Post Syndicated from Brian Smitches original https://aws.amazon.com/blogs/devops/create-a-multi-region-python-package-publishing-pipeline-with-aws-cdk-and-codepipeline/
Customers can author and store internal software packages in AWS by leveraging the AWS CodeSuite (AWS CodePipeline, AWS CodeBuild, AWS CodeCommit, and AWS CodeArtifact). As of the publish date of this blog post, there is no native way to replicate your CodeArtifact Packages across regions. This blog addresses how a custom solution built with the AWS Cloud Development Kit and AWS CodePipeline can create a Multi-Region Python Package Publishing Pipeline.
Whether it’s for resiliency or performance improvement, many customers want to deploy their applications across multiple regions. When applications are dependent on custom software packages, the software packages should be replicated to multiple regions as well. This post will walk through how to deploy a custom package publishing pipeline in your own AWS Account. This pipeline connects a Python package source code repository to build and publish pip packages to CodeArtifact Repositories spanning three regions (the primary and two replica regions). While this sample CDK Application is built specifically for pip packages, the underlying architecture can be reused for different software package formats, such as npm, Maven, NuGet, etc.
Solution overview
The following figure demonstrates the solution workflow:
- A CodePipeline pipeline orchestrates the building and publishing of the software package
-
- This pipeline is triggered by commits on the main branch of the CodeCommit repository
- A CodeBuild job builds the pip packages using twine to be distributed
- The publish stage (third column) uses three parallel CodeBuild jobs to publish the distribution package to the two CodeArtifact repositories in separate regions
- The first CodeArtifact Repository stores the package contents in the primary region.
- The second and third CodeArtifact Repository act as replicas and store the package contents in other regions.
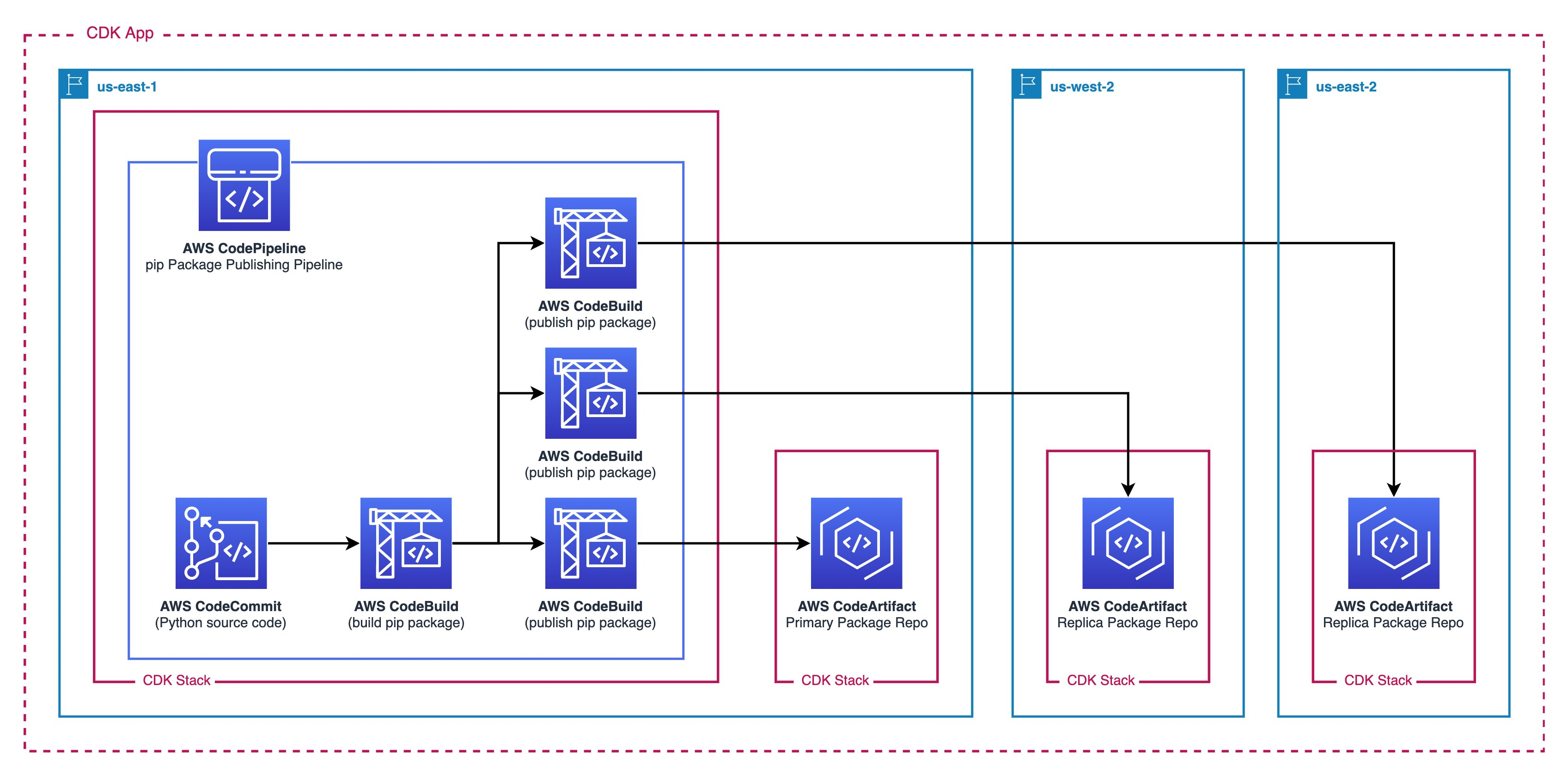
Figure 1. Architecture diagram
All of these resources are defined in a single AWS CDK Application. The resources are defined in CDK Stacks that are deployed as AWS CloudFormation Stacks. AWS CDK can deploy the different stacks across separate regions.
Prerequisites
Before getting started, you will need the following:
- An AWS account
- An instance of the AWS Cloud9 IDE or an alternative local compute environment, such as your personal computer
- The following installed on your compute environment:
-
- AWS CDK
- AWS Command Line Interface (AWS CLI)
- npm
- The AWS Accounts must be bootstrapped for CDK in the necessary regions. The default configuration uses
us-east-1,us-east-2andus-west-2as these three regions support CodeArtifact.
A new AWS Cloud9 IDE is recommended for this tutorial to isolate these actions in this post from your normal compute environment. See the Cloud9 Documentation for Creating an Environment.
Deploy the Python Package Publishing Pipeline into your AWS Account with the CDK
The source code can be found in this GitHub Repository.
- Fork the GitHub Repo into your account. This way you can experiment with changes as necessary to fit your workload.
- In your local compute environment, clone the GitHub Repository and
cdinto the project directory:
- Install the necessary node packages:
- (Optional) Override the default configurations for the CodeArtifact domainName, repositoryName, primaryRegion, and replicaRegions.
- navigate to
./bin/multiregion_package_publishing.tsand update the relevant fields. - From the project’s root directory (
multi-region-python-package-publishing-pipeline), deploy the AWS CDK application. This step may take 5-10 minutes.
- navigate to
- When prompted “Do you wish to deploy these changes (y/n)?”, Enter
y.
Viewing the deployed CloudFormation stacks
After the deployment of the AWS CDK application completes, you can view the deployed AWS CDK Stacks via CloudFormation. From the AWS Console, search “CloudFormation’ in the search bar and navigate to the service dashboard. In the primary region (us-east-1(N. Virginia)) you should see two stacks: CodeArtifactPrimaryStack-<region> and PackagePublishingPipelineStack.

