Post Syndicated from Jonathan Nguyen original https://aws.amazon.com/blogs/security/how-to-automate-incident-response-for-amazon-eks-on-amazon-ec2/
Triaging and quickly responding to security events is important to minimize impact within an AWS environment. Acting in a standardized manner is equally important when it comes to capturing forensic evidence and quarantining resources. By implementing automated solutions, you can respond to security events quickly and in a repeatable manner. Before implementing automated security solutions, it’s important for your security team to have a defined process and understanding of which actions to take for specific AWS resources.
In a previous two-part post, we discussed using Amazon GuardDuty and Amazon Detective to detect security issues for an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. In this post, we walk through the differences of Amazon Elastic Cloud Compute (Amazon EC2) and EKS clusters on EC2 when responding to security events. By understanding the differences between the two AWS resource types, you can enhance your existing EC2 incident response (IR) automation to include EKS. Then, we walk you through the deployment and use of a sample solution based on the Automated Forensics Orchestrator for Amazon EC2 solution to automate the end-to-end incident response process for EKS, which includes acquisition, isolation, investigation and reporting.
If you’re familiar with the differences between responding and investigating Amazon EC2 and Amazon EKS resources and want to skip to the solution, skip to the Solution prerequisites.
Note: Amazon EKS on AWS Fargate, which is an AWS managed serverless computing engine, isn’t covered in this post.
Amazon EC2 compared to Amazon EKS resources for incident response
Although Amazon EKS clusters are running on EC2 instances, it’s important to understand the differences between the two and how to handle incident response automation for each resource type. EC2 is a virtual machine where you can install customized applications and packages to complete a task. Amazon EKS is an AWS managed service that you can use to run Kubernetes on EC2 instances without needing to install, operate, and maintain your own Kubernetes control plane or nodes. You can use existing plugins and tooling from the Kubernetes community. EKS clusters can have managed node groups, which create and manage the underlying EC2 instances. Because of Kubernetes cluster architecture, multiple EC2 instances within a node group can be tied to a single EKS cluster. There can also be multiple pods—each running different processes—running on an EC2 instance. GuardDuty can monitor and detect security events for EKS resources and provide information to help identify which resources are impacted, such as EKS cluster name, Kubernetes workload details, tags, and AWS Identity and Access Management (IAM) principals.
For incident response automation purposes, security teams need to understand the relationship between Amazon EKS and Amazon EC2 to determine the appropriate response to a possible security event. For example, if GuardDuty identifies Execution:Kubernetes/AnomalousBehavior.ExecInPod, you might want to investigate the command invoked on the identified pod along with other pods within the EKS cluster. To expand the investigation, you would need to capture and investigate evidence on the entire EKS cluster, which can include multiple EC2 instances.
Accessing Amazon EKS clusters using kubectl
To collect relevant forensic evidence, such as volatile memory, there might be instances where you need to run commands on Amazon EKS clusters. Kubectl is a command line tool that you can use to manage and run commands on EKS clusters using the Kubernetes API. Access with kubectl is limited to the container environment and doesn’t provide full shell access to the host. Although AWS Systems Manager (AWS SSM) can be used to interact with an EKS cluster’s EC2 instances, kubectl allows administrators to manage pods, scale applications, and view cluster logs. We dive into specific actions where kubectl is used in the later sections of this post.
When automating the workflow of response actions to an Amazon EKS cluster, you can incorporate the kubectl commands within Amazon Lambda functions. To invoke commands using kubectl, you need to get credentials for the EKS cluster to:
- Authenticate to an IAM principal authorized to work with Amazon EKS
- Obtain the EKS cluster endpoint
- Verify the certificate authority data for the EKS endpoint
- Generate a bearer token from the IAM principal
- Create a kubeconfig configuration dictionary
For more detailed information, see A Container-Free Way to Configure Kubernetes Using AWS Lambda and a deep dive into simplified Amazon EKS access management.
Capturing volatile memory on EKS
Volatile memory (RAM) in a memory dump is important because it contains the EC2 instance’s in-progress operations. Volatile memory is extremely important in determining the root cause of a security event. Although the commands for capturing volatile memory between EC2 instances and Amazon EKS clusters are similar, there is one important difference to keep in mind. For Linux operating systems, you can use the insmod command with the appropriate LiME kernel module (.ko file) to capture volatile memory:
sudo insmod $lime.ko "path=/path/to/dump.mem format=lime"
For Amazon EKS cluster EC2 instances, there can be multiple pods on a single EC2 instance. Knowing which process ID (PID) is associated to a pod is important to map the actions that could have resulted in a security event or compromise.

