Post Syndicated from Grab Tech original https://engineering.grab.com/telematics-at-grab
Telematics is a collection of sensor data such as accelerometer data, gyroscope data, and GPS data that a driver’s mobile phone provides, and we collect, during the ride. With this information, we apply data science logic to detect traffic events such as harsh braking, acceleration, cornering, and unsafe lane changes, in order to help improve our consumers’ ride experience.
Introduction
As Grab grows to meet our consumers’ needs, the number of driver-partners has also grown. This requires us to ensure that our consumers’ safety continues to remain the highest priority as we scale. We developed an in-house telematics engine which uses mobile phone sensors to determine, evaluate, and quantify the driving behaviour of our driver-partners. This telemetry data is then evaluated and gives us better insights into our driver-partners’ driving patterns.
Through our data, we hope to improve our driver-partners’ driving habits and reduce the likelihood of driving-related incidents on our platform. This telemetry data also helps us determine optimal insurance premiums for driver-partners with risky driving patterns and reward driver-partners who have better driving habits.
In addition, we also merge telematics data with spatial data to further identify areas where dangerous driving manoeuvres happen frequently. This data is used to inform our driver-partners to be alert and drive more safely in such areas.
Background
With more consumers using the Grab app, we realised that purely relying on passenger feedback is not enough; we had no definitive way to tell which driver-partners were actually driving safely, when they deviated from their routes or even if they had been involved in an accident.
To help address these issues, we developed an in-house telematics engine that analyses telemetry data, identifies driver-partners’ driving behaviour and habits, and provides safety reports for them.
Architecture details
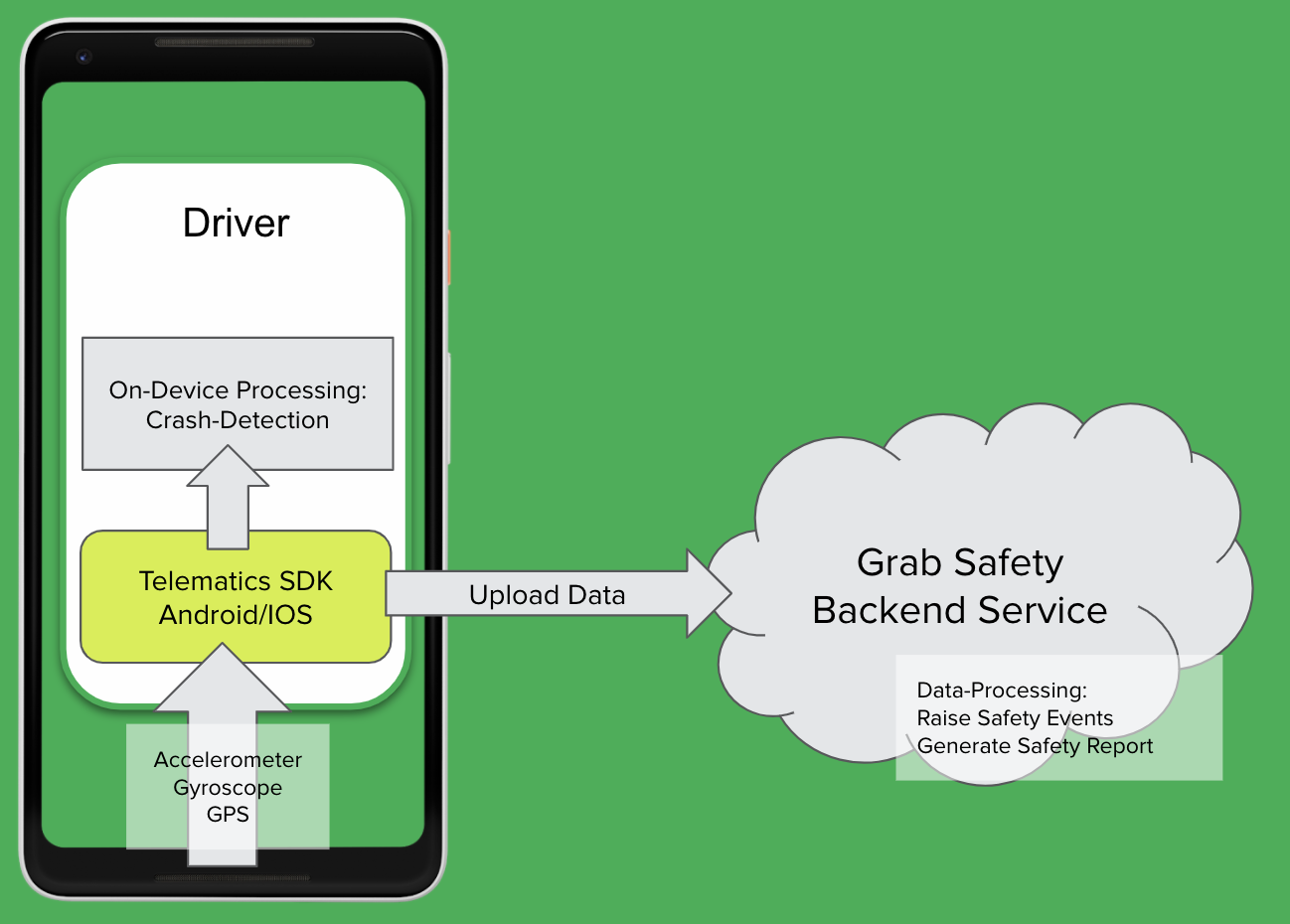
As shown in the diagram, our telematics SDK receives raw sensor data from our driver-partners’ devices and processes it in two ways:
- On-device processing for crash detection: Used to determine situations such as if the driver-partner has been in an accident.
- Raising traffic events and generating safety reports after each job: Useful for detecting events like speeding and harsh braking.
Note: Safety reports are generated by our backend service using sensor data that is only uploaded as a text file after each ride.
Implementation
Our telematics framework relies on accelerometer, gyroscope and GPS sensors within the mobile device to infer the vehicle’s driving parameters. Both accelerometer and gyroscope are triaxial sensors, and their respective measurements are in the mobile device’s frame of reference.
