Post Syndicated from Grab Tech original https://engineering.grab.com/real-time-data-ingestion
Typically, modern applications use various database engines for their service needs; within Grab, these would be MySQL, Aurora and DynamoDB. Lately, the Caspian team has observed an increasing need to consume real-time data for many service teams. These real-time changes in database records help to support online and offline business decisions for hundreds of teams.
Because of that, we have invested time into synchronising data from MySQL, Aurora and Dynamodb to the message queue, i.e. Kafka. In this blog, we share how real-time data ingestion has helped since it was launched.
Introduction
Over the last few years, service teams had to write all transactional data twice: once into Kafka and once into the database. This helped to solve the inter-service communication challenges and obtain audit trail logs. However, if the transactions fail, data integrity becomes a prominent issue. Moreover, it is a daunting task for developers to maintain the schema of data written into Kafka.
With real-time ingestion, there is a notably better schema evolution and guaranteed data consistency; service teams no longer need to write data twice.
You might be wondering, why don’t we have a single transaction that spans the services’ databases and Kafka, to make data consistent? This would not work as Kafka does not support being enlisted in distributed transactions. In some situations, we might end up having new data persisting into the services’ databases, but not having the corresponding message sent to Kafka topics.
Instead of registering or modifying the mapped table schema in Golang writer into Kafka beforehand, service teams tend to avoid such schema maintenance tasks entirely. In such cases, real-time ingestion can be adopted where data exchange among the heterogeneous databases or replication between source and replica nodes is required.