Figure 1: EKS cluster node list
To get a list of PIDs on the EC2 instance, as shown in Figure 1, the following crictl command needs to be invoked:
crictl inspect $(crictl ps | grep [pod-name] | awk '{print $1}') | grep -i pid
After the crictl command is invoked, you will see the output of existing PIDs for the EC2 instance to use in the nsenter command, as shown in the following figure.

Figure 2: EKS node process ID list
To create a mapping between a pod and the PID from a memory dump, the following nsenter command needs to be invoked on the target EC2 instance:
nsenter -t $PID -u hostname
After the nsenter command is invoked, you will see the output of pod and PID information for the EC2 instance, as shown in the following figure.

Figure 3: EKS node process ID to pod mapping commands
After you have the pod-to-PID mapping, you can export that information for later investigation. If you skip this step, the memory dump output will still have the PID information, but you won’t be able to map it back to previously running pods. It’s important to work with your security teams during forensic investigations to determine if this information is used during an investigation and update the automated workflow accordingly.
Network segmentation on EKS
After relevant forensic artifacts, such as volatile memory, disk volumes, and application logs, are collected from an Amazon EKS cluster, you might want to isolate compromised resources from the rest of your application resources. During resource isolation, EC2 instances can be isolated using security groups and network access control lists (NACLs). For EKS clusters, you can cordon the worker node, which makes the node tainted and unschedulable. When a node is cordoned, the Kubernetes scheduler is also blocked from placing new pods on the node. Another mechanism for isolating the EKS cluster is applying a Network Policy to deny ingress or egress traffic to the pod. Network policies, like NACLs, are stateless and control network traffic at the IP address or port level in an EKS cluster.
Depending on the scope of isolation, you can take the following approaches to isolating a pod on an EKS cluster in your automation.
- Apply a network policy – You can add a network policy rule to limit ingress or egress from your pod. This will not impact other pods in the cluster unless there are additional rules applied. You would use this option if you’re sure that the compromise hasn’t gained access to the underlying EC2 instance.
- Cordon the node – Removing the node won’t impact other nodes on the cluster but will block the scheduling of pods on the node. It doesn’t affect other nodes within the cluster.
- Apply a security group – Applying a security group can impact the entire EC2 instance and limit traffic between Amazon EKS cluster nodes, the Kubernetes control plane, the cluster’s worker nodes, and external destinations. This is an option if you believe the underlying EC2 instance has been compromised.
- Add a NACL rule – Like the security group option, this will impact the entire EC2 instance. Depending on the rule, it can also affect non-EKS workloads within the subnet.
Identity and access management for EKS
In addition to the IAM role associated to an EC2 instance profile, Amazon EKS uses service-linked IAM roles and Kubernetes role-based authorization control (RBAC) configuration. The IAM principal that creates the EKS cluster has system:masters permissions within the RBAC configuration on the EKS cluster. RBAC provides Kubernetes identities access for cluster-specific components and workflows. In addition to default identities created on EKS clusters, application-specific roles can be used within an EKS cluster. For example, IAM roles for service accounts (IRSA) can be used to associate an IAM role with a Kubernetes service account and assigned to containers within an EKS Pod. IRSA can help implement least privilege by restricting the Pod’s container to retrieve credentials for the IAM role associated with the Kubernetes service account. For a deeper dive into EKS IAM and how IAM roles are used within EKS, see Identity and access management for Amazon EKS.
Deciding how to revoke Amazon EKS permissions using automation can be challenging because revoking the AWS Security Token Service (AWS STS) credentials or changing the instance profile on the EC2 instance will impact all pods on the EC2 instance. Updating or changing the RBAC configurations on an EKS cluster requires application-specific knowledge to determine which identities are authorized to have specific permissions. It’s important to discuss with your application and security teams how permissions should be handled in the event of a compromised EKS cluster.
