Post Syndicated from João Tomé original https://blog.cloudflare.com/euro-2024s-impact-on-internet-traffic-a-closer-look-at-finalists-spain-and-england

National team sports unite countries, and football (known as “soccer” in the US) is the world’s most popular sport, boasting approximately 3.5 billion fans globally. The UEFA Euro 2024, running from June 14 to July 14, 2024, significantly impacts Internet traffic across participating European nations. This blog post focuses on the two finalists, Spain and England, and comes after an initial post we published during the first week of the tournament.
Analyzing traffic patterns reveals distinct high-level trends. Spain saw the most significant drops in Internet traffic during games against major teams and former champions such as Italy (the defending champion), Germany, and France. In contrast, England’s games had crucial moments towards the end, leading to the largest traffic reductions in the UK, especially during the knockout stages.
For context, as previously mentioned, football games like the Super Bowl, differ from other events such as elections. When major teams or national squads play, especially in matches that captivate many viewers, Internet traffic often drops. This is particularly true if the game is broadcast on a national TV channel. During such broadcasts, people tend to focus more on their TV sets, relying on the traditional broadcast signal rather than online streaming, especially for games that aren’t behind a paywall. This is a typical scenario when national teams play in Europe.
Semifinals: differences between four countries
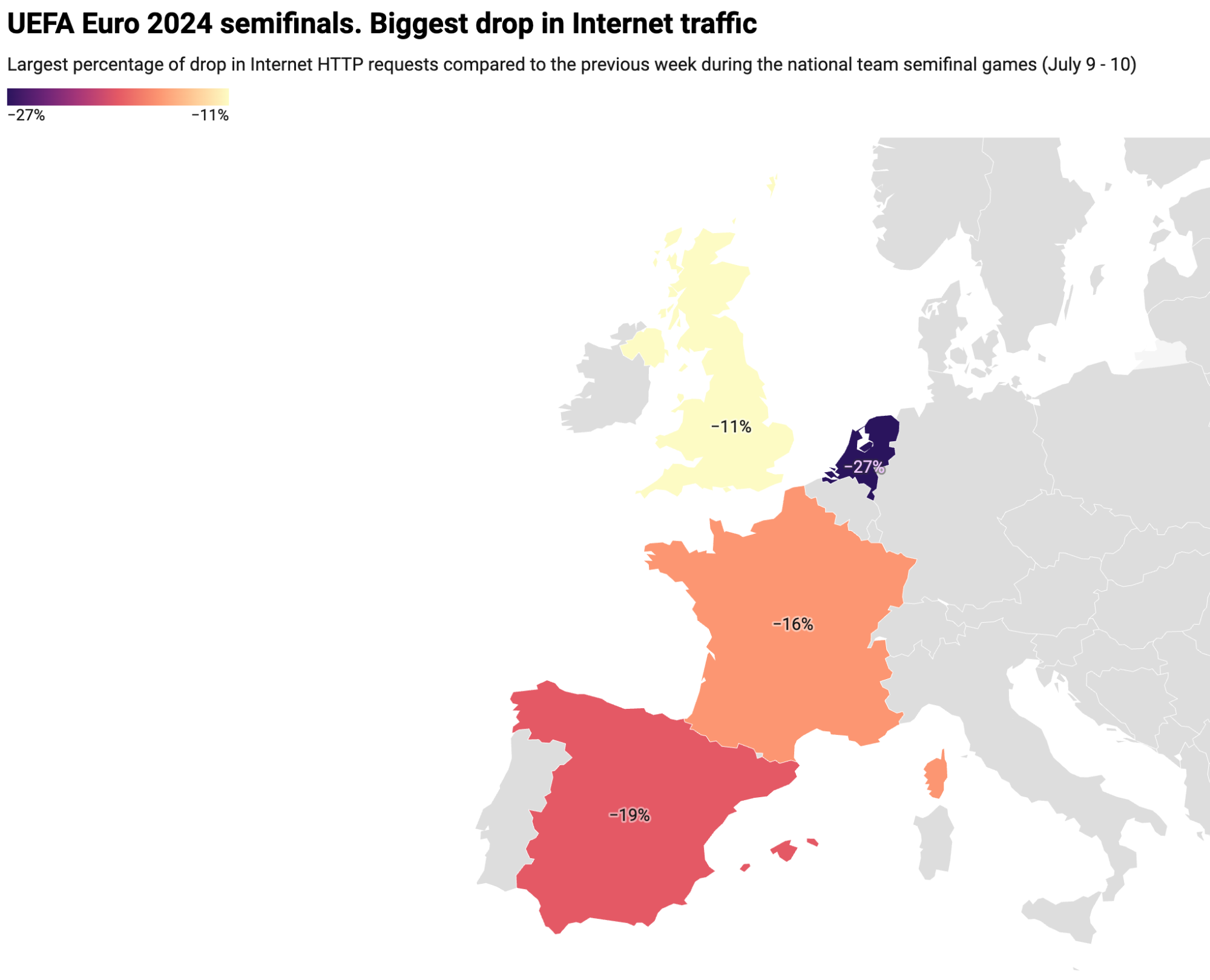
Let’s first analyze the impact of the semifinals on the four countries with national teams playing, using UK-related data for England. The following table displays the traffic drop percentages and the times of the largest declines during the Spain vs. France and Netherlands vs. England matches. Note that England is the only one not on Central European Time.
