Post Syndicated from mikesefanov original https://yahooeng.tumblr.com/post/162320493306
By Suhas Sadanandan, Director of Engineering
When it comes to performance and reliability, there is perhaps no application where this matters more than with email. Today, we announced a new Yahoo Mail experience for desktop based on a completely rewritten tech stack that embodies these fundamental considerations and more.
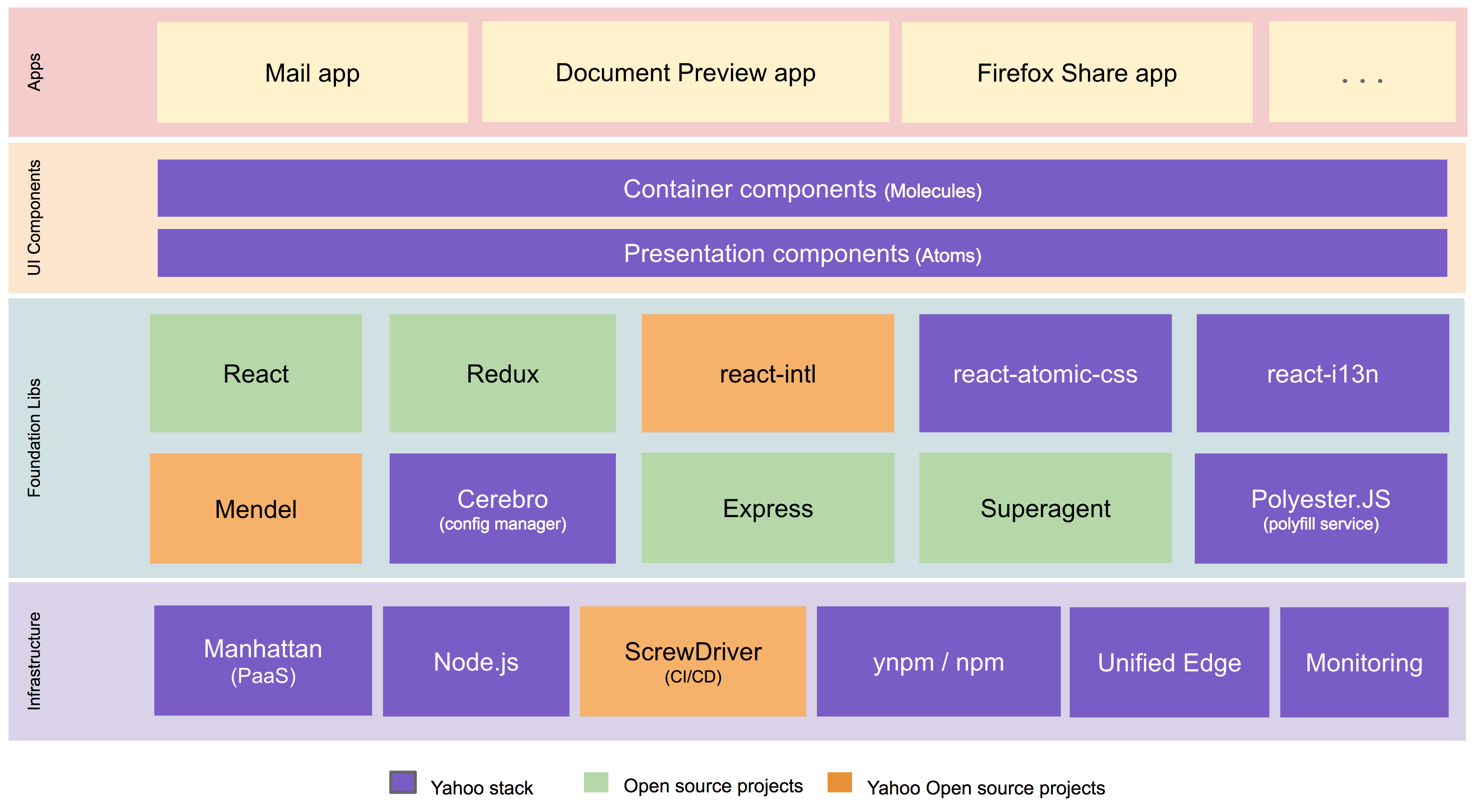
We built the new Yahoo Mail experience using a best-in-class front-end tech stack with open source technologies including React, Redux, Node.js, react-intl (open-sourced by Yahoo), and others. A high-level architectural diagram of our stack is below.
