Post Syndicated from Emily Terrell original https://blog.cloudflare.com/patent-troll-sable-pays-up
Back in February, we celebrated our victory at trial in the U.S. District Court for the Western District of Texas against patent trolls Sable IP and Sable Networks. This was the culmination of nearly three years of litigation against Sable, but it wasn’t the end of the story.
Today we’re pleased to announce that the litigation against Sable has finally concluded on terms that we believe send a strong message to patent trolls everywhere — if you bring meritless patent claims against Cloudflare, we will fight back and we will win.
We’re also pleased to announce additional prizes in Project Jengo, and to make a final call for submissions before we determine the winners of the Final Awards. As a reminder, Project Jengo is Cloudflare’s effort to fight back against patent trolls by flipping the incentive structure that has encouraged the growth of patent trolls who extract settlements out of companies using frivolous lawsuits. We do this by asking the public to help identify prior art that can invalidate any of the patents that a troll holds, not just the ones that are asserted against Cloudflare. We’ve already given out over $125,000 to individuals since the launch of Project Jengo in 2017, and we’re looking forward to celebrating the successful end of the Sable iteration of Project Jengo with our Final Awards!
To learn more about how things concluded with Sable and next steps in Project Jengo, read on.
Background
For anyone just joining us on this odyssey, here is a little background on how we got here:
Sable sued Cloudflare back in March 2021. Sable is a patent troll. It doesn’t make, develop, innovate, or sell anything. Sable IP is merely a shell entity formed to monetize (make money from) an ancient patent portfolio acquired by Sable Networks from Caspian Networks in 2006. Caspian Networks was a router company that went out of business nearly 20 years ago. Using Caspian’s old patents, Sable sued Cloudflare and many other companies, including Cisco, Fortinet, Check Point, SonicWall, and Juniper Networks, alleging patent infringement. While these other companies resolved their disputes with Sable out of court, Cloudflare fought back.
Sable initially asserted around 100 claims from four different patents against Cloudflare, accusing multiple Cloudflare products and features of infringement. Sable’s patents — the old Caspian Networks patents — related to hardware-based router technologies common over 20 years ago. Sable’s infringement arguments stretched these patent claims to their limits (and beyond) as Sable tried to apply Caspian’s hardware-based technologies to Cloudflare’s modern software-defined services delivered on the cloud.
Cloudflare fought back against Sable by launching a new round of Project Jengo, Cloudflare’s prior art contest, seeking prior art to invalidate all of Sable’s patents.
After years of Cloudflare aggressively litigating against Sable’s patents before the U.S. Patent and Trademark Office and the district court, Sable was left with only one claim from one patent to assert against Cloudflare at trial. If you’d like to know more, we described those battles, in which Cloudflare successfully eliminated around 99% of Sable’s claims, in more detail in a prior blog post.
Sable and Cloudflare came together in a five-day jury trial in Waco, Texas in February 2024. At trial, Sable did its best to try to map its decades-old router technology onto Cloudflare’s modern software-based architecture. But Sable’s case was riddled with technical issues and its efforts backed only by the desire for a payout.
The jury agrees: Cloudflare does not infringe
To defeat Sable’s claim of infringement we needed to explain to the jury — in clear and understandable terms — why what Cloudflare does is different from what was covered by claim 25 of Sable’s remaining patent, U.S. Patent No. 7,012,919 (the ’919 patent). To do this, we enlisted the help of one of our talented Cloudflare engineers, Eric Reeves, as well as Dr. Paul Min, Senior Professor of Electrical & Systems Engineering at Washington University, an expert in the field of computer networking. Eric and Dr. Min helped us explain to the jury the multiple reasons we didn’t infringe.