While reviewing the key challenges around real-time data ingestion, we realised that there were many potential user requirements to include. To build a standardised solution, we identified several points that we felt were high priority:
- Make transactional data readily available in real time to drive business decisions at scale.
- Capture audit trails of any given database.
- Get rid of the burst read on databases caused by SQL-based query ingestion.
To empower Grabbers with real-time data to drive their business decisions, we decided to take a scalable event-driven approach, which is being facilitated with a bunch of internal products, and designed a solution for real-time ingestion.
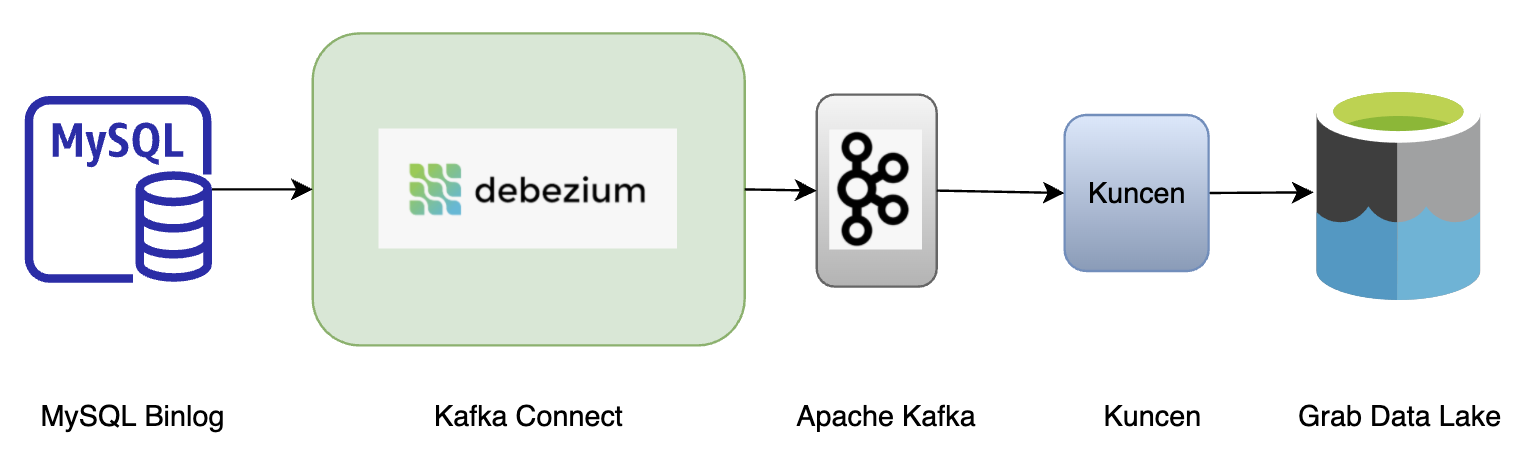
Anatomy of architecture
The solution for real-time ingestion has several key components:
- Stream data storage
- Event producer
- Message queue
- Stream processor
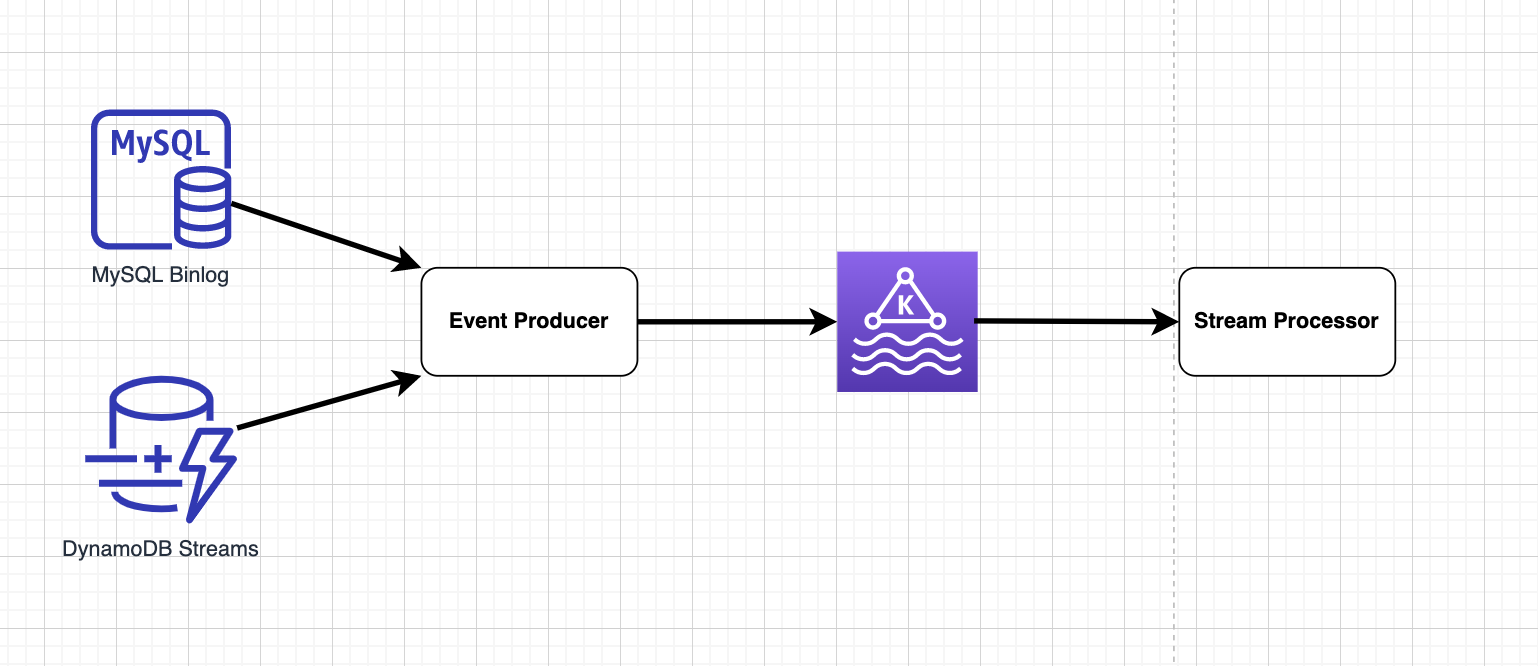
Stream storage
Stream storage acts as a repository that stores the data transactions in order with exactly-once guarantee. However, the level of order in stream storage differs with regards to different databases.
For MySQL or Aurora, transaction data is stored in binlog files in sequence and rotated, thus ensuring global order. Data with global order assures that all MySQL records are ordered and reflects the real life situation. For example, when transaction logs are replayed or consumed by downstream consumers, consumer A’s Grab food order at 12:01:44 pm will always appear before consumer B’s order at 12:01:45 pm.
However, this does not necessarily hold true for DynamoDB stream storage as DynamoDB streams are partitioned. Audit trails of a given record show that they go into the same partition in the same order, ensuring consistent partitioned order. Thus when replay happens, consumer B’s order might appear before consumer A’s.
