Since the beginning, GitHub.com has been a Ruby on Rails monolith. Today, the application is nearly two million lines of code and more than 1,000 engineers collaborate on it daily. We deploy as often as 20 times a day, and nearly every week one of those deploys is a Rails upgrade.
Upgrading Rails weekly
Every Monday a scheduled GitHub Action workflow triggers an automated pull request, which bumps our Rails version to the latest commit on the Rails main branch for that day. All our builds run on this new version of Rails. Once all the builds pass, we review the changes and ship it the next day. Starting an upgrade on Monday you will already have an open pull request linking the changes this Rails upgrade proposes and a completed build.
This process is a far stretch from how we did Rails upgrades only a few years ago. In the past, we spent months migrating from our custom fork of Rails to a newer stable release, and then we maintained two Gemfiles to ensure we’d remain compatible with the upcoming release. Now, upgrades take under a week. You can read more about this process in this 2018 blog post. We work closely with the community to ensure that each Rails release is running in production before the release is officially cut.
There are real tangible benefits to running the latest version of Rails:
We give developers at GitHub the very best version of our tools by providing the latest version of Rails. This ensures users can take advantage of all the latest improvements including better database connection handling, faster view rendering, and all the amazing work happening in Rails every day.
We have removed nearly all of our Rails patches. Since we are running on the latest version of Rails, instead of patching Rails and waiting for a change, developers can suggest the patch to Rails itself.
Working on Rails is now easier than ever to share with your team! Instead of telling your team you found something in Rails that will be fixed in the next release, you can work on something in Rails and see it the following week!
Maintaining more up-to-date dependencies gives us a better security posture. Since we already do weekly upgrades, adding an upgrade when there is a security advisory is standard practice and doesn’t require any extra work.
There are no “big bang” migrations. Since each Rails upgrade incorporates only a small number of changes, it’s easier to understand and dig into if there are incompatibilities. The worst issues from a tough upgrade are unexpected changes from an unknown location. These issues can be mitigated by this upgrade strategy.
Catching bugs in the main branch and contributing back strengthens our engineering team and helps our developers deepen their expertise and understanding of our application and its dependencies.
Testing Ruby continuously
Naturally, we have a similar process for Ruby upgrades. In February 2022, shortly after upgrading to Ruby 3.1, we started building and testing Ruby shas from 3.2-alpha in a parallel build. When CI runs for the GitHub Rails application, two versions of the builds run: one build uses the Ruby version we are running in production and one uses the latest Ruby commit including the latest changes in Ruby, which we update weekly.
While we build Ruby with every change, GitHub only ships numbered Ruby versions to production. The builds help us maintain compatibility with the upcoming Ruby version and give us insight into what Ruby changes are coming.
In early December 2022, with CI giving us confidence we were compatible before the usual Christmas release of Ruby 3.2, we were able to test Ruby release candidates with a portion of production traffic and give the Ruby team insights into any changes we noticed. For example, we could reproduce an increase in allocations due to keyword argument handling that was fixed before the release of Ruby 3.2 due to this process. We also identified a subtle change when to_str and #to_i is applied. Because we upgrade all the time, identifying and resolving these issues was standard practice.
This weekly upgrade process for Ruby allowed us to upgrade our monolith from Ruby 3.1 to Ruby 3.2 within a month of release. After all, we had already tested and run it in production! At this point, this was the fastest Ruby upgrade we had ever done. We broke this record with the release of Ruby 3.2.1, which we adopted on release day.
This upgrade process has proved to be invaluable for our collaboration with the Ruby core team. A nice side effect of having these builds is that we are able to easily test and profile our own Ruby changes before we suggest them upstream. This can make it easier for us to identify regressions in our own application and better understand the impact of changes on a production environment.
Should I do it, too?
Our ability to do frequent Ruby and Rails upgrades is due to some engineering maturity at GitHub. Doing weekly Rails upgrades requires a thorough test suite with many great engineers working to maintain and improve it. We also gain confidence from having great test environments along with progressive rollout deploys. Our test suite is likely to catch problems, and if it doesn’t, we are confident we will catch it during deploy before it reaches customers.
If you have these tools, you should also upgrade Rails weekly and test using the latest Ruby. GitHub is a better Rails app because of it and it has enabled work from my team that I am really proud of.