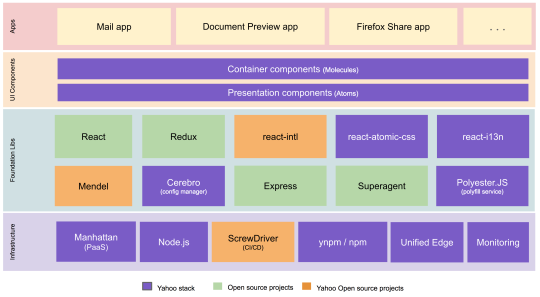
In building our new tech stack, we made use of the most modern tools available in the industry to come up with the best experience for our users by optimizing the following fundamentals:
Performance
A key feature of the new Yahoo Mail architecture is blazing-fast initial loading (aka, launch).
We introduced new network routing which sends users to their nearest geo-located email servers (proximity-based routing). This has resulted in a significant reduction in time to first byte and should be immediately noticeable to our international users in particular.
We now do server-side rendering to allow our users to see their mail sooner. This change will be immediately noticeable to our low-bandwidth users. Our application is isomorphic, meaning that the same code runs on the server (using Node.js) and the client. Prior versions of Yahoo Mail had programming logic duplicated on the server and the client because we used PHP on the server and JavaScript on the client.
Using efficient bundling strategies (JavaScript code is separated into application, vendor, and lazy loaded bundles) and pushing only the changed bundles during production pushes, we keep the cache hit ratio high. By using react-atomic-css, our homegrown solution for writing modular and scoped CSS in React, we get much better CSS reuse.
In prior versions of Yahoo Mail, the need to run various experiments in parallel resulted in additional branching and bloating of our JavaScript and CSS code. While rewriting all of our code, we solved this issue using Mendel, our homegrown solution for bucket testing isomorphic web apps, which we have open sourced.
Rather than using custom libraries, we use native HTML5 APIs and ES6 heavily and use PolyesterJS, our homegrown polyfill solution, to fill the gaps. These factors have further helped us to keep payload size minimal.
With all the above optimizations, we have been able to reduce our JavaScript and CSS footprint by approximately 50% compared to the previous desktop version of Yahoo Mail, helping us achieve a blazing-fast launch.
In addition to initial launch improvements, key features like search and message read (when a user opens an email to read it) have also benefited from the above optimizations and are considerably faster in the latest version of Yahoo Mail.
We also significantly reduced the memory consumed by Yahoo Mail on the browser. This is especially noticeable during a long running session.
Reliability
With this new version of Yahoo Mail, we have a 99.99% success rate on core flows: launch, message read, compose, search, and actions that affect messages. Accomplishing this over several billion user actions a day is a significant feat. Client-side errors (JavaScript exceptions) are reduced significantly when compared to prior Yahoo Mail versions.
Product agility and launch velocity
We focused on independently deployable components. As part of the re-architecture of Yahoo Mail, we invested in a robust continuous integration and delivery flow. Our new pipeline allows for daily (or more) pushes to all Mail users, and we push only the bundles that are modified, which keeps the cache hit ratio high.
Developer effectiveness and satisfaction
In developing our tech stack for the new Yahoo Mail experience, we heavily leveraged open source technologies, which allowed us to ensure a shorter learning curve for new engineers. We were able to implement a consistent and intuitive onboarding program for 30+ developers and are now using our program for all new hires. During the development process, we emphasise predictable flows and easy debugging.
Accessibility
The accessibility of this new version of Yahoo Mail is state of the art and delivers outstanding usability (efficiency) in addition to accessibility. It features six enhanced visual themes that can provide accommodation for people with low vision and has been optimized for use with Assistive Technology including alternate input devices, magnifiers, and popular screen readers such as NVDA and VoiceOver. These features have been rigorously evaluated and incorporate feedback from users with disabilities. It sets a new standard for the accessibility of web-based mail and is our most-accessible Mail experience yet.
Open source
We have open sourced some key components of our new Mail stack, like Mendel, our solution for bucket testing isomorphic web applications. We invite the community to use and build upon our code. Going forward, we plan on also open sourcing additional components like react-atomic-css, our solution for writing modular and scoped CSS in React, and lazy-component, our solution for on-demand loading of resources.
Many of our company’s best technical minds came together to write a brand new tech stack and enable a delightful new Yahoo Mail experience for our users.
We encourage our users and engineering peers in the industry to test the limits of our application, and to provide feedback by clicking on the Give Feedback call out in the lower left corner of the new version of Yahoo Mail.



{kind=link}
{kind=link}
{kind=link}
{kind=link}