From slide deck presented by Cloudflare to the jury during the trial
First, we explained that the accused Cloudflare products (Magic Transit and Argo for Packets) do not route “flows” or “micro-flows” as required by claim 25. Instead, they handle packets individually, on a packet-by-packet basis. Indeed, processing each packet individually is important to the functioning of these products and Cloudflare’s DDoS and security services as a whole.
Eric also helped to tell our invention story to the jury. He explained how the Cloudflare team saw problems that needed to be solved, and built unique and innovative new products to solve them. He described the work that went into developing Magic Transit and Argo for Packets, and how these products are part of Cloudflare’s modern software-based approach, which is fundamentally different from the hardware-based technology of the ’919 patent. Together, Eric and Dr. Min explained how the benefits of Magic Transit and Argo for Packets enjoyed by Cloudflare’s customers are not attributable to any technology claimed by the ’919 patent.
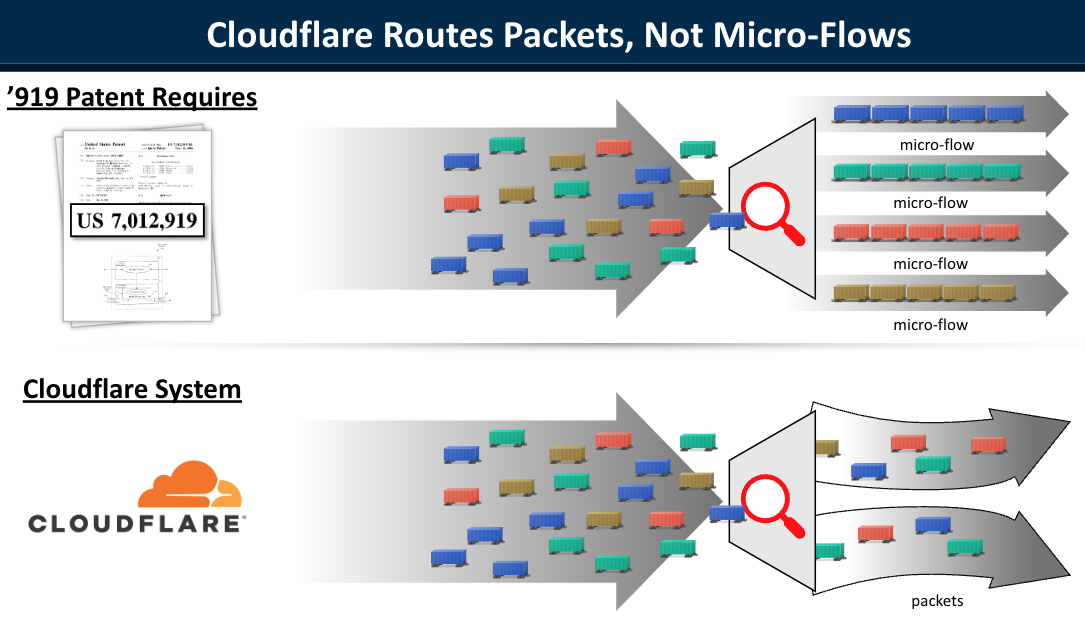
From slide deck presented by Cloudflare to the jury during the trial
Second, we explained that Cloudflare doesn’t infringe because claim 25 of the ’919 patent requires certain processes to occur “at” ingress and egress line cards, and Cloudflare’s accused servers do not include line cards.

From slide deck presented by Cloudflare to the jury during the trial
As Dr. Min explained, “line cards” are a specific type of hardware — a physical hardware “card” — that are commonly used in routers. Sable’s witnesses could not deny that the technology of the ’919 patent was tied to old router technology. After all, Caspian Networks Inc. (where the ’919 patent inventors worked) was a router company. Caspian’s core products were routers, and we showed the jury documents describing Caspian’s routers, which used “flow-based” technology on physical hardware line cards.

Trial exhibit, image of sample line card
While Sable’s technical expert tried his hardest to convince the jury that various software and hardware components of Cloudflare’s servers constitute “line cards,” his explanations defied credibility. The simple fact is that Cloudflare’s servers do not have line cards.
Ultimately, the jury understood, returning a verdict that Cloudflare does not infringe claim 25 of the ‘919 patent.

Excerpt from Verdict Form completed by the jury
The jury agrees: Sable’s patent claim is invalid
In addition to proving that we do not infringe, we also took on the challenge of proving to the jury that claim 25 of the ’919 patent is invalid and never should have been issued.
Proving invalidity to a jury is hard. The burden on the defendant is high: Cloudflare needed to prove by clear and convincing evidence that claim 25 is invalid. And, proving it by describing how the claim is obvious in light of the prior art is complicated.
To do this, we again relied on our technical expert, Dr. Min, to explain how two prior art references, U.S. Patent No. 6,584,071 (Kodialam) and U.S. Patent No. 6,680,933 (Cheeseman) together render claim 25 of the ’919 patent obvious. Kodialam and Cheeseman are patents from Nortel Networks and Lucent relating to router technology developed in the late 1990s. Both are prior art to the ’919 patent (i.e., they pre-date the priority date of the ’919 patent), and when considered together by a person skilled in the area of computer engineering and computer networking technology, they rendered obvious the so-called invention of claim 25.

Excerpt from Verdict Form completed by the jury
Sable does not get its payday …
Sable’s real motivation for suing Cloudflare — its desire for a payout — was made clear by Sable’s trial witnesses, who were unified only by their desire to present a wildly inflated view of the alleged “value” of the Sable patent and the damages allegedly owed by Cloudflare.
Sable’s attorneys tried their best to present their clients as reasonable businessmen, just trying to get what they’re owed for Cloudflare’s purported use of Sable’s patent. But Sable couldn’t hide its true colors from the jury. When Sable presented testimony from Brooks Borchers, the founder of Sable IP, Mr. Borchers was forced to admit that Sable IP is in the “business” of filing lawsuits.

Excerpt from Borchers trial testimony
In fact, Mr. Borchers was forced to admit that Sable’s approach is to sue first and ask questions later. Even among patent trolls, this is hardly a noble business practice.