Ruby champion Eileen Uchitelle explains why investing in Rails is important in her Rails Conf 2022 Keynote:
Ultimately, if more companies treated the framework as an extension of the application, it would result in higher resilience and stability. Investment in Rails ensures your foundation will not crumble under the weight of your application. Treating it as an unimportant part of your application is a mistake and many, many leaders make this mistake.
Thanks to contributions from people around the world, using Ruby is better than ever. GitHub, along with hundreds of other companies, benefits from Ruby and Rails continuing to improve. Upgrading regularly and investing in our frameworks is a staple of the work we do on the Ruby Architecture team at GitHub. We are always grateful for the Ruby community and glad that we can give back in a way that improves our application and tools as much as it improves them for everyone else.
Performance is an essential aspect of any production application, and GitHub is no exception. In the last year, we’ve been making significant investments to improve the performance of some of our most critical workflows. There’s a lot to share, but today we’re going to focus on a little-known feature of some Rack-powered web servers called rack.after_reply that saved us 30ms p50 and 50ms+ p99 on every request across the site.
The problem
First, let me talk about how we found ourselves looking at this Rack web server functionality. When diving into performance, we often look at flamegraphs that reveal where time is being spent for a given request. Eventually, we started to notice a pattern. It turned out we were spending a significant amount of time sending statsd metrics throughout a request. In fact, it could be up to 65ms per request! While telemetry enables us to improve GitHub, it doesn’t help users directly, especially when it impacts the performance of our page loads.
There’s no need to send telemetry immediately, especially if it’s expensive, so we started discussing ways to remove telemetry network calls out of the critical path. This resulted in the question, “Can we batch all of our telemetry calls and send them at once?” There’s far too much data to use a background job, so we had to look at other potential solutions. We came across Rack::Events and spiked out a proof of concept. Unfortunately, this approach caused any work performed in Rack::Events callbacks to block the response from closing. This resulted in two issues. First, users would see the browser loading indicator until the deferred code was complete. Second, this impacted our metrics since response times still included the time it took to run our deferred code.
A potential path forward
Recognizing the potential, we kept digging. Eventually, we came across a feature that seemed to do exactly what we wanted, rack.after_reply. The Puma source code describesrack.after_reply as: “A rack extension. If the app writes #call’ables to this array, we will invoke them when the request is done.” In other words, this would allow us to collect telemetry metrics during a request and flush them in a single batch after the browser received the full response, avoiding the issue of network calls slowing down response times. There was a problem though. We don’t use Puma at GitHub, we use Unicorn.
We had a clear path forward. All we needed to do was implement rack.after_reply in Unicorn. This functionality has a lot of use cases outside of sending telemetry metrics, so we contributed rack.after_reply back to Unicorn. This allowed us to write a small wrapper class around rack.after_reply, making it easier to use in the application:
class AfterResponse
def initialize(env)
env[“rack.after_reply”] ||= []
env[“rack.after_reply”] << -> do
self.call
end
@to_perform = []
end
# Calls each callable defined via #perform
def call
@to_perform.each do |block|
begin
block.call(self)
rescue Object => e
Rails.logger.error(e)
end
end
end
# Adds given block to the array of callables that will
# be called after the user has received the response.
def perform(name, &block)
@to_perform << block
end
end
With the hard part completed, we wrote a small wrapper around our telemetry class to buffer all of our stats data. Combining that with a middleware that performs roughly the following, users now receive responses 30ms faster P50 across all pages. P99 response times improved too, with a 50ms+ reduction across the site.
GitHub.after_response.perform do
GitHub.statsd.flush!
end
In conclusion
There are a few drawbacks to this approach that are worth mentioning. The primary disadvantage is that a Unicorn worker executes the rack.after_reply code, making it unable to serve another HTTP request until your callables finish running. If not kept in check, this can potentially increase HTTP queueing, the time spent waiting for a web server worker to serve a request. We mitigated this by adding timeout behavior to prevent any code from running too long.
It’s a little early to talk about it, but there is progress toward making this functionality an official part of the Rack spec. A recently released gem also implements additional functionality around this feature called maybe_later that’s worth checking out.
Overall, we’re pleased with the results. Unicorn-powered applications now have a new tool at their disposal, and our customers reap the benefits of this performance enhancement!
