Post Syndicated from Samit Kumbhani original https://aws.amazon.com/blogs/security/how-to-use-aws-database-encryption-sdk-for-client-side-encryption-and-perform-searches-on-encrypted-attributes-in-dynamodb-tables/
Today’s applications collect a lot of data from customers. The data often includes personally identifiable information (PII), that must be protected in compliance with data privacy laws such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). Modern business applications require fast and reliable access to customer data, and Amazon DynamoDB is an ideal choice for high-performance applications at scale. While server-side encryption options exist to safeguard customer data, developers can also add client-side encryption to further enhance the security of their customer’s data.
In this blog post, we show you how the AWS Database Encryption SDK (DB-ESDK) – an upgrade to the DynamoDB Encryption Client – provides client-side encryption to protect sensitive data in transit and at rest. At its core, the DB-ESDK is a record encryptor that encrypts, signs, verifies, and decrypts the records in DynamoDB table. You can also use DB-ESDK to search on encrypted records and retrieve data, thereby alleviating the need to download and decrypt your entire dataset locally. In this blog, we demonstrate how to use DB-ESDK to build application code to perform client-side encryption of sensitive data within your application before transmitting and storing it in DynamoDB and then retrieve data by searching on encrypted fields.
Client-side encryption
For protecting data at rest, many AWS services integrate with AWS Key Management Service (AWS KMS). When you use server-side encryption, your plaintext data is encrypted in transit over an HTTPS connection, decrypted at the service endpoint, and then re-encrypted by the service before being stored. Client-side encryption is the act of encrypting your data locally to help ensure its security in transit and at rest. When using client-side encryption, you encrypt the plaintext data from the source (for example, your application) before you transmit the data to an AWS service. This verifies that only the authorized users with the right permission to the encryption key can decrypt the ciphertext data. Because data is encrypted inside an environment that you control, it is not exposed to a third party, including AWS.
While client-side encryption can be used to improve overall security posture, it introduces additional complexity on the application, including managing keys and securely executing cryptographic tasks. Furthermore, client-side encryption often results in reduced portability of the data. After data is encrypted and written to the database, it’s generally not possible to perform additional tasks such as creating index on the data or search directly on the encrypted records without first decrypting it locally. In the next section, you’ll see how you can address these issues by using the AWS Database Encryption SDK (DB-ESDK)—to implement client-side encryption in your DynamoDB workloads and perform searches.
AWS Database Encryption SDK
DB-ESDK can be used to encrypt sensitive attributes such as those containing PII attributes before storing them in your DynamoDB table. This enables your application to help protect sensitive data in transit and at rest, because data cannot be exposed unless decrypted by your application. You can also use DB-ESDK to find information by searching on encrypted attributes while your data remains securely encrypted within the database.
In regards to key management, DB-ESDK gives you direct control over the data by letting you supply your own encryption key. If you’re using AWS KMS, you can use key policies to enforce clear separation between the authorized users who can access specific encrypted data and those who cannot. If your application requires storing multiple tenant’s data in single table, DB-ESDK supports configuring distinct key for each of those tenants to ensure data protection. Follow this link to view how searchable encryption works for multiple tenant databases.
While DB-ESDK provides many features to help you encrypt data in your database, in this blog post, we focus on demonstrating the ability to search on encrypted data.
How the AWS Database Encryption SDK works with DynamoDB
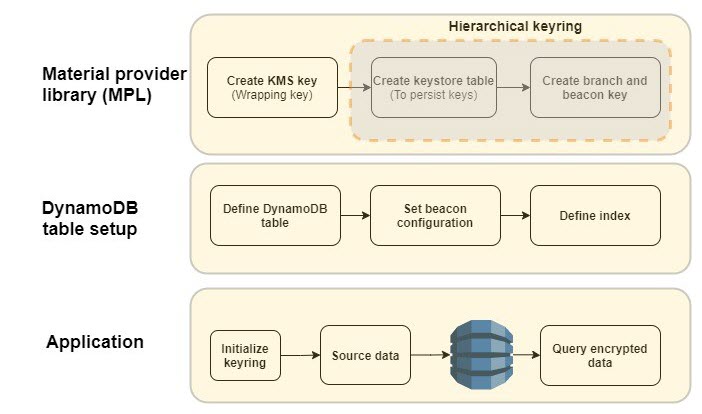
Figure 1: DB-ESDK overview
As illustrated in Figure 1, there are several steps that you must complete before you can start using the AWS Database Encryption SDK. First, you need to set up your cryptographic material provider library (MPL), which provides you with the lower level abstraction layer for managing cryptographic materials (that is, keyrings and wrapping keys) used for encryption and decryption. The MPL provides integration with AWS KMS as your keyring and allows you to use a symmetric KMS key as your wrapping key. When data needs to be encrypted, DB-ESDK uses envelope encryption and asks the keyring for encryption material. The material consists of a plaintext data key and an encrypted data key, which is encrypted with the wrapping key. DB-ESDK uses the plaintext data key to encrypt the data and stores the ciphertext data key with the encrypted data. This process is reversed for decryption.
The AWS KMS hierarchical keyring goes one step further by introducing a branch key between the wrapping keys and data keys. Because the branch key is cached, it reduces the number of network calls to AWS KMS, providing performance and cost benefits. The hierarchical keyring uses a separate DynamoDB table is referred as the keystore table that must be created in advance. The mapping of wrapping keys to branch keys to data keys is handled automatically by the MPL.
Next, you need to set up the main DynamoDB table for your application. The Java version of DB-ESDK for DynamoDB provides attribute level actions to let you define which attribute should be encrypted. To allow your application to search on encrypted attribute values, you also must configure beacons, which are truncated hashes of plaintext value that create a map between the plaintext and encrypted value and are used to perform the search. These configuration steps are done once for each DynamoDB table. When using beacons, there are tradeoffs between how efficient your queries are and how much information is indirectly revealed about the distribution of your data. You should understand the tradeoff between security and performance before deciding if beacons are right for your use case.
After the MPL and DynamoDB table are set up, you’re ready to use DB-ESDK to perform client-side encryption. To better understand the preceding steps, let’s dive deeper into an example of how this all comes together to insert data and perform searches on a DynamoDB table.
AWS Database Encryption SDK in action
Let’s review the process of setting up DB-ESDK and see it in action. For the purposes of this blog post, let’s build a simple application to add records and performs searches.
The following is a sample plaintext record that’s received by the application:
Prerequisite: For client side encryption to work, set up the integrated development environment (IDE) of your choice or set up AWS Cloud9.
Note: To focus on DB-ESDK capabilities, the following instructions omit basic configuration details for DynamoDB and AWS KMS.
Configure DB-ESDK cryptography
As mentioned previously, you must set up the MPL. For this example, you use an AWS KMS hierarchical keyring.
- Create KMS key: Create the wrapping key for your keyring. To do this, create a symmetric KMS key using the AWS Management Console or the API.
- Create keystore table: Create a DynamoDB table to serve as a keystore to hold the branch keys. The logical keystore name is cryptographically bound to the data stored in the keystore table. The logical keystore name can be the same as your DynamoDB table name, but it doesn’t have to be.
- Create keystore keys: This operation generates the active branch key and beacon key using the KMS key from step 1 and stores it in the keystore table. The branch and beacon keys will be used by DB-ESDK for encrypting attributes and generating beacons.
At this point, the one-time set up to configure the cryptography material is complete.
Set up a DynamoDB table and beacons
The second step is to set up your DynamoDB table for client-side encryption. In this step, define the attributes that you want to encrypt, define beacons to enable search on encrypted data, and set up the index to query the data. For this example, use the Java client-side encryption library for DynamoDB.
- Define DynamoDB table: Define the table schema and the attributes to be encrypted. For this blog post, lets define the schema based on the sample record that was shared previously. To do that, create a DynamoDB table called OrderInfo with order_id as the partition key and order_time as the sort key.
DB-ESDK provides the following options to define the sensitivity level for each field. Define sensitivity level for each of the attributes based on your use case.
- ENCRYPT_AND_SIGN: Encrypts and signs the attributes in each record using a unique encryption key. Choose this option for attributes with data you want to encrypt.
- SIGN_ONLY: Adds a digital signature to verify the authenticity of your data. Choose this option for attributes that you would like to protect from being altered. The partition and sort key should always be set as SIGN_ONLY.
- DO_NOTHING: Does not encrypt or sign the contents of the field and stores the data as-is. Only choose this option if the field doesn’t contain sensitive data and doesn’t need to be authenticated with the rest of your data. In this example, the partition key and sort key will be defined as “Sign_Only” attributes. All additional table attributes will be defined as “Encrypt and Sign”: email, firstname, lastname, last4creditcard and expirydate.
- Configure beacons: Beacons allow searches on encrypted fields by creating a mapping between the plaintext value of a field and the encrypted value that’s stored in your database. Beacons are generated by DB-ESDK when the data is being encrypted and written by your application. Beacons are stored in your DynamoDB table along with your encrypted data in fields labelled with the prefix aws_dbe_b_.
It’s important to note that beacons are designed to be implemented in new, unpopulated tables only. If configured on existing tables, beacons will only map to new records that are written and the older records will not have the values populated. There are two types of beacons – standard and compound. The type of beacon you configure determines the type of queries you are able to perform. You should select the type of beacon based on your queries and access patterns:
- Standard beacons: This beacon type supports querying a single source field using equality operations such as equals and not-equals. It also allows you to query a virtual (conceptual) field by concatenating one or more source fields.