Figure 2. Screenshot showing the CloudFormation Stacks in the primary region
Switch regions to one of the secondary regions us-west-2 (Oregon) or us-east-2 (Ohio) to see the remaining stacks named CodeArtifactReplicaStack-<region>. These correspond to the three AWS CDK Stacks from the architecture diagram.

Figure 3. Screenshot showing the CloudFormation stacks in a separate region
Viewing the CodePipeline Package Publishing Pipeline
From the Console, select the primary region (us-east-1) and navigate to CodePipeline by utilizing the search bar. Select the Pipeline titled packagePipeline and inspect the state of the pipeline. This pipeline triggers after every commit from the CodeCommit repository named PackageSourceCode. If the pipeline is still in process, then wait a few minutes, as this pipeline can take approximately 7–8 minutes to complete all three stages (Source, Build, and Publish). Once it’s complete, the pipeline should reflect the following screenshot:

Figure 4. A screenshot showing the CodePipeline flow
Viewing the Published Package in the CodeArtifact Repository
To view the published artifacts, go to the primary or secondary region and navigate to the CodeArtifact dashboard by utilizing the search bar in the Console. You’ll see a repository named package-artifact-repo. Select the repository and you’ll see the sample pip package named mypippackage inside the repository. This package is defined by the source code in the CodeCommit repository named PackageSourceCode in the primary region (us-east-1).

Figure 5. Screenshot of the package repository
Create a new package version in CodeCommit and monitor the pipeline release
Navigate to your CodeCommit’s PackageSourceCode (us-east-1 CodeCommit > Repositories > PackageSourceCode. Open the setup.py file and select the Edit button. Make a simple modification, change the version = '1.0.0' to version = '1.1.0' and commit the changes to the Main branch.

Figure 6. A screenshot of the source package’s code repository in CodeCommit
Now navigate back to CodePipeline and watch as the pipeline performs the release automatically. When the pipeline finishes, this new package version will live in each of the three CodeArtifact Repositories.
Install the custom pip package to your local Python Environment
For your development team to connect to this CodeArtifact Repository to download repositories, you must configure the pip tool to look in this repository. From your Cloud9 IDE (or local development environment), let’s test the installation of this package for Python3:
- Copy the connection instructions for the pip tool. Navigate to the CodeArtifact repository of your choice and select View connection instructions
- Select Copy to copy the snippet to your clipboard

Figure 7. Screenshot showing directions to connect to a code artifact repository
- Paste the command from your clipboard
- Run
pip install mypippackage==1.0.0

Figure 8. Screenshot showing CodeArtifact login
- Test the package works as expected by importing the modules
- Start the Python REPL by running
python3in the terminal

Figure 9. Screenshot of the package being imported
Clean up
Destroy all of the AWS CDK Stacks by running cdk destroy --all from the root AWS CDK application directory.
Conclusion
In this post, we walked through how to deploy a CodePipeline pipeline to automate the publishing of Python packages to multiple CodeArtifact repositories in separate regions. Leveraging the AWS CDK simplifies the maintenance and configuration of this multi-region solution by using Infrastructure as Code and predefined Constructs. If you would like to customize this solution to better fit your needs, please read more about the AWS CDK and AWS Developer Tools. Some links we suggest include the CodeArtifact User Guide (with sections covering npm, Python, Maven, and NuGet), the CDK API Reference, CDK Pipelines, and the CodePipeline User Guide.
About the authors: