was inspired by the World Space Week 2023 theme of ‘Space and Entrepreneurship’ — the new Moonhack projects showcase inventions that were created for space exploration but are now used in everyday life, such as mobile phone cameras and LEDs.
Kaye shared that in Australia, inventions created for space travel and exploration are part of the science curriculum at primary school level. She hopes that this year’s Moonhack will help more young people understand how space exploration and coding are connected to their daily lives.
What will young people gain from taking part in Moonhack?
Moonhack features six unique coding projects, giving young people of all ages and experience levels the opportunity to engage and learn. The project brief introduced this year encourages participants to be creative, coding a solution on any platform they choose.
Coders who respond to the project brief will also be in with a chance of having their project selected to be developed into an official Code Club Australia project, for other young people and educators around the world to enjoy.
Kaye emphasised that Moonhack is about more than just taking part in a global event; it also helps young people to better understand the real-world opportunities that coding can offer.
“The more kids we expose this to, the better, expanding coding past just coding and having purpose behind it. And I do try to link things in so that we’re connecting with real-world context, careers…”
Kaye North
How your young coders can get involved
Registration for Moonhack 2023 is open now. The challenge runs from 10 to 26 October, and projects can be submitted until 30 November. Participation is free and open to any young coder, whether they are part of a Code Club or not. The 2023 projects are already available in English, Arabic, Croatian, Dutch, Filipino, French, Greek, Hindi, Indonesian, Mandarin, Portuguese, and Spanish, and will be available in more languages soon.
To find out more and register to take part, visit the Moonhack website.
The European Astro Pi Challenge is back for another year. This is young people’s chance to write computer programs that run on board the International Space Station.
ESA astronaut Samantha Cristoforetti with one of the upgraded Astro Pi computers on which young people’s programs will run.
Young people can take part in two Astro Pi challenges: Mission Zero and Mission Space Lab. Participation is free and open for young people up to age 19 in ESA Member States (see more details about eligibility on the Astro Pi website). Young people can participate in one or both of the challenges.
Their programs will run on the two new upgraded Astro Pi computers, which launched into space in December 2021. The Astro Pis were named after the two inspirational European scientists Nikola Tesla and Marie Skłodowska-Curie by Mission Zero participants. For the 2021/22 European Astro Pi Challenge, these new computers ran over 17,000 programs written by young people from 26 countries.
Here is ESA astronaut Matthias Maurer getting the new Astro Pis ready for young people’s experiments.
You can register for Mission Space Lab from today
In Mission Space Lab, teams of young people work together with a mentor who supports them, as they design a scientific experiment to be run on the Astro Pis in space.
Teams write programs that use an Astro Pi’s sensors and camera to collect data from the International Space Station, which the teams then analyse. This video has more information about the Astro Pi computers and how teams can choose an experiment idea:
Registration for Mission Space Lab is now open, and participation takes place over eight months. Mentors need to register their team and submit the team’s experiment idea by 28 October 2022. For more details on how to register, visit the Mission Space Lab webpages.
Mission Zero is the beginners’ challenge where young people write a simple program and get a taste of space science.
All eligible programs that follow the official guidelines will run in space for up to 30 seconds. The young people who participate receive a certificate they can download which shows their program’s exact start and end time, and the position of the ISS when their program ran — a piece of space science history to keep!
Mission Zero opens on 22 September 2022. Watch this space for more details on launch day.
Stay up to date
The European Astro Pi Challenge is an ESA Education project run in collaboration with us here at the Raspberry Pi Foundation.
You can stay up to date with all of the latest Astro Pi news by following the Astro Pi Twitter account or signing up to the newsletter at astro-pi.org
It’s been an incredible year for the European Astro Pi Challenge. We’ve sent new hardware into space, seen record numbers of young people participate in the Challenge, and received lots of fantastic programs. Before we say goodbye to the 2021/22 European Astro Pi Challenge, the Raspberry Pi Foundation and the European Space Agency are thrilled to announce this year’s winning and highly commended Mission Space Lab teams.
What is Mission Space Lab?
In Mission Space Lab, teams of young people aged up to 19 work together to create scientific experiments to be carried out on the International Space Station. Their mission is to design and create a program to run on the two Astro Pi computers — space-adapted Raspberry Pis with cameras and a range of sensors.
ESA astronaut Samantha Cristoforetti with the new Astro Pi computers on the ISS Credit: ESA/NASA
This year, 799 teams of young people designed experiments and entered Mission Space Lab and 502 of these teams were invited to Phase 2, which is 25% more than last year! The teams each received an Astro Pi kit to write and test their programs on and 299 teams submitted programs that passed rigorous testing at Astro Pi Mission Control and achieved ‘flight status’.
After their program collected data during the experiment’s three-hour runtime on the ISS, each team analysed the results and wrote a short report to describe their experiment.
We were especially excited to see what experiments young people would investigate this year, as their programs would be the first to run on the brand-new Astro Pi units, which were named after Nikola Tesla and Marie Curie by participants in this year’s Mission Zero.
The two original Astro Pis with the new upgraded Astro Pis, together on the ISS Credit: ESA/NASA
Let’s take a look at the teams’ investigations for Mission Space Lab 2021/22!
Clouds, volcanos, and seaweed rafts
In this year’s Challenge, the environment and climate change was a strong theme among the 205 team experiment reports. Several teams investigated topics such as changing water levels, wildfires, and the effect of different clouds and aeroplane contrails on global warming.
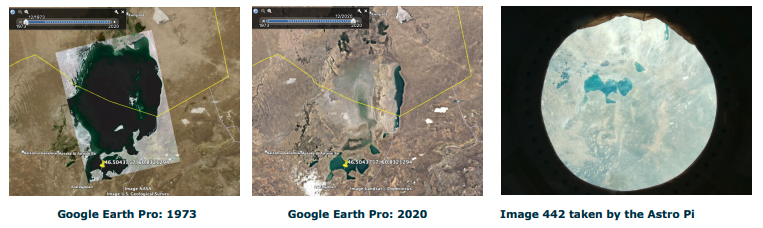
Team Seekers from Itis Delpozzo Cuneo in Italy and Team Adastra from St Paul’s Girls’ School in the UK made observations about reduction of water levels in the Aral Sea, located between Kazakhstan and Uzbekistan.
Team Adastra compared their image of the Aral Sea with data from Google Earth to show the significant decrease in water coverage
“We have gained skills with data research and machine learning, in relation to scientific experiments, which will hopefully give us a basis to move into more complex projects with machine learning.”