Moving to automated EKS incident response
Now that you understand the nuances of Amazon EKS on Amazon EC2 as it relates to incident response, you can decide how to incorporate functionality to respond to EKS in an existing solution your team might be using. It’s also important to understand where a human-in-the-loop needs to be incorporated to follow internal processes and procedures. Before incorporating automation into IR capabilities, you should walk through each step and verify the action the automation takes to make sure that the security and application teams are aligned. In this post, we incorporated Amazon EKS IR capabilities across acquisition, isolation, and investigation into the Automated Forensics Orchestrator for Amazon EC2 solution.
Solution prerequisites
For this walkthrough, you need to have the following elements in place:
- AWS Command Line Interface (AWS CLI) (2.2.37 or later).
- AWS Cloud Development Kit (AWS CDK) V2 (2.2 or newer)
- AWS Systems Manager Agent (SSM Agent) is installed in Amazon EKS clusters (application cluster).
- AWS Security Hub must be enabled to create a Security Hub custom action.
- Forensic investigation Amazon Machine Image (AMI) with tools, such as Cast or other third-party software, used to investigate the forensic artifacts generated.
- Forensic kernel modules for the corresponding operating system (OS) of the EKS cluster. To learn more about the requirements, see How to automatically build forensic kernel modules for Amazon Linux EC2 instances.
Solution overview
The solution follows a similar pattern and workflow as the Automated Forensics Orchestrator for Amazon EC2 but has been customized for Amazon EKS.

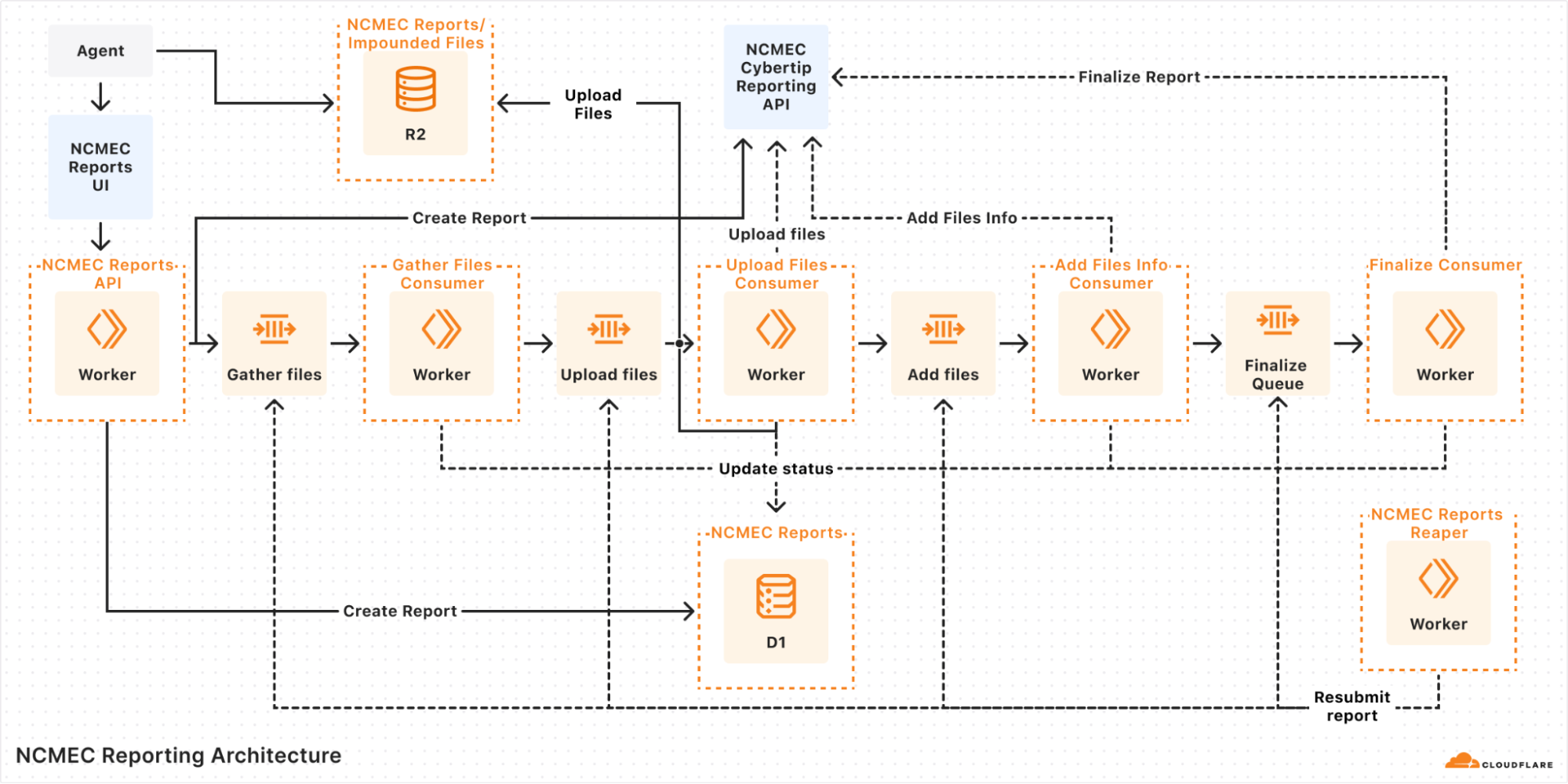
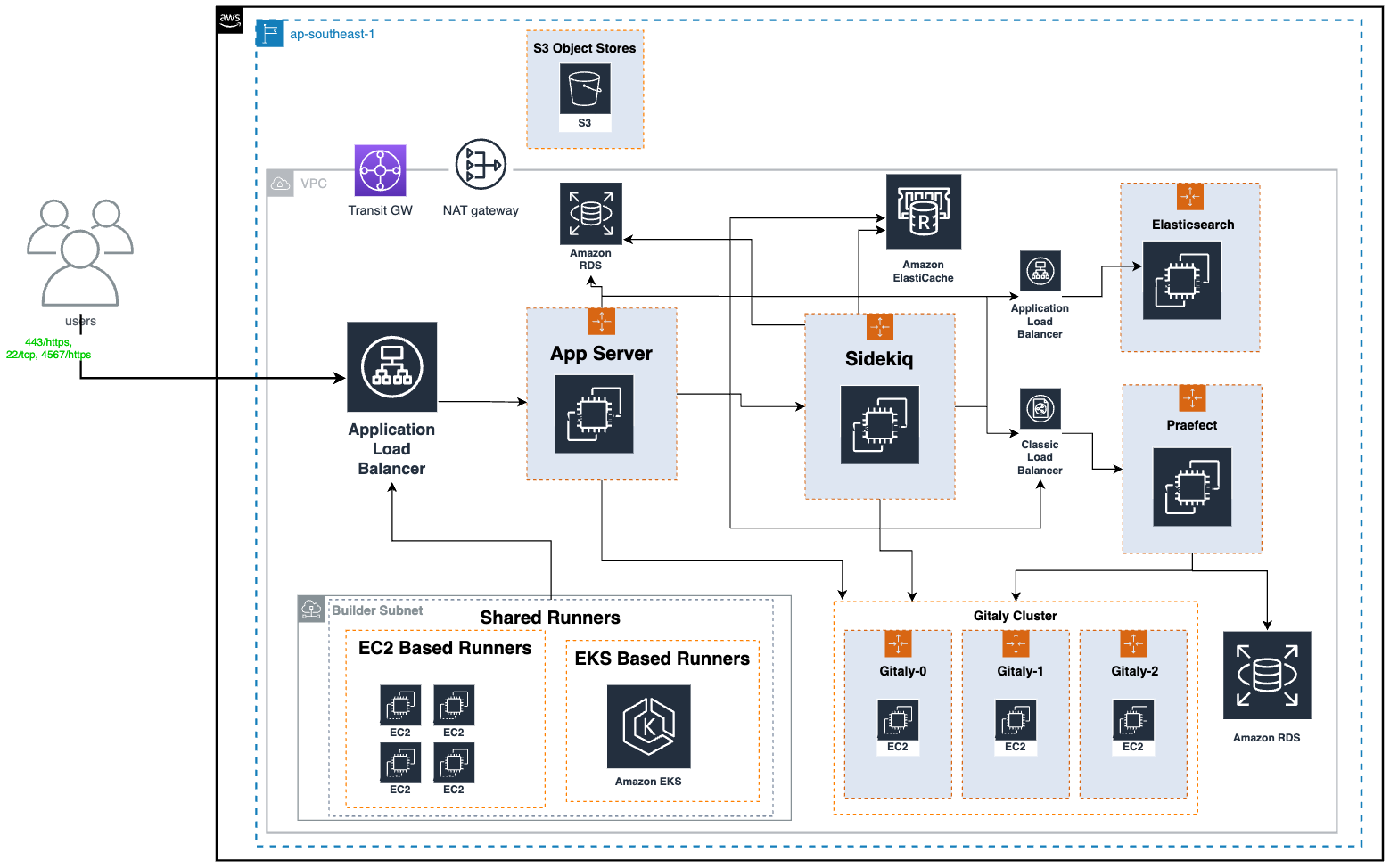
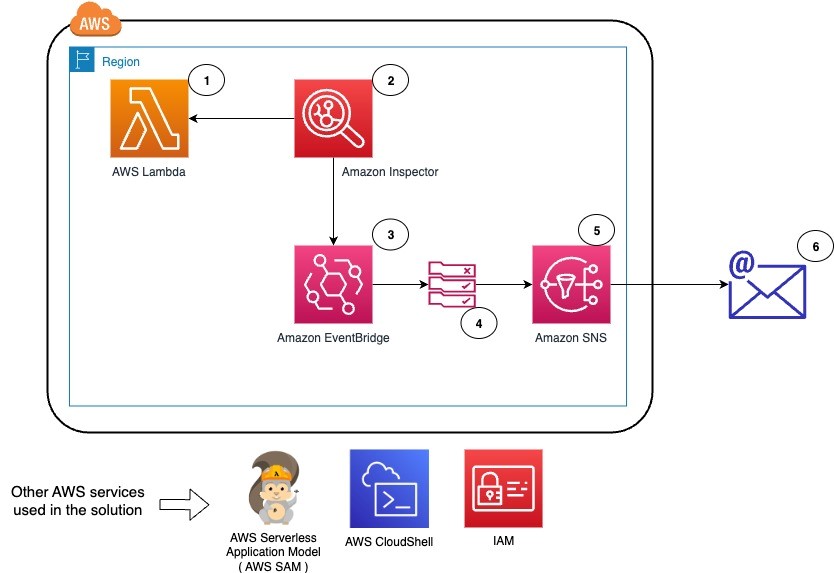
Figure 4: Automated Forensics Orchestrator for Amazon EKS architecture
The workflow, as shown in Figure 4, is:
- In the AWS application account, GuardDuty monitors for malicious activities that are specific to Amazon EKS resources. For example, a pod within an EKS cluster is invoking API commands using an unauthenticated
system:anonymoususer. GuardDuty findings are sent to Security Hub in the security account using native integration. - Security Hub custom actions send finding information to Amazon EventBridge to invoke automated downstream workflows.
- For a specified event, EventBridge provides the EKS resource information for the forensics process to target and initiates an AWS Step Functions workflow.
- Step Functions triages the request as follows:
- Gets the EKS information, including which EC2 instances the pod is hosted on.
- Determines if isolation is required based on the Security Hub custom action.
- Determines if acquisition is required based on tags associated with the EC2 instance. The current tag that is evaluated is the following:
- Tag name:
IsTriageRequired - Tag key:
trueorfalse
- Tag name:
- Initiates the acquisition flow based on triaging output
- Triaging details are stored in Amazon DynamoDB.
- The following two acquisition flows are initiated in parallel:
- Memory forensics flow – The Step Functions workflow captures the memory data and stores it in Amazon Simple Storage Service (Amazon S3). Post memory acquisition completion, the node is isolated by cordoning the node, creating a network policy, and applying a restricted security group to the cluster. To help maintain the chain of custody, a new security group is attached to the targeted instance and removes access for users, admins, or developers.
- Disk forensics flow – The Step Functions workflow takes a snapshot of the Amazon Elastic Block Storage (Amazon EBS) volume and shares it with the forensic account.
Note: The isolation action is initiated based on the selected Security Hub custom action.
- Acquisition details are stored in DynamoDB.
- After the disk or memory acquisition process is complete, and the evidence has been captured successfully, a notification is sent to an investigation Step Functions state machine to begin the automated investigation of the captured data.
- The investigation Step Functions starts a forensic instance from a forensic AMI loaded with customer forensic tools:
- Loads the memory data from Amazon S3 for memory investigation.
- Creates an Amazon EBS volume from the snapshot and attaches it for disk analysis.