That being said, the data collected from these sensors have no fixed sample rate, so we need to implement sensor data time synchronisation. For example, there will be temporal misalignment between gyroscope and accelerometer data if they do not share the same timestamp. The sample rate that comes from the accelerometer and gyroscope also varies independently. Therefore, we need to uniformly sample the sensor data to be at the same frequency rate.
This synchronisation process is done in two steps:
- Interpolation to uniform time grid at a reasonably higher frequency.
- Decimation from the higher frequency to the output data rate for accelerometer and gyroscope data.
We then use the Fourier Transform to transform a signal from time domain to frequency domain for compression. These components are then written to a text file on the mobile device, compressed, and uploaded after the end of each ride.
Learnings/Conclusion
There are a few takeaways that we learned from this project:
- Sensor data frequency: There are many device manufacturers out there for Android and each one of them has a different sensor chipset. The frequency of the sensor data may vary from device to device.
- Four-wheel (4W) vs two-wheel (2W): The behaviour is different for a driver-partner on 2W vs 4W, so we need different rules for each.
- Hardware axis-bias: The device may not be aligned with the vehicle during the ride. It cannot be assumed that the phone will remain in a fixed orientation throughout the trip, so the mobile device sensors might not accurately measure the acceleration/braking or sharp turning of the vehicle.
- Sensor noise: There are artifacts in sensor readings, which are basically a single outlier event that represents an error and is not a valid sensor reading.
- Time-synchronisation: GPS, accelerometer, and gyroscope events are captured independently by three different sensors and have different time formats. These events will need to be transformed into the same time grid in order to work together. For example, the GPS location from 30 seconds prior to the gyroscope event will not work as they are out of sync.
- Data compression and network consumption: Longer rides will contain more telematics data. It will result in a bigger upload size and increase in time for file compression.
What’s next?
There are a few milestones that we want to accomplish with our telematics framework in the future. However, our number one goal is to extend telematics to all bookings across Grab verticals. We are also planning to add more on-device rules and data processing for event detections to further eliminate future delays from backend communication for crash detection.
With the data from our telematics framework, we can improve our passengers’ experience and improve safety for both passengers and driver-partners.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!