Post Syndicated from Brandon Abear original https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/
This is a guest post co-written with Brandon Abear, Dinesh Sharma, John Bush, and Ozcan IIikhan from GoDaddy.
GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, attract customers, and manage their work.
At GoDaddy, we take pride in being a data-driven company. Our relentless pursuit of valuable insights from data fuels our business decisions and ensures customer satisfaction. Our commitment to efficiency is unwavering, and we’ve undertaken an exciting initiative to optimize our batch processing jobs. In this journey, we have identified a structured approach that we refer to as the seven layers of improvement opportunities. This methodology has become our guide in the pursuit of efficiency.
In this post, we discuss how we enhanced operational efficiency with Amazon EMR Serverless. We share our benchmarking results and methodology, and insights into the cost-effectiveness of EMR Serverless vs. fixed capacity Amazon EMR on EC2 transient clusters on our data workflows orchestrated using Amazon Managed Workflows for Apache Airflow (Amazon MWAA). We share our strategy for the adoption of EMR Serverless in areas where it excels. Our findings reveal significant benefits, including over 60% cost reduction, 50% faster Spark workloads, a remarkable five-times improvement in development and testing speed, and a significant reduction in our carbon footprint.
Background
In late 2020, GoDaddy’s data platform initiated its AWS Cloud journey, migrating an 800-node Hadoop cluster with 2.5 PB of data from its data center to EMR on EC2. This lift-and-shift approach facilitated a direct comparison between on-premises and cloud environments, ensuring a smooth transition to AWS pipelines, minimizing data validation issues and migration delays.
By early 2022, we successfully migrated our big data workloads to EMR on EC2. Using best practices learned from the AWS FinHack program, we fine-tuned resource-intensive jobs, converted Pig and Hive jobs to Spark, and reduced our batch workload spend by 22.75% in 2022. However, scalability challenges emerged due to the multitude of jobs. This prompted GoDaddy to embark on a systematic optimization journey, establishing a foundation for more sustainable and efficient big data processing.
Seven layers of improvement opportunities
In our quest for operational efficiency, we have identified seven distinct layers of opportunities for optimization within our batch processing jobs, as shown in the following figure. These layers range from precise code-level enhancements to more comprehensive platform improvements. This multi-layered approach has become our strategic blueprint in the ongoing pursuit of better performance and higher efficiency.

The layers are as follows:
- Code optimization – Focuses on refining the code logic and how it can be optimized for better performance. This involves performance enhancements through selective caching, partition and projection pruning, join optimizations, and other job-specific tuning. Using AI coding solutions is also an integral part of this process.
- Software updates – Updating to the latest versions of open source software (OSS) to capitalize on new features and improvements. For example, Adaptive Query Execution in Spark 3 brings significant performance and cost improvements.
- Custom Spark configurations – Tuning of custom Spark configurations to maximize resource utilization, memory, and parallelism. We can achieve significant improvements by right-sizing tasks, such as through
spark.sql.shuffle.partitions, spark.sql.files.maxPartitionBytes, spark.executor.cores, and spark.executor.memory. However, these custom configurations might be counterproductive if they are not compatible with the specific Spark version.
- Resource provisioning time – The time it takes to launch resources like ephemeral EMR clusters on Amazon Elastic Compute Cloud (Amazon EC2). Although some factors influencing this time are outside of an engineer’s control, identifying and addressing the factors that can be optimized can help reduce overall provisioning time.
- Fine-grained scaling at task level – Dynamically adjusting resources such as CPU, memory, disk, and network bandwidth based on each stage’s needs within a task. The aim here is to avoid fixed cluster sizes that could result in resource waste.
- Fine-grained scaling across multiple tasks in a workflow – Given that each task has unique resource requirements, maintaining a fixed resource size may result in under- or over-provisioning for certain tasks within the same workflow. Traditionally, the size of the largest task determines the cluster size for a multi-task workflow. However, dynamically adjusting resources across multiple tasks and steps within a workflow result in a more cost-effective implementation.
- Platform-level enhancements – Enhancements at preceding layers can only optimize a given job or a workflow. Platform improvement aims to attain efficiency at the company level. We can achieve this through various means, such as updating or upgrading the core infrastructure, introducing new frameworks, allocating appropriate resources for each job profile, balancing service usage, optimizing the use of Savings Plans and Spot Instances, or implementing other comprehensive changes to boost efficiency across all tasks and workflows.
Layers 1–3: Previous cost reductions
After we migrated from on premises to AWS Cloud, we primarily focused our cost-optimization efforts on the first three layers shown in the diagram. By transitioning our most costly legacy Pig and Hive pipelines to Spark and optimizing Spark configurations for Amazon EMR, we achieved significant cost savings.
For example, a legacy Pig job took 10 hours to complete and ranked among the top 10 most expensive EMR jobs. Upon reviewing TEZ logs and cluster metrics, we discovered that the cluster was vastly over-provisioned for the data volume being processed and remained under-utilized for most of the runtime. Transitioning from Pig to Spark was more efficient. Although no automated tools were available for the conversion, manual optimizations were made, including:
- Reduced unnecessary disk writes, saving serialization and deserialization time (Layer 1)
- Replaced Airflow task parallelization with Spark, simplifying the Airflow DAG (Layer 1)
- Eliminated redundant Spark transformations (Layer 1)
- Upgraded from Spark 2 to 3, using Adaptive Query Execution (Layer 2)
- Addressed skewed joins and optimized smaller dimension tables (Layer 3)
As a result, job cost decreased by 95%, and job completion time was reduced to 1 hour. However, this approach was labor-intensive and not scalable for numerous jobs.
Layers 4–6: Find and adopt the right compute solution
In late 2022, following our significant accomplishments in optimization at the previous levels, our attention moved towards enhancing the remaining layers.
Understanding the state of our batch processing
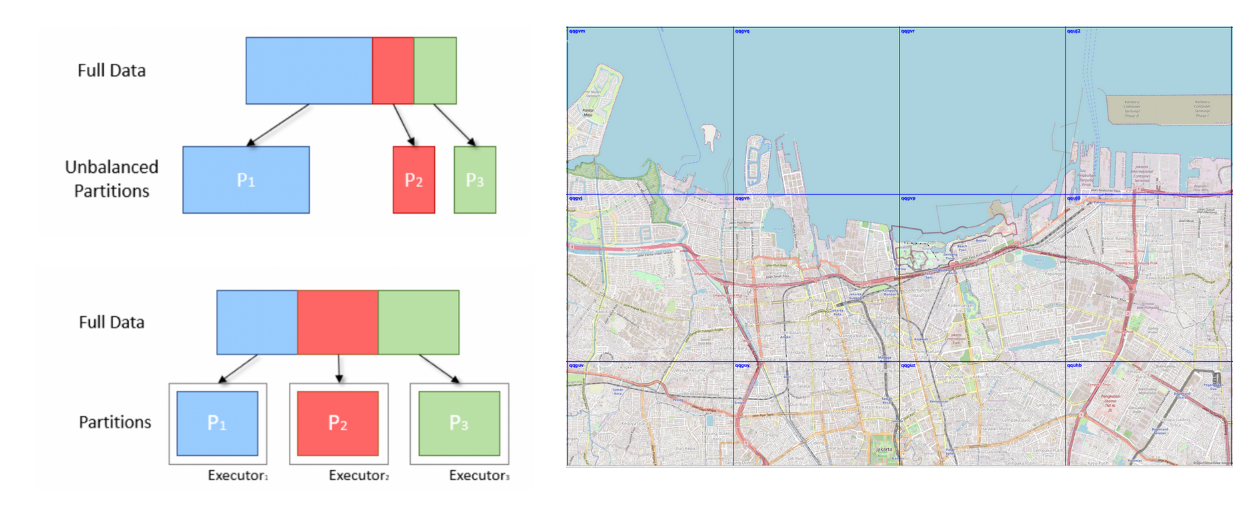
We use Amazon MWAA to orchestrate our data workflows in the cloud at scale. Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks referred to as workflows. In this post, the terms workflow and job are used interchangeably, referring to the Directed Acyclic Graphs (DAGs) consisting of tasks orchestrated by Amazon MWAA. For each workflow, we have sequential or parallel tasks, and even a combination of both in the DAG between create_emr and terminate_emr tasks running on a transient EMR cluster with fixed compute capacity throughout the workflow run. Even after optimizing a portion of our workload, we still had numerous non-optimized workflows that were under-utilized due to over-provisioning of compute resources based on the most resource-intensive task in the workflow, as shown in the following figure.

This highlighted the impracticality of static resource allocation and led us to recognize the necessity of a dynamic resource allocation (DRA) system. Before proposing a solution, we gathered extensive data to thoroughly understand our batch processing. Analyzing the cluster step time, excluding provisioning and idle time, revealed significant insights: a right-skewed distribution with over half of the workflows completing in 20 minutes or less and only 10% taking more than 60 minutes. This distribution guided our choice of a fast-provisioning compute solution, dramatically reducing workflow runtimes. The following diagram illustrates step times (excluding provisioning and idle time) of EMR on EC2 transient clusters in one of our batch processing accounts.

Furthermore, based on the step time (excluding provisioning and idle time) distribution of the workflows, we categorized our workflows into three groups:
- Quick run – Lasting 20 minutes or less
- Medium run – Lasting between 20–60 minutes
- Long run – Exceeding 60 minutes, often spanning several hours or more
Another factor we needed to consider was the extensive use of transient clusters for reasons such as security, job and cost isolation, and purpose-built clusters. Additionally, there was a significant variation in resource needs between peak hours and periods of low utilization.
Instead of fixed-size clusters, we could potentially use managed scaling on EMR on EC2 to achieve some cost benefits. However, migrating to EMR Serverless appears to be a more strategic direction for our data platform. In addition to potential cost benefits, EMR Serverless offers additional advantages such as a one-click upgrade to the newest Amazon EMR versions, a simplified operational and debugging experience, and automatic upgrades to the latest generations upon rollout. These features collectively simplify the process of operating a platform on a larger scale.
Evaluating EMR Serverless: A case study at GoDaddy
EMR Serverless is a serverless option in Amazon EMR that eliminates the complexities of configuring, managing, and scaling clusters when running big data frameworks like Apache Spark and Apache Hive. With EMR Serverless, businesses can enjoy numerous benefits, including cost-effectiveness, faster provisioning, simplified developer experience, and improved resilience to Availability Zone failures.
Recognizing the potential of EMR Serverless, we conducted an in-depth benchmark study using real production workflows. The study aimed to assess EMR Serverless performance and efficiency while also creating an adoption plan for large-scale implementation. The findings were highly encouraging, showing EMR Serverless can effectively handle our workloads.
Benchmarking methodology
We split our data workflows into three categories based on total step time (excluding provisioning and idle time): quick run (0–20 minutes), medium run (20–60 minutes), and long run (over 60 minutes). We analyzed the impact of the EMR deployment type (Amazon EC2 vs. EMR Serverless) on two key metrics: cost-efficiency and total runtime speedup, which served as our overall evaluation criteria. Although we did not formally measure ease of use and resiliency, these factors were considered throughout the evaluation process.
The high-level steps to assess the environment are as follows:
- Prepare the data and environment:
- Choose three to five random production jobs from each job category.
- Implement required adjustments to prevent interference with production.
- Run tests:
- Run scripts over several days or through multiple iterations to gather precise and consistent data points.
- Perform tests using EMR on EC2 and EMR Serverless.
- Validate data and test runs:
- Validate input and output datasets, partitions, and row counts to ensure identical data processing.
- Gather metrics and analyze results:
- Gather relevant metrics from the tests.
- Analyze results to draw insights and conclusions.
Benchmark results
Our benchmark results showed significant enhancements across all three job categories for both runtime speedup and cost-efficiency. The improvements were most pronounced for quick jobs, directly resulting from faster startup times. For instance, a 20-minute (including cluster provisioning and shut down) data workflow running on an EMR on EC2 transient cluster of fixed compute capacity finishes in 10 minutes on EMR Serverless, providing a shorter runtime with cost benefits. Overall, the shift to EMR Serverless delivered substantial performance improvements and cost reductions at scale across job brackets, as seen in the following figure.