Team Adastra
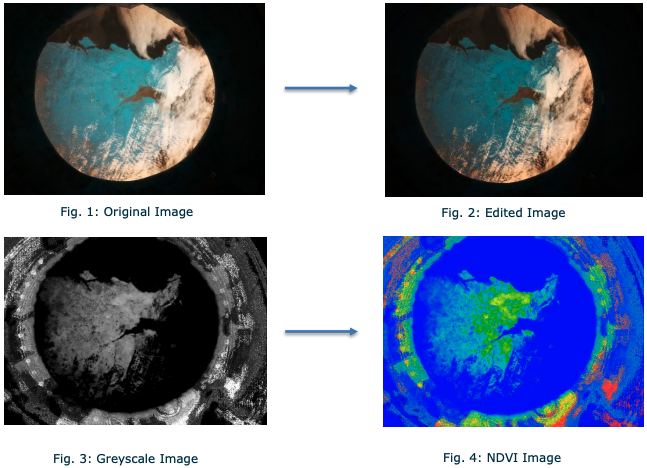
Team St Marks from Saint Marks Church of England School in the UK calculated NDVI (normalised difference vegetation index) for images they had captured to look for macroplastics in the ocean. This is a technique for identifying vegetation from images. The team used it to search for the rafts of sargassum seaweed that form around plastics floating on the water. They were lucky enough to successfully photograph and identify several seaweed rafts during their three hour experiment time.
Two seaweed rafts (circled in red) off the coast of Brazil captured by Team St Marks
Team Nanokids from the UK used the Coral machine learning accelerator to analyse images of clouds in real time. Collecting this data could be used to warn aircraft of the risk of turbulence, predict weather, and detect pollution. The team reported that they “learned a lot about the various different cloud types, their characteristics and their different effects, as well as how to create a simple ML model with Teachable Machine, which will help us in future projects.”
Cumulonimbus cloud analysed by Team Nanokids
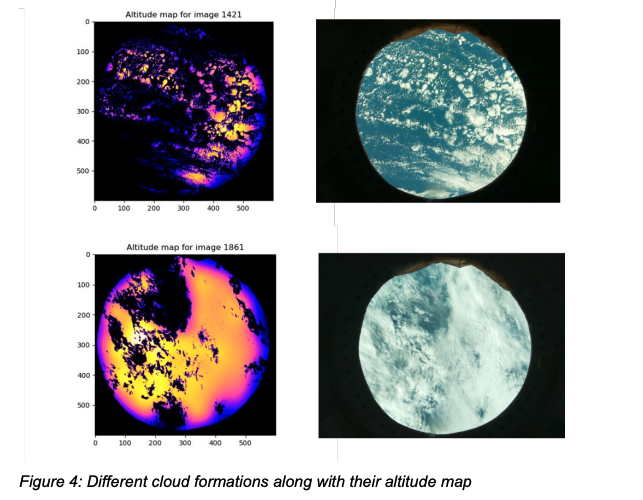
Team Centauri from Diverbot in Spain were inspired by the influence of high altitude cloud vapour on the Greenhouse Effect to calculate the height of clouds from images taken by the Raspberry Pi High Quality Camera. They identified the potential to scale-up their experiment, in order to analyse hundreds or thousands of images of clouds and calculate their impact on the temperature of the Earth.
Some examples of the cloud formations analysed by Team Centauri
We also saw lots of experiment reports about volcanoes. Team Six Sense from Escola Secundária Inês de Castro in Portugal ran an experiment inspired by the La Palma volcano, which erupted in September 2021. The team’s experiment captured images of a volcano in Fogo Island, Cape Verde.
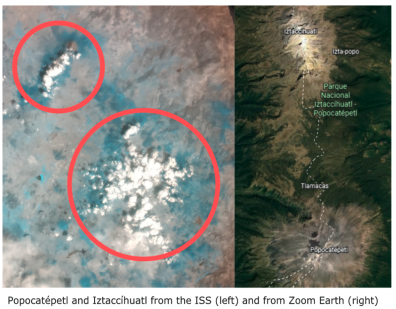
Team LandISS from Liceo Scientifico “A. Landi” in Italy captured an extraordinary image of emissions from the Popocatépetl volcano in Mexico, which reactivated in 1994 and has been producing powerful explosions at irregular intervals ever since.
Popocatépetl volcano in the Iztaccíhuatl–Popocatépetl National Park by Team LandISS
Team DuoDo from Liceul Teoretic Tudor Vianu in Romania investigated if there had been changes to vegetation health on the Earth since the pandemic, by comparing NDVI calculations from their data. The judges were especially impressed with how they reported their analysis and results.
NDVI processing by Team DoDuo
Team Atlantes from Niubit in Spain wanted to build a bridge between the real and virtual world by visualising their NDVI calculations as a three dimensional Minecraft video game. Check out how they did this and some of their results in their video.
From ISS 🛰️ to Minecraft 🧱 : Astro Pi Mission Space Lab 2021-22 by Team Atlantes
Team Rocha21, from IES José Frugoni Pérez in the Canary Islands, also explored different ways to communicate and share their data. They used sonoUno (software originally developed to sonify astronomical data) and online Braille translators to design tactile diagrams in order to explore their Life on Earth photographs and NDVI data, working in collaboration with six visually-impaired students.
Up in space
Some of this year’s Mission Space Lab teams chose to conduct their experiments about life on the ISS. We saw experiments to investigate the possibility for growing fungi as space crops (Team NGC224 from CoderDojo Perugia in Italy) and the effect of temperature and pressure on the human body on Earth and in space (Team CDV-CDI2 from CoderDojo Votanikos in Greece, in collaboration with CoderDojo Iraq).
Team Hyperion from JVS Hyperion in Belgium investigated the effect of the sun on the Earth’s magnetic field, comparing data collected during daytime and nighttime as the ISS orbited Earth.
Not only did we get to see this year’s experiments, but we also had a chance to hear them! Sound and music was very popular among the Mission Space Lab teams.
Team Cuza3 from Colegiul National ”Alexandru Ioan Cuza” in Romania, made “The Ballad of Pressure” by attributing notes to pressure data from the ISS. Team Alessi Pi from Liceo Scientifico “G.Alessi” in Italy made a melody by mapping data to a music scale with other sensor readings mapped to additional instruments.
Team Gubbins, from Hyvinkään Lukio in Finland, measured magnetic flux density to determine the strength of the Earth’s magnetic field, using the Astro Pi magnetometer, which they sonified and used to make a music video.
Sonification of the Earth’s magnetic field by Team Gubbins
And the winning teams are…
The judges from ESA and the Raspberry Pi Foundation took on the huge task of reviewing all the reports to consider scientific merit, experiment design and methodology, data analysis, report quality, and innovative use of the Astro Pi hardware.
The ten winning teams come from coding clubs and schools from France, Italy, Greece, Spain, Romania, and the United Kingdom and will each receive cool space swag.
Click each team name to read their experiment report.
Every Astro Pi team that reached Phase 3 of Mission Space Lab will receive a certificate signed by ESA astronaut Samantha Cristoforetti to show family and friends that they have had a scientific experiment run on the ISS!
The winning and highly commended teams will be invited to an online Q&A with an ESA astronaut in the autumn. Look out for more information about this soon!
Congratulations Mission Space Lab teams 2021/22
Everyone from the Raspberry Pi Foundation and ESA Education teams congratulates this year’s Mission Space Lab participants — we hope you found it as fun and inspiring as we did!
Thank you to everyone who has been involved in Mission Zero and Mission Space Lab as part of this year’s Challenge. It has been incredible to have 28,126 young people from 26 countries run their programs in space! We can’t wait to do it all again.
When will the 2022/23 European Astro Pi Challenge lift off?
Mission Zero and Mission Space Lab relaunch in September 2022!
If you know a young person who would be interested in the Challenge, sign up for the newsletter on astro-pi.org and follow the Astro Pi Twitter account for all the latest announcements.
The James Webb Telescope reveals emerging stellar nurseries and individual stars in the Carina Nebula that were previously obscured. Credits: NASA, ESA, CSA, and STScI. Full image here.
“Somewhere, something incredible is waiting to be known.” — Carl Sagan
In the past few years, space technology and travel have been trending with increased attention and endeavors (including private ones). In our 2021 Year in Review we showed how NASA and SpaceX flew higher, at least in terms of interest on the Internet.
This week, NASA in collaboration with the European Space Agency (ESA) and the Canadian Space Agency (CSA), released the first images from the James Webb Telescope (JWST) which conducts infrared astronomy to “reveal the unseen universe”.
Webb’s First Deep Field is the first operational image taken by the James Webb Space Telescope, depicting a galaxy cluster with a distance of 5.12 billion light-years from Earth. Revealed to the public on 11 July 2022. Credits: NASA, ESA, CSA, and STScI. Full image here.
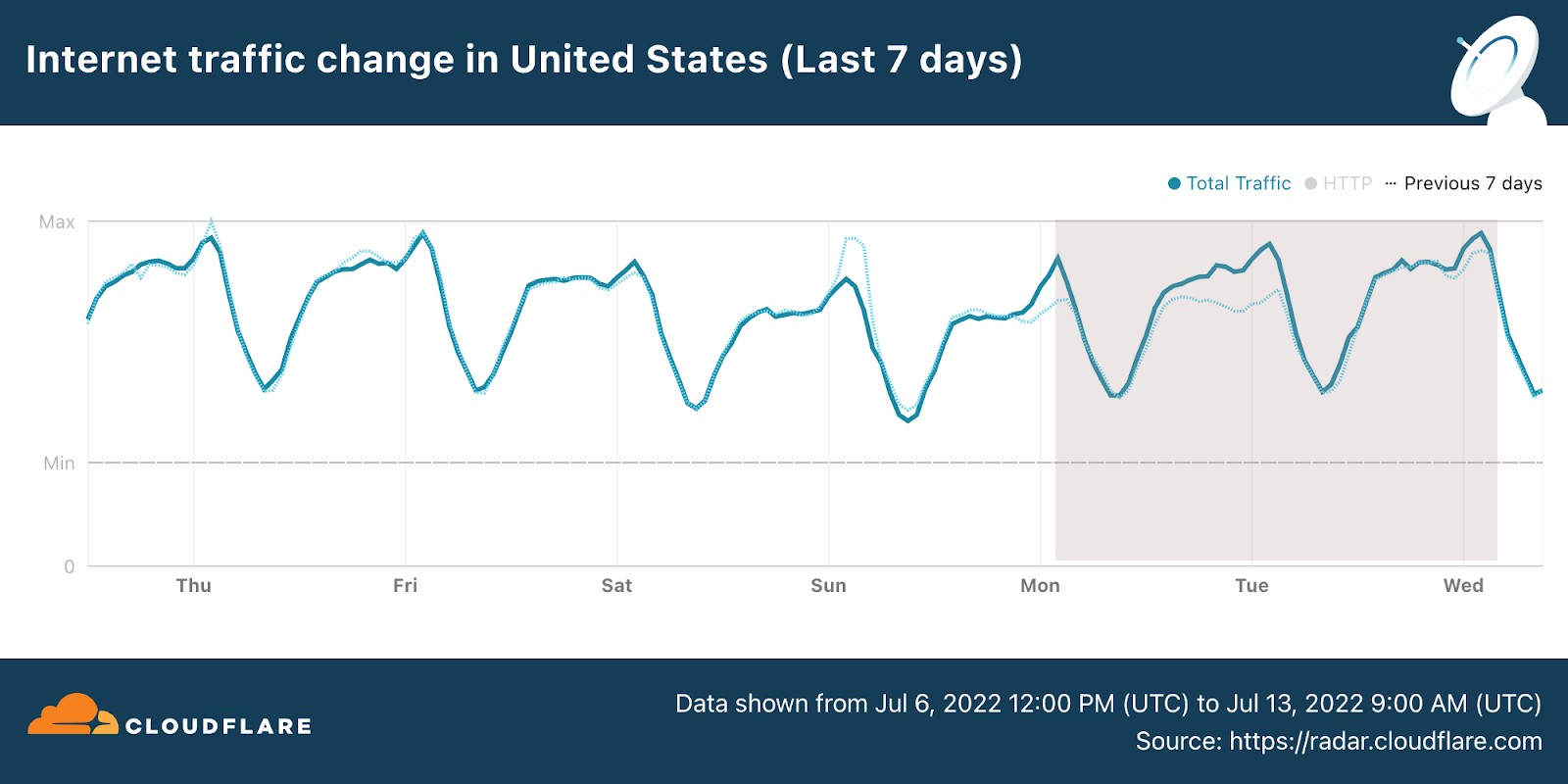
So, let’s dig into something we really like here at Cloudflare, checking how real life and human interest has an impact on the Internet. In terms of general Internet traffic in the US, Radar shows us that there was an increase both on July 11 and July 12, compared to the previous week (bear in mind that July 4, the previous Monday, was the Independence Day holiday in the US).
Next, we look at DNS request trends to get a sense of traffic to Internet properties (and using from this point on EST time in all the charts). Let’s start with the cornucopia of NASA, ESA and other websites (there are many, some dedicated just to the James Webb Telescope findings).