- Systems Manager documents (SSM documents) are used to run a forensic investigation.
- DynamoDB stores the state of the forensic tasks and their result when the jobs are complete. Investigation job details are stored in DynamoDB.
- Investigation details are shared with customers using Amazon Simple Notification Service (Amazon SNS).
- Forensic AMI is used by investigation Step Functions to perform memory and disk investigation.
Solution deployment
You can deploy the Amazon EKS IR automation solution using the AWS CDK or synthesizing a CDK into AWS CloudFormation templates and deploying them using AWS Management Console. Although the solution can be deployed in a single AWS account, the AWS Security Reference Architecture (AWS SRA) recommends that you use separate AWS accounts for forensic evidence and security tooling. The solution deployment follows AWS SRA recommendations.
The latest code for the Amazon EKS IR automation solution can be found at sample-eks-incident-response-automation, where you can also contribute to the sample code. For instructions and more information about using the AWS CDK, see Getting Started with AWS CDK.
Deploy the automation that collects, stores, and investigates forensic artifacts in the forensic AWS account:
- To build the app when navigating to the project’s root folder, use the following commands.
npm cinpm run-build-lambda- Run the following commands in your terminal while authenticated in your forensic solution AWS account. Be sure to replace <INSERT_AWS_ACCOUNT> with your account number and replace <INSERT_REGION> with the AWS Region that you want the solution deployed to.
Example:
cdk deploy —all -c account=1234567890 -c region=us-east-1 —require-approval=never -c secHubAccount=0987654321 -c STACK_BUILD_TARGET_ACCT=forensicAccount
Deploy the Security Hub custom action and EventBridge in the Security Hub Region of the delegated administrator account where security findings are consolidated:
- To build the app when navigating to the project’s root folder, use the following commands.
npm cinpm run build-lambda- Run the following commands in your terminal while authenticated in your Security Hub aggregator AWS account. Be sure to replace
<INSERT_AWS_ACCOUNT>with your account number and replace<INSERT_REGION>with the AWS Region that you want the solution deployed to.
Example:
cdk deploy --all -c account=0987654321 -c region=us-east-1 --require-approval=never -c forensicAccount=1234567890 -c STACK_BUILD_TARGET_ACCT=securityHubAccount -c sechubregion=us-east-1
Deploy the cross-account IAM role the security automation will use in the application AWS account where the EKS workload exists:
- Sign in to the AWS CloudFormation console of the application AWS account.
- Launch the CloudFormation cross-account-role.yml stack.
- Pass the following CloudFormation input parameters:
- solutionInstalledAccount=<Forensic Solution AWS Account Number>
- solutionAccountRegion=<Region of solution deployment>
- kmsKey=<ARN of the application account EBS volume encryption KMS key>
Use the solution to respond to an EKS GuardDuty alert
You can now use the automated solution on an Amazon EKS cluster with a GuardDuty finding that’s integrated with Security Hub. If you need to create GuardDuty findings, see How to generate security findings to help your security team with incident response simulations.
After you have an EKS security finding, you can go through either one of the IR workflows:
- Forensic triage – This workflow evaluates in-scope EKS resources, collects volatile and non-volatile memory, conducts an investigation, and exports investigation artifacts to a forensic S3 bucket.
- Forensic isolation – In addition to components of the previous workflow, the in-scope EKS resources are quarantined at the network and IAM layers.
In this example, you’ll use the forensic isolation workflow because that covers the end-to-end capabilities of the solution.
Run the forensic isolation workflow:
- Open the AWS Security Hub console in the Security Hub aggregator account.
- Choose Findings in the navigation pane and then select a security finding for Amazon EKS.
- Select the custom action for Forensic Isolation. This will start the workflow in the Security Hub aggregator account and invoke the Step Functions in the forensic account.
- Open the AWS Step Functions console in the forensic account.
- In the navigation pane, choose State Machines and then select the Forensic-Triage-Function to view the workflow graph status. In the following figure, the Step Functions workflow has successfully completed.

Figure 5: EKS triage Step Functions graph view
- In the Get Resource Info Case step, the pod name from the GuardDuty finding is extracted to identify the EKS cluster it’s part of and the related EC2 resources.