In both Spain and the UK, traffic decreased the most at the end of the game, details of which are provided below. In France and the Netherlands, significant drops of 16% and 27% respectively occurred primarily in the first half.
| Country | Drop on traffic | Date / time of biggest drop (local time) |
|---|---|---|
| Spain | -19% | Jul 9, 22:45 |
| France | -16% | Jul 9, 21:00 |
| Netherlands | -27% | Jul 10, 21:15 |
| England (UK) | -11% | July 10, 21:45 |
Traffic in the UK: England’s late goal impact
England’s matches frequently saw crucial moments near the end, leading to the largest dips in UK Internet traffic. This trend was especially pronounced during the knockout phases and after Scotland’s exit from the tournament. England’s tournament opener, a win against Serbia on June 16, experienced the most significant traffic drop at the game’s start – an 8% decrease from the previous week.
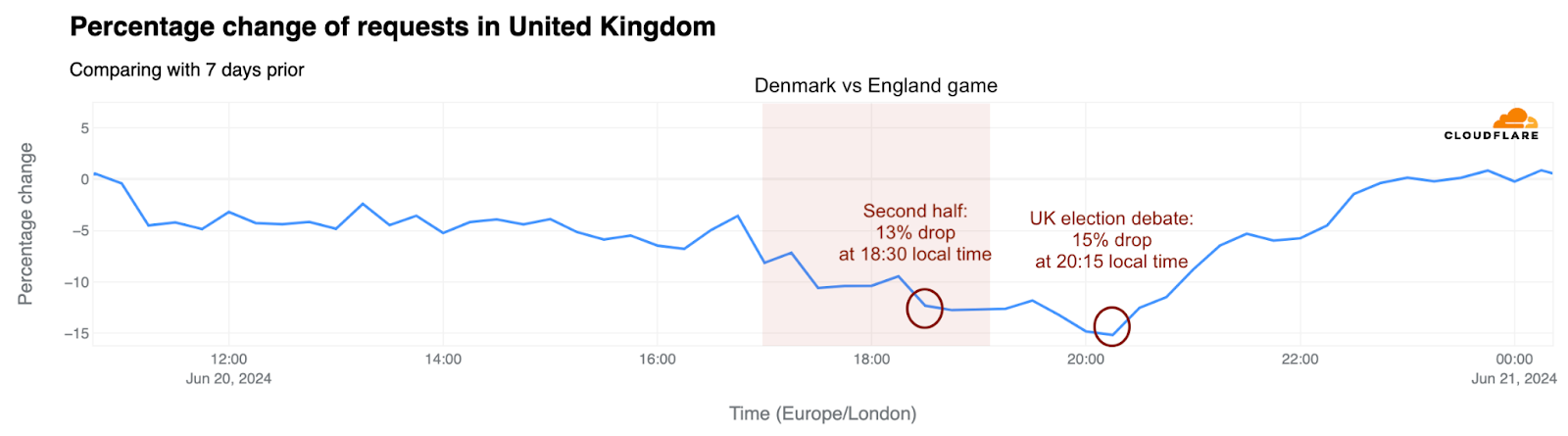
UK election debate vs England’s game
The second game, on June 20, against Denmark, ended in a draw and saw a bigger drop in traffic. During the game, traffic in the UK initially dropped 8% compared to the previous week, then fell even further in the second half, by as much as 13%. Following the game, the BBC broadcast a significant live event – the debate between the country’s four major political parties. It started at 20:00 local time, and 15 minutes later, traffic experienced its largest drop of the day: 15%.
The third and final group stage game for England, a draw against Slovenia, saw a 5% drop in Internet traffic during the second half and a 4% drop in the first half. In the round of 16 game against Slovakia on June 30, traffic dipped 9% in the UK towards the end of the second half as Jude Bellingham scored a crucial late goal. During extra time, when Harry Kane scored, traffic decreased further to 10% below the previous week’s level.
Next, during the July 6 quarter-final against Switzerland, traffic in the UK dipped 3% during the game, mostly towards the end of regular time. However, it decreased further by 11% towards the end of extra time and during the penalty shootouts.