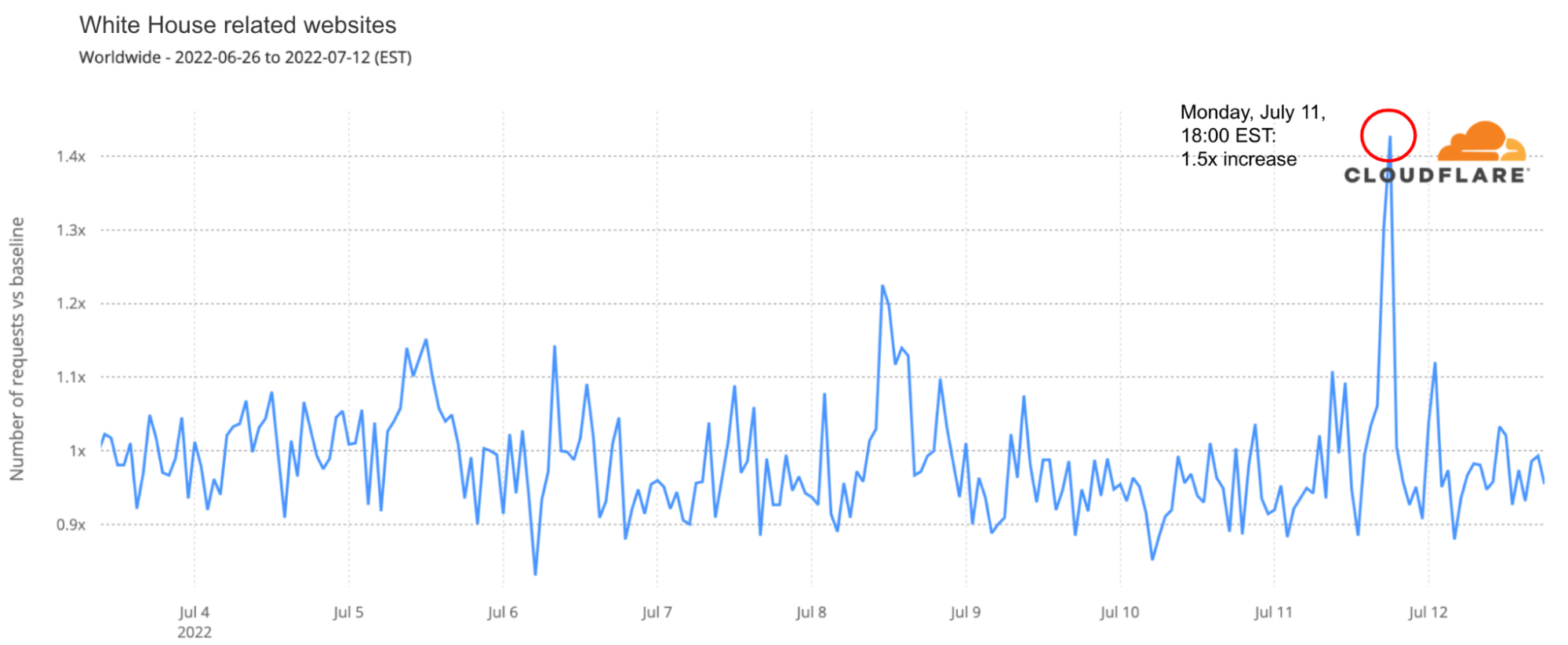
There are two clear spikes in the next chart. The first was around the time the first galaxy cluster infrared image was announced by Joe Biden, on Monday, July 11, 2022 (at 17:00), with traffic rising 13x higher than in the previous week. There was also a 5x spike at 01:00 EST that evening. The second spike was higher and longer and happened during Tuesday, July 12, 2022, when more images were revealed. Tuesday’s peak was at 10:00, with traffic being 19x higher than in the previous week — traffic was higher than 10x between 09:00 and 13:00.
The first image was presented by US president at around 17:00 on July 11. DNS traffic was 1.5x higher to White House-related websites than any time in the preceding month.
Conclusion: space, the final frontier
As we saw in 2021, space projects and announcements continue to have a clear impact on the Internet, in this case in our DNS request view of Internet traffic. So far, what the James Webb Telescope images are showing us is a glimpse of a never-before-seen picture of parts of the universe (there’s no lack of excitement in Cloudflare’s internal chat groups).
You can keep an eye on these and other trends using Cloudflare Radar and follow @CloudflareRadar on Twitter — recently we covered extensively Canada’s Internet outage.
Your young people don’t need to wait to become astronauts to be part of a space mission! In Mission Zero, the free beginners’ coding activity of the European Astro Pi Challenge, young people can create a simple computer program to send to the International Space Station (ISS) today.
This year, young people taking part in Astro Pi Mission Zero have the historic chance to help name the special Raspberry Pi computers we are sending up to the ISS for the Astro Pi Challenge. Their voices will decide the names of these unique pieces of space exploration hardware.
Your young people can become part of a space mission today!
The European Astro Pi Challenge is a collaboration by us and ESA Education. Astro Pi Mission Zero is free, open to all young people up to age 19 from eligible countries*, and it’s designed for beginner coders.
You can support participants easily, whether at home, in the classroom, or in a youth club. Simply sign up as a mentor and let your young people follow the step-by-step instructions we provide (in 19 European languages!) for writing their Mission Zero code online. Young people can complete Mission Zero in around an hour, and they don’t need any previous coding experience.
Mission Zero is the perfect coding activity for parents and their children at home, for STEM or Scouts club leaders and attendees, and for teachers and students who are new to computer programming. You don’t need any special tech for Mission Zero participants. Any computer with a web browser and internet connection works for Mission Zero, because everything is done online.
We need young people to help name the Raspberry Pis we’re sending to space
Mission Zero participants follow our step-by-step instructions to create a simple program that takes a humidity reading on board the ISS and displays it for the astronauts — together with the participants’ own unique messages. And as part of their messages, they can vote for the name of the new hardware for the Astro Pi Challenge, hardware with Raspberry Pi computers at its heart.
The shiny new Raspberry Pi-powered hardware for the Astro Pi Challenge, which will replace the Raspberry Pi-powered Astro Pi units that have run Astro Pi participants’ code on board the ISS every year since 2015.
The new Astro Pi hardware, which will travel up in a rocket to the ISS on 21 December, is so new that these special augmented computers don’t even have names yet. Participants in Astro Pi Mission Zero get to vote for a name inspired by our list of ten renowned European scientists. Their vote will be part of the message they send to space.
Your young people’s messages to the ISS astronauts can say anything they like (apart from swear words, of course). Maybe they want to send some encouraging words to the astronauts or tell them a joke. They can even design a cool pixel art image to show on the Astro Pi hardware’s display:
Some of the pixel art from last year’s Astro Pi Mission Zero participants.
Whatever else they code for their Mission Zero entry, they’re supporting the astronauts with their important work on board the ISS. Since Mission Zero participants tell the Astro Pi hardware to read and display the humidity level inside the ISS, they provide helpful information for the astronauts as they go about their tasks.
Their own place in space history
After a participant’s Mission Zero code has run and their message has been shown in the ISS, we’ll send you a special certificate for them so you can commemorate their space mission.
The certificate will feature their name, the exact date and time their code ran, and a world map to mark the place on Earth above which the ISS was while their message was visible up there in space.
