Post Syndicated from mikesefanov original https://yahooeng.tumblr.com/post/161855616651

By Michael Natkovich, Akshai Sarma, Nathan Speidel, Marcus Svedman, and Cat Utah
Big Data is no longer just Apache server logs. Nowadays, the data may be user engagement data, performance metrics, IoT (Internet of Things) data, or something else completely atypical. Regardless of the size of the data, or the type of querying patterns on it (exploratory, ad-hoc, periodic, long-term, etc.), everyone wants queries to be as fast as possible and cheap to run in terms of resources. Data can be broadly split into two kinds: the streaming (generally real-time) kind or the batched-up-over-a-time-interval (e.g., hourly or daily) kind. The batch version is typically easier to query since it is stored somewhere like a data warehouse that has nice SQL-like interfaces or an easy to use UI provided by tools such as Tableau, Looker, or Superset. Running arbitrary queries on streaming data quickly and cheaply though, is generally much harder… until now. Today, we are pleased to share our newly open sourced, forward-looking general purpose query engine, called Bullet, with the community on GitHub.
With Bullet, you can:
- Powerful and nested filtering
- Fetching raw data records
- Aggregating data using Group Bys (Sum, Count, Average, etc.), Count Distincts, Top Ks
- Getting distributions of fields like Percentiles or Frequency histograms
One of the key differences between how Bullet queries data and the standard querying paradigm is that Bullet does not store any data. In most other systems where you have a persistence layer (including in-memory storage), you are doing a look-back when you query the layer. Instead, Bullet operates on data flowing through the system after the query is started – it’s a look-forward system that doesn’t need persistence. On a real-time data stream, this means that Bullet is querying data after the query is submitted. This also means that Bullet does not query any data that has already passed through the stream. The fact that Bullet does not rely on a persistence layer is exactly what makes it extremely lightweight and cheap to run.
To see why this is better for the kinds of use cases Bullet is meant for – such as quickly looking at some metric, checking some assumption, iterating on a query, checking the status of something right now, etc. – consider the following: if you had a 1000 queries in a traditional query system that operated on the same data, these query systems would most likely scan the data 1000 times each. By the very virtue of it being forward looking, 1000 queries in Bullet scan the data only once because the arrival of the query determines and fixes the data that it will see. Essentially, the data is coming to the queries instead of the queries being farmed out to where the data is. When the conditions of the query are satisfied (usually a time window or a number of events), the query terminates and returns you the result.
A Brief Architecture Overview
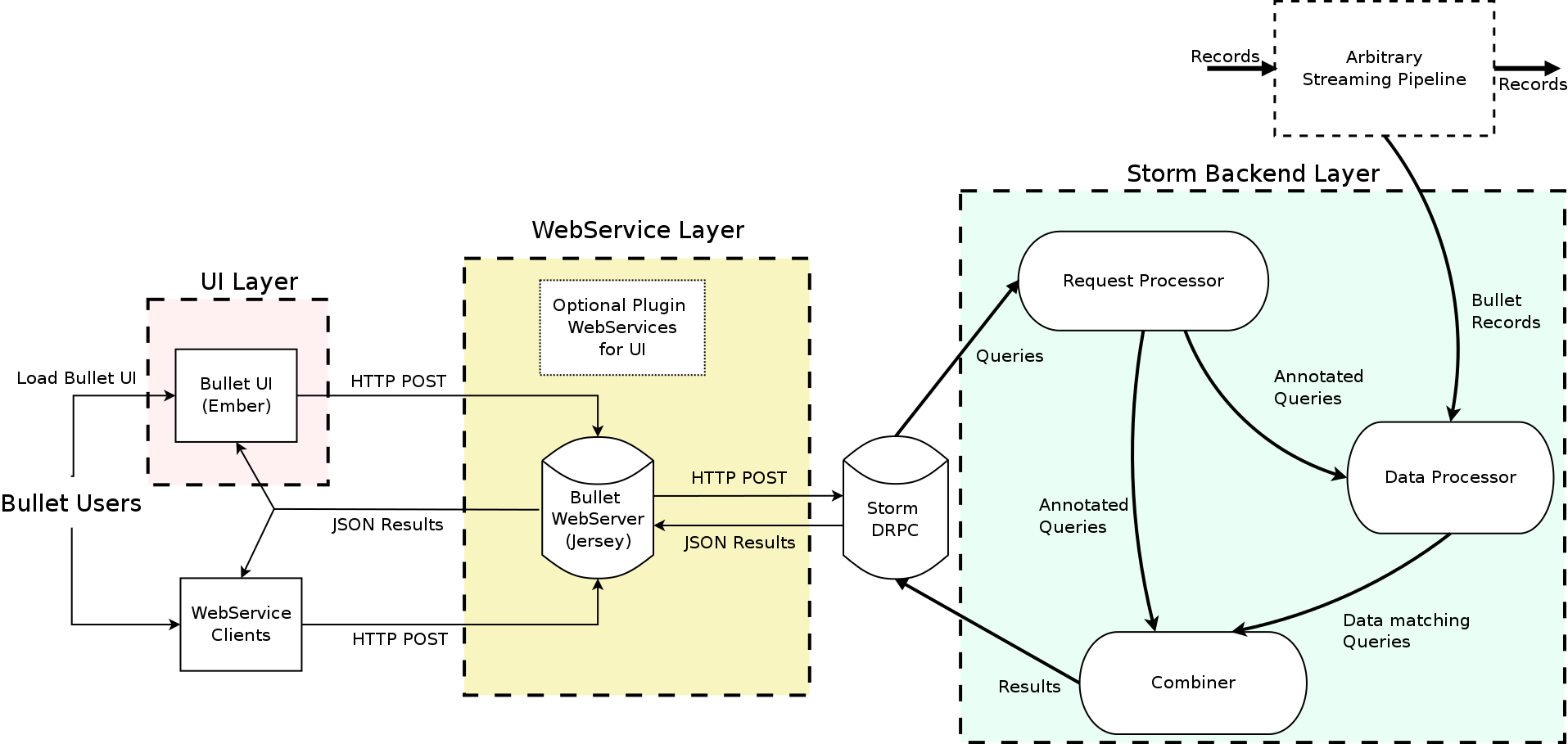{kind=link}
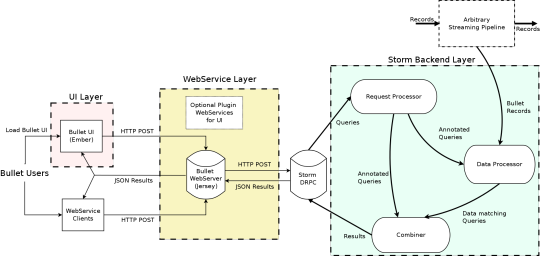
High Level Bullet Architecture
The Bullet architecture is multi-tenant, can scale linearly for more queries and/or more data, and has been tested to handle 700+ simultaneous queries on a data stream that had up to 1.5 million records per second, or 5-6 GB/s. Bullet is currently implemented on top of Storm and can be extended to support other stream processing engines as well, like Spark Streaming or Flink. Bullet is pluggable, so you can plug in any source of data that can be read in Storm by implementing a simple data container interface to let Bullet work with it.