Historically, we devoted more time to tuning our long-run workflows. Interestingly, we discovered that the existing custom Spark configurations for these jobs did not always translate well to EMR Serverless. In cases where the results were insignificant, a common approach was to discard previous Spark configurations related to executor cores. By allowing EMR Serverless to autonomously manage these Spark configurations, we often observed improved outcomes. The following graph shows the average runtime and cost improvement per job when comparing EMR Serverless to EMR on EC2.

The following table shows a sample comparison of results for the same workflow running on different deployment options of Amazon EMR (EMR on EC2 and EMR Serverless).
| Metric |
EMR on EC2
(Average) |
EMR Serverless
(Average) |
EMR on EC2 vs
EMR Serverless |
| Total Run Cost ($) |
$ 5.82 |
$ 2.60 |
55% |
| Total Run Time (Minutes) |
53.40 |
39.40 |
26% |
| Provisioning Time (Minutes) |
10.20 |
0.05 |
. |
| Provisioning Cost ($) |
$ 1.19 |
. |
. |
| Steps Time (Minutes) |
38.20 |
39.16 |
-3% |
| Steps Cost ($) |
$ 4.30 |
. |
. |
| Idle Time (Minutes) |
4.80 |
. |
. |
| EMR Release Label |
emr-6.9.0 |
. |
| Hadoop Distribution |
Amazon 3.3.3 |
. |
| Spark Version |
Spark 3.3.0 |
. |
| Hive/HCatalog Version |
Hive 3.1.3, HCatalog 3.1.3 |
. |
| Job Type |
Spark |
. |
AWS Graviton2 on EMR Serverless performance evaluation
After seeing compelling results with EMR Serverless for our workloads, we decided to further analyze the performance of the AWS Graviton2 (arm64) architecture within EMR Serverless. AWS had benchmarked Spark workloads on Graviton2 EMR Serverless using the TPC-DS 3TB scale, showing a 27% overall price-performance improvement.
To better understand the integration benefits, we ran our own study using GoDaddy’s production workloads on a daily schedule and observed an impressive 23.8% price-performance enhancement across a range of jobs when using Graviton2. For more details about this study, see GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless.
Adoption strategy for EMR Serverless
We strategically implemented a phased rollout of EMR Serverless via deployment rings, enabling systematic integration. This gradual approach let us validate improvements and halt further adoption of EMR Serverless, if needed. It served both as a safety net to catch issues early and a means to refine our infrastructure. The process mitigated change impact through smooth operations while building team expertise of our Data Engineering and DevOps teams. Additionally, it fostered tight feedback loops, allowing prompt adjustments and ensuring efficient EMR Serverless integration.
We divided our workflows into three main adoption groups, as shown in the following image:
- Canaries – This group aids in detecting and resolving any potential problems early in the deployment stage.
- Early adopters – This is the second batch of workflows that adopt the new compute solution after initial issues have been identified and rectified by the canaries group.
- Broad deployment rings – The largest group of rings, this group represents the wide-scale deployment of the solution. These are deployed after successful testing and implementation in the previous two groups.