We recently added beta support for Ruby to the CodeQL engine that powers GitHub code scanning, as part of our efforts to make it easier for developers to build and ship secure code. Ruby support is particularly exciting for us, since GitHub itself is a Ruby on Rails app. Any improvements we or the community make to CodeQL’s vulnerability detection will help secure our own code, in addition to helping Ruby’s open source ecosystem.
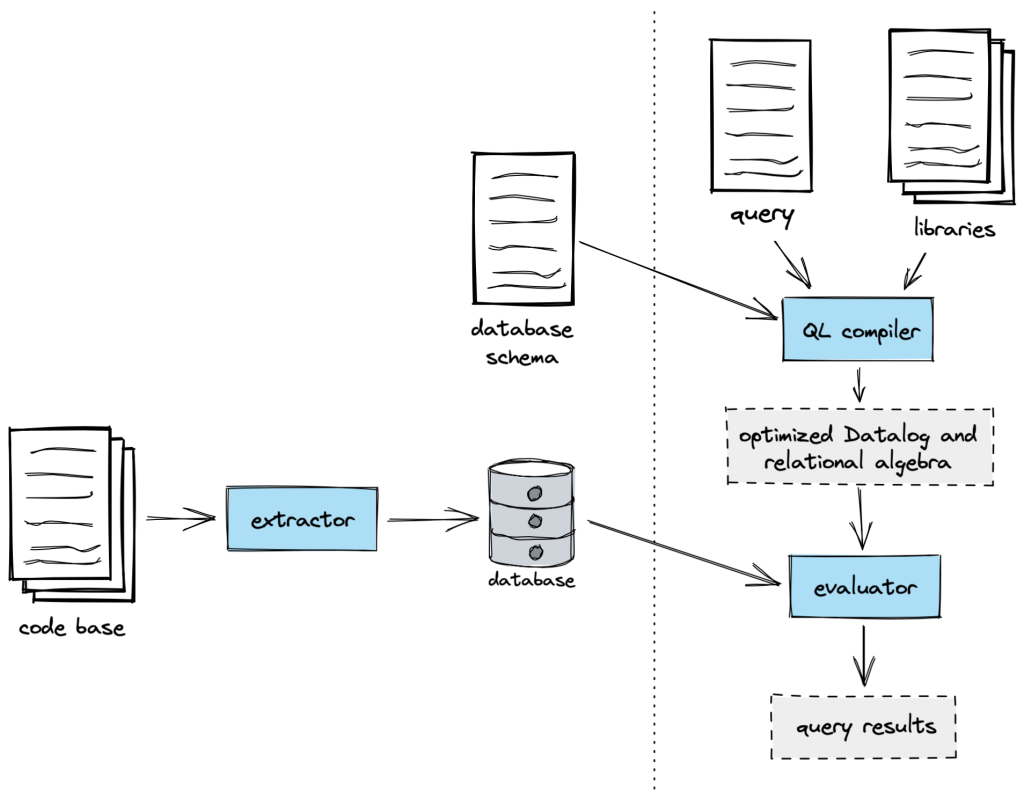
CodeQL’s static analysis works by running queries over a database representation of a program. The following diagram gives a high-level overview of the process:
While there’s plenty I’d love to tell you about how we write queries, and about our rich set of analysis libraries, I’m going to focus in this post on how we build those databases: how we’ve typically done it for other languages and how we did things a little differently for Ruby.
Introducing the extractor
If you want to be able to create databases for a new language in CodeQL, you need to write an extractor. An extractor is a tool that:
parses the source code to obtain a parse tree,
converts that parse tree into a relational form, and
writes those relations (database tables) to disk.
You also need to define a schema for the database produced by your extractor. The schema specifies the names of tables in the database and the names and types of columns in each table.
Let’s visit parse trees, parsers, and database schemas in more detail.
Parse trees
Source code is just text. If you’re writing a compiler, performing static analysis, or even just doing syntax highlighting, you want to convert that text to a structure that is easier to work with. The structure we use is a parse tree, also known as a concrete syntax tree.