Moreover, there are multiple formats to choose from for both MySQL binlog and DynamoDB stream records. We eventually set ROW for binlog formats and NEW_AND_OLD_IMAGES for DynamoDB stream records. This depicts the detailed information before and after modifying any given table record. The binlog and DynamoDB stream main fields are tabulated in Figures 2 and 3 respectively.


Event producer
Event producers take in binlog messages or stream records and output to the message queue. We evaluated several technologies for the different database engines.
For MySQL or Aurora, three solutions were evaluated: Debezium, Maxwell, and Canal. We chose to onboard Debezium as it is deeply integrated with the Kafka Connect framework. Also, we see the potential of extending solutions among other external systems whenever moving large collections of data in and out of the Kafka cluster.
One such example is the open source project that attempts to build a custom DynamoDB connector extending the Kafka Connect (KC) framework. It self manages checkpointing via an additional DynamoDB table and can be deployed on KC smoothly.
However, the DynamoDB connector fails to exploit the fundamental nature of storage DynamoDB streams: dynamic partitioning and auto-scaling based on the traffic. Instead, it spawns only a single thread task to process all shards of a given DynamoDB table. As a result, downstream services suffer from data latency the most when write traffic surges.
In light of this, the lambda function becomes the most suitable candidate as the event producer. Not only does the concurrency of lambda functions scale in and out based on actual traffic, but the trigger frequency is also adjustable at your discretion.
Kafka
This is the distributed data store optimised for ingesting and processing data in real time. It is widely adopted due to its high scalability, fault-tolerance, and parallelism. The messages in Kafka are abstracted and encoded into Protobuf.
Stream processor
The stream processor consumes messages in Kafka and writes into S3 every minute. There are a number of options readily available in the market; Spark and Flink are the most common choices. Within Grab, we deploy a Golang library to deal with the traffic.
Use cases
Now that we’ve covered how real-time data ingestion is done in Grab, let’s look at some of the situations that could benefit from real-time data ingestion.
1. Data pipelines
We have thousands of pipelines running hourly in Grab. Some tables have significant growth and generate workload beyond what a SQL-based query can handle. An hourly data pipeline would incur a read spike on the production database shared among various services, draining CPU and memory resources. This deteriorates other services’ performance and could even block them from reading. With real-time ingestion, the query from data pipelines would be incremental and span over a period of time.
Another scenario where we switch to real-time ingestion is when a missing index is detected on the table. To speed up the query, SQL-based query ingestion requires indexing on columns such as created_at, updated_at and id. Without indexing, SQL based query ingestion would either result in high CPU and memory usage, or fail entirely.
Although adding indexes for these columns would resolve this issue, it comes with a cost, i.e. a copy of the indexed column and primary key is created on disk and the index is kept in memory. Creating and maintaining an index on a huge table is much costlier than for small tables. With performance consideration in mind, it is not recommended to add indexes to an existing huge table.
Instead, real-time ingestion overshadows SQL-based ingestion. We can spawn a new connector, archiver (Coban team’s Golang library that dumps data from Kafka at minutes-level frequency) and compaction job to bubble up the table record from binlog to the destination table in the Grab data lake.

2. Drive business decisions
A key use case of enabling real-time ingestion is driving business decisions at scale without even touching the source services. Saga pattern is commonly adopted in the microservice world. Each service has its own database, splitting an overarching database transaction into a series of multiple database transactions. Communication is established among services via message queue i.e. Kafka.
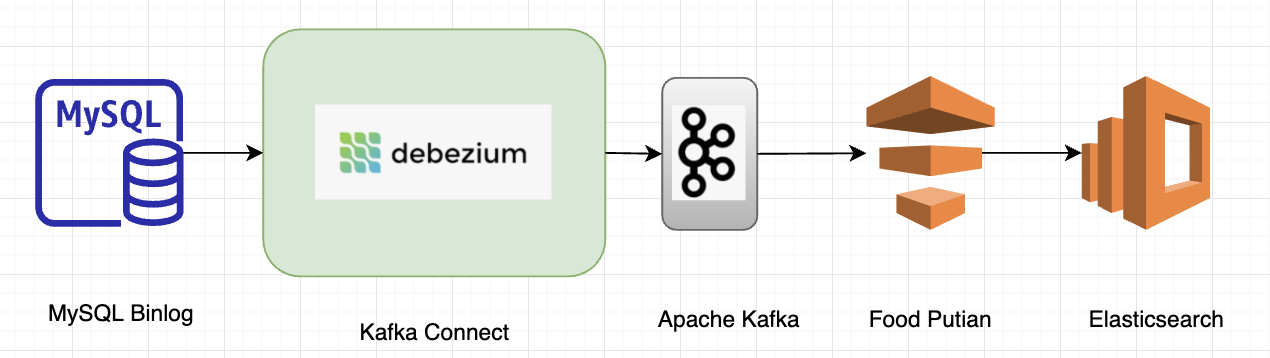
In an earlier tech blog published by the Grab Search team, we talked about how real-time ingestion with Debezium optimised and boosted search capabilities. Each MySQL table is mapped to a Kafka topic and one or multiple topics build up a search index within Elasticsearch.