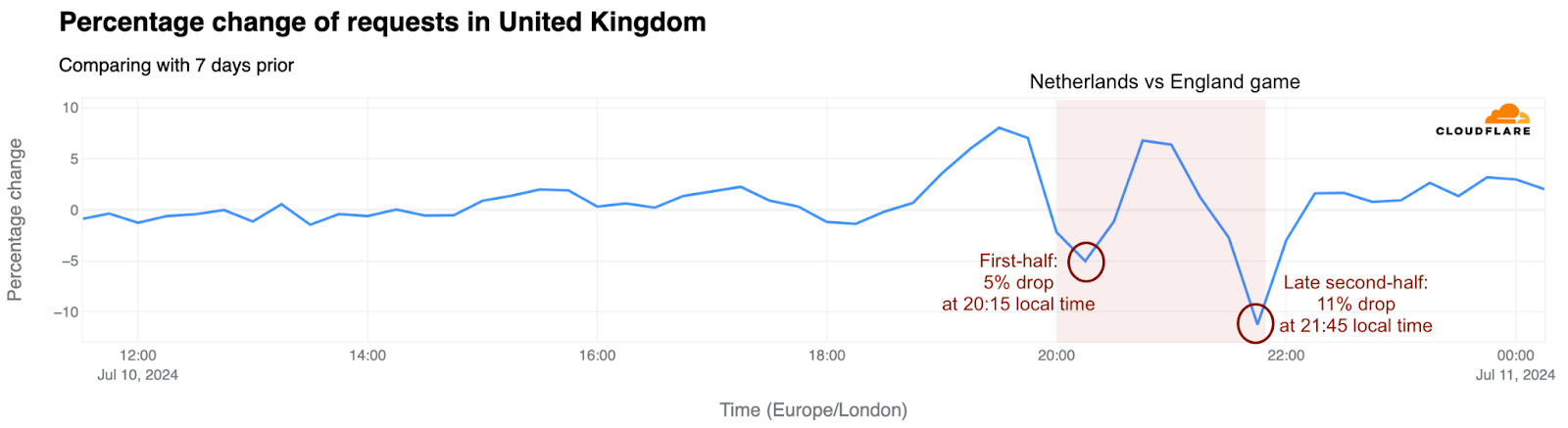
The semi-final between England and the Netherlands on July 10, 2024, experienced a noticeable drop in UK traffic – 5% at 20:15, when the first two goals were scored. Traffic decreased further, to 11% below the previous week, at the end of the game as Ollie Watkins scored the winning goal, securing England’s spot in the final.
Spain’s big game traffic impact
Spain was the only team to win all its matches without going to penalties throughout the tournament. The most significant drops in Internet traffic occurred during games against other major teams and previous titleholders like Italy, Germany, and France.
Spain’s first game in the tournament against Croatia on June 15, during dinner time in the country, ended in a decisive 3-0 win. It was accompanied by a significant drop in traffic – 7% in the first half and 9% in the second.
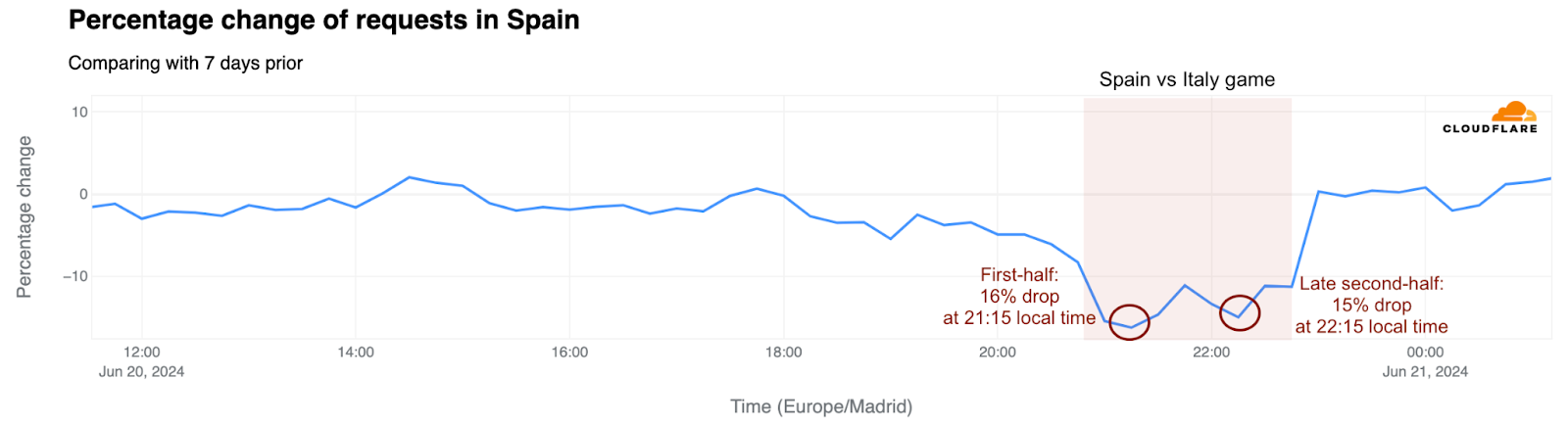
The June 20 match against Italy, featuring two teams with rich histories of European and World titles – and Italy as the defending champion – captured significant attention. Also broadcast on national TV, as the other games were, it led to substantial drops in traffic: a 16% decrease early in the first half, and a 15% drop in the second half, right after halftime, aligning with Calafiori’s goal that secured Spain’s win.