Excerpts from Borchers trial testimony
What’s more, Mr. Borchers and his lawyers have teamed up on cases like this before, following the same sue-first-and-ask-questions-later playbook in hopes of a payout. Sable’s true motivations for suing Cloudflare were on full display after this testimony, making Sable’s damages demand all the more galling.
Sable’s damages expert, Stephen Dell, told the jury that Sable was owed somewhere between $25 million and $94.2 million in damages. But, Mr. Dell was forced to admit to multiple flaws in his damages calculation, and Cloudflare’s damages expert Chris Bakewell explained to the jury how bad inputs and faulty assumptions led Mr. Dell to a wildly inflated damages figure. Indeed, after hearing Sable’s expert’s testimony, Judge Albright said he was “very skeptical” of Mr. Dell’s opinions, explaining that he was “very concerned that there’s not support for his methodology.”
In the end, Mr. Dell’s outsized damages demand didn’t matter because the jury found that Cloudflare did not infringe and that the asserted patent claim is invalid. But, it was revealing of Sable’s motivation (greed) and the lengths that it would go to try to get a payout.
When all was said and done, after all the testimony and argument, we were thrilled when the jury returned its verdict — after less than two hours of deliberations — finding across the board for Cloudflare. The jury’s verdict is truly a validation of our strong belief in the importance of standing up to patent trolls like Sable, and we are grateful for the jury’s time, attention and consideration!
Sable admits defeat, and agrees to pay Cloudflare!
A jury verdict is not the end of the road in a patent case … there are post-trial motions, appeals, and other procedural hurdles to jump through before a case is truly over. Tired from the fight, and smarting from its loss, Sable decided it wanted to throw in the towel and end the fight once and for all.
In the end, Sable agreed to pay Cloudflare $225,000, grant Cloudflare a royalty-free license to its entire patent portfolio, and to dedicate its patents to the public, ensuring that Sable can never again assert them against another company.
Let’s repeat that first part, just to make sure everyone understands:
Sable, the patent troll that sued Cloudflare back in March 2021 asserting around 100 claims across four patents, in the end wound up paying Cloudflare. While this $225,000 can’t fully compensate us for the time, energy and frustration of having to deal with this litigation for nearly three years, it does help to even the score a bit. And we hope that it sends an important message to patent trolls everywhere to beware before taking on Cloudflare.

Excerpt from the Dedication to the Public and Royalty Free License Agreement between Sable and Cloudflare
And, let’s talk a bit more about that final part:
Sable has agreed to dedicate its entire patent portfolio to the public. This means that Sable will tell the U.S. Patent and Trademark Office that it gives up all of its legal rights to its patent portfolio. Sable can never again use these patents to sue for infringement; they can never again use these patents to try to make a quick buck.

Excerpt from the Dedication to the Public and Royalty Free License Agreement between Sable and Cloudflare
To sum it up …
Cloudflare fought back against the patent troll and we won. We not only defeated Sable’s claims in court, we forced Sable to pay Cloudflare for the trouble, and we got Sable’s patents dedicated to the public, ensuring that it can never assert these patents against any other company ever again. It was admittedly a lot of work for Cloudflare, but totally worth it.
Project Jengo for Sable: Conclusion of the Case
A crucial part of our efforts to secure this across-the-board win are our Project Jengo participants.
Since the launch of the Project Jengo for the Sable case, we’ve received hundreds of prior art references from dedicated Project Jengo participants. So far we have awarded $70,000 in prizes to the winners of Chapters 1 through 8. And we still have $30,000 in prizes to award in the Final Awards.
This blog post marks the official “Conclusion of the Case” under the Project Jengo Sable Rules. We will continue to accept submissions during the 30-day Grace Period, which lasts until November 2, 2024, and then will move on to selecting winners of the Final Awards.
We are thrilled to announce the winners of Chapters 7 and 8
We publicly celebrated the Chapter 1, Chapter 2, Chapter 3 and Chapters 4-6 winners in previous blog posts. However, as the trial approached in the Sable case, we chose not to make public announcements for the Chapter 7 and 8 winners out of respect for the judicial process. Now that the case is over, we are delighted to give a big public shout out to the winners of Project Jengo Chapters 7 and 8!
We selected four total winners in Chapters 7 and 8, each receiving prizes of $5,000, for a grand total of $20,000. Our Chapter 7 winners, George W. and Madhu, each provided helpful and detailed charts containing element-by-element comparisons of the prior art to the relevant Sable patents. George W. is an electrical engineer and lawyer, who is active in the intellectual property community. He learned about Project Jengo in an article posted online, and thought it was a clever idea. The Chapter 8 winners, Jatin and Ketan, also provided thoughtful and detailed submissions. Jatin submitted two pieces of prior art that were particularly good references for Sable’s U.S. Patent No. 7,012,919, which contains the one claim that remained asserted against Cloudflare at trial.
We also want to again thank our prior chapter winners and everyone who participated in Project Jengo! We look forward to selecting the Final Awards winners — it will be fun to take a walk down memory lane re-reviewing the fantastic prior art submitted by our prior winners, and we can’t wait to check out the new submissions, too! Please use the “Submit Prior Art” link on this page for your final entries. Once we’ve announced our Final Awards, we will also update the Sable patents prior art listing on our website, to share all the prior art submitted by our Project Jengo participants.