10 key things about Astro Pi Mission Zero
It’s young people’s unique chance to be part of a real space mission
Participation is free
Participants send the ISS astronauts their own unique message
This year only, participants can help name the two special Raspberry Pi computers that are travelling up to the ISS
Mission Zero is open to young people up to age 19 who live in eligible countries (more about eligibility here)
It’s a beginners’ coding activity with step-by-step instructions, available in 19 languages
Completing the activity takes about one hour — at home, in the classroom, or in a Scouts or coding club session
The activity can be done online in a web browser on any computer
Participants will receive a special certificate to help celebrate their space mission
Mission Zero is open until 18 March 2022
If you don’t want to let any young people in your life miss out on this amazing opportunity, sign up as their Mission Zero mentor today.
* The European Astro Pi Challenge is run as a collaboration by us at the Raspberry Pi Foundation and ESA Education. That’s why participants need to be from an ESA Member State, or from Slovenia, Canada, Latvia, Lithuania, or Malta, which have agreements with ESA.
If you live elsewhere, it’s possible to partner with Mission Zero mentors and young people in an eligible country. You can work together to support the young people to form international Mission Zero teams that write programs together.
If you live elsewhere and cannot partner with people in an eligible country, Mission Zero is still an awesome and inspiring project for your young people to try out coding. While these young people’s code unfortunately won’t run on the ISS, they will receive a certificate to mark their efforts.
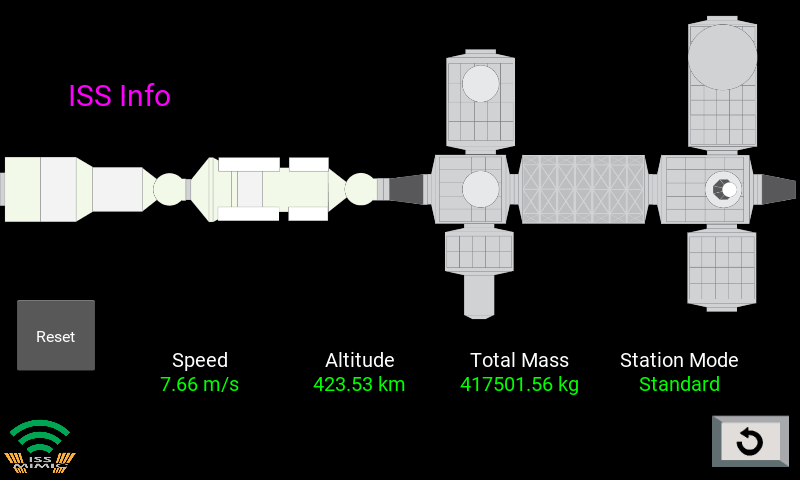
Did you see the coolest International Space Station (ISS) on Earth on the blog last week? ISS Mimic is powered by Raspberry Pi, mirrors exactly what the real ISS is doing in orbit, and was built by NASA engineers to make the ISS feel more real for Earth-bound STEAM enthusiasts.
Here’s (most of) the team behind ISS Mimic
The team launched ISS Mimic in celebration of 20 years of continuous human presence in space on the ISS. And they’ve been getting lots of questions since we posted about their creation so, we asked them back to fill you in with a quick Q&A.
And here are newbies Dallas and Estefannie (Estefannie made the ISS Mimic video)
1. Since this is NASA-related, “MIMIC” must be an acronym, right?
Yes, we forced one: “Mechatronic Instantiated Model, Interactively Controlled”
2. What’s your subtitle?
“The second-most complicated International Space Station ever made”. We also like “1/100th scale for 1/100,000,000th cost”
3. Wait, are US tax dollars paying for you to make this?
No, it’s a volunteer project, but we do get lots of support. It’s done on our own time and money — though many NASA types and others have kicked in to help buy materials.
Yes — mostly other organisations that we have teamed up with. We partner with a non-profit makerspace near NASA, Creatorspace, for tools, materials, and outreach. And an awesome local 3D printer manufacturer, re:3D, has joined us and printed our (large) solar panels for free, and is helping to refine our models. They are also working towards making a kit of parts for sale for those who don’t have a printer or the time to print all the pieces, with a discount for educators.
Particularly helpful has been Space Center Houston (NASA’s visitor center), who invited us to present to the public and at an educator conference (pre-COVID), and allowed us to spend a full day filming in their beautiful facility. Our earliest supporter was Boeing, who we‘ve worked with to facilitate outreach to educators and students from the start.
The real International Space Station (ISS) in orbit
5. How long have you been working on this?
5 years — a looong time. We spent much effort early on to establish the scale and feasibility and test the capabilities of 3D printing. We maintained a hard push to keep the materials cost down and reduce build time/complexity for busy educators. We always knew we’d use Raspberry Pi for the brain, but were looking for less costly options for the mechatronics. We’d still like to cut the cost down a lot to make the project more attainable for lower-income schools and individuals.
6. Have you done any outreach so far?
All of the support has allowed us to take our prototype to schools and STEM events locally. But we really want this to be built around the world to reach those who don’t have much connection to space exploration and hands-on STEM. The big build is probably most suitable for teens and adults, while the alternative builds (in-work) would be much more approachable for younger students.
‘ISS Mimic’ on display
7. So, this just for schools?
No, not at all. Our focus is to make it viable for schools/educators — in cost and build complexity — but we want any space nerd to be able to build their own and help drive the design.
8. Biggest challenge?
Gravity. And time to work on the project… and trying to keep the cost down.
9. What about a Lunar Gateway or Habitat version of ISS Mimic?
It’s on our radar! Another build that’s screaming to be made is hacking the LEGO ISS model (released this year) to rotate its joints and light LEDs.
Raspberry Pi on the real ISS
There are two Raspberry Pi computers aboard the real ISS right now! And even better, young people have the chance to write Python code that will run on them — IN SPACE — as part of the European Astro Pi Challenge.
A sci-fi writer wanted to add some realism to his fiction. The result: a Raspberry Pi-based Martian timepiece. Rosie Hattersley clocks in from the latest issue of The MagPi Magazine.