We further broke down these workflows into granular deployment rings to adopt EMR Serverless, as shown in the following table.
| Ring # |
Name |
Details |
| Ring 0 |
Canary |
Low adoption risk jobs that are expected to yield some cost saving benefits. |
| Ring 1 |
Early Adopters |
Low risk Quick-run Spark jobs that expect to yield high gains. |
| Ring 2 |
Quick-run |
Rest of the Quick-run (step_time <= 20 min) Spark jobs |
| Ring 3 |
LargerJobs_EZ |
High potential gain, easy move, medium-run and long-run Spark jobs |
| Ring 4 |
LargerJobs |
Rest of the medium-run and long-run Spark jobs with potential gains |
| Ring 5 |
Hive |
Hive jobs with potentially higher cost savings |
| Ring 6 |
Redshift_EZ |
Easy migration Redshift jobs that suit EMR Serverless |
| Ring 7 |
Glue_EZ |
Easy migration Glue jobs that suit EMR Serverless |
Production adoption results summary
The encouraging benchmarking and canary adoption results generated considerable interest in wider EMR Serverless adoption at GoDaddy. To date, the EMR Serverless rollout remains underway. Thus far, it has reduced costs by 62.5% and accelerated total batch workflow completion by 50.4%.
Based on preliminary benchmarks, our team expected substantial gains for quick jobs. To our surprise, actual production deployments surpassed projections, averaging 64.4% faster vs. 42% projected, and 71.8% cheaper vs. 40% predicted.
Remarkably, long-running jobs also saw significant performance improvements due to the rapid provisioning of EMR Serverless and aggressive scaling enabled by dynamic resource allocation. We observed substantial parallelization during high-resource segments, resulting in a 40.5% faster total runtime compared to traditional approaches. The following chart illustrates the average enhancements per job category.

Additionally, we observed the highest degree of dispersion for speed improvements within the long-run job category, as shown in the following box-and-whisker plot.

Sample workflows adopted EMR Serverless
For a large workflow migrated to EMR Serverless, comparing 3-week averages pre- and post-migration revealed impressive cost savings—a 75.30% decrease based on retail pricing with 10% improvement in total runtime, boosting operational efficiency. The following graph illustrates the cost trend.

Although quick-run jobs realized minimal per-dollar cost reductions, they delivered the most significant percentage cost savings. With thousands of these workflows running daily, the accumulated savings are substantial. The following graph shows the cost trend for a small workload migrated from EMR on EC2 to EMR Serverless. Comparing 3-week pre- and post-migration averages revealed a remarkable 92.43% cost savings on the retail on-demand pricing, alongside an 80.6% acceleration in total runtime.

Layer 7: Platform-wide improvements
We aim to revolutionize compute operations at GoDaddy, providing simplified yet powerful solutions for all users with our Intelligent Compute Platform. With AWS compute solutions like EMR Serverless and EMR on EC2, it provided optimized runs of data processing and machine learning (ML) workloads. An ML-powered job broker intelligently determines when and how to run jobs based on various parameters, while still allowing power users to customize. Additionally, an ML-powered compute resource manager pre-provisions resources based on load and historical data, providing efficient, fast provisioning at optimum cost. Intelligent compute empowers users with out-of-the-box optimization, catering to diverse personas without compromising power users.
The following diagram shows a high-level illustration of the intelligent compute architecture.