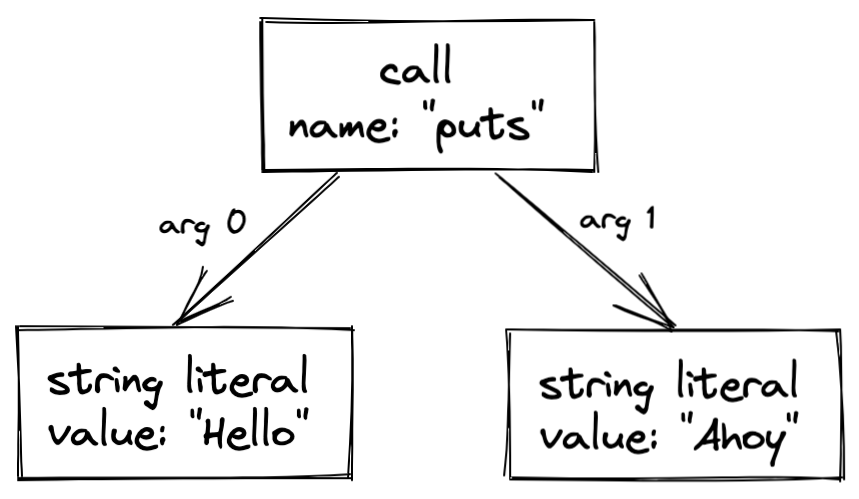
Here’s a friendly little Ruby program that prints a couple of greetings:
puts("Hello", "Ahoy")
The program contains three expressions: the string literals "Hello" and "Ahoy" and a call to a method named puts. I could draw a minimal parse tree for the program like this:
Compilers and static analysis tools like CodeQL often convert the parse tree into a simpler format known as an abstract syntax tree (AST), so-called because it abstracts away some of the syntactic details that do not affect the meaning of the program, such as comments, whitespace, and parentheses. If I wanted – and if I assume that puts is a method built into the language – I could write a simple interpreter that executes the program by walking the AST.
For CodeQL, the Ruby extractor stores the parse tree in the database, since those syntactic details can sometimes be useful. We then provide a query library to transform this into an AST, and most of our queries and query libraries build on top of that transformed AST, either directly or after applying further transformations (such as the construction of a data-flow graph).
Choosing a parser
For each language we’ve supported so far, we’ve used a different parser, choosing the one that gives the best performance and compatibility across all the codebases we want to analyze. For example, our C# extractor parses C# source code using Microsoft’s open source Roslyn compiler, while our JavaScript extractor uses a parser that was derived from the Acorn project.
For Ruby, we decided to use tree-sitter and its Ruby parser. Tree-sitter is a parser framework developed by our friends in GitHub’s Semantic Code Team and is the technology underlying the syntax highlighting and code navigation (jump-to-definition) features on GitHub.com.
Tree-sitter is fast, has excellent error recovery, and provides bindings for several languages (we chose to use the Rust bindings, which are particularly pleasant). It has parsers not only for Ruby, but for most other popular languages, and provides machine-readable descriptions of each language’s grammar. These opened up some exciting possiblities for us, which I’ll describe later.
In practice, the parse tree produced by tree-sitter for our example program is a little more complicated than the diagram above (for one thing, string literal nodes have child nodes in order to support string interpolation). If you’re curious, you can go to the tree-sitter playground, select Ruby from the dropdown, and try it for yourself.
Handling ambiguity
Ruby has a flexible syntax that delights (most of) the people who program in it. The word ‘elegant’ gets thrown around a lot, and Ruby programs often read more like English prose than code. However, this elegance comes at a significant cost: the language is ambiguous in several places, and dealing with it in a parser creates a lot of complexity.
Ruby is simple in appearance, but is very complex inside, just like our human body.
– Yukihiro 'Matz' Matsumoto, Ruby's creator
Matz’s Ruby Interpreter (MRI) is the canonical implementation of the Ruby language, and its parser is implemented in the file parse.y (from which Bison generates the actual parser code). That file is currently 14,000 lines long, which should give you a sense of the complexity involved in parsing Ruby.
One interesting example of Ruby’s ambiguity occurs when parsing an unadorned identifier like foo. If it had parentheses – foo() – we could parse it unambiguously as a method call, but parentheses are optional in Ruby. Is foo a method call with zero arguments, or is it a variable reference? Well, that ultimately depends on whether a variable named foo is in scope. If so, it’s a variable reference; otherwise, we can assume it’s a call to a method named foo.
What type of parse-tree node should the parser return in this case? The parser does not track which variables are in scope, so it cannot decide. The way tree-sitter and the extractor handle this is to emit an identifier node rather than a call node. It’s only later, as we evaluate queries, that our AST library builds a control-flow graph of the program and uses that to decide whether the node is a method call or a variable reference.