The Mars Clock project is adapted from code Phil wrote in JavaScript and a Windows environment for Raspberry Pi
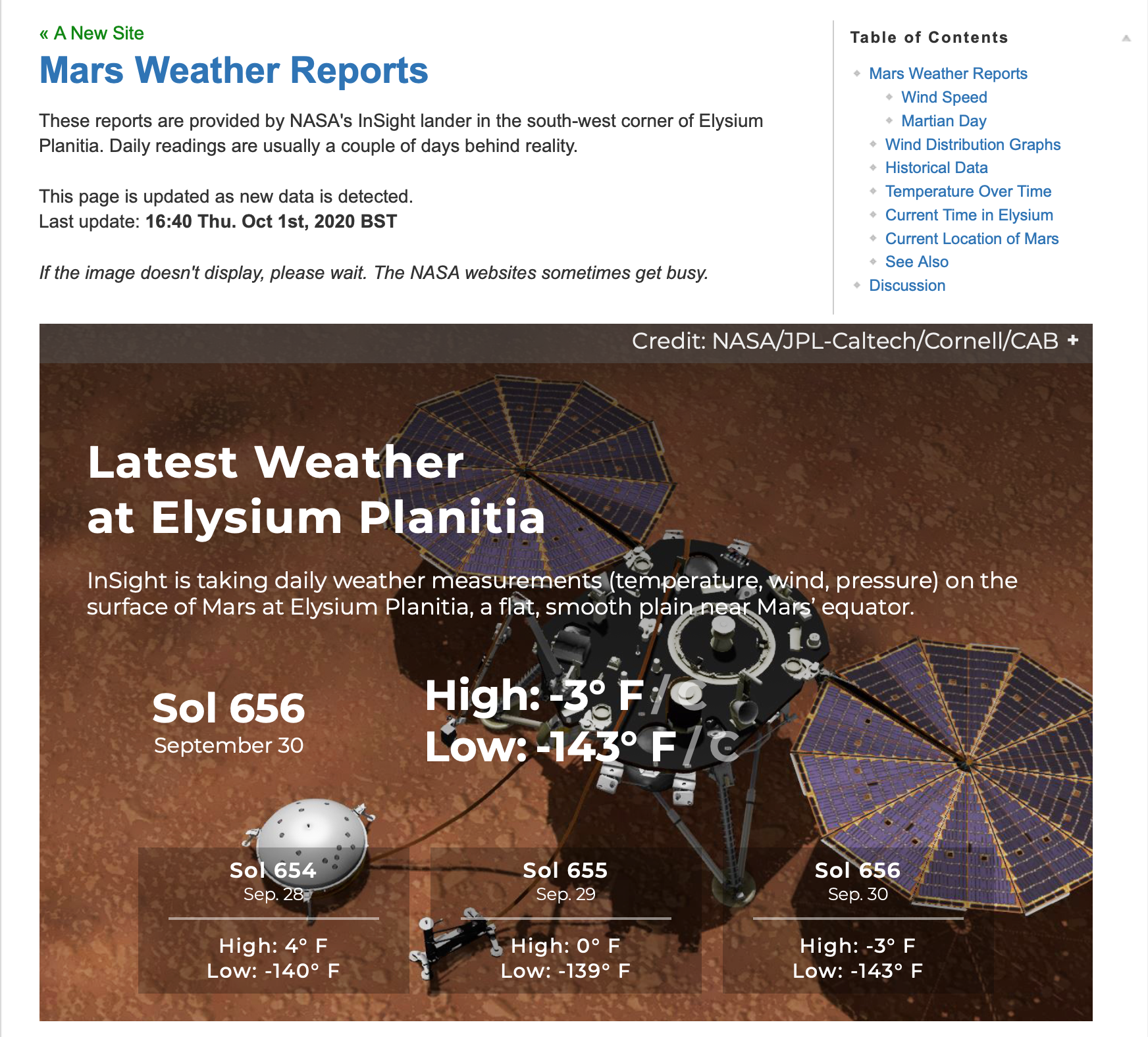
Ever since he first clapped eyes on Mars through the eyepiece of a telescope, Philip Ide has been obsessed with the Red Planet. He’s written several books based there and, many moons ago, set up a webpage showing the weather on Mars. This summer, Phil adapted his weather monitor and created a Raspberry Pi-powered Mars Clock.
Mission: Mars
After writing several clocks for his Mars Weather page, Phil wanted to make a physical clock: “something that could sit on my desk or such like, and tell the time on Mars.” It was to tell the time at any location on Mars, with presets for interesting locations “plus the sites of all the missions that made it to the surface – whether they pancaked or not.”
The projects runs on a 2GB Raspberry Pi 4 with official 7-inch touchscreen
Another prerequisite was that the clock had to check for new mission file updates and IERS bulletins to see if a new leap second had been factored into Universal Coordinated Time.
“Martian seconds are longer,” explains Phil, “so everything was pointing at software rather than a mechanical device. Raspberry Pi was a shoo-in for the job”. However, he’d never used one.
“I’d written some software for calculating orbits and one of the target platforms was Raspberry Pi. I’d never actually seen it run on a Raspberry Pi but I knew it worked, so the door was already open.” He was able to check his data against a benchmark NASA provided. Knowing that the clocks on his Mars Weather page were accurate meant that Phil could focus on getting to grips with his new single-board computer.
Phil’s Mars Weather page shows seasonal trends since March 2019.
He chose a 2GB Raspberry Pi 4 and official-inch touchscreen with a SmartiPi Touch 2 case. “Angles are everything,” he reasons. He also added a fan to lower the CPU temperature and extend the hardware’s life. Along with a power lead, the whole setup cost £130 from The Pi Hut.
Since his Mars Clock generates a lot of data, he made it skinnable so the user can choose which pieces of information to view at any one time. It can display two types of map – Viking or MOLA – depending on the co-ordinates for the clock. NASA provides a web map-tile service with many different data sets for Mars, so it should be possible to make the background an interactive map, allowing you to zoom in/out and scroll around. Getting these to work proved rather a headache as he hit incompatibilities with the libraries.
Learn through experience
Phil wrote most of the software himself, with the exception of libraries for the keyboard and FTP which he pulled from GitHub. Here’s all the code.
The Mars Clock’s various skins show details of missions to Mars, as well as the location’s time and date
He used JavaScript running on the Node.js/Electron framework. “This made for rapid development and is cross-platform, so I could write and test it on Windows and then move it to the Raspberry Pi,” he says. With the basic code written, Phil set about paring it back, reducing the number and duration of CPU time-slices the clock needed when running. “I like optimised software,” he explains.
His decades as a computer programmer meant other aspects were straightforward. The hardware is more than capable, he says of his first ever experience of Raspberry Pi, and the SmartiPi case makers had done a brilliant job. Everything fit together and in just a few minutes his Raspberry Pi was working.
The SmartiPi Touch 2 case houses Raspberry Pi 4 and a fan to cool its CPU
Since completing his Mars Clock Phil has added a pi-hole and a NAS to his Raspberry Pi setup and says his confidence using them is such that he’s now contemplating challenging himself to build an orrery (a mechanical model of the solar system). “I have decades of programming experience, but I was still learning new things as the project progressed,” he says. “The nerd factor of any given object increases exponentially if you make it yourself.”
A group of us NASA engineers work on the International Space Station (ISS) for our day-jobs but craved something more tangible than computer models and data curves to share with the world. So, in our free time, we built ISS Mimic. It’s still in the works, but we are publishing now to celebrate 20 years of continuous human presence in space on the ISS.