The final group stage game for Spain against Albania on June 24, which was non-decisive with Spain’s advancement already secured, saw a traffic decrease of 6%. Then came the knockout phase. It began with a round of 16 match against Georgia on June 30, where traffic fell by up to 8%, with a more pronounced drop in the first half coinciding with Spain equalizing the game.
The July 5 quarterfinals against host Germany was also a game that matched two football giants, in terms of national team international football titles. The game began with an initial 10% decline in traffic, followed by a 7% drop in the second half, and an 8% drop at the end of extra time, around the time Merino scored the winning goal.
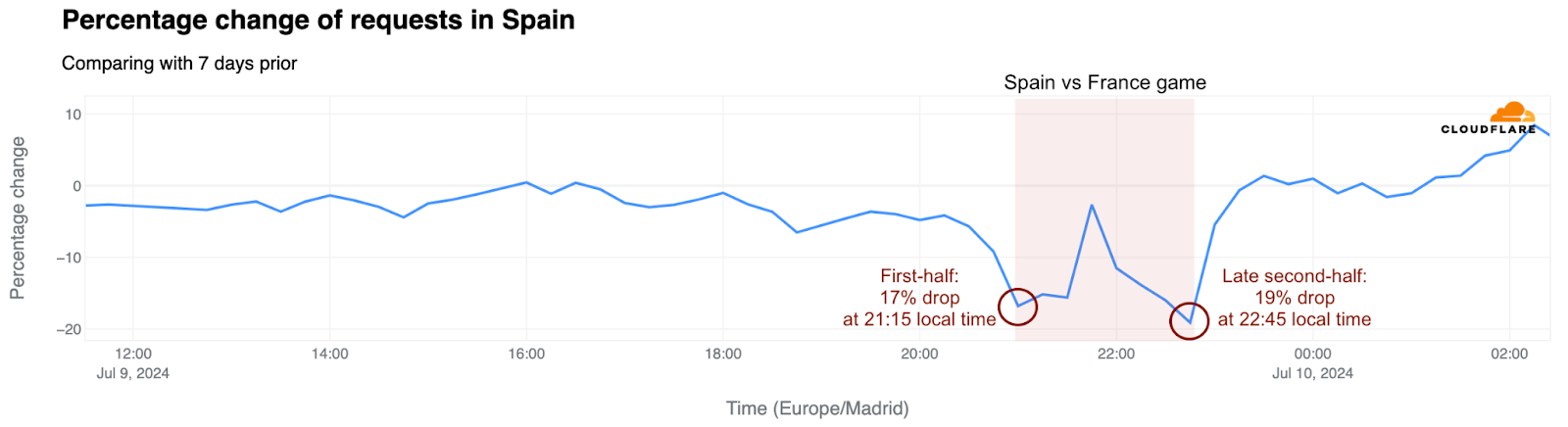
Spain’s semi-final on July 9 saw early goals and a swift turnaround after France’s initial goal. The game started with a 17% drop in traffic compared to the previous week, persisting through the first half. By the end of the second half, as France aggressively sought to score and Spain defended vigorously to avoid extra time, traffic dipped further to a 19% drop. Ultimately, the Spanish squad secured a spot in the final.
Conclusion
The UEFA Euro 2024 has significantly impacted Internet traffic across participating European countries from Cloudflare’s perspective. Games broadcast on national TV drew fans’ attention away from the Internet. Critical moments such as last-minute goals, extra time, or penalty shootouts also led to larger drops in traffic as fans focused more on the game.
Also, distinct patterns have emerged in the finalist countries, Spain and England. For Spain, matches against traditional football powerhouses resulted in noticeable drops in traffic, indicating high viewer engagement during key matches. England’s games also saw significant traffic reductions at critical moments, particularly during the knockout stages.
For more trends and insights about the Internet and major events like the Olympics and the 2024 elections (including a regularly updated report), check out Cloudflare Radar for the latest updates.