Earlier today the document describing Network Time Security for NTP officially became RFC 8915. This means that Network Time Security (NTS) is officially part of the collection of protocols that makes the Internet work. We’ve changed our time service to use the officially assigned port of 4460 for NTS key exchange, so you can use our service with ease. This is big progress towards securing a ubiquitous Internet protocol.
Over the past months we’ve seen many users of our time service, but very few using Network Time Security. This leaves computers vulnerable to attacks that imitate the server they use to obtain NTP. Part of the problem was the lack of available NTP daemons that supported NTS. That problem is now solved: chrony and ntpsec both support NTS.
Time underlies the security of many of the protocols such as TLS that we rely on to secure our online lives. Without accurate time, there is no way to determine whether or not credentials have expired. The absence of an easily deployed secure time protocol has been a problem for Internet security.
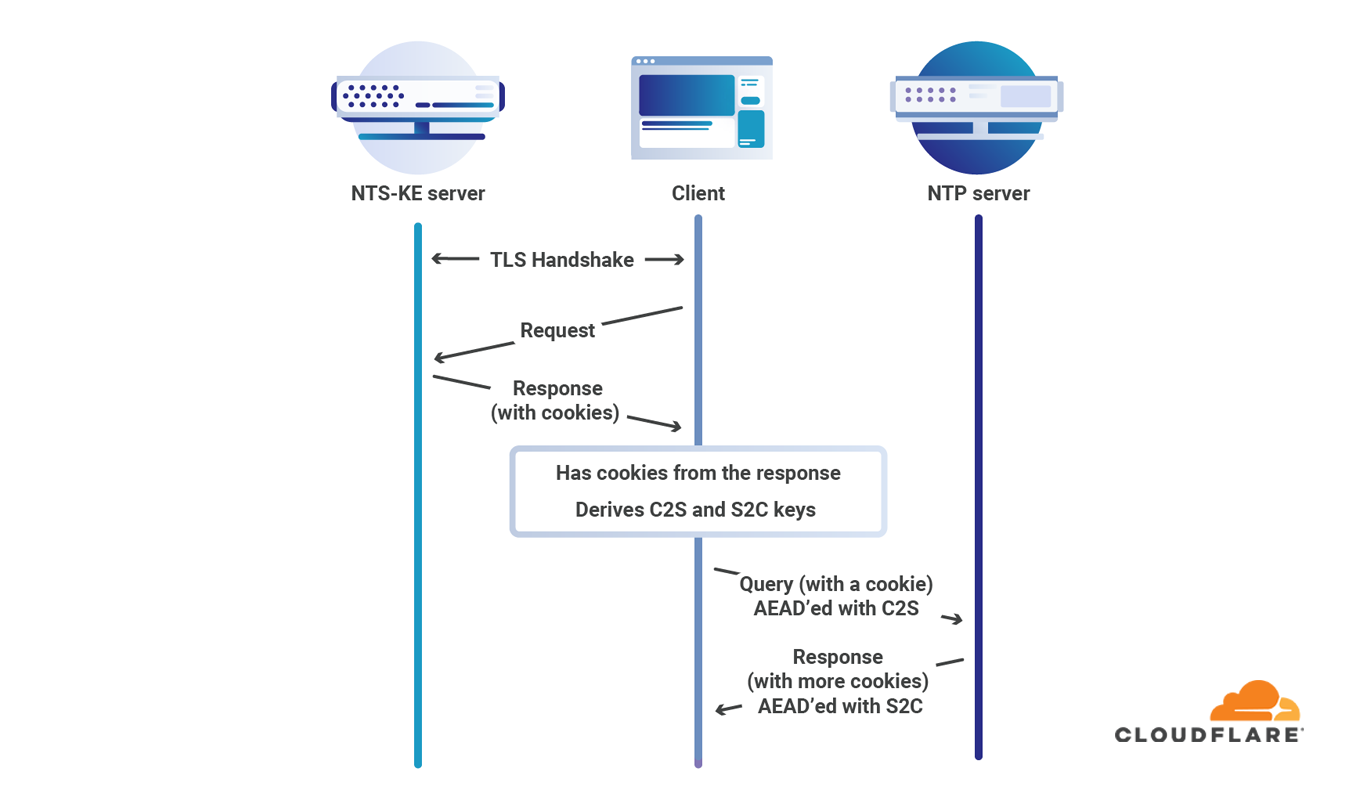
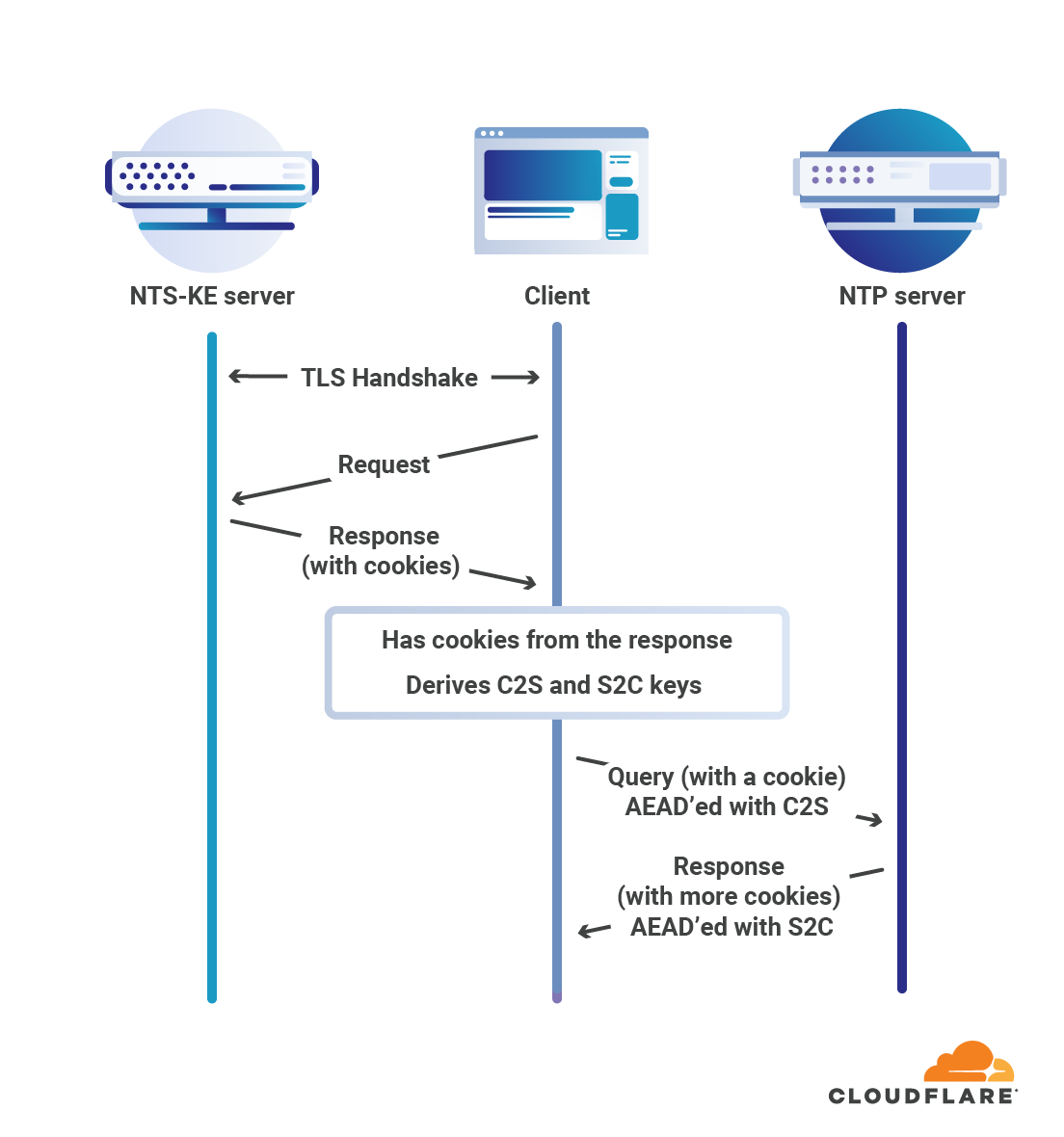
Without NTS or symmetric key authentication there is no guarantee that your computer is actually talking NTP with the computer you think it is. Symmetric key authentication is difficult and painful to set up, but until recently has been the only secure and standardized mechanism for authenticating NTP. NTS uses the work that goes into the Web Public Key Infrastructure to authenticate NTP servers and ensure that when you set up your computer to talk to time.cloudflare.com, that’s the server your computer gets the time from.