Insights and recommended best-practices
The following section discusses the insights we’ve gathered and the recommended best practices we’ve developed during our preliminary and wider adoption stages.
Infrastructure preparation
Although EMR Serverless is a deployment method within EMR, it requires some infrastructure preparedness to optimize its potential. Consider the following requirements and practical guidance on implementation:
- Use large subnets across multiple Availability Zones – When running EMR Serverless workloads within your VPC, make sure the subnets span across multiple Availability Zones and are not constrained by IP addresses. Refer to Configuring VPC access and Best practices for subnet planning for details.
- Modify maximum concurrent vCPU quota – For extensive compute requirements, it is recommended to increase your max concurrent vCPUs per account service quota.
- Amazon MWAA version compatibility – When adopting EMR Serverless, GoDaddy’s decentralized Amazon MWAA ecosystem for data pipeline orchestration created compatibility issues from disparate AWS Providers versions. Directly upgrading Amazon MWAA was more efficient than updating numerous DAGs. We facilitated adoption by upgrading Amazon MWAA instances ourselves, documenting issues, and sharing findings and effort estimates for accurate upgrade planning.
- GoDaddy EMR operator – To streamline migrating numerous Airflow DAGs from EMR on EC2 to EMR Serverless, we developed custom operators adapting existing interfaces. This allowed seamless transitions while retaining familiar tuning options. Data engineers could easily migrate pipelines with simple find-replace imports and immediately use EMR Serverless.
Unexpected behavior mitigation
The following are unexpected behaviors we ran into and what we did to mitigate them:
- Spark DRA aggressive scaling – For some jobs (8.33% of initial benchmarks, 13.6% of production), cost increased after migrating to EMR Serverless. This was due to Spark DRA excessively assigning new workers briefly, prioritizing performance over cost. To counteract this, we set maximum executor thresholds by adjusting
spark.dynamicAllocation.maxExecutor, effectively limiting EMR Serverless scaling aggression. When migrating from EMR on EC2, we suggest observing the max core count in the Spark History UI to replicate similar compute limits in EMR Serverless, such as --conf spark.executor.cores and --conf spark.dynamicAllocation.maxExecutors.
- Managing disk space for large-scale jobs – When transitioning jobs that process large data volumes with substantial shuffles and significant disk requirements to EMR Serverless, we recommend configuring
spark.emr-serverless.executor.disk by referring to existing Spark job metrics. Furthermore, configurations like spark.executor.cores combined with spark.emr-serverless.executor.disk and spark.dynamicAllocation.maxExecutors allow control over the underlying worker size and total attached storage when advantageous. For example, a shuffle-heavy job with relatively low disk usage may benefit from using a larger worker to increase the likelihood of local shuffle fetches.
Conclusion
As discussed in this post, our experiences with adopting EMR Serverless on arm64 have been overwhelmingly positive. The impressive results we’ve achieved, including a 60% reduction in cost, 50% faster runs of batch Spark workloads, and an astounding five-times improvement in development and testing speed, speak volumes about the potential of this technology. Furthermore, our current results suggest that by widely adopting Graviton2 on EMR Serverless, we could potentially reduce the carbon footprint by up to 60% for our batch processing.
However, it’s crucial to understand that these results are not a one-size-fits-all scenario. The enhancements you can expect are subject to factors including, but not limited to, the specific nature of your workflows, cluster configurations, resource utilization levels, and fluctuations in computational capacity. Therefore, we strongly advocate for a data-driven, ring-based deployment strategy when considering the integration of EMR Serverless, which can help optimize its benefits to the fullest.
Special thanks to Mukul Sharma and Boris Berlin for their contributions to benchmarking. Many thanks to Travis Muhlestein (CDO), Abhijit Kundu (VP Eng), Vincent Yung (Sr. Director Eng.), and Wai Kin Lau (Sr. Director Data Eng.) for their continued support.
About the Authors
 Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games.
Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games.
 Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan.
Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan.
 John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike.
John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike.
Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects.
 Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.









 Jaydev Nath is a Solutions Architect at AWS, where he works with ISV customers to build secure, scalable, reliable, and cost-efficient cloud solutions. He brings strong expertise in building SaaS architecture on AWS with a focus on Generative AI and data analytics technologies to help deliver practical, valuable business outcomes for customers.
Jaydev Nath is a Solutions Architect at AWS, where he works with ISV customers to build secure, scalable, reliable, and cost-efficient cloud solutions. He brings strong expertise in building SaaS architecture on AWS with a focus on Generative AI and data analytics technologies to help deliver practical, valuable business outcomes for customers. David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights.
David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights. Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.
Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.



 Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.










 Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI. Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains.
Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains. Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.
Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.

 Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas, USA. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas, USA. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data. Pinar Yasar is the Data Engineering Manager at Getir. Her passion is to accelerate self-service analytics for her internal customers and build highly scalable and cost-effective solutions in the cloud.
Pinar Yasar is the Data Engineering Manager at Getir. Her passion is to accelerate self-service analytics for her internal customers and build highly scalable and cost-effective solutions in the cloud.


 Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible. Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.