This video was filmed and produced by our friend, new teammate, and Raspberry Pi regular Estefannie of Estefannie Explains it All. Most of the images in this blog are screen grabbed from her wonderful video too.
What does Mimic do?
One of the first versions of ISS Mimic at a public event at the Space Center in Houston, before 3D printed parts saved the day
ISS Mimic is a 1% scale model of the International Space Station, bringing the American football field-sized beauty down to a tabletop-sized build. Most elements in the final version of the build which you see in the video are 3D printed — even the solar arrays. It has 12 motors: 10 to control the solar panels and two to turn the thermal radiators. All of these are fed by live data streaming from the ISS, so what you see on ISS Mimic is what’s happening that very moment on the real deal up in space.
Physical connection
Lunch onboard the real ISS
Despite the global ISS effort, most people seem to feel disconnected from space exploration and all the STEAM goodness within. Beyond headlines and rocket launches, even space enthusiasts may feel out of touch. Most of what is available is via apps and videos, which are great, but miss the physical aspect.
Some of the team showing off the earliest version of their homage to the ISS
ISS Mimic is intended to provide an earthbound, tangible connection to that so-close-but-so-far-away orbiting science platform. We want space excitement to fuel STEAM interest.
Raspberry Pi brains and Braun
As you may have guessed, a Raspberry Pi is the brain of the business. Raspberry Pi taps into NASA’s public ISS live data stream to parse the telemetry into the bits we want. There’s JavaScript and tons of Python, including Kivy for the graphics.
The main screen for the Mimic program
Users toggle through various touchscreen data displays of things like battery charge states, electrical power generated, joint angles, communication dish status, gyroscope torques, and even airlock air pressure — fun to watch prior to a spacewalk!
The user can also touchscreen-activate the physical model, in which case Raspberry Pi sends the telemetry along to Arduinos, which in turn command motors in the model to do their thing, rotating the solar panels and thermal radiators to the proper angle. The solar panel joints use compact geared DC motors with Hall-effect sensors for feedback. The sensor signals are sent back down to the Arduino, which keeps track of the position of each joint compared to ISS telemetry, and updates motor command accordingly to stay in sync.
Some of the data Raspberry Pi can receive
The thermal radiator motors are simpler. Since they only rotate about 180° total, a simple RC micro servo is utilised with the desired position sent from an Arduino directly from the Raspberry Pi data stream.
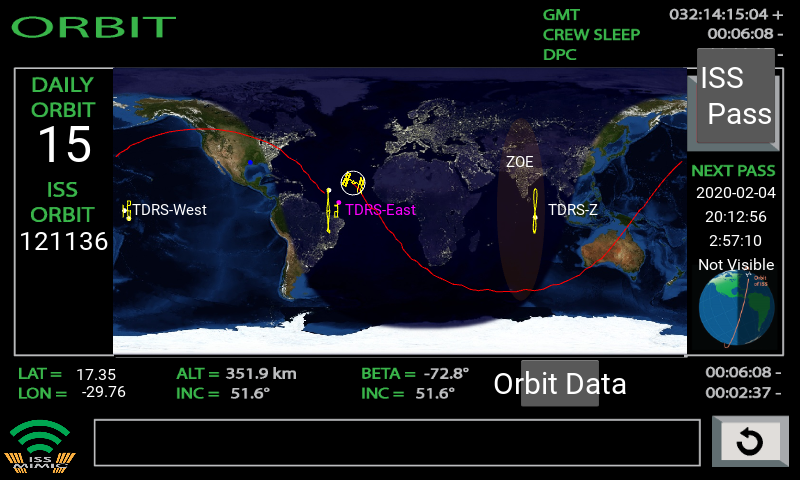
When MIMIC is in ‘live mode’, the motor commands are the exact data stream coming from ISS. This is a fun mode to leave it in for long durations when it’s in the corner of the room. But it changes slowly, so we also include advanced playback, where prior orbit data stored on Raspberry Pi is played back at 60× speed. A regular 90-minute orbit profile can be played back in 90 seconds.
Tracking the ISS orbit
We also have ‘disco mode’, which may have been birthed during lack of sleep, but now we plan to utilise it whenever we want to grab attention — such as to alert users that the ISS is flying overhead.
LED addiction
We may have a mild LED addiction, and we have LEDs embedded where the ISS batteries would live at the base of the solar arrays. They change colour with the charge voltage, so we can tell by watching them when the ISS is going into Earth’s shadow, or when the batteries are fully charged, etc.
That doesn’t look like TOO many LEDs to us…
A few times when we were working on the model and the LEDs suddenly changed, we thought we had bumped something. But it turned out the first array was edging behind Earth. These are fun to watch during spacewalks, and the model gives us advanced notice that the crew is about to be in darkness.
We plan to cram more LEDs in to react to other data. The project is open source, so anyone can build one and improve the design — help wanted! After all, the ISS itself is a worldwide collaboration with 19 countries participating by providing components and crew.
Chaotic wire management
The solar panels on the ISS are mounted on what’s known as the ‘outboard truss’ — one each on the Port and Starboard ends of ISS. Everything on the outboard truss rotates together as part of the sun-tracking (in addition to each solar array rotating individually). So, you can’t just run the power/signal wires through the interface or they would twist and break. ISS Mimic has the same issue.
A closer look at the newest ISS Mimic’s mini solar panels
Even though our solar panels don’t generate power, their motors still require power and signals. The ISS has a specialised, unique build; but fortunately we were able to solve our problem with a simple slip ring design sourced from Amazon.
So twisty. So shiny. So tricky to manage cables for.
Wire management turned out to be a big issue for us. We had bird nests in several places early on (still present on the Port side solar), so we created some custom PCBs just for wire management, to keep the chaos down. We incorporated HDMI connectors and cables in some places to provide nice shielding and convenient sized coupling — actually a bit more compact than the Ethernet we’d used before.
The real ISS flexing its power-generating solar panels in space
Also, those solar panels are huge, and the mechanism that supports the outboard truss (everything on the sides that rotate together) on the ISS includes a massive 10 foot diameter bull gear called the Solar Alpha Rotary Joint. A pinion gear from a motor interfaces with this gear to turn it as needed.
Some of the 3D printed parts for the latest iteration of the build
We were pleasantly surprised that our 3D-printed bull gear held up quite well with a similar pinion-driven design. Overall, our 3D prints have survived better than expected. We are revamping most models to include more detail, and we could certainly use help here.
Education focus
Our sights are set firmly on educators as our primary area of focus, and we’ve been excited to partner with Space Center Houston to speak at public events and a space exploration educator conference with international attendance earlier this year.
Team ISS Mimic at STEM outreach during the first Robotics National Championship
The feedback has been encouraging and enlightening. We want to keep getting feedback from educators, so please provide more insights by either commenting on this blog or via the contact info listed at the bottom.