With this new approach, there is no data loss, i.e. changes via MySQL command line tool or other DB management tools can be captured. Schema evolution is also naturally supported; the new schema defined within a MySQL table is inherited and stored in Kafka. No producer code change is required to make the schema consistent with that in MySQL. Moreover, the database read has been reduced by 90 percent including the efforts of the Data Synchronisation Platform.
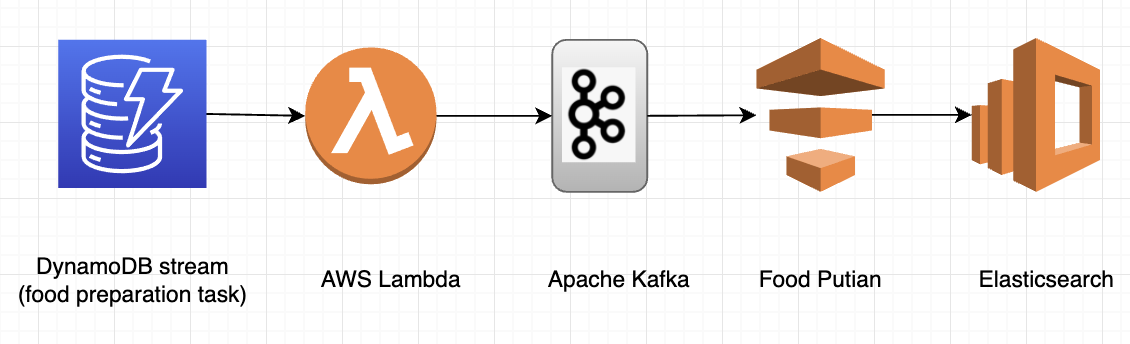
The GrabFood team exemplifies mostly similar advantages in the DynamoDB area. The only differences compared to MySQL are that the frequency of the lambda functions is adjustable and parallelism is auto-scaled based on the traffic. By auto-scaling, we mean that more lambda functions will be auto-deployed to cater to a sudden spike in traffic, or destroyed as the traffic falls.
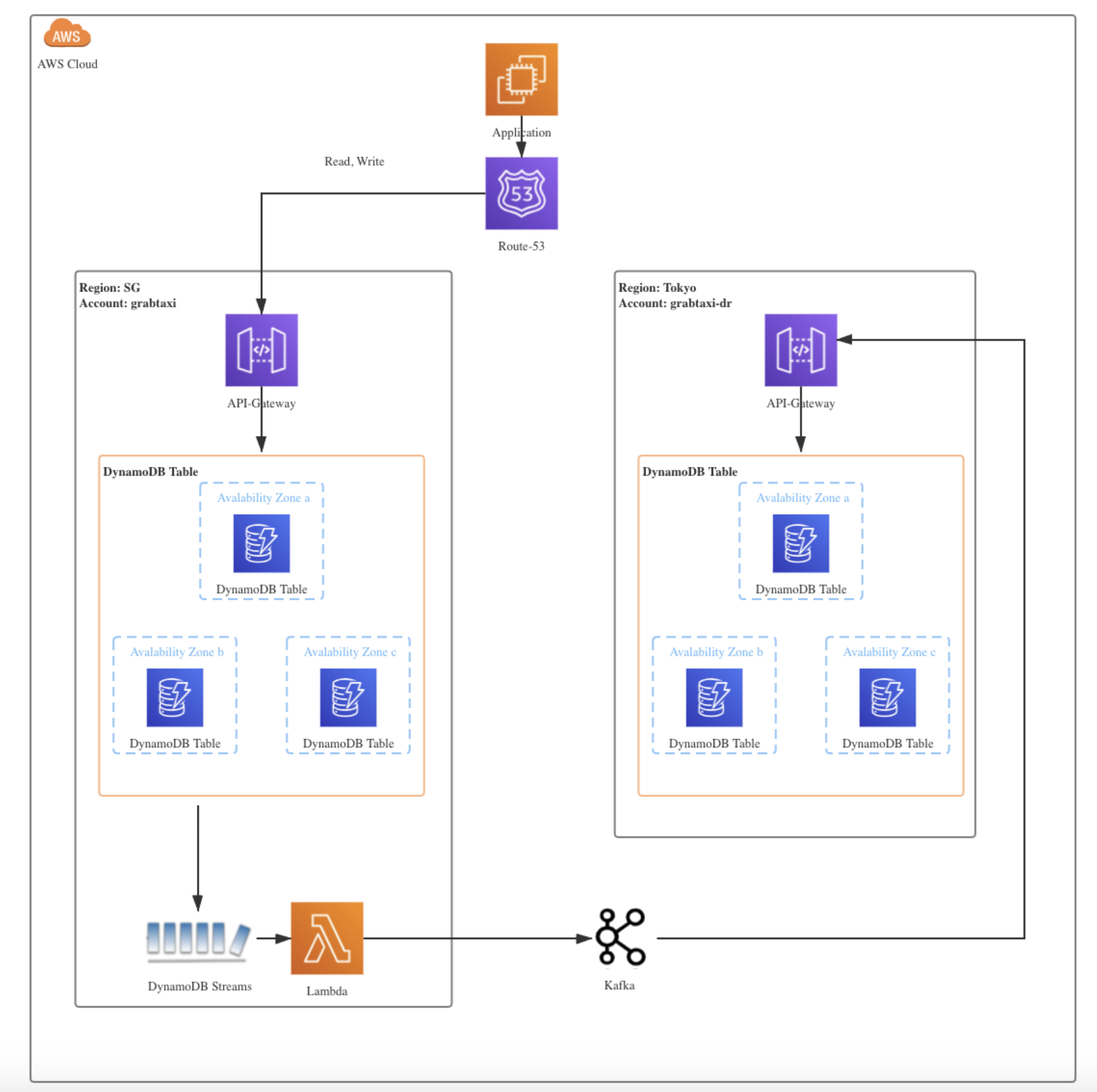
3. Database replication
Another use case we did not originally have in mind is incremental data replication for disaster recovery. Within Grab, we enable DynamoDB streams for tier 0 and critical DynamoDB tables. Any insert, delete, modify operations would be propagated to the disaster recovery table in another availability zone.
When migrating or replicating databases, we use the strangler fig pattern, which offers an incremental, reliable process for migrating databases. This is a method whereby a new system slowly grows on top of an old system and is gradually adopted until the old system is “strangled” and can simply be removed. Figure 7 depicts how DynamoDB streams drive real-time synchronisation between tables in different regions.
4. Deliver audit trails
Reasons for maintaining data audit trails are manifold in Grab: regulatory requirements might mandate businesses to keep complete historical information of a consumer or to apply machine learning techniques to detect fraudulent transactions made by consumers. Figure 8 demonstrates how we deliver audit trails in Grab.
Summary
Real time ingestion is playing a pivotal role in Grab’s ecosystem. It:
- boosts data pipelines with less read pressure imposed on databases shared among various services;
- empowers real-time business decisions with assured resource efficiency;
- provides data replication among tables residing in various regions; and
- delivers audit trails that either keep complete history or help unearth fraudulent operations.
Since this project launched, we have made crucial enhancements to facilitate daily operations with several in-house products that are used for data onboarding, quality checking, maintaining freshness, etc.
We will continuously improve our platform to provide users with a seamless experience in data ingestion, starting with unifying our internal tools. Apart from providing a unified platform, we will also contribute more ideas to the ingestion, extending it to Azure and GCP, supporting multi-catalogue and offering multi-tenancy.
In our next blog, we will drill down to other interesting features of real-time ingestion, such as how ordering is achieved in different cases and custom partitioning in real-time ingestion. Stay tuned!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!