- Compound beacons: This beacon type supports querying a combination of encrypted and signed or signed-only fields and performs complex operations such as begins with, contains, between, and so on. For compound beacons, you must first build standard beacons on individual fields. Next, you need to create an encrypted part list using a unique prefix for each of the standard beacons. The prefix should be a short value and helps differentiate the individual fields, simplifying the querying process. And last, you build the compound beacon by concatenating the standard beacons that will be used for searching using a split character. Verify that the split character is unique and doesn’t appear in any of the source fields’ data that the compound beacon is constructed from.
Along with identifying the right beacon type, each beacon must be configured with additional properties such as a unique name, source field, and beacon length. Continuing the previous example, let’s build beacon configurations for the two scenarios that will be demonstrated in this blog post.
Scenario 1: Identify orders by exact match on the email address.
In this scenario, search needs to be conducted on a singular attribute using equality operation.
- Beacon type: Standard beacon.
- Beacon name: The name can be the same as the encrypted field name, so let’s set it as email.
- Beacon length: For this example, set the beacon length to 15. For your own uses cases, see Choosing a beacon length.
Scenario 2: Identify orders using name (first name and last name) and credit card attributes (last four digits and expiry date).
In this scenario, multiple attributes are required to conduct a search. To satisfy the use case, one option is to create individual compound beacons on name attributes and credit card attributes. However, the name attributes are considered correlated and, as mentioned in the beacon selection guidance, we should avoid building a compound beacon on such correlated fields. Instead in this scenario we will concatenate the attributes and build a virtual field on the name attributes
- Beacon type: Compound beacon
- Beacon Configuration:
- Define a virtual field on firstname and lastname, and label it fullname.
- Define standard beacons on each of the individual fields that will be used for searching: fullname, last4creditcard, and expirydate. Follow the guidelines for setting standard beacons as explained in Scenario 1.
- For compound beacons, create an encrypted part list to concatenate the standard beacons with a unique prefix for each of the standard beacons. The prefix helps separate the individual fields. For this example, use C- for the last four digits of the credit card and E- for the expiry date.
- Build the compound beacons using their respective encrypted part list and a unique split character. For this example, use ~ as the split character.
- Beacon length: Set beacon length to 15.
- Beacon Name: Set the compound beacon name as CardCompound.
- Define index: Following DynamoDB best practices, secondary indexes are often essential to support query patterns. DB-ESDK performs searches on the encrypted fields by doing a look up on the fields with matching beacon values. Therefore, if you need to query an encrypted field, you must create an index on the corresponding beacon fields generated by the DB-ESDK library (attributes with prefix aws_dbe_b_), which will be used by your application for searches.
For this step, you will manually create a global secondary index (GSI).
Scenario 1: Create a GSI with aws_dbe_b_email as the partition key and leave the sort key empty. Set the index name as aws_dbe_b_email-index. This will allow searches using the email address attribute.
Scenario 2: Create a GSI with aws_dbe_b_FullName as the partition key and aws_dbe_b_CardCompound as the sort key. Set the index name as aws_dbe_b_VirtualNameCardCompound-index. This will allow searching based on firstname, lastname, last four digits of the credit card, and the expiry date. At this point the required DynamoDB table setup is complete.
Set up the application to insert and query data
Now that the setup is complete, you can use the DB-ESDK from your application to insert new items into your DynamoDB table. DB-ESDK will automatically fetch the data key from the keyring, perform encryption locally, and then make the put call to DynamoDB. By using beacon fields, the application can perform searches on the encrypted fields.
- Keyring initialization: Initialize the AWS KMS hierarchical keyring.
- Insert source data: For illustration purpose, lets define a method to load sample data into the OrderInfo table. By using DB-ESDK, the application will encrypt data attributes as defined in the DynamoDB table configuration steps.
- Query Data: Define a method to query data using plaintext values
Scenario 1: Identify orders associated with email address [email protected]. This query should return Order ID ABC-1001.
Scenario 2: Identify orders that were placed by John Doe using a specific credit card with the last four digits of 4567 and expiry date of 082026. This query should return Order ID ABC-1003 and ABC-1004.
Note: Compound beacons support complex string operation such as begins_with. In Scenario 2, if you had only the name attributes and last four digits of the credit card, you could still use the compound beacon for querying. You can set the values as shown below to query the beacon using the same code:
Now that you have the building blocks, let’s bring this all together and run the following steps to set up the application. For this example, a few of the input parameters have been hard coded. In your application code, replace <KMS key ARN> and <branch-key-id derived from keystore table> from Step 1 and Step 3 mentioned in the Configure DB-ESDK cryptography sections.
Conclusion
You’ve just seen how to build an application that encrypts sensitive data on client side, stores it in a DynamoDB table and performs queries on the encrypted data transparently to the application code without decrypting the entire data set. This allows your applications to realize the full potential of the encrypted data while adhering to security and compliance requirements. The code snippet used in this blog is available for reference on GitHub. You can further read the documentation of the AWS Database Encryption SDK and reference the source code at this repository. We encourage you to explore other examples of searching on encrypted fields referenced in this GitHub repository.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.