Note: Per the solution, a guardrail is added to block action on an EC2 instance that is part of an EKS cluster with the IsTriageRequired tag with a value set to
false. If automation is invoked against a protected EC2 instance resource, acquisitionFlow is skipped and a notification will be sent to the SNS topic. - Because the EKS cluster isn’t excluded through the IsTriageRequired tag, a parallel invocation of Step Functions is invoked to capture forensic evidence.
- Select the Disk-Forensics-Acquisition-Function. The workflow here is similar to a normal EC2 incident response flow to capture snapshots and EBS volumes with the caveat that the EKS cluster can have multiple EC2 instances. In the following figure, the Step Functions workflow has successfully completed.
Figure 6: Disk forensics acquisition Step Functions graph view
- Select the Memory-Forensics-Acquisition-Function; In the following figure, the Step Function workflow has successfully completed.
Figure 7: Memory forensics acquisition Step Functions graph view
- As previously mentioned, you will need to determine if you want to map pods to process ID (PID) as part of this workflow. The automation captures the volatile memory where you will be able see the PIDs on the EC2 instance but does not map the PID to node for deeper investigation.
- After the Is Memory Acquisition Complete step is complete and if the Security Hub custom action for Forensic Isolation was selected, the isolation workflow of the EKS cluster begins. The isolation workflow will go through EKS-specific steps to:
- Label the affected pods on the EKS cluster.
- Apply a network policy to the affected pods.
- Revoke IAM role sessions.
- Cordon the node.
Note: One reason you might not want to automatically map pods to PIDs is to minimize interaction with the possibly compromised cluster and quickly move towards isolation.
- To expedite the investigation process, the
Forensic-Investigation-Functionis invoked when theMemory-Forensics-Acquisition-Functionis completed and separately by theDisk-Forensics-Acquisition-Function. This is because of the disk and memory forensic evidence collection completing at different times. A forensic EC2 instance will be launched and begin conducting the investigation on the forensic artifacts. The completed investigation artifacts will be sent to Amazon S3 as they’re completed.- You can use the console to view EKS artifacts within the dedicated S3 bucket in the forensic AWS account.
- The forensic investigation results from the automated workflow are also saved to the dedicated S3 bucket in the forensic AWS account.

Figure 8: Completed memory investigation artifacts for EKS



Note: Depending on your desired workflow, you can edit these steps or add additional isolation steps to change instance profiles, security groups, or NACL rules.


Figure 9: Completed disk investigation artifacts for EKS
As part of the automation, the forensic investigation EC2 instance in the forensic account is terminated after investigation is completed. The automation can be updated to retain the EC2 instance to so that your security teams can continue their investigation and review investigation artifacts to expedite root cause analysis.
As previously mentioned, the workflow you just went through encompasses both investigation and isolation of Amazon EKS resources. If your security teams want to conduct a more thorough investigation prior to isolating EKS resources, select the Forensic Triage custom action in Security Hub. Additionally, if you want to update the solution to be invoked from your security incident and event management (SIEM) tool, you can directly invoke the Forensic-Triage-Function Step Functions from your SIEM.
Clean up
For the cross-account IAM role in the application account, you can:
- Go to the AWS CloudFormation console for the application account and Region where you deployed the cross-account IAM role, select the cross-account-role stack.
- Choose the option to Delete the stack.
To clean up the CDK stacks, run the following command in the source folder in the Security Hub aggregator account and forensic account.
cdk destroy --all
Conclusion
In this post, we showed you the differences between Amazon EKS and Amazon EC2 resources and how to handle EKS automation for incident response. Even though EKS clusters are on EC2 instances, it’s important to understand the differences before implementing an automated solution that will affect EKS resources. We also walked through the deployment of an EKS-customized Automated Forensics Orchestrator for Amazon EC2 solution and showed you the end-to-end IR lifecycle to respond to a possible EKS compromise. The same approach to customize existing EC2 IR automated solutions can be used to expand support for EKS resources within your AWS environment to increase your security posture.
If you have feedback about this post, submit comments in the comments section that follows. If you have questions about this post, start a thread on re:Post.

















 Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it
Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it 



























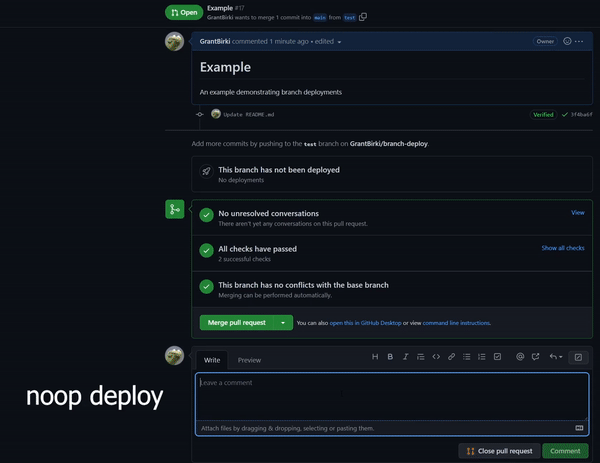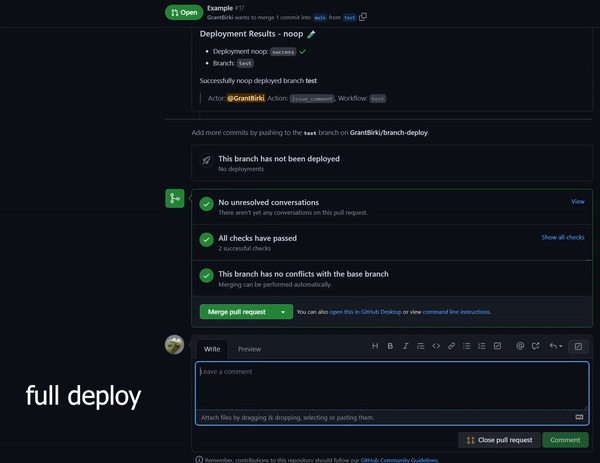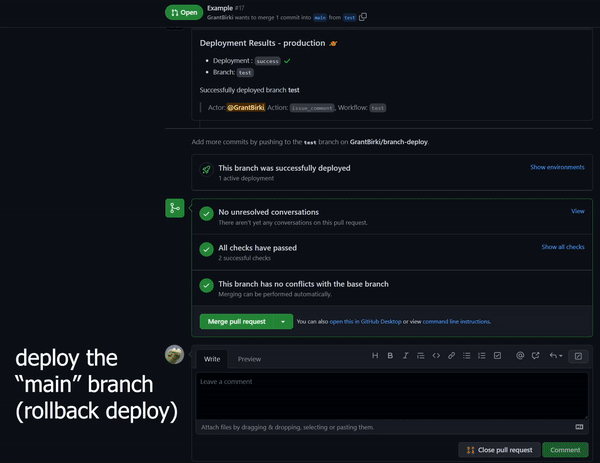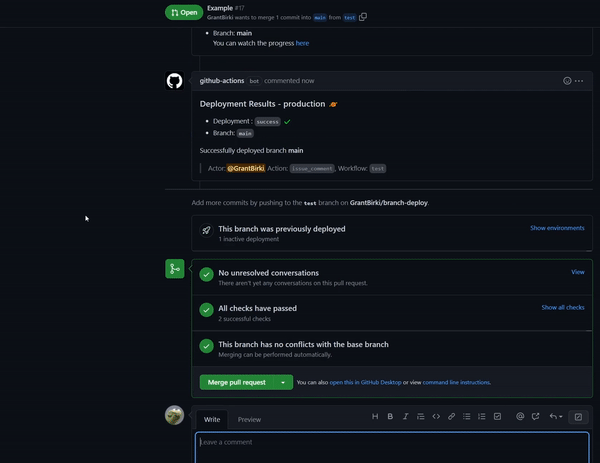


 Detects when IssueOps commands are used on a pull request.
Detects when IssueOps commands are used on a pull request.  Configurable: choose your command syntax, environment, noop trigger, base branch, reaction, and more.
Configurable: choose your command syntax, environment, noop trigger, base branch, reaction, and more. Respects your branch protection settings configured for the repository.
Respects your branch protection settings configured for the repository. Comments and reacts to your IssueOps commands.
Comments and reacts to your IssueOps commands. Triggers GitHub deployments for you with simple configuration.
Triggers GitHub deployments for you with simple configuration. Deploy locks to prevent multiple deployments from clashing.
Deploy locks to prevent multiple deployments from clashing. Configurable environment targets.
Configurable environment targets.