Our involvement in developing and promoting NTS included making a specialized server and releasing the source code, participation in the standardization process, and much working with implementers to hunt down bugs. We also set up our time service with support for NTS from the beginning, and it was a useful resource for implementers to test interoperability.
NTS operation diagram
When Cloudflare supported TLS 1.3 browsers were actively updating, and so deployment quickly took hold. However, the long tail of legacy installs and extended support releases slowed adoption. Similarly until Let’s Encrypt made encryption easy for webservers most web traffic was not encrypted.
By contrast ssh quickly displaced telnet as the way to access remote systems: the security benefits were substantial, and the experience was better. Adoption of protocols is slow, but when there is a real security need it can be much faster. NTS is a real security improvement that is vital to adopt. We’re proud to continue making the Internet a better place by supporting secure protocols.
We hope that operating systems will incorporate NTS support and TLS 1.3 in their supplied NTP daemons. We also urge administrators to deploy NTS as quickly as possible, and NTP server operators to adopt NTS. With Let’s Encrypt provided certificates this is simpler than it has been in the past
We’re continuing our work in this area with the continued development of the Roughtime protocol for even better security as well as engagement with the standardization process to help develop the future of Internet time.
Cloudflare is willing to allow any device to point to time.cloudflare.com and supports NTS. Just as our Universal SSL made it easy for any website to get the security benefits of TLS, our time service makes it easy for any computer to get the benefits of secure time.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.