NASA Mission Control — failure is actually an option… sometimes
A highlight for the team was when the ISS Mimic prototype was requested to live for a month in NASA’s Mission Control Center and was synced to live data during an historic spacewalk. Mimic experienced an ‘anomaly’ when a loose wire caused one of the solar panel motors to spin at 100× the normal rate.
Our tiny computer with the ISS Mimic’s control panel
You’ll be happy to know that none of the engineering professionals were fooled into thinking the real ISS was doing time-trials. Did I mention it’s still a work in progress? You can’t be scared of failure (for non-critical applications!), particularly when developing something brand-new. It’s part of shaking out problems and learning.
Space exploration has an exciting Future
Showing off ISS Mimic during a STEM outreach event at the Space Center in Houston
It’s an exciting time in human and robotic spaceflight, with lots of budding projects and new organisations joining the effort. This feels like a great time to deepen our connection to this great progress, and we hope ISS Mimic can help us to do that, as well as encourage more students to play in coding, mechatronics, and STEAM.
One of the best parts of this project has been teaming up with organisations to share the love. We partner with a non-profit makerspace near NASA called Creatorspace, for tools, materials, and outreach. And an awesome local 3D printer manufacturer, re:3D, has joined us to print some of our larger components for free and is helping to refine our models. Space Center Houston (NASA’s visitor centre) invited us to present to the public and at an educator conference, and generously allowed us to spend a full day filming in their beautiful facility. Our earliest supporter was Boeing, who we’ve worked with to facilitate outreach to educators and students from the start. And of course we are thankful to NASA for providing the public data stream that makes the project possible.
Astro Pi
Did you know that there are Raspberry Pi computers aboard the real ISS that young people can run their own Python programs on? Find out more at astro-pi.org.
High-school student Eleanor Sigrest successfully crowdfunded her way onto a zero-G flight to test her latest Raspberry Pi-powered project. NASA Goddard engineers peer reviewed Eleanor’s experimental design, which detects unwanted movement (or ‘slosh’) in spacecraft fluid tanks.
The Raspberry Pi-packed setup
The apparatus features an accelerometer to precisely determine the moment of zero gravity, along with 13 Raspberry Pis and 12 Raspberry Pi cameras to capture the slosh movement.
What’s wrong with slosh?
The Broadcom Foundation shared a pretty interesting minute-by-minute report on Eleanor’s first hyperbolic flight and how she got everything working. But, in a nutshell…
The full apparatus onboard the zero gravity flight
You don’t want the fluid in your space shuttle tanks sloshing around too much. It’s a mission-ending problem. Slosh occurs on take-off and also in microgravity during manoeuvres, so Eleanor devised this novel approach to managing it in place of the costly, heavy subsystems currently used on board space craft.
Eleanor wanted to prove that the fluid inside tanks treated with superhydrophobic and superhydrophilic coatings settled quicker than in uncoated tanks. And she was right: settling times were reduced by 73% in some cases.
At just 13 years old, Eleanor won the Samueli Prize at the 2016 Broadcom MASTERS for her mastery of STEM principles and team leadership during a rigorous week-long competition. High praise came from Paula Golden, President of Broadcom Foundation, who said: “Eleanor is the epitome of a young woman scientist and engineer. She combines insatiable curiosity with courage: two traits that are essential for a leader in these fields.”
Eleanor aged 13 with her award-winning project ‘Rockets & Nozzles & Thrust… Oh My’
That week-long experience also included a Raspberry Pi Challenge, and Eleanor explained: “During the Raspberry Pi Challenge, I learned that sometimes the simplest solutions are the best. I also learned it’s important to try everyone’s ideas because you never know which one might work the best. Sometimes it’s a compromise of different ideas, or a compromise between complicated and simple. The most important thing is to consider them all.”
Do you know young people who dream of sending something to space? You can help them make that dream a reality!
We’re calling on educators, club leaders, and parents to inspire young people to develop their digital skills by participating in this year’s European Astro Pi Challenge.
The European Astro Pi Challenge, which we run in collaboration with the European Space Agency, gives young people in 26 countries* the opportunity to write their own computer programs and run them on two special Raspberry Pi units — called Astro Pis! — on board the International Space Station (ISS).
This year’s Astro Pi ambassador is ESA astronaut Thomas Pesquet. Thomas will accompany our Astro Pis on the ISS and oversee young people’s programs while they run.
And the young people need your support to take part in the Astro Pi Challenge!
Astro Pi is back big-time!
The Astro Pi Challenge is back and better than ever, with a brand-new website, a cool new look, and the chance for more young people to get involved.
During the last challenge, a record 6558 Astro Pi programs from over 17,000 young people ran on the ISS, and we want even more young people to take part in our new 2020/21 challenge.
British ESA astronaut Tim Peake was the ambassador of the first Astro Pi Challenge in 2015.
So whether your children or learners are complete beginners to programming or have experience of Python coding, we’d love for them to take part!
You and your young people have two Astro Pi missions to choose from: Mission Zero and Mission Space Lab.
Mission Zero — for beginners and younger programmers
In Mission Zero, young people write a simple program to take a humidity reading onboard the ISS and communicate it to the astronauts with a personalised message, which will be displayed for 30 seconds.
Mission Zero is designed for beginners and younger participants up to 14 years old. Young people can complete Mission Zero online in about an hour following a step-by-step guide. Taking part doesn’t require any previous coding experience or specific hardware.
All Mission Zero participants who follow the simple challenge rules are guaranteed to have their programs run aboard the ISS in 2021.
All you need to do is support the young people to submit their programs!
Mission Zero is a perfect activity for beginners to digital making and Python programming, whether they’re young people at home or in coding clubs, or groups of students or club participants.
We have made some exciting changes to this year’s Mission Zero challenge:
Participants will be measuring humidity on the ISS instead of temperature
For the first time, young people can enter individually, as well as in teams of up to 4 people
You have until 19 March 2021 to support your young people to submit their Mission Zero programs!
Mission Space Lab — for young people with programming experience
In Mission Space Lab, teams of young people design and program a scientific experiment to run for 3 hours onboard the ISS.
Mission Space Lab is aimed at more experienced or older participants up to 19 years old, and it takes place in 4 phases over the course of 8 months.
Your role in Mission Space Lab is to mentor a team of participants while they design and write a program for a scientific experiment that increases our understanding of either life on Earth or life in space.
The best experiments will be deployed to the ISS, and teams will have the opportunity to analyse their experimental data and report on their results.
* ESA Member States in 2020: Austria, Belgium, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Luxembourg, the Netherlands, Norway, Poland, Portugal, Romania, Spain, Sweden, Switzerland, Latvia, and the United Kingdom. Other participating states: Canada, Latvia, Slovenia, Malta.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.