The UI, web service, and the backend layers constitute your standard three-tier architecture. The Bullet backend can be split into three main subsystems:
- Request Processor – receives queries, adds metadata, and sends it to the rest of the system
- Data Processor – reads data from an input stream, converts it to a unified data format, and matches it against queries
- Combiner – combines results for different queries, performs final aggregations, and returns results
The web service can be deployed on any servlet container, like Jetty. The UI is a Node-based Ember application that runs in the client browser. Our full documentation contains all the details on exactly how we perform computationally-intractable queries like Count Distincts on fields with cardinality in the millions, etc. (DataSketches).
Usage at Yahoo
An instance of Bullet is currently running at Yahoo in production against a small subset of Yahoo’s user engagement data stream. This data is roughly 100,000 records per second and is about 130 MB/s compressed. Bullet queries this with about 100 CPU Virtual Cores and 120 GB of RAM. This fits on less than 2 of our (64 Virtual Cores, 256 GB RAM each) test Storm cluster machines.
One of the most popular use cases at Yahoo is to use Bullet to manually validate the instrumentation of an app or web application. Instrumentation produces user engagement data like clicks, views, swipes, etc. Since this data powers everything we do from analytics to personalization to targeting, it is absolutely critical that the data is correct. The usage pattern is generally to:
- Submit a Bullet query to obtain data associated with your mobile device or browser (filter on a cookie value or mobile device ID)
- Open and use the application to generate the data while the Bullet query is running
- Go back to Bullet and inspect the data
In addition, Bullet is also used programmatically in continuous delivery pipelines for functional testing instrumentation on product releases. Product usage is simulated, then data is generated and validated in seconds using Bullet. Bullet is orders of magnitude faster to use for this kind of validation and for general data exploration use cases, as opposed to waiting for the data to be available in Hive or other systems. The Bullet UI supports pivot tables and a multitude of charting options that may speed up analysis further compared to other querying options.
We also use Bullet to do a bunch of other interesting things, including instances where we dynamically compute cardinalities (using a Count Distinct Bullet query) of fields as a check to protect systems that can’t support extremely high cardinalities for fields like Druid.
What you do with Bullet is entirely determined by the data you put it on. If you put it on data that is essentially some set of performance metrics (data center statistics for example), you could be running a lot of queries that find the 95th and 99th percentile of a metric. If you put it on user engagement data, you could be validating instrumentation and mostly looking at raw data.
We hope you will find Bullet interesting and tell us how you use it. If you find something you want to change, improve, or fix, your contributions and ideas are always welcome! You can contact us here.
Helpful Links