 Salim Tutuncu is a Sr. PSA Specialist on Data & AI, based from Amsterdam with a focus on the EMEA North and EMEA Central regions. With a rich background in the technology sector that spans roles as a Data Engineer, Data Scientist, and Machine Learning Engineer, Salim has built a formidable expertise in navigating the complex landscape of data and artificial intelligence. His current role involves working closely with partners to develop long-term, profitable businesses leveraging the AWS Platform, particularly in Data and AI use cases.
Salim Tutuncu is a Sr. PSA Specialist on Data & AI, based from Amsterdam with a focus on the EMEA North and EMEA Central regions. With a rich background in the technology sector that spans roles as a Data Engineer, Data Scientist, and Machine Learning Engineer, Salim has built a formidable expertise in navigating the complex landscape of data and artificial intelligence. His current role involves working closely with partners to develop long-term, profitable businesses leveraging the AWS Platform, particularly in Data and AI use cases. Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.










 Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games.
Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games. Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan.
Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan. John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike.
John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike. Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects.
Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects. Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.














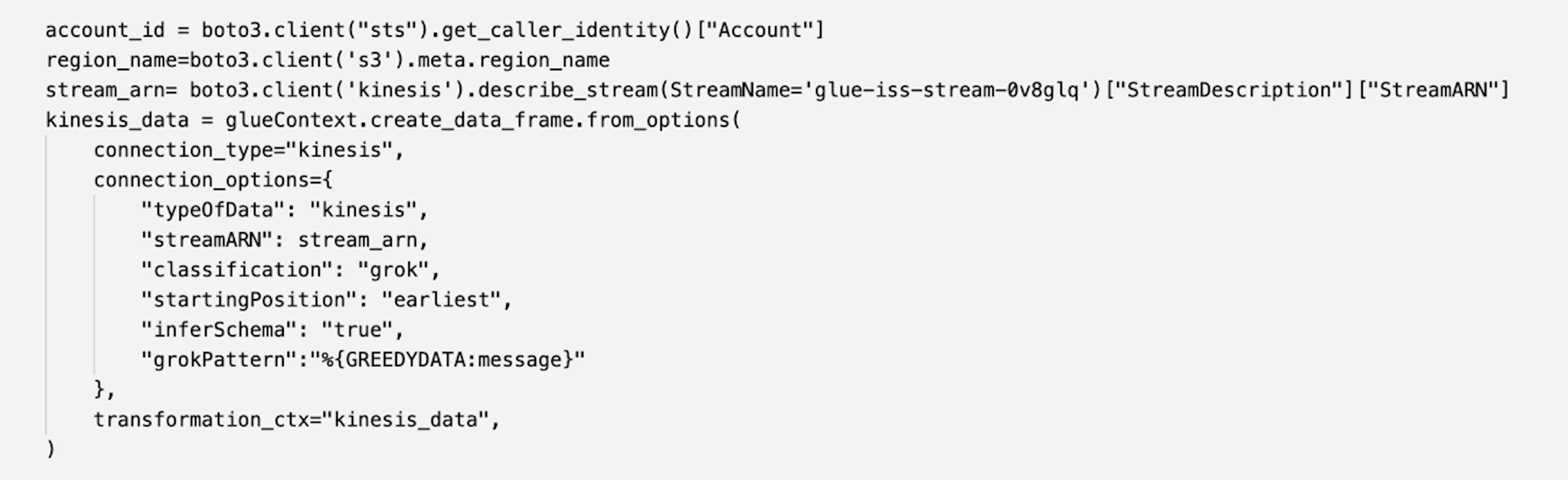












 Chao Pan is a Data Analytics Solutions Architect at Amazon Web Services. He’s responsible for the consultation and design of customers’ big data solution architectures. He has extensive experience in open-source big data. Outside of work, he enjoys hiking.
Chao Pan is a Data Analytics Solutions Architect at Amazon Web Services. He’s responsible for the consultation and design of customers’ big data solution architectures. He has extensive experience in open-source big data. Outside of work, he enjoys hiking.