Representing a parse tree in a relational database
While the parse trees produced by most parser libraries typically represent nodes and edges in the tree as objects and pointers, CodeQL uses a relational database. Going back to the simple diagram above, I can attempt to convert it to relational form. To do that, I should first define a schema (in a simplified version of CodeQL’s schema syntax):
The expressions table has a row for each expression in the program. Each one is given a unique id, a primary key that I can use to reference the expression from other tables. The kind column defines what kind of expression it is. I can decide that a value of 1 means the expression is a method call, 2 means it’s a string literal, and so on.
The calls table has a row for each method call, and it allows me to specify data that is specific to call expressions. The first column is a foreign key, i.e. the id of the corresponding entry in the expressions table, while the second column specifies the name of the method. You might have expected that I’d add columns for the call’s arguments, but calls can take any number of arguments, so I wouldn’t know how many columns to add. Instead, I put them in a separate call_arguments table.
The call_arguments table, therefore, has one row per argument in the program. It has three columns: one that’s a reference to the call expression, another that’s a reference to an argument, and a third that specifies the index, or number, of that argument.
Finally, the string_literals table lets me associate the literal text value with the corresponding entry in the expressions table.
Populating our small database
Now that I’ve defined my schema, I’m going to manually populate a matching database with rows for my little greeting program:
expressions
id
kind
100
1 (call)
101
2 (string literal)
102
2 (string literal)
calls
expr_id
name
100
“puts”
call_arguments
call_id
arg_id
arg_index
100
101
0
100
102
1
string_literals
expr_id
val
101
“Hello”
102
“Ahoy”
Suppose this were a SQL database, and I wanted to write a query to find all the expressions that are arguments in calls to the puts method. It might look like this:
SELECT call_arguments.arg_id
FROM call_arguments
INNER JOIN calls ON calls.expr_id = call_arguments.call_id
WHERE calls.name = "puts";
In practice, we don’t use SQL. Instead, CodeQL queries are written in the QL language and evaluated using our custom database engine. QL is an object-oriented, declarative logic-programming language that is superficially similar to SQL but based on Datalog. Here’s what the same query might look like in QL:
from MethodCall call, Expr arg
where
call.getMethodName() = "puts" and
arg = call.getAnArgument()
select arg
MethodCall and Expr are classes that wrap the database tables, providing a high-level, object-oriented interface, with helpful predicates like getMethodName() and getAnArgument().
Language-specific schemas
The toy database schema I defined might look as though it could be reused for just about every programming language that has string literals and method calls. However, in practice, I’d need to extend it to support some features that are unique to Ruby, such as the optional blocks that can be passed with every method call.
Every language has these unique quirks, so each one GitHub supports has its own schema, perfectly tuned to match that language’s syntax. Whereas my toy schema had only two kinds of expression, our JavaScript and C/C++ schemas, for example, both define over 100 kinds of expression. Those schemas were written manually, being refined and expanded over the years as we made improvements and added support for new language features.
In contrast, one of the major differences in how we approached Ruby is that we decided to generate the database schema automatically. I mentioned earlier that tree-sitter provides a machine-readable description of its grammar. This is a file called node-types.json, and it provides information about all the nodes tree-sitter can return after parsing a Ruby program. It defines, for example, a type of node named binary, representing binary operation expressions, with fields named left, operator, and right, each with their own type information. It turns out this is exactly the kind of information we want in our database schema, so we built a tool to read node-types.json and spit out a CodeQL database schema.
I’ve talked about how the parser gives us a parse tree, and how we could represent that same tree in a database. That’s really the main job of an extractor – massaging the parse tree into a relational database format. How easy or difficult that is depends a lot on how similar those two structures look. For some languages, we defined our database schema to closely match the structure (and naming scheme) of the tree produced by the parser. That is, there’s a high level of correspondence between the parser’s node names and the database’s table names. For those languages, an extractor’s job is fairly simple. For other languages, where we perhaps decided that the tree produced by the parser didn’t map nicely to our ideal database schema, we have to do more work to convert from one to the other.
For Ruby, where we wrote a schema-generator to automatically translate tree-sitter’s description of its node types, our extractor’s job is quite simple: when tree-sitter parses the program and gives us those tree nodes, we can perform the same translations and automatically produce a database that conforms to the schema.
Language independence
This extraction process is not only straightforward, it’s also completely language-agnostic. That is, the process is entirely mechanical and works for any tree-sitter grammar. Our schema-generator and extractor know nothing about Ruby or its syntax – they simply know how to translate tree-sitter’s node-types.json. Since tree-sitter has parsers for dozens of languages, and they all have corresponding node-types.json files, we have effectively written a pair of tools that could produce CodeQL databases for any of them.
One early benefit of this approach came when we realized that, to provide comprehensive analysis of Ruby on Rails applications, we’d also need to parse the ERB templates used to render Rails views. ERB is a distinct language that needs to be parsed separately and extracted into our database. Thankfully, tree-sitter has an existing ERB parser, so we simply had to point our tooling at that node-types.json file as well, and suddenly we had a schema-generator and extractor that could handle both Ruby and ERB.
As an aside, the ERB language is quite simple, mostly consisting of tags that differentiate between the parts of the template that are text and the parts that are Ruby code. The ERB parser only cares about those tags and doesn’t parse the Ruby code itself. This is because tree-sitter provides an elegant feature that will return a series of byte offsets delimiting the parts that are Ruby code, which we can then pass on to the Ruby parser. So, when we extract an ERB file, we parse and extract the ERB parse tree first, and then perform a second pass that parses and extracts the Ruby parse tree, ignoring the text parts of the template file.
Of course, this automated approach to extraction does come with some tradeoffs, since it involves deferring some work from the extraction stage to the analysis stage. Our QL AST library, for example, has to do more work to transform the parse tree into a user-friendly AST representation, compared with some languages where the AST classes are thin wrappers over database tables. And if we look at our existing extractor for C#, for example, we see that it gets type information from the Roslyn compiler frontend, and stores it in the database. Our language-independent tooling, meanwhile, does not attempt any kind of type analysis, so if we wanted to use it on a static language, we’d have to implement that type analysis ourselves in QL.
Nonetheless, we are excited about the possibilities this language-independent tooling opens up as we look to expand CodeQL analysis to cover more languages in the future, especially for dynamic languages. There’s a lot more to analyzing a language than producing a database, but getting that part working with little to no effort should be a major time-saver.
github/github: so good, they named it twice
github/github is the Ruby on Rails application that powers GitHub.com, and it’s rather large. I’ve heard it said that it’s one of the largest Rails apps in the world. That means it’s an excellent stress test for our Ruby extractor.
It was actually the second Ruby program we ever extracted (the first was “Hello, World!”).
Of course, extraction wasn’t quite perfect. We observed a number of parser errors that we fixed upstream in the tree-sitter-ruby project, so our work not only resulted in improved Ruby code-viewing on GitHub.com, but also improvements in the other projects that use tree-sitter, such as Neovim’s syntax highlighting.
It was also a useful benchmark in our goal of making extraction as fast as possible. CodeQL can’t start doing the valuable work of analyzing for vulnerabilities until the code has been extracted and a database produced, so we wanted to make this as fast as possible. It certainly helps that tree-sitter itself is fast, and that our automatic translation of tree-sitter’s parse tree is simple.
The biggest speedup – and where our choice to implement the extractor in Rust really helped – was in implementing multi-threaded extraction. With the design we chose for the Ruby extractor, the work it performs on each source file is completely independent of any other source file. That makes extraction an embarrassingly parallel problem, and using the Rayon library meant we barely had to change any code at all to take advantage of that. We simply changed a for loop to use a Rayon parallel-iterator, and it handled the rest. Suddenly extraction got eight times faster on my eight-core laptop.
CodeQL now runs on every pull request against github/github, using a 32-core Actions runner, where Ruby extraction takes just 15 seconds. The core engine still has to perform ‘database finalization’ after the extractor finishes, and this takes a little longer (it parallelizes, but not “embarrassingly”), but we are extremely pleased with the extractor’s performance given the size of the github/github codebase, and given our experiences with extracting other languages.
We should be in a good place to accommodate all our users’ Ruby codebases, large and small.
Try it out
I hope you’ve enjoyed this dive into the technical details of extracting CodeQL databases. If you’d like to try CodeQL on your Ruby projects, please refer to the blog post announcing the Ruby public beta, which contains several handy links